百度搜索详解预训练模型在信息检索第一阶段的应用

百度技术 稿
导读:近年来,预训练模型在自然语言处理的不同任务中都取得了极大的成功,在信息检索中也进步不小。近期,我们邀请到了中科院的范意兴博士现场分享,内容聚焦预训练模型在信息检索中第一阶段检索(召回阶段)的应用,并对最近几年的相关研究进行系统的梳理和回顾。
一、信息检索的发展过程
1、信息检索三个层次的视角
1)从基础问题的角度。查询与文档的相关性度量是信息检索的核心问题,重点关注检索结果的准确度,但相关性目前仍无明确定义,是与场景、需求和认知有关的一个概念。
2)从检索框架的角度,需要从大量的文档集合里快速返回相关的文档并排序,除了检索结果的正确性,还要考虑检索的效率。
3)从系统的角度,不仅要解决排序的问题,还要解决用户意图模糊、用户输入有错、文档结构异质等问题。
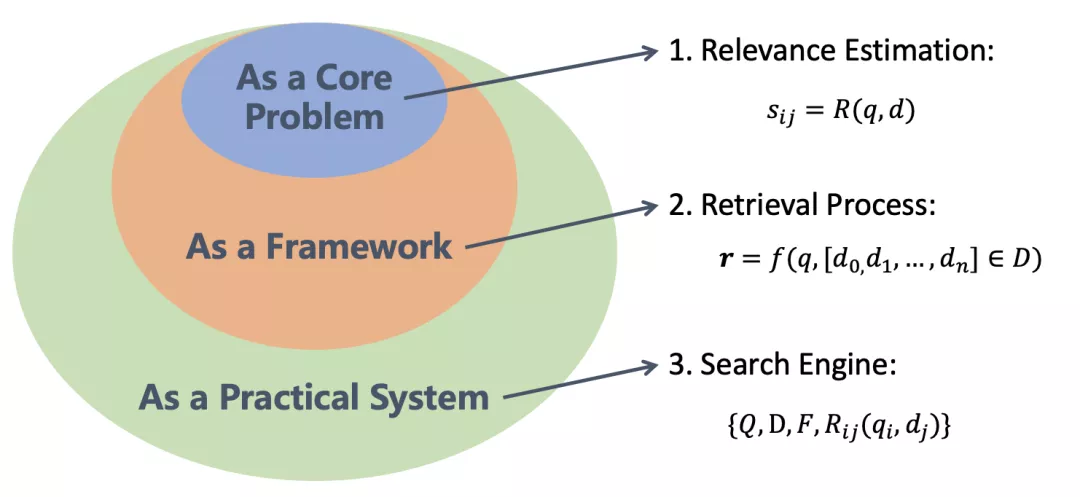
2、信息检索的发展过程
1) 相关性度量
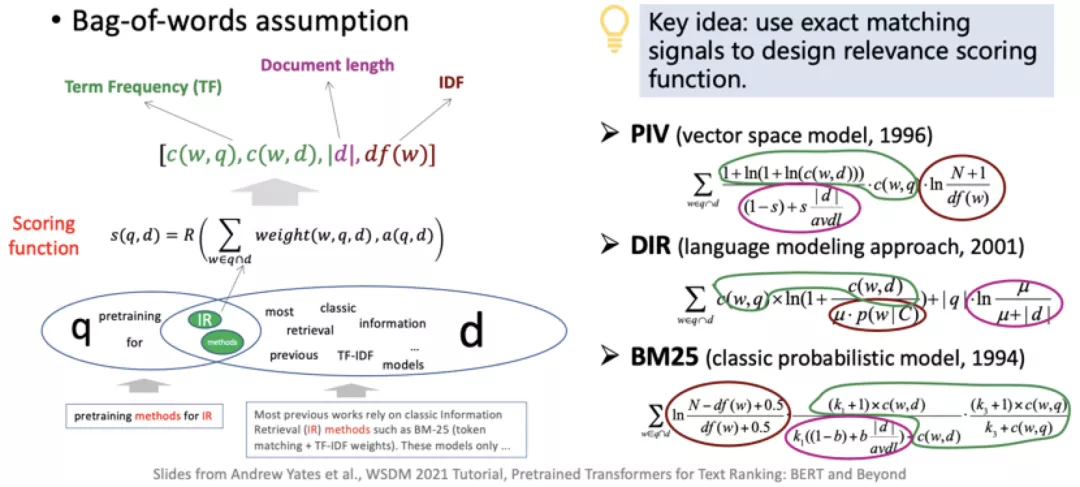
相关性度量的建模范式,经历了 传统检索模型、Learning-to-rank (LTR)模型、Neural IR(NeuIR)模型 的演进。传统检索模型更多关注查询和文档中重叠的词,在此基础上建模权重,后将不同权重的得分组合,得到相关性得分。代表性的方法包括 PlV、DIR、Language Model、BM25等,都是通过对词频、文档长度、以及词的IDF的不同组合方式,来得到度量的得分。
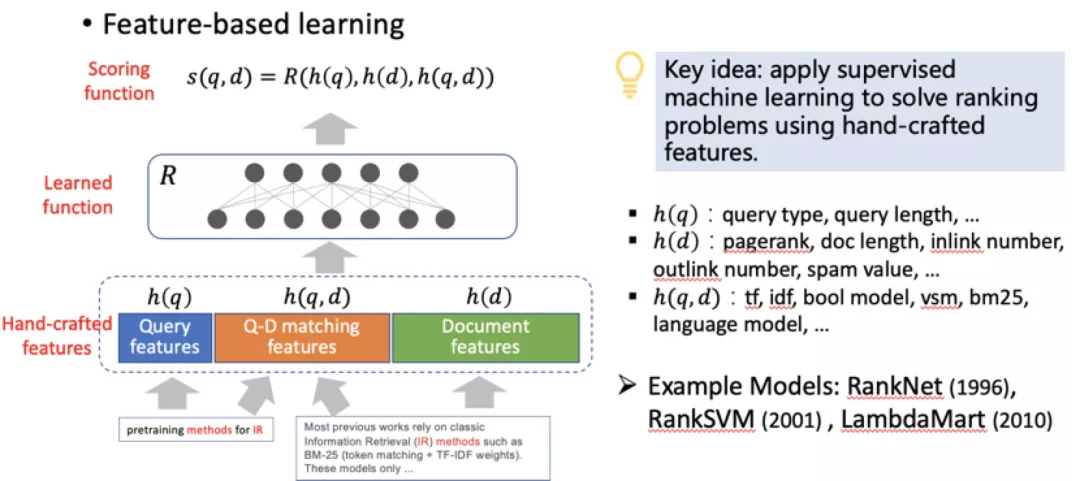
LTR 模型的建模过程,是从指标函数的计算变成特征学习的过程。通过人工构造不同特征,后采用神经网络或者函数优化的方式,来解决特征组合的问题。代表方法包括RankNet、RankSVM、LambdaMart等。
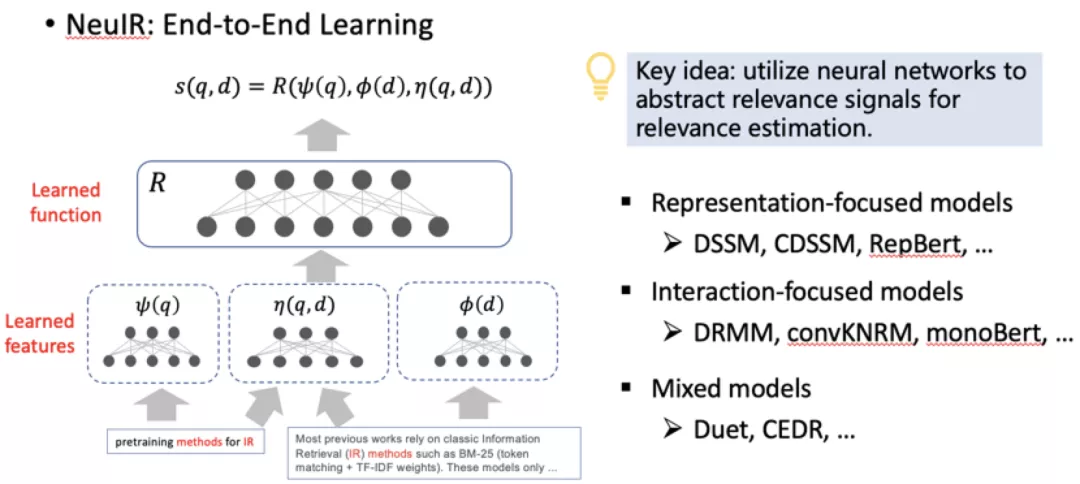
NeuIR方法 更进一步,通过模型学习构建人工设计特征的过程,采用机器学习优化的方式来抽取特征。大致可以分为3类:一是基于表示的方法,单独学习查询和文档的表示进行打分;二是基于交互的方法,把查询和文档从底层做交互,对交互信号进行抽象得到打分;三是将二者结合起来进行打分。
2) 检索框架
检索框架的发展经历了从单阶段检索到多阶段检索的过程,早期的检索引擎(例如Indri、ES等)主要是构建单阶段检索,使用BM25、LM等传统算法。后续引入了更多的阶段来进一步提升系统的效率,包括L2R和Neural等,这些方法的计算复杂度很高,通常放在 Reranker 阶段。
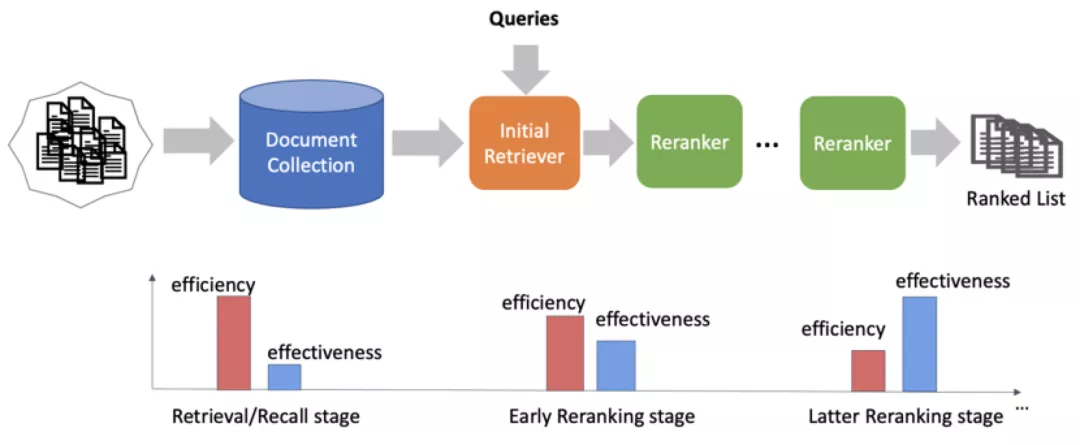
3) 检索系统
为了满足实际检索场景的需要,检索系统包含更多的模块,包括查询改写、意图理解、文档索引等。在检索系统中,从底层文档存储的结构来看,它经历了从基于符号的系统架构到基于向量的系统架构的转变,在真实的检索系统中,通常也会结合二者的优势来建模。
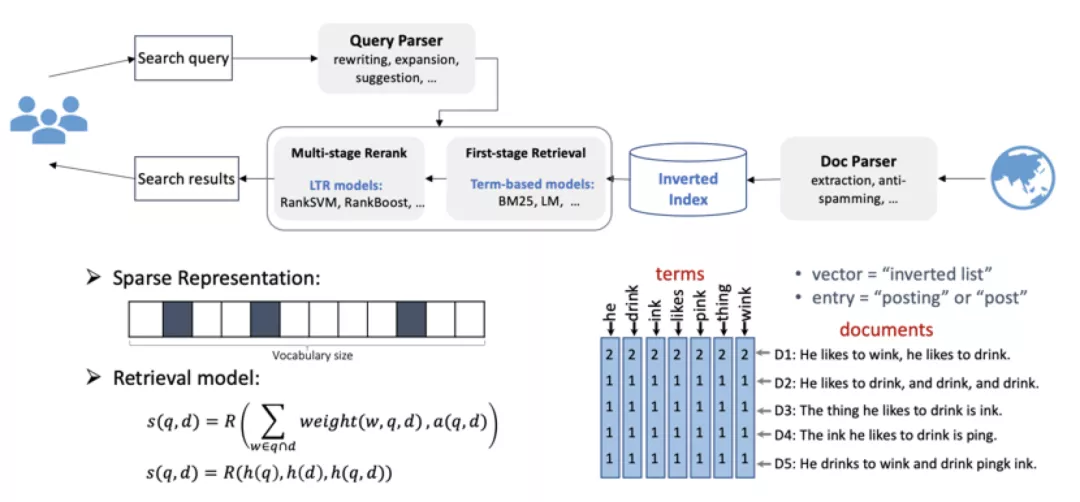
基于符号的检索系统,通过把文档表示成一个高维稀疏的向量,每个词在向量里占一维,每个文档映射在词表向量上就是一个极度稀疏的表示。存储结构采用倒排索引的方式,在离线阶段把文档索引起来。
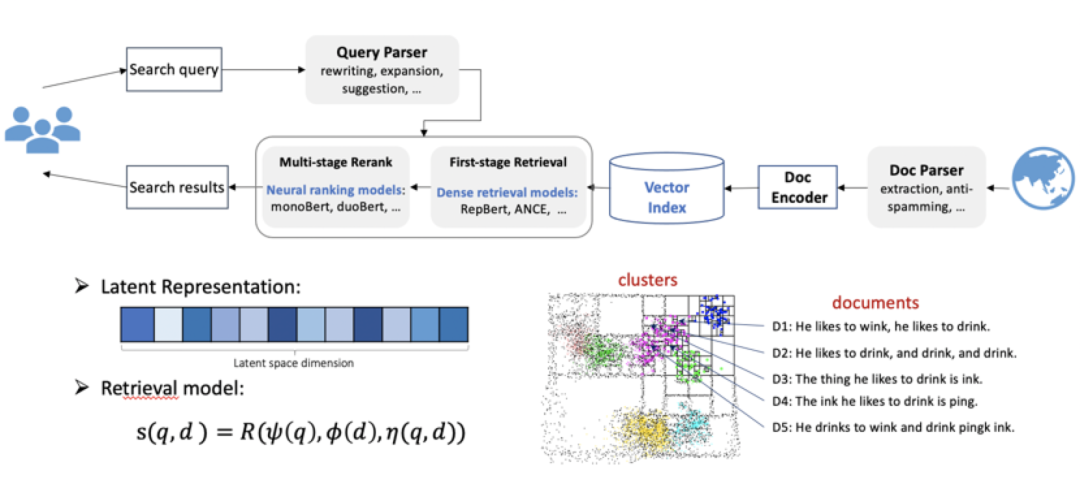
基于向量的检索系统 主要通过语义映射将文档映射到一个低维稠密的向量空间。这里采用的索引方式包括基于图和量化的方法,这种方式也带动了整个系统的架构变迁。
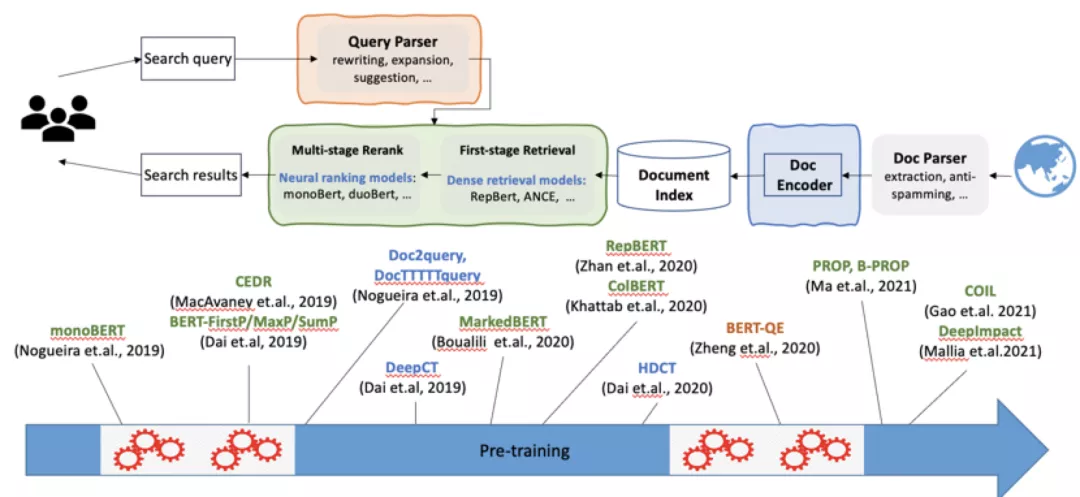
预训练的方法在检索系统中的不同模块都有应用:在Query Parser层面有rewriting、expansion、suggestion;在Doc Encode层面也有很多文档编码的方式;在第一阶段检索、重排阶段也提出了不同的模型。
二、预训练在检索第一阶段的应用
1、基于Term-based检索模型的两个问题
第一阶段检索早期的方法是基于Term-based的方法,主要是对文档清洗,通过倒排方式索引到引擎中。这类方法面临两个经典的问题:一是查询稀疏与文档冗余带来的词失配的问题;二是无序词排列导致丢失语义依赖信息的问题。这两个问题造成语义信息丢失,导致后续建模无法提升性能。
2、三种解决方法
针对以上问题主要有三类不同提升方法,分别是:稀疏检索方法(Sparse Retrieval)、稠密检索方法(Dense Retrieval)、混合方法(Hybrid Retrieval)。
- Sparse Retrieval:
- 保持表示的稀疏性,与倒排索引集成以实现高效检索。
- Dense Retrieval:
- 从符号空间到语义空间,使用神经网络算法进行语义相似检索
- Hybrid: 结合基于倒排的检索和语义检索,继承两者的优点。
1)Sparse Retrieval
根据改进倒排索引中模块的不同,Sparse Retrieval可以分为Neural Weighting Scheme和Sparse Representation Learning两类。
- Neural Weighting Scheme
利用离散符号空间中的预训练模型改进项加权方案。
主要包括:
a)Term Re-weighting
通过改变原始文档在倒排索引中的权重来提升语义,通过预训练的模型从语义的角度来估计词的权重。其中有两个代表方法:
- DeepCT [Dai et al., SIGIR 2020] :核心思想是用BERT里学好的基于上下文的向量来估计每一个词对于文档的重要度并把它索引到倒排索引中替换原来的基于词频统计权重的方式。
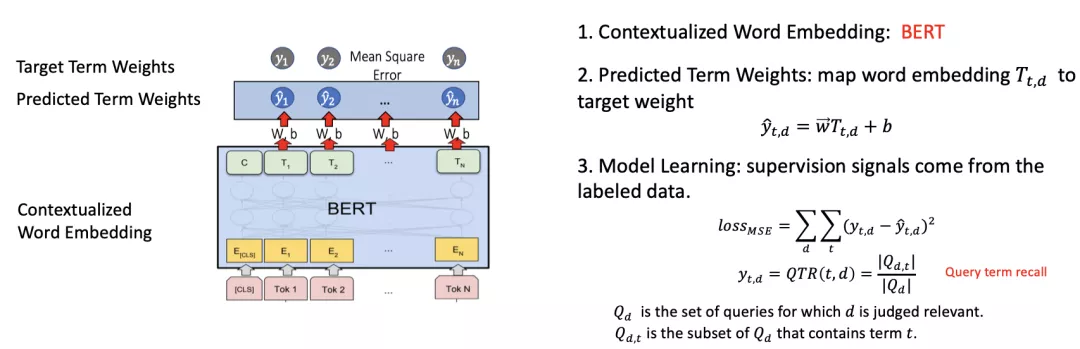
这里的关键问题是如何构建监督信号来学习词权重,论文提出了一种 Query term recall 的监督信号进行学习。
- HDCT[Dai et al., WWW 2020]
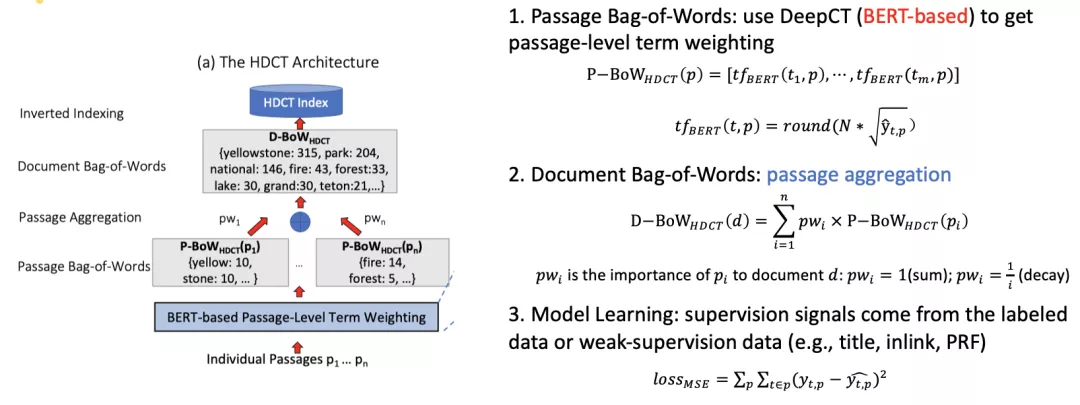
核心思想是将文档拆成段落,对每个段落去估计每个词的权重最后把每个段落里的权重组合起来。存在两个核心问题:一是每个段落中词的权重如何评估,这里直接采用了DeepCT的估计方式,此外,对预测的打分开根乘以N再Round到整数后进行索引,避免匹配过程被部分高权重的词所主导。二是如何组合段落的词权重形成文档的词权重,论文采用的是平均加权和按段落位置衰减的方式加权。
b)Document Expansion
为文档扩展语义相关词项,提高部分词项的权重,缓解词汇失配问题。其思想是在索引的过程中预测和文档相关的词并全部加入文档中,添加到倒排索引中去。
- doc2query/docTTTTTquery [Noqueira et al., 2019]
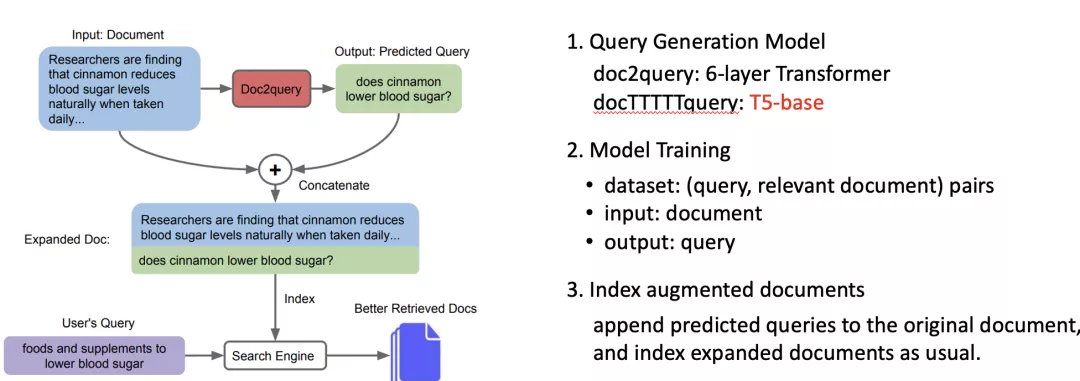
doc2query的结构是6层的Transformer,docT5query与doc2query的区别是利用了一个更强大的预训练模型T5来生成扩展词项。其核心思想都是利用给定的查询和文档的标注对训练一个Seq2Seq生成模型,然后对每个文档生成伪query拼接到文档尾部进行索引构建。
- UED (Unified Encoder-Decoder) [Yan et al., AAAI 2021]
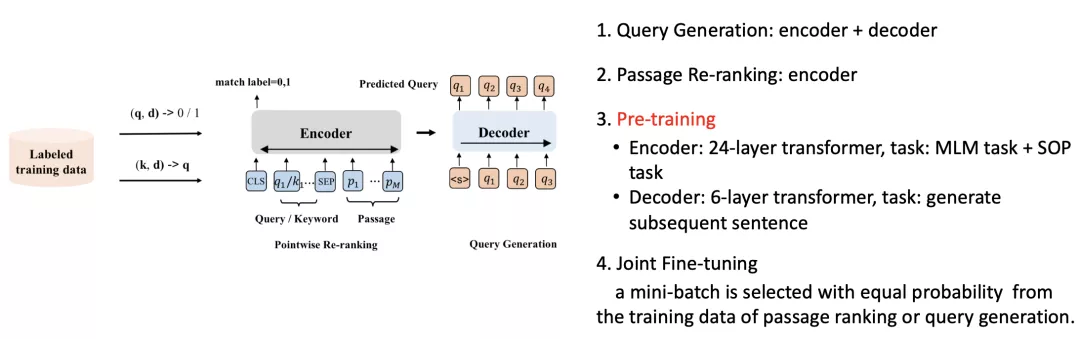
该方法的核心思想是利用训练集中有标注好的(q,d)对同时训练判别模型和生成模型,一方面可以只用Encoder部分将(q,d)拼起来做相关性的判别预测,另一方面可以额外加一个Decoder部分来生成查询。两部分同时学习互相增益会使Encoder部分更强。
c)Expansion + Re-weighting
该种方式是把文档扩展与词权重同时进行学习,代表性工作有:
- SparTerm [Bai et al., AAAI 2021]
SparTerm方法在整个词表上进行词权重评估,从而达到词项扩展以及词权重估计同时进行的效果。
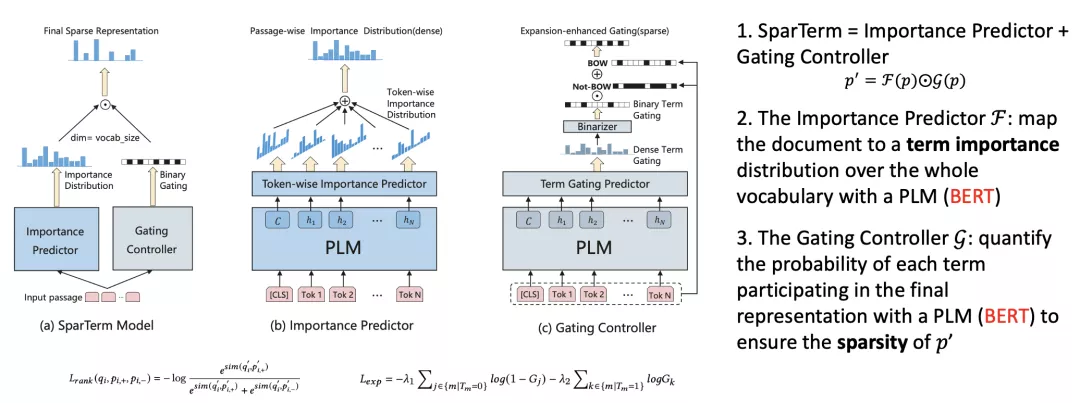
- SPLADE [Formal et al., SIGIR 2021]
SparTerm的重要性估计部分是提前学习好的并且从实验结果来看词项扩展能力比较受限,SPLADE在它的基础上做了扩展:一是把原来词估计的权重进行saturate function使扩展能力变强,二是利用FLOPS正则项约束来使整体网络可以端到端地学习。
- Sparse Representation Learning
另一种方法就是把文档映射到一个语义向量的隐空间中去。
- Latent Term Indexing
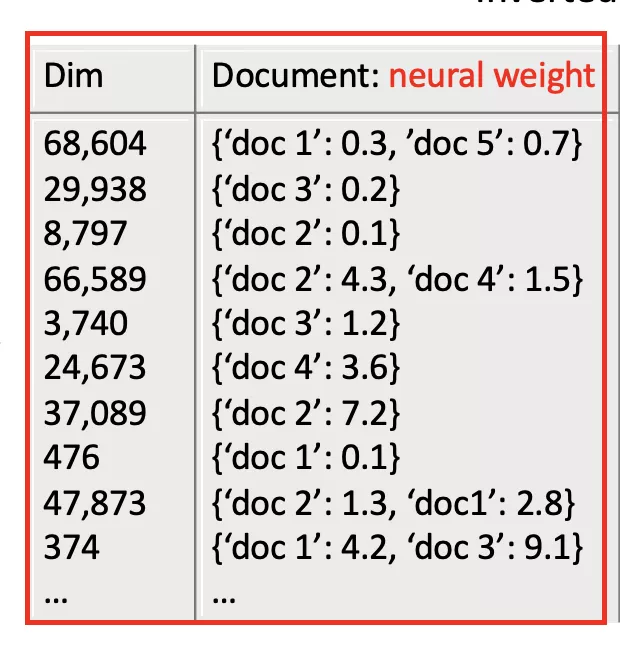
文档倒排索引中每个维度对应的词,现在映射到一个关联多维语义的“latent term ”的ID。
- SNRM [Zamani et al., CIKM 2018]
核心思想是对文档的词序列进行卷积操作获取每一个N-grams的表示,然后将其经过全连接的映射进行语义抽象后再反向稀疏化放大到更高的维度,最后通过池化操作得到高维稀疏的文档表达。
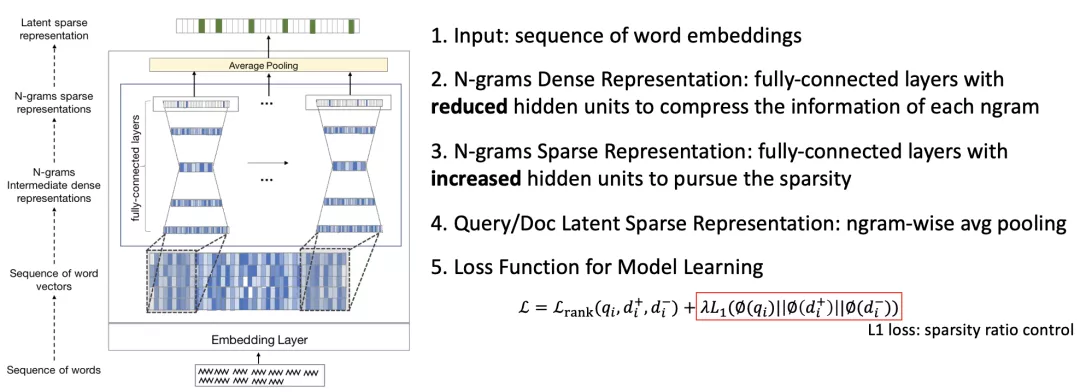
- UHD-BERT (Bucketed Ultra-High Dimensional Sparse Representations) [Jang et al., 2021]

在SNRM基础上提出一个基于BERT的稀疏表示学习方法,区别于SNRM用的卷积和全连接,UHD-BERT底层Encoder用的是BERT。
2)Dense Retrieval
Dense Retrieval直接改变了原有的检索模式,把查询和文档映射到语义空间中,然后用ANN算法来进行检索。一般采用双塔的编码方式对查询和文档单独地编码得到二者独立的表达,从而使文档可以进行离线索引。这类方法可以分为两类:Term-level Representations、Doc-level Representations。
- Term-level Representations
- ColBERT [Khattab et al., SIGIR 2020]
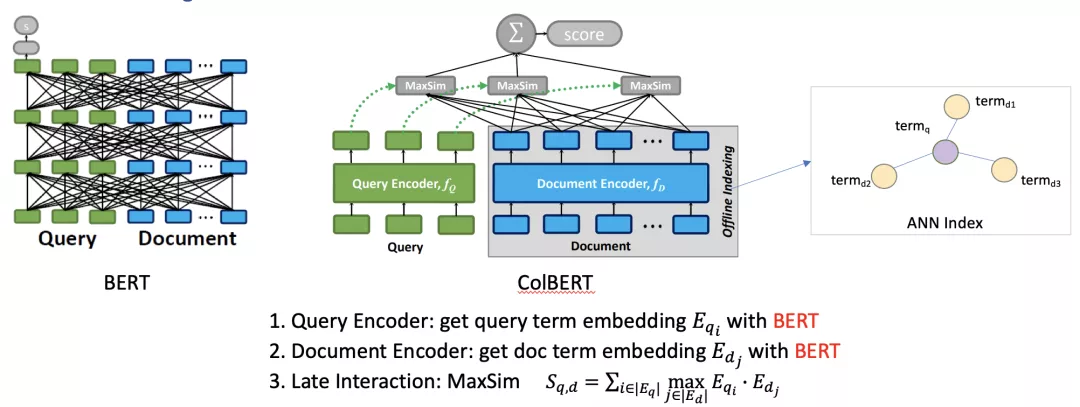
核心思想是把交互的过程延迟到后面去使得前面表达的计算可以单独进行,上层交互采用MaxSim计算函数对每个查询词和文档中的每一个词计算相似度取最大,然后把每个查询词的得分加和起来得到最终的相似度分值,ColBERT性能相对于上文提到的方法都有较大提升。
- Doc-level Representations
- RepBERT [Zhan et al., 2020] , DPR [Karpukhin et al., EMNLP 2020]

该方法是采用双塔的BERT来建模查询和文档的表示进行相似度计算。在训练的方式上有一些特别,会采用一些BM25召回的强负例来提升模型的建模能力。
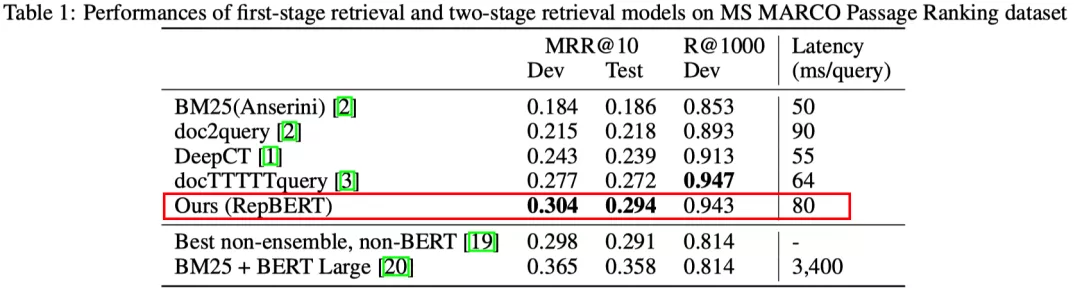
可以看到,RepBERT方法非常简单而且性能比DeepCT等都要好但相对于BM25+BERT Large这样交互式的模型还是要差。
- TCT-ColBERT [Lin et al., 2020]
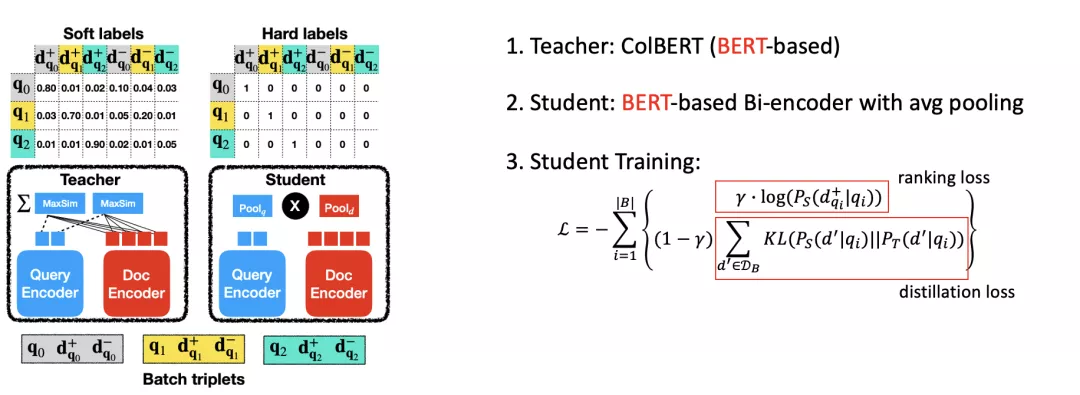
ColBERT性能相比传统方法得到大幅提升但需要大量的文档存储,TCT-ColBERT通过蒸馏技术,将ColBERT的强建模能力蒸馏到类似于RepBERT这样的双塔架构上去,从而降低搜索延迟减少存储代价。
- Multi-vector —— ME-BERT [Luan et al., TACL 2020]
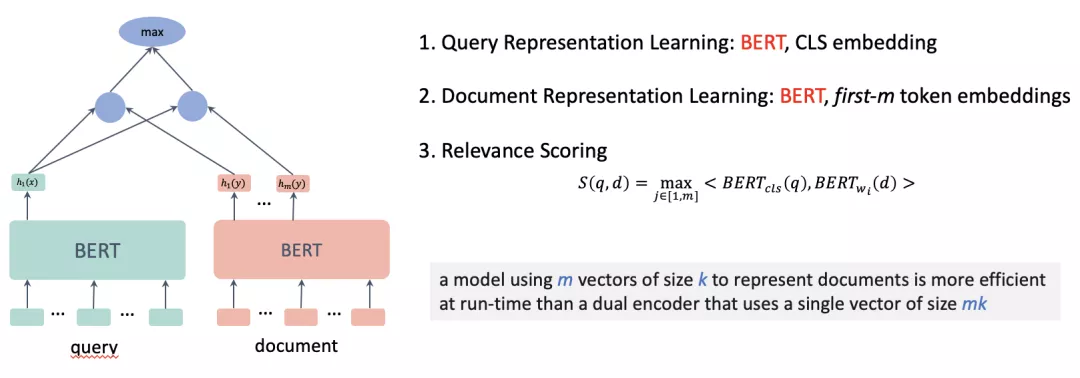
将BERT得到的前M个词的表达作为文档的表达,构建索引的时候同时索引多个向量,计算最终得分的时候通过max来取与查询表达相似度最高的分值。
- Multi-vector [Tang et al., TACL 2021]

相较于直接取前M个词的表达,该种方法用聚类的方法,利用k-means对文档所有词的表达进行聚类得到k个簇中心,所有簇中心的向量共同作为文档表达,然后与查询计算相似度,取最大的相似度分值作为最终的相关性得分。
3) Hybrid of Sparse-dense Retrieval
除了以上的两种建模方式,还可以将两种方式结合起来利用Sparse Retrieval和Dense Retrieval各自的优势来提升性能。
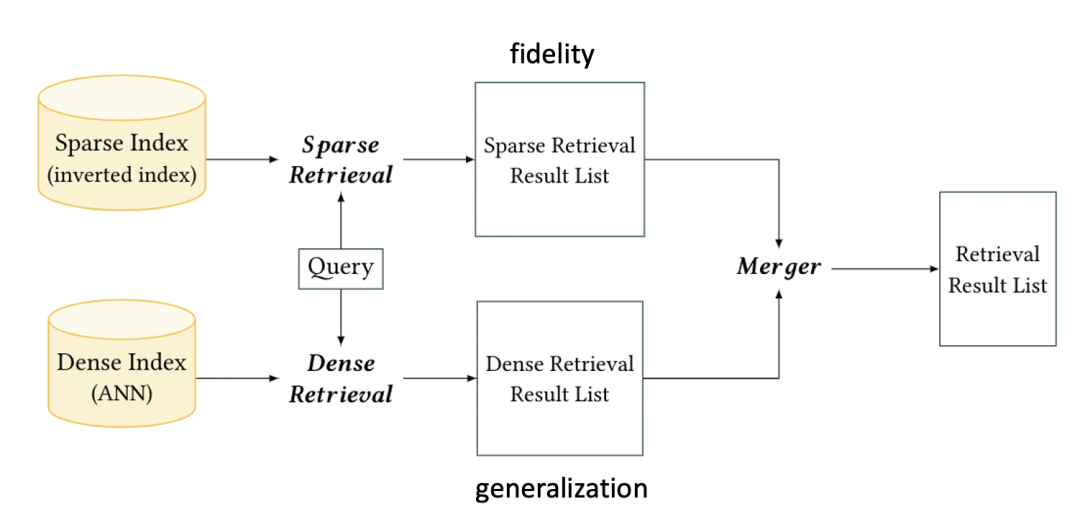
- CLEAR [Gao et al., ECIR 2021]
该方法是先用Sparse Retrieval进行检索将检索不好的查询再用Dense Retrieval进行增强。方式就是先计算Sparse Retrieval的结果并估计残差项,然后用残差项来监督Dense Retrieval模型的训练。

- COIL (COntextualized Inverted List) [Gao et al., NAACL 2021]
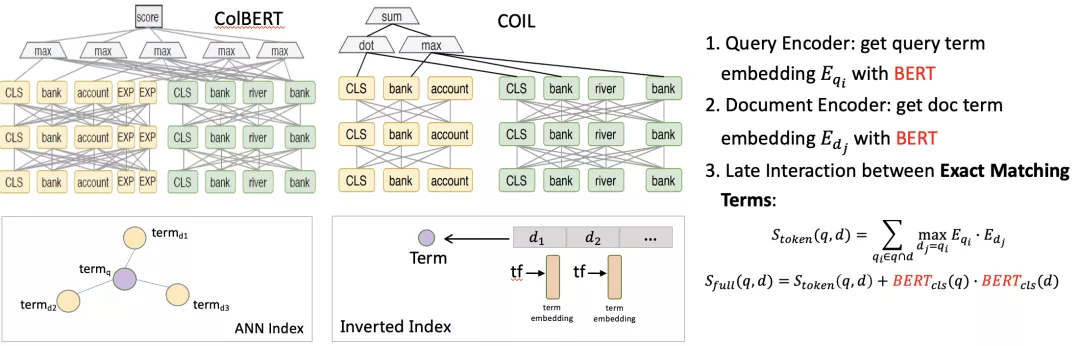
另一种是基于ColBERT基础之上,ColBERT依赖于ANN的检索方式计算量很大,而COIL改变底层索引结构改用倒排索引方式能够减少计算量。
三、在检索第一阶段的挑战性问题
1、负样本采样**
现在研究较多问题是,如何挖掘更强的负例来提升模型的判断能力。一般来说,无论用怎样的神经网络方法,最后算loss时都是区分正例和负例间的差异。由于召回阶段的文档规模非常大,在训练时不能将所有负例文档都进行计算,实际训练时一般通过采样来选择负例,如何高效挖掘最具信息量的负例是模型训练的一个关键问题。
当前几种方法有:
- ANCE
核心思想是初始学习先用BM25的方法采一些负例学习双塔的BERT模型,后续的学习过程利用前面学好的模型进行初始化,并对文档进行索引来检索得到top-n文档随机采样负样本,其中每隔一段时间都需要对文档索引进行更新,因此该方法的训练代价较大。
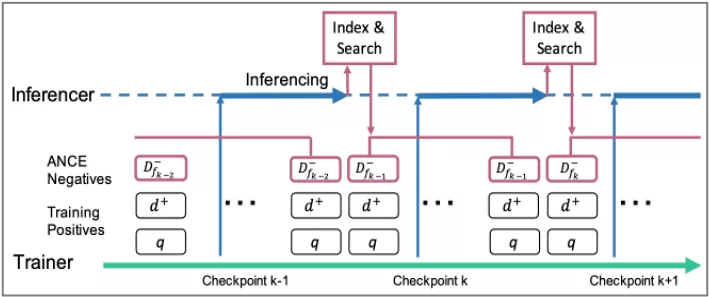
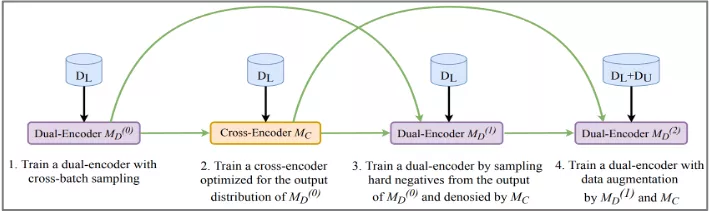
- RocketQA
RocketQA是百度提出的方法,它跟ANCE比较接近只是做了额外的 denoised 操作,如果使用学到的双塔模型的召回结果进行负样本采样的话可能会带来假负样本。该方法额外训练了一个更强的排序模型对召回的文档中靠前的部分进行相关性评估并去除可能的伪负样本。
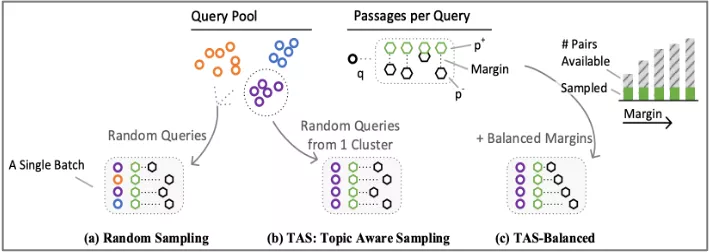
- TAS-Balanced
TAS-Balanced用了一个更复杂的采样策略,先对查询进行聚类,然后同一batch内的样本按簇进行采样。除此之外,在采样负样本时考虑了与正样本具有不同margin的文档。
2、索引联合学习
大部分双塔模型学习是独立于索引过程的,在训练过程中,查询和文档的相关性是基于神经网络输出的稠密向量计算得到。然而,在检索时,相关性的计算是基于索引后的文档表达,例如量化后的向量表示。两者之间的差异会对检索的性能造成一定的损失。那么怎么样能在学文档表示的同时,与索引阶段联合优化,也是一个很重要的问题。
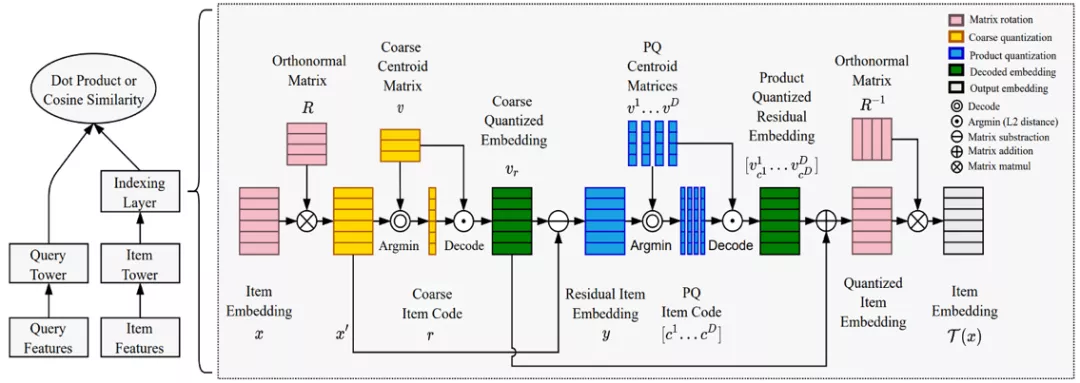
京东做了一个较新的方法就是把相关性的计算跟中间索引的过程联合起来。将乘积量化的索引过程的梯度回传到表达学习模块,以实现表达学习和索引构建的联合训练。
3、联合生成模型和判别模型
判别模型学的是查询和文档相关性的一个判别问题,生成模型需要输入一个文档去生成查询的序列。生成模型通常对模型要求更高因为需要对文档语义有深度的理解。如何结合两种建模方式的优势来提升检索的性能也是一个值得探索的方向。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%99%BE%E5%BA%A6%E6%90%9C%E7%B4%A2%E8%AF%A6%E8%A7%A3%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B%E5%9C%A8%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2%E7%AC%AC%E4%B8%80%E9%98%B6%E6%AE%B5%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


