美团基于知识图谱的剧本杀标准化建设与应用
来源:李翔 陈焕 志华等 美团技术团队
剧本杀作为爆发式增长的新兴业务,在商家上单、用户选购、供需匹配等方面存在不足,供给标准化能为用户、商家、平台三方创造价值,助力业务增长。
本文介绍了美团到店综合业务数据团队从0到1快速建设剧本杀供给标准化的过程及算法方案。我们将美团到店综合知识图谱(GENE,GEneral NEeds net)覆盖至剧本杀行业,构建剧本杀知识图谱,实现供给标准化建设,包括剧本杀供给挖掘、标准剧本库构建、供给与标准剧本关联等环节,并在多个场景进行应用落地,希望给大家带来一些帮助或启发。
一、背景
剧本杀行业近年来呈爆发式增长态势,然而由于剧本杀是新兴行业,平台已有的类目体系和产品形态,越来越难以满足飞速增长的用户和商户需求,主要表现在下面三个方面:
- 平台类目缺失 :平台缺少专门的“剧本杀”类目,中心化流量入口的缺失,导致用户决策路径混乱,难以建立统一的用户认知。
- 用户决策效率低 :剧本杀的核心是剧本,由于缺乏标准的剧本库,也未建立标准剧本和供给的关联关系,导致剧本信息展示和供给管理的规范化程度低,影响了用户对剧本选择决策的效率。
- 商品上架繁琐 :商品信息需要商户人工一一录入,没有可用的标准模板用以信息预填,导致商户在平台上架的剧本比例偏低,上架效率存在较大的提升空间。
为了解决上述痛点,业务需要进行剧本杀的供给标准化建设:首先建立“剧本杀”新类目,并完成相应的供给(包括商户、商品、内容)的类目迁移。以此为基础,以剧本为核心,搭建标准剧本库,并关联剧本杀供给,继而建立剧本维度的信息分发渠道、评价评分和榜单体系,满足用户“以剧本找店”的决策路径。
值得指出的是,供给标准化是简化用户认知、帮助用户决策、促进供需匹配的重要抓手,标准化程度的高低对平台业务规模的大小有着决定性影响。具体到剧本杀行业,供给标准化建设是助力剧本杀业务持续增长的重要基础,而标准剧本库的搭建是剧本杀供给标准化的关键。由于基于规格如「城限」、背景如「古风」、题材如「情感」等剧本属性无法确定具体的剧本,但剧本名称如「舍离」则能起唯一标识的作用。因此,标准剧本库的搭建,首先是标准剧本名称的建设,其次是规格、背景、题材、难度、流派等标准剧本属性的建设。
综上,美团到店综合业务数据团队与业务同行,助力业务进行剧本杀的供给标准化建设。在建设过程中,涉及了剧本名称、剧本属性、类目、商户、商品、内容等多种类型的实体,以及它们之间的多元化关系构建。而知识图谱作为一种揭示实体及实体间关系的语义网络,用以解决该问题显得尤为合适。特别地,我们已经构建了 美团到店综合知识图谱(GENE,GEneral NEeds net) ,因此,我们基于GENE的构建经验快速进行剧本杀这一新业务的知识图谱构建,从0到1实现剧本杀标准化建设,从而改善供给管理和供需匹配,为用户、商户、平台三方创造出更大的价值。
二、解决方案
我们构建的GENE,围绕本地生活用户的综合性需求,以行业体系、需求对象、具象需求、场景要素和场景需求五个层次逐层递进,覆盖了玩乐、医美、教育、亲子、结婚等多个业务,体系设计和技术细节可见 美团到店综合知识图谱 相关的文章。剧本杀作为一项新兴的美团到店综合业务,体现了用户在玩乐上的新需求,天然适配GENE的体系结构。因此,我们将GENE覆盖至剧本杀新业务,沿用相同的思路来进行相应知识图谱的构建,以实现相应的供给标准化。
基于知识图谱来实现剧本杀标准化建设的关键,是以标准剧本为核心构建剧本杀知识图谱。图谱体系设计如下图1所示,具体地,首先在行业体系层进行剧本杀新类目的构建,挖掘剧本杀供给,并建立供给(包括商户、商品、内容)与类目的从属关系。在此基础上,在需求对象层,进一步实现标准剧本名称这一核心对象节点和其剧本属性节点的挖掘以及关系构建,建立标准剧本库,最后将标准剧本库的每个标准剧本与供给和用户建立关联关系。此外,具象需求、场景要素、场景需求三层则实现了对用户在剧本杀上的具象的服务需求和场景化需求的显性表达,这部分由于与剧本杀供给标准化建设的联系不多,在这里不做展开介绍。
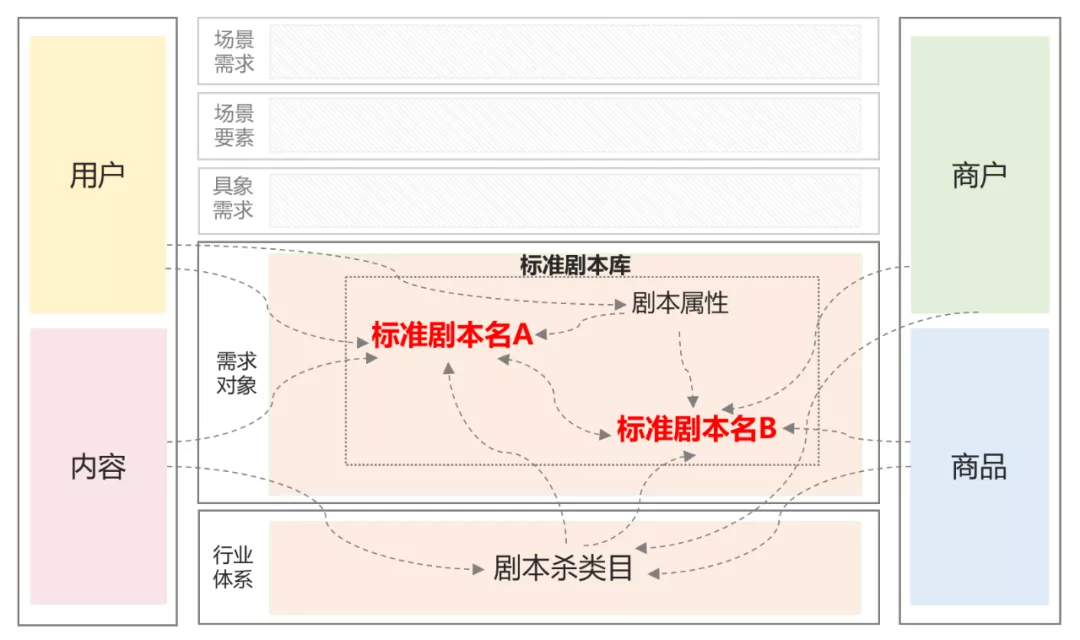
图 1
剧本杀知识图谱中用于供给标准化部分的具体样例如下图2所示。其中,标准剧本名称是核心节点,围绕它的各类标准剧本属性节点包括题材、规格、流派、难度、背景、别称等。同时,标准剧本之间可能构建诸如“同系列”等类型的关系,比如「舍离」和「舍离2」。此外,标准剧本还会与商品、商户、内容、用户之间建立关联关系。
我们基于剧本杀知识图谱的这些节点和关系进行供给标准化,在图谱构建过程中,包括了 剧本杀供给挖掘 、 标准剧本库构建 、 供给与标准剧本关联 三个主要步骤,下面对三个步骤的实现细节以及涉及的算法进行介绍。
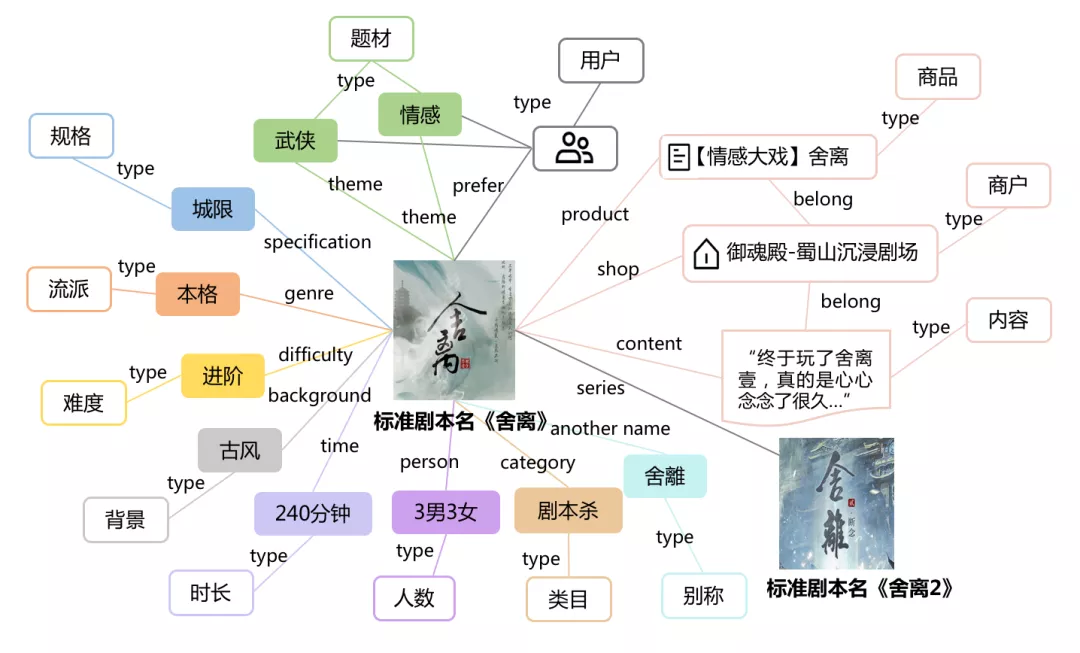 图 2
图 2
三、实现方法
3.1 剧本杀供给挖掘
剧本杀作为新兴的业务,已有的行业类目树中并没有相应的类目,无法直接根据类目获取剧本杀的相关供给(包括商户、商品和内容)。因此,我们需要首先进行剧本杀供给的挖掘,即从当前与剧本杀行业相近类目的供给中挖掘出剧本杀的相关供给。
对于剧本杀的商户供给挖掘,需要判断商户是否提供剧本杀服务,判别依据包括了商户名、商品名及商品详情、商户UGC三个来源的文本语料。这个本质上是一个多源数据的分类问题,然而由于缺乏标注的训练样本,我们没有直接采用端到端的多源数据分类模型,而是依托业务输入,采用无监督匹配和有监督拟合相结合的方式高效实现,具体的判别流程如下图3所示,其中:
- 无监督匹配 :首先构造剧本杀相关的关键词词库,分别在商户名、商品名及商品详情、商户UGC三个来源的文本语料中进行精确匹配,并构建基于BERT^[1]^ 的通用语义漂移判别模型进行匹配结果过滤。最后,根据业务规则基于各来源的匹配结果计算相应的匹配分数。
- 有监督拟合 :为了量化不同来源匹配分数对最终判别结果的影响,由运营先人工标注少量商户分数,用以表征商户提供剧本杀服务的强弱。在此基础上,我们构造了一个线性回归模型,拟合标注的商户分数,获取各来源的权重,从而实现对剧本杀商户的精准挖掘。
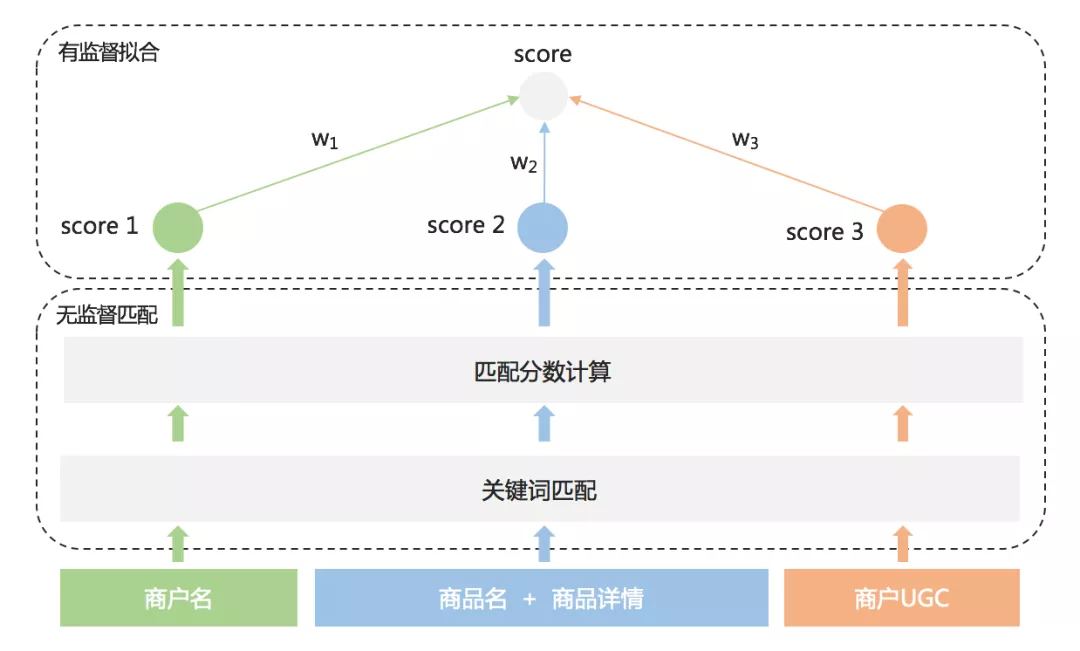
图 3
采用上述方式,实现了桌面和实景两种剧本杀商户的挖掘,准确率和召回率均达到了要求。基于剧本杀商户的挖掘结果,能够进一步对商品进行挖掘,并创建剧本杀类目,从而为后续剧本杀知识图谱构建及标准化建设打好了数据基础。
3.2 标准剧本库构建
标准剧本作为整个剧本杀知识图谱的核心,在剧本杀供给标准化建设中扮演着重要的角色。我们基于剧本杀商品相似聚合的方式,结合人工审核来挖掘标准剧本,并从相关发行方获取剧本授权,从而构建标准剧本库。标准剧本由两部分构成,一个是标准剧本名称,另一个是标准剧本属性。因此,标准剧本库构建也分为标准剧本名称的挖掘和标准剧本属性的挖掘两个部分。
3.2.1 标准剧本名称的挖掘
我们根据剧本杀商品的特点,先后采用了规则聚合、语义聚合和多模态聚合三种方法进行挖掘迭代,从数十万剧本杀商品的名称中聚合得到数千标准剧本名称。下面分别对三种聚合方法进行介绍。
规则聚合
同一个剧本杀商品在不同商户的命名往往不同,存在较多的不规范和个性化。一方面,同一个剧本名称本身就可以有多种叫法,例如「舍离」、「舍离壹」、「舍离1」就是同一个剧本;另一方面,剧本杀商品名除了包含剧本名称外,商家很多时候也会加入剧本的规格和题材等属性信息以及吸引用户的描述性文字,例如「《舍离》情感本」。所以我们首先考虑剧本杀商品的命名特点,设计相应的清洗策略对剧本杀商品名称进行清洗后再聚合。
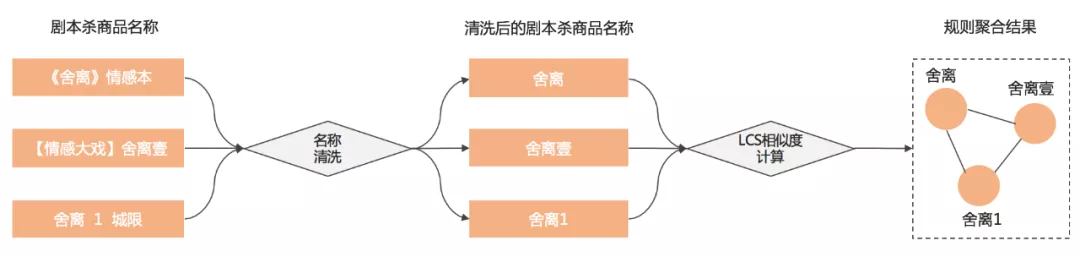
图 4
我们除了梳理常见的非剧本词,构建词库进行规则过滤外,也尝试将其转换为命名实体识别问题^[2]^ ,采用序列标注对字符进行“是剧本名”与“不是剧本名”两个类别的区分。对于清洗后的剧本杀商品名称,则通过基于最长公共子序列(LCS)的相似度计算规则,结合阈值筛选对其进行聚合,例如「舍离」、「舍离壹」、「舍离1」最后均聚在一起。整个流程如上图4所示,采用规则聚合的方式,能够在建设初期帮助业务快速对剧本杀商品名称进行聚合。
语义聚合
规则聚合的方式虽然简单好用,但由于剧本名称的多样性和复杂性,我们发现聚合结果中仍然存在一些问题:1)不属于同一个剧本的商品被聚合,例如「舍离」和「舍离2」是同一个系列的两个不同剧本,却被聚合在一起。2)属于同一个剧本的商品没有聚合,例如,商品名使用剧本的简称缩写(「唐人街名侦探和猫」和「唐探猫」)或出现错别字(「弗洛伊德之锚」和「佛洛依德之锚」)等情况时则难以规则聚合。
针对这上述这两种问题,我们进一步考虑使用商品名称语义匹配的方式,从文本语义相同的角度来进行聚合。常用的文本语义匹配模型分为交互式和双塔式两种类型。交互式是把两段文本一起输入进编码器,在编码的过程中让其相互交换信息后再进行判别;双塔式模型是用一个编码器分别给两个文本编码出向量,然后基于两个向量进行判别。
由于商品数量众多,采用交互式的方法需要将商品名称两两组合后再进行模型预测,效率较为低下,为此,我们采用双塔式的方法来实现,以Sentence-BERT^[3]^ 的模型结构为基础,将两个商品名称文本分别通过BERT提取向量后,再使用余弦距离来衡量两者的相似度,完整结构如下图5所示:
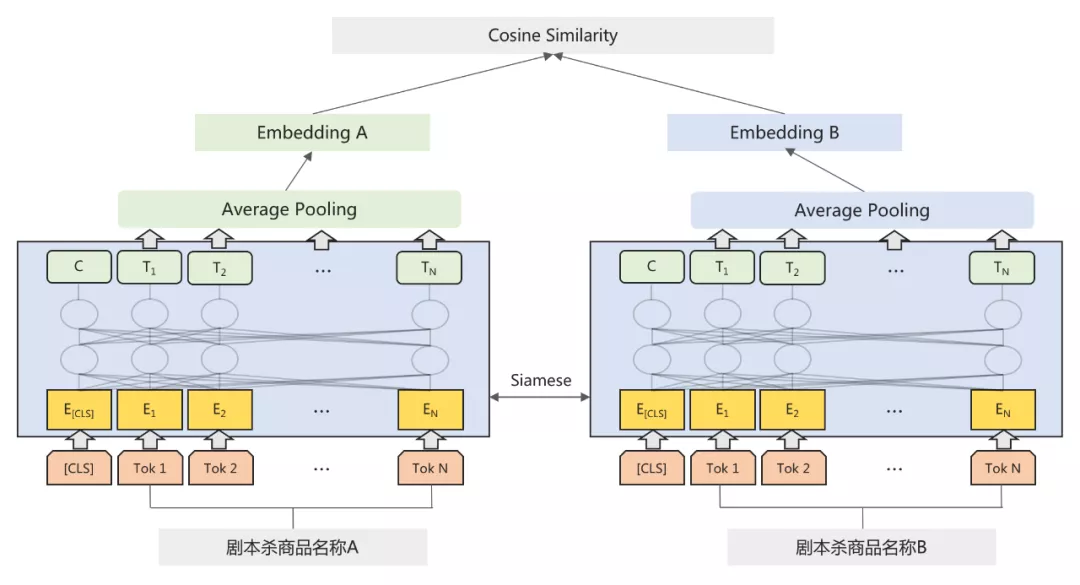
图 5
在训练模型的过程中,我们首先基于规则聚合的结果,通过同聚簇内生成正例和跨聚簇交叉生成负例的方式,构造粗粒度的训练样本,完成初版模型的训练。在此基础上,进一步结合主动学习,对样本数据进行完善。此外,我们还根据上文提到的规则聚合出现的两种问题,针对性的批量生成样本。具体地,通过在商品名称后添加同系列编号,以及使用错字、别字和繁体字替换等方式来实现样本的自动构造。
多模态聚合
通过语义聚合的方式实现了从商品名称文本语义层面的同义聚合,然而我们通过对聚合结果再分析后发现还存在一些问题:两个商品属于同一个剧本,但仅从商品名称的角度是无法判别。例如,「舍离2」和「断念」从语义的角度无法聚合,但是它们本质上是一个剧本「舍离2·断念」。虽然这两个商品的名称各异,但是它们的图像往往是相同或相似的,为此,我们考虑引入商品的图像信息来进行辅助聚合。
一个简单的方法是,使用CV领域成熟的预训练模型作为图像编码器进行特征提取,直接计算两个商品的图像相似度。为了统一商品图像相似度计算和商品名称语义匹配的结果,我们尝试构建一个剧本杀商品的多模态匹配模型,充分利用商品名称和图像信息来进行匹配。模型沿用语义聚合中使用的双塔式结构,整体结构如下图6所示:
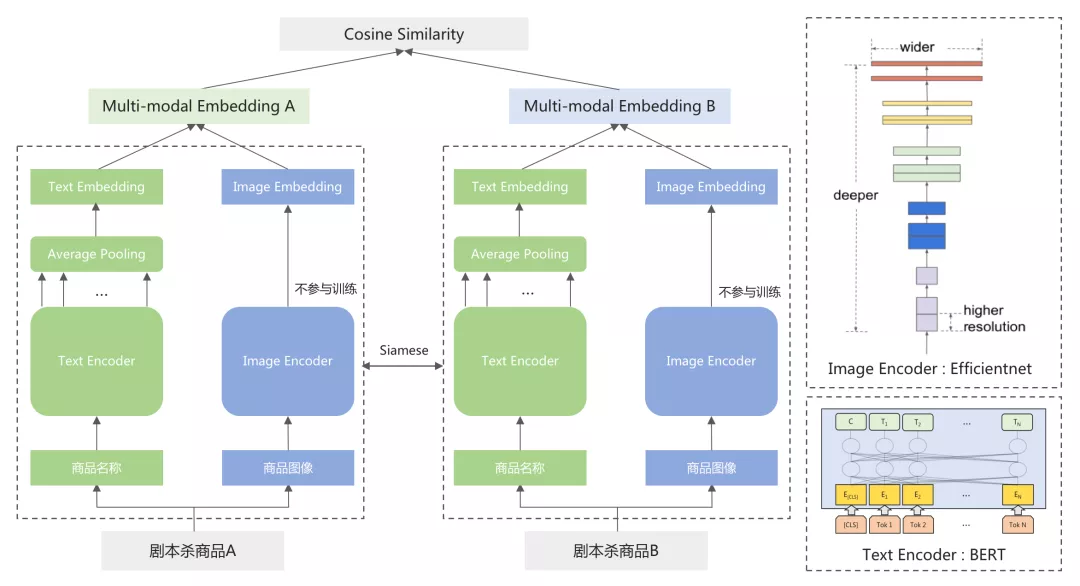 图 6
图 6
在多模态匹配模型中,剧本杀商品的名称和图像分别通过文本编码器和图像编码器得到对应的向量表示后,再进行拼接作为最终的商品向量,最后使用余弦相似度来衡量商品之间的相似度。其中:
- 文本编码器 :使用文本预训练模型BERT^[1]^ 作为文本编码器,将输出平均池化后作为文本的向量表示。
- 图像编码器 :使用图像预训练模型EfficientNet^[4]^ 作为图像编码器,提取网络最后一层输出作为图像的向量表示。
在训练模型的过程中,文本编码器会进行Finetune,而图像编码器则固定参数,不参与训练。对于训练样本构建,我们以语义聚合的结果为基础,以商品图像相似度来圈定人工标注样本的范围。具体地,对于同聚簇内商品图像相似度高的直接生成正例,跨聚簇交叉的商品图像相似度低的直接生成负例,而对于剩余的样本对则交由人工进行标注确定。通过多模态聚合,弥补了仅使用文本匹配的不足,与其相比准确率提升了5%,进一步提升了标准剧本的挖掘效果。
3.2.2 标准剧本属性的挖掘
标准剧本的属性包括了剧本的背景、规格、流派、题材、难度等十余个维度。由于商户在剧本杀商品上单的时候会录入商品的这些属性值,所以对于标准剧本属性的挖掘,本质上是对该标准剧本对应的所有聚合商品的属性的挖掘。
在实际过程中,我们通过投票统计的方式来进行挖掘,即对于标准剧本的某个属性,通过对应的聚合商品在该属性上的属性值进行投票,选择投票最高的属性值,作为该标准剧本的候选属性值,最后由人工审核确认。此外,在标准剧本名称挖掘的过程中,我们发现同一个剧本的叫法多种多样,为了对标准剧本能有更好的描述,还进一步为标准剧本增加了一个别称的属性,通过对标准剧本对应的所有聚合商品的名称进行清洗和去重来获取。
3.3 供给与标准剧本关联
在完成标准剧本库构建后,还需要建立剧本杀的商品、商户和内容三种供给,与标准剧本的关联关系,从而使剧本杀的供给实现标准化。由于通过商品和标准剧本的关联关系,可以直接获取该商品对应商户和标准剧本的关系,所以我们只需要对商品和内容进行标准剧本关联。
3.3.1 商品关联
在3.2节中,我们通过聚合存量剧本杀商品的方式来进行标准剧本的挖掘,在这个过程中其实已经构建了存量商品和标准剧本的关联关系。对于后续新增加的商品,我们还需要将其和标准剧本进行匹配,以建立两者之间的关联关系。而对于与标准剧本无法关联的商品,我们则自动进行标准剧本名称和属性的挖掘,经由人工审核后再加入标准剧本库。
整个商品关联流程如下图7所示,首先对商品名称进行清洗再进行匹配关联。在匹配环节,我们基于商品和标准剧本的名称及图像的多模态信息,对两者进行匹配判别。
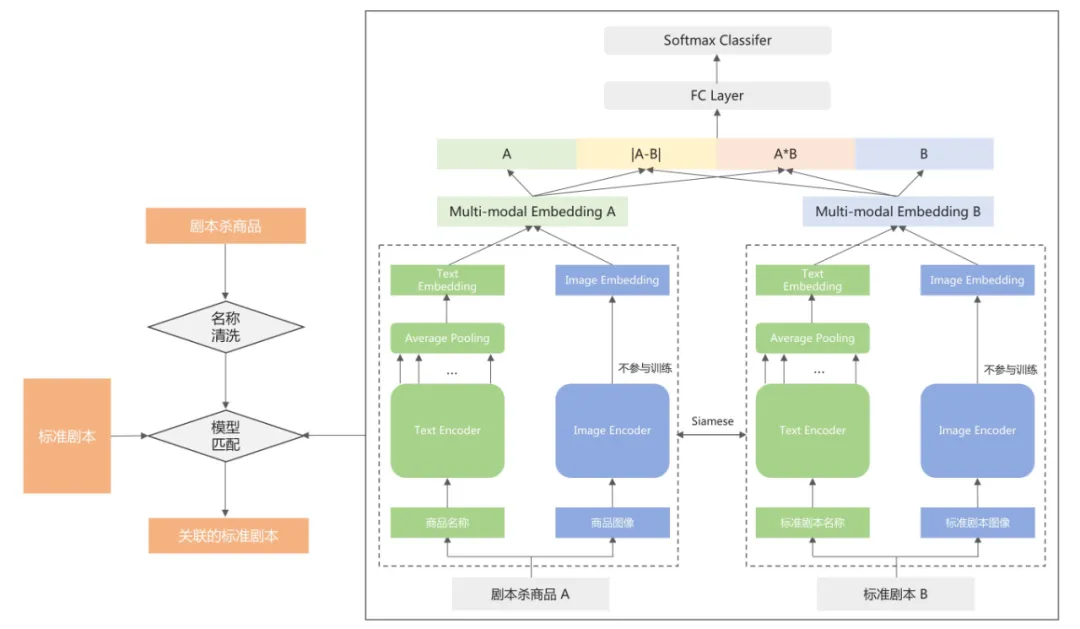
图 7
与商品之间的匹配不同,商品与标准剧本的关联不需要保持匹配的对称性。为了保证关联的效果,我们在3.2.1节的多模态匹配模型的结构基础上进行修改,将商品和标准剧本的向量拼接后通过全连接层和softmax层计算两者关联的概率。训练样本则直接根据存量商品和标准剧本的关联关系构造。通过商品关联,我们实现了绝大部分剧本杀商品的标准化。
3.3.2 内容关联
对于剧本杀内容关联标准剧本,主要针对用户产生的内容(UGC,例如用户评价)这一类型的内容和标准剧本的关联。由于一段UGC文本通常包含多个句子,且其中只有部分句子会提及标准剧本相关信息,所以我们将UGC与标准剧本的匹配,细化为其子句粒度的匹配,同时出于效率和效果的平衡的考虑,进一步将匹配过程分为了召回和排序两个阶段,如下图8所示:
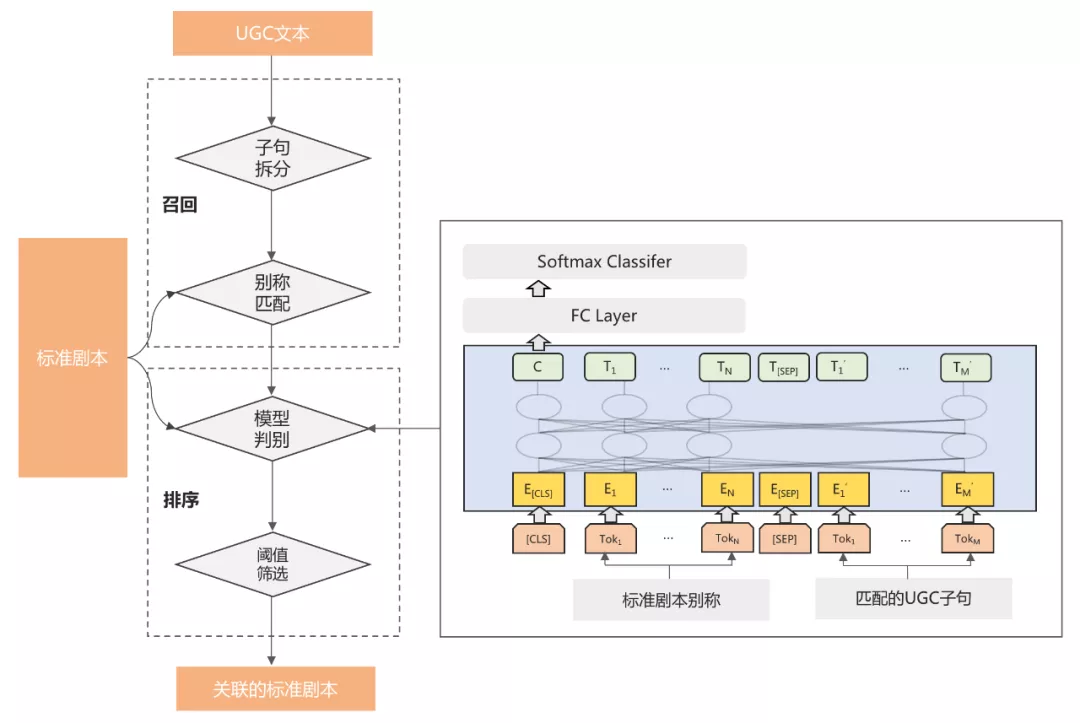
图 8
在召回阶段,将UGC文本进行子句拆分,并根据标准剧本名称及其别称,在子句集合中进行精确匹配,对于匹配中的子句则将进入到排序阶段进行精细化的关联关系判别。
在排序阶段,将关联关系判别转换为一个Aspect-based的分类问题,参考属性级情感分类的做法^[5]^ ,构建基于BERT句间关系分类的匹配模型,将实际命中UGC子句的标准剧本别称和对应的UGC子句用[SEP]相连后输入,通过在BERT后增加全连接层和softmax层来实现是否关联的二分类,最后对模型输出的分类概率进行阈值筛选,获取UGC关联的标准剧本。
与上文中涉及的模型训练不同,UGC和标准剧本的匹配模型无法快速获取大量训练样本。考虑到训练样本的缺乏,所以首先通过人工少量标注数百个样本,在此基础上,除了采用主动学习外,我们还尝试对比学习,基于Regularized Dropout^[6]^ 方法,对模型两次Dropout的输出进行正则约束。最终在训练样本不到1K的情况下,UGC关联标准剧本的准确率达到上线要求,每个标准剧本关联的UGC数量也得到了大幅提升。
四、应用实践
当前剧本杀知识图谱,以数千标准剧本为核心,关联百万供给。剧本杀供给标准化建设的结果已在美团多个业务场景上进行了初步的应用实践。下面介绍具体的应用方式和应用效果。
4.1 类目构建
通过剧本杀供给挖掘,帮助业务识别出剧本杀商户,从而助力剧本杀新类目和相应剧本杀列表页的构建。剧本杀类目迁移、休闲娱乐频道页的剧本杀入口、剧本杀列表页均已上线,其中,频道页剧本杀ICON固定第三行首位,提供了中心化流量入口,有助于建立统一的用户认知。上线示例如图9所示((a)休闲娱乐频道页剧本杀入口,(b)剧本杀列表页)。
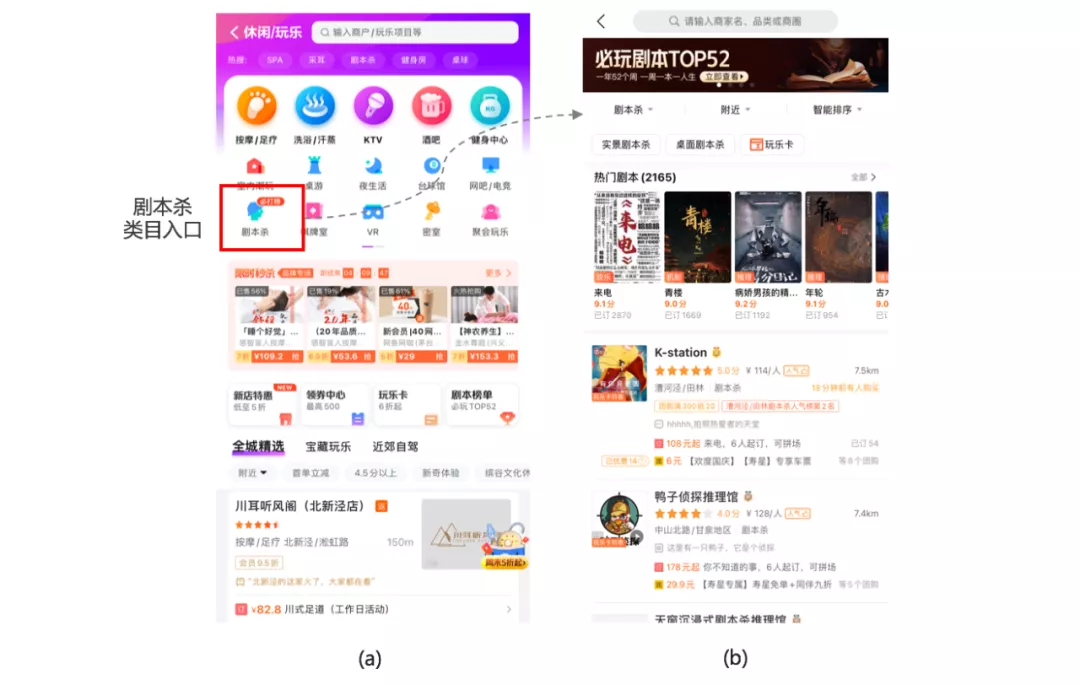
图 9
4.2 个性化推荐
剧本杀知识图谱包含的标准剧本及属性节点,以及其与供给和用户的关联关系,可应用于剧本杀各页面的推荐位。一方面应用于剧本列表页热门剧本推荐(图10(a)),另一方面还应用于剧本详情页的商品在拼场次推荐(图10(b)左)、可玩门店推荐(图10(b)左)和相关剧本推荐模块(图10(b)右)。这些推荐位的应用,帮助培养了用户在平台找剧本的心智,优化了用户认知和选购体验,提高了用户和供给的匹配效率。
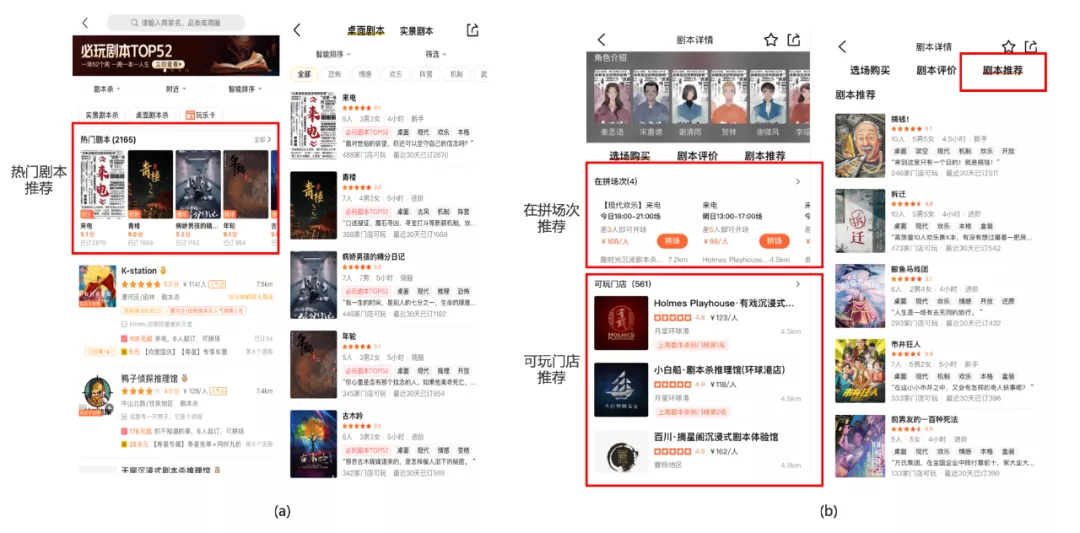
图10
以剧本列表页的热门剧本推荐模块为例,剧本杀知识图谱包含的节点和关系除了可以直接用于剧本的召回,还可以进一步在精排阶段进行应用。在精排中,我们基于剧本杀知识图谱,结合用户行为,参考Deep Interest Network(DIN)^[7]^ 模型结构,尝试对用户访问剧本的序列和访问商品的序列进行建模,构建双通道DIN模型,深度刻画用户兴趣,实现剧本的个性化分发。其中商品访问序列部分,通过商品与标准剧本的关联关系将其转为为剧本序列,与候选剧本采用Attention方式进行建模,具体模型结构如下图11所示:
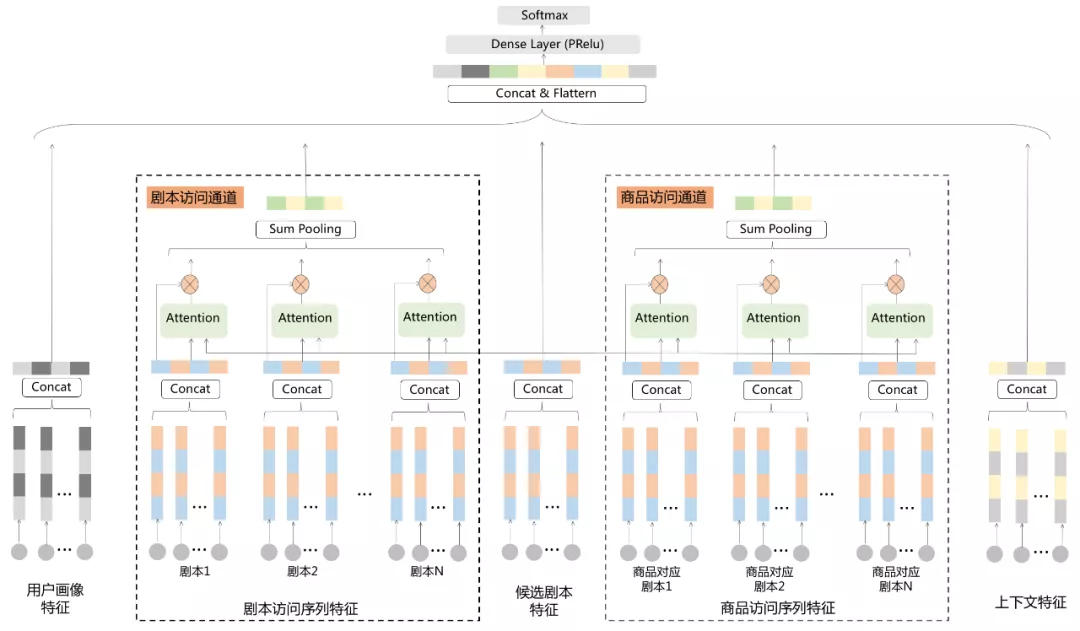
图 11
4.3 信息外露和筛选
基于剧本杀知识图谱中的节点和关系,在剧本杀列表页和在剧本列表页增加相关标签筛选项,并外露剧本的属性和关联的供给信息,相关应用如下图12所示。这些标签筛选项和信息的外露,为用户提供了规范的信息展示,降低了用户决策成本,更加方便了用户选店和选剧本。
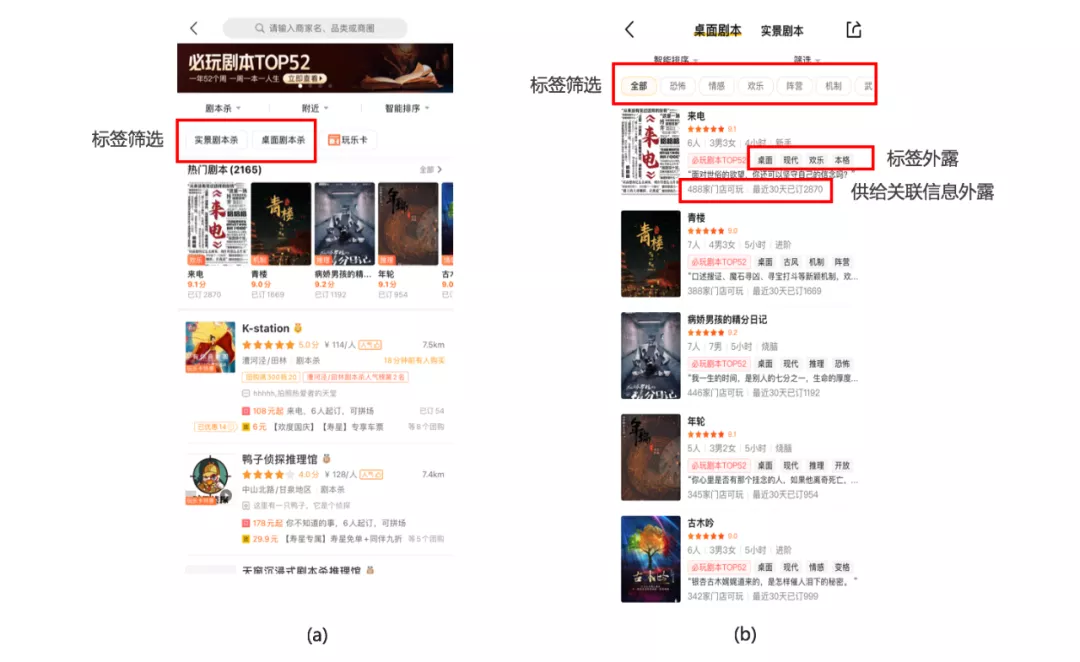
图 12
4.4 评分和榜单
在剧本详情页,内容和标准剧本的关联关系参与到剧本的评分计算中(图13(a))。在此基础上,基于剧本维度,形成经典必玩和近期热门的剧本榜单,如图13(b)所示,从而为用户的剧本选择决策提供了更多的帮助。
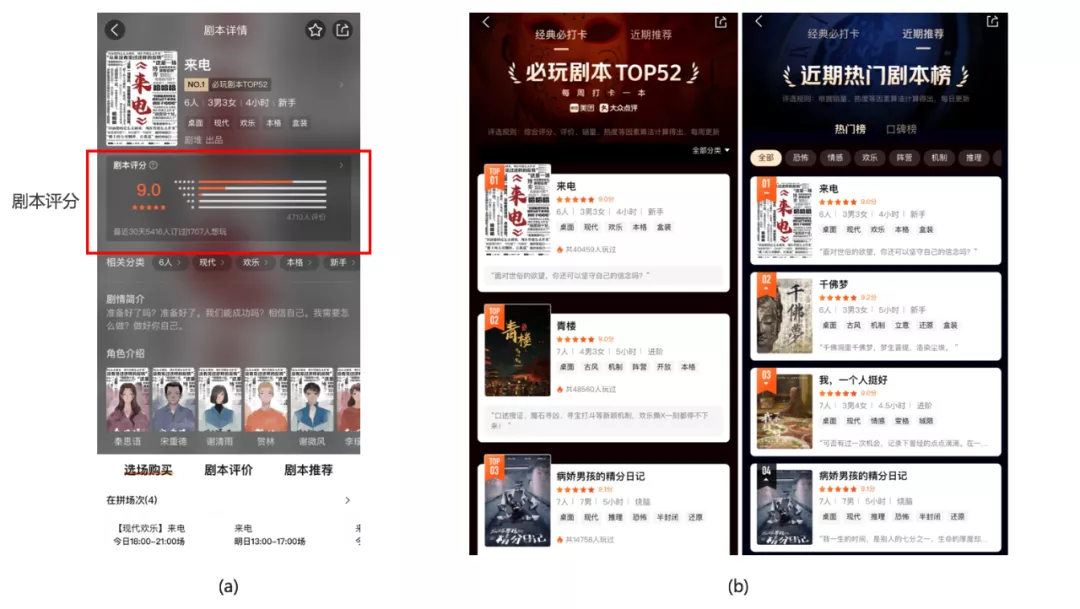
图 13
五、总结展望
面对剧本杀这一新兴行业,我们快速响应业务,以标准剧本为核心节点,结合行业特点,通过剧本杀供给挖掘、标准剧本库构建、供给与标准剧本关联,构建相应的知识图谱,从0到1逐步推进剧本杀的供给标准化建设,力求以简单而有效的方法来解决剧本杀业务的问题。
目前,剧本杀知识图谱已在剧本杀多个业务场景中取得应用成果,赋能剧本杀业务持续增长,显著提升了用户体验。在未来的工作中,我们也将不断进行优化和探索:
- 标准剧本库的持续完善 :优化标准剧本名称和属性以及相应的供给关联关系,保证标准剧本库的质与量俱佳,并尝试引入外部的知识补充当前的标准化结果。
- 剧本杀场景化 :当前剧本杀知识图谱主要以“剧本”这类用户的具象需求对象为主,后续将深入挖掘用户的场景化需求,探索剧本杀和其他行业的联动,更好的助力剧本杀行业的发展。
- 更多的应用探索 :将图谱数据应用于搜索等模块,在更多的应用场景中提升供给匹配效率,从而创造出更大的价值。
参考文献
[1] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[2] Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.
[3] Reimers N, Gurevych I. Sentence-bert: Sentence embeddings using siamese bert-networks[J]. arXiv preprint arXiv:1908.10084, 2019.
[4] Tan M, Le Q. EfficientNet: Rethinking model scaling for convolutional neural networks[C]//International Conference on Machine Learning. PMLR, 2019: 6105-6114.
[5] Sun C, Huang L, Qiu X. Utilizing BERT for aspect-based sentiment analysis via constructing auxiliary sentence[J]. arXiv preprint arXiv:1903.09588, 2019.
[6] Liang X, Wu L, Li J, et al. R-Drop: Regularized Dropout for Neural Networks[J]. arXiv preprint arXiv:2106.14448, 2021.
[7] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1059-1068.
作者简介
李翔、陈焕、志华、晓阳、王奇等,均来自美团到店平台技术部到综业务数据�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BE%8E%E5%9B%A2%E5%9F%BA%E4%BA%8E%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E7%9A%84%E5%89%A7%E6%9C%AC%E6%9D%80%E6%A0%87%E5%87%86%E5%8C%96%E5%BB%BA%E8%AE%BE%E4%B8%8E%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


