网易大数据用户画像实践

分享嘉宾:张长江 网易 大数据技术专家
编辑整理:黄乐平
出品平台:DataFunTalk
导读: 网易大数据生态数量级巨大,且产品线丰富,覆盖用户娱乐、电商、教育等领域,并且APP 活跃度高,积累了多维度的用户行为数据。通过集团数据资产构建全域用户画像,旨在服务于域内众多业务场景,同时也在探索外部商业化方案。今天借此机会,同大家分享下网易在大数据用户画像中的实战应用经验。
今天的介绍会围绕下面三点展开:
- 网易生态数据介绍
- 用户画像中心分类
- 网易用户画像实战案例
01 网易生态数据介绍
整个用户画像实践经验,都依赖于网易易数中台,所以首先给大家介绍下网易生态数据情况。
1. 网易数据总览

网易数据总览特征如下:
- 数据量超亿级,每日上亿级账号活跃,可触达同人;
- 服务场景多,生态较为复杂,覆盖多行业产品线,包括游戏、教育、电商、泛娱乐等;
- 优质用户平均标签覆盖率达70%以上;
- 提供包括但不限于参与人、流量域、位置域、关系域等主题域解决方案,即能够封装用户画像在主题域的通用化模块。
2. 网易产品线丰富
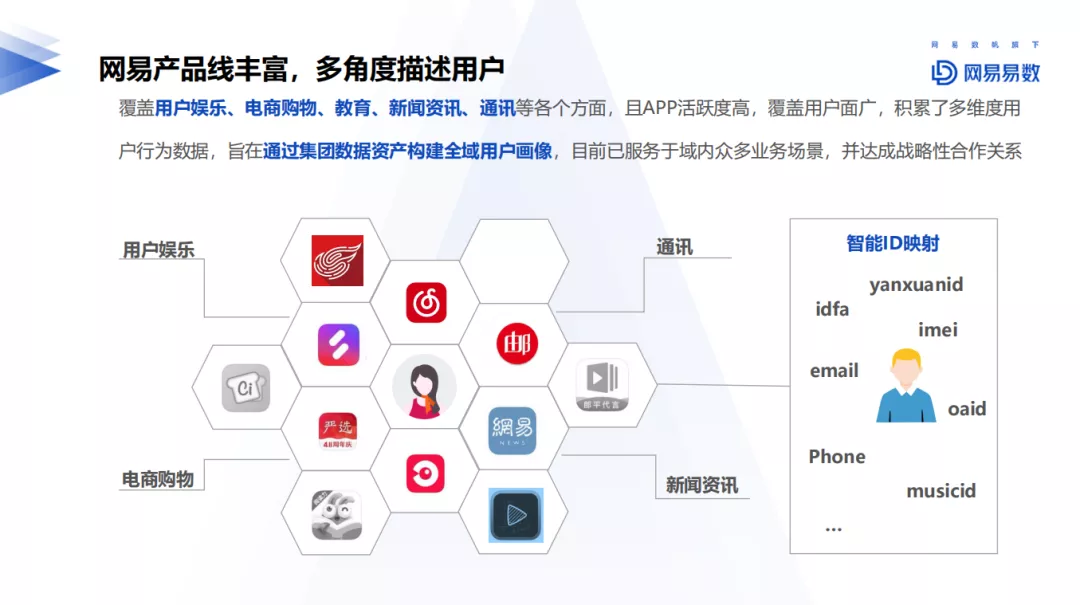
网易产品线丰富,覆盖从用户娱乐、电商购物、教育、新闻资讯等各个维度用户行为数据,APP活跃度高,涵盖用户群广。项目组整体目标是通过集团数据资产构建全域资产用户画像,已应用于网易生态圈内众多业务场景,同时探索产品化及方法论,服务于生态圈外部合作机构,进行商业化操作。
3. 全链路数据中台产品矩阵
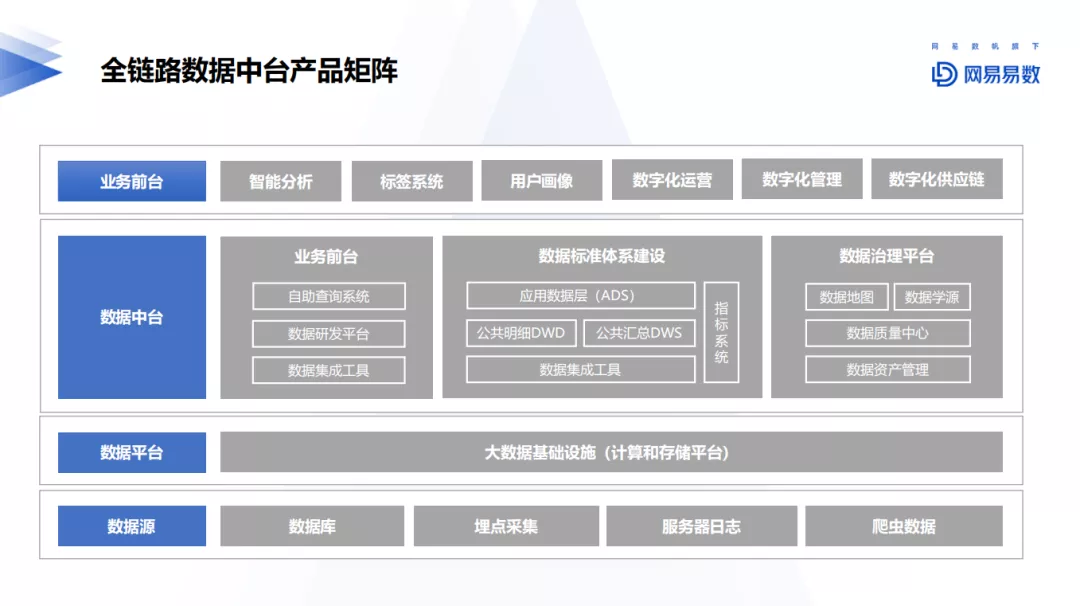
全链路数据中台产品矩阵,包括底层日志等数据源层,数据平台加工层,整体标签的离线或实时加工、挖掘算法及监控,以及上层业务应用,如智能分析、增长运营、推荐搜索等一系列业务层应用,组成了网易数据中台产品矩阵。网易易数产品矩阵,为网易用户画像起着极为关键的支撑作用,尤其是数据标准体系、数据治理平台等模块,很好的承载着用户画像落地和质量保障。
02 用户画像中心分类
首先介绍下杭研用户画像整体数据架构及落地情况,主要分为三部分:其一为基础的用户画像,基础标签 ( 如性别、年龄 )、行为统计 ( 如活跃 )、兴趣偏好及预测等标签;其二为关系库部分,即IDMapping;其三为主题域部分,即对地域、社交、搜索关键词等相关方面的工作。
1. 网易数据架构
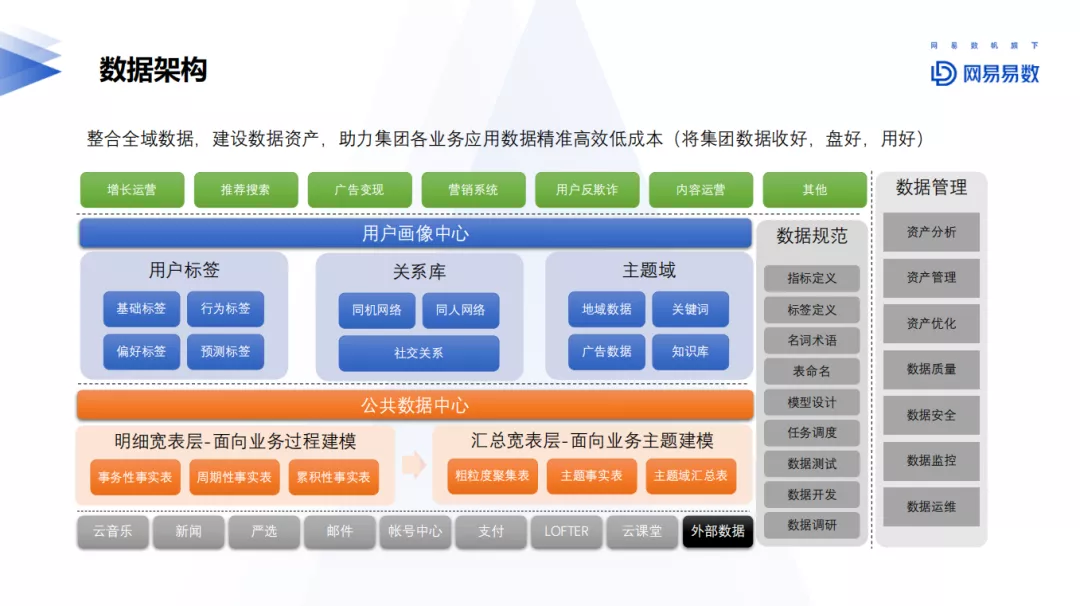
网易整体数据架构底层与各个业务方进行数据交换合作,共同建立公共数据中心,以数仓为蓝本进行架构。
中间层为用户画像中心:
- 用户标签的分类包括基础标签、行为标签、偏好标签以及预测标签等,不同公司分类方法略有不同,如根据更新周期,分为静态标签 ( 性别等 ) 和动态标签 ( 年龄等 );偏好标签包括用户的长中短期偏好等,预测标签主要应用于广告投放部分,例如游戏达人,高价值用户群等。
- 关系库主要是IDMapping,目前已经有较多的方案论和解决方案,例如多账号的归一用于后续的业务数据挖掘工作,提升对用户的识别能力。典型场景为两个手机号对应只有其中一个有过注册行为信息,另一个没有注册行为信息,但对于上层而言,应该打通他们作为同一个行为主体。关系库主要包括同机网络 ( 同一设备多个ID的关系 )、同人网络 ( 同一个人多个设备信息 ) 以及社交关系 ( 人与人之间的关系 ) 等。
- 主题域主要包括地域数据、广告数据、关键词和知识库方向,其中知识库和图谱数据,主要应用于网易域内外内容知识打通。
顶层的应用场景包括增长运营、推荐搜索、广告变现、营销系统、用户反欺诈及内容运营等方面,对业务方提供全方位的服务,不局限于单一应用场景。还有数据规范和数据管理部分,作为数据标准化,沉淀经验方法论。
2. 网易用户画像构建流程

用户画像整体构建流程依托于网易易数中台,搭建起完整的业务数仓体系,融合多方业务数据源。经过多年的探索实践,已经形成完整的用户画像体系,从数据层面到产品层面,逐渐打磨,提供标签管理、监控、报表、算法、开发及权限管理,融合在各业务产品体系。诸如关系图谱形成API的接口服务输出各业务方;数据服务包括人群圈选、人群分析等运用于市场及运营团队;特征库方面描述了用户向量化的特征相比标签粒度更为细腻,适用于算法团队迭代开发。在此基础上沉淀了多种数据应用,包括增长运营、广告DMP、智能风控等方面。
3. 网易用户标签

目前整体总标签数达1000+,其中不包含单一业务行为数据。标签分类如下:
- 基础标签,即对用户的自然属性描述,例如性别、年龄、教育背景、生活习惯 ( 早起晚起 )、地理位置 ( POI信息 )、职业状况 ( 所属行业 )、经济情况 ( 有车有房 )、设备信息 ( 手机、运营商等 )、会员信息 ( 各业务方会员等级 )、衍生信息。其中衍生标签,如评估是否已婚,在原有的标签体系下没有此类标签,但可以通过对多个标签进行组合生成新的标签,包括是否有小孩、30岁满足某个条件等。
- 行为标签包括地域、广告、搜索、全域、播放、点击、评论、关注、收藏、购买等维度。
- 偏好标签包括出行购物、手机数码、家装家居、教育公益、文化娱乐、新闻资讯、金融理财、游戏竞技、动漫影视、明星艺人等维度。
- 预测标签包括利用算法等进行预测生成的标签,包括是否出行,是否买车等等。
另外,标签的枚举值也相当重要,业务分析过程中很容易出现枚举值的偏差,不符合实际业务逻辑。除此之外还包括标签间的冲突,例如年龄15岁,学历却是博士或者有小孩,策略类标签是标签领域较为有挑战性的地方。
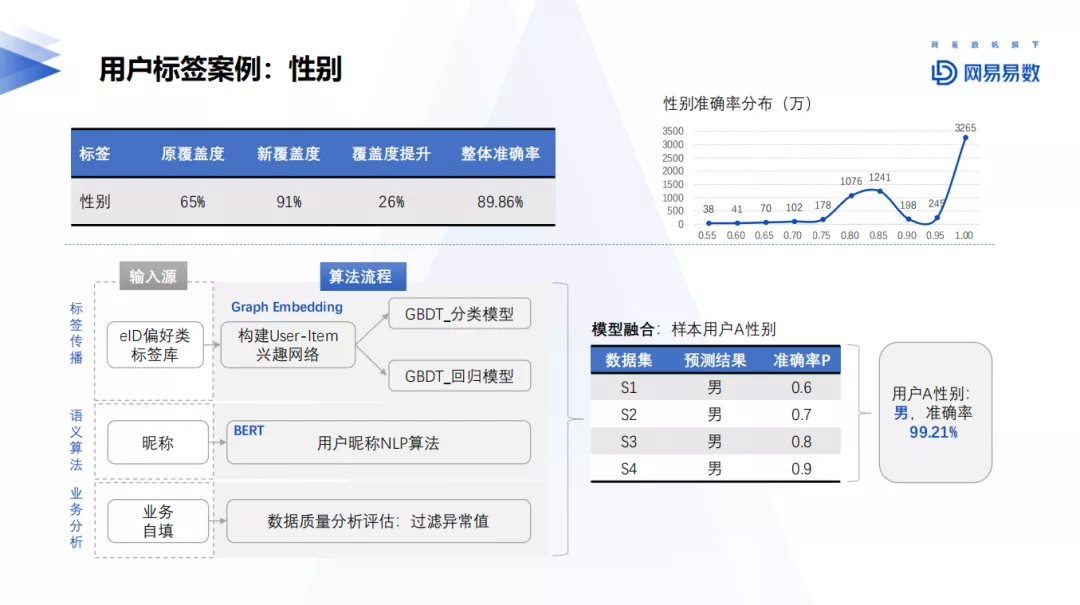
用户标签案例:性别。主要包括三种方案,其一为标签传播,根据用户在各个业务场景,例如母婴商品点击行为标签等进行item标记,构建User-Item的兴趣网络进行Graph Embedding,最后进行分类预测用户的性别;其二为利用NLP算法对用户的昵称进行语义分析;其三为利用业务属性自行填写的内容进行判断,此处需要对数据质量进行过滤,排除诸如出生为1990-01-01的参数异常值信息。基于上述的三类算法特征结果集进行模型的融合,然后对用户的性别进行预测,同时判断该用户性别的准确率,大部分准确率在0.6+以上可以应用于实际业务场景中。当然除了常见的算法融合,还包括数据融合、特征融合等等。其中需要突破的地方包括特征的稀疏性,因为IDMapping打通后的数据覆盖率仅20%左右,这个严重影响了模型的整体效果。
4. IDMapping

IDMapping主要指用户设备的打通,用于识别用户的唯一性,现今采用的手段有两种,其一通过工程层面打通,如SDK埋点,优点是准确率较高,缺点是还会存在一人多机等现象,导致了不能够较好地完整描述一个用户画像;其二指数据层面打通,通过ID关系网,采用规则和算法结合的方法,进行同人识别,优点是很好解决一人多机现象,缺点是准确率难以评估。本次分享,主要指数据层面打通。

IDMapping整体的思路及方案,具体要结合各种账户、设备之间的关系对,以及设备使用规律等用户数据,利用规则过滤+数据挖掘算法 ( 连通图划分及社区发现 ) 判断账号是否属于同人。在IDMapping过程中,常遇到的问题及对应解决方案如下:
- 用户有多个设备信息,定义相应的阈值进行关联。当然,社区发现当前应用于营销场景,暂没有用于风控或用户运营等场景,因为会把一些异常的账号关联在一起,且会存在仅登录使用过一次的设备信息。
- 设备过期 ( 一般在2年半左右时间 ),设定衰减系数,对单用户多设备加大衰减力度。
- 当然也会存在一些异常数据信息,通过算法识别出包括但不限于以下场景,诸如借用朋友设备、设备脏数据、刷号等行为轨迹。

IDMapping的存储方式包括两个ID类型 ( 关系对 )、最近采集时间、最早采集时间、采集源数据、采集源列表、采集的频次和周期。其中共线关系的部分增加了时间衰减系数,同步递减应用于结果,同时也增加了某些参数的权重部分用于提高业务的可选性和高可性。
5. 地域主题域
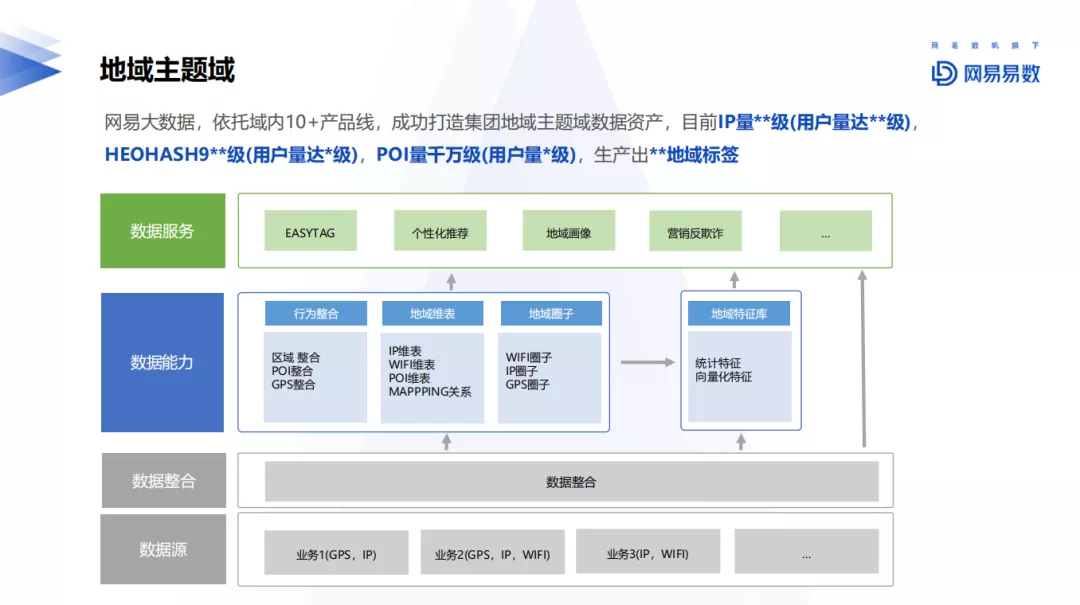
地域主题域可以挖掘用户的需求信息,包括是否有车,是否经常去4S店,通过WIFI、设备等信息获取亲戚、同事等关系,通过IP可以捕获学校的学生信息,根据作息规律进行统计。当然除此之外,地域主题域还用于反欺诈领域,针对黄牛等用户群进行修改地域参数信息,规避系统检测。
6. 用户画像管理与存储
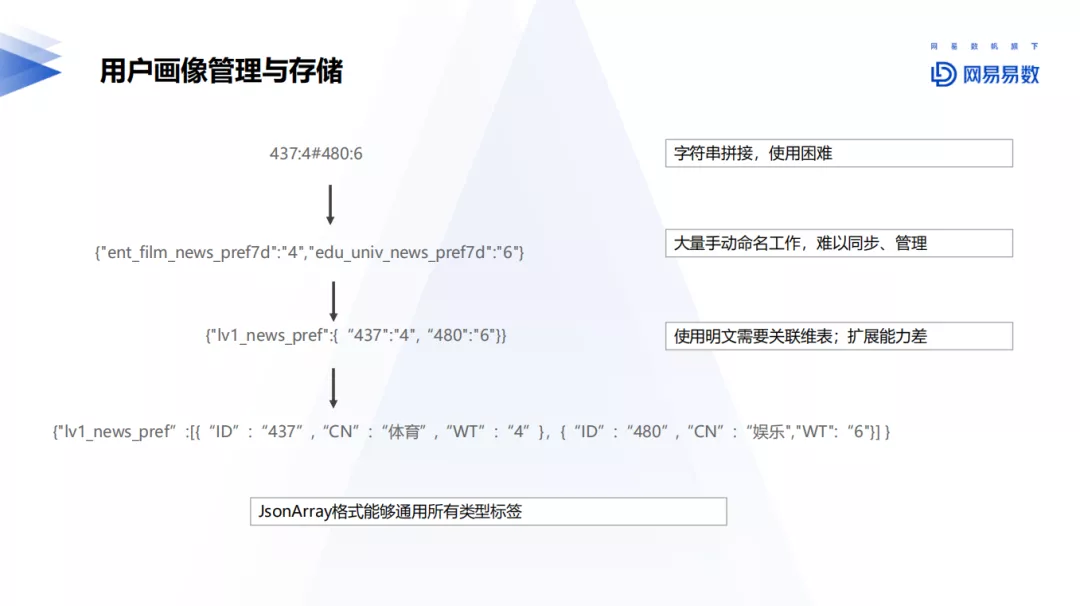
用户画像管理与存储在网易大数据经历了多次迭代,包括前期字符串的拼接、手工标签命名、明文关联维表,再到现在利用JsonArray格式进行标签类型管理,这种有个比较大的缺点,就是存在冗余严重,正在尝试新的方案设计。
7. 质量校验与保障体系
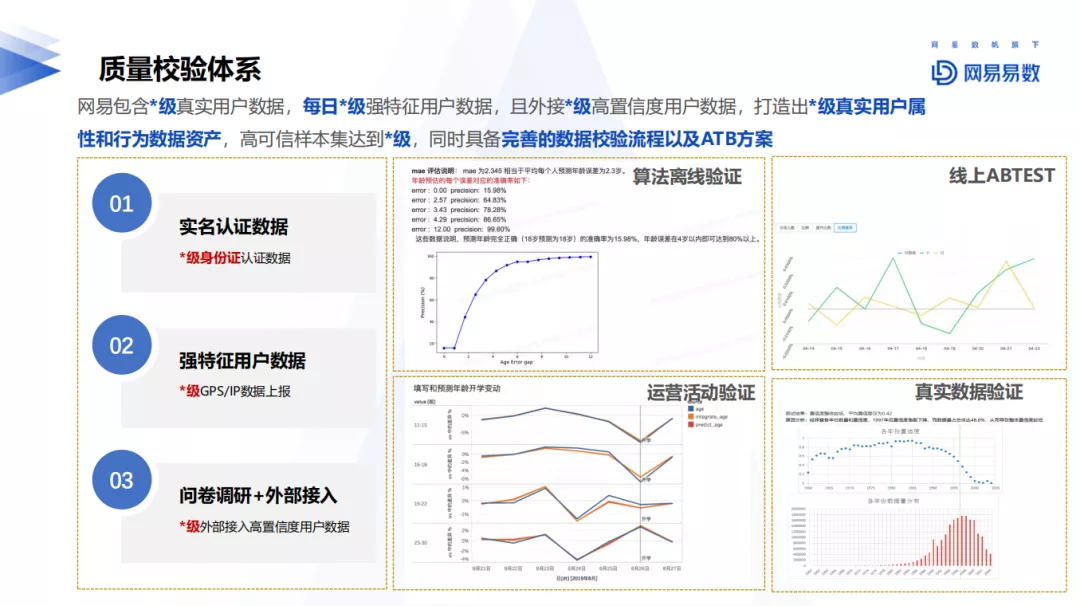
网易标签包含真实的用户数据及特征用户数据,利用无监督的算法模型预测姓名、年龄、有车、有房等,利用有监督进行提升数据质量,提升标签的整体效果。主要包括三方面的工作:
- 利用实名认证数据,作为高可信的样本集;
- 利用强特征用户数据,通过GPS\IP等用户行为数据;
- 利用外部数据,增加高置信用户数据质量。
除此之外,还包括利用一些常见的算法,例如交叉验证准确率和召回率,线上ABTest、算法离线验证、运营活动验证、真实数据验证等等方案。

质量保障标签管理方法论,包括以下四点:
- 每个标签定义第一责任人,用于快速响应业务需求,同时处理标签异常问题;
- 流程优化,标签的流程较为漫长,需要了解业务、算法、开发的全流程,利用端到端的模式,通过快速响应增加标签规范化的评审工作;
- 测试监控方面,测试在标签上线前对标签规范和质量输出测试报告,预测则是针对规范、枚举值等范围,建立监控预警机制;
- 管理平台化,则是标签生产、加工、处理、应用全流程体系化、标签化、工具产品化,不断迭代升级�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BD%91%E6%98%93%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%94%A8%E6%88%B7%E7%94%BB%E5%83%8F%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


