网易有数机器学习平台批调度与调度系统的深度解析
问君,网易有数机器学习平台研发工程师
本文主要介绍了网易有数机器学习平台在深度学习任务批调度的一些实践探索,并对k8s调度机制的原理做部分解析。
1 背景介绍
近几年来,AI和大数据异常火热,伴随着AI经常出现的一个词就是机器学习平台,作为一个机器学习平台,平台提供训练所需要的硬件资源,平台支持使用tfjob分布式训练任务训练模型,由于平台部署在私有集群,所以集群内项目的资源是有限的,在项目初期,项目训练任务不多的时候,每个任务都能获取足够的资源进行训练。随着项目里的训练任务越来越多,逐渐暴露出了一些在任务调度上的问题:
(1)多个tfjob同时提交会发生资源竞争而产生任务死锁,多个任务都无法正常完成;
(2)单个超大资源的训练任务长期抢占剩余资源(剩余资源也不够此任务启动),后续的小资源任务也无法获得资源;
(3)业务方需要手动错峰提交训练任务,加大业务方工作量;
(4)业务方无法判断夜里cpu利用率低是团队训练资源没充分利用还是资源竞争导致死锁,无法进行资源优化。
出现问题的原因是当前k8s的默认调度器只支持对单个pod的调度,对tfjob这种对应多个pod并且需要同时启动的任务无法做到批调度,这些问题影响了平台资源利用率,也影响了业务方的模型训练效率,成为平台需要解决的痛点之一。
由于平台整个构建在k8s集群上,在介绍平台批调度之前,需要先了解k8s原生的调度逻辑。
2 kube-scheduler
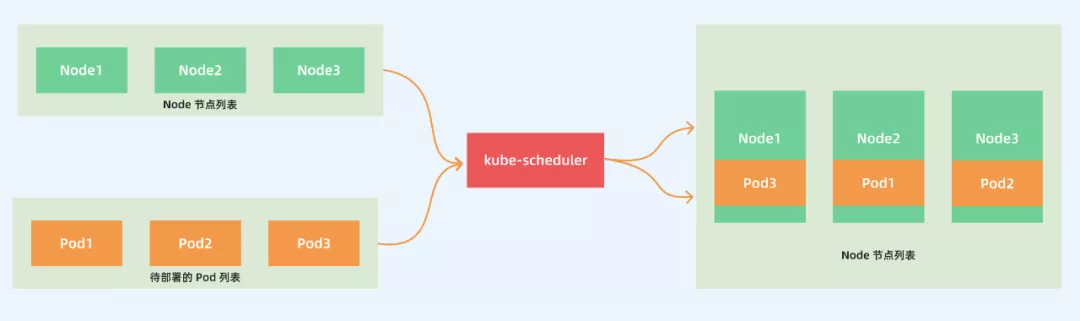
kube-scheduler是 kubernetes 的核心组件之一,主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将 Pod 调度到最优的工作节点上面去,从而更加合理、更加充分的利用集群的资源,这也是我们选择使用 kubernetes 一个非常重要的理由。
调度流程
下面介绍下kubernete调度程序是如何工作的:
(1)默认调度器根据指定的参数启动(如果使用 kubeadm 搭建的集群,启动配置文件位于 /etc/kubernetes/manifests/kube-schdueler.yaml);
(2)watch apiserver,将 spec.nodeName 为空的 Pod 放入调度器内部的调度队列中;
(3)从调度队列中 Pop 出一个 Pod,开始一个标准的调度周期;
(4)从Pod 属性中检索“硬性要求”(比如 CPU/内存请求值,nodeSelector/nodeAffinity),然后过滤阶段发生,在该阶段计算出满足要求的节点候选列表;
(5)从 Pod 属性中检索“软需求”,并应用一些默认的“软策略”(比如 Pod 倾向于在节点上更加聚拢或分散),最后,它为每个候选节点给出一个分数,并挑选出得分最高的最终获胜者;
(6)和 apiserver 通信(发送绑定调用),然后设置 Pod 的 spec.nodeName 属性表示将该 Pod 调度到的节点。
3 kube-scheduler扩展
默认情况下,kube-scheduler提供的默认调度器能够满足我们绝大多数的要求,可以保证我们的 Pod 可以被分配到资源充足的节点上运行。但是在实际的线上项目中,可能我们自己会比 kubernetes 更加了解我们自己的应用,比如我们希望一个 Pod 只能运行在特定的几个节点上,或者这几个节点只能用来运行特定类型的应用,这就需要我们的调度器能够可控。
另外伴随着Kubernetes在公有云以及企业内部IT系统中广泛应用,越来越多的开发人员尝试使用Kubernetes运行和管理Web应用和微服务以外的工作负载。典型场景包括机器学习和深度学习训练任务,高性能计算作业,基因计算工作流,甚至是传统的大数据处理任务。此外,Kubernetes集群所管理的资源类型也愈加丰富,不仅有GPU,TPU和FPGA,RDMA高性能网络,还有针对领域任务的各种定制加速器,kube-scheduler的调度能力已经不能完美满足上述各种场景,这就需要能对调度做一些定制修改。
3.1 早期方案
最初对于Kube-scheduler进行扩展的方式主要有两种,一种是调度器扩展(Scheduler Extender), 另外一种是多调度器(Multiple schedulers)。接下来我们对这两种方式分别进行介绍和对比。
Scheduler Extender
对于Kubernetes项目来说,它很乐意开发者使用并向它提bug或者PR(受欢迎),但是不建议开发者为了实现业务需求直接修改Kubernetes核心代码,因为这样做会影响Kubernetes本身的代码质量以及稳定性。因此Kubernetes希望尽可能通过外围的方式来解决客户自定义的需求。
其实任何好的项目都应该这样思考:尽可能抽取核心代码,这部分代码不应该经常变动或者说只能由maintainer改动(提高代码质量,减小项目本身开发&运维成本);将第三方客户需求尽可能提取到外围解决(满足客户自由),例如:插件的形式(eg: CNI,CRI,CSI and scheduler framework etc)。
社区最初提供的方案是通过Extender的形式来扩展scheduler。Extender是外部服务,支持Filter、Preempt、Prioritize和Bind的扩展,scheduler运行到相应阶段时,通过调用Extender注册的webhook来运行扩展的逻辑,影响调度流程中各阶段的决策结果。
以Filter阶段举例,执行过程会经过2个阶段:
- scheduler会先执行内置的Filter策略,如果执行失败的话,会直接标识Pod调度失败。
- 如何内置的Filter策略执行成功的话,scheduler通过Http调用Extender注册的webhook, 将调度所需要的Pod和Node的信息发送到到Extender,根据返回filter结果,作为最终结果。
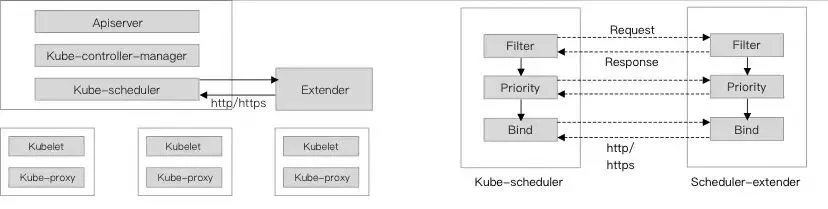
Extender存在以下问题:
- 调用Extender的接口是HTTP请求,受到网络环境的影响,性能远低于本地的函数调用。同时每次调用都需要将Pod和Node的信息进行marshaling和unmarshalling的操作,会进一步降低性能。
- 用户可以扩展的点比较有限,位置比较固定,无法支持灵活的扩展,例如只能在执行完默认的Filter策略后才能调用。
Multiple schedulers
Scheduler在Kubernetes集群中其实类似于一个特殊的Controller,通过监听Pod和Node的信息,给Pod挑选最佳的节点,更新Pod的spec.NodeName的信息来将调度结果同步到节点。所以对于部分有特殊的调度需求的用户,有些开发者通过自研Custom Scheduler来完成以上的流程,然后通过和default scheduler同时部署的方式,来支持自己特殊的调度需求。
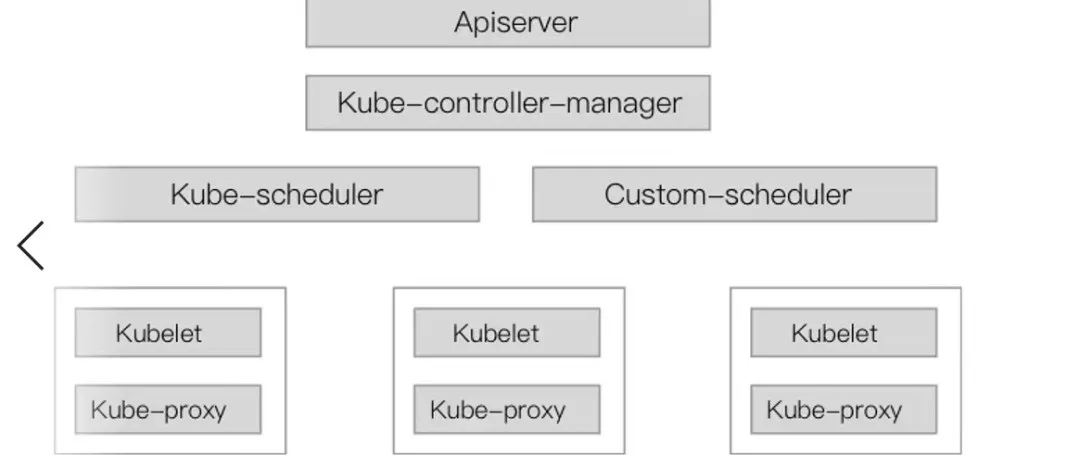
Custom Scheduler会存在以下问题:
(1)如果与default scheduler同时部署,因为每个调度器所看到的资源视图都是全局的,所以在调度决策中可能会在同一时刻在同一个节点资源上调度不同的Pod,导致节点资源冲突的问题;
(2)有些用户将调度器所能调度的资源通过Label划分不同的池子,可以避免资源冲突的现象出现。但是这样又会导致整体集群资源利用率的下降;
(3)有些用户选择通过完全自研的方式来替换default scheduler,这种会带来比较高的研发成本,以及Kubernetes版本升级后可能存在的兼容性问题。
3.2 调度框架Scheduling Framework
框架简介
社区也逐渐的发现开发者所面临的困境,为了解决如上问题,使Kube-scheduler扩展性更好、代码更简洁,社区从Kubernetes 1.16版本开始, 构建了一种新的调度框架Kubernetes Scheduling Framework的机制。
Scheduling Framework在原有的调度流程中, 定义了丰富扩展点接口,开发者可以通过实现扩展点所定义的接口来实现插件,将插件注册到扩展点。Scheduling Framework在执行调度流程时,运行到相应的扩展点时,会调用用户注册的插件,影响调度决策的结果。通过这种方式来将用户的调度逻辑集成到Scheduling Framework中。
ps: 该调度框架需要重新编译kube-schduler。
具体调度过程
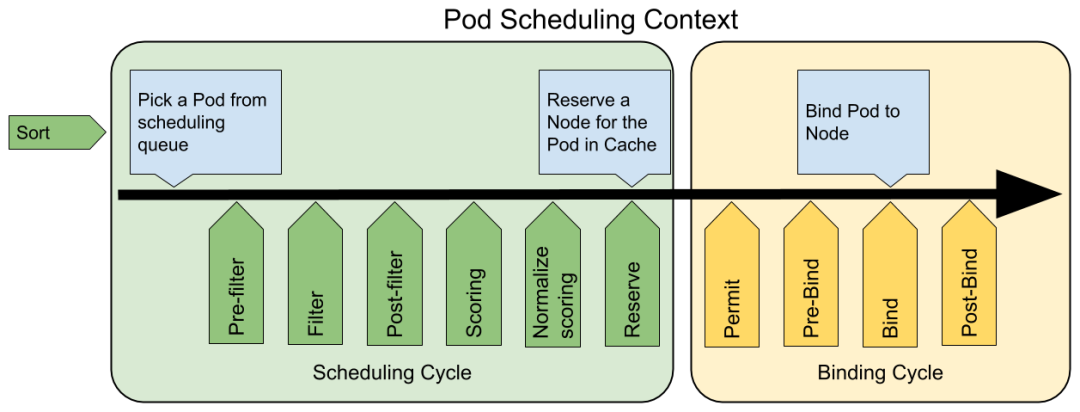
Framework的调度流程是分为两个阶段scheduling cycle和binding cycle。scheduling cycle是同步执行的,同一个时间只有一个scheduling cycle,是线程安全的。binding cycle是异步执行的,同一个时间中可能会有多个binding cycle在运行,是线程不安全的。
Scheduling cycle
(1)QueueSort 扩展用于对 Pod 的待调度队列进行排序,以决定先调度哪个 Pod,QueueSort 扩展本质上只需要实现一个方法 Less(Pod1, Pod2) 用于比较两个 Pod 谁更优先获得调度即可,同一时间点只能有一个 QueueSort 插件生效。
(2)Pre-filter 扩展用于对 Pod 的信息进行预处理,或者检查一些集群或 Pod 必须满足的前提条件,如果 pre-filter 返回了 error,则调度过程终止。
(3)Filter 扩展用于排除那些不能运行该 Pod 的节点,对于每一个节点,调度器将按顺序执行 filter 扩展;如果任何一个 filter 将节点标记为不可选,则余下的 filter 扩展将不会被执行。调度器可以同时对多个节点执行 filter 扩展。
(4)Post-filter 是一个通知类型的扩展点,调用该扩展的参数是 filter 阶段结束后被筛选为可选节点的节点列表,可以在扩展中使用这些信息更新内部状态,或者产生日志或 metrics 信息。
(5)Scoring 扩展用于为所有可选节点进行打分,调度器将针对每一个节点调用 Soring 扩展,评分结果是一个范围内的整数。在 normalize scoring 阶段,调度器将会把每个 scoring 扩展对具体某个节点的评分结果和该扩展的权重合并起来,作为最终评分结果。
(6)Normalize scoring 扩展在调度器对节点进行最终排序之前修改每个节点的评分结果,注册到该扩展点的扩展在被调用时,将获得同一个插件中的 scoring 扩展的评分结果作为参数,调度框架每执行一次调度,都将调用所有插件中的一个 normalize scoring 扩展一次。
(7)Reserve 是一个通知性质的扩展点,有状态的插件可以使用该扩展点来获得节点上为 Pod 预留的资源,该事件发生在调度器将 Pod 绑定到节点之前,目的是避免调度器在等待 Pod 与节点绑定的过程中调度新的 Pod 到节点上时,发生实际使用资源超出可用资源的情况。(因为绑定 Pod 到节点上是异步发生的)。这是调度过程的最后一个步骤,Pod 进入 reserved 状态以后,要么在绑定失败时触发 Unreserve 扩展,要么在绑定成功时,由 Post-bind 扩展结束绑定过程。
Binding cycle
(1)Permit 扩展用于阻止或者延迟 Pod 与节点的绑定。Permit 扩展可以做下面三件事中的一项:
- approve(批准):当所有的 permit 扩展都 approve 了 Pod 与节点的绑定,调度器将继续执行绑定过程
- deny(拒绝):如果任何一个 permit 扩展 deny 了 Pod 与节点的绑定,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展
- wait(等待):如果一个 permit 扩展返回了 wait,则 Pod 将保持在 permit 阶段,直到被其他扩展 approve,如果超时事件发生,wait 状态变成 deny,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展
(2)Pre-bind 扩展用于在 Pod 绑定之前执行某些逻辑。例如,pre-bind 扩展可以将一个基于网络的数据卷挂载到节点上,以便 Pod 可以使用。如果任何一个 pre-bind 扩展返回错误,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展。
(3)Bind 扩展用于将 Pod 绑定到节点上:
- 只有所有的 pre-bind 扩展都成功执行了,bind 扩展才会执行
- 调度框架按照 bind 扩展注册的顺序逐个调用 bind 扩展
- 具体某个 bind 扩展可以选择处理或者不处理该 Pod
- 如果某个 bind 扩展处理了该 Pod 与节点的绑定,余下的 bind 扩展将被忽略
(4)Post-bind 是一个通知性质的扩展:
- Post-bind 扩展在 Pod 成功绑定到节点上之后被动调用
- Post-bind 扩展是绑定过程的最后一个步骤,可以用来执行资源清理的动作
(5)Unreserve 是一个通知性质的扩展,如果为 Pod 预留了资源,Pod 又在被绑定过程中被拒绝绑定,则 unreserve 扩展将被调用。Unreserve 扩展应该释放已经为 Pod 预留的节点上的计算资源。在一个插件中,reserve 扩展和 unreserve 扩展应该成对出现。
3.3 利用Scheduling Framework实现批调度
为什么 Kubernetes 调度系统需要批调度?
默认的调度器是以 Pod 为调度单元进行依次调度,不会考虑 Pod 之间的相互关系。但是很多数据计算类的离线作业具有组合调度的特点,即要求所有的子任务都能够成功创建后,整个作业才能正常运行。如果只有部分子任务启动的话,启动的子任务将持续等待剩余的子任务被调度。这正是 Gang Scheduling 的场景。
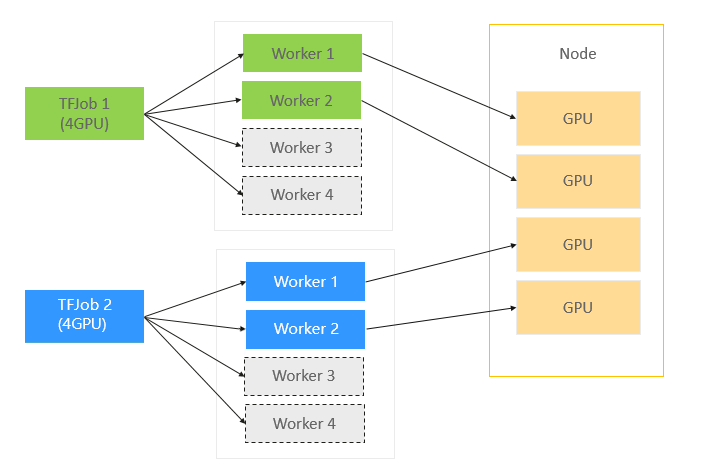
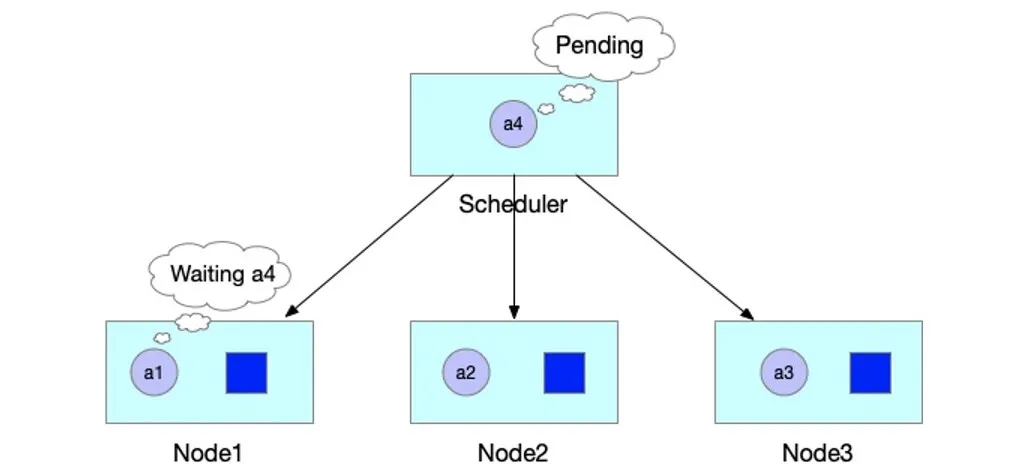
如下图所示,JobA 需要 4 个 Pod 同时启动,才能正常运行。Kube-scheduler 依次调度 3 个 Pod 并创建成功。到第 4 个 Pod 时,集群资源不足,则 JobA 的 3 个 Pod 处于空等的状态。但是它们已经占用了部分资源,如果第 4 个 Pod 不能及时启动的话,整个 JobA 无法成功运行,更糟糕的是导致集群资源浪费。
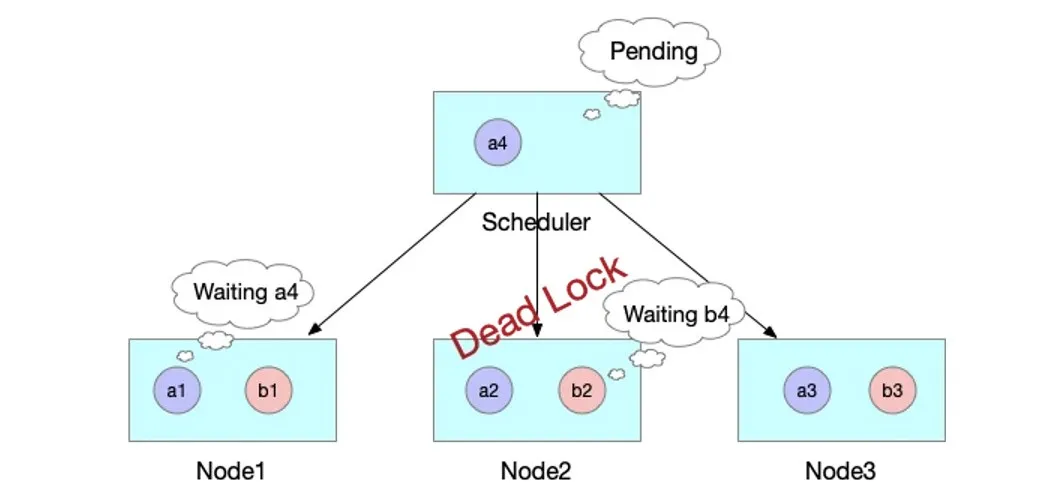
如果出现更坏的情况的话,如下图所示,集群其他的资源刚好被 JobB 的 3 个 Pod 所占用,同时在等待 JobB 的第 4 个 Pod 创建,此时整个集群就出现了死锁。
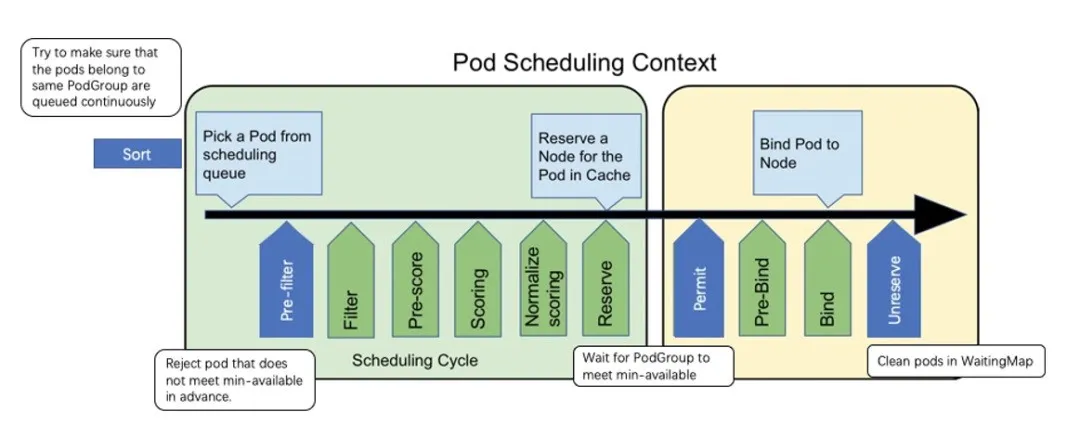
基于 Scheduling Framework 的实现方案
PodGroup
要进行批调度,需要引入podGroup的概念,通过 label 的形式来定义 PodGroup ,拥有同样 label 的 Pod 同属于一个 PodGroup。min-available 是用来标识该 PodGroup 的作业能够正式运行时所需要的最小副本数。
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "3"
ps: 要求属于同一个 PodGroup 的 Pod 必须保持相同的优先级
Permit
Framework 的 Permit 插件提供了延迟绑定的功能,即 Pod 进入到 Permit 阶段时,用户可以自定义条件来允许 Pod 通过、拒绝 Pod 通过以及让 Pod 等待状态(可设置超时时间)。Permit 的延迟绑定的功能,刚好可以让属于同一个 PodGruop 的 Pod 调度到这个节点时,进行等待,等待积累的 Pod 数目满足足够的数目时,再统一运行同一个 PodGruop 的所有 Pod 进行绑定并创建。
举个实际的例子,当 JobA 调度时,需要 4 个 Pod 同时启动,才能正常运行。但此时集群仅能满足 3 个 Pod 创建,此时与 Default Scheduler 不同的是,并不是直接将 3 个 Pod 调度并创建。而是通过 Framework 的 Permit 机制进行等待。
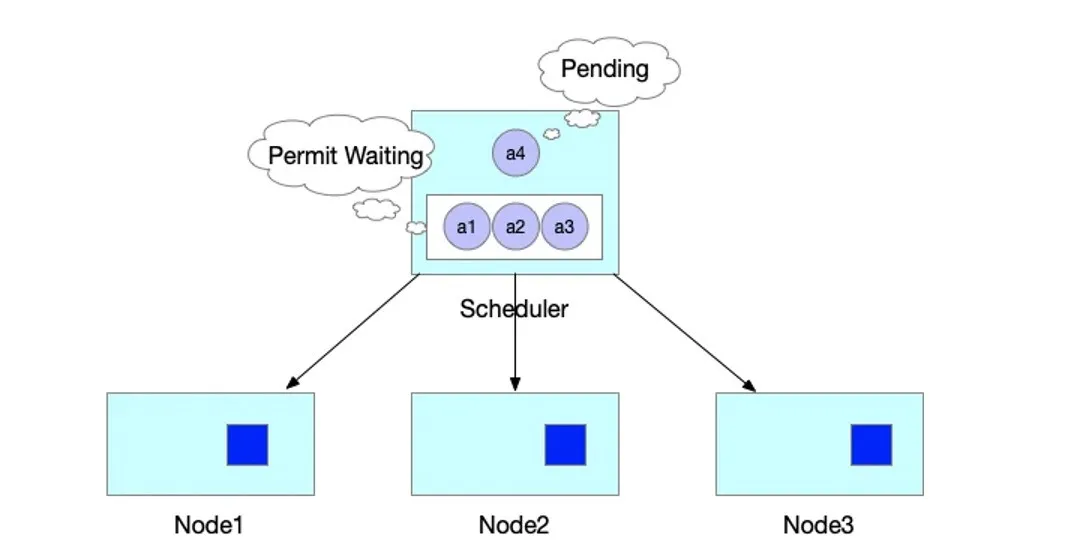
此时当集群中有空闲资源被释放后,JobA 的中 Pod 所需要的资源均可以满足。
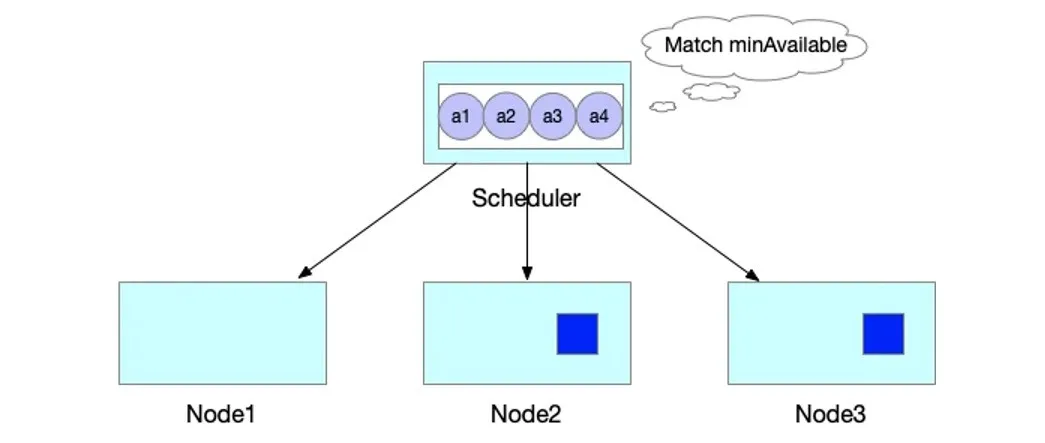
则 JobA 的 4 个 Pod 被一起调度创建出来,正常运行任务。
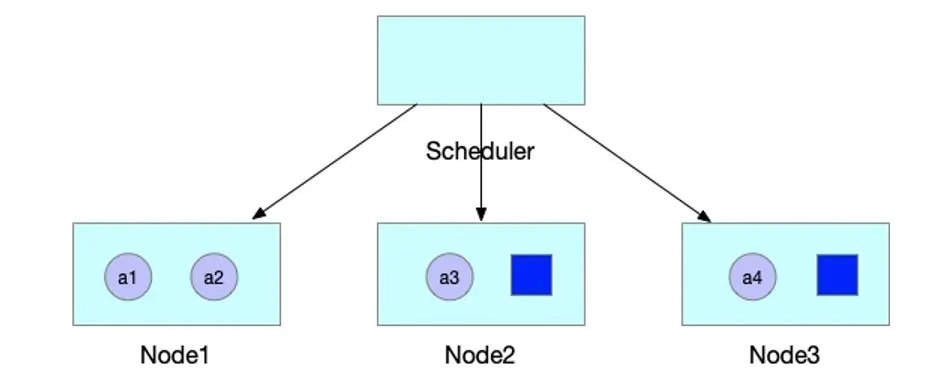
Prefilter
为了减少无效的调度操作,提升调度的性能,我们在 Prefilter 阶段增加一个过滤条件,当一个 Pod 调度时,会计算该 Pod 所属 PodGroup 的 Pod 的 Sum(包括 Running 状态的),如果 Sum 小于 min-available 时,则肯定无法满足 min-available 的要求,则直接在 Prefilter 阶段拒绝掉,不再进入调度的主流程。
UnReserve
如果某个 Pod 在 Permit 阶段等待超时了,则会进入到 UnReserve 阶段,我们会直接拒绝掉所有跟 Pod 属于同一个 PodGroup 的 Pod,避免剩余的 Pod 进行长时间的无效等待。
3.4 利用Scheduling Framework实现binpack调度
为什么需要Binpack功能?
Kubernetes默认开启的资源调度策略是LeastRequestedPriority,消耗的资源最少的节点会优先被调度,使得整体集群的资源使用在所有节点之间分配地相对均匀。但是这种调度策略往往也会在单个节点上产生较多资源碎片。
下面拿一个简单的例子来说明这种问题。如下图所示,资源在节点之间平均使用,所以每个节点使用3个GPU卡,则两个节点各剩余1GPU的资源。这是有申请2GPU的新作业,提交到调度器,则因为无法提供足够的资源,导致调度失败。
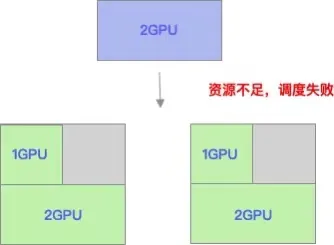
基于 Scheduling Framework 的实现方案
Binpack实现已经抽象成Kubernetes Scheduler Framework的Score插件RequestedToCapacityRatio,用于优选阶段给节点打分。将节点根据自己定义的配置进行打分。具体的实现可以分为两个部分,构建打分函数和打分。
构建打分函数
构建打分函数的过程比较容易理解,就是用户可以自己定义不同的利用率所对应的分值大小,以便影响调度的决策过程。
如果用户可以自行设定打分规则,即如果资源利用率为0的时候,得分为0分,当资源利用率为100时,得分为10分,所以得到的资源利用率越高,得分越高,则这个行为就是Binpack的资源分配方式。
打分
用户可以自己定义在Binpack计算中所要参考的资源以及权重值,例如可以只是设定GPU和CPU的值和权重。
resourcetoweightmap:
"cpu": 1
"nvidia.com/gpu": 1
然后在打分过程中,会通过计算node.Allocated/node.Total的结果得到对应资源的利用率,并且将利用率带入上文中所述的打分函数中,得到相应的分数。最后将所有的资源根据weight值,加权得到最终的分数。
Score = line(resource1_utilization) * weight1 + line(resource2_utilization) * weight2 ....) / (weight1 + weight2 ....)
4 网易有数机器学习平台批调度简介
4.1 开源调研
为避免重复造轮子,选择优先调研社区方案,首先就选择上述k8s scheduling framework框架,但是发现此框架需要k8s1.16版本,当前平台k8s版本只有1.13,考虑k8s版本升级影响较多,故放弃此方案。
考虑升级兼容问题,于是决定调研Multiple scheduler方案,当前较活跃的方案是volcano调度器。
4.2 Volcano
volcano是华为云开源的针对ai/大数据场景的批调度服务,脱胎于kube-batch, kube-batch是kubeflow原生的批调度器项目,volcano在此基础上提供了增强型的volcano scheduler,用于补充k8s默认调度器批调度的短板。
Volcano scheduler实现
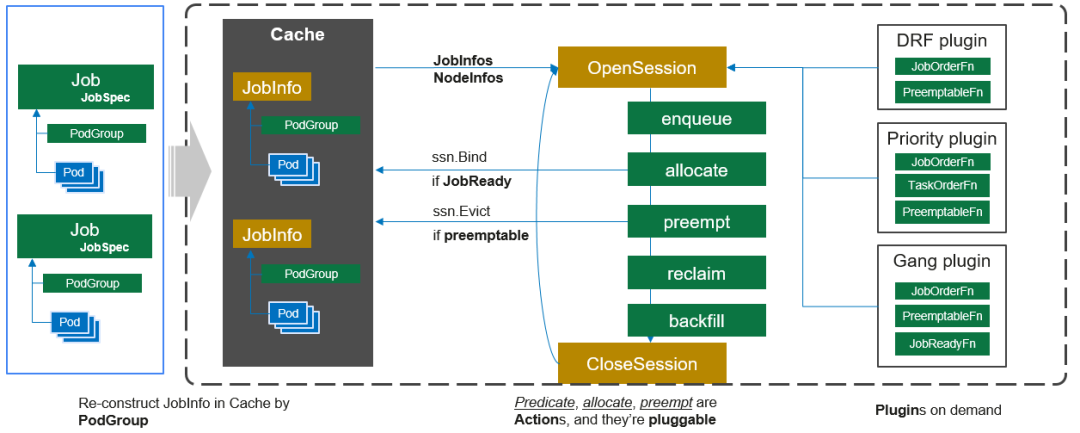
- 客户端提交的Job被scheduler以podGroup的形式观察到并缓存起来;
- 周期性的开启会话,一个调度周期开始;
- 等待job的pod全部被创建后,podGroup状态变为enqueue,Job进入会话的待调度队列中;
- 遍历所有的待调度Job,按照用户自定义的次序依次执行enqueue(入列)、allocate(预选&&优选)、preempt(优先级调度)、reclaim(队列权重资源回收)、backfill(最大化调度)等动作,为job的所有pod都找到合适的节点才会将pod绑定到节点上。action中执行的具体算法逻辑取决于注册的plugin中各函数的实现;
- 关闭本次会话。
volcano批调度tfjob过程
- 部署volcano;
- tf-operator增加–enable-gang-scheduling=true参数即可, 开启后tf-operator创建pod的时候会指定pod的调度器为volcano。
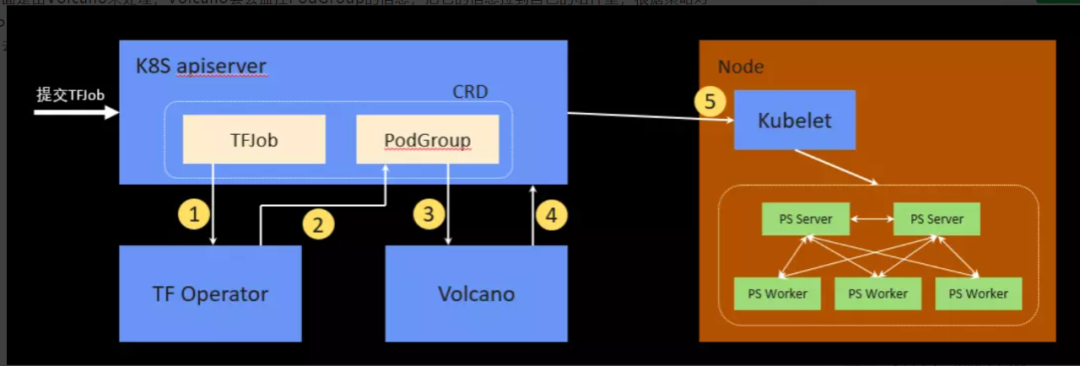
volcano scheduler调度时监控的是podGroup,podGroup相当于tfjob的抽象,等待tf-operator创建完所有pod后,会进入上面volcano scheduler的调度流程,当判断所有pod都可调度后,volcano scheduler会将所有pod调度到具体node上, 交由node上的kubelet拉起pod。
4.3 平台适配问题
由于平台对每个项目namespace做了resourcequota资源限制,在资源不足的情况下,tf-operator无法创建出所有pod,会被apiserver的准入控制器拦截,volcano感知不到pod全部被创建,无法进入调度逻辑。但是平台短期内不会更改项目资源隔离以及限制,故无法满足平台需求。和社区沟通过,社区也在尝试支持resourcequota限制下的tfjob批调度。
4.4 最终实现
由于前面的开源组件暂时都无法适配解决平台当前批调度的痛点,考虑到上述实现批调度的方式都是对pod进行分组来避免多个tfjob的资源竞争,但是实际上也可以通过优先队列的方式每次只调度一个任务来实现这个目的,结合平台实际业务,决定在平台业务的任务入口层设计一层缓冲队列解决此问题。
任务队列优选
平台当前支持提交任务的方式有三种,都会通过平台自有组件jobdashboard,jobdashboard就是平台用来管理所有训练任务的组件。
为实现训练任务批调度的目的,决定在jobdashboard增加一层缓存队列,作为对k8s调度策略的扩展,在任务下发到k8s集群上之前,先对每个请求的资源进行过滤筛选才决定要不要下发,借鉴开源实现对所有tfjob进行过滤、排序、优选, 确保足够的资源供tfjob成功运行。
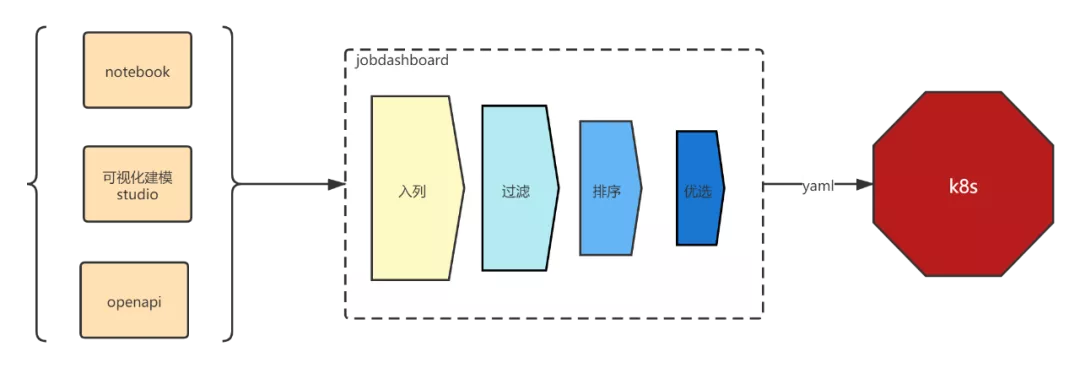
(1)入列**。**
- 平台所有提交的训练任务都会以yaml格式的string字符串通过jobdashboard保存到数据库中,确保任务持久化。
- jobdashboard启动后需要利用consual进行选主操作,确认为master属性的jobdashboard会启动异步轮询线程继续处理数据库中的训练任务。
(2)过滤**。**
- 从数据库拿到所有任务后,开始按照namespace分组,确保每个namespace的任务互不影响。
- 平台的每个训练任务会填写预申请资源,从任务yaml信息中pod.spec.request拿到整个任务的cpu/memory/gpu申请值,并比对namespace的resourcequota分配的资源数,过滤掉不符合要求的任务。
(3)排序**。**
- 拿到过滤好的任务队列后,按cpu申请值大小排序,默认按照cpu申请值较大的排序。
(4)优选**。**
- 选取cpu申请值最大的任务下发给k8s,并检测任务状态确认任务启动后才继续调度下一个任务。
Webhook拦截
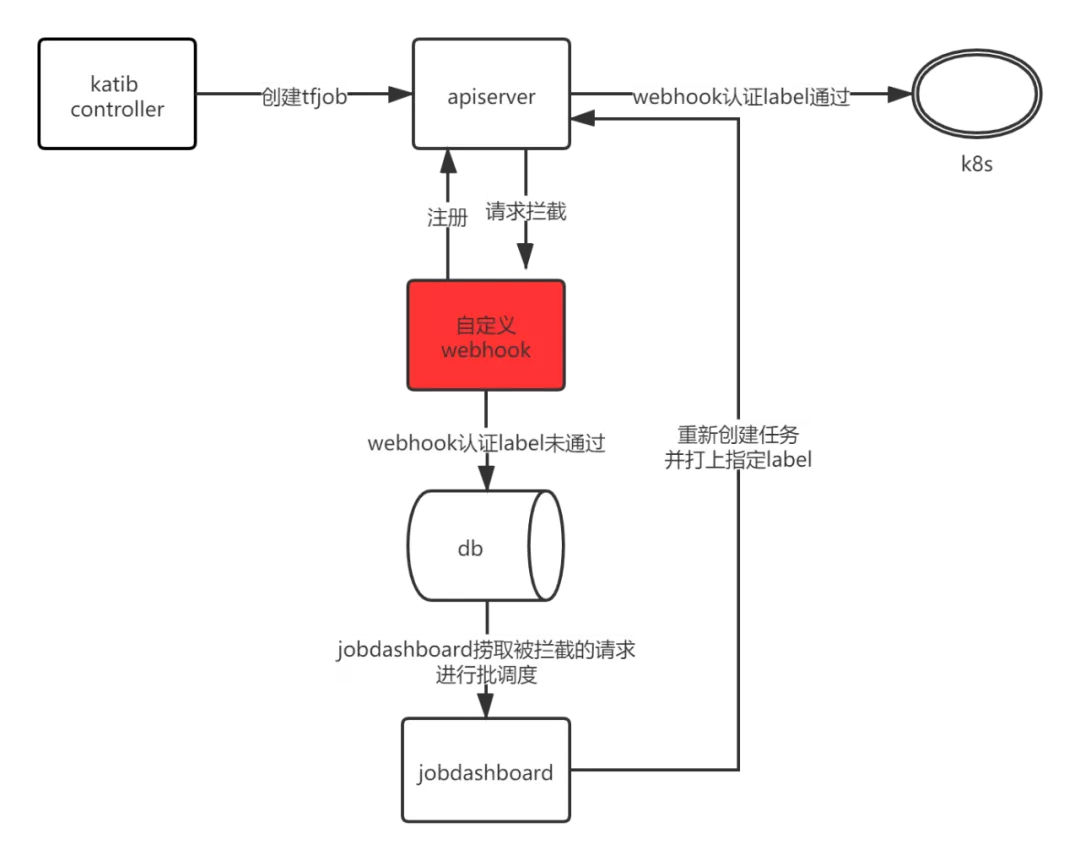
平台后期在可视化建模里扩展了automl自动调参功能,用户可使用可视化建模方便的进行automl并可视化的比较训练指标信息。其中选用了较适合平台的katib组件来实现automl,katib自动调参过程中会自行创建tfjob直接提交到apiserver,绕过了平台的jobdashboard组件,这导致任务提交会发生冲突,katib提交的tfjob无法复用jobdashboard的批调度逻辑。
为复用上述平台已有的批调度逻辑,平台自定义一个k8s admission webhook准入控制器,拦截非平台组件jobdashboard创建tfjob的请求,转发至jobdashboard继续进行批调度逻辑。
4.5 未来工作思考
在线推理也是机器学习平台的重要基础功能,在线推理计算资源的自动调度也一直是机器学习平台的重点之一,当前业界常见的解决方案是HPA
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BD%91%E6%98%93%E6%9C%89%E6%95%B0%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%B9%B3%E5%8F%B0%E6%89%B9%E8%B0%83%E5%BA%A6%E4%B8%8E%E8%B0%83%E5%BA%A6%E7%B3%BB%E7%BB%9F%E7%9A%84%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


