级大规模集群运维与调优实践
作者:bellen,腾讯云大数据研发工程师。
腾讯云 Elasticsearch 被广泛应用于日志实时分析、结构化数据分析、全文检索等场景中,本文将以情景植入的方式,向大家介绍与腾讯云客户合作过程中遇到的各种典型问题,以及相应的解决思路与方法,希望与大家一同交流。
背景
某中型互联网公司的游戏业务,使用了腾讯云的 Elasticsearch 产品,采用 ELK 架构存储业务日志。
因为游戏业务本身的日志数据量非常大(写入峰值在 100w qps),在服务客户的几个月中,踩了不少坑,经过数次优化与调整,把客户的 ES 集群调整得比较稳定,避免了在业务高峰时客户集群的读写异常,并且降低了客户的资金成本和使用成本。
场景 1:与客户的初次交锋
解决方案架构师 A: bellen, XX 要上线一款新游戏,日志存储决定用 ELK 架构,他们决定在 XX 云和我们之间二选一,我们首先去他们公司和他们交流一下,争取拿下!
bellen: 好,随时有空!
和架构师一起前往该公司,跟负责底层组件的运维部门的负责人进行沟通。
XX 公司运维老大:不要讲你们的 PPT 了,先告诉我你们能给我们带来什么!
bellen:呃,我们有很多优势,比如可以灵活扩缩容集群,还可以一键平滑升级集群版本,并且提供有跨机房容灾的集群从而实现高可用……
XX 公司运维老大:你说的这些别的厂商也有,我就问一个问题,我们现在要存储一年的游戏日志,不能删除数据,每天就按 10TB 的数据量算,一年也得有个 3PB 多的数据,这么大的数量,都放在 SSD 云盘上,成本太高了。你们有什么方案既能够满足我们存储这么大数据量的需求,同时能够降低我们的成本吗?
bellen: 我们本身提供的有冷热模式的集群,热节点采用 SSD 云硬盘,冷节点采用 SATA 盘,采用 ES 自带的 ILM 索引生命周期管理功能,定期把较老的索引从热节点迁移到冷节点上,这样从整体上可以降低成本。另外,也可以定期把更老的索引通过 snapshot 快照备份到 COS 对象存储中,然后删除索引,这样成本就更低了。
XX 公司运维老大:存储到 COS 就是冷存储呗,我们需要查询 COS 里的数据时,还得再把数据恢复到 ES 里?这样不行,速度太慢了,业务等不了那么长时间,我们的数据不能删除,只能放在 ES 里!你们能不能给我们提供一个 API, 让老的索引数据虽然存储在 COS 里,但是通过这个 API 依然可以查询到数据,而不是先恢复到 ES, 再进行查询?
bellen:呃,这个可以做,但是需要时间。是否可以采用 hadoop on COS 的架构,把存量的老的索引数据通过工具导入到 COS,通过 hive 去查询,这样成本会非常低,数据依然是随时可查的。
XX 公司运维老大:那不行,我们只想用成熟的 ELK 架构来做,再增加 hadoop 那一套东西,我们没那么多人力搞这个事!
bellen: 好吧,那可以先搞一个集群测试起来,看看性能怎么样。关于存量数据放在 COS 里但是也需要查询的问题,我们可以先制定方案,尽快实施起来。
XX 公司运维老大:行吧,我们现在按每天 10TB 数据量预估,先购买一个集群,能撑 3 个月的数据量就行,能给一个集群配置的建议吗?
bellen: 目前支持单节点磁盘最大 6TB, cpu 和内存的话可以放到 8 核 32G 单节点,单节点跑 2w qps 写入没有问题,后面也可以进行纵向扩容和横向扩容。
XX 公司运维老大:好,我们先测试一下。
场景 2:集群扛不住压力了
N 天后,架构师 A 直接在微信群里反馈:bellen, 客户反馈这边的 ES 集群性能不行啊,使用 logstash 消费 kafka 中的日志数据,跑了快一天了数据还没追平,这是线上的集群,麻烦紧急看一下吧。
我一看,一脸懵, 什么时候已经上线了啊,不是还在测试中吗?
XX 公司运维 B: 我们购买了 8 核 32G*10 节点的集群,单节点磁盘 6TB, 索引设置的 10 分片 1 副本,现在使用 logstash 消费 kafka 中的数据,一直没有追平,kafka 中还有很多数据积压,感觉是 ES 的写入性能有问题。
随后我立即查看了集群的监控数据,发现 cpu 和 load 都很高,jvm 堆内存使用率平均都到了 90%,节点 jvm gc 非常频繁了,部分节点因为响应缓慢,不停的离线又上线。
经过沟通,发现用户的使用姿势是 filebeat+kafka+logstash+elasticsearch, 当前已经在 kafka 中存储了有 10 天的日志数据,启动了 20 台 logstash 进行消费,logstash 的 batch size 也调到了 5000,性能瓶颈是在 ES 这一侧。客户 8 核 32G*10 节点的集群,理论上跑 10w qps 没有问题,但是 logstash 消费积压的数据往 ES 写入的 qps 远不止 10w,所以是 ES 扛不住写入压力了,只能对 ES 集群进行扩容,为了加快存量数据的消费速度,先纵向扩容单节点的配置到 32 核 64GB,之后再横向增加节点,以保证 ES 集群能够最大支持 100w qps 的写入(这里需要注意的是,增加节点后索引的分片数量也需要调整)。
所以一般新客户接入使用 ES 时,必须要事先评估好节点配置和集群规模,可以从以下几个方面进行评估:
- 存储容量:要考虑索引副本数量、数据膨胀、ES 内部任务额外占用的磁盘空间(比如 segment merge)以及操作系统占用的磁盘空间等因素,如果再需要预留 50%的空闲磁盘空间,那么集群总的存储容量大约为源数据量的 4 倍
- 计算资源:主要考虑写入,2 核 8GB 的节点可以支持 5000qps 的写入,随着节点数量和节点规格的提升,写入能力基本呈线性增长
- 索引和分片数量评估:一般一个 shard 的数据量在 30-50GB 为宜,可以以此确定索引的分片数量以及确定按天还是按月建索引。需要控制单节点总的分片数量,1GB 堆内存支持 20-30 个分片为宜;另外需要控制集群整体的分片数量,集群总体的分片数量一般不要超过 3w。
场景 3:logstash 消费 kafka 性能调优
上面遇到的问题是业务上线前没有对集群配置和规模进行合理的评估,导致上线后 ES 集群扛不住了。通过合理的扩容处理,集群最终抗住了写入压力,但是新的问题又随之出现了。
因为 kafka 积压的数据比较多,客户使用 logstash 消费 kafka 数据时,反馈有两个问题:
- 增加多台 logstash 消费 kafka 数据,消费速度没有线性提升
- kafka 的不同 topic 消费速度不均匀、topic 内不同 partition 消费的速度也不均匀
经过分析客户 logstash 的配置文件,发现问题出现的原因主要是:
- topic 的 partition 数量少,虽然 logstash 机器数量多,但是却没有充分利用机器资源并行消费数据,导致消费速度一直上不去
- 所有 logstash 的配置文件都相同,使用一个 group 同时消费所有的 topic,存在资源竞争的问题
分析后,对 kafka 和 logstash 进行了如下优化:
- 提高 kafka topic 的分区数量
- 对 logstash 进行分组;对于数据量较大的 topic,可以单独设置一个消费组进行消费,有一组 logstash 单独使用这个消费组对该 topic 进行消费;其它的数据量较小的 topic,可以共用一个消费组和一组 logstash
- 每组 logstash 中总的 consumer_threads 数量和消费组总的 partion 数量保持一致,比如有 3 个 logstash 进程,消费的 topic 的 partition 数量为 24, 那么每个 logstash 配置文件中的 consumer_threads 就设置为 8
通过上述优化,最终使得 logstash 机器资源都被充分利用上,很快消费完堆积的 kafka 数据,待消费速度追平生成速度后,logstash 消费 kafka 一直稳定运行,没有出现积压。
另外,客户一开始使用的是 5.6.4 版本的 logstash,版本较老,使用过程中出现因为单个消息体过长导致 logstash 抛异常后直接退出的问题:
whose size is larger than the fetch size 4194304 and hence cannot be ever returned. Increase the
fetch size on the client (using max.partition.fetch.bytes),
or decrease the maximum message size the broker will allow (using message.max.bytes)
通过把 logstash 升级至高版本 6.8 避免了这个问题(6.x 版本的 logstash 修复了这个问题,避免了 crash)。
场景 4:磁盘要满了,紧急扩容?
客户的游戏上线有一个月了,原先预估每天最多有 10TB 的数据量,实际则是在运营活动期间每天产生 20TB 的数据,原先 6TB*60=360TB 总量的数据盘使用率也达到了 80%。针对这种情况,我们建议客户使用冷热分离的集群架构,在原先 60 个热节点的基础上,增加一批 warm 节点存储冷数据,利用 ILM(索引生命周期管理)功能定期迁移热节点上的索引到 warm 节点上。
通过增加 warm 节点的方式,客户的集群磁盘总量达到了 780TB, 可以满足最多三个月的存储需求。但是客户的需求还没有满足:
XX 公司运维老大:给我们一个能存放一年数据的方案吧,总是通过加节点扩容磁盘的方式不是长久之计,我们得天天盯着这个集群,运维成本很高!并且一直加节点,ES 会扛不住吧?
bellen: 可以尝试使用我们新上线的支持本地盘的机型,热节点最大支持 7.2TB 的本地 SSD 盘,warm 节点最大支持 48TB 的本地 SATA 盘。一方面热节点的性能相比云盘提高了,另外 warm 节点可以支持更大的磁盘容量。单节点可以支持的磁盘容量增大了,节点数量就不用太多了,可以避免踩到因为节点数量太多而触发的坑。
XX 公司运维老大:现在用的是云盘,能替换成本地盘吗,怎么替换?
bellen: 不能直接替换,需要在集群中新加入带本地盘的节点,把数据从老的云盘节点迁移到新的节点上,迁移完成后再剔除掉旧的节点,这样可以保证服务不会中断,读写都可以正常进行。
XX 公司运维老大:好,可以实施,尽快搞起来!
云盘切换为本地盘,是通过调用云服务后台的 API 自动实施的。在实施之后,触发了数据从旧节点迁移到新节点的流程,但是大约半个小时候,问题又出现了:
XX 公司运维小: bellen, 快看一下,ES 的写入快掉 0 了。
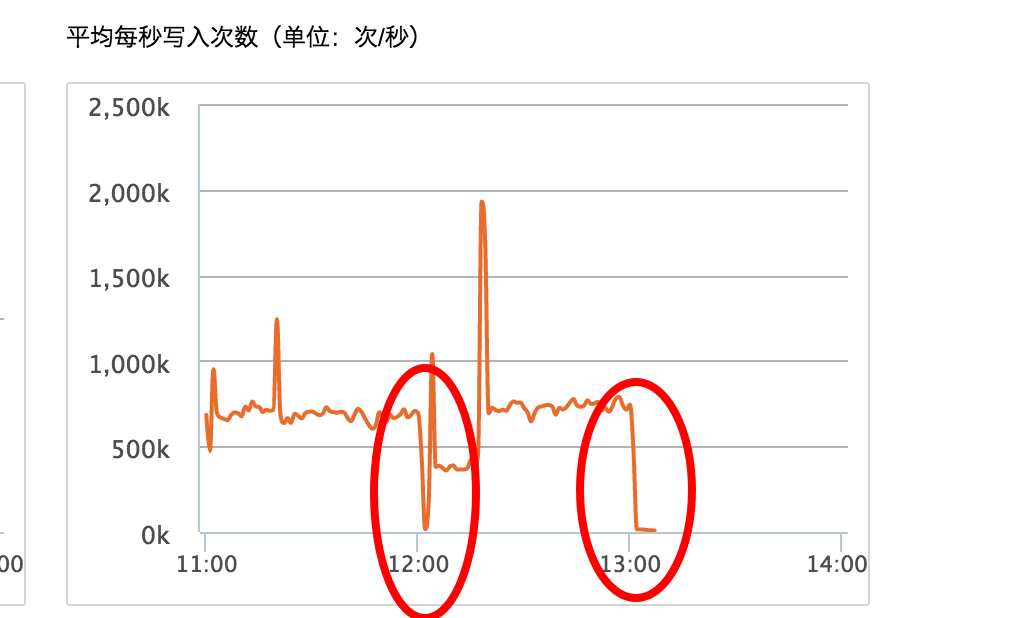
 通过查看集群监控,发现写入 qps 直接由 50w 降到 1w,写入拒绝率猛增,通过查看集群日志,发现是因为当前小时的索引没有创建成功导致写入失败。
通过查看集群监控,发现写入 qps 直接由 50w 降到 1w,写入拒绝率猛增,通过查看集群日志,发现是因为当前小时的索引没有创建成功导致写入失败。
紧急情况下,执行了以下操作定位到了原因:
- GET _cluster/health
发现集群健康状态是 green,但是有大约 6500 个 relocating_shards, number_of_pending_tasks 数量达到了数万。
- GET _cat/pending_tasks?v
发现大量的"shard-started"任务在执行中,任务优先级是"URGENT", 以及大量的排在后面的"put mapping"的任务,任务优先级是"HIGH";“URGENT"优先级比"HIGH"优先级要高,因为大量的分片从旧的节点迁移到新的节点上,造成了索引创建的任务被阻塞,从而导致写入数据失败。
- GET _cluster/settings
为什么会有这么多的分片在迁移中?通过 GET _cluster/settings 发现"cluster.routing.allocation.node_concurrent_recoveries"的值为 50,而目前有 130 个旧节点在把分片迁移到 130 个新节点中,所以有 130*50=6500 个迁移中的分片。而"cluster.routing.allocation.node_concurrent_recoveries"参数的值默认为 2,应该是之前在执行纵向扩容集群时,为了加快分片迁移速度人为修改了这个值(因为集群一开始节点数量没有很多,索引同时迁移中的分片也不会太多,所以创建新索引不会被阻塞)。
- PUT _cluster/settings
现在通过 PUT _cluster/settings 把"cluster.routing.allocation.node_concurrent_recoveries"参数修改为 2。但是因为"put settings"任务的优先级也是"HIGH”, 低于"shard-started"任务的优先级,所以更新该参数的操作还是会被阻塞,ES 报错执行任务超时。此时,进行了多次重试,最终成功把"cluster.routing.allocation.node_concurrent_recoveries"参数修改为了 2。
- 取消 exclude 配置
现在通过 GET _cluster/health 看到迁移中的分片数量在逐渐减少,为了不增加新的迁移任务,把执行数据迁移的 exclude 配置取消掉:
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._name": ""
}
}
- 加速分片迁移
同时调大分片恢复时节点进行数据传输的每秒最大字节数(默认为 40MB),加速存量的分片迁移任务的执行:
PUT _cluster/settings
{
"transient": {
"indices": {
"recovery": {
"max_bytes_per_sec": "200mb"
}
}
}
}
- 提前创建索引
现在看到迁移中的分片数量慢慢减少,新索引已经创建成功了,写入恢复正常了。到下个整点时,发现新建索引还是比较慢,因为还有几百个分片在迁移中,创建新索引大概耗时 5 分钟,这 5 分钟内写入也是失败的。
 等几百个迁移中的分片都执行完毕后,新建索引就比较快了,也不会再写入失败了。但是问题是当前正在执行云盘节点切换为本地盘的流程,需要把数据从旧的130个节点上迁移到新的130个节点上,数据迁移的任务不能停,那该怎么办?既然新创建索引比较慢,那就只好提前把索引都创建好,避免了在每个整点数据写入失败的情况。通过编写python脚本,每天执行一次,提前把第二天的每个小时的索引创建好,创建完成了再把"cluster.routing.allocation.exclude._name"更改为所有的旧节点,保证数据迁移任务能够正常执行。
等几百个迁移中的分片都执行完毕后,新建索引就比较快了,也不会再写入失败了。但是问题是当前正在执行云盘节点切换为本地盘的流程,需要把数据从旧的130个节点上迁移到新的130个节点上,数据迁移的任务不能停,那该怎么办?既然新创建索引比较慢,那就只好提前把索引都创建好,避免了在每个整点数据写入失败的情况。通过编写python脚本,每天执行一次,提前把第二天的每个小时的索引创建好,创建完成了再把"cluster.routing.allocation.exclude._name"更改为所有的旧节点,保证数据迁移任务能够正常执行。
- 结果展示
总量 400TB 的数据,大约经过 10 天左右,终于完成迁移了。配合提前新建索引的 python 脚本,这 10 天内也没有出现写入失败的情况。
经过了这次扩容操作,总结了如下经验:
- 分片数量过多时,如果同时进行迁移的分片数量过多,会阻塞索引创建和其它配置更新操作,所以在进行数据迁移时,要保证"cluster.routing.allocation.node_concurrent_recoveries"参数和"cluster.routing.allocation.cluster_concurrent_rebalance"为较小的值。
- 如果必须要进行数据迁移,则可以提前创建好索引,避免 ES 自动创建索引时耗时较久,从而导致写入失败。
场景 5:10 万个分片?
在稳定运行了一阵后,集群又出问题了。
XX 公司运维 B: bellen, 昨晚凌晨 1 点钟之后,集群就没有写入了,现在 kafka 里有大量的数据堆积,麻烦尽快看一下?
通过 cerebro 查看集群,发现集群处于 yellow 状态,然后发现集群有大量的错误日志:
{"message":"blocked by: [SERVICE_UNAVAILABLE/1/state not recovered / initialized];:
[cluster_block_exception] blocked by: [SERVICE_UNAVAILABLE/1/state not recovered /
initialized];","statusCode":503,"error":"Service Unavailable"}
然后再进一步查看集群日志,发现有"master not discovered yet…“之类的错误日志,检查三个 master 节点,发现有两个 master 挂掉,只剩一个了,集群无法选主。
登陆到挂了的 master 节点机器上,发现保活程序无法启动 es 进程,第一直觉是 es 进程 oom 了;此时也发现 master 节点磁盘使用率 100%, 检查了 JVM 堆内存快照文件目录,发现有大量的快照文件,于是删除了一部分文件,重启 es 进程,进程正常启动了;但是问题是堆内存使用率太高,gc 非常频繁,master 节点响应非常慢,大量的创建索引的任务都超时,阻塞在任务队列中,集群还是无法恢复正常。
看到集群 master 节点的配置是 16 核 32GB 内存,JVM 实际只分配了 16GB 内存,此时只好通过对 master 节点原地增加内存到 64GB(虚拟机,使用的腾讯云 CVM, 可以调整机器规格,需要重启),master 节点机器重启之后,修改了 es 目录 jvm.options 文件,调整了堆内存大小,重新启动了 es 进程。
3 个 master 节点都恢复正常了,但是分片还需要进行恢复,通过 GET _cluster/health 看到集群当前有超过 10w 个分片,而这些分片恢复还需要一段时间,通过调大"cluster.routing.allocation.node_concurrent_recoveries”, 增大分片恢复的并发数量。实际上 5w 个主分片恢复得是比较快的了,但是副本分片的恢复就相对慢很多,因为部分副本分片需要从主分片上同步数据才能恢复。此时可以采取的方式是把部分旧的索引副本数量调为 0, 让大量副本分片恢复的任务尽快结束,保证新索引能够正常创建,从而使得集群能够正常写入。
总结这次故障的根本原因是:集群的索引和分片数量太多,集群元数据占用了大量的堆内存,而 master 节点本身的 JVM 内存只有 16GB(数据节点有 32GB), master 节点频繁 full gc 导致 master 节点异常,从而最终导致整个集群异常。所以要解决这个问题,还是得从根本上解决集群的分片数量过多的问题。
目前日志索引是按照小时创建,60 分片 1 副本,每天有 24 60 2=2880 个分片,每个月就产生 86400 个分片,这么多的分片可能会带来严重的问题。有以下几种方式解决分片数量过多的问题:
- 可以在 ILM 的 warm phase 中开启 shrink 功能,对老的索引从 60 分片 shrink 到 5 分片,分片数量可以降低 12 倍;
- 业务可以把每小时创建索引修改为每两个小时或者更长,可以根据每个分片数量最多支持 50GB 的数据推算多长时间创建新索引合适;
- 对老的索引设置副本为 0,只保留主分片,分片数量能够再下降近一倍,存储量也下降近一倍;
- 定期关闭最老的索引,执行{index}/_close。
和客户沟通过后,客户表示可以接受方式 1 和方式 2,但是方式 3 和 4 不能接受,因为考虑到存在磁盘故障的可能性,必须保留一个副本来保证数据的可靠性;另外还必须保证所有数据都是随时可查询的,不能关闭。
场景 6:有点坑的 ILM
在上文中,虽然通过临时给 master 节点增加内存,抗住了 10w 分片,但是不能从根本上解决问题。客户的数据是计划保留一年的,如果不进行优化,集群必然扛不住数十万个分片。所以接下来需要着重解决集群整体分片数量过多的问题。前文也提到了,客户可以接受开启 shrink 以及降低索引创建粒度(经过调整后,每两个小时创建一个索引),这在一定程度上减少了分片的数量,能够使集群暂时稳定一阵。
辅助客户在 kibana 上配置了如下的 ILM 策略:
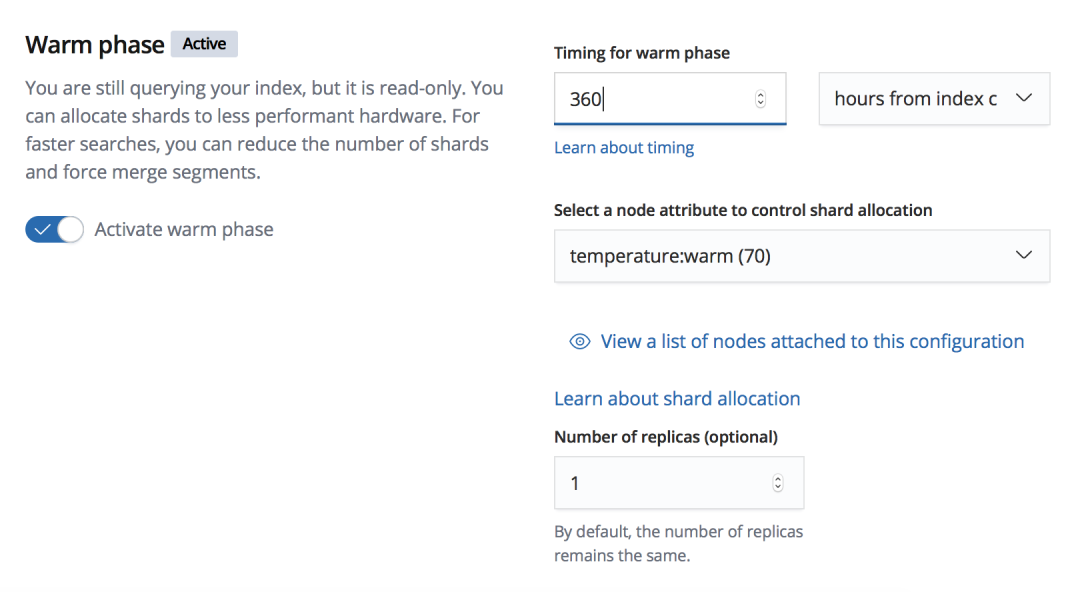 在 warm phase, 把创建时间超过 360 小时的索引从 hot 节点迁移到 warm 节点上,保持索引的副本数量为 1。之所以使用 360 小时作为条件,而不是 15 天作为条件,是因为客户的索引是按小时创建的,如果以 15 天作为迁移条件,则在每天凌晨都会同时触发 15 天前的 24 个索引一共 24*120=2880 个分片同时开始迁移索引,容易引发前文介绍的由于迁移分片数量过多导致创建索引被阻塞的问题。所以以 360 小时作为条件,则在每个小时只会执行一个索引的迁移,这样把 24 个索引的迁移任务打平,避免其它任务被阻塞的情况发生。
在 warm phase, 把创建时间超过 360 小时的索引从 hot 节点迁移到 warm 节点上,保持索引的副本数量为 1。之所以使用 360 小时作为条件,而不是 15 天作为条件,是因为客户的索引是按小时创建的,如果以 15 天作为迁移条件,则在每天凌晨都会同时触发 15 天前的 24 个索引一共 24*120=2880 个分片同时开始迁移索引,容易引发前文介绍的由于迁移分片数量过多导致创建索引被阻塞的问题。所以以 360 小时作为条件,则在每个小时只会执行一个索引的迁移,这样把 24 个索引的迁移任务打平,避免其它任务被阻塞的情况发生。
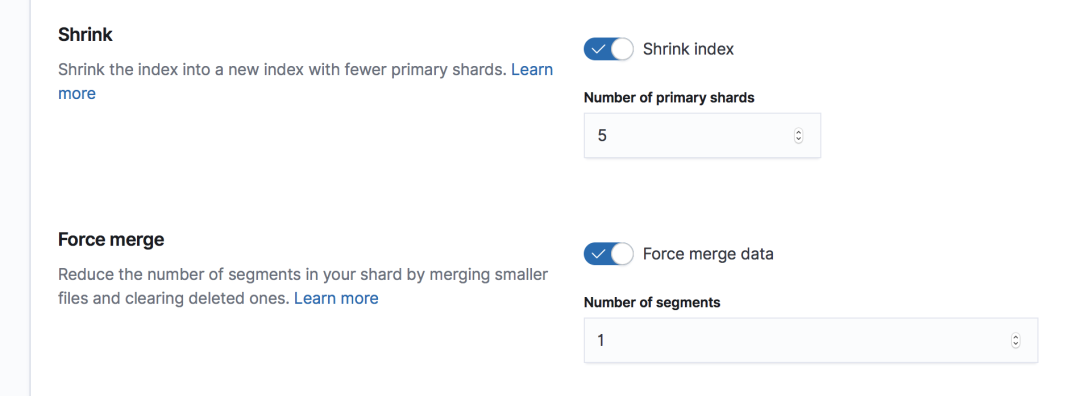 同时,也在 warm phase 阶段,设置索引 shrink,把索引的分片数缩成 5 个,因为老的索引已经不执行写入了,所以也可以执行 force merge, 强制把 segment 文件合并为 1 个,可以获得更好的查询性能。
同时,也在 warm phase 阶段,设置索引 shrink,把索引的分片数缩成 5 个,因为老的索引已经不执行写入了,所以也可以执行 force merge, 强制把 segment 文件合并为 1 个,可以获得更好的查询性能。
另外,设置了 ILM 策略后,可以在索引模板里增加 index.lifecycle.name 配置,使得所有新创建的索引都可以和新添加的 ILM 策略关联,从而使得 ILM 能够正常运行。
客户使用的 ES 版本是 6.8.2, 在运行 ILM 的过程中, 也发现一些问题:
- 新添加的策略只能对新创建的索引生效,存量的索引只能通过批量修改索引 settings 里的 index.lifecycle.name 执行策略;
- 如果一个策略进行了修改,那么所有存量的索引,不管是有没有执行过该策略,都不会执行修改后的策略,也即修改后的策略只对修改成功后新创建的索引生效。比如一开始的策略没有开启 shrink, 现在修改策略内容添加了 shrink 操作,那么只有之后新创建的索引在达到策略触发条件(比如索引已经创建超过 360 个小时)后才会执行 shrink, 而之前的所有索引都不会执行 shrink,此时若想对存量的索引也执行 shrink,只能够通过脚本批量执行了;
- 在 warm phase 同时执行索引迁移和 shrink 会触发 es 的 bug, 如上图中的 ILM 策略,索引本身包含 60 分片 1 副本,初始时都在 hot 节点上,在创建完成 360 小时之后,会执行迁移,把索引都迁移到 warm 节点上,同时又需要把分片 shrink 到 5,在实际执行中,发现一段时间后有大量的 unassigned shards,分片无法分配的原因如下:
"deciders" : [
{
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated to the same node on which a copy of the shard already exists [[x-2020.06.19-13][58], node[LKsSwrDsSrSPRZa-EPBJPg], [P], s[STARTED], a[id=iRiG6mZsQUm5Z_xLiEtKqg]]"
},
{
"decider" : "awareness",
"decision" : "NO",
"explanation" : "there are too many copies of the shard allocated to nodes with attribute [ip], there are [2] total configured shard copies for this shard id and [130] total attribute values, expected the allocated shard count per attribute [2] to be less than or equal to the upper bound of the required number of shards per attribute [1]"
}
这是因为 shrink 操作需要新把索引完整的一份数据都迁移到一个节点上,然后在内存中构建新的分片元数据,把新的分片通过软链接指向到几个老的分片的数据,在 ILM 中执行 shrink 时,ILM 会对索引进行如下配置:
{
"index.routing" : {
"allocation" : {
"require" : {
"temperature" : "warm",
"_id" : "LKsSwrDsSrSPRZa-EPBJPg"
}
}
}
}
问题是索引包含副本,而主分片和副本分片又不能在同一个节点上,所以会出现部分分片无法分配的情况(不是全部,只有一部分)。这里应该是触发了 6.8 版本的 ILM 的 bug,需要查看源码才能定位解决这个 bug,目前还在研究中。当前的 workaround 是通过脚本定期扫描出现 unassigned shards 的索引,修改其 settings:
{
"index.routing" : {
"allocation" : {
"require" : {
"temperature" : "warm",
"_id" : "LKsSwrDsSrSPRZa-EPBJPg"
}
}
}
}
优先保证分片先从 hot 节点迁移到 warm 节点,这样后续的 shrink 才能顺利执行(也可能执行失败,因为 60 个分片都在一个节点上,可能会触发 rebalance, 导致分片迁移走,shrink 的前置条件又不满足,导致执行失败)。要完全规避这个问题,还得在 ILM 策略中设置,满足创建时间超过 360 个小时的索引,副本直接调整为 0,但是客户又不接受,没办法。
场景 7:自己实现 SLM
上文介绍了 10w 个分片会给集群带来的影响和通过开启 shrink 来降低分片数量,但是仍然有两个需要重点解决的问题:
- 索引不断新建,如何保证一年内,集群总的分片数量不高于 10w,稳定在一个较低的水位?
- ILM 中执行 shrink 可能会导致部分分片未分配以及 shrink 执行失败,怎么彻底解决呢?
可以估算一下,按小时建索引,60 分片 1 副本,一年的分片数为 24 120 365=1051200 个分片,执行 shrink 后分片数量 24 10 350 + 24 120 15 = 127200(15 天内的新索引为了保障写入性能和数据可靠性,仍然保持 60 分片 1 副本,旧的索引 shrink 为 5 分片 1 副本), 仍然有超过 10w 个分片。结合集群一年总的存储量和单个分片可以支持的数据量大小进行评估,我们期望集群总体的分片数量可以稳定为 6w~8w,怎么优化?
可以想到的方案是执行数据冷备份,把比较老的索引都冷备到其它的存储介质上比如 HDFS、S3、腾讯云的 COS 对象存储等。但是问题是这些冷备的数据如果也要查询,需要先恢复到 ES 中才可查,恢复速度比较慢,客户无法接受。由此也产生了新的想法,目前老的索引仍然是 1 副本,可以把老索引先进行冷备份,再把副本调为 0,这样做有以下几点好处:
- 集群整体分片数量能降低一半;
- 数据存储量也能降低一半,集群可以存储更多数据;
- 老的索引仍然随时可查;
- 极端情况下,磁盘故障引起只有一个副本的索引数据无法恢复时,可以从冷备介质中进行恢复。
经过和客户沟通,客户接受了上述方案,计划把老索引冷备到腾讯云的对象存储 COS 中,实施步骤为:
- 所有存量的老索引,需要批量处理,尽快地备份到 COS 中,然后批量修改副本数量为 0;
- 最近新建的索引,采用按天备份的策略,结合 ILM, 修改策略,在 ILM 执行过程中修改索引副本数为 0(ILM 的 warm phase 和 cold phase 都支持设置副本数量)。
其中第一个步骤的实施可以通过脚本实现,本案例中就采用了腾讯云 SCF 云函数进行实施,方便快捷可监控。实施要点有:
- 按天创建 snapshot,批量备份每天产生的 24 个索引,如果是按月或者更大粒度创建快照,因数据量太大如果执行快照过程中出现中断,则必须全部重来,耗时耗力;按小时创建快照也不适用,会造成快照数量太多,可能会踩到坑。
- 每创建一个快照,后续需要轮询快照的状态,保证前一个快照 state 为"SUCCESS"之后,再创建下一个快照;因为快照是按天创建的,快照名字可以为 snapshot-2020.06.01, 该快照只备份 6 月 1 号的所有索引。而在检查到 snapshot-2020.06.01 快照执行成功后,然后新建下一个快照时,需要知道要对哪天的索引打快照,因此需要记录当前正在执行哪一个快照。有两种方式记录,一是把当前正在执行的快照日期后缀"2020.06.01"写入到文件中, 脚本通过定时任务轮询时,每次都读文件;另外一种方式是创建一个临时的索引,把"2020.06.01"写入到这个临时索引的一个 doc 中,之后对该 doc 进行查询或者更新。
- 创建快照时,可以把"include_global_state"置为 false, 不对集群的全局状态信息进行备份。
在实施完第一个步骤之后,就可以批量把对索引进行过备份的索引副本数都调为 0, 这样一次性释放了很多磁盘空间,并且显著降低了集群整体的分片数量。
接下来实施第二个步骤,需要每天执行一次快照,多创建时间较久的索引进行备份。实施比较简单,可以通过 crontab 定时执行脚本或者使用腾讯云 SCF 执行。
之后,就可以修改 ILM 策略,开启 cold phase, 修改索引副本数量为 0:
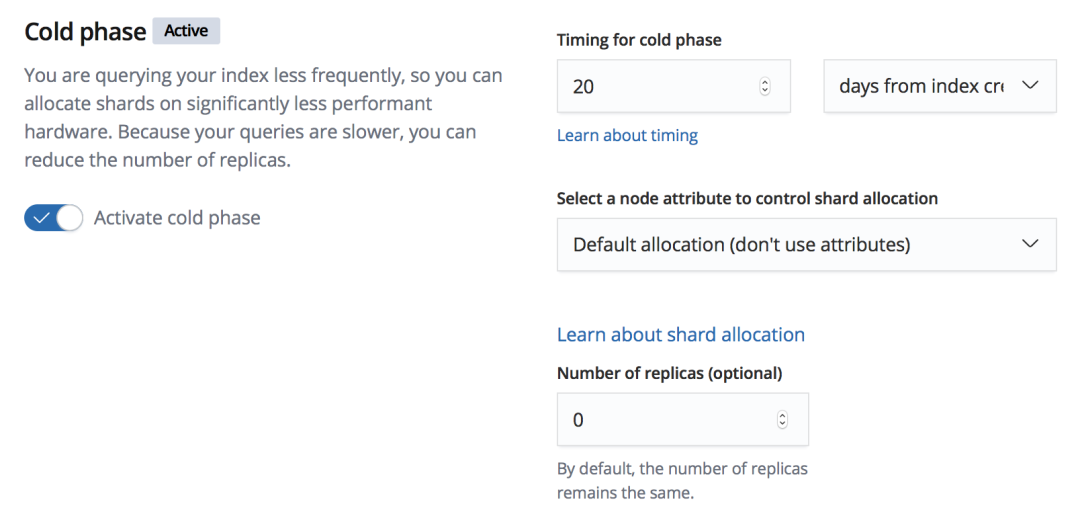 此处的 timing 是创建时间 20 天后,需要保证在第二步骤中,对过去老索引数据备份先执行完成后才可以进入到 cold phase.
此处的 timing 是创建时间 20 天后,需要保证在第二步骤中,对过去老索引数据备份先执行完成后才可以进入到 cold phase.
通过老索引数据冷备并且降低索引副本,我们可以把集群整体的分片数量维持在一个较低的水位。但是还有另外一个问题待解决,也即 shrink 失败的问题。刚好,我们可以利用对老索引数据冷备并且降低索引副本的方案,来彻底解决 shrink 失败的问题。
在前文有提到,shrink 失败归根结底是因为索引的副本数量为 1, 现在我们可以把数据备份和降低副本提前,让老索引进入到 ILM 的 warm phase 中时已经是 0 副本,之后再执行 shrink 操作就不会有问题了;同时,因为副本降低了,索引从 hot 节点迁移到 warm 节点迁移的数据量也减少了一半,从而降低了集群负载,一举两得。
因此,我们需要修改 ILM 策略,在 warm phase 就把索引的副本数量调整为 0, 然后去除 cold phase。
另外一个可选的优化项是:对老的索引进行冻结,冻结索引是指把索引常驻内存的一些数据从内存中清理掉(比如 FST, 元数据等), 从而降低内存使用量,而在查询已经冻结的索引时,会重新构建出临时的索引数据结构存放在内存中,查询完毕再清理掉;需要注意的是,默认情况下是无法查询已经冻结的索引的,需要在查询时显式的增加"ignore_throttled=false"参数。
经过上述优化,我们最终解决了集群整体分片数量过多和 shrink 失败的问题。在实施过程中引入了额外的定时任务脚本实施自动化快照,实际上在 7.4 版本的 ES 中,已经有这个功能了,特性名称为 SLM(快照生命周期管理),并且可以结合 ILM 使用,在 ILM 中增加了"wait_for_snapshot"的 ACTION, 但是却只能在 delete phase 中使用,不满足我们的场景。
场景 8:客户十分喜欢的 Searchable Snapshots!
在上述的场景中,我们花费大量的精力去解决问题和优化使用方式,保证 ES 集群能够稳定运行,支持 PB 级别的存储。溯本回原,如果我们能有一个方案使得客户只需要把热数据放在 SSD 盘上,然后冷数据存储到 COS/S3 上,但同时又使冷数据能够支持按需随时可查,那我们前面碰到的所有问题都迎刃而解了。可以想象得到的好处有:
- 只需要更小规模的集群和非常廉价的 COS/S3 对象存储就可以支持 PB 级别的数据量,客户的资金成本非常低;
- 小规模的集群只需要能够支撑热索引的写入和查询即可,集群整体的分片数不会太多,从而避免了集群不稳定现象的发生。
而这正是目前 es 开源社区正在开发中的 Searchable Snapshots 功能,从 Searchable Snapshots API 的官方文档上可以看到,我们可以创建一个索引,将其挂载到一个指定的快照中,这个新的索引是可查询的,虽然查询时间可能会慢点,但是在日志场景中,对一些较老的索引进行查询时,延迟大点一般都是可以接受的。
所以我认为,Searchable Snapshots 解决了很多痛点,将会给 ES 带来新的繁荣!
总结
经历过上述运维和优化 ES 集群的实践,我们总结到的经验有:
- 新集群上线前务必做好集群规模和节点规格的评估
- 集群整体的分片数量不能太多,可以通过调整使用方式并且借助 ES 本身的能力不断进行优化,使得集群总体的分片数维持在一个较低的水位,保证集群的稳定性
- Searcha
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BA%A7%E5%A4%A7%E8%A7%84%E6%A8%A1%E9%9B%86%E7%BE%A4%E8%BF%90%E7%BB%B4%E4%B8%8E%E8%B0%83%E4%BC%98%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


