的查询毛刺问题原因分析
如果业务对查询延迟很敏感,Elasticsearch 查询延迟中的毛刺现象就是比较困扰的一类问题,由于出现毛刺的时间点已经过去,无法稳定复现,对于根因的分析比较困难,无法用系统化调试的思想,从现象出发逐步推理,定位问题,能做的通常就是看一下监控系统对应时间点的指标情况,而在 es 中,导致查询延迟发生波动的因素非常多,今天我们来列举一下可能的因素,并尝试用对应的方法来定位和解决他们。
通常一个系统中会有多种不同的查询同时存在,他们本身正常的查询延迟就可能存较大差异,因此即使系统在理想状态下,查询延迟的曲线也可能存在较大波动,特别是查询条件不固定,某些查询本身就耗时较长。我们只讨论一个特定的查询语句在某个时刻产生了较大延迟,即这个查询语句正常不应该耗时那么久。
另外 es 和 lucene 层面的查询缓存只是一种优化,查询缓存本身并不能保证查询延迟,因此不在本文讨论范畴。
GC 的影响
查询延迟受 GC 的影响是常见因素之一,一个查询被转发的相关分片,任意节点产生一个长时间的 GC 都会导致整个查询耗时变长。
定位方式:
查看对应时间点的节点 GC 指标,参考 kibana 或 gc log
解决方式:
堆内存不足可能的因素比较多,例如配置的 JVM内存较小,open 的索引过多,导致 FST 占用空间过大(未开启 offheap 的情况下),聚合占用了大量内存,netty 层占用大量内存,以及 cache 占用的内存等,主要是根据自己的业务特点,找到内存被谁占用了,然后合理规划JVM 内存空间。可以通过 REST API 或 MAT 分析内存,参考命令:
curl -sXGET "http://localhost:9200/_cat/nodes?h=name,port,segments.memory,segments.index_writer_memory,segments.version_map_memory,segments.fixed_bitset_memory,fielddata.memory_size,query_cache.memory_size,request_cache.memory_size&v"
HBase 通过 offheap 的方式降低 JVM 占用,来避免 FGC,es 将 FST offheap 后也大幅降低了 JVM 占用情况,不过 FST offheap 之后有可能会被系统清理,再次查询 FST 就会发生 io,也会造成查询延迟不稳定,不过这种概率非常小。而在 es 中聚合,scroll等操作都可能导致 JVM 被大幅占用,增加了不确定性。
系统 cache 失效
查询,以及聚合,需要访问磁盘上不同的文件,es 建议为系统 cache 保留一半的物理内存空间,当系统 cache 失效,发生磁盘 io,对查询延迟产生明显的影响。pagecache 什么时候会失效?使用 pagecache 的地方很多,linux 默认会缓存绝大部分的文件读写,例如查询,写日志,入库写 segment 文件,merge 时读写的文件,以及es 所在节点部署的其他的程序、脚本文件执行的对 io 上面的操作等都会抢占 pagecache。linux 按一定策略和阈值来清理 pagecache,应用层无法控制哪些文件不被清理。
因此我们需要了解一个查询语句在 io 上的需求,主要是以下两个问题:
- 查询过程需要实时读取哪些文件?
- 一次查询需要几次 io?读取多少字节?消耗多少时间?
查询过程需要实时读取哪些文件
es 中的查询是一个复杂的过程,不同的查询类型需要访问不同的 lucene 文件,我将常见类型的查询可能访问的文件整理如下:
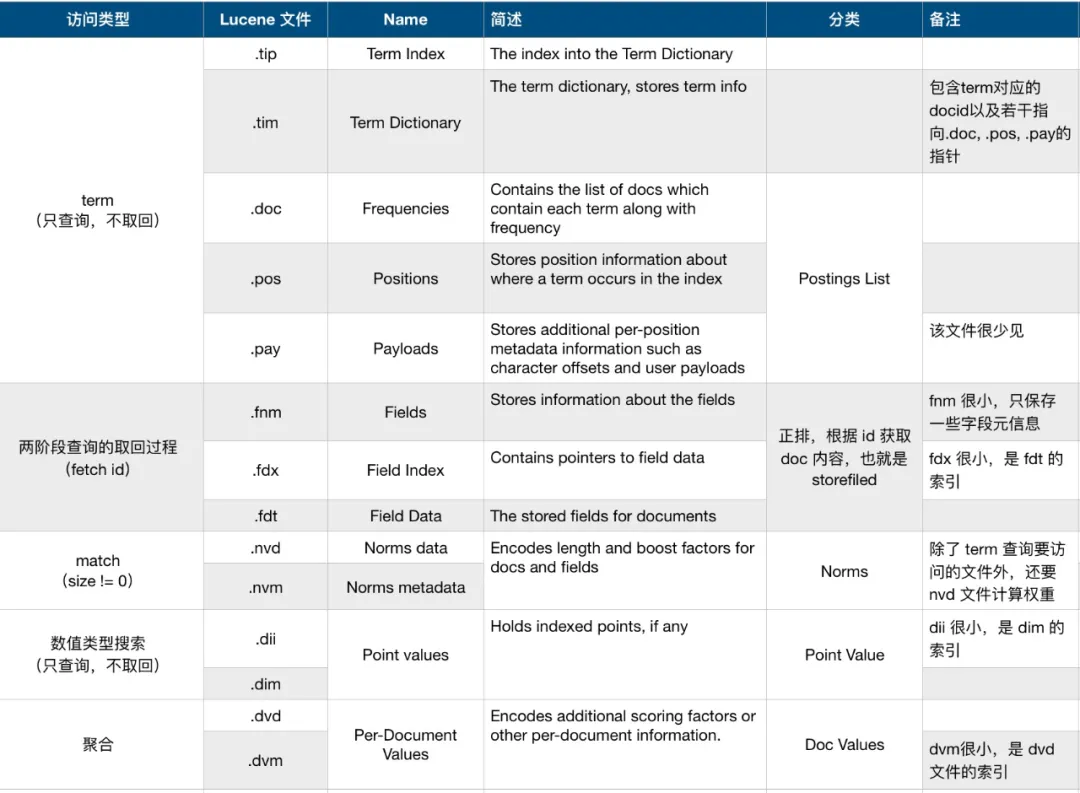
真正查询过程中,并非所有文件都会实时读取,有些文件已经在 open 索引的时候读取完毕常驻内存,有些元信息文件也是在 open 的时候解析一次。为了验证搜索过程实际访问的文件与预期是否一致,我写了一个 systemtap 脚本来 hook 系统调用的 read 及 pread 函数,并把调用情况打印出来,验证过程样本数据使用 geonames 索引,为了便于演示,将索引 forcemerge 为单个分段,并将 store 设置为 niofs。
仅查询,不取回
分布式搜索由两阶段组成,当请求中 size=0时,只执行查询阶段,不需要取回。因此 term 查询或 match 查询,因此查询过程一般只需要用到倒排索引,因此,如下类型的查询:
_search?size=0
{
"query": {
"match": {
"name": {
"query": "Farasi"
}
}
}
}
只需要读取 tim 文件。因为tip 是在内存常驻的,而 size=0的时候只需要返回 hit 数量,es 在实现的时候有一个提前终止的优化,直接从 tim 中取 docFreq 作为 hit,不需要访问 postings list。

但是当查询含有 post_filter ,自定义的terminate_after等情况时,不会走提前终止的优化过程。再者就是类似如下的多个查询条件时,lucene 需要对每个字段的查询结果做交并集,这就需要拿到 postings list才行:
_search?size=0
{
"query": {
"bool": {
"must": { "match": { "name": "Farasi" }},
"must_not": { "match": { "feature_code": "CMP" }}
}
}
}
因此会读取 .doc 文件:

当 size!=0 时,term 查询和 match 查询需要读取的文件不一样,因此下面单独讨论。
term查询,加取回
带上 fetch 阶段后,原来查询过程需要访问的文件不变,fetch 过程需要从 stored fields 中取,因为 _source 字段本身就是存储到 stored fields 中的。
_search?size=1
{
"query": {
"term": {
"country_code.raw": {
"value": "CO"
}
}
}
}
因此,需要相比仅查询的过程,还需要多访问 fdt,fdx文件。

match查询,加取回
match 查询由于需要计算评分,需要使用 Norms 信息,因此在 term 查询加取回的基础上还要多访问 Norms 文件
_search?size=10
{
"query": {
"match": {
"name": {
"query": "Farasi"
}
}
}
}
需要读取 Norms中的 nvd 文件:

数值类型查询
数值类型的字段使用 BKD-tree 建立索引,不会存储到倒排,因此查询过程需要读取 Point Value。取回过程与 term 查询相同。
_search?size=0
{
"query": {
"range": {
"geonameid": {
"gte": 3682501,
"lte": 3682504
}
}
}
}
查询过程只需要读取 dim 文件:

聚合
对于 metric 和 bucket 聚合,需要访问的文件相同,当 size=0时,只需要读取 dvd 文件。
_search?size=0
{
"aggs": {
"name": {
"terms": { "field": "name.raw" }
}
}
}
以下为部分截图,省略了后面的3万多条记录。

GET API
使用 GET API获取单条文档时,与 fetch 过程并不相同
_doc/IrOMznAB5onF36XmwY4W
以下结果想必会出乎意料:

_id 字段是被建立了索引的。这个 _id 是 es 层面概念,并非 lucene 倒排表里的 docid,因此根据 _id 单条 GET 的时候,需要先执行一次 lucene 查询(termsEnum.seekExact)来获取 lucene 中数字类型的 docid,查询过程自然需要查找 FST,读取 tim。
然后根据这个 docid 去 stored field 中读取 _source,因此需要读取 fdx,fdt 文件
最后,GET API 除了返回 _source 之外,还要返回该文档的元信息字段,包括:_version、_seq_no、_primary_term,这三个字段是保存在 docvalue 中的,因此需要读取 dvd 文件。
两阶段的查询过程中,query 阶段返回的 docid 是 lucene 内部数字类型的 id,fetch 的时候可以直接获取了。
查询需要几次 io?
在了解了查询会涉及到动态读取哪些文件之后,我们还需要知道在 io 上需要多大的代价,为了验证实际搜索过程的 io 情况,我们再编写一个新的 systemtap 脚本,将查询过程对每个文件读取的字节数,耗费时间等信息打印出来:
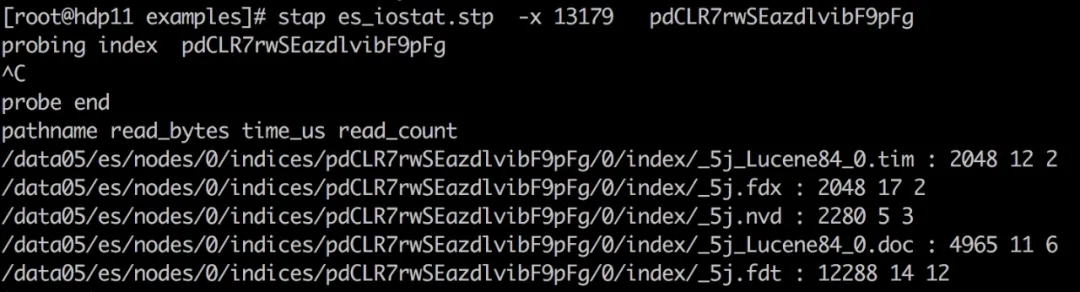
为了观测到查询在 io 上的影响,我们需要排除一些干扰因素:
无 pagecache 的测试:
- 用 vmtouch 驱逐该索引在 pagecache 的缓存
- 执行 _cache/clear 清理 es 层面的缓存
有 pagecache 的测试:
- 执行 _cache/clear 清理 es 层面的缓存
- 使用相同查询执行第2次
此外,系统环境干净,单节点,没有写入操作,没有其他无关进程影响。然后对几种常见类型的查询进行统计,结果如下表:
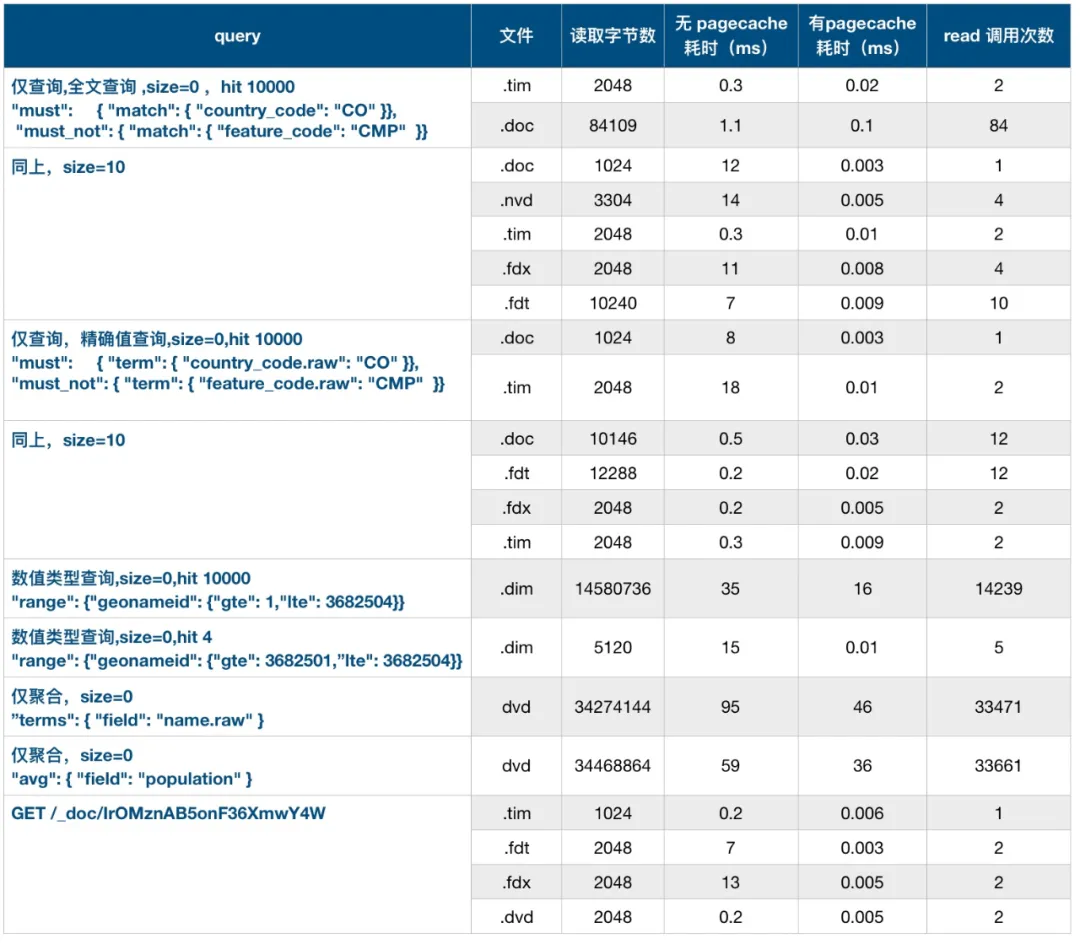
你可能不想看这种明细表,我来总结一下:多数查询所需的 read 调用次数及需要读取的数据量都不大,但是有两种情况需要较多的 io,因为他们都与数据量有关:
- 聚合的时候,所需 io 取决于参与聚合的数据量。
- 数值类型的 range query,所需 io 取决于命中的结果集大小。
业务对于上述两种类型的查询要特别关注。可以考虑设法优化,例如聚合前尽量通过查询条件缩小参与聚合的结果集,以及 range 查询的时候尽量缩小范围。其次还有两种情况需要的 io 相对较多,但比上面的要少一个数量级:
- 多条件查询时,需要对多个字段的结果集做交并,结果集较大时,需要读取doc 文件的次数较多,本例中有几十次。
- 深度翻页,要取决于要取回的数据量。因为单条 GET 那读那么多的文件,代价略大。
结论:在仅查询的场景下,访问 doc 和 dim 文件的次数可能会比较多,通常业务的查询语句都比较复杂,混合多种查询条件,io 量虽然是很大,但是当磁盘比较繁忙,而 page cache又未命中的情况下,查询延迟可能会比较大。
FST offheap 后的影响
FST 的 offheap 通过 mmap tip 文件,让 FST 占用的内存空间从堆内转向 pagecache 来实现,既然在 pagecache 中,当被 pagecache 驱逐后,就会产生 io,产生明显的查询延迟。简单来说就是这种 offheap 的效果有可能导致 FST 不在 heap 了。
虽然 tip 被逐出 pagecache 的几率很小,但是,随着集群规模变大,偶然因素就会变成必现情况。
解决方式:自研一种 offheap也很简单, FST 的查找过程就是在数组里跳来跳去的找,所以比 HBase 的 offheap 简单很多。如果不想改代码,解决方式参考上一条。
如何观测查询在 io 上的延迟
当生产环境查询延迟产生毛刺,我们想要确定这个较高的延迟是否受 io 的影响导致,但是很不幸,目前还很难观测到,即使查询延迟毛刺发生在当下,Profile API 也无法给出在 io 上的耗时(通过 systemtap 脚本中为 pread 过程注入延迟,发现读取 tim 文件的耗时在 Profile结果里体现不出来的,fdt,fdx文件的读取延迟体现在create_weight字段,dim 文件的读取延迟体现在build_scorer字段等,难以界定问题)发现如果想要观测到这些指标,需要在 lucene 层面做出一些改进,然后在 Profile API 和 Slow log 中展示出来,而且还仅限于使用 niofs 的情况下才能拿到指标。
既然搜索需要不可控次数的 io,搜索延迟就注定是无法保障的。例如:
- 索引写入会占用io,虽然不多,但是存在瞬间刷盘的时刻
- 如果有 update,会比 index 操作占用更多 io util
- 如果存在巨大的 shard,查询可能会占用较大 io util
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%9A%84%E6%9F%A5%E8%AF%A2%E6%AF%9B%E5%88%BA%E9%97%AE%E9%A2%98%E5%8E%9F%E5%9B%A0%E5%88%86%E6%9E%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


