网易云音乐大任务优化实践
导读: 最近接了一个大flow优化任务,这个任务是用来做新用户的归属,属于比较重要的任务,但是任务产出时间比较晚,一般要到15点之后才能完成,非常影响数据分析。和这个任务有关联的flow有4个,主flow有67个节点和其他flow加在一起超过了100+节点。
Flow优化过程包括:
- 长时间Job优化
- 关键节点Job优化
- 调度优化
- 队列优化
1 长时间Job优化
遇到优化整个flow的情况,第一个想法肯定是优化其中执行时间最长的任务,下面介绍两个优化明显的例子。
例子1:优化业务逻辑实现方式

看到这俩任务心里一喜

因为这个执行时间太异常了,超过了10个小时,即使数据很大也不太可能单个job需要执行这么久,基本认定是代码写的有问题,找到这俩任务对应的代码,扫了一遍果然发现了问题,简化代码逻辑如下:
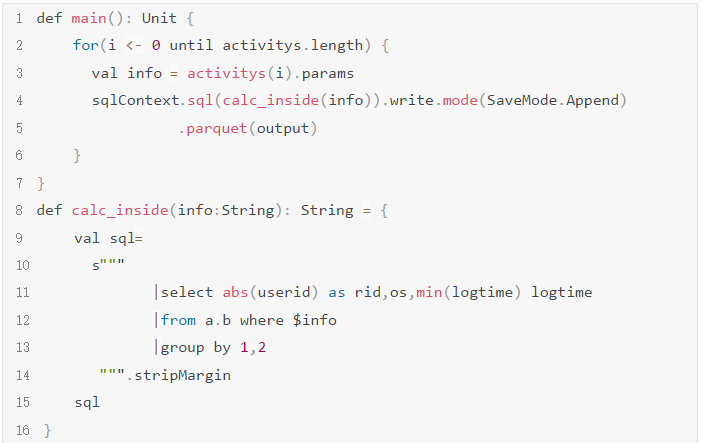
这段代码有两个问题:
- 数据是append到目录中的,如果任务执行到一半失败了,并不会清除目录中写成功的数据,重新回跑任务就会造成数据重复;
- 每次for循环会触发一次spark job执行,所有job是串行的,任务越多执行时间越慢。
针对这两个问题做了如下优化:
每次for循环不触发spark job,而是生成一张TempView 再union all 所有的view表触发一次spark job,这样串行job就变成了并行的stage,而且最终结果可以用overwriter一次性写入到目的路径中。

\\ 例子2:优化分区使用方式**

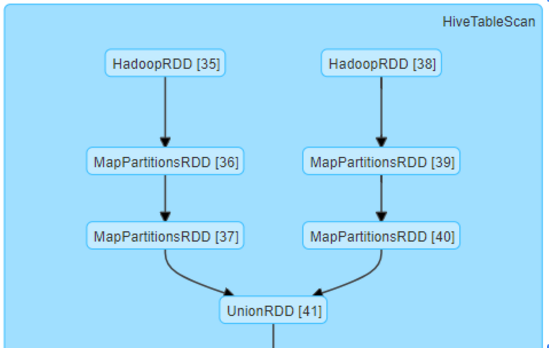
这个任务中有一块逻辑用到了一张超大的分区表,业务只需要读取其中两个分区,简化代码实现如下:

这块代码用了activeclick/adclick两个分区,但是用or做连接,在spark2.3.2 action = ‘a’ or (action = ‘b’ and ${filter})会读取所有分区的数据, 并不是只读 a b两个分区耗时很长。
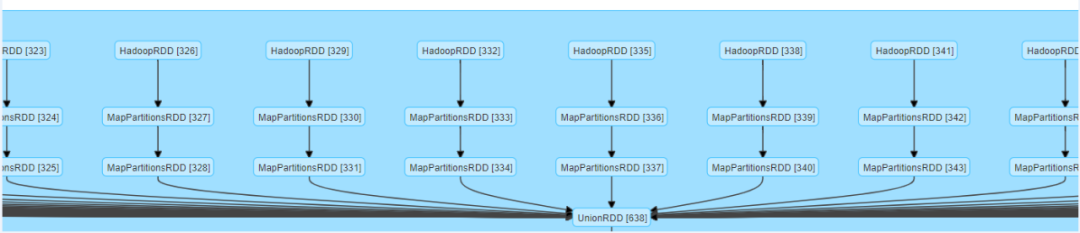
优化代码如下:

2 关键节点Job优化
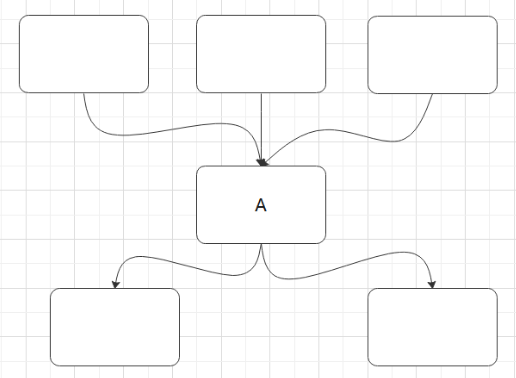
什么是关键节点呢?下图中的A就是关键节点,这里的关键节点不是说任务很重要,而是在flow图的结构中很关键,优化这个节点可以直接提升整个flow的产出时间,关键节点有两个特点:
- 这个任务的结束时间决定下一级任务的开始执行时间;
- 执行时间较长。也就是说有一段时间整个flow只有这一个任务在执行,优化这个任务就能很明显提升整个flow的时间。
在我优化的这个flow里面就有几个关键节点,举一个例子说一说。resource节点在8:20 - 8:53 这个时间点整个Flow只有这一个任务在执行,如果能优化这个任务就能直接提前下一级任务开始时间。

分析任务代码和日志后发现这个任务是有优化点的,这个任务使用了动态分区,数据写入花费了将近1h时间,占了整个任务之间的2/3。然后分析了依赖这个分区表的任务,大部分任务都没用到动态的那个分区,只有一个小任务用到了第二分区,且非必须。所以打算把动态分区取消掉,只保留日期分区。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BD%91%E6%98%93%E4%BA%91%E9%9F%B3%E4%B9%90%E5%A4%A7%E4%BB%BB%E5%8A%A1%E4%BC%98%E5%8C%96%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


