美团搜索中查询改写技术的探索与实践
杨俭 宗宇 谢睿等 美团技术团队 稿
1. 引言
在搜索场景中,由于用户搜索词Query和检索文本Document之间存在大量表述不一的情况,在文本检索框架下,此类文本不匹配导致的漏召回问题严重影响着用户的体验。对这类问题业界一般有两种方案:用户端拓展用户的查询词——即查询改写,或Document端拓展文档关键词——即Document标签。本文主要介绍前一种解决漏召回的方案:查询改写(Query Rewriting,或称为查询扩展Query Expansion)。查询改写的应用方式是对原始Query拓展出与用户需求关联度高的改写词,多个改写词与用户搜索词一起做检索,从而用更好的表述,帮用户搜到更多符合需求的商户、商品和服务。
在美团搜索的技术架构下,查询改写控制召回语法中的文本,命名实体识别(Named Entity Recognition,简称NER)^{[1]} 控制召回语法中的检索域,意图识别控制召回的相关性以及各业务的分流和产品形态,这是最为核心的三个查询理解信号。查询改写策略在美团搜索的全部流量上生效,除扩展用户搜索词外,在整个美团搜索技术架构中作为基础语义理解信号,从索引扩展、排序特征、前端高亮等多方面影响着用户体验。对搜索召回结果中的无结果率、召回结果数以及搜索点击率等指标,也有着直接且显著的影响。
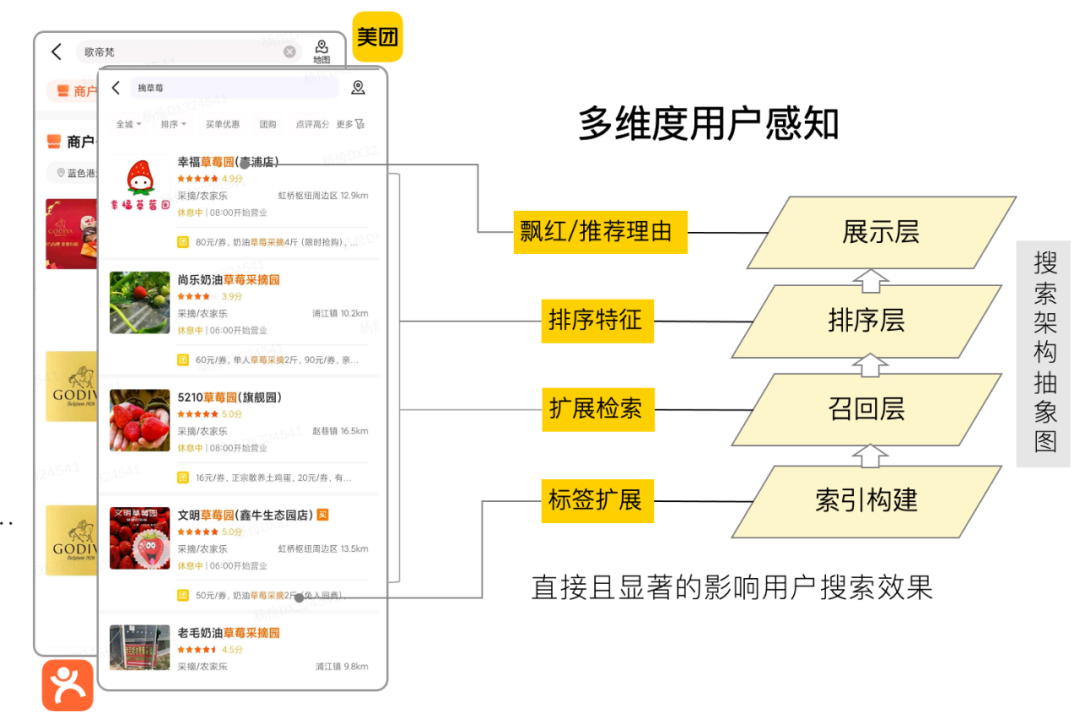
图1 查询改写信号在美团搜索上的使用
本文会介绍美团搜索场景下查询改写这一任务上的迭代经验,内容主要分为三个部分。第一部分会对查询改写任务在美团搜索场景下的挑战进行简单的介绍;第二部分会介绍查询改写任务上整体技术栈建设的实践经验第三部分是总结与展望。目前,业界在文本召回策略方面公开的分享较少,希望本文能对从事搜索、广告、推荐中召回相关工作的同学有所启发或者帮助。
2. 背景与挑战
2.1 美团搜索场景下查询改写信号的使用方式
在美团的搜索场景下,查询改写主要用于解决以下四类语义鸿沟导致的漏召回问题:
- 语义拓展:主要是同义词、下位词以及常见的大小写数字和繁简转化等,例如“理发”、“剪发”、“造型”、“发艺”、“美发”、“剪头”等等。
- 用户表达和商家表达上的Gap:非语言上的同义。如用户表述口语化“学吉他”,商户描述书面化“吉他培训”;用户输入不完全匹配商户名:“希尔顿大酒店”(商家更常见的描述为“希尔顿酒店”)。
- 场景拓展:例如“摘草莓”在美团的搜索场景下,用户基于对平台的认知对应需求是“草莓园”。
- 其他漏召回问题:部分的多字少字、纠错等问题,如“房屋扫”对应“家政保洁”的需求;理论上查询改写可以通过增加改写词解决所有漏召回问题,诸如“冬日四件套”包括“冰糖葫芦、烤地瓜、炒栗子、热奶茶”这类有时效性的网红概念,也可以通过改写进行解决。
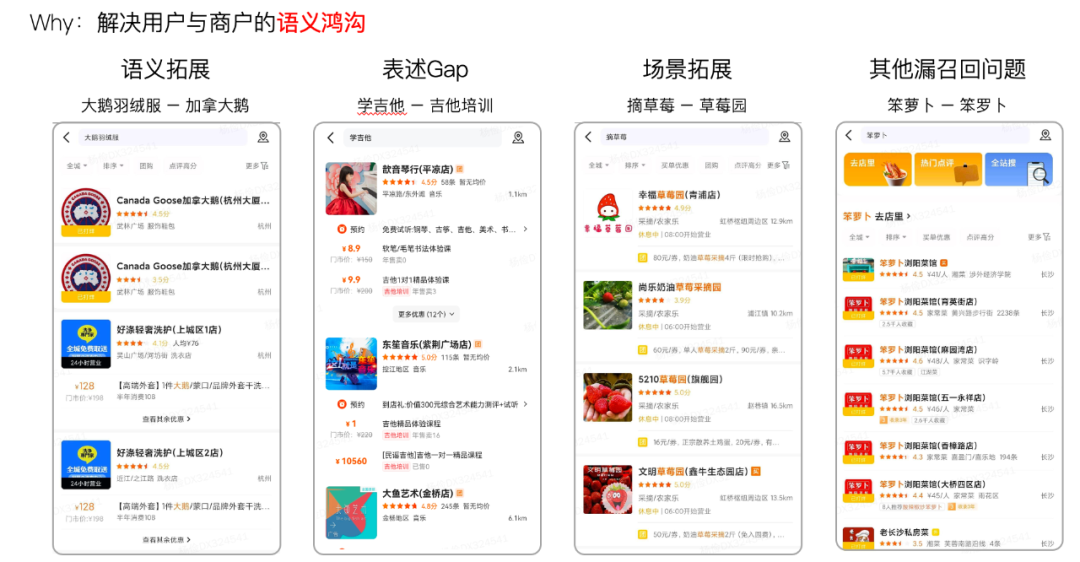
图2 查询改写在美团App搜索上应用的例子
2.2 美团搜索场景下查询改写信号的难点和挑战
搜索是在用户搜索词以及供给两方面约束下尽可能提高用户触达效率以及商业化指标,而美团的搜索场景增加了“地域”第三个约束。具体的行业对比如下图所示:
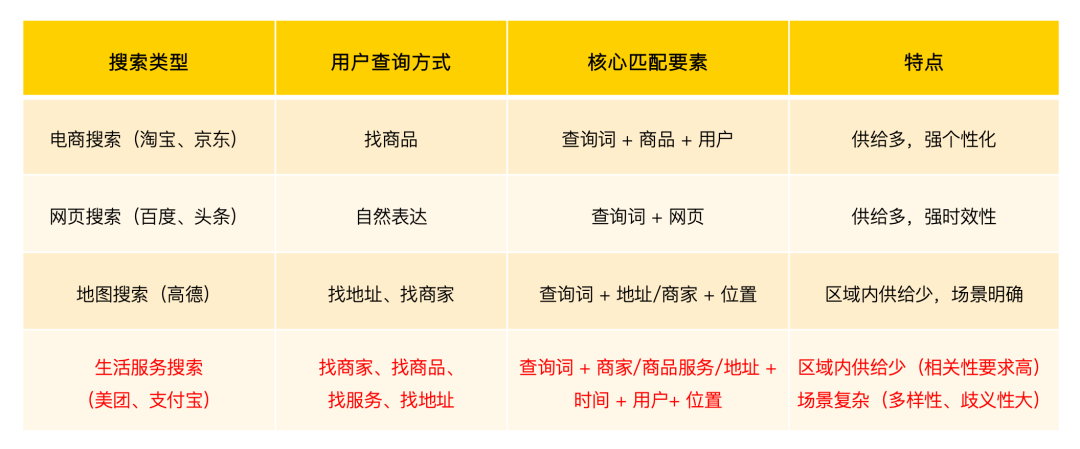 图3 美团搜索场景在与其他搜索场景的异同点
图3 美团搜索场景在与其他搜索场景的异同点
通过对比行业内搜索场景可以发现,美团的搜索场景下用户需求和服务商家大多是面向本地,而生活服务领域业务非常细碎,相对用户对生活服务某个领域的需求而言,本地化供给相对较少。
与此同时,美团搜索还聚合了多种履约形式的结果,搜索结果中会有团购、外卖、买菜、优选等业务的自然结果聚块,以及在本地相关业务均无结果时的推荐结果聚块。在有限的曝光位置下,每个自然结果聚块的不相关的结果会挤占其他聚块的收益,因此不能依赖排序解决相关性问题。这就要求美团搜索场景的查询改写在多个业务场景下要强相关且高效率,算法层面需要解决覆盖问题、准确率问题以及多业务问题。以该要求为出发点,在具体算法迭代时查询改写还面临以下两方面挑战:
① 对用户的查询面临着复杂的需求场景
- 语言歧义情况多 :短Query增加了歧义的可能性,例如在美团场景下“剪个头发”是一个商户名,不能改写为“理发”;相同Query在不同城市含义不同,如“工大”在不同城市指代的学校不同。
- 认知关联性 :用户的搜索天然有对美团平台“找店”的认知,需要类似“配眼镜”等同于“眼睛店”的场景关联知识。
- 场景多 :随业务的发展,客观需求增多,查询改写承接的场景越来越多、越来越精细,目前,已经接入餐饮、到综、酒店旅游、外卖、商品、广告等多个业务场景。
② 对平台的供给需要兼顾供给建设特点和发展阶段
- 美团商户大部分不会做关键词SEO(Search Engine Optimization):文本不匹配导致的漏召回问题更为严重,对改写的需求很大。
- 商户的外露形式导致真实交互意图不明确:大部分商户同时提供多种菜品、商品、团单服务,例如,一个音乐培训机构往往提供多种乐器的培训课程。
- 与业务特点和发展阶段强关联:美团是一个聚合生活服务方方面面的平台,并且各业务对改写的需求不同,对于一些重交易的业务来说弱相关的改写可以接受,而对一些重体验的业务来说,对改写的要求更严格,需要一定的区分度。
3. 技术选型
下图4总结了目前查询改写迭代的技术框架以及对应解决的问题。我们在各个子核心模块如离线候选挖掘算法探索、语义关系判别模型、向量化召回、在线生成改写词有较为深入的探索。除信号本身迭代,在信号的使用上也通过改写分级信号加入排序、召回相关性等做联动取得了不错的线上收益。
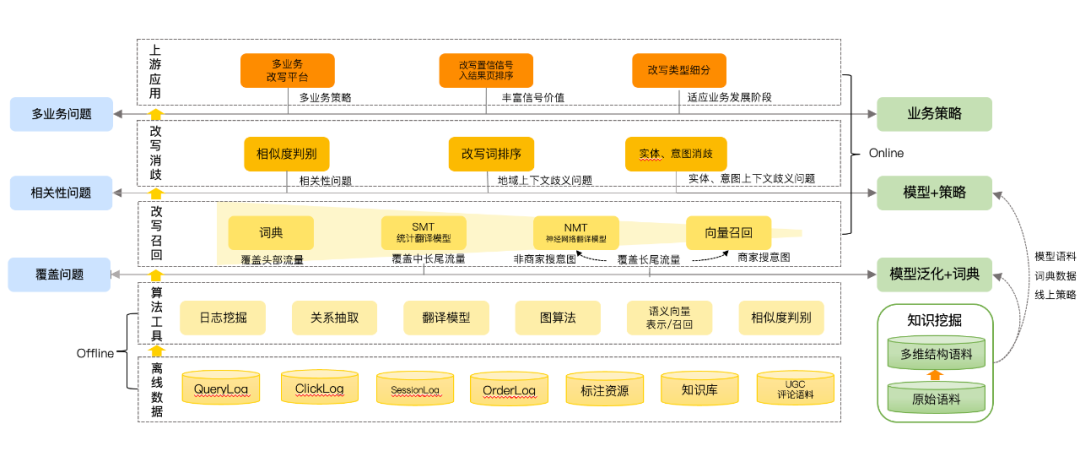
图4 查询改写技术迭代框架
下面,我们将从离线到在线全面的介绍查询改写任务下的各模块技术的迭代。
3.1 原始语料挖掘
高质量的数据可以显著改善头部流量的改写效果,并且决定了后续模型性能的天花板。在候选集生成方面,基于搜索日志的挖掘、基于翻译思想、基于图计算、基于Embedding都是工业界和学术界常用的方法;在候选集过滤判别方面则有句间关系分类、Embedding相似度计算等方法。我们结合美团搜索场景总结了各个方法的优缺点,并在每个挖掘算法组件都结合了用户行为和语义两方面信息,下文将对离线语料挖掘做具体介绍。
3.1.1 搜索日志挖掘候选语料
搜索日志挖掘是工业界常用的同义词获取手段,挖掘的主要方向有:
- 用户搜索后点击共同商户: 利用两个点击相同Document的Query构建相关关系。这种相关关系可以挖掘到大量词对,但这种简单的假设缺点也很明显,点击共现的Query可能有不同程度的漂移。在美团场景下提供综合服务的店铺很多,会有两种类型团单大量出现在相同商户下的情况,挖掘到“拔牙”→“补牙”这种有语义漂移噪声的可能性更大。此外,这个方法依赖现有搜索的效果,无法挖掘到无结果Query的改写词。
- 从搜索Session中挖掘: Session是指用户在一段时间内“打开App→多个页面的浏览,多个功能的点击、支付等行为→离开App”的一次交互过程。该方法是利用用户在整次App访问过程中连续输入的Query来构建相关关系。Session挖掘依赖搜索结果程度低,因此泛化能力更强。但相应的缺点是,Session时间切割不好确定,并且序列中每个搜索词之间的关联方式比较隐蔽,甚至可能没有相关关系。需要结合业务特点设计时长、引入点击(例如一次Session在有点击前的搜索词都无点击,可能是有具体需求未被满足)等条件做挖掘。
- 词对齐: 词对齐借鉴了翻译的思想,具体方法是将Query召回的商户标题去除了商户名部分后剩余的部分做为平行语料,设计一些对齐策略如字对齐(包含相同的字)、拼音对齐(相同拼音)、结构对齐(分词后词位置相同)。该方法的缺点是强依赖于现有搜索的效果。
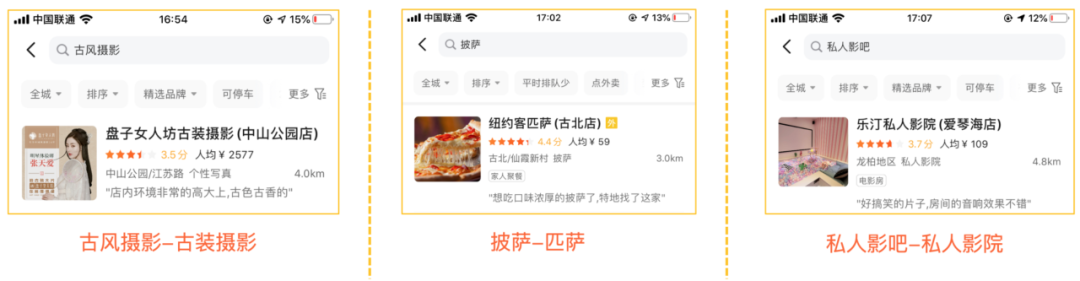
图5 查询改写词对齐挖掘方法示意图
- 商户/商品内SEO: 商品场景下,部分商家上架时会做SEO,如:“加长 狗狗牵引绳 狗绳 狗项圈 遛狗泰迪金毛宠物大型中型小型犬 狗链子”。这一类挖掘来源的缺点是有比较大的噪声,并且噪音关联性较大比较难分辨(存在上下位类型、同位词类型、作弊等噪音类型)。
以上简单方法均可以挖掘到大量相关词对,但基于的假设和设计的规则都很简单,优缺点都非常明显。下面介绍几种优化的挖掘方法。
3.1.2 基于图方法挖掘
图方法如经典的协同过滤以及Graph Embedding等,在推荐场景中通过利用用户和Document的关系构建图结构来推荐更相似的Document。在搜索场景下用户的搜索Query以及平台的Document通过点击、下单等方式同样也可以建模成图结构。在美团搜索的使用场景下,我们对构图方式做了如下两个改进:① Query和Document之间的边权重使用Query点击Document的点击次数和点击率进行Wilson平滑的结果,而不只是Query点击Document的次数,从而提高相关性;② 在二部图中,将用户在Session中自行改写的Query也视为Document节点,与点击的Document标题一起进行构图,从而提高挖掘的数据量。
我们早期用SimRank++算法^{[2]} 验证了构图方式两个优化点的可行性,SimRank++算法是一种同构信息网络中的相似度量算法,它的思想是:如果两个用户相似,则与这两个用户相关联的物品也类似;如果两个物品类似,则与这两个物品相关联的用户也类似。该算法的优点是可以使用Spark进行大规模全局优化,并且边权重可以根据需要调整。优化构图后人工评测SimRank++优化前后查询改写数据量提升了约30%,同时准确率从72%提升到83%。
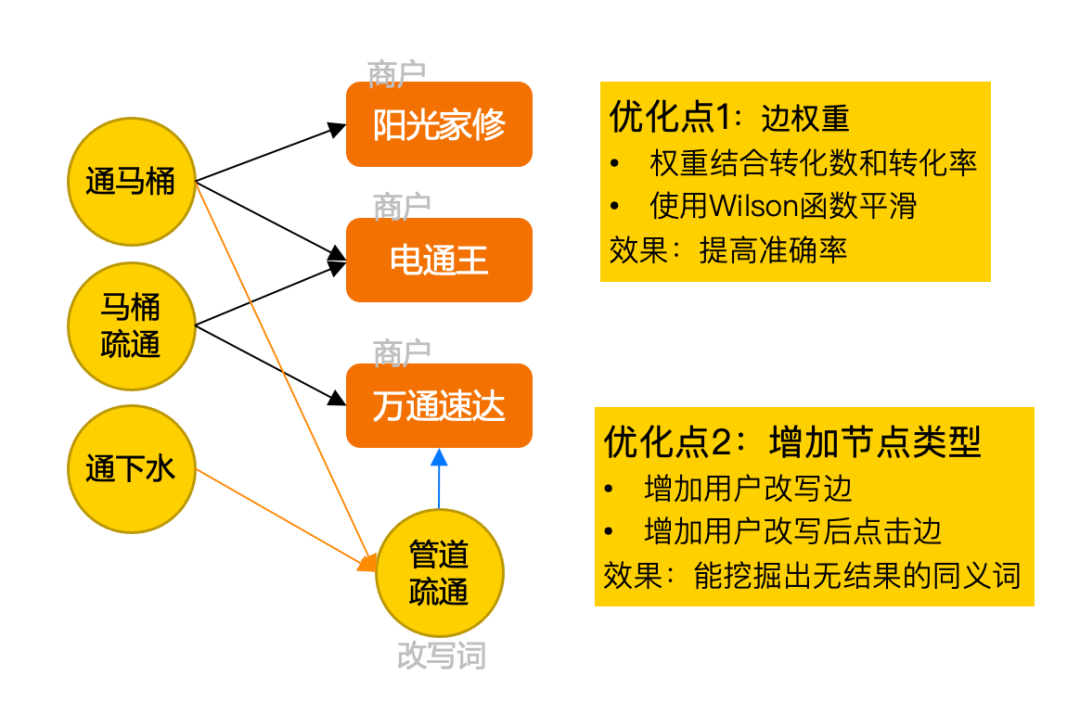
图6 改进构图方法的图方法挖掘
后续,我们用相同的思路尝试了其他图神经网络模型(GNN)。DeepWalk^{[3]} 在构造Sentence上下文采用随机游走的方法。随机游走一般是将Query之间的关系建立成图,通过从一个点随机游走,建立起多条路径,每条路径上的Query组成一个句子,再使用上下文相关原理训练Query的Embedding。随机游走的优点就是关系具有传递性,和Query共现不同,可以将间接关系的Query建立联系。少量的数据经过游走能够产生够多的训练数据。例如在Session1中用户先搜索Query1后改为Query2再查询,在Session2中用户先搜索Query2后改为Query3再查询,共现的方法无法直接建立Query1和Query3的关联关系,而随机游走能够很好地解决。在改写词挖掘任务中,基于图的方法相较于直接从搜索日志挖掘词对的方法,挖掘的效率和准确率均有所提升。
3.1.3 基于语义向量挖掘
在word2vec^{[4]} 后,Embedding的思想迅速从NLP领域扩散到几乎所有机器学习的领域,号称“万物皆可Embedding”,只要是一个序列问题均可以从上下文的角度表示其中的节点。此外,Embedding在数据稀疏性表示上的优势也有利于后续深度学习的探索。将Query Embedding到低维语义空间,通过计算Embedding间的相似度查找相关词,在挖掘相似词的任务中是常见且易于实践的挖掘方法。除了简单的在用户评论等语料上训练大规模词向量外(即图7a),在实践中还尝试了以下两种构建上下文的方法:
- 通过Query召回商户构建Doc2Vec^{[5]} :通过Query召回或点击的商户作为上下文训练Embedding表征Query(即图7b)。由于美团场景下同一商户提供的服务、商品繁多,该方法在没有考虑Query本身类目意图的情况下,噪声比较大。
- 通过用户Session构建改写序列^{[6]} :通过一个Session序列作为上下文训练Embedding表征Query(即图7c)。该方法的优点是有效的利用了用户自行换词的限制条件,挖掘覆盖率和准确率都相对更高。
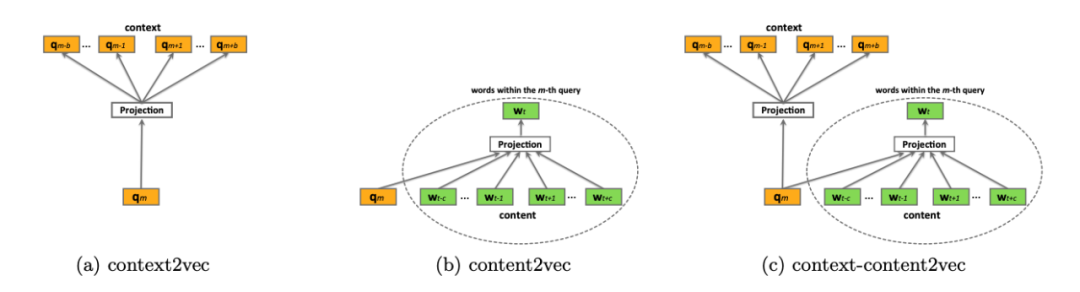
图7 词向量相似词挖掘中上下文的构造方法
设计不同的上下文结构得到Embedding后,为了进一步提高准确率后续的基本的步骤是:① 训练语料通过分词后,利用fastText训练Query的词向量,fastText训练时考虑了字级别的Ngram特征,可以将未登录Query的字、词Embedding进行简单求和或求平均,解决OOV(Out-Of-Vocabulary)的问题;② 在目标词表中,用词向量表示该词;③ 利用LSH,查找向量cosine相似度高于一定阈值候选词,或使用DSSM双塔模型^{[7]} ,通过有监督训练提高精度;④ XGBoost结合特征工程进一步过滤。
BERT^{[8]} 自提出以来深刻改变了自然语言处理领域的研究应用生态,我们尝试了一些使用BERT Embedding的方法,其中比较有效的是通过Fine-Tuning的Sentence-BERT^{[9]} 或SimCSE^{[10]} 模型获取词向量。
BERT计算语义相似度是通过句间关系下游任务完成的,方法是用特殊字符将两个句子连接成一个整体做分类,带来的问题是使用时需要两两组合造成大量冗余计算,因此不适合做语义相似度搜索或无监督聚类任务。Sentence-BERT借鉴了孪生网络模型的框架,将不同的句子输入到两个参数共享的BERT模型中,获取到每个句子的表征向量,该向量可以用于语义相似度计算,也可以用于无监督的聚类任务。
我们实践的方法基本与Sentence-BERT思想大致相同,使用下图中左图的方法构造有监督的改写对训练数据,用右图的方法在不同意图类型的历史搜索Query进行向量计算。
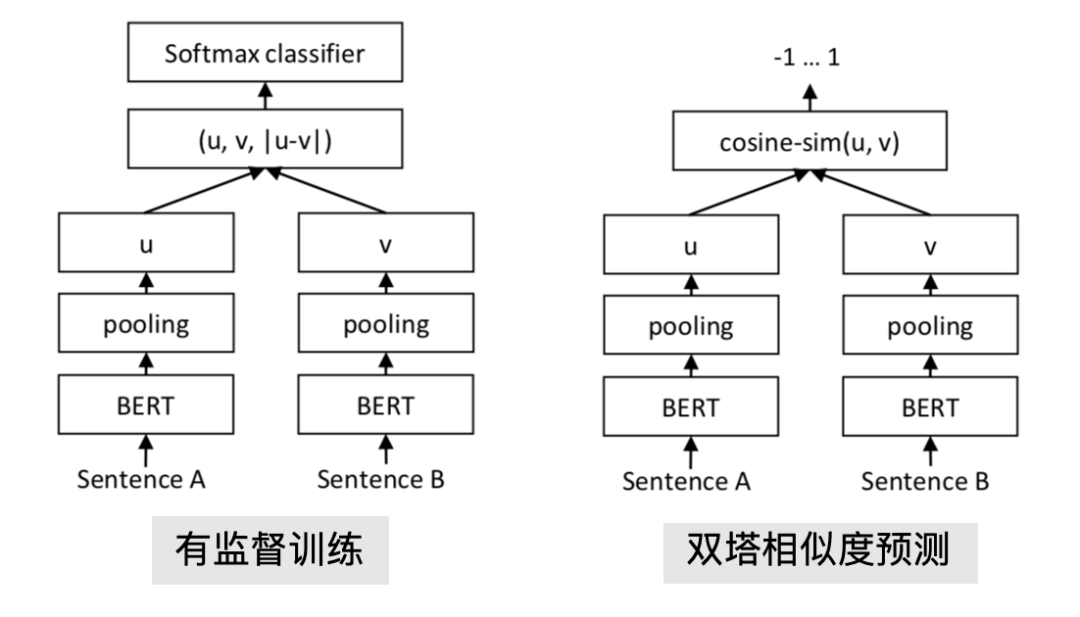
图8 Sentence-BERT训练和预测结构示意图
相比于前面的方法,双塔结构BERT的方法捕捉语义的能力更强,并且有监督训练的方式结合一些模型结构上的调整,能够减少各类漂移严重的Case。此外Sentence-BERT不依赖统计特征和平行语料,在任何业务上均可以比较方便的迁移和Fine-Tuning,对一些冷启动的业务场景非常友好。在此基础上利用Faiss^{[11]} 向量检索方法构建离线检索流程,能够支持在亿级别候选池中高效检索,通过该方法构建的改写候选能达到千万甚至亿级别数据量,且实测准确率较高。近几年的对比学习等方法在文本表示领域不断刷新榜单,从向量构建和向量交互方式等方面均可做持续的探索。
3.2 语义判别模型
3.2.1 BERT语义判别模型
从以上多个途径的挖掘方法中可以得到千万级别的相似词对,但仍然有大量语义漂移的Case,其中近义词漂移问题最为严重。原因是Embedding基于相同上下文的假设太强,而近义词的上下文很相似,包括在商户和商户类目的上下文(一个商家通常会提供多种服务)以及用户Session换词的上下文相似(用户在某一类意图下多次浏览意图下的概念),因此很容易挖掘出“大提琴”→“小提琴”这种同位词Case,并且加大了从用户点击行为或意图分类等其他维度过滤恶劣Case的难度。
而图方法由于侧重于关联性而忽略了语义漂移问题,在一些搜索量小的Query节点上边关系较少,导致比较如“电动车上牌”→“电动车专卖”等Case,并且相似度分数没有绝对意义。为了从语义维度过滤类似的疑难Case,我们通过引入BERT的语义信息来解决这类问题。BERT使用预训练+微调的思路来解决自然语言处理问题,模型特点除网络更深外,双向语言模型的设计思路可以更好的利用上下文信息避免同位词漂移问题。下面介绍查询改写任务中对BERT句间关系任务做的一些探索。
在BERT提出之初,我们用挖掘数据和少量人工标注数据在美团场景语料预训练的MT-BERT^{[12]}做句间关系任务的两阶段Tuning。而在实践中发现在现有挖掘数据上训练得到的模型在某些Case区分度不高,如我们之前提到的“大提琴”→“小提琴”以及“葡萄酒”→“葡萄”这类字面编辑距离不大的Case。因此如何构建高质量的正负例数据是逼近BERT在查询改写任务性能上限的关键。
我们首先尝试的是一种协同训练的方法,协同训练是一种半监督的方法,它关注的问题是如何在有标记数据较少时利用大量的未标记数据来改善模型性能。考虑到离线挖掘数据噪音较大,我们探索了NMT(Nature Machine Translation)和MT-BERT协同训练的方法,达到同时提高数据质量和模型质量的效果,整体系统的框架图如下:
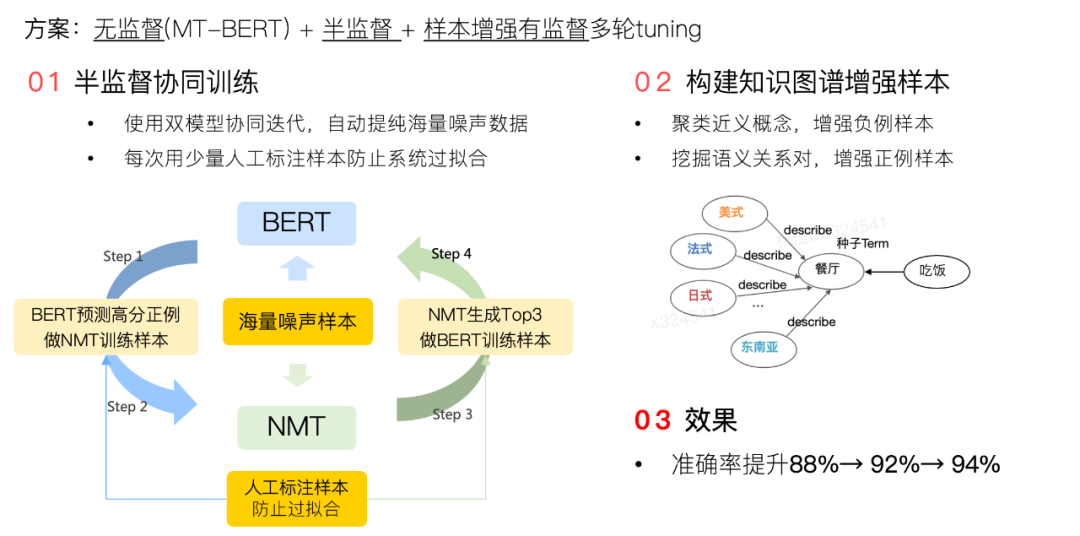
图9 NMT-BERT协同训练流程图
整个协同训练的流程是:
- Step1 BERT判别模型产出NMT训练数据: 将经过离线挖掘平行语料Fine-Tuning后的MT-BERT模型在全量待预测数据上预测,设置一定阈值后返回高质量正例交给NMT。
- Step2 NMT Fine-Tuning: 在BERT返回的高质量正例中加入部分人工标注数据,作为NMT模型训练数据进行训练,获得NMT模型和指标。
- Step3 NMT产出判别模型训练数据: 随机抽选一定数量的Query用NMT模型生成TopN个改写词对,产出下一阶段BERT判别模型Fine-Tuning数据。
- Step4 BERT判别模型Fine-Tuning: 用Step3生成的数据取头部K个词对作为正例,尾部X个词做负例,对BERT判别模型做Fine-Tuning。
- 循环以上步骤直至收敛:循环迭代上述步骤,直到双方模型在评测集上收敛。
在实际实验中,协同训练在迭代3轮后收敛,在人工构建的Benchmark集合上前两轮BERT和NMT效果提升明显,最终的效果明显好于直接使用训练样本+人工标注数据Tuning。
协同训练可以有效解决“葡萄酒”→“葡萄”等字面文本相似度较高的Case,但噪声数据频率较高的“马琴”→“二胡”这类字面匹配不明显,上下文比较相似的同位词Case仍然存在。这里使用了关系抽取的方法针对性的挖掘了这类疑难Case。例如针对同位词负例的挖掘使用了一些Pattern的方法,挖掘UGC中提到“如A、B、C等”类似的句式,经过过滤后构造高质量的同位词负例数据。经过负例数据的优化,模型准确率得到进一步提升。
最终,BERT语义判别模型的训练过程分为四个阶段:① 无监督:使用美团场景的语料在BERT模型基础上进行Continue Train;② 半监督:使用算法挖掘的数据进行Co-training Tuning;③ 样本增强监督:使用人工挖掘的高质量负例Tuning;④ 使用人工标注的数据做最终的Tuning。最终模型的准确率达到了94%以上,解决了大量语义漂移Case。
3.2.2 针对商品的BERT语义判别模型
随着美团业务场景的丰富,电商类型的搜索和供给流量占比开始变高,商品领域的误改写问题开始增多。通过分析用户Query和改写的Case发现上述模型不能很好的迁移到商品领域中,主要的原因除了训练数据的覆盖外,商品搜索场景下用户搜索商品对应改写的要求是同一事物,对改写的准确率要求更高,而是商户场景用户表达的是需求,对应改写的要求是表述需求相同即可。此外从Document角度看,商品召回字段较单一,不存在商户搜索时一个商户对应多种服务的问题,场景简化后算法空间是比较大的。因此单独对商品领域的改写判别模型做了优化:
- 训练数据构建 :商品改写模型首先要解决的是没有训练样本的问题。使用SPU共现、向量召回等规则方法,持续跟进质检标注数据等人工方法,通过类目组合、点击、UGC构建困难负例等挖掘方法,最终构建了数百万高质量训练数据。
- 数据增强 :在模型训练的采样过程中使用Random Negatives、Batch Negatives、Hard Sample Negatives等方法,增强模型对误改写的识别能力和鲁棒性。
- 模型结构优化 :对Baseline的句间关系BERT做了模型结构上的探索,尝试了R-Drop^{[13] 和Child-tuning^{[14]} 提升模型表达能力。总体F1提升了2.5PP。
- 图向量融合 :尝试基于搜索结果构造图模型的方法,结合线上实际搜索结果增强判别能力。通过对线上召回商品标题做实体识别,并将各个实体作为节点与Query一同构图,以预测Query到召回实体的边类型为目标,使用GCN^{[15]} 和GAT^{[16]} 方法产出的Graph Embedding通过向量Pooling的方法融入BERT句间关系判别模型中,最终F1提升1.6PP,解决了“宝宝”改写为“娃娃”误召回“玩具娃娃”这类歧义性问题。
3.3 在线服务
通过以上几种挖掘手段,结合判别模型进一步提高准确率后能够得到数据量约千万级别的高质量改写对。但线上词典的应用方式泛化效率低下,下文会阐述如何通过线上模型进一步提高查询改写的整体效果。
美团查询改写线上有以下几种方案:(1)高精度的词典改写;(2)较高精度的模型改写(统计翻译模型+XGBoost排序模型);(3)覆盖长尾Query的语义NMT(神经网络翻译模型)端到端生成改写;(4)覆盖商户名搜索流量的在线向量化检索。
词典改写是业界通用的方法,需要注意的是同义词替换需要结合上下文信息,比如“百姓”和“平民”单独看是可以同义的,但在“百姓大药房”和“平民大药房”中则是一个严重漂移的改写,在对词典改写类型分类后结合实体识别信息设计策略可以解决大部分此类问题。下面的篇幅将对美团搜索查询改写的后三种在线模块分别做介绍。
3.3.1 SMT(统计翻译模型)
通过离线挖掘改写Query的方式存在的问题是覆盖不足,但是一个Query里包含的短Term可以进行改写,例如生活服务领域常见的例子:“XX坏了”=“维修XX”。从这个角度思考可以将查询改写任务抽象为一个典型的机器翻译任务。可设定f为用户搜索词,e为目标改写词,SMT整体可以抽象为一个噪声信道模型,根据贝叶斯公式求解SMT公式推导:
\tilde{e} = arg \underset{e \in e^*}{\,max\,}p(e|f) = arg \underset{e \in e^*}{\,max\,}p(e|f) \frac{p(f|e)p(e)}{p(f)} = arg \underset{e \in e^*}{\,max\,}p(f|e)p(e)
其中得到的两个概率p(f|e)即为概率转移模型,p(e)为语言模型。由此将改写模型拆分为两部分,结合已有的千万级别平行语料得到词对齐候选,分别训练Decode模型(概率转移模型)和语言模型。在实际的构建过程中针对遇到的Case,对模型的细节做了一些定制优化:
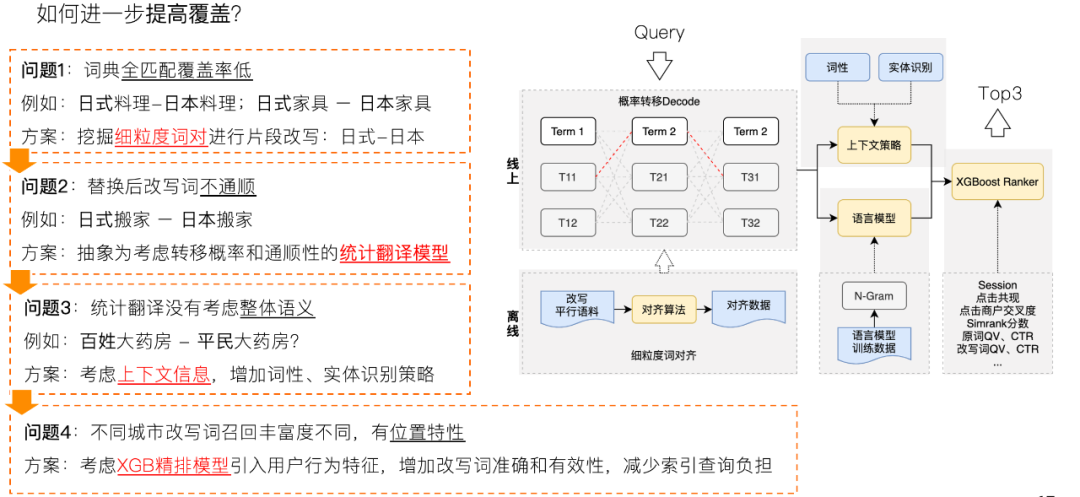
图10 SMT改写流程示意图
- 对齐字典过滤: 由于平行语料的噪音,以及对齐产生的错误数据,我们使用离线训练的BERT语义判别模型结合规则(例如两个Term分布的类目交叉熵,是否互相包含等维度的特征)对生成后的对齐词表做了过滤优化。
- 结构化Decode模型: SMT的Decode采用的是BeamSearch算法,BeamSearch的参数主要分为两部分:(1)映射概率的参数,在对齐词表的score基础上单独添加了一些衡量两个Term之间的相似度特征;(2)转移概率的参数,在语言模型基础上添加了Term结合度的信息。
- 排序模型: 改写的最终目的是召回更多相关且优质的商户、商品和服务,因此在得到大量的SMT生成的改写结果后,仍然要考虑两方面的问题,一方面是语义相关性,另一方面是有效性。解决的方案是引入XGBoost排序模型,使用的特征同时考虑语义相关性和改写词召回结果维度的业务统计效果。在语义相关性方面使用的特征包括原词改写词各自的点击特征、文本特征;候选对的文本编辑距离、文本语义相似度分数、Session转移次数以及时间间隔等。在有效性方面引入了地域和流行性两方面信息,包括在Document和Document类目两个维度的曝光、点击、下单等共现特征。排序模型取Top3的优质改写,减少了搜索检索索引压力的同时能有效保证改写词召回当地优质相关结果。
最终,线上的整体框架类似业界经典的的Learning to Rewriting框架^{[17-18]} ,模型上线后对线上的有改写流量覆盖占比有近12%的提升,在QV_CTR等指标上获得了非常可观的收益。
3.3.2 NMT(神经网络翻译模型)
在线上引入同义词替换、SMT统计翻译改写后,线上有改写的流量覆盖率接近70%。但在中长尾Query中仍然有覆盖不足的情况,主要由以下两类问题导致:
- 分词粒度引入的挖掘效率问题:无论是同义词替换或是基于更短Term的SMT翻译改写,都对分词结果和候选有一定依赖。而中文同义的粒度往往只是某一个字的变换,例如“学XX”→“培训XX”,且在单字维度的改写容易造成Case,同时不可能将所有的“学XX”挖掘出来达到提升覆盖的目的。
- 语义相近不能对齐的复杂Query改写问题:用户在输入一些自然语言的Query时,如:“哪里有便宜的手机卖”在商家侧则是“手机优惠”,基于词片段候选的方法泛化能力较弱,不能解决类似的问题。
从以上问题出发,需要一个不依赖候选的生成式改写模型,我们考虑使用深度语义翻译模型NMT来解决这类问题。
2016年年底Google公布的神经网络机器翻译(GNMT)^{[19]} 宣告了神经网络机器翻译性能超过1989年的IBM机器翻译模型(SMT,基于短语的机器翻译模型)。推动这一巨大发展就是引入Attention机制^{[20]} 的Sequence to Sequence(Seq2Seq)的端到端模型。但在实际的使用中发现,NMT生成的改写词存在不符合语义(生僻或不通顺)以及改写有语义漂移两个问题,导致在线上新增改写的有效比例低,甚至会导致严重的漂移Case。因此要引入NMT做改写必须结合搜索的使用场景对以上两个问题做优化,目标是生成无意图漂移、能够产生实际召回影响的改写词。基于以上问题分析和思考,通过引入环境因素引导NMT生成更高质量的改写是大方向目标,从这个角度出发我们调研了强化学习的方法。
强化学习的过程是一个智能体(Agent)采取行动(Action)从而改变自己的状态(State)获得奖励(Reward)与环境(Environment)发生交互的循环过程。我们希望借助强化学习的思想,将预训练的NMT改写模型作为Agent,在强化学习迭代的过程中其生成的改写(Action)通过搜索系统(Environment)产生最终的曝光和点击(Reward)来指导NMT优化模型参数(State)。
经过进一步调研,我们参考了Google QA系统^{[21]} 以及知乎的工作^{[22]} ,即通过强化学习的方法,把搜索系统当做一个Environment,改写模型当做Agent,从而将大搜的结果质量考虑进来。但由于美团场景下的排序与位置、用户等排序因素强相关,将整个大搜作为Environment将改写词召回向前排序的反馈机制不可借鉴,并且请求在线排序会导致训练速度慢等一系列工程问题。结合NMT实际的表现,考虑优先保障生成改写的语义相似度,使用大搜召回日志结合BERT语义判别模型做Environment,目标为原词改写词在搜索系统交互中的商户集合的交叉度和自然语义相似度。最终整体的框架图如下所示:
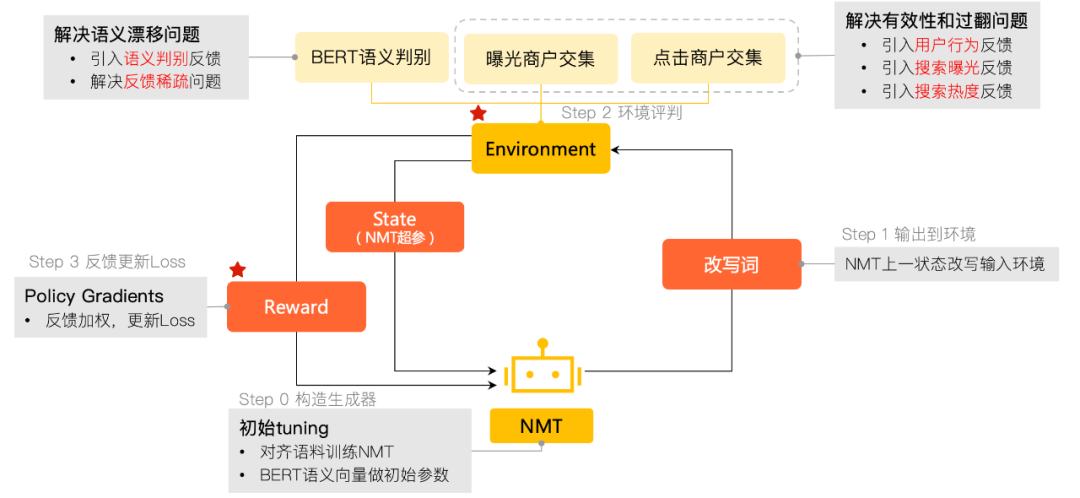
图11 强化学习NMT训练流程和NMT模型结构图
下面详细介绍算法模块设计和流程:
Step 0 预训练NMT生成器
- 模型 :生成器使用预训练的NMT,模型结构是经典Seq2Seq模型。考虑到实际搜索场景下用户搜索词较短,使用了基于字切分的初始化Embedding,并且在Encoder-Decoder之间引入Attention,Attention机制可以很好地替代在SMT里面的对齐机制,非常符合查询改写的任务背景。此外,我们还使用了通过美团语料Fine-Tuning的BERT初始化Encoder,这样做的好处是引入更多的语义信息且模型收敛较快。
- 预训练数据 :预训练在整个系统中是非常重要的,由于使用离线历史日志模拟搜索系统,在强化学习过程中若生成器产生的改写词都非常生僻会导致Reward稀疏,最终系统不能收敛或效果没有优化。因此,我们在数据方面做了以下优化,考虑到NMT做改写的优势是语义泛化,我们从上述离线挖掘得到的数据去除了商户名地址等专有名词别名;在整体的训练中强化学习会对改写词和原词一样的结果做“惩罚”,带来的后果是部分专有名词如一些固定叫法的商品名等改写为有漂移的其他商品,因此在训练数据中加入了少量商品名的原词改写对,限制模型在这一类Query的泛化能力。
- 模型优化 :查询改写中的短Query翻译在实践中发现容易出现过翻(不断重复翻译某一些词语)和漏翻(翻译过程中会漏掉一些词语)问题。过翻的原因有两种,一是由于训练语料噪音或训练不充分,二是翻译过程中出现OOV的情况下,由于NMT是序列问题,后面的翻译过程会损失信息,从而导致过翻。解决过翻问题的方法除了丰富和优化训练数据外,还引入了Coverage(覆盖率)机制。即为每个源端词维护一个Coverage Vector来表示这个词语被翻译的程度,在解码过程中该覆盖率信息会传入Attention Model,从而使它能够更加关注未被翻译的源端词。漏翻的问题则是由于训练语料中有大量一对多的改写对,导致NMT无法学习到准确的对齐信息,通过在强化学习中引入编辑距离来解决这类问题。
Step 1 原词改写词输入环境计算反馈
从用户角度出发,好的改写词应该是语义相同、改写词新增召回的商户与原词召回商户很相似,并且用户在点击的商户分布上应该是比较一致的。此外,从改写的有效性出发,改写词需要是通顺的、有较丰富召回结果的热门搜索词。从上面的分析中得出,满足相似度高的改写应返回正反馈,不相似、不通顺改写词应返回负反馈。因为将环境分为两个部分,离线搜索日志模拟搜索系统以及BERT语义判别系统,分别从搜索系统和用户的交互以及语义判别两个角度对产生的Action做出反馈。
- 离线搜索日志模拟搜索系统 :离线搜索日志中包含一次搜索中,搜索系统最终曝光的商户列表以及用户在列表上的点击行为,通过收集较长一段时间的搜索日志,我们假设历史Query足够丰富,储存历史Query的召回商户ID列表和用户点击商户ID列表两张宽表,在强化学习过程中通过在这两个宽表上检索出原词和NMT生成改写词的历史召回商户ID列表和历史点击商户ID列表,可以将这个过程比作检索召回和点击两个维度的One-Hot向量表征检索词,通过计算这两个向量的重合度得到召回相似度和用户意向相似度的数学表征。通过这种方法我们看似得到一个较合理的环境输出,但仍存在几个问题,一是原词不在历史Query中的特征缺失情况,我们对NMT改写到原词设计了较小的固定正反馈解决该问题;二是改写词不在历史Query中的情况,我们认为改写词不同于原词不应该是生僻的,因此对查找不到改写词的情况给与了一个固定的负反馈。此外还对相似度的计算做了Sigmod平滑,捕捉更大的变化梯度。
- BERT模拟语义判别系统 :有了模拟搜索系统为什么还需要语义判别?原因是用户在商户列表页的点击不一定完全代表其意图。一方面是前面提到的,一个商户可能具有多个语义并列的服务。如大部分口腔医院都提供“拔牙”和“补牙”的服务,在这两个搜索词的商户召回和点击交叉是很大的;另一方面在现有的搜索系统中可能存在错误的改写,尤其是改写词是热门搜索词或原词的子串时,用户的点击可能因为图片或商户比较热门产生点击,这样的点击并不代表用户的原始意图。因此在强化学习系统引入语义判别的信息,从而避免这类搜索系统和用户行为遗漏的问题,并且也可以在一定程度上解决Reward稀疏问题。
Step 2 打分器对环境产生的反馈做权重加和 。
根据环境给的反馈分数基于权重叠加后生成归一化的Reward,这里根据业务场景和实际问题做了多轮迭代,设计了加权的反馈打分器,分别给搜索、用户行为、语义判别、字面匹配度几个方面不同的权重,最终归一化到0-1之间作为最终的反馈。
Step 3 迭代打分器结果到生成器继续训练的loss中 。
根据打分器的分数将Reward叠加在NMT Fine-Tuning的模型Loss中,这里对比了几种方法,其中Google用Batch的平均句子长度对加和平均的Loss做归一化叠加方式效果最好。
在强化学习的Query语料上重复1~3步骤,直到模型收敛。
通过上线后的效果分析,引入强化学习的NMT可以解决语义类型改写(挑筋→拨筋,劳动争议→劳动纠纷,柴火烧→柴火灶),生僻的简写(法甜店→法式甜点,足指→足部指甲),输入错误导致的简写(瑜教练→瑜伽教练,桑洗浴→桑拿洗浴),自然语言类型Query去词(染发剂哪里买→染发剂,祛斑哪家医院好→祛斑医院)。
总体来说,强化学习能够在生成改写词的质量上有一定的提升,尤其在相关性方面引入了搜索系统和用户的反馈后改写的精度和效率有较大提升,离线评估准确率由69%提升至87%,在线上提高复杂长尾Query改写覆盖的同时不会引入影响用户体验的恶劣BadCase,在整体美团搜索长尾Query的QV_CTR等指标上取得了较好的收益。
3.3.3 在线向量化召回
向量化召回随着Sentence-BERT,SimCSE等向量表示方法近期在学术界的刷榜,逐渐有越来越多的公司开始尝试大规模应用起来,如Facebook^{[23]} 、淘宝搜索^{[24]} 、京东^{[25]} 等。得益于预训练模型表达能力强等特点,对比传统的DSSM等方法有更好的泛化能力和准确度。
在改写场景使用向量召回还有两个优点:一方面Query和改写词较短且长度相近,并且语义和类型较一致,参数一致的双塔即可保证一定的准确率;另一方面改写词从候选池中检索出来而不是生成,可以控制改写词的有效性以及限制语义类型。通过分析美团搜索的漏召回问题发现商户名精搜漏召回问题较大,此外考虑到美团场景下,商户提供的服务丰富、Document端文本较长意图较分散的问题,我们先在商户意图下文本不匹配导致的少无结果问题中尝试了向量化召回(下文称为“模糊改写”)并取得了非常好的效果,下面将进行详细介绍。
首先对这类Case做归纳总结,认为模糊改写要解决的问题是:用户有明确商户意图时,因文本不匹配,或NER切分错误导致无结果、漏召回问题,这类Case用户意图明确但Query表述模糊。例如:搜索“九匠和牛烧肉”未召回POI“九匠精酿烤肉”、搜索“宁波莱斯小火车”未召回POI“宁波火车来斯主题公园”。这类问题混合了多种文本变体,难以在现有结构化召回框架内解决。
确定问题的边界后,总结这类Case有以下特点:(1)Query是多变的,但商户名召回池是有限且确定的;(2)Query和商户名文本长度较短,非常适合向量化召回算法;(3)可以摆脱现有布尔检索召回框架的限制,避免简单文本匹配导致漏召回。因此我们制定了以向量召回为基础的模糊改写流程:
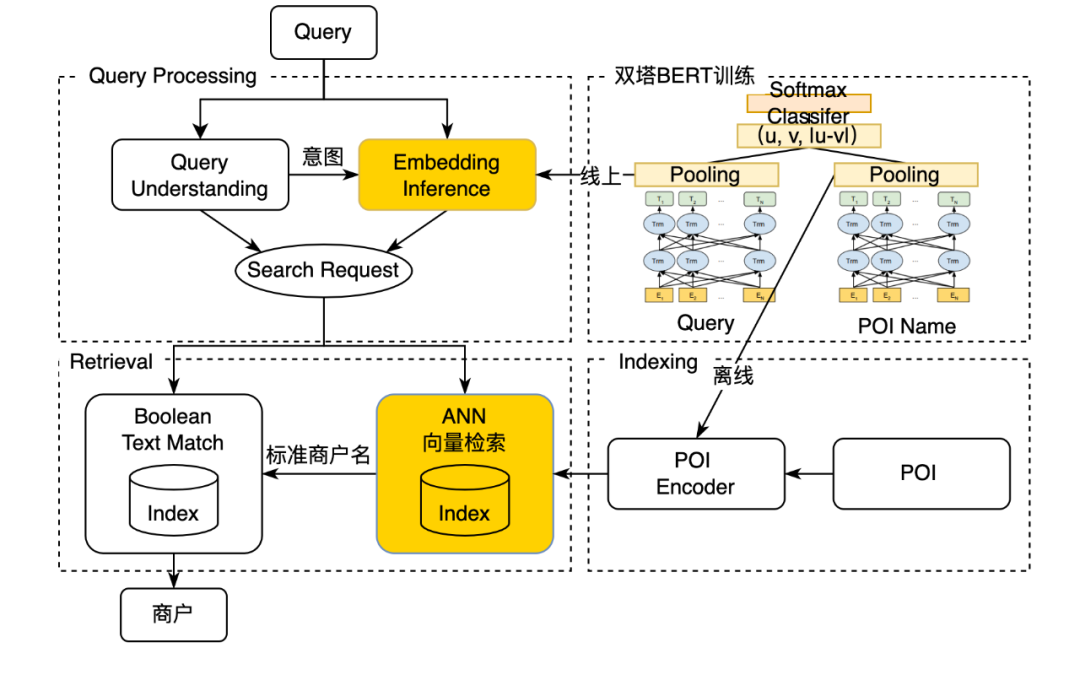
图12 向量召回技术架构示意图
下面会着重介绍模糊改写的核心模型以及线上服务处理流程两部分。
模型结构: 模型结构采用双塔Query Tower Q和POI Tower P,对于给定的Query和POI,公式中使用 q表示输入Query文本,p表示输入POI标题文本,模型计算过程为:
f(q,p)=G(Q(q),P(p))
其中Q(q)表示产出Query Embedding的BERT塔,P(p)表示产出POI标题文本Embedding的BERT塔,G表示打分计算函数,比如Inner Product、L2 distance等。
**
向量Pooling:** 根据BERT模型各层越远离下游任务泛化能力越强的特性,经过多次实验验证使用倒数第二层向量做Avg Pooling后输出的结果有更高的准确率和召回率。
Negative Sampling: Facebook在论文《Embedding-based Retrieval in Facebook Search》^{[23]} 中强调了负样本分布的问题。我们在负采样上有三部分:Random Negatives、Batch Negatives、Hard Sample Negatives,并增加了一组超参来调整三者的比例。Random Negatives 越多,召回商户质量较高但相关性会有所下降;Batch Negatives参考了SimCSE的做法,增加后相关性有所提升;Hard Sample Negatives是通过规则筛选了一批商户名文本上很相似的不同商户,以及加入错误的改写、纠错对,以较低的比例加入每一轮的训练中,进一步提升相关性表达。

图13 向量召回双塔模型训练数据构造示意图
Loss函数: Loss选用了Binary Cross-Entropy的Pointwise Loss函数,原因是对于有标准商户名Label的情况下,模型预测改写商户名“绝对正确”的性能好于Pairwise预测“相对正确”的改写商户名。在实际的对比实验结果中也体现了这一点。
线上服务搭建: 如图12所示,线上分为前置流量划分模块、Query端的在线文本向量化、ANN向量检索以及后置规则四部分。
- 前置流量划分模块:前置流量划分模块控制模糊改写服务调用逻辑,仅在商户名搜索意图下传统文本召回无结果时调用。一方面保证效果,另一方面减少对下游TFServing向量预测服务和向量检索服务的流量压力。
- Query端的在线文本向量化:预训练模型的线上性能一直是困扰大型NLP模型在搜索系统落地的困难之一。模型上尝试了Faster-Transformer,并将模型转为FP16精度进行加速。工程上除整体服务的缓存外,考虑到Query向量与城市无关,在这一模块也设计了一层缓存,进一步减少实时调用。
- ANN检索:向量检索使用了美团搜索团队自研的Antler向量检索引擎,该服务基于Faiss库封装,实现了IVFFlat、HNSW等向量检索算法,并支持分布式向量检索、实时索引、多字段分片、向量子空间、标量过滤等检索能力,对模糊改写在不同城市检索不同的POI库提供了高性能的多字段检索支持。ANN的参数调整同样对整体效果有上下2PP的影响。
- 后置规则:通过设计编辑距离等简单文本过滤规则和简单的词权重策略,优先保证商户名的核心部分的相关度,进一步提高模糊改写的效果。
模糊改写项目上线后,对“九匠和牛烧肉”未召回POI“九匠精酿烤肉”这类目标Case解决很好,在用户搜索商户名时出现换字、多字、少字的情况泛化能力很强,并且训练数据中加入同义词替换后也解决部分同义字、同义词替换的漏召回问题。从线上效果看,QV_CTR、无结果率以及长尾BadCase等指标上均有较大收益,有效改善了这部分流量的用户搜索体验。
除积累了向量检索的算法工程经验外,我们总结这个项目的成功之处在于通过一系列问题发现和问题分类的手段界定了清晰的问题边界,并做了合适的技术选型,使用意图信号限制应用范围对向量召回扬长避短,最终收益超出预期。向量检索近几年在业界各大公司均有尝试,我们认为在非商户名搜索流量以及商品搜索流量上还有巨大的挖掘空间,结合美团场景中商户多字段、多服务、多业务的难点,模型的变体有非常多可尝试的点,我们会在后续的文章介绍在线向量化检索方向的探索,敬请期待。
3.4 查询改写服务能力平台化
查询改写项目经过上述介绍的迭代,在美团搜索不同发展时期均贡献了不错的业务收益。并且随着技术影响力的扩大,逐步与大众点评App搜索、外卖App搜索、搜索广告等业务方建立了合作,在美团搜索的商品、外卖、酒店旅游等业务沉淀了相应的数据和技术能力。与此同时,各业务也根据自身的发展阶段和业务特点对查询改写提出了一些独有的需求,对此我们把查询改写的核心功能做了抽象,整个技术框架的发展方向为:
- 数据精细化 :数据层面区分几个核心业务,提供的词关系包括同义、上下位、同位、不相关等语义维度,搜索召回使用同义词下位词,推荐广告等还可以考虑使用同位词,不相关词则提供给相关性或排序模型做训练负例。在持续的挖掘过程中通过模型和人工校验分出不同精度的数据,用于排序特征也获得了超出预期的收益。
- 算法工具化 :在数据量覆盖率方面提供全面的算法挖掘工具,在语义判别方面不断迭代模型精度,并结合应用场景解决短文本的歧义性问题,跟踪和探索业界前沿方法。
- 在线服务可运维 :在线服务方面支持快速的业务接入、在线AB实验和干预等。
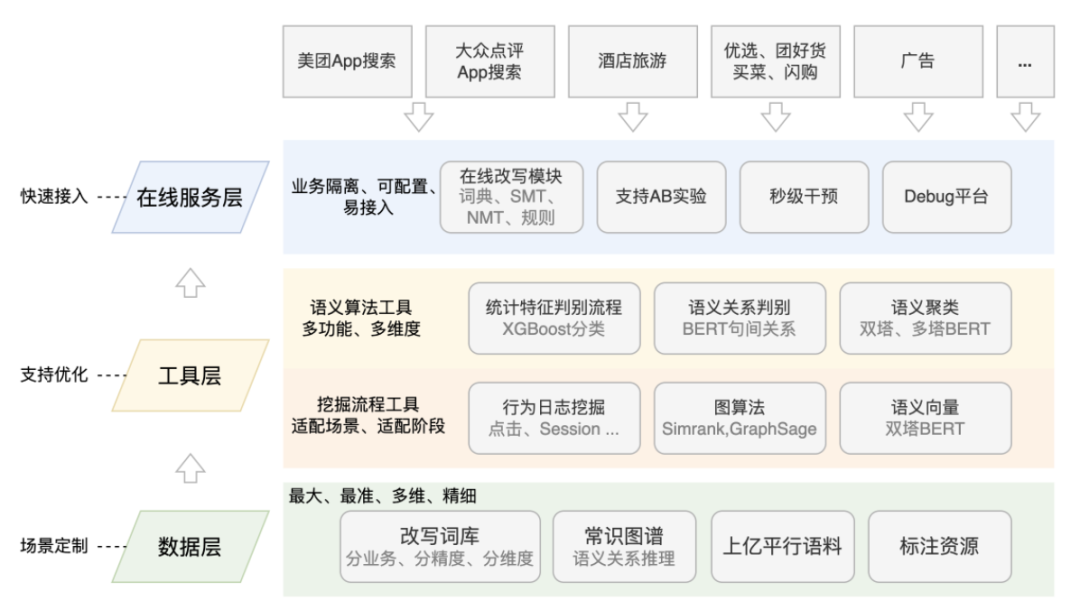
图14 查询改写平台技术框架图
4. 总结与展望
本文介绍了美团场景下查询改写任务上的探索和实践经验,在垂直领域搜索召回这一课题上结合实际业务场景和用户需求探索了语义判别模型、语义检索模型、图模型等前沿算法技术,积累了生活服务领域短语关联认知数据。其中在离线数据部分介绍了策略、统计翻译、图方法和Embedding等多种技术角度的挖掘方法,并对总结了各个方法在实践过程中的出发点、效果和优缺点。在线模型方面结合垂直领域搜索的结构化检索特点,设计了高精度的词典改写、较高精度的模型改写(基于SMT统计翻译模型和XGBoost排序模型)、覆盖长尾Query的基于强化学习方法优化的NMT模型、针对商户搜索的向量化召回四种线上方案。
目前,在美团App搜索中有改写流量占比约73%,在大众点评App搜索有改写流量占比约67%。构建的查询改写能力和服务平台支持各个业务频道内搜索以及搜索广告平台等,并取得了不错的收益。现在查询改写服务高峰期集群QPS(Query Per Second)已经达到了6万次/秒,我们会进一步投入研发,提升公司内乃至业界内的技术影响力。
如何更好地连接用户和平台上的服务、商家、商品是一个需要长期和多方面投入解决的问题。我们未来可能会进行以下几个方向的迭代:
- 进一步探索向量检索 :在生活服务的场景下,用户的需求和平台上提供的服务都是庞大的,且会越来越细致和多样。而近几年的对比学习等方法在文本表示领域不断刷新榜单,业界也已经在探索和布局在线向量召回。我们认为这方面的成长空间巨大,会持续投入。
- 语义判别模型探索 :语义理解离不开上下文,对于搜索来说用户的短文本搜索词的理解更是如此。类似前文介绍在Graph Embedding做的尝试,后续可以考虑多模态等方法,更好的解决搜索上下文下的语义判别问题。
- 生成式改写探索 :强化学习还可以向SeqGAN^{[26]} 等方向尝试,以及用更好的生成器来解决长尾搜索词改写问题。
- 进一步细化词关系能力建设 :在与各个业务合作的过程中发现各类的词关系均有用途,可以根据相关性的强弱作用于召回、相关性、排序等其他各模块。这方面目前定义比较完备的是阿里巴巴在商品领域构建的AliCoCo^{[27]} 。在生活服务领域词关系是更为丰富的,我们希望能建立起生活服务领域最大、最精细、最丰富的词关系结构化数据,更好的服务于使用方。
5. 作者简介
杨俭、宗宇、谢睿、武威,均来自美团平台/搜索与NLP部。
6. 参考文献
[1] 温丽红、罗星驰等. 美团搜索中NER技术的探索与实践.
[2] Antonellis, Ioannis, Hector Garcia-Molina, and Chi-Chao Chang. “Simrank++ query rewriting through link analysis of the clickgraph (poster).” Proceedings of the 17th international conference on World Wide Web. 2008.
[3] Perozzi, Bryan, Rami Al-Rfou, and Steven Skiena. “Deepwalk: Online learning of social representations.” Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 2014.
[4] Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
[5] Grbovic, Mihajlo, et al. “Context-and content-aware embeddings for query rewriting in sponsored search.” Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 2015.
[6] Djuric, Nemanja, et al. “Hierarchical neural language models for joint representation of streaming documents and their content.” Proceedings of the 24th international conference on world wide web. 2015.
[7] Shen, Yelong, et al. “Learning semantic representations using convolutional neural networks for web search.” Proceedings of the 23rd international conference on world wide web. 2014.
[8] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[9] Reimers, Nils, and Iryna Gurevych. “Sentence-bert: Sentence embeddings using siamese bert-networks.” arXiv preprint arXiv:1908.10084 (2019).
[10] Gao, Tianyu, Xingcheng Yao, and Danqi Chen. “SimCSE: Simple Contrastive Learning of Sentence Embeddings.” arXiv preprint arXiv:2104.08821 (2021).
[11] Johnson, Jeff, Matthijs Douze, and Hervé Jégou. “Billion-scale similarity search with gpus.” IEEE Transactions on Big
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%BE%8E%E5%9B%A2%E6%90%9C%E7%B4%A2%E4%B8%AD%E6%9F%A5%E8%AF%A2%E6%94%B9%E5%86%99%E6%8A%80%E6%9C%AF%E7%9A%84%E6%8E%A2%E7%B4%A2%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


