网易严选在严选供应链复杂业务系统的落地实践
复杂业务系统长期迭代,难免会逐渐腐化,如何治理腐化,并设计出能够延缓腐化,保持长期高效能的方案是一个开发同学难免要遇到的问题,本文旨在介绍一套基于DDD的落地实施方案,提供另外一种解决问题的思路。
系统背景
Teddy出入库系统,是进销存概念里的进和销,核心能力是仓库货物的出库和入库的流转,在严选供应链体系中承上启下,对接了数十个上下游系统,如下图所示,是订单履约、采购补货、仓间调拨、特殊出入库等业务场景的核心流程。
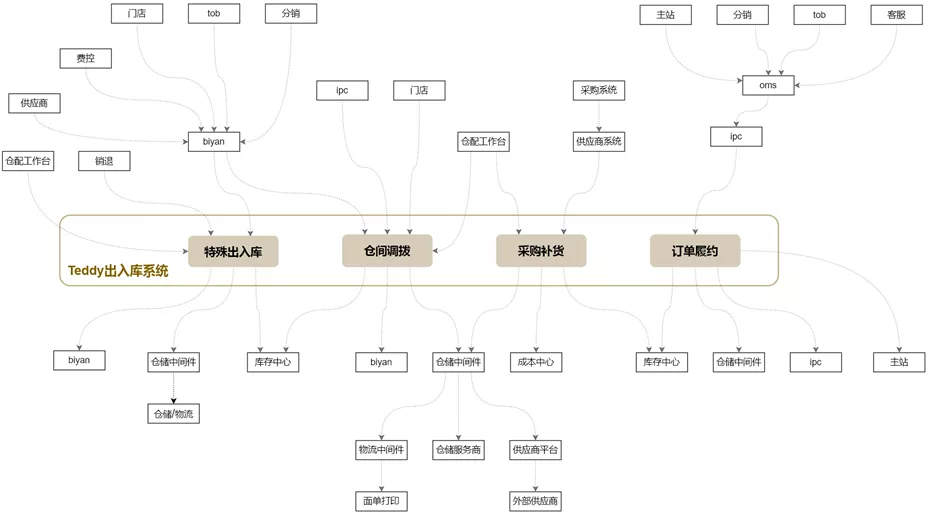
Teddy出入库系统作为一个元老级的应用,16年就已经存在,当时还叫做进销存,17年底做过一次拆分,自拆分上线以来,也已经经过了接近三年时间,这期间需求不断,迭代节奏飞快,原来的包袱不仅没卸下,反而越来越重,当下已经积重难返;此外,在这期间也经历了相当多的产品和开发,由于缺乏长期维护的文档和规范,业务逻辑演进的愈发复杂,代码风格也不加节制的多种多样。
总结下当前面临的一些问题,主要是以下几点:
业务复杂,边界不清
早期野蛮生长,大包大揽,边界不清的问题倒也合情合理,能够让人理解。
但在业务逻辑上,各种功能的迭代,一直在做加法,早已臃肿不堪,其中相当一部分不再使用的逻辑、不再存在的场景、过于复杂的流转过程等,连当年的产品经理也直呼后悔为嘛要这么做(ˉ▽ˉ;)…
架构混乱,功能分散
22万行的代码,层级就是没有层级,如下图所示,各种相互的依赖关系,功能逻辑散落在各种类里面。如果认真去看,可以找到每一种代码里的坏味道,比如循环查询、分散的功能点、过长的方法、分不清层次的service、模糊的模块边界等等。
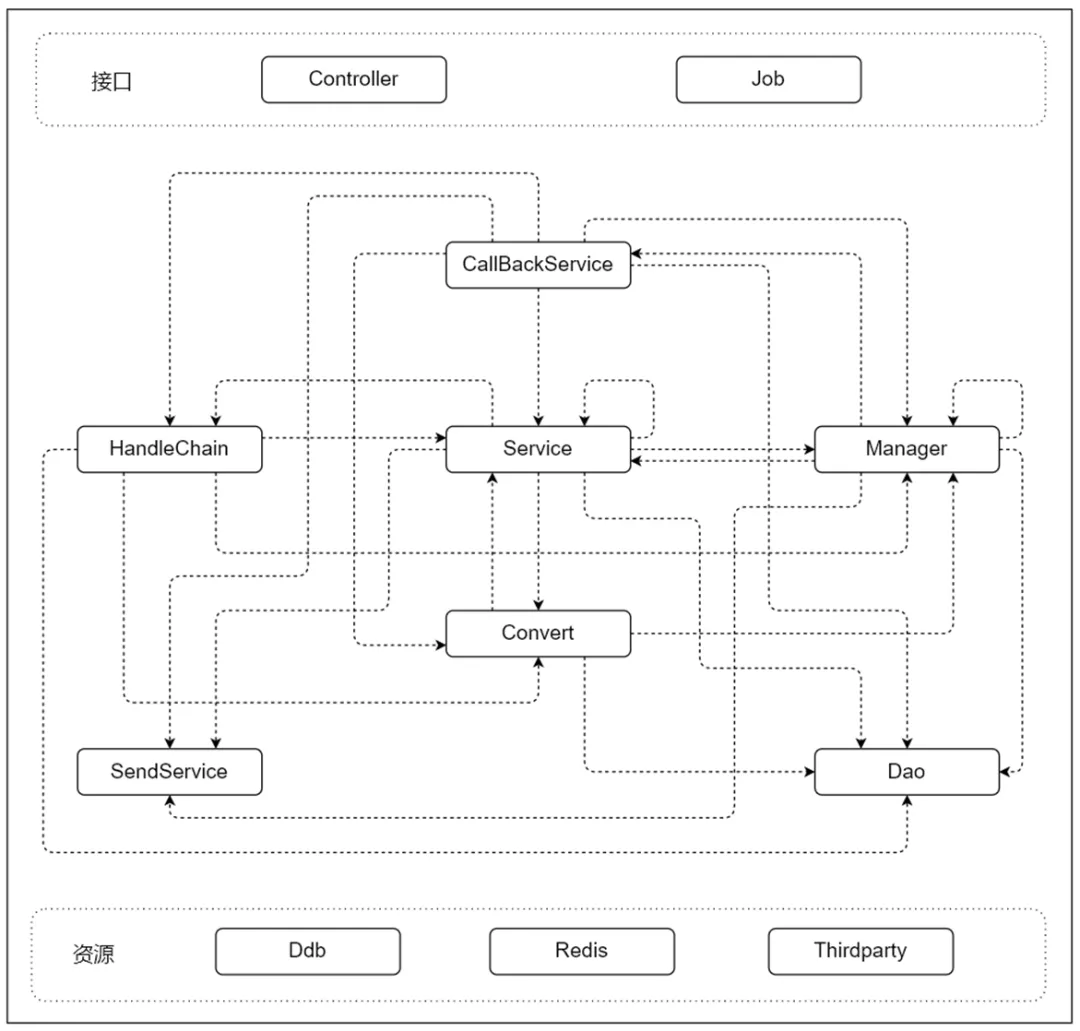
多种单据、多个仓库服务商,多个功能按仓配置等都在这里面
需求交付效率不可控
显而易见,伴随这些问题逐渐形成的,就是越来越不可控的需求评估范围,越来越评估不准确的需求工时,需求的交付效率和交付质量都面临很大的风险。
(插一句,虽然我们代码有点乱,但系统还是很稳定的 (ˉ▽ˉ;)… )
该怎么办?
长痛不如短痛,推倒吧,从头开始。
(一定要插播一句,推倒重构并不是应对复杂系统的最好办法,更好的思路是在日常的功能需求中,持续优化迭代,及时调整系统的整体结构,避免快速腐化。但当然现实是否能够如愿,就很难说了)
考虑到我们系统的现状,重构我们分为了两个部分,一块是技术架构方面的,另一块是业务逻辑方面,旨在精简优化复杂的逻辑,以及一些边界治理的工作,这一部分本篇文章就不细讲了,后面着重介绍下技术层面的实现。
设计及落地实践
方案选择
首当其冲的第一个问题,就是方案选型,基于当前的现状,我们先确定了一个整体的诉求: 业务边界清淅,架构合理,功能内聚,长期迭代能更好的避免腐化。
摆在面前的有两个选择:
第一种,延续以往的做法,以数据库表结构为核心,逻辑层进行合理的模块划分和分层
第二种,领域驱动设计,以领域模型为核心,解耦业务逻辑与数据库表结构的强耦合关系
领域驱动设计与之前的系统设计开发过程有很大的不同,第一点,就在于系统的参与角色,产品、开发、测试等,需要形成一套通用语言;第二点,在于方案设计不再把db设计放在一个核心问题去解决,更加专注于业务模型本身,进行领域、业务聚合的设计,领域层的聚合及实体才是整个系统的核心内容;第三点,真正的面向对象编程,由过程式的事务脚本方式,转变为真正的面向对象。

如上图所示,第一种方案的优点很明确,把架构划分清楚,采用一些优秀的设计模式,重新写一遍代码,确实能得到不少收益,但是缺点也是很明显的,面向过程的编程方式,功能逻辑易分散,长期迭代很容易又走回到原来的状态;相比较而言,第二种方案虽然前期学习成本、开发成本都比较高,但优势也很明确,业务导向,领域模型优先,边界规范易维持,核心业务逻辑内聚在领域内,低耦合,高内聚,易于长期维护。
基于我们的整体诉求,以及之前长期迭代下来面临到的一些问题,核心业务逻辑的高度内聚,逻辑功能避免分散是我们比较关注的目标,所以我们决定选择领域驱动设计。
落地实施
介绍下整体的实施步骤:
第一步建模:简单说,就是基于业务场景,与产品、开发、测试等协作,充分沟通,达成共识,形成通用语言,构建领域模型。这里我们采取了用例法,将主要的业务逻辑作为用例输入,聚焦事件 -> 命令->提取实体,最终划定出限界上下文。建模的过程不再详述,本文着重点在于一套领域驱动设计的落地代码模板,如对建模过程感兴趣可以留言联系交流。
第二步实施:通过领域模型指导架构设计和编码实现,并落地实施。
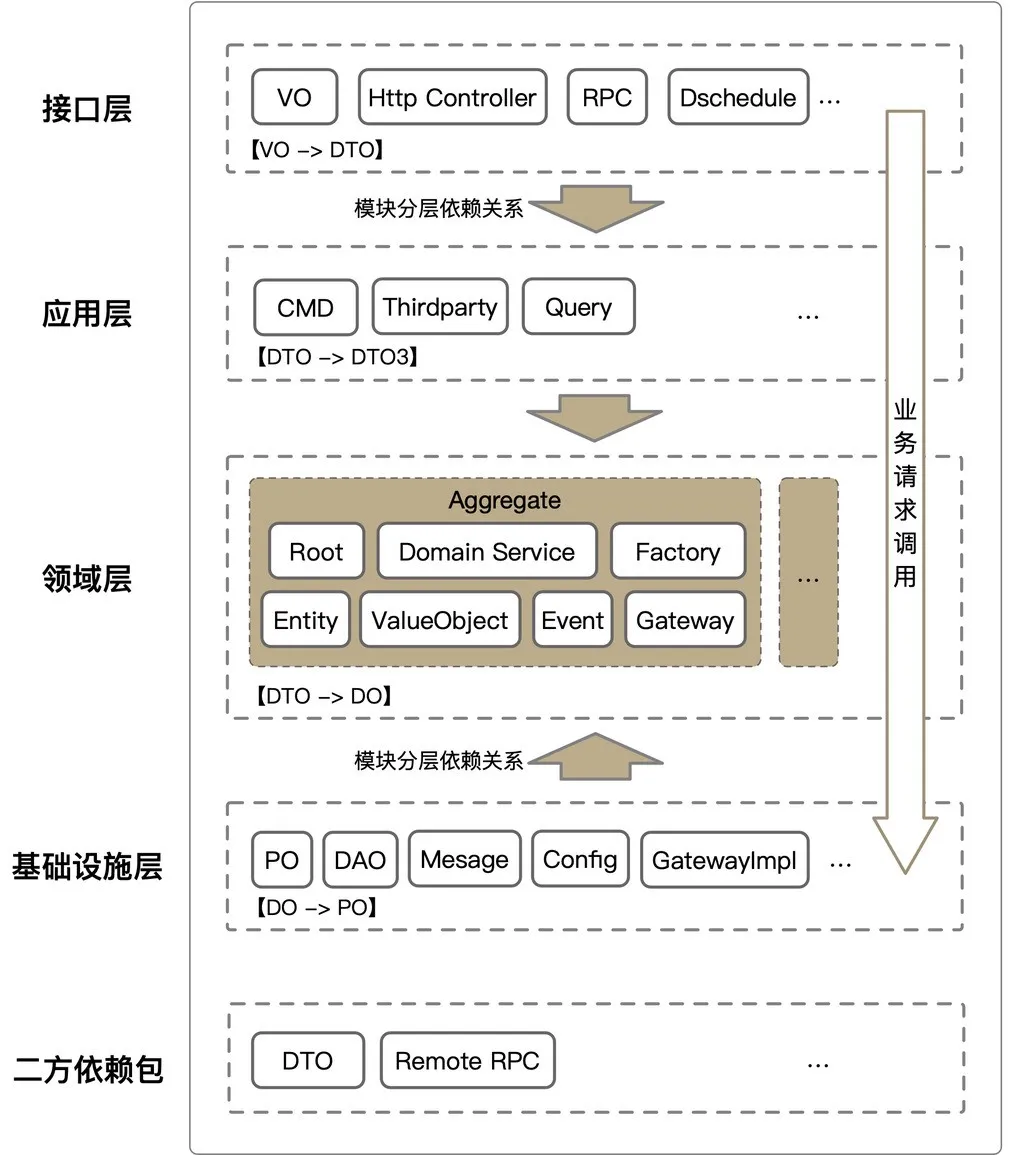
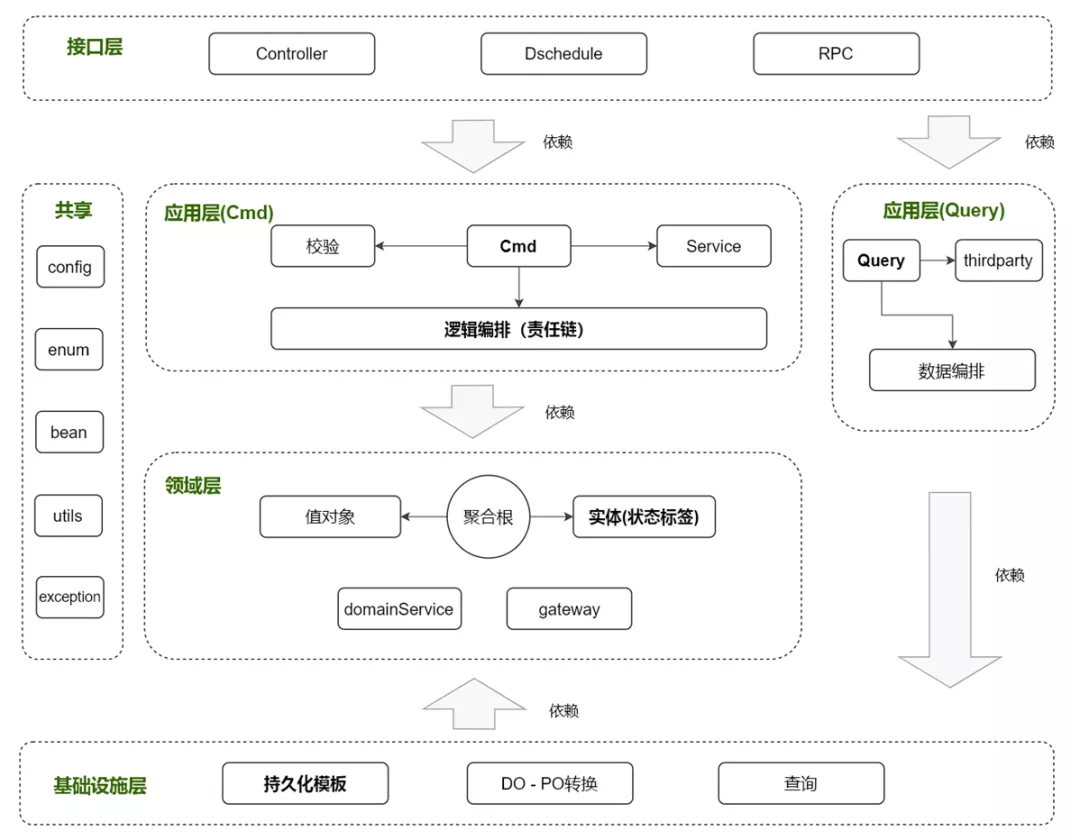
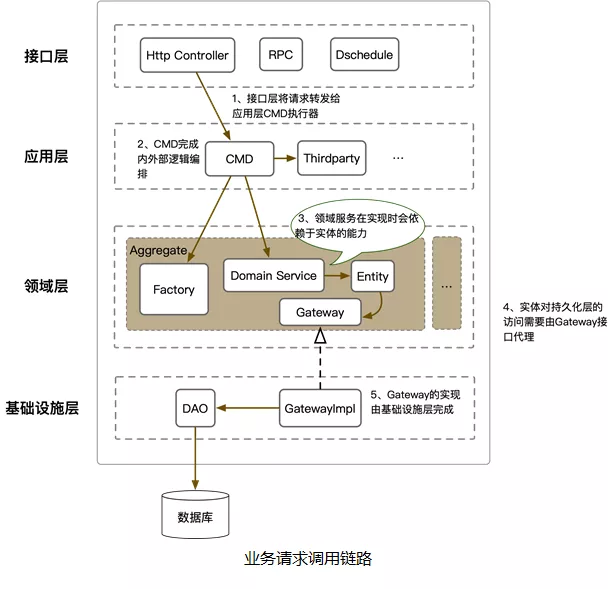
我们先看系统架构,整体上基于严选这边的中台应用架构(如上图)进行设计,系统架构如下图所示,基本上是一个洋葱架构的底子,加上CQRS,并基于具体实践演化出的一个结构,与洋葱架构的一个显著区别在于:应用层依赖了基础设施层,而不是基础设施层依赖应用层,这样可以带来编码上的很多便利;另一个小的区别是,在此之外增加了一个共享依赖包,放置一些工具类、枚举值、异常类、领域层的入参DTO等。
领域层:处于系统最底层,包含业务聚合、实体、领域能力等;领域层需要的持久化,以及其他能力需要在领域层定义gateWay接口,在基础设施层或者应用层进行实现。
基础设施层:依赖领域层,承接数据持久化等基础服务,实现了领域层定义的持久化gateWay接口,进行DO - PO数据转换,封装持久化细节等。
应用层:依赖领域层和基础设施层,对接外围接口层适配器,提供查询和命令能力,并采用责任链模式进行逻辑编排。
接口层:依赖应用层,提供外部服务的访问入口,包括但不限于HTTP、RPC等。
共享包:工具类、异常类、服务中的DTO对象等,共享包的存在主要是为了解决领域层和应用层共享数据结构的问题。
以一次命令执行为例,各组件在执行流程中的作用如下:
实践中遇到的问题:
1. 背着包袱的重构场景,聚合与实体要怎么设计?
这里面的问题是,面对已经存在的复杂业务模型,自顶向下设计(如下图所示)非常困难,而且与原有的数据结构模型会有很大的出入,这会带来大量的数据转换工作。

考虑到这种场景的特殊性,盲目的自顶向下设计可能无法落地实施,那么有没有可能不去忽视这种现状,而是在自顶向下划分了服务边界、聚合边界之后,结合原有的数据结构去设计聚合内的实体,以及实体间的关系?这会带来相当程度的便利:
(1)实体与db持久化数据间的转换相对简单一些
(2) 原有的代码实现中,相当一部分代码可以进行复用,这同时也极大的避免了一些隐藏逻辑被忽略的问题
(3) 实体本身的能力相对独立一些,会避免一些深层的嵌套逻辑
当然,坏处也是有的,整个聚合实体的关系,是比较扁平的,类似于一个大的包裹类,包含了这个业务子域涉及到的所有实体,扁平的数据模型一定程度上降低了业务模型的准确反映。
另外一个值得一提的点是,实体的更新应该由聚合封装为聚合能力,对外提供统一的入口,而不是在应用层调度多个具体的实体,聚合持久化不属于聚合能力的范畴,应该作为服务方法,单独被调用。
2. 号称很薄的逻辑编排,真的能薄下来吗?
逻辑编排的问题在于,应用层提供给外围的接口能力,大多数情况下并不仅仅是直接更新领域聚合这么简单,它还需要做很多其他的事情,比如调用下第三方服务、发个消息等。在步骤比较少的情况下,应用层平铺直下(如下图)也无可厚非,但当应用层需要编排更多的步骤时,这样的代码就会越来越复杂臃肿了。
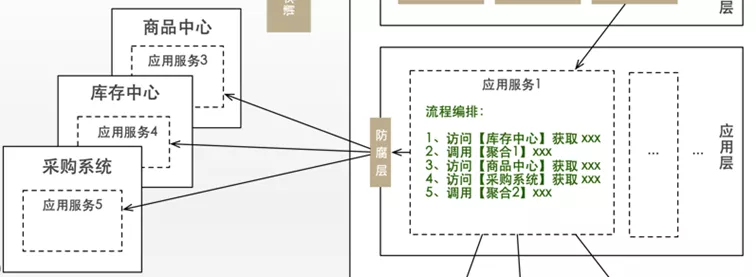
逻辑编排基本上还是事务脚本式的过程式编码,这意味着很容易走回到原本的状态,逻辑会越来越分散,代码会越来越臃肿,为此,我们引入了责任链的设计模式,来对这些逻辑编排进行结构上的优化。
如下图所示,聚合更新、第三方调用、消息发送等,这些都能封装成一个一个的节点,在cmd命令内,将它们串联起来。逻辑结构清晰稳固,而且,还可以做到节点粒度的复用。这里面需要特别提到的一个点是,针对某个命令,领域层的聚合模型更新只会有一个入口,而聚合模型组装、持久化等又是单独的调用。
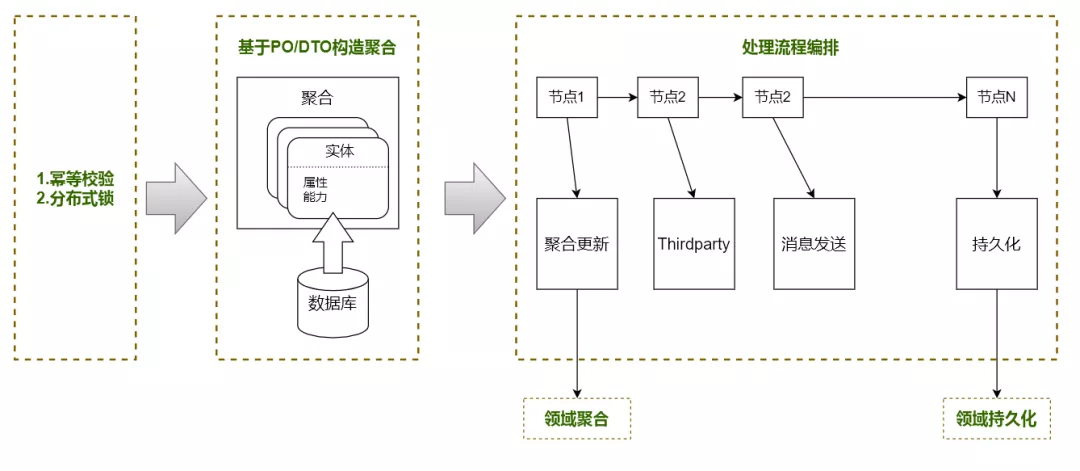
3. 离开权力中心的数据库持久化,该怎么实现?
如前所述,在领域聚合设计中,我们将持久化方法与聚合能力区分开来,让每一个实体不需要独自考虑持久化的问题,这就带来第一个问题,在业务逻辑处理完,怎么才能知道哪一个实体需要持久化?
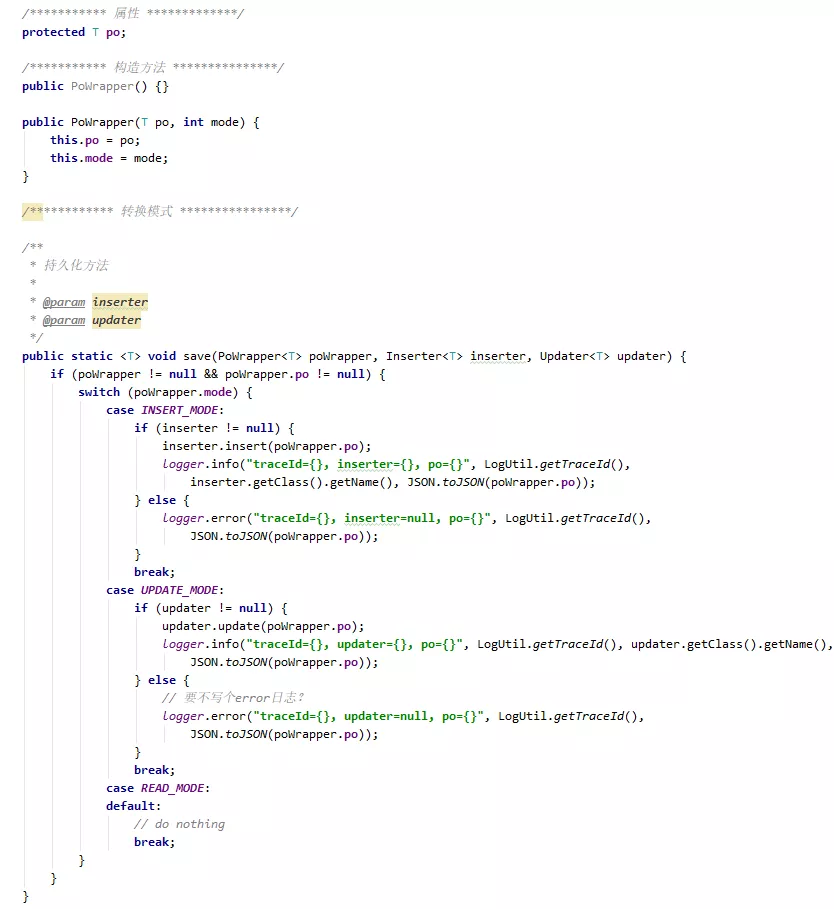
有很多种方式可以考虑,此处我们选择了一个比较简单的解决方案,为每一个实体添加状态标签(mode:read、update、insert)。如下图所示,在进行相应的操作后,我们会更新该实体的状态标签,在最终持久化的过程中,遍历所有实体,根据标签进行相应的处理。
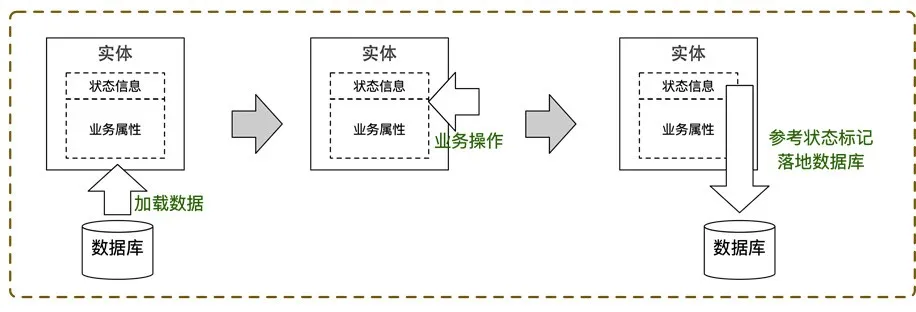
这个时候,会带来持久化的第二个问题,即持久化过程中需要大量的if else代码去判断实体是处于什么状态。
为此,我们引入了一个模板方法,如下图所示,poWrapper内部包含一个po实例,和一个状态标签(等同于实体的状态标签),poWrapper同时定义了一套执行模板,执行模板里包含 insert以及update接口,对于每一个实体来说,要做的事情就很明确了,首先进行do -> poWrpper的转换(包含状态标签),然后poWrapper根据wrapper的状态标签,以及具体的insert/update的实现方法,进行po的更新或插入,这个持久化模板的最大好处是:代码非常简洁,同时隐藏了dao的实现细节。
4. CQRS中的Q,怎样才能简化下实现?
查询应用相对命令应用来说简单一些,但是也正是查询应用,让我们决定打破洋葱架构的依赖关系。洋葱架构依赖关系图如下,假如遵从这种依赖层级,就意味着应用
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BD%91%E6%98%93%E4%B8%A5%E9%80%89%E5%9C%A8%E4%B8%A5%E9%80%89%E4%BE%9B%E5%BA%94%E9%93%BE%E5%A4%8D%E6%9D%82%E4%B8%9A%E5%8A%A1%E7%B3%BB%E7%BB%9F%E7%9A%84%E8%90%BD%E5%9C%B0%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


