网易云音乐广告预估模型演进过程
作者:Neil 稿
导读:: 本文先介绍了效果广告的基本原理,然后以云音乐广告系统从浅层模型到深度模型的演进为主线,介绍了广告算法团队在算法优化过程中遇到的问题、思考和解决的过程。
广告是云音乐的重要收入来源之一,最近两年云音乐广告平台在深度(机器)学习技术上做了很大的投入,期间也遇到了许多问题,也取得了一些不错的成果。本文将以模型演进为主线,重点介绍遇到的问题、思考和解决问题的过程,希望能为其他同学在类似的算法场景下提供一些参考。
广告系统最典型的机器学习应用场景是广告点击率(CTR)预估,另外在广告主需要考核成本的时候还会用到转化率(CVR)预估,其中也有大量的深度学习实践,考虑到篇幅,本文聚焦在CTR预估,以后再单独介绍CVR的相关实践。
1 云音乐广告系统的特点
广告作为互联网的主要商业模式之一,是各大互联网公司的重要业务。云音乐广告平台是国内第一个专注于基于音频流量变现的广告平台,有一些自己的特点,比如:
- MAU过亿,人均每日时长在音乐类APP排名第一;
- 用户“听”的时间远多于“看”的时间,而广告需要“看”;
- 用户比较挑剔,对广告容忍度较低;
- 场景中有音乐偏好特点,如喜欢摇滚,或少儿,英文歌曲等。
这些基本特点决定了算法模型的选择、优化等基本面,后续会穿插着提到。
2 广告系统为什么需要CTR预估
1. 广告主和媒体的博弈问题
我前面提到广告点击率(CTR)预估是典型的机器学习应用场景,但为什么需要CTR预估呢,为了解释清楚这个问题,需要先了解效果广告的机制。效果广告要的是直接转化率,这一点跟品牌广告不同,品牌广告主要打品牌知名度,比如汽车广告,房产广告等,广告主不指望用户看完这个广告之后立刻去买一辆车子或者房子,而是先让用户熟悉这个品牌。而效果广告则希望用户看完广告之后立刻去成交,例如淘宝上的商品搜索广告,百度搜索广告等,都以转化为目的。效果广告的主要博弈方是广告主和媒体方,扩展一下也包含了广告平台、用户等参与方,但为了简化问题我们只考虑最主要的部分,双方的利益如下图所示。
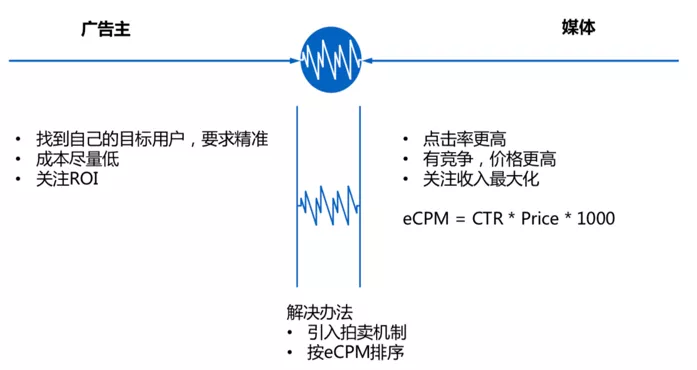
广告主最关注ROI,希望用最低的成本拿到自己的目标用户,底线是不能长期做亏本生意。媒体方则希望提高点击率(按点击率计费时,点击越多收入越多)、通过竞争提升单次点击价格,关注的是流量变现价值的最大化。这两方的诉求目标是矛盾的,解决办法是引入经济学的拍卖机制,然后用计算机程序来实现自动竞价,把经济学和计算机科学结合起来解决这个博弈问题,下面详细介绍一下。
2. GFP vs GSP
大家应该在电视里面看过拍卖的场景,比如拍卖某个古董时,从低价开始喊,然后不断加价,直到没人再加为止,这时候锤子一敲就成交了,这个模式叫做英式拍卖,这种公开叫价的形式叫明拍。还有一种叫暗拍,情况类似于每个竞买人把自己的价格写好,等全部交上去后按价格的高低排序,价格最高者得。如果是第一价格模式则按第一价格支付,按第二价格模式则出价最高的人按照第二名的价格支付。

GFP(Generalized First Price)广义第一价格模式
早期的互联网产品,比如Yahoo和MSN采用的是GFP,广告主针对某个关键词出价,价高者得且按自己的出价支付。早期百度的竞价排名也是类似的规则。但这种模式最大的问题是系统收入非常不稳定,竞买人需要频繁修改出价以拿到流量或者希望以更低的价格拿到流量。
GSP(Generalized Second Price)
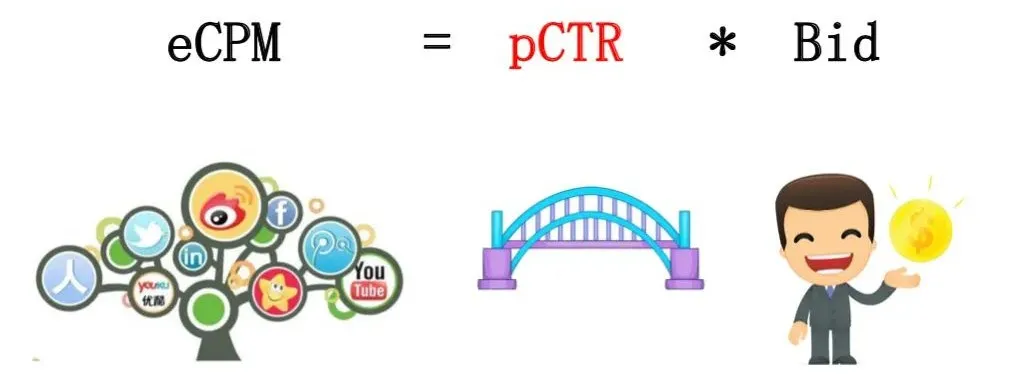
2002年Google在Adwords业务中采用了GSP机制,即出价最高者按照第二名的出价来支付。GSP模式由于看不到其他人的出价,可以鼓励广告主按照自己认为的真实价值来出价,鼓励“讲真话”。并且排序时还引入了质量得分,通常是pCTR,即预估的广告点击率,然后按照Price * pCTR排序,这样可以惩罚广告质量差的广告。用Bid来表示出价,则按eCPM排序的规则为:eCPM = Bid * pCTR * 1000 。
由于在竞拍的过程中,不可能所有参与竞买的广告都能得到曝光,并且不同的人对于不同的广告点击率也不一样,所以CTR不能使用历史统计值,而且即使有历史统计值也解决不了新广告的问题,因此CTR只能预估,但如何预估呢?
3. 经济学+机器学习
机器学习为CTR预估找到了一个解决方案:利用机器学习的回归技术来预测点击概率。
可以用一个公式来表示,点击概率 p = f(user features, context features, ad features)
这样一来,就比较完美地平衡了广告主和媒体方的利益:
- 精准投放保障广告主的ROI;
- 拍卖机制保障媒体方流量价值的最大化;
- 在这过程中,CTR预估扮演着非常关键的桥梁作用。
3 浅层学习CTR预估模型优化
业界早期阶段,在2012年以前,几乎主流公司都使用LR模型来预估CTR。LR有很多优点,比如简单、易于并行化、可解释性强。比较适合处理广告场景高维、稀疏的数据。
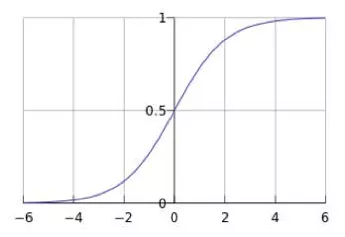
(利用sigmoid函数映射点击概率)
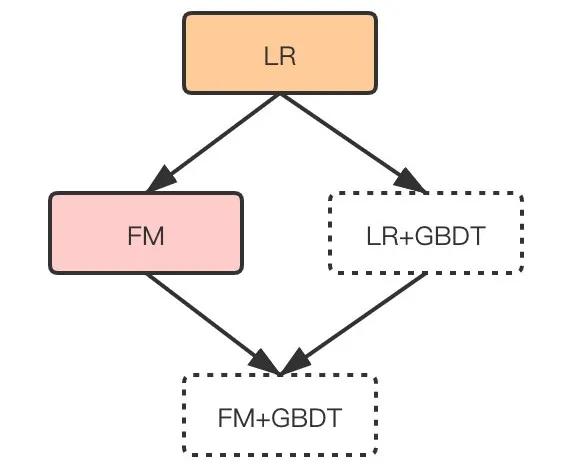
云音乐广告系统最初采用的是LR模型,至今也还作为基线在跑着。后来尝试了FM,以及LR+GBDT,FM+GBDT,如下图:
LR模型阶段打下了很多基础,做了很多数据和特征工程的事情,避免Garbage in, garbage out,争取达到效果的上限。
1. 数据采样
(1)样本正确选取问题
最开始,各个广告位的历史数据是放在一起训练的,最终训练出一个模型。启动画也包含其中,并且数据量占了很大比例,但启动画有一个很大的问题,就是误点率很高,误点数据基本上是随机分布,没办法体现出用户的真实意图,很多数据都是噪声,严重影响模型的准确性。因此需要去除不能真实反应用户意图的场景数据。
另外,最初的版本iOS和Android双端数据也是放在一起训练的,但通过一段时间的运行发现,双端的广告主数据几乎完全不一样,基本上可以看做是两个数据集,并且在同样的广告位,其CTR和CVR的表现也有显著差异。所以需要拆分不同的数据分布。
因此,对于训练样本的选择来说,我们把开机画数据拆了出去,同时iOS和Android分端训练,这样一来,模型效果得到了大幅提升。
AB实验中,iOS端eCPM提升了11.12%,Android端eCPM提升了10.50%,全流量后效果表现一致。
(2)样本不平衡问题
在我们的CTR场景,尤其是CVR场景,正负样本比例相差非常大。CTR正负样本比例大约从1:1000至1:100,CVR从曝光到转化则是1:10000,甚至更低。在模型的训练过程中,正样本变成了小概率事件,很容易被模型当作噪声而忽略了。
我们在CTR模型中,把正样本上采样了10倍,效果上Android端AUC提升1.02%,iOS端AUC提升0.75% 。
对CVR模型(深度模型)的训练数据,我们对负样本降采样10倍,AUC提升了1.06%,线上效果也表现显著。
(3)其它的样本问题
- 我们找到并去除了很多异常数据。比如点击时间在曝光时间之前。
- 处理了延迟回滚的激活数据。有些激活数据延迟很严重,有半天甚至几天的时间,CVR的正样本本来就少,所以我们通过扩大匹配时间窗口等手段,尽量不错过对正样本的处理。
- Review打点是否存在Bug等。
经过优化,离线AUC提高了1.4%, eCPM相对基线提高了3.73% 。
2. 特征组合
我们有一个CASE分析工具,可以分析不同权重对结果的影响程度。我们发现模型并没有学出用户侧与广告侧的匹配关系,主要依靠单特征在影响pCTR打分。尽管做了一些人工特征组合,比如广告主+年龄,但由于太稀疏没有学出来。很自然我们想用FM模型来尝试一下自动特征组合。
(1)尝试FM
FM引入了隐向量,为每一个特征学习一个隐权重向量。在做特征交叉时,使用两个特征隐向量的内积作为交叉特征的权重。与直接特征组合(用POLY2模型的方式)需要该组合的所有特征同时存在才更新参数不同,对训练数据中没有出现的组合FM也能够学到。
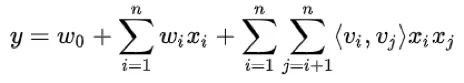
举例来说:用直接特征组合时,只有当广告主为“潭州教育”且“用户年龄为20岁”时才会更新该组合特征的参数(否则其中一个为0,则相乘后也为0),但这种组合太稀疏,基本上训练不充分。
FM由于使用两个特征向量的内积来表示权重,比如广告主(潭州教育)的特征向量为v_i,年龄为20岁的特征向量为v_j,权重w=向量积<v_i,v_j>,只要出现了广告主(潭州教育)或年龄为20岁的样本,都可以共享更新相应的特征向量。解决了稀疏特征组合的问题。FM的不足是只有二阶特征组合,非线性表达能力依然不足。
效果:线下AUC提升0.75%,但线上效果不稳定,因此只做了小流量上线,不符合全流量的标准。
我们推断了效果不理想的原因:一是我们的特征中,连续特征很多,将其离散化取决于经验,因此即使做了二阶交叉,解决的可能不是关键问题;第二,云音乐的广告推荐场景属于弱个性化推荐场景。相对来说云音乐的歌曲推荐属于强个性化推荐,淘宝的商品推荐也属于强个性化推荐,不仅拥有足够的样本数据做训练,每个人的偏好也相对更明显。而个人对广告的喜爱与否并不是那么明显(有时候说喜欢广告,不如说不那么讨厌的广告)。在这种场景下,二阶特征组合的记忆力并不算太好,基于这种推断,我们自然开始尝试GBDT。
(2)尝试GBDT
GBDT的引入带来了如下优点:
- GBDT在处理连续特征方面有着天然的优势,它基于树模型对连续特征能做到比较优化的切分,也避免了人工凭经验做切分。
- GBDT每个样本最终落在了每一颗子树叶子上的0/1矩阵,即特征向量,对特征做了深层交叉。可以理解为对样本进行了降维、聚类操作,提取了有效的信息,提供了更好的记忆力。
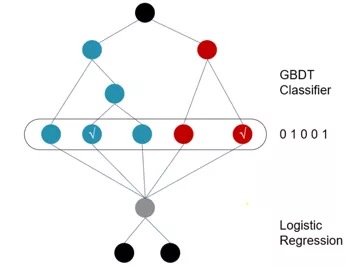
LR+GBDT模型相比基线LR模型,AUC绝对值提升1.03%,相对提升1.71%,效果非常显著。线上CTR和eCPM提升稳定,符合全流量标准。
之后我们又尝试了FM+GBDT,但效果不如LR+GBDT。浅层学习阶段,最终LR+GBDT胜出,成为了效果最好的模型。我们的推测原因是:弱个性化场景下需要有深度记忆功能。LR处理了稀疏特征记忆能力,GBDT处理好了深度组合特征以及连续特征的记忆能力,这正是我们音频流量广告场景(结合我们的广告主特点)所适合的。我们这个思路会持续到深度学习阶段。
比如喜欢听儿童歌曲的用户,年龄可能在25岁以上,并且可能喜欢购买化妆品,可能是年轻的妈妈们。喜欢听英文歌曲的用户,也许是爱好英文歌曲,也许正在锻炼自己的听力,喜欢点击英语培训广告,需要多种特征组合起来才能更精确。
4 人类行为可预测的认知 – 个人理论总结
人类行为有93%是可预测的,这是美国东北大学科学家的一项研究结论。我认为这一基本原则是很多优化工作的指导基础。
1. 个体人格相对稳定,才能用历史预测未来
人类行为可预测是因为人格的相对稳定性,人格包含性格、气质、能力、兴趣、爱好等成分,是由先天的遗传和后天的环境因素共同决定的。招聘面试也是采用了这个原理。
2. 人类具有共同的行为模式,可以用群体预测个体
由此原理引出了协同过滤算法,即利用某种共同兴趣或共同经历的群体行为来预测个体的行为。比如大多数读过笑傲江湖和神雕侠侣的人,都读过倚天屠龙记,假如有某个人读了笑傲江湖和神雕侠侣,我们可以推断他很大概率会喜欢倚天屠龙记。
做算法上的任何优化,都应该遵循这两个基本原则。
5 深度模型演进和优化
深度模型的引入,一方面是由于业界已经有很多公司成功把深度学习应用到了CTR预估,并取得了效果;其实更重要的原因是延续LR+GBDT的优化思路,需要持续做,上面提到了用LR处理稀疏特征记忆,用GBDT处理深度组合特征和连续特征记忆,自然会想到Wide&Deep模型,即使用Wide的记忆能力,以及Deep的泛化能力。我们从Wide&Deep切入深度学习,并且做了很多尝试。如图:
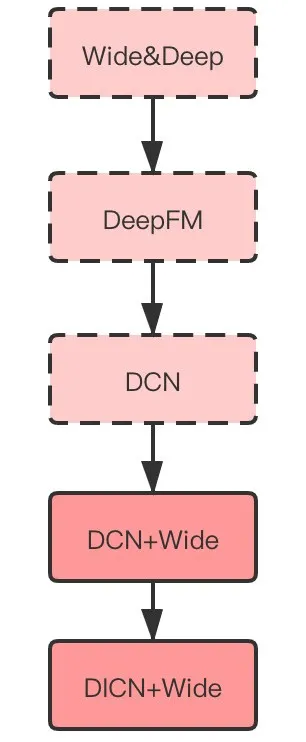
Wide&Deep、DeepFM、DCN都没有全流量,第一个全流量的深度模型是DCN+Wide,目前(2020年10月)正在跑的是DICN+Wide。下面介绍一下这些模型的特点和问题,以及做的优化工作。
1. Wide&Deep
在讲Wide&Deep之前,我先讲一下业界早期尝试将深度学习应用于广告CTR预估的情况。业界早期的时候,使用的是纯DNN模型(MLP),但无论怎么优化都很难超越LR+GBDT,主要原因是广告场景有大量的长尾稀疏数据,DNN采用Embedding的方式训练不出来,后来尝试了很多方法把DNN和LR以及其它浅层模型融合起来,融合之后的效果才超过了LR,比如采用LR训练后的权重参数,或者进一步将FM的隐向量作为Embedding输入等。Wide&Deep就是在这种情况下作为一种融合方案之一,由Google在2016年发布出来的。
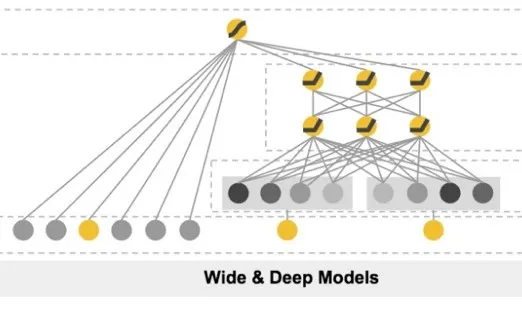
W&D通过将浅层模型和深层模型联合训练,融合了浅层模型的记忆能力和深层模型的泛化能力。通过Wide侧较好地解决了长尾数据的拟合,弥补了纯DNN的不足。
不过理论归理论,有没有效果还要看实际场景,我们最开始W&D的效果始终没有赶上LR,后来做了一些特征优化,比如连续特征同时做离散化处理,用全连接代替Wide和Deep融合时直接相加,最后的效果只是与LR模型打平。
我们根据浅层学习时的经验,认为是Deep侧对特征交叉训练不够,纯DNN模型只是隐性交叉,并且是稀疏的场景,隐性交叉需要足够的样本和足够多的训练时间。因此后续的思路是需要在Deep侧做特征交叉方面的尝试。
由于是第一个深度模型,也让我们体会到了,并不是所有深度模型的效果都会优于浅层模型,尤其是做过良好特征工程的LR模型。
2. DeepFM
本来顺着上面的思路应该优化Deep侧,但由于根据以往的经验,DeepFM模型的效果可能还不错,我们还尝试了DeepFM模型。
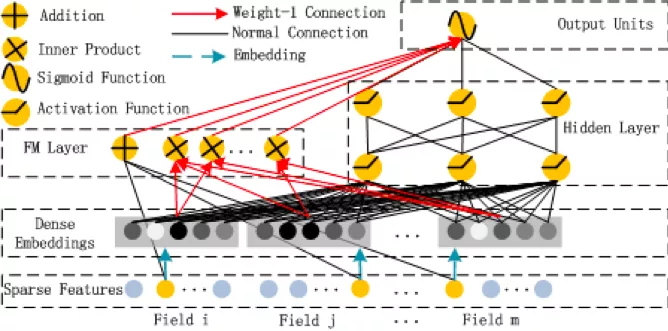
优化了特征、正则项、模型层数和embedding size等调优,最终效果与基线LR的AUC相差千分位,依然不好,与浅层模型时单独尝试FM的效果表现一致,这坚定了我们往优化Deep侧的方向去尝试。
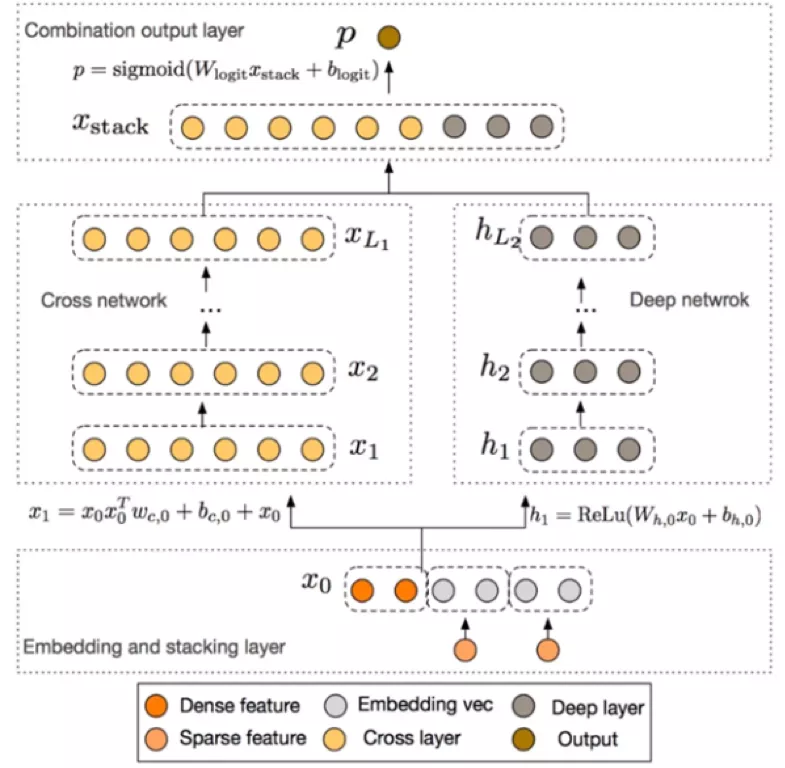
3. DCN
DCN的引入主要是为了解决纯DNN没有特征显式交叉的问题,它在Wide&Deep的基础上,把Wide侧改成了Cross Network,示意如下:
该模型的核心是Cross Network,设计用来高效地进行特征交叉,公式如下:
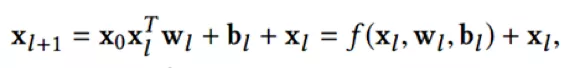
xl表示第l层的cross layer输出,wl是参数,bl是偏置,都是列向量。其实是应用了残差网络的思想,如下图所示:
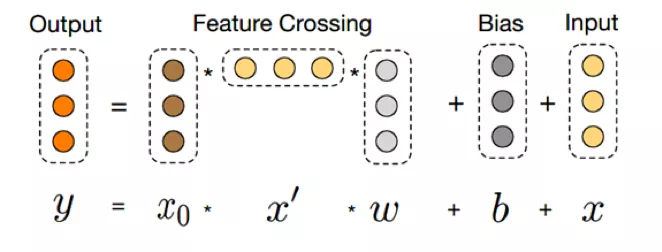
这样模型就能够高效地学习到高阶的非线性特征组合了。DCN的效果:离线AUC比LR高0.69%,线上eCPM提升幅度稳定达到3%,达到了上线标准。
我们观察到的现象是当特征显性高阶交叉时效果就会更好,与LR采用GBDT组合特征时效果会更好的表现是一致的。应该是挖掘出了音乐场景下深层次的关系。后来我们还在DCN上面引入了Attention机制,也取得了一定的效果。
4. DCIN+Wide
顺着前面的优化思路,DCN已经解决了特征深度交叉,以及泛化的功能,DIN解决了用户短期兴趣问题,这些解决的都是头部数据的问题,这些数据有一定的量来训练,而广告场景的长尾数据问题依然没有解决。因此我们很自然地把Wide侧增加了进去,模型示意图如下:
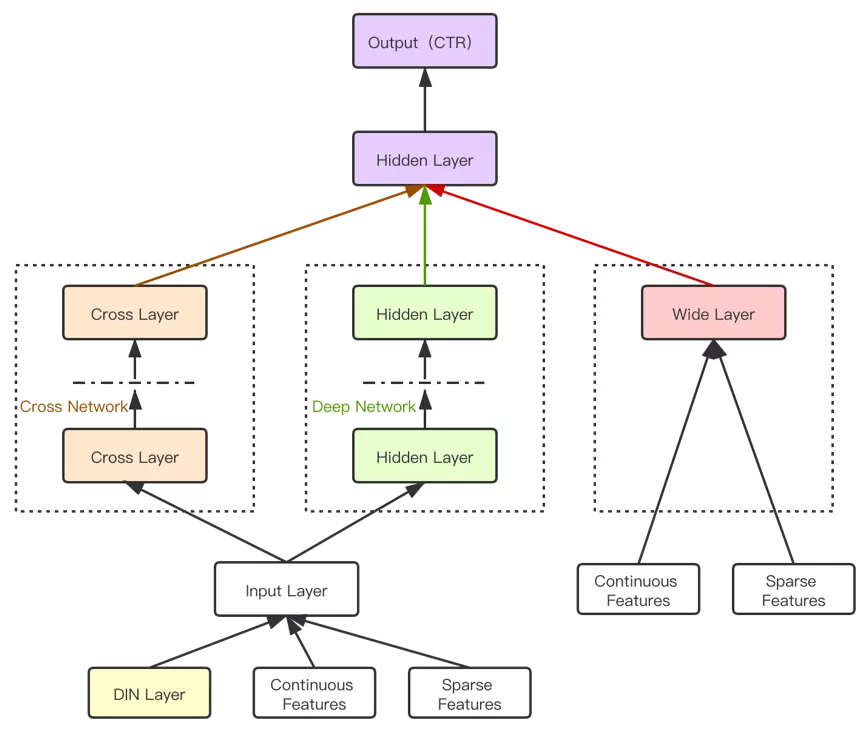
Wide的加入,使得长尾数据的记忆能力得到了一定的加强,线下AUC和线上效果都有一定的提升,虽然提升量不算太大,但为人工特征工程提供了可能。这是我们现在的线上模型(2020年10月)。
下面介绍一些我们对深度模型做的优化点。
5. 激活函数的优化
在优化DeepFM的过程中,最初Deep模型的隐藏层激活函数用的是ReLU,但我们发现Deep侧不起作用,进一步发现隐藏层的很多输出为0。
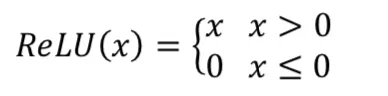
从ReLU函数的定义可以知道,负梯度时该ReLU单元会被置为0,这是它单侧抑制的能力。但由于我们的数据特点,ReLU的这个特点变成了局限,在训练过程中导致大量神经元不可逆死亡,进而使大量参数无法更新,从而训练过程失败。
后来我们把激活函数换成了PReLU,公式如下:
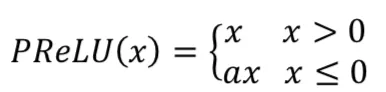
当x小于0时,用了一个很小的正数a实现一个斜率为a的线性函数ax,这样既实现了单侧抑制功能,又不至于导致大量神经元不可逆死亡。a可以作为网络中的参数通过训练更新。当a=0时,PReLU退化成ReLU;如果a是一个固定值,则PReLU退化成Leaky ReLU(LReLU)。BP更新a时,采用的是带动量的更新方式:
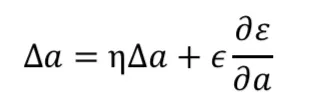
ReLU和PreLU的函数曲线图对比如下:
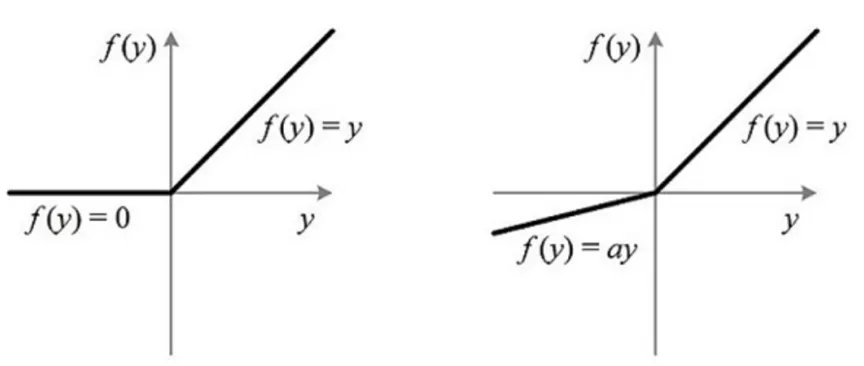
采用PReLU作为激活函数之后,解决了神经元死亡的问题,AUC提升了千分之五。
6. 递减学习率和Batch size的优化
我们使用adam优化器,学习率初始值设置为 a,之后每n步降低0.96,AUC提升了千分之二。我们的Batch size设置为10000,比起很多公司的CTR场景设置来说偏大,主要是由于我们很多场景的CTR是千分位,需要考虑每个batch里有一定数据的正样本。
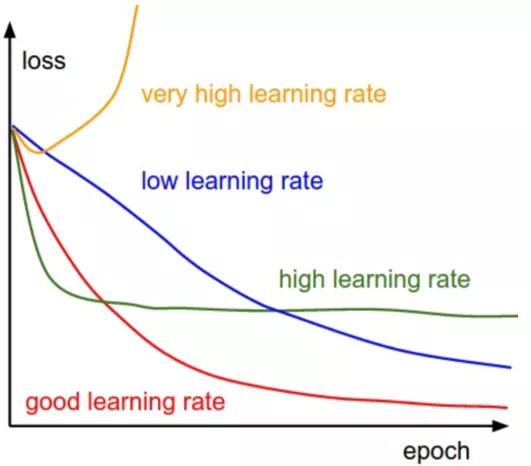
从上图看到,太高的学习率会导致不收敛或者震荡,太低的学习率则收敛速度太慢,递降的学习率一开始比较大可以让模型快速收敛,后面逐步减少则可以精确收敛。
7. 缺失值处理
由于我们的数据稀疏,很多属性和特征的覆盖率不高,经常会存在样本中域缺失的情况。我们给缺失的域�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BD%91%E6%98%93%E4%BA%91%E9%9F%B3%E4%B9%90%E5%B9%BF%E5%91%8A%E9%A2%84%E4%BC%B0%E6%A8%A1%E5%9E%8B%E6%BC%94%E8%BF%9B%E8%BF%87%E7%A8%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


