算法工程师之路搜索召回策略篇

作者: 洪九
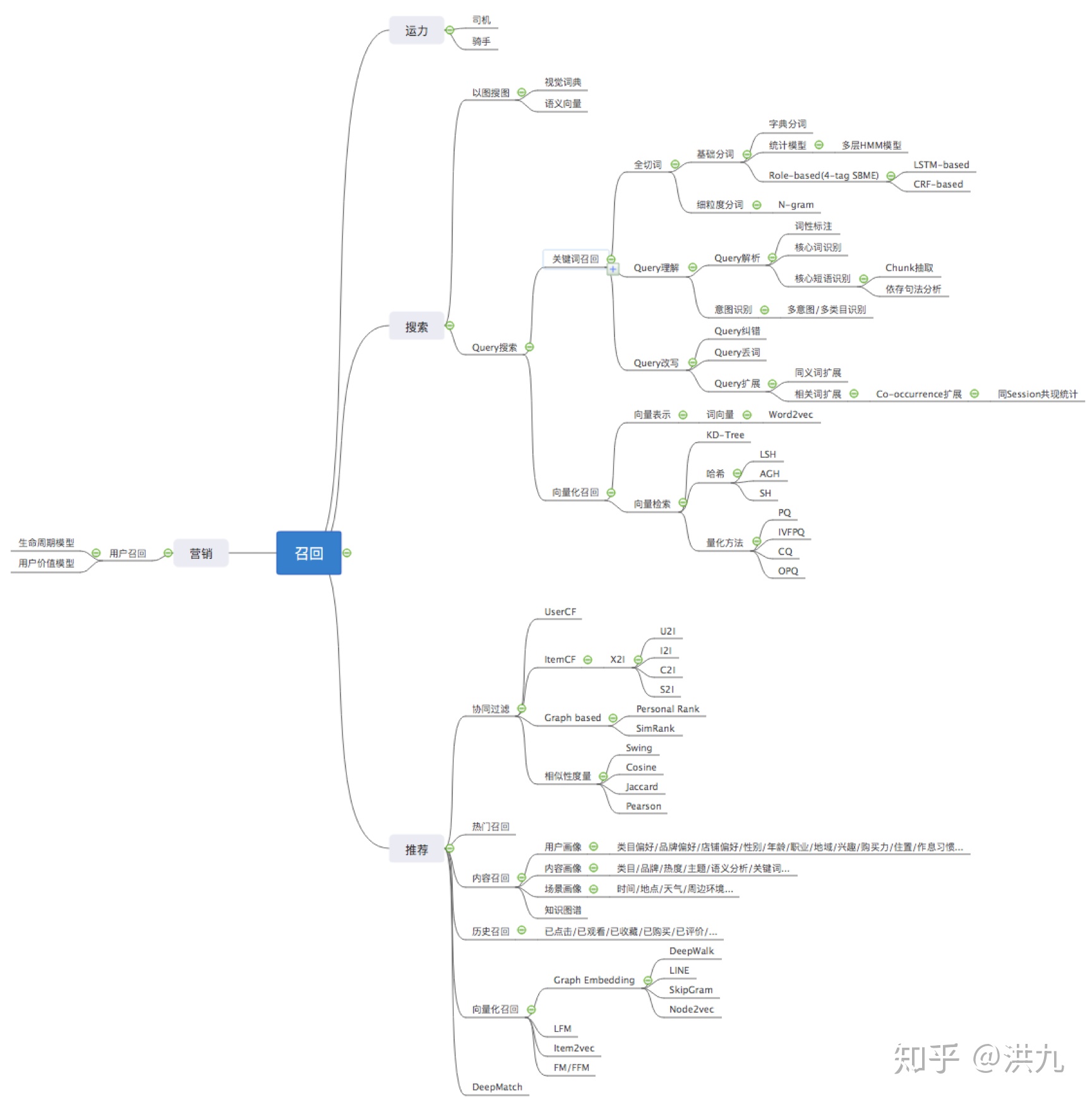
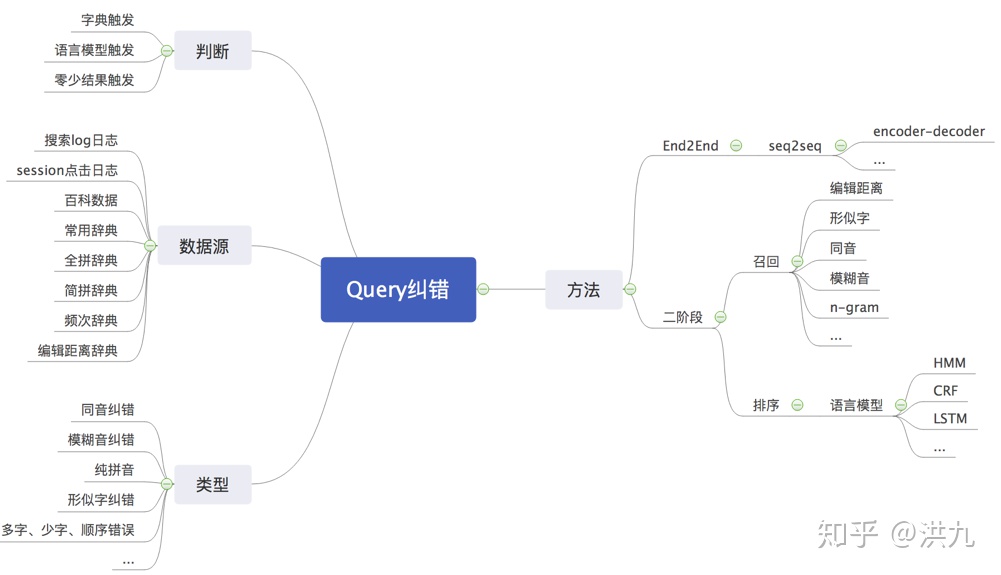
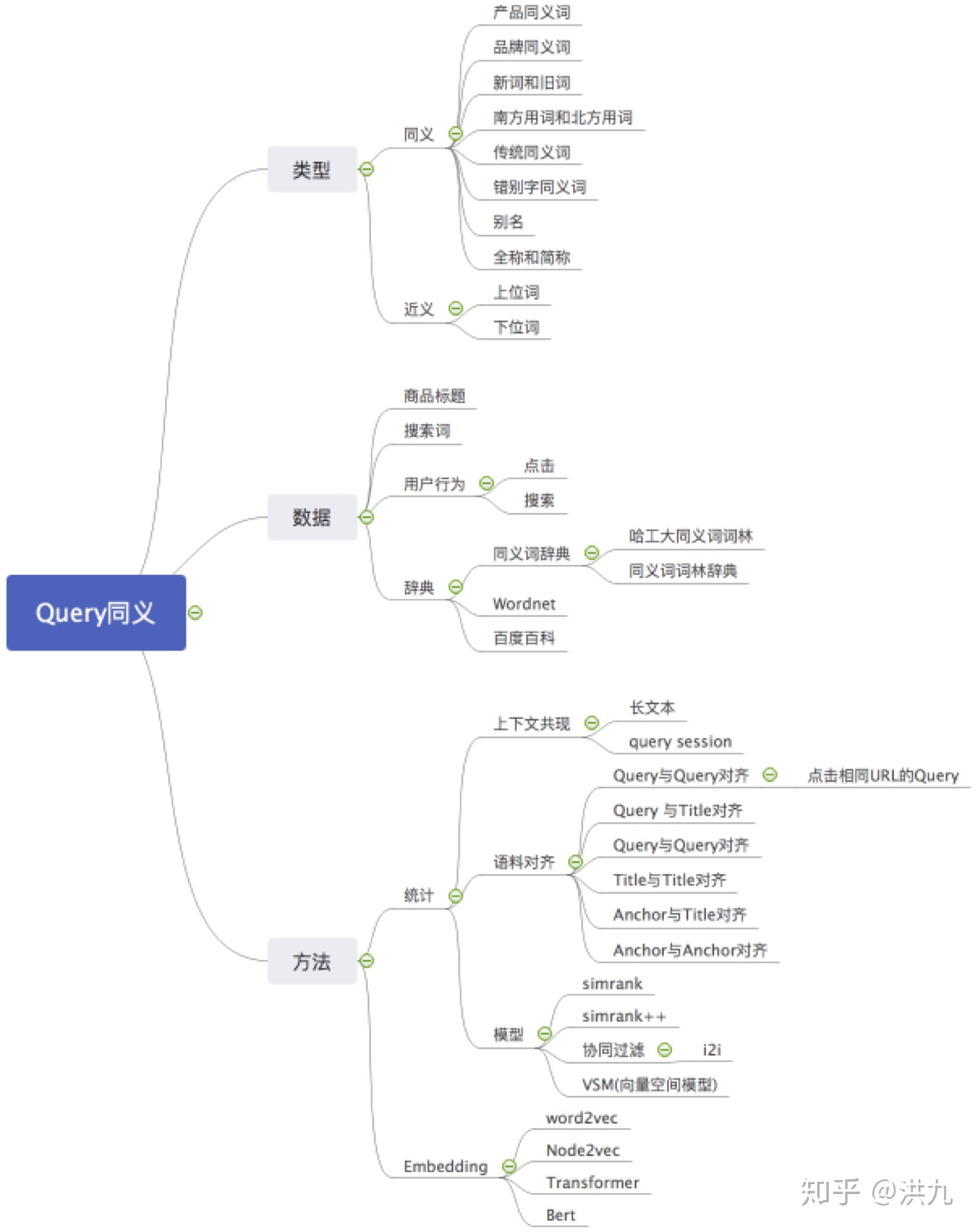
1.召回策略
召回阶段通常是推荐、搜索、广告和O2O分单中的第一步,其输出作为后续阶段的输入。最终展示给用户的数据是这个集合的子集。召回太多,导致后续的精细化排序过程计算压力大,用户被“读懂”的幸福感降低;召回太少,用户看到的内容太少,不利于用户和平台发生转化。 所以召回阶段对系统的性能至关重要。
关于召回暂时想到这么多,后续补充.
2. 搜索召回
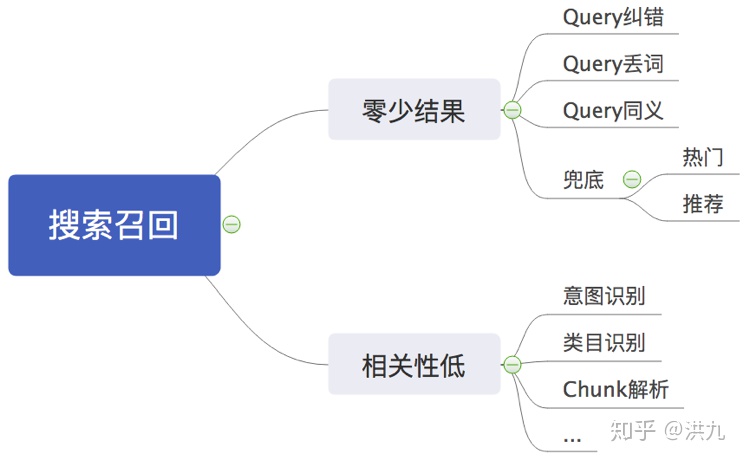
 搜索的使命是“ 找你所需”,在用户已经通过 Query 明确表达 搜索意图 的情况下,只需要对Query切词然后从倒排表中召回相关文档即可。但是用户很多时候并不能通过Query准确表达自己的真实需求,或者由于语言本身的复杂性, 导致用户输入的Query无法与引擎匹配。种种以上原因导致“ 相关性低”或“ 零少结果”。所以 搜索召回与推荐召回不同的是很大一部分工作集中在对Query的分析上。
搜索的使命是“ 找你所需”,在用户已经通过 Query 明确表达 搜索意图 的情况下,只需要对Query切词然后从倒排表中召回相关文档即可。但是用户很多时候并不能通过Query准确表达自己的真实需求,或者由于语言本身的复杂性, 导致用户输入的Query无法与引擎匹配。种种以上原因导致“ 相关性低”或“ 零少结果”。所以 搜索召回与推荐召回不同的是很大一部分工作集中在对Query的分析上。
2.1 Query多粒度切词
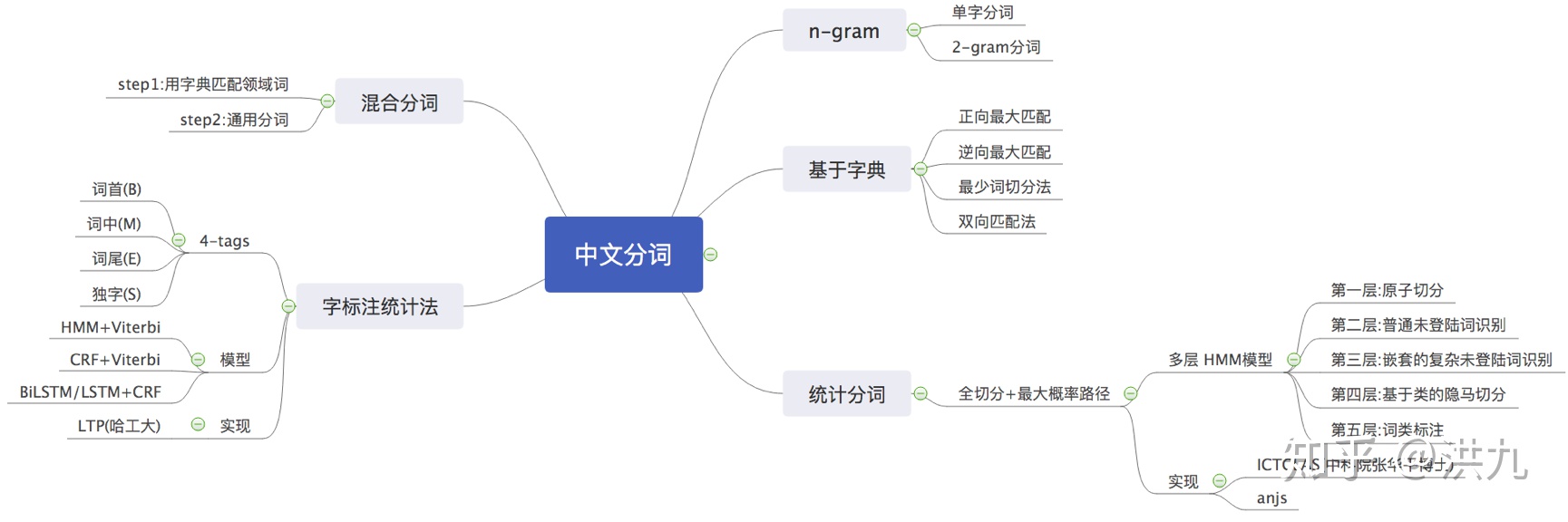
不同的分词算法,在准确率、歧义词、未登录词识别等方面性能有较大差别。 “小孩才做选择大人全都要”,为了不漏掉丝毫理解用户的机会,可以采取多种不同粒度的分词算法结果组合的策略。
比如:
Query:结婚的和尚未结婚的
分词一: 结婚/的/和尚/未/结婚/的
分词二: 结婚/的/和/尚未/结婚/的
分词三: 结婚/婚的/的和/和尚/尚未/未结/结婚/婚的
可以把多种分词结果组合去重丢给引擎,也可以看成是一种 Model Ensemble 方法。
参考资料:
1.基于层叠隐马模型的汉语词法分析
基于层叠隐马模型的汉语词法分析(_办法www.docin.com 2. bi-LSTM + CRF 序列标注
https://ansvver.github.io/lstm_crf_ner.htmlansvver.github.io
2.2 Query纠错
在百度中搜索“ 肯得鸡”。
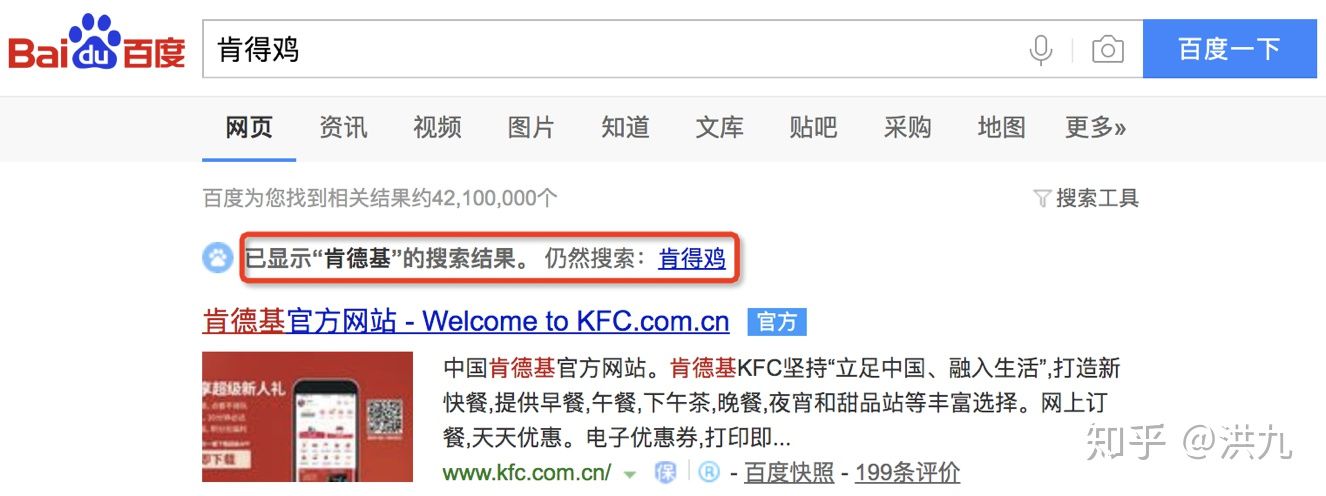 可以看到百度已经帮我们把错误纠正了,避免了“零少结果”,提高了用户体验。
可以看到百度已经帮我们把错误纠正了,避免了“零少结果”,提高了用户体验。
参考资料:
1.搜索引擎的Query自动纠错技术和架构详解
https://blog.csdn.net/catherine_985/article/details/78789089
2.3 Query丢词
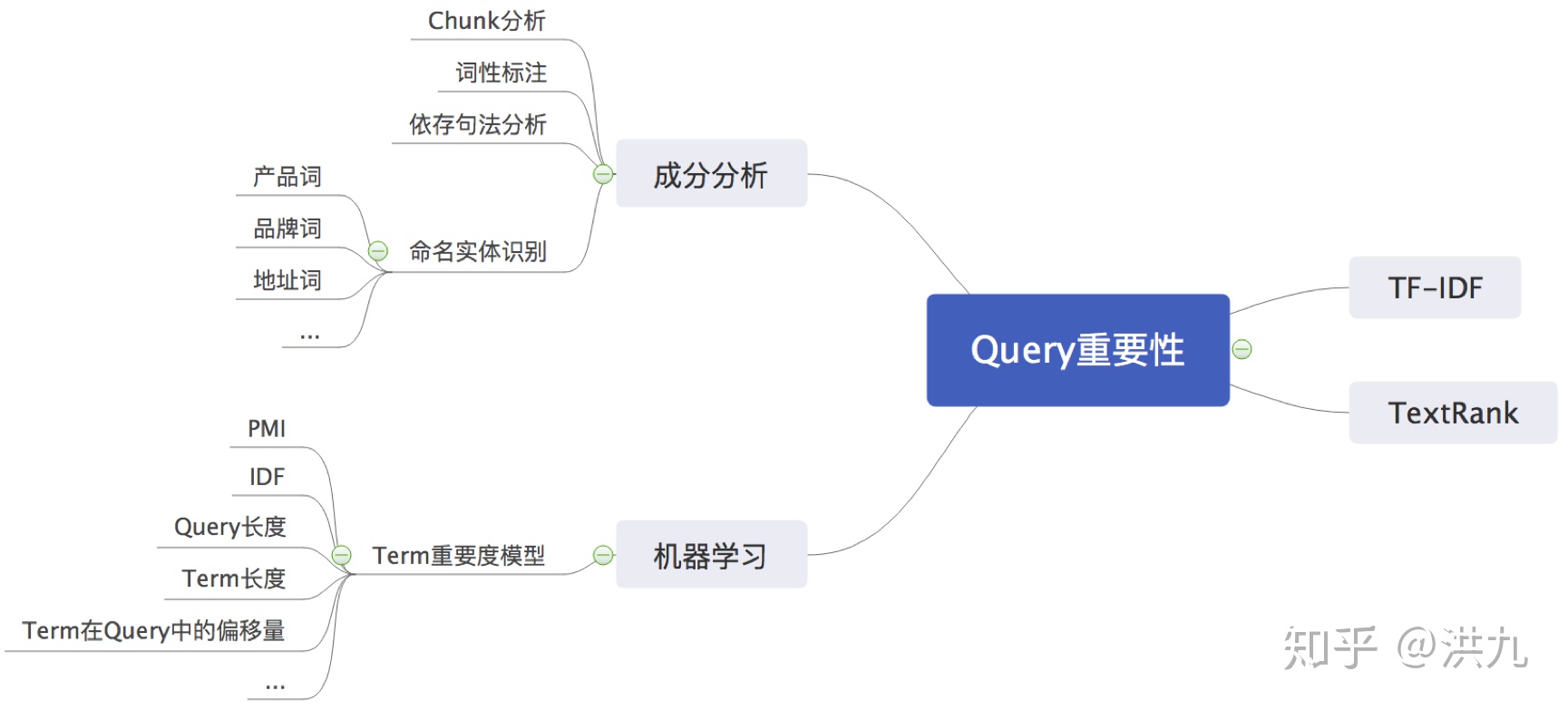
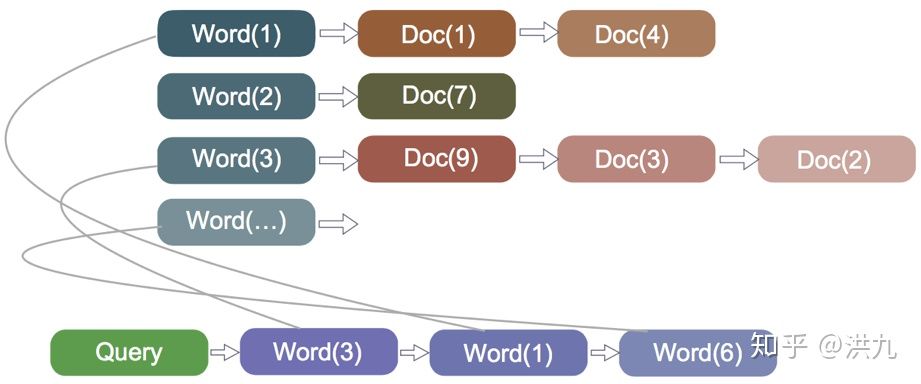
丢词相当于把 用户较长尾的搜索需求“泛化”。比如用户搜索“ 上好佳饼干”,但发现引擎中目前没有相关商品记录。对Query做简单的分析:
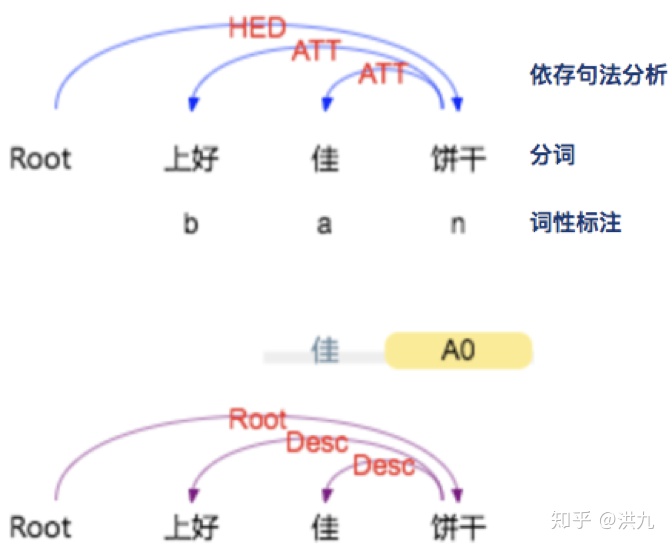
以上结果在 http://ltp.ai/demo.html 计算
根据 依存句法分析 结果, 核心词汇 为“ 饼干”,“ 上好 佳为修饰词”。同时根据“自定义”规则, “名词”(这里为“饼干”)的重要程度高一些。因此可以丢掉修饰词,只根据“饼干”召回相关的item。所以, Query丢词策略需要识别Query中哪些是重要词汇, 最大努力的保留Query的原始语义。
2.4 Query同义
比如用户搜索“番茄”,引擎如果可以“ 番茄 西红柿”一起搜索, 零少结果 的可能性就会小很多。
参考资料:
1.搜索引擎中同义词的挖掘及使用 http://www.mamicode.com/info-detail-2486542.html
- Random walks on the random graph https://arxiv.org/abs/1504.01999
- 基于MapReduce的SimRank++算法研究与实 https://blog.csdn.net/yangxudong/article/details/24788137
- Querying Word Embeddings for Similarity and Relatedness http://aclweb.org/anthology/N18-1062
- Learning Query and Document Relevance from a Web-scale Click Graph https://www.researchgate.net/publication/305081382_Learning_Query_and_Document_Relevance_from_a_Web-scale_Click_Graph
- 基于点击图模型Query和Document相关性的计算
https://blog.csdn.net/qq_27717921/article/details/80549350
- 面向检索信息的同义词挖掘(后续补充到图中)
2.5 Query向量化
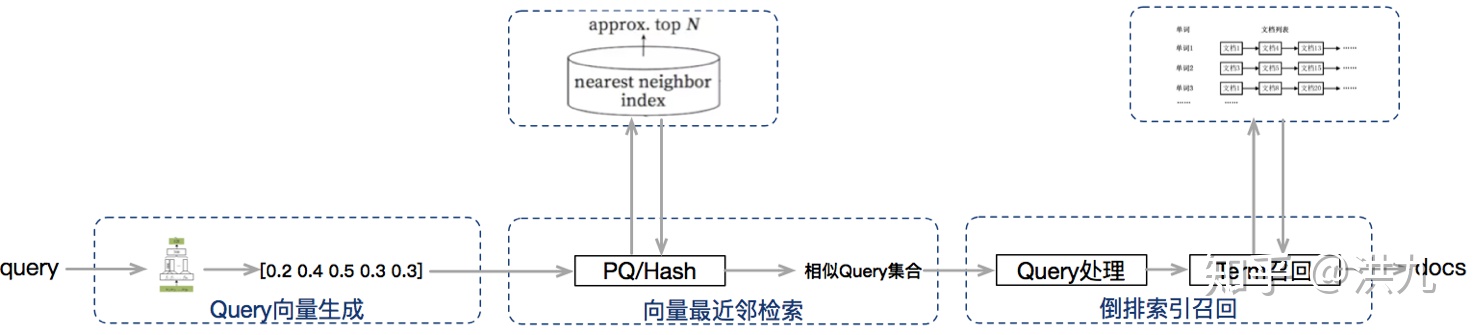
相比于传统的基于关键词的 精准检索 方式, 向量化召回 直接从 全库向量集合 中依据 向量相似度定义 检索最相近的候选集合。得益于向量表示较好的 泛化能力 和 语义表达能力,可以作为传统方法的 补充。对检索结果的多样性
2.5.1 Query向量生成
用户输入的Query具有很大的 自由度,无法 离线预先生成向量。目前可参考的Query向量生成模型有很多,简单介绍下了解的几种。
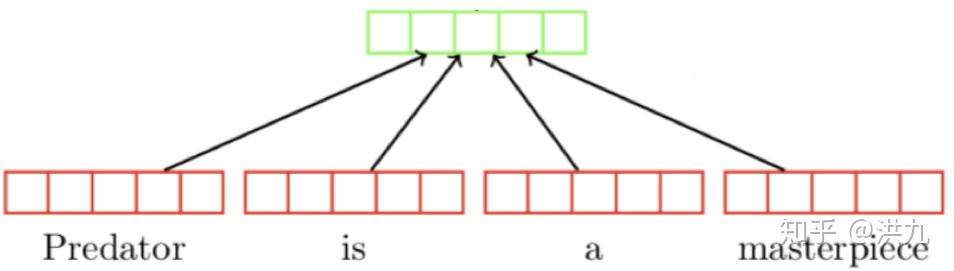
1).Simple BOW方法
将Query每个Word的Embedding向量简单平均。
2). NN Method
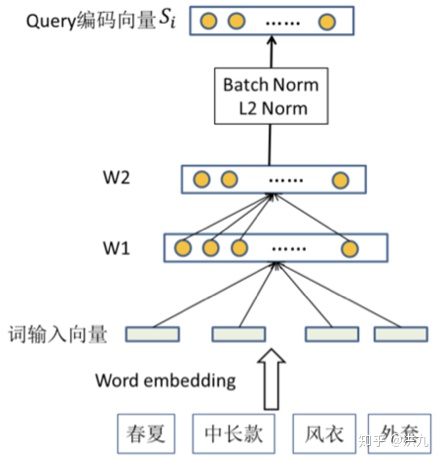
就是将离线生成的Word Embedding向量经过一个NN网络,有点类似于 NLP领域 目前比较时髦的 Transformer。
3). Deep Average Network Method
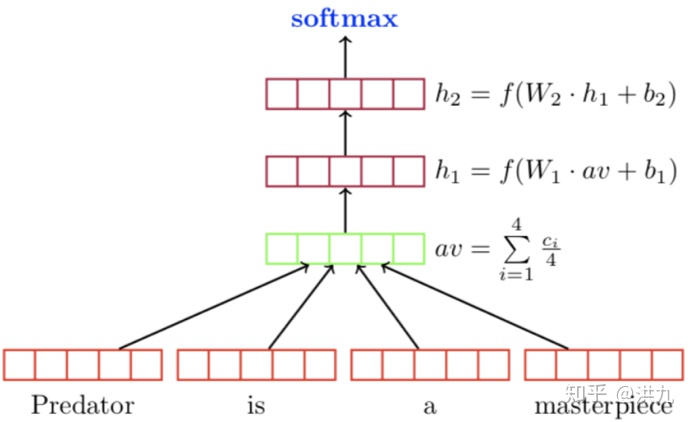
4).Bi-LSTM + Self-attention
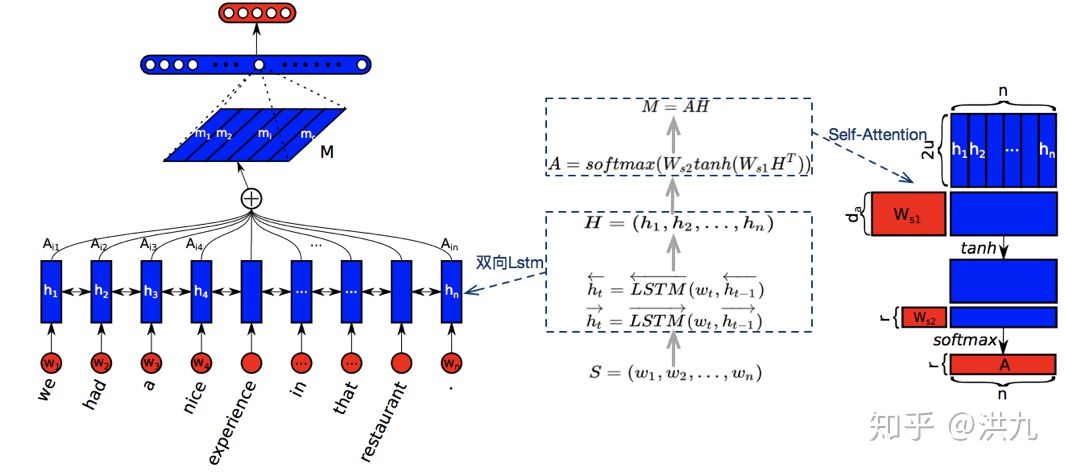 参考文档:
参考文档:
- A STRUCTURED SELF-ATTENTIVE SENTENCE EMBEDDING
https://arxiv.org/pdf/1703.03130.pdf
2.论文笔记:A Structured Self-Attentive Sentence Embedding
https://www.cnblogs.com/wangxiaocvpr/p/9501442.html
- A Self-Attention Setentence Embedding 阅读笔记
https://blog.csdn.net/weixin_41362649/article/details/88806420
4.《A Self-Attention Setentence Embedding》阅读笔记及实践
https://blog.csdn.net/john_xyz/article/details/80650677
2.5.2 向量化检索的基础设施
实践中向量化检索主要有以下几种方式:
1).hash函数族空间划分法
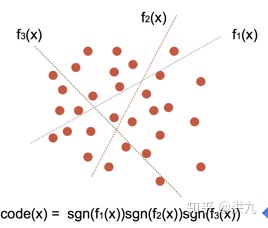
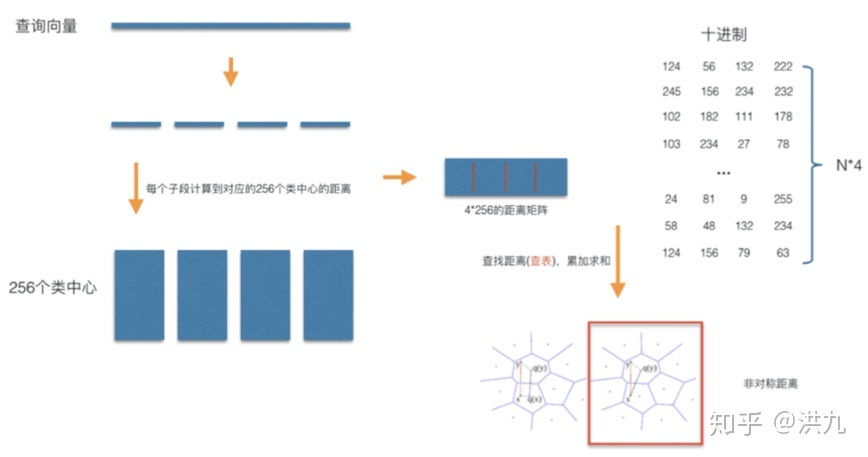
2).PQ积量化方法
索引过程:
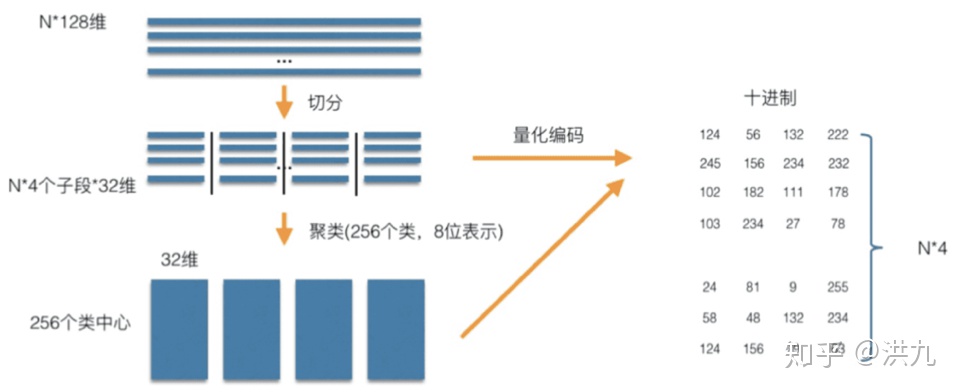
检索过程:
在工程落地方面,向量化检索在阿里、滴滴等厂都有应用。其中阿里在 将开源的Faiss单机引擎改造成分布式版本,支持 全库候选集的召回。同时阿里与浙大合作研发了 基于图的向量化检索引擎(NSG算法),也已经在线上大规模应用。
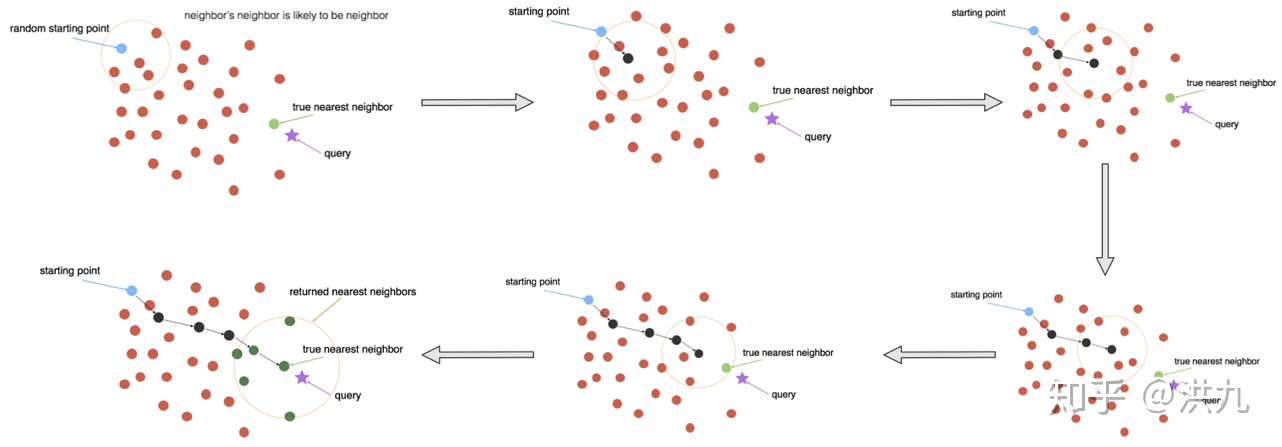
详情参考Paper:Fast Approximate Nearest Neighbor Search With The Navigating Spreading-out Graph
Fast Approximate Nearest Neighbor Search With The Navigating Spreading-out Grapharxiv.org
可喜可贺的是京东开源了分布式的 向量化检索引擎Vearch,同样也是基于开源Faiss库。降低了需要向量化检索的探索成本。
Vearch 系统介绍 - zh_docs 0.1 文档vearch.readthedocs.io
2.6 Query意图识别
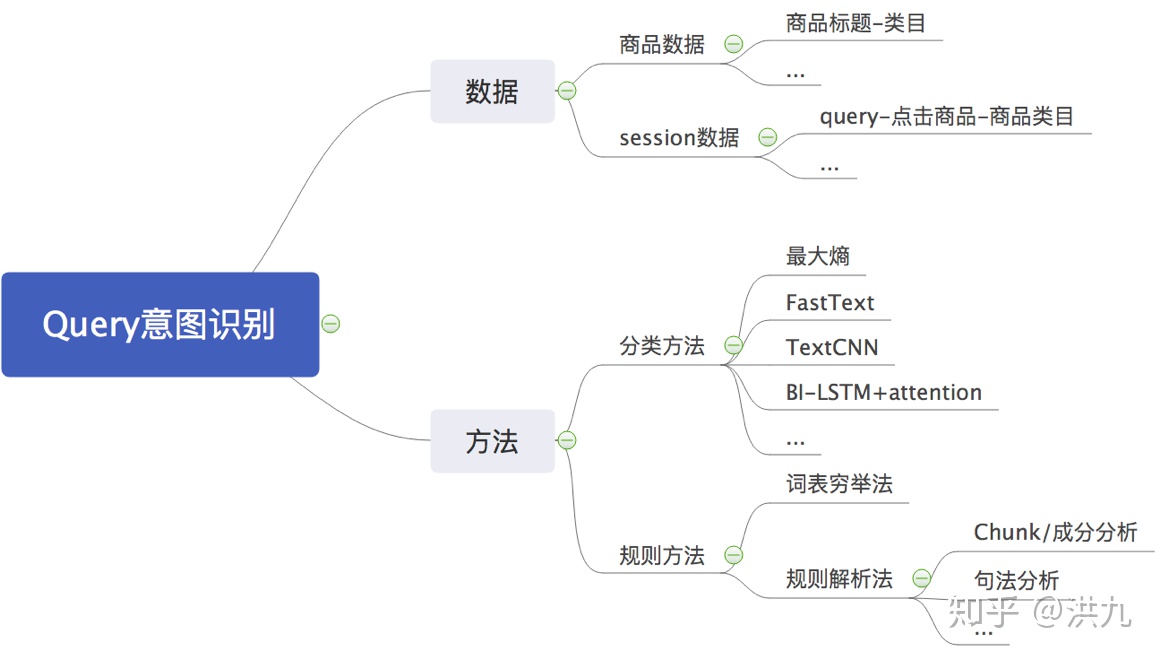
用户输入关键词“Apple”,有可能是想搜索一种 水果,也有可能是想搜索 电子产品。如果引擎可以 准确“猜”到用户的意图,就可以将最相关的Item呈现给用户。所以, 引擎对用户意图理解的正确与否对提高搜索的相关性至关重要。
再举一个例子(从网上找的):
多意图
如:仙剑奇侠传
游戏?–> 游戏软件?……
电视剧?–> 电视剧下载?相关新闻?……
电影?–> 电影下载?查看影评?剧情介绍?……
音乐?–> 歌曲下载?在线听歌?歌词下载?……
小说?–> 小说下载?在线观看?……
意图强度
如:荷塘月色
荷塘月色歌曲 –> 歌曲下载:50%
荷塘月色小区 –> 房产需求:20%
荷塘月色菜 –> 菜谱需求:10%
参考资料:
- 搜索引擎算法之关键词类目预测 https://blog.csdn.net/poson/article/details/89672802
- Using Search-Logs to Improve Query Tagging https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/38276.pdf
- 搜索引擎的查询意图识别(query理解) https://blog.csdn.net/bgfuufb/article/details/83957003
- 搜索意图识别浅析
https://blog.csdn.net/w97531/article/details/83892403
- 计算广
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%AE%97%E6%B3%95%E5%B7%A5%E7%A8%8B%E5%B8%88%E4%B9%8B%E8%B7%AF%E6%90%9C%E7%B4%A2%E5%8F%AC%E5%9B%9E%E7%AD%96%E7%95%A5%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


