端到端特性概览翻译
原文地址: https://my.oschina.net/u/992559/blog/1819948
作者: moyiguke
Apache Flink 端到端(end-to-end)Exactly-Once特性概览
本文是flink博文的翻译,原文链接 https://flink.apache.org/features/2018/03/01/end-to-end-exactly-once-apache-flink.html
2017年12月份发布的Apache Flink 1.4版本,引进了一个重要的特性:TwoPhaseCommitSinkFunction (关联Jira https://issues.apache.org/jira/browse/FLINK-7210) ,它抽取了两阶段提交协议的公共部分,使得构建端到端Excatly-Once的Flink程序变为了可能。这些外部系统包括Kafka0.11及以上的版本,以及一些其他的数据输入(data sources)和数据接收(data sink)。它提供了一个抽象层,需要用户自己手动去实现Exactly-Once语义。
如果仅仅是使用,可以查看这个文档 https://ci.apache.org/projects/flink/flink-docs-release-1.4/api/java/org/apache/flink/streaming/api/functions/sink/TwoPhaseCommitSinkFunction.html。
如果想要了解更多,这篇文章我们会深入了解这个特性,以及Flink背后做的工作。
纵览全篇,有以下几点:
- 描述Flink checkpoints的作用,以及它是如何保障Flink程序Exactly-Once的语义的。
- 展现Flink如何与两阶段提交协议与输入输出(data sources and data sinks)交互,借此传递端到端的Exactly-Once语义保证。
- 通过一个简单的例子来展现如何使用TwoPhaseCommitSinkFunction,来实现Exactly-Once的文件输出(file sink)。
Apache Flink程序的Exactly-Once语义
当我们在讨论Exactly-Once语义的时候,我们指的是每一个到来的事件仅会影响最终结果一次。就算机器宕机或者软件崩溃,即没有数据重复,也没有数据丢失。
Flink很久之前就提供了Exactly-Once语义。在过去的几年时间里,我们 对Flink的checkpoint做了深入的描述 ,这个是Flink能够提供Exactly-Once语义的核心。 Flink文档也对这个特性做了深入的介绍 。
在我们继续之前,有一个关于checkpoint算法的简要介绍,这对于了解更广的主题来说是十分必要的。
一个checkpoint是Flink的一致性快照,它包括:
- 程序当前的状态
- 输入流的位置
Flink通过一个可配置的时间,周期性的生成checkpoint,将它写入到存储中,例如S3或者HDFS。写入到存储的过程是异步的,意味着Flink程序在checkpoint运行的同时还可以处理数据。
在机器或者程序遇到错误重启的时候,Flink程序会使用最新的checkpoint进行恢复。Flink会恢复程序的状态,将输入流回滚到checkpoint保存的位置,然后重新开始运行。这意味着Flink可以像没有发生错误一样计算结果。
在Flink 1.4.0版本之前,Flink仅保证Flink程序内部的Exactly-Once语义,没有扩展到在Flink数据处理完成后存储的外部系统。
Flink程序可以和不同的接收器(sink)交互,开发者需要有能力在一个组件的上下文中维持Exactly-Once语义。
为了提供端到端Exactly-Once语义,除了Flink应用程序本身的状态,Flink写入的外部存储也需要满足这个语义。也就是说,这些外部系统必须提供提交或者回滚的方法,然后通过Flink的checkpoint来协调。
在分布式系统中,协调提交和回滚的通用做法是 两阶段提交。接下来,我们讨论Flink的TwoPhaseCommitSinkFunction如何使用两阶段提交协议来保证端到端的Exactly-Once语义。
Flink程序端到端的Exactly-Once语义
我们简略的看一下两阶段提交协议,以及它如何在一个读写Kafka的Flink实例程序中提供端到端的Exactly-Once语义。Kafka是一个流行的消息中间件,经常被拿来和Flink一起使用,Kafka 在最近的0.11版本中添加了对事务的支持。这意味着 现在Flink读写Kafka有了必要的支持,使之能提供端到端的Exactly-Once语义。
Flink对端到端的Exactly-Once语义不仅仅局限在Kafka,你可以使用任一输入输出源(source、sink),只要他们提供了必要的协调机制。例如 Pravega ,来自DELL/EMC的流数据存储系统,通过Flink的TwoPhaseCommitSinkFunction也能支持端到端的Exactly-Once语义。
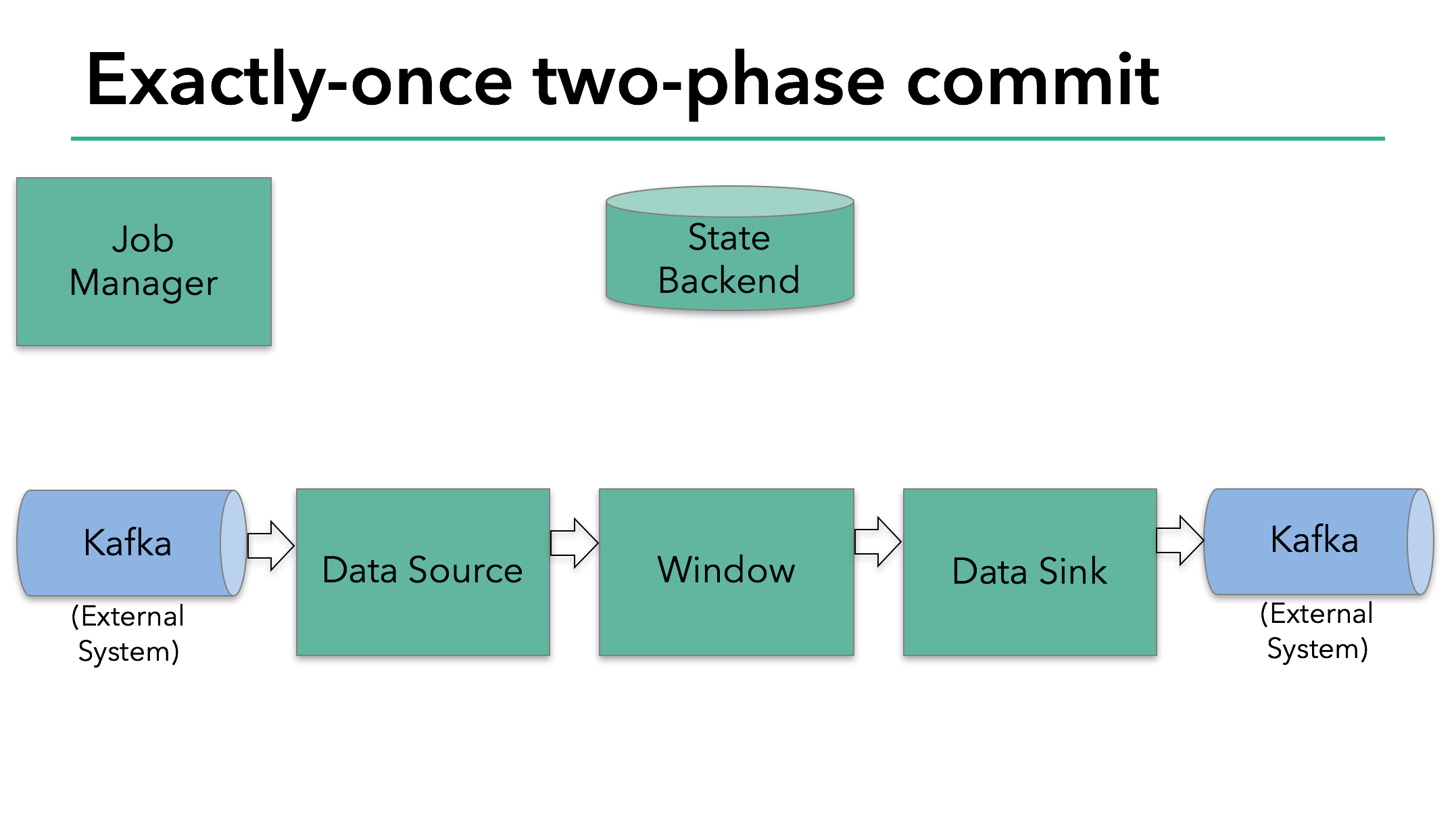
在这个示例程序中,我们有:
- 从Kafka读取数据的data source(KafkaConsumer,在Flink中)
- 窗口聚合
- 将数据写回到Kafka的data sink(KafkaProducer,在Flink中)
在data sink中要保证Exactly-Once语义,它必须将所有的写入数据通过一个事务提交到Kafka。在两个checkpoint之间,一个提交绑定了所有要写入的数据。
这保证了当出错的时候,写入的数据可以被回滚。
然而在分布式系统中,通常拥有多个并行执行的写入任务,简单的提交和回滚是效率低下的。为了保证一致性,所有的组件必须先达成一致,才能进行提交或者回滚。Flink使用了两阶段提交协议以及预提交阶段来解决这个问题。
在checkpoint开始的时候,即两阶段提交中的预提交阶段。首先,Flink的JobManager在数据流中注入一个checkpoint屏障(它将数据流中的记录分割开,一些进入到当前的checkpoint,另一些进入下一个checkpoint)。
屏障通过operator传递。对于每一个operator,它将触发operator的状态快照写入到state backend。
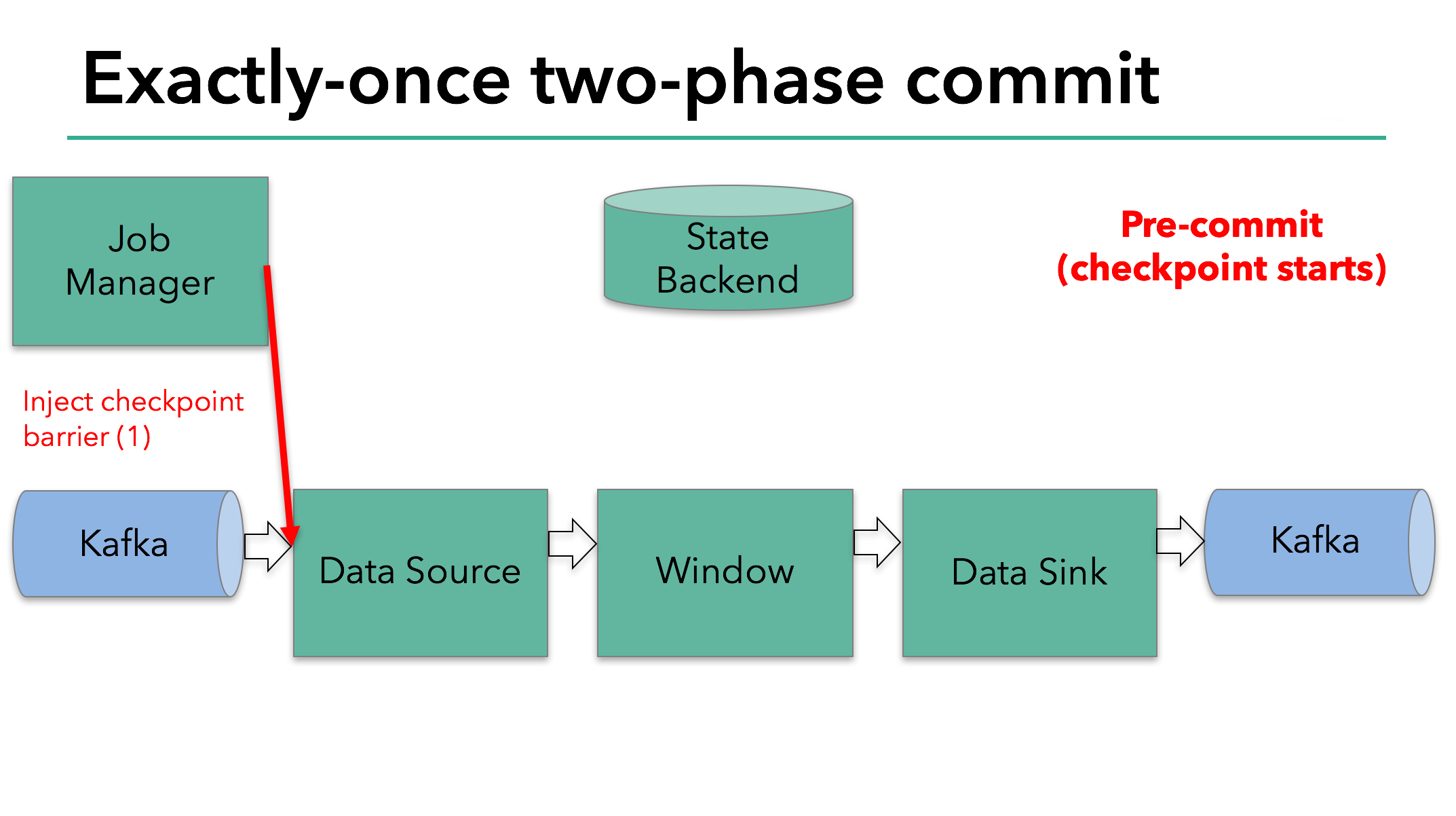
data source保存了Kafka的offset,之后把checkpoint屏障传递到后续的operator。
这种方式仅适用于operator有他的内部状态。内部状态是指,Flink state backends保存和管理的内容-举例来说,第二个operator中window聚合算出来的sum。当一个进程有它的内部状态的时候,除了在checkpoint之前将需要将数据更改写入到state backend,不需要在预提交阶段做其他的动作。在checkpoint成功的时候,Flink会正确的提交这些写入,在checkpoint失败的时候会终止提交。
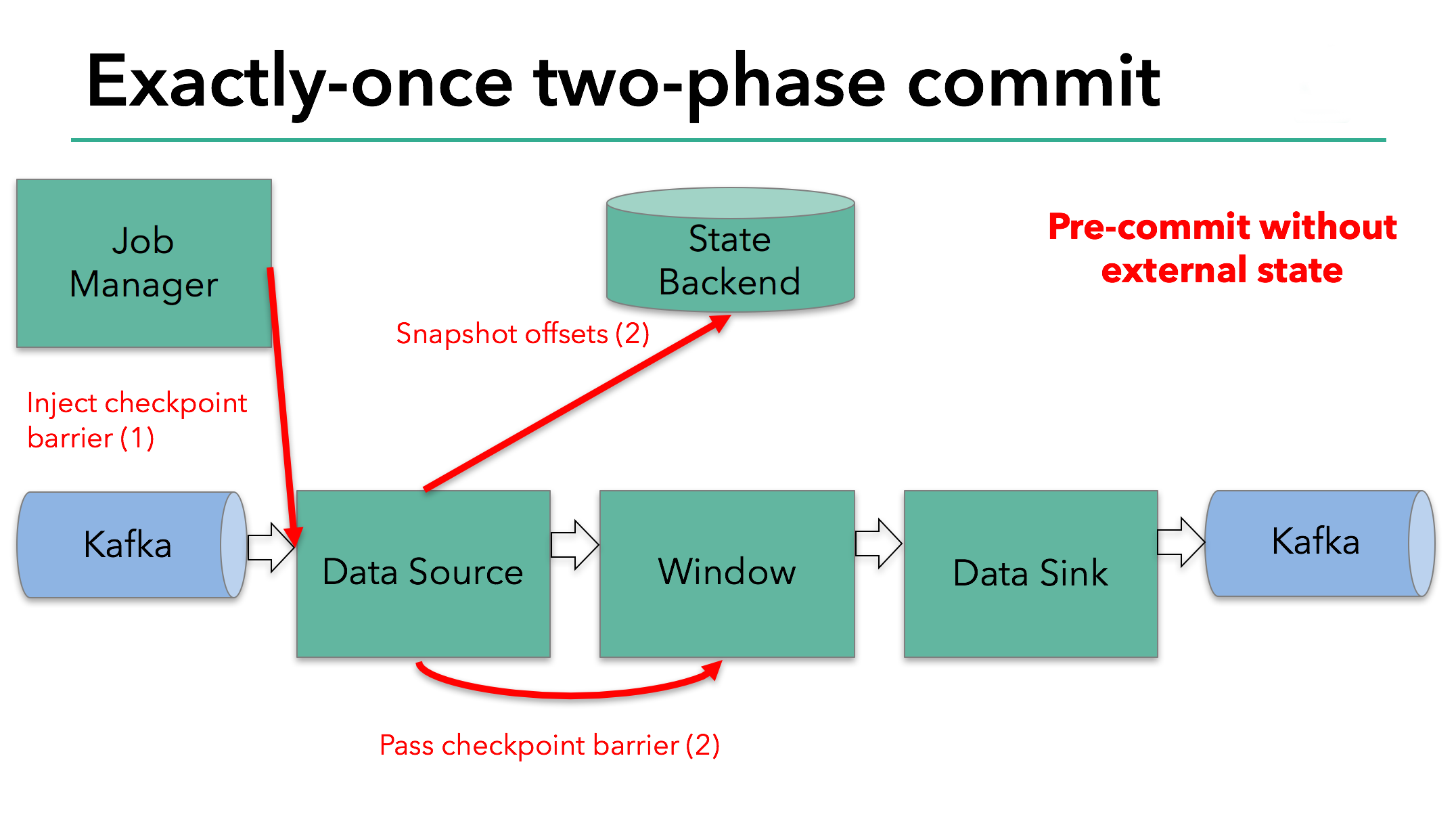
然而,当一个进程有外部状态的时候,需要用一种不同的方式来处理。外部状态通常由需要写入的外部系统引入,例如Kafka。因此,为了提供Exactly-Once保证,外部系统必须提供事务支持,借此和两阶段提交协议交互。
我们知道在我们的例子中,由于需要将数据写到Kafka,data sink有外部的状态。因此,在预提交阶段,除了将状态写入到state backend之外,data sink必须预提交自己的外部事务。
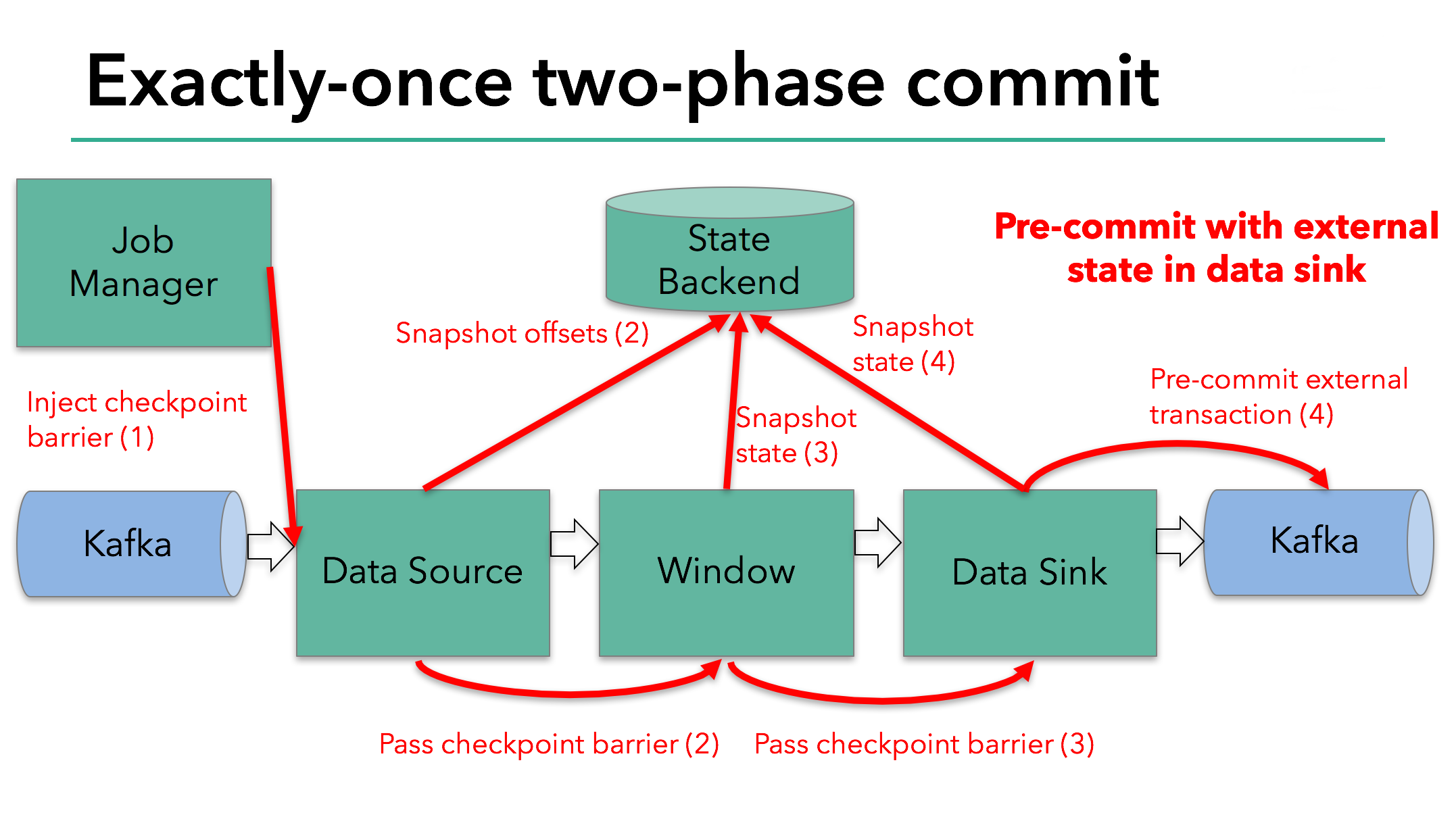
当checkpoint屏障在所有operator中都传递了一遍,以及它触发的快照写入完成,预提交阶段结束。这个时候,快照成功结束,整个程序的状态,包括预提交的外部状态是一致的。万一出错的时候,我们可以通过checkpoint重新初始化。
下一步是通知所有operator,checkpoint已经成功了。这时两阶段提交中的提交阶段,Jobmanager为程序中的每一个operator发起checkpoint已经完成的回调。data source和window operator没有外部的状态,在提交阶段中,这些operator不会执行任何动作。data sink拥有外部状态,所以通过事务提交外部写入。
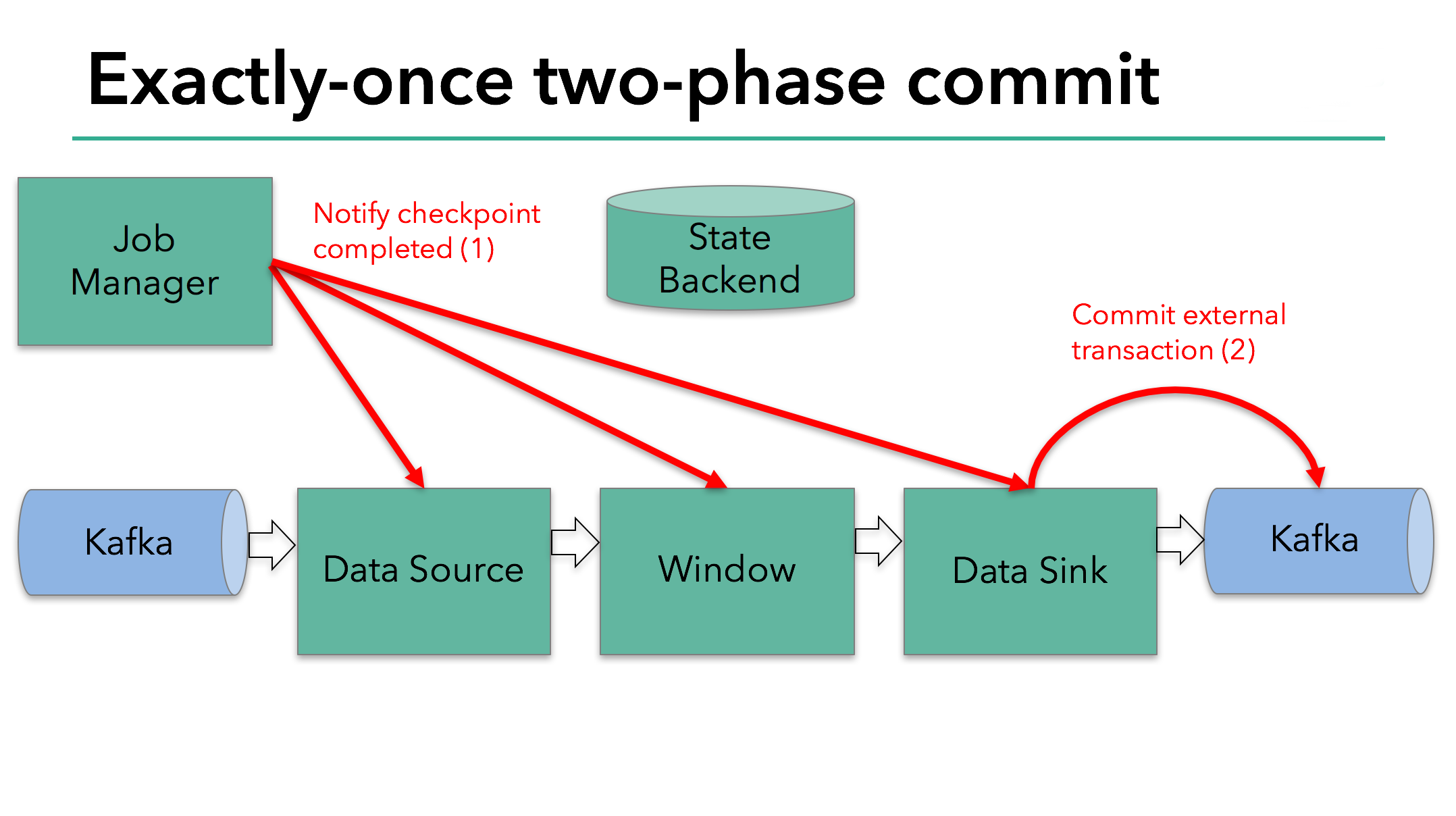
让我们对上述的知识点汇总一下:
- 一旦所有的operator完成预提交,就提交一个commit。
- 如果至少有一个预提交失败,其他的都会失败,这时回滚到上一个checkpoint保存的位置。
- 预提交成功后,提交的commit也需要保障最终成功-operator和外部系统需要提供这个保障。如果commit失败了(比如网络中断引起的故障),整个flink程序也因此失败,它会根据用户的重启策略重启,可能还会有一个尝试性的提交。这个过程非常严苛,因为如果提交没有最终生效,会导致数据丢失。
因此,我们可以确定所有的operator同意checkpoint的最终结果:要么都同意提交数据,要么提交被终止然后回滚。
在Flink程序中实现两阶段提交
完整的实现两阶段提交协议可能会有一点复杂,因此Flink将通用逻辑提取到一个abstract的类TwoPhaseCommitSinkFunction。
让我们通过一个简单的文件操作例子来说明如何使用TwoPhaseCommitSinkFunction。我们只需要实现四个method,并使sink呈现Exactly-Once语义。
- beginTransaction - 在事务开始前,我们在目标文件系统上面的临时目录上创建一个临时文件。随后,我们在程序处理的时候可以将数据写入到这个文件。
- preCommit - 在预提交阶段,我们刷新文件到磁盘,关闭文件,不要重新打开写入。我们也会为下一个checkpoint的文件写入开启一个新的事务。
- commit - 在提交阶段,我们原子性的将预提交阶段的文件移动到真正的目标目录。需要注意的是,这增加了输出数据的可见性的延迟。
- abort - 在终止阶段,我们删除临时文件。
我们知道,如果步骤中有任何错误,Flink会通过最新的checkpoint来恢复程序状态。在一个罕见的场景中,预提交成功了,在通知到达operator之前失败了。这时候,Flink将operator的状态恢复到预提交阶段,即还未真正提交的时候。
为了能在重启的时候能够正确的终止或者提交事务,我们需要在预提交阶段将足够的信息保存到checkpoint中。在这个例子中,这些信息是临时文件以及目标目录的地址。
TwoPhaseCommitSinkFunction 已经把这个场景考虑进去了,在从checkpoint恢复的时候,它会优先提交一个commit。我们的任务是将commit实现成一个幂等的操作。一般的,这不是难题。在这个例子中,我们可以发现这种情况:临时文件不在临时目录中,但是已经移动到目标目录了。
在TwoPhaseCommitSinkFunction中,有一些其他的边界条件也考虑在内了。通过 Flink文档 查看更多。
总结
如果你看到了这么后面,很感谢你通读这个详细的帖子。以下是我们主要覆盖的关键点:
- Flink的checkpoint系统是它支撑两阶段协议和保障Exactly-Once语义的基础设施,
- 这种实现方案的优点是,Flink不像其他系统那样,通过网络传输存储数据 - 它不需要像大部分批处理程序那样,将每一个计算结果保存到磁盘。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%AB%AF%E5%88%B0%E7%AB%AF%E7%89%B9%E6%80%A7%E6%A6%82%E8%A7%88%E7%BF%BB%E8%AF%91/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


