网易云音乐数仓治理之数据任务重构实践
作者简介:冷面,网易云音乐资深数据开发工程师,长期从事大数据开发,数仓建设、模型设计、数据治理、数据应用和服务等工作。目前主要负责云音乐离线数仓建设、会员业务线上数据服务、离线/实时ABTEST系统开发。
导读: 云音乐数仓在经历了前期混沌摸索,中期建设完善,如今已逐步形成了一套适合自己的数仓体系和建设规范。增量模型及任务全部走线上设计评审流程,但仍有大量历史任务“年久失修”等待治理。本文以重构会员自动化运营模型为例,分享下数据任务重构实践。
1 背景
云音乐会员自动化运营,通过对人群、资源位、投放规则等配置打包形成不同的投放策略,完成站内资源整合。针对不同用户不同行为不同位置推送不同资源内容,精准投放,加强转化,提高会员渗透率,提高会员续费率。

(自动化运营策略)
运营效果的评估,依赖大量数据指标在不同分析维度的表现。数据指标如投放PV/UV、触点曝光PV/UV、触点点击PV/UV、收银台曝光PV/UV、SKU点击PV/UV、购买人数、订单数,以及各阶段的漏斗转化数据等;分析维度如投放策略、投放资源、投放位置、投放人群、用户OS、SKU类型等等。
(自动化运营指标分析)
2 问题
早期数仓建设缺乏方法论指导,更多是烟囱式开发,没有分层,没有主题域,没有规范。需求驱动,模型设计复用性考虑不足,所有表产出自一个任务流,耦合严重,在稳定性和可用性方面存在不少问题。
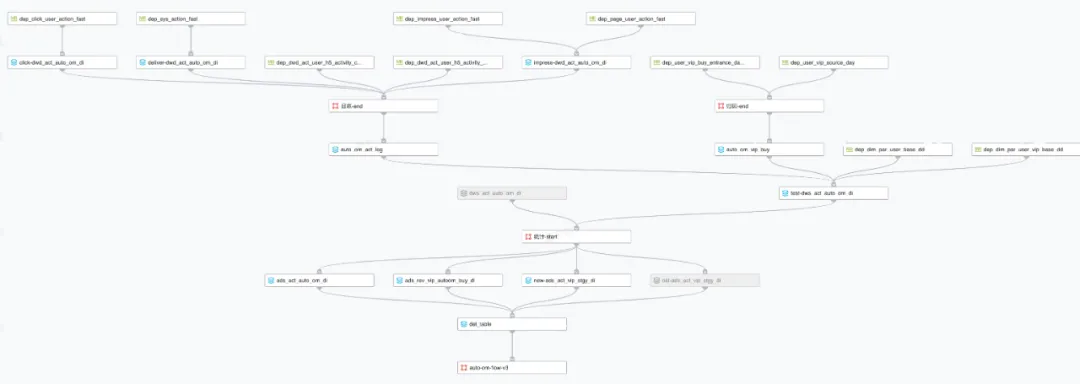
(auto-om-flow)
3 重构
本次重构以对业务影响最小,尽量做到下游无感知为原则,从规范、效率、质量方面着手,进行任务治理。
3.1 规范
模型设计:遵循高内聚低耦合的原则,划分合适的业务主题域,给出清晰的表分层。建表、字段遵循数仓通用规范。
主题域:云音乐-事实-交易营收。
表分层:dwd用户行为明细层、dws原子指标轻度聚合层、ads业务场景指标高度汇总层。
-
dwd
music_new_dm.dwd_act_auto_om_di
-
dws
music_new_dm.dws_act_auto_om_di
-
ads
music_new_dm.ads_act_auto_om_di
music_new_dm.ads_rev_vip_autoom_buy_di
music_new_dm.ads_act_vip_stgy_di
任务解耦:一个任务流产出一张正式表,任务名即表名,任务按业务归属、表分层部署在对应网易有数大数据平台目录下。
任务节点:
- 开始节点:任务入口,虚拟节点,建议命名:start。
- 结束节点:任务终点,虚拟节点,有数大数据平台默认以任务名为结束节点。
- 说明节点:任务注释文档说明用,有数大数据平台无文档节点,建议使用SQL节点注释语法实现,命名readme。
- 依赖节点:表依赖节点,MR节点,以while循环check表数据文件时间戳形式检测表是否ready。建议命名:dep-表名[-分区名]
- 计算节点:临时表或正式表产出节点,SQL节点。建议命名:[insert-]表名[-分区名]
- 依赖配置:有数大数据平台支持线上模式编辑调度配置任务依赖、节点依赖,任务或节点需同属于有数大数据平台任务,暂不支持配置Pandora任务依赖。也可使用任务内MR节点方式配置依赖。两种方式各有优劣,按需配置,不做要求。
- 临时表:任务逻辑较为复杂或需要复用中间结果时,考虑使用临时表或视图表。因磁盘读写速度远低于内存读写,故应多使用内存表,尽量减少临时表落盘。但是,当不得不做一件有代价的事情的时候,应考虑最大化利用其价值。
操作建议:
- 数据量较小时,建议使用view或with as语法组织代码,提高可读性,减少磁盘io;
- 数据量较大时,建议落实体表到临时库,设置生命周期定时清理,既提高数据复用,又方便出错时异常排查,当下游修改逻辑时又可降低数据回跑成本;
- 考虑语法标准及查询引擎的支持度,不建议使用temporary table/temporary view等语法建临时表、临时视图;
- 考虑表元数据稳定及查询便利性,建议任务上线即固定临时表命名,使用动态日期分区而非动态表名区分每天数据。
开发测试:有数大数据平台任务支持开发模式、线上模式,所有任务节点需在开发模式测试通过后才可提交上线。
上线审核:圈选任务提交上线,走工单审批,需业务负责人check通过后可通过上线。
调度配置:任务上线调度需配置调度参数,调度周期,调度时间,任务依赖,执行队列,并发设置等,详见数仓通用规范。
报警配置:任务上线默认配置负责人接收失败报警。按需配置报警对象(任务、节点),触发规则(失败、延迟),报警接收(负责人、报警组),报警方式(邮件、短信、电话、popo),循环报警等。
以下五张为详细任务解耦图:
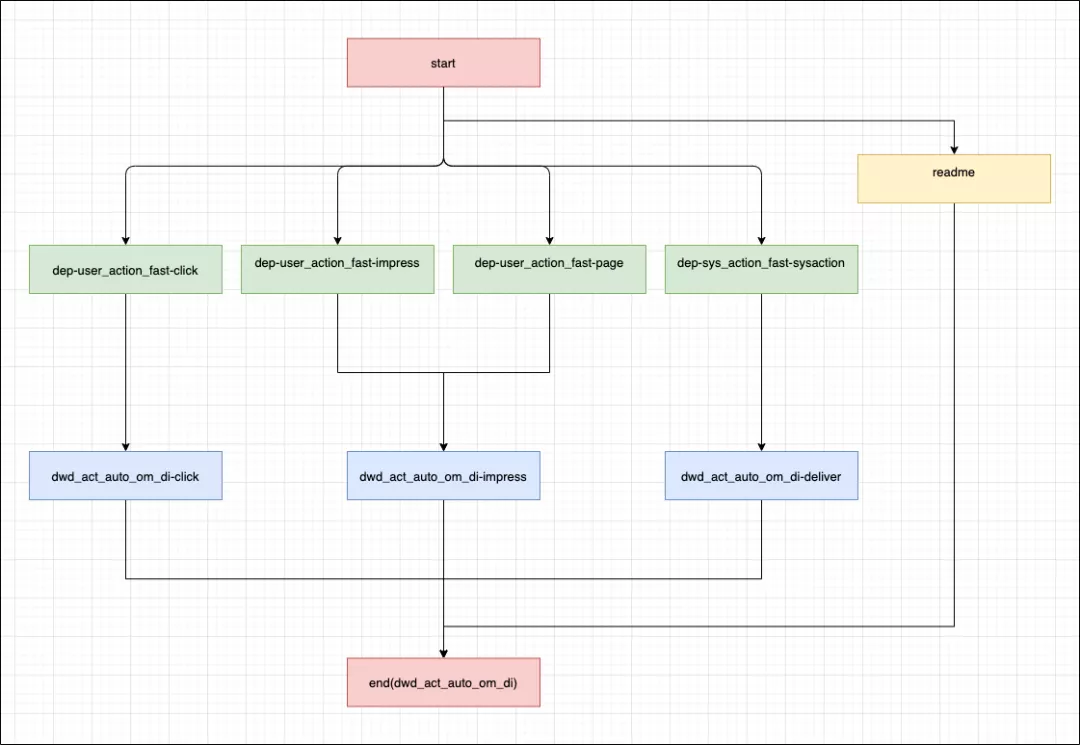
(dwd_act_auto_om_di)
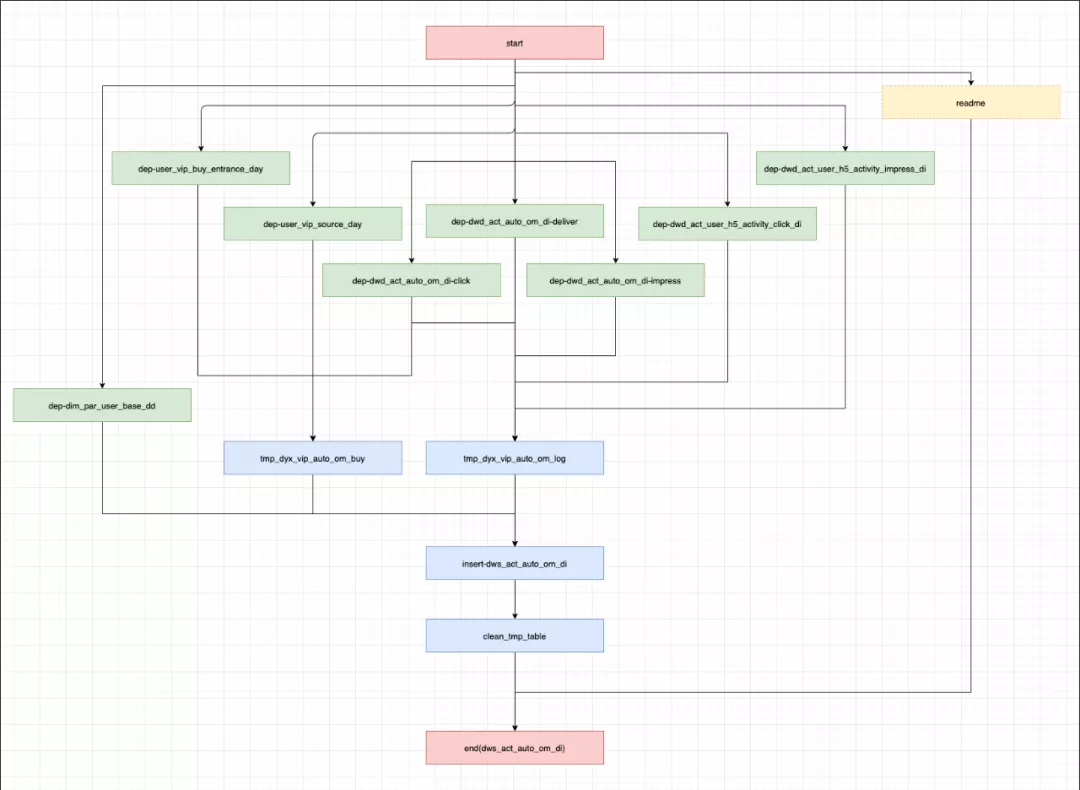
(dws_act_auto_om_di)
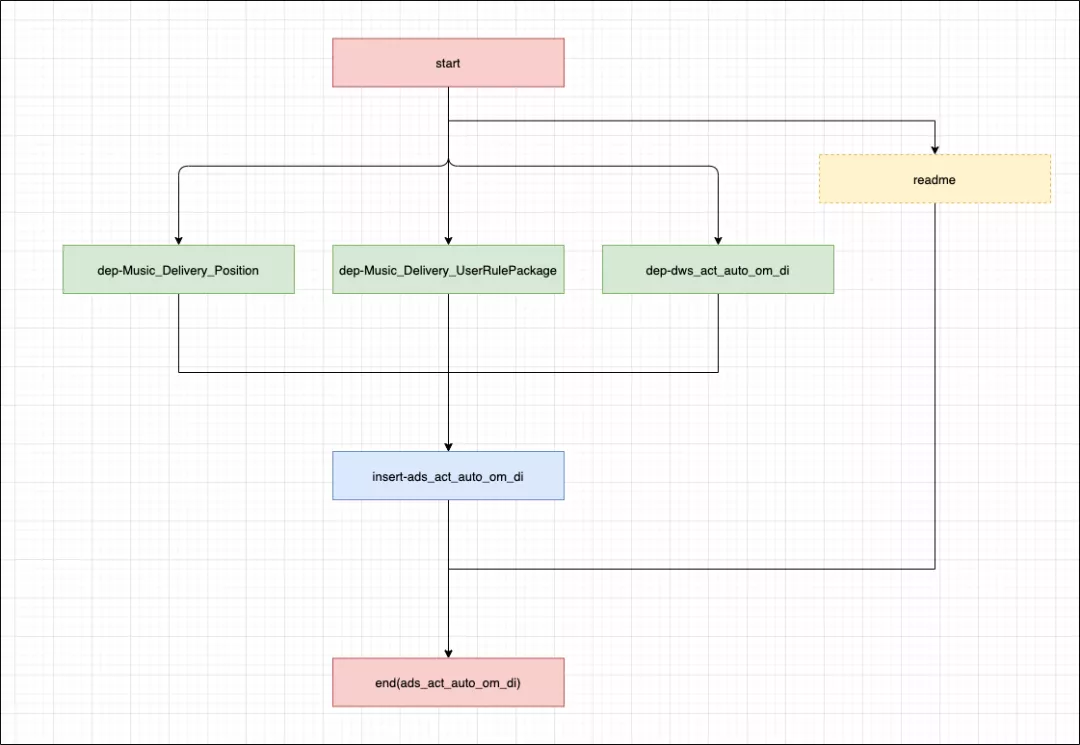
(ads_act_auto_om_di)
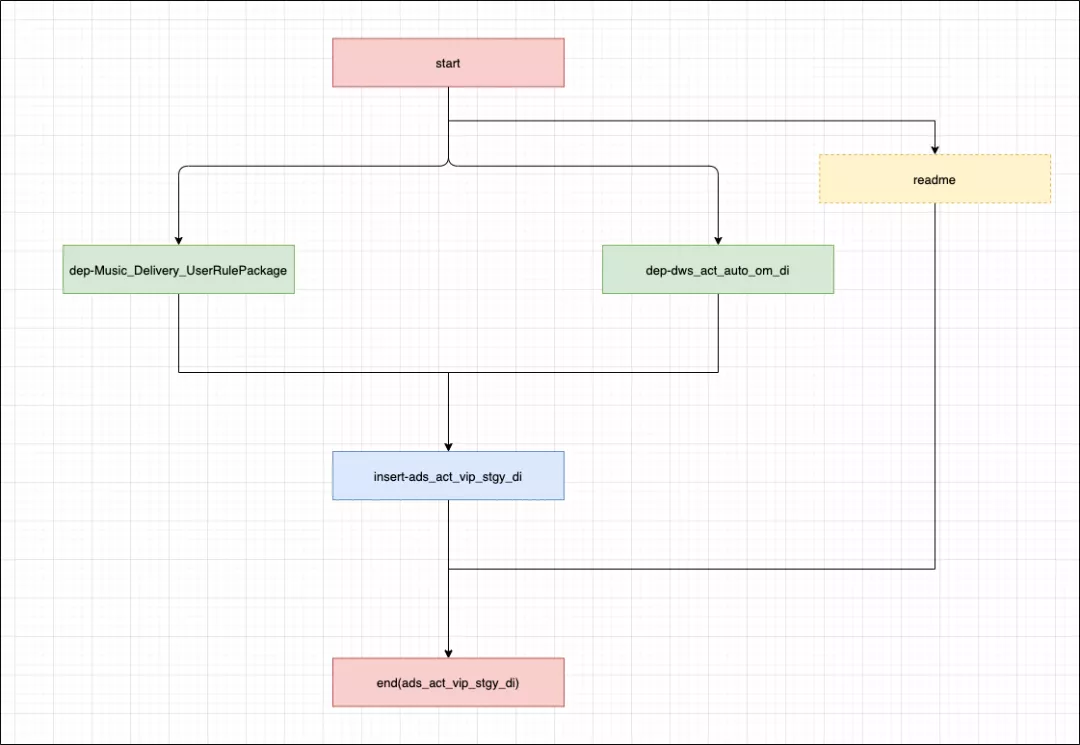
(ads_act_vip_stgy_di)
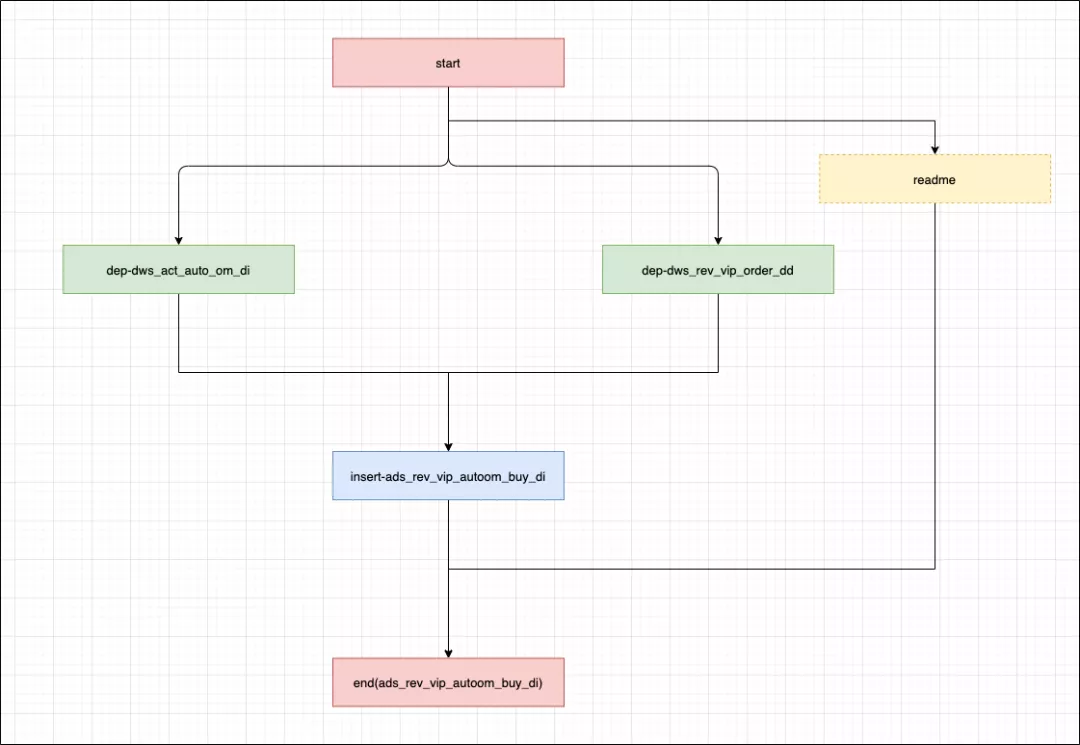
(ads_rev_vip_autoom_buy_di)
3.2 效率
执行引擎:原workflow仍有大量任务使用hive执行,本次全部迁移spark。
性能优化:分析输入输出数据量级,业务计算逻辑,CPU/内存等资源参数调节,达到性能优化目的。
Spark调优:
- 开启动态资源分配 dynamicAllocation
- cpu/内存配比建议同集群总资源配比,最大化利用集群资源
- 开启broadcastjoin,有数大数据平台环境默认关闭(内存限制),spark官方建议开启,可极大提高join小表性能
- 调节parallelism和repartition参数,提高并行度
- 开启convertMetastoreParquet,充分利用spark读parquet性能
- lateral view explode优化,多次explode前,手动触发shuffle操作,减少单分区处理数据量大小
- 控制输出文件大小,减少小文件数,减轻nn压力
- 充分利用spark3 AQE优化
性能提升:单节点执行效率提升5倍,整体产出时间提前3小时,存储空间占用降低80%,文件数占用降低90%。

(重构前后对比)
dwd_act_auto_om_di 存储及文件数降低。
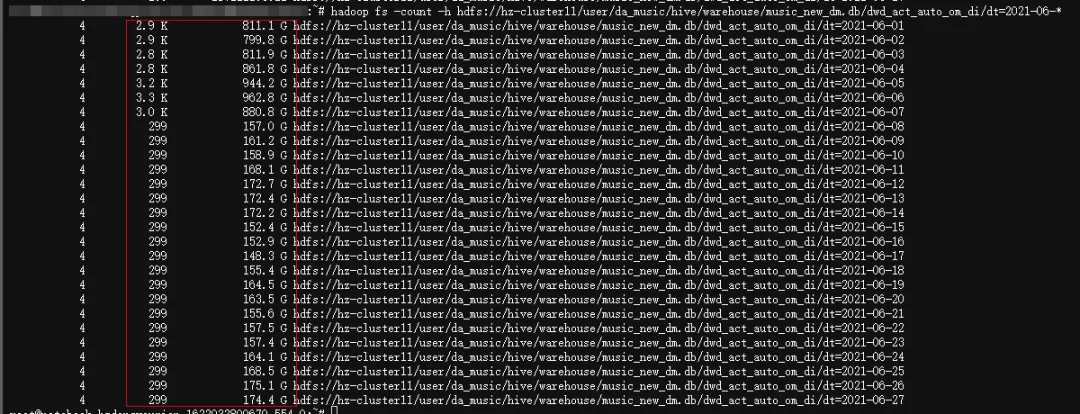
(存储及文件数降低)
ads_act_auto_om_di表提高并行度及explode优化以提高执行效率缩短时长示例。
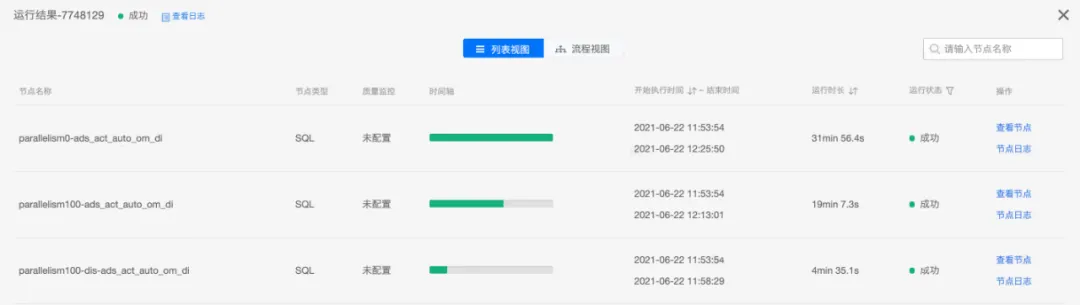
(优化计算示例)
ads_act_vip_stgy_di表执行时长由60分钟缩短至10分钟,产出时间由11点提前至9点。
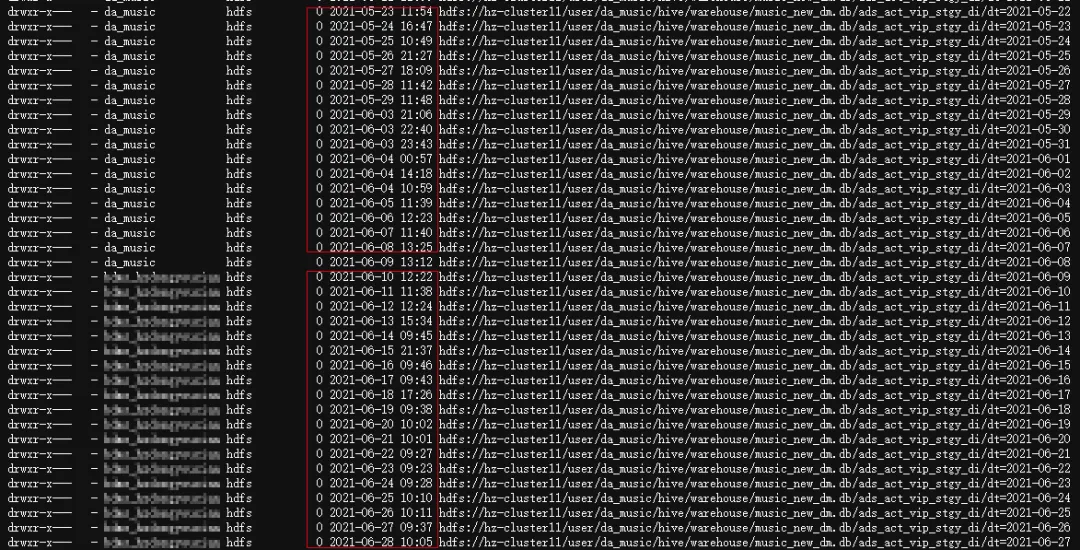
(产出时间提前)
3.3 质量
数据校验:重构应保证数据准确性、一致性,对重构前后产出数据做一定的规则校验。如count、count distinct、NULL值、枚举值范围、数值型分布、最大最小值比较等。
-- 分区前缀代表不同优化策略
select dt,
count(1) as c,
count(distinct os) as c_os,
count(distinct positionid) as c_pos,
sum(vipbuy_amt) as s_amt,
ma
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BD%91%E6%98%93%E4%BA%91%E9%9F%B3%E4%B9%90%E6%95%B0%E4%BB%93%E6%B2%BB%E7%90%86%E4%B9%8B%E6%95%B0%E6%8D%AE%E4%BB%BB%E5%8A%A1%E9%87%8D%E6%9E%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


