腾讯互联网知识图谱的构建及应用

分享嘉宾:单子非 腾讯 高级应用研究员
编辑整理:盛泳潘 重庆大学 助理研究员
出品平台:DataFunTalk
导读: 大家好,我是单子非,来自腾讯的微信事业群。我今天分享的主题是"知识图谱的构建与互联网场景下的应用"。主要想从学术界与工业界两个角度给大家带来一些分享:将介绍通用及垂直领域知识图谱构建,基于知识图谱的自然语言理解、生成、推荐等互联网业务场景。
01知识图谱介绍
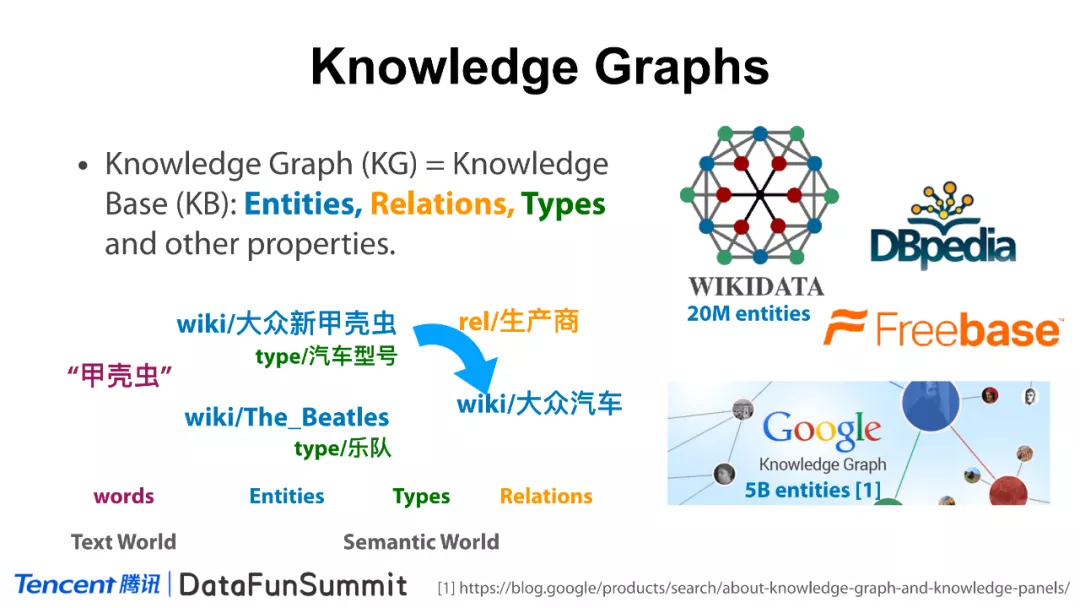
知识图谱(知识库,KG)是实体、关系、类型和其它一些属性的集合,我们可以用图结构去描述它。KG和文本的关系是什么?如上图,“甲壳虫”只是文本层面的一个表示,在知识库中,它可能就是实体层面的表示,例如“甲壳虫”既有可能是一种昆虫,又有可能是一种汽车,也有可能是一种乐队。实体之间是有关系的,例如“大众新甲壳虫”和“大众汽车”之间有一种“生产商”的关系。知识图谱中同样有类别信息,例如“大众新甲壳虫”可能是一种汽车型号;“The_Beatles”可能是一个乐队等。所以说,知识图谱是一种异构的,有多种实体、关系和属性的图结构。“甲壳虫”是在文本世界(Text World)中的一种表示;实体、关系、类型、属性是在语义世界(Semantic World)中的表示。有很多重要且有趣的工作是将这里的文本世界与语义世界进行打通。常见的公开知识图谱有Wikidata(包含2千万左右的实体)、DBpedia、Freebase、Google Knowledge Graph(包含50亿左右的实体)等。当然,我们现在也有很多的中文知识图谱,例如CN-DBpedia、大词林等等。
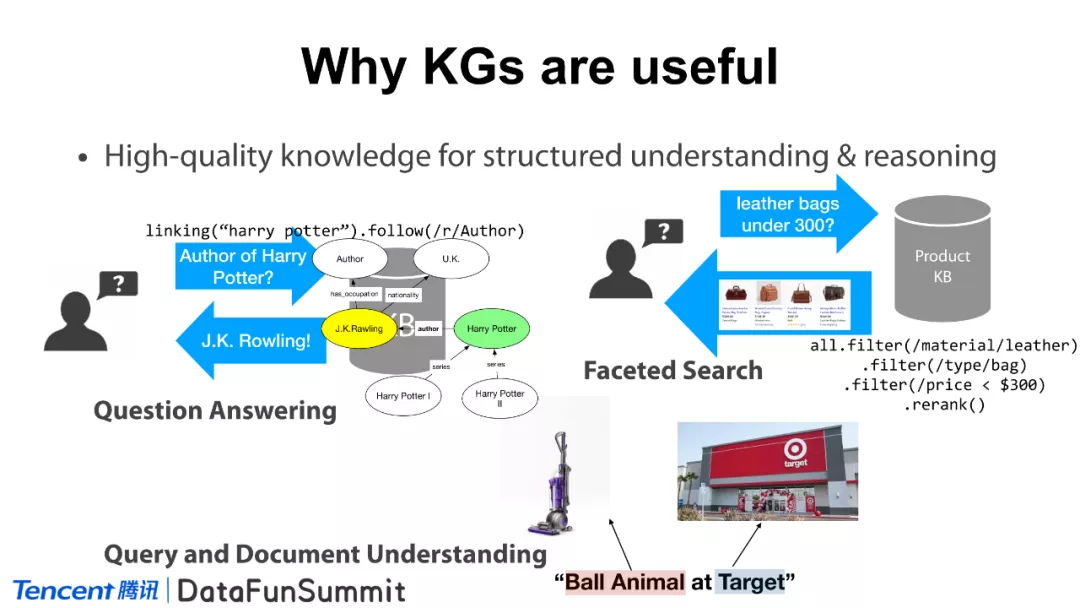
为什么说知识图谱是有用的呢?知识图谱中涵盖的高质量的知识可以帮助我们进行理解与推理。如上图,我们举几个例子:在智能问答(Question Answering)方面,一般用户会有一个问题(query),例如《哈利波特》一书的作者是谁(Author of Harry Potter)?怎么进行解答呢?我们首先会将这个问题做成一个结构化的查询语句。然后将这个语句在知识库上进行执行,我们会发现J.K.Rawling这个节点和Harry Potter这个节点之间存在作者关系(author),所以就能回答这个知识导向的问题。在结构化搜索(Faceted Search)中,用户可能会有一些复杂的问题,例如“我要去买300元以下的皮包”,机器可以解析到这句话本质是个限定化的搜索,如它的材质是皮、商品种类是包,价格是300元以下等,那么我们在商品的知识库中进行搜索,可返回给用户一些最满足上述条件的商品。知识图谱还能帮助我们做问题与文本语义的理解(Query and Document Understanding)。例如,这句话“Ball Animal at Target”是什么意思呢?对此,有的系统可能会很迷惑,但是如果有知识图谱来辅助理解,就可以发现“Ball Animal”是一个戴森吸尘器的型号,“Target”是美国的一个连锁商场。这些词其实都是有歧义的,但是只要能和知识图谱进行准确的关联,那么我们就会得知:其实用户是想要在Target购买吸尘器。

知识图谱在推荐系统中也会有很多应用,像视频推荐领域,用户会喜欢看一些视频。传统的推荐系统一般会基于用户与物品的交互,因此对于一些尾部的、缺乏交互的物品效果可能不是太好。那么我们如何基于知识图谱与内容理解的方法去提升尾部物品推荐的效果呢?
如上图所示,通过挖掘用户点过“赞”的视频,这个视频有其文本描述信息,如果能将这些文本中准确地映射到知识库中,例如,这里的“霉霉”其实是说泰勒·斯威夫特(女歌手)(/person/Taylor_Swift),“世界巡回演唱会”指的是1989年的World_Tour(/event/The_1989_World_Tour),“Love Story”是她的一首歌(/song/Love_Story_(Taylor_Swift))等等。如果能够发现这些文本与实体之间的关联,那么我们就能在相应的知识图谱上做一定的扩展。例如,我们可以给用户推荐泰勒·斯威夫特的其它演唱会的视频,以及与她相似的其它歌手的视频等等。如此,这个推荐系统就具有比较好的多样性与可解释性。上述为一个简单的应用思路,近期也有很多论文探索知识图谱在推荐中的应用,大家感兴趣的话可以去阅读。
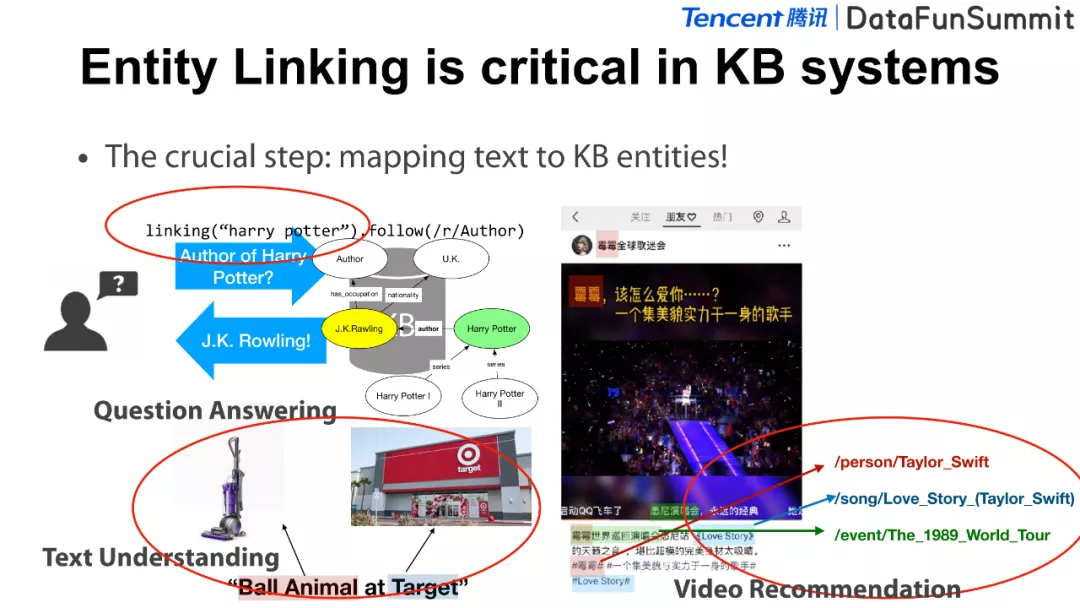
在以上几个应用中,我们都看到了一个通用的步骤,即如何将文本映射到知识库中的实体,该问题被称为实体链接(Entity Linking),在实际应用中发挥着重要的作用。在接下来的部分,我将会介绍如何构建一个实体链接系统,以及该研究方向近年来的一些研究进展。
02 知识图谱的应用和实体链接的进展
以上是一些知识图谱的综述,下一部分的重点是知识图谱的应用和实体链接的进展。

这里先给实体链接下一个定义:给定一段文本,并从中找出知识库中的实体。例如,从“高尔夫甲壳虫哪个贵”这句话中应该能识别出两个实体,即大众高尔夫(/wiki/大众高尔夫)和大众新甲壳虫(/wiki/大众新甲壳虫),这就是实体链接需要解决的问题。
实体链接同样有两个别名:
实体消歧(Entity Disambiguation)或实体消解(Entity Resolution)。

实体链接要怎么做呢?如上图所示,我们从“高尔夫甲壳虫哪个贵”这个句子开始。第一步是去做指称识别(mention detection),又可被称为命名实体识别(named entity recognition),检测出这句话中有“高尔夫”和“甲壳虫”两个实体的mention(在不同的翻译中,可译为“指称“、“实体词”、“提及”等)。第二步是根据这两个指称去生成一些候选项(Candidate Generation)。高尔夫可能是一种汽车或一项运动;甲壳虫可能是一种昆虫、汽车或者乐队。然后,就是将文本映射到知识库中的可能实体上;最后一步是给这些已有候选项进行打分,并将高分的结果返回给下游任务。以上即为实体链接的主要过程,那么其中的每一步是如何完成的呢?以下我们将分别进行阐述说明。
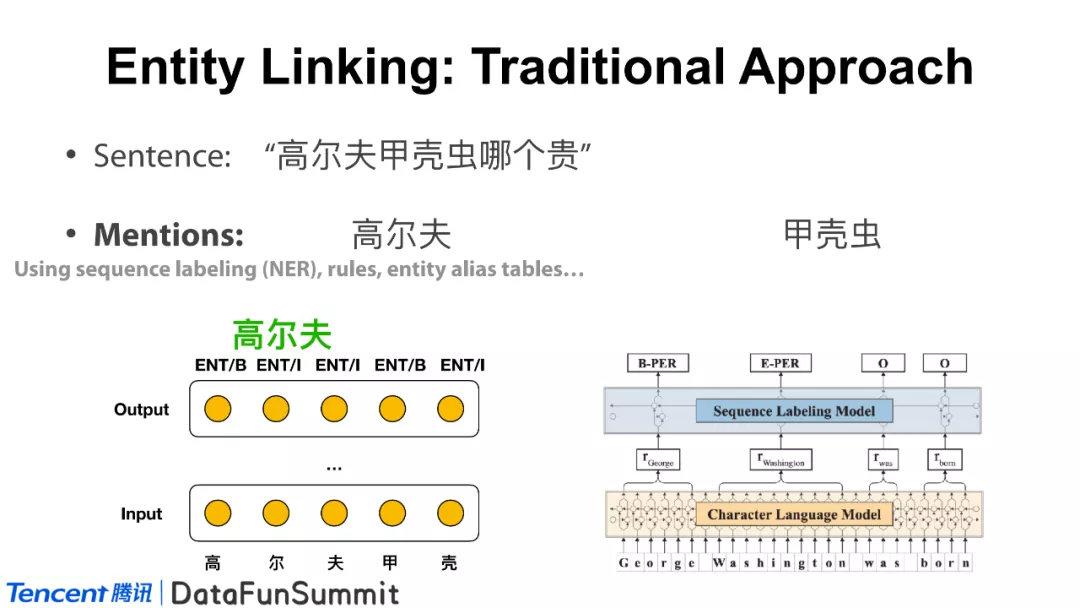
在做mention detection时有很多方法,例如序列标注、基于规则的方法、基于词典匹配的方法等。现在流行的预训练语言模型也能帮助我们更简单地去完成这项任务,我们将输入的句子看成是输入层(Input)的一个序列,在输出层(Output)来识别该句子中的mention。以序列标注方法为例,近年来流行的BERT,LSTM等模型都可以帮助我们来完成这项任务。

第二个步骤就是候选项的生成,传统的方法将依赖于词表(alias table),即我们有一个数据集,其中包含了所有可能的mention到实体的映射(有时还包括映射的概率/热度),我们就可以借助于词表完成候选项的生成工作。那么这种方法是不是一个完备的方法呢(Is this a good approach)?据此,近年来也产生了很多讨论,这种方式的依赖性很强,因为每增加一个新实体,我们都需要知道其对应的所有可能的mention,实际上这是一个非常强的假设。

在有了实体的候选项以后,第三步就是如何给这些候选项来打分。传统的度量指标主要依据特征工程而提出,包括:热度,当前词链接到知识库的概率以及一些其它的语境与匹配的信息。这些都可以训练浅层的机器学习模型打分函数。

在2018年的一项工作(请见《DeepType: Multilingual Entity Linking by Neural Type System Evolution》)中提出,实体的类型是非常重要的信息,研究者可将它们用于实体链接预测。如上图(左),这句话是“一个人看见了Jaguar在告诉公路上加速”,上图(右)的这句话是:“一个猎物看见了Jaguar穿越丛林”。“Jaguar”这个词是有歧义的,它可能是一只“美洲虎”,也可能是一辆“捷豹”(即一个汽车的品牌)。在当前语境中是一目了然的,其核心思想在于:我们能否使用语境去预测实体的类别(Use context to predict entity types),然后根据类别去给定一个分数,最后结合这个词在词表中的概率去进行联合预测,即P(E|M)= X1,TypeCoherence(E, Context) = Y1。以上方法不仅简单,而且取得了较好的效果。但是,我们也可以看到,上述工作依然依赖于词表。

实体链接并不是一个已解决的问题,目前的挑战主要包括:
- 大多数方法对于词表的强依赖。即先要有mention到实体的映射,才能指导我们去做实体链接。例如在工业界,就需要我们不断去挖掘这样的词表映射关系,这样的过程总会有一定的错误。对于新实体(fresh entities)的响应也不会特别快;
- 另外一个挑战就是对于少样本尾部实体的链接。有些模型对头部实体的表现会比较好,然而每天都会有新的人物、产品、专辑以及事件会出现,对于这些新的实体,是否能有效地进行链接;
- 庞大的知识库规模。现在的知识库规模不断在扩大,例如,谷歌知识图谱已达到了10亿的规模,在如此规模下是否能进行有效地实体链接;
- 多语言的知识图谱。实体往往是不依赖于语言的,如何能在跨语言的场景下进行实体链接。

在方法部分,我们着重讲一下后面两个点,即实体候选项的生成与打分的最新研究进展。对于前者,我们提出了基于双塔模型的实体召回策略(Entity retrieval with dual encoders),以及基于特征化实体表示(Featurized entity representations)的尾部实体链接改进方法。对于后者,我们会介绍一个基于阅读理解的实体打分方法(Entity scoring with reading comprehension)。

要减轻实体链接对词表的依赖,一个有效的方法被称为:深度召回(Deep Retrieval)。该方法的主要思路是,不在依赖于这种词表,我们可通过深度学习模型学习到这样的映射,然后将最有可能的实体候选项作为该模型的结果进行召回。具体的做法是,将语境中的实体词当成是向量表示,然后在向量空间中进行检索,找到与它最近的候选项。这里举个例子,如上图,在“Costa has not played since being struck by the AC Milan forward(Costa在AC米兰这场比赛后就再没有打过了).”这句话中,我们将这句话编码为一个向量[0.135, -0.047, 0.028, …],然后在一个向量空间中搜索,从图中可知,mention的向量附近的往往就是一些很匹配的实体(如Jorge_Costa, Ricardo_Costa等)。最后召回的结果中排名第一的就是Ricardo_Costa,即为链接的正确答案。
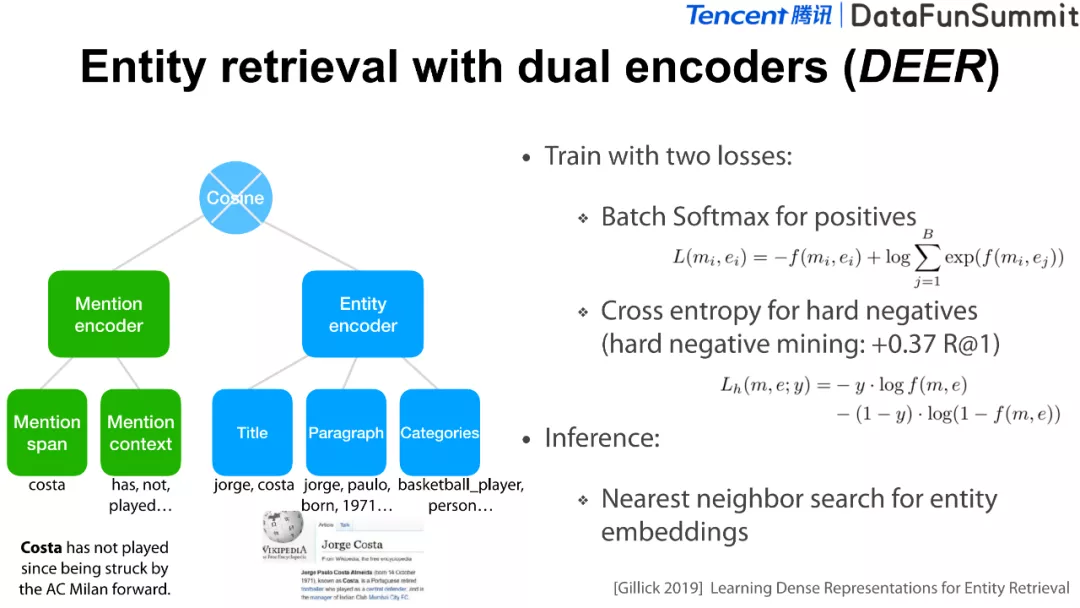
这是我们实验小组2019年发表的一篇论文(请见《Learning Dense Representations for Entity Retrieval》),我们把mention与实体通过“双塔”的结构进行编码,并且通过两个损失函数对模型进行训练。在正样本上使用Batch Softmax Loss进行优化,并做了一些负样本的挖掘,对负样本使用cross entropy loss优化。在推断时,我们将实体进行编码后,在统一的隐式空间检索它的邻居实体。

这个方法的局限性在于:在结构上它是一个浅层的词袋(bag of word)模型。再者,它依赖于一个相对比较复杂的负样本挖掘的步骤,才能获得比较好的效果。

为了改进上述模型,我们不得不提到预训练语言模型BERT,BERT于2018年提出,对迁移学习(Transfer learning)、语境中的词嵌入(Contextualized word embeddings)、Transformer架构(Transformers)、大规模无监督预料下的预训练(Pre-training with unsupervised data)这几个概念进行了较好的融合。BERT的核心思想在于:能够运用大规模的无标注文本语料去预训练一个好的语言模型,又能够迁移到很多下游任务当中。

由于大家对BERT都有相当的认识,因此我就不再赘述相关的基础知识。但在这里,我主要想讲一下BERT的两个任务,一个是遮蔽语言模型(masked language model, MLM),一个是下一句子预测(next sentence prediction, NSP)。第一个任务很像完形填空,即将一个句子的一个词盖住,让模型去预测盖住的位置是哪一个词;第二个任务是预测当前的两个句子是否为上下句关系。这样的好处是,我们可以利用无监督的语料去做预训练。介绍上述两个任务的目的是为将它们应用于后续的实体链接任务做铺垫。

我们能否将BERT用于实体链接的任务呢?答案是肯定的。主要的建模思路是,像在维基百科这样大规模的知识图谱或文本语料中,往往会有大量的内链,其所在语境蕴含了很多语义信息,而BERT能够较好地获取无结构文本中的语义信息。因此,我们想是否能从mention的上下文中学习完成实体的嵌入表示。以上图为例,对于句子“Valentian: first woman in space(Valentian是第一个登上太空的女性).”,我们的模型能够根据Valentian这个实体学到一些新的知识,所以我们设计了一个实体链接的任务,即根据mention所在的语境去预测它指的是哪一个实体。其中,我们设计了一个masking策略,即在一定的时候把整个mention替换为一个[MASK],在其它的时候就不去替换。采用了这样的训练任务后,模型会学习到语境中的语义信息以及提及对应的实体嵌入表示,具体请见《Learning Cross-Context Entity Representations from Text》。

如上图,该模型的架构直观,也是一个双塔模型,左边是用BERT去编码mention所在的语境,右边是为实体学习其专有的嵌入表示。我们将这个方法称为RELIC(Representations of Entities Learned In Context),即从上下文语境中学习实体的表示。在训练模型时,我们使用的是批量软最大化损失函数(Batch Softmax loss)。

该方法取得了优质的效果,超过了最新的方法(state-of-the-art)。再者,该方法是工业友好的(Industry-friendly),能够训练好BERT就能学到这些实体的嵌入表示。最后,该方法在实体候选的效果上优于之前介绍的DEER模型。

另外,我们还获得了新的发现:该方法训练得到的实体嵌入表示还能做智能问答。怎么做呢?以上图为例,我们将“In which Lake District town would you find the Cumberland Pencil Museum(坎伯兰铅笔博物馆在哪个城市)?”这个问题直接进行编码后在向量空间中搜索,得到的答案即为坎伯兰铅笔博物馆所在的城市——凯瑟克(Keswick)。类似于闭卷问答(closed-book)的定义,就是说模型不去获取相关的文本,而是通过记忆来回答相关的问题。相较于开卷问答(open-book)中的最好方法,该方法在召回率上达到了80%。

RELIC方法也有一定的局限性:
- 由于该模型需要根据每个实体学一个嵌入表示,那么对于新实体的效果是不那么好的,因为在一般情况下,每个实体至少需要有10个左右的mention在训练集中,才能学习得到较好的嵌入表示;
- 对于较大规模的知识库,由于需要训练10亿规模的嵌入表示,故这也是一个挑战。

所以,我们提出了一个新的方法,其设计想法来源于:
- 是否能让实体的嵌入表示共享参数,使得对于新实体的容忍性也比较好;
- 是否能有效解决多语言实体表示的问题。

我们的答案是肯定的,并且思路也非常简单,就是说将RELIC模型中实体编码器换成基于BERT的实体编码器,进而去编码实体相关的文本特征。在训练模型的过程中,使得mention与实体的空间尽量相似。为什么该模型能够解决多语言的问题?这是因为我们可以使用多语言的预训练模型Multilingual Bert(简称mBERT)自动实现在多语言间的转换。在损失函数方面,我们使用了批量软最大化损失函数(Batch Softmax)以及基于负采样的交叉熵(Cross Entropy for hard negatives)损失。
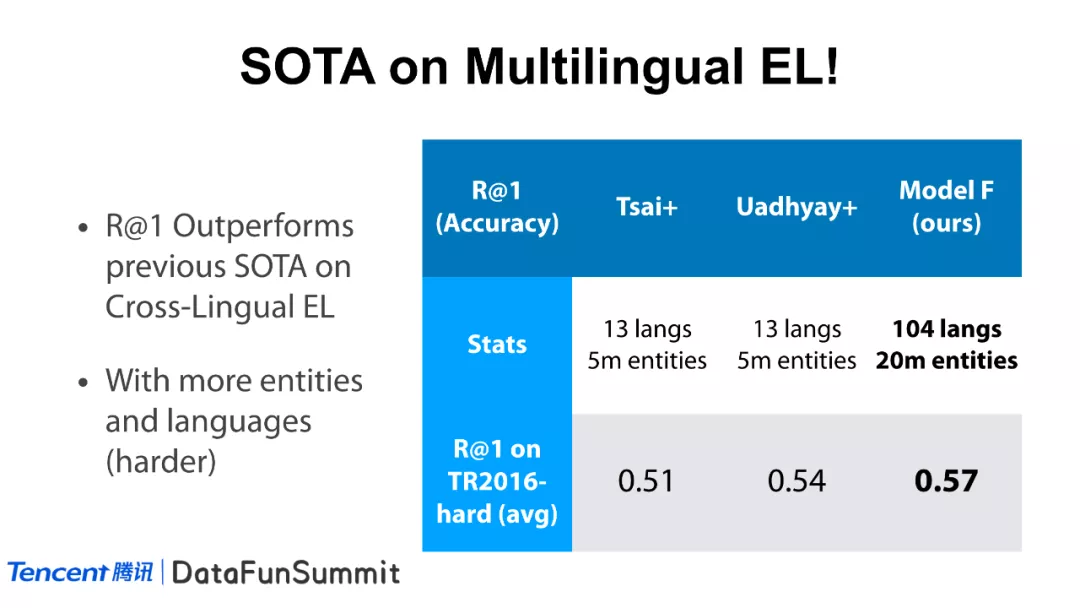
该方法在已有的跨语言实体链接任务上表现较好。再者,在测试语料方面,我们所使用语言数据集是对比方法的10倍,实体数量是其4倍,依然超过了最新的基线方法。

另外,在这项工作中,我们还发布了一个新的跨语言实体链接数据集(即测试集),其中包括了30万左右的mention,横跨9种语言。有8807种实体没有英文描述,是传统的基于英文的方法较难处理的一个数据集,以鼓励学术界更多的研究者投身于多语言实体链接这项任务之中。

我们的实体链接系统在维基百科头部100种语言上都取得了不错的效果。在holdout数据集上,该方法相较于词表的候选项生成方法有不同程度的提升,尤其是在一些低资源的语言上。低资源语言受词表大小的限制,其性能效果有限,而我们的方法却能在上述情形下达到较好的效果。

以下,我们再举几个例子让大家获得更直观的感受。一个例子是,用波兰语对小火车进行描述,它被进口到了德国并有一篇对其进行描述的文章。我们希望将“Tramino”这个词链接到波兰语的相关实体上,这是一个成功的例子。另一个例子是,有一段关于喷灌洒水装置的日语描述以及一段英文描述,我们可以借助于“喷灌洒水装置”这个词实现这两段文本之间的相互链接。由此可以发现,我们的模型对于跨语言实体链接是效果的。

对于不同频度的实体,即头部与尾部的实体,我们也做了一定的分析。如上图所示,我们的方法对于尾部的实体获得了显著的提升,尤其是对于从未出现在训练集中的实体或出现小于14次的实体。相较于基于嵌入表示的RELIC模型,我们的方法能够取得较大的提升。因此,该方法能够较好地应用到更大规模的知识库上,因为它可以泛化到尾部的实体上。
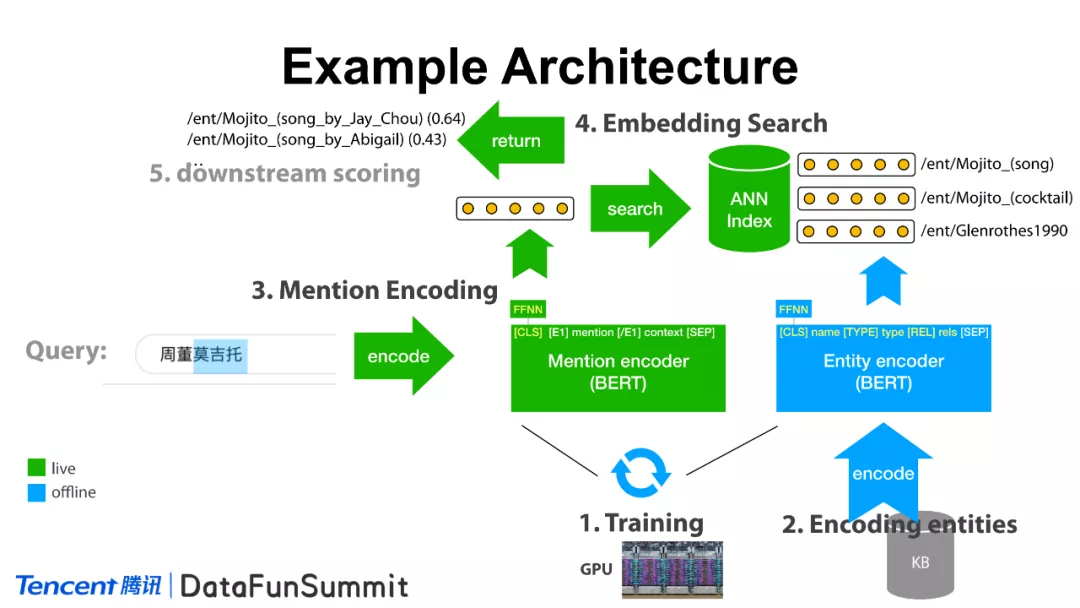
怎么样去实现这样一个架构呢?简单来说,我们去训练这样一个双塔模型,使用实体编码器去编码实体描述,并把其放在一个最近邻搜索的索引空间中。当一个查询(query)来临,如“周董莫吉托”,该模型将其编码为实体向量,然后在最近邻索引空间中去检索,这样相应的实体就会被召回。

之前介绍的是实体候选项生成部分,下面我们介绍实体候选项打分,即在获得实体的候选项之后,如何为它们进行打分。
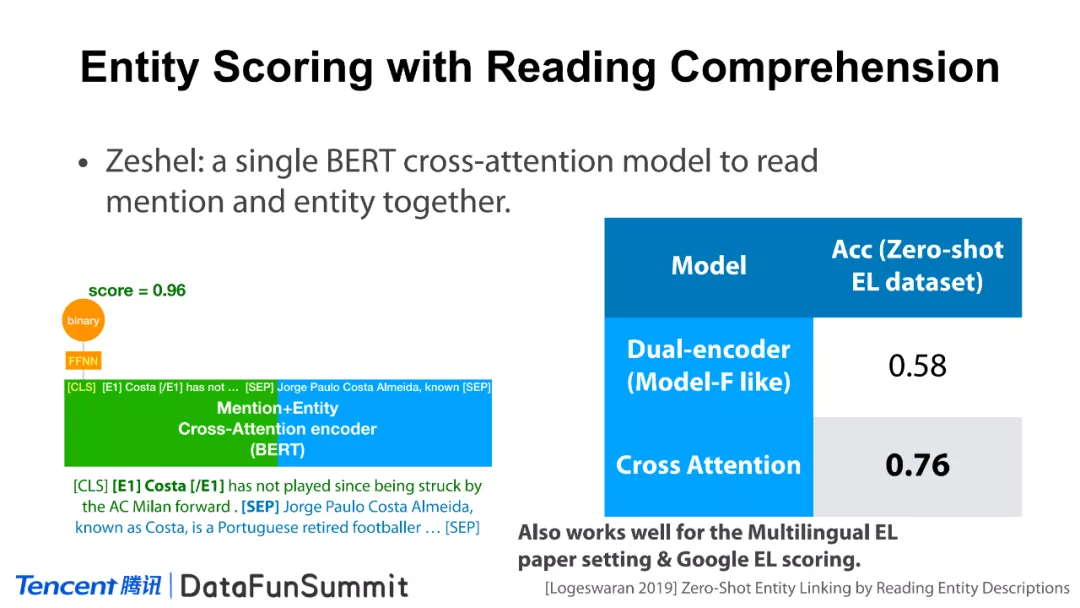
对于上述问题,目前较为有效的仍是基于阅读理解的方法(请见《Zero-Shot Entity Linking by Reading Entity Descriptions》)。如上图所示,该方法的思路非常直观,即通过BERT去编码mention和实体描述拼接好的一段文本,与RELIC双塔模型的区别在于,通过交叉注意力机制(cross-attention)可对mention和实体描述进行横向地比较,故比基于ID表示的模型更有表达力。在实验中我们发现,该方法相较于双编码器的方法(dual-encoder)实现了较大的性能提升。为什么称为Zero-Shot呢?这是因为只要有实体的描述信息,就可以将其与实体的mention相互比较,而不需要依赖大量的数据。在上述工作中,作者也发布了一个零样本实体链接的数据集。
03 知识图谱构建技术
以上内容为一些对实体链接方向研究进展的介绍,希望能帮助大家开展实体链接相关的开发和研究。接下来,我将主要介绍知识图谱构建方面的一些技术点。

早期的大多数知识库是由人工进行标注的,例如医疗领域的知识库。然后,逐渐过渡到一些规则的方法。近些年来,研究者们普遍采用机器学习的方法和系统去完成知识的抽取以及知识库的构建。
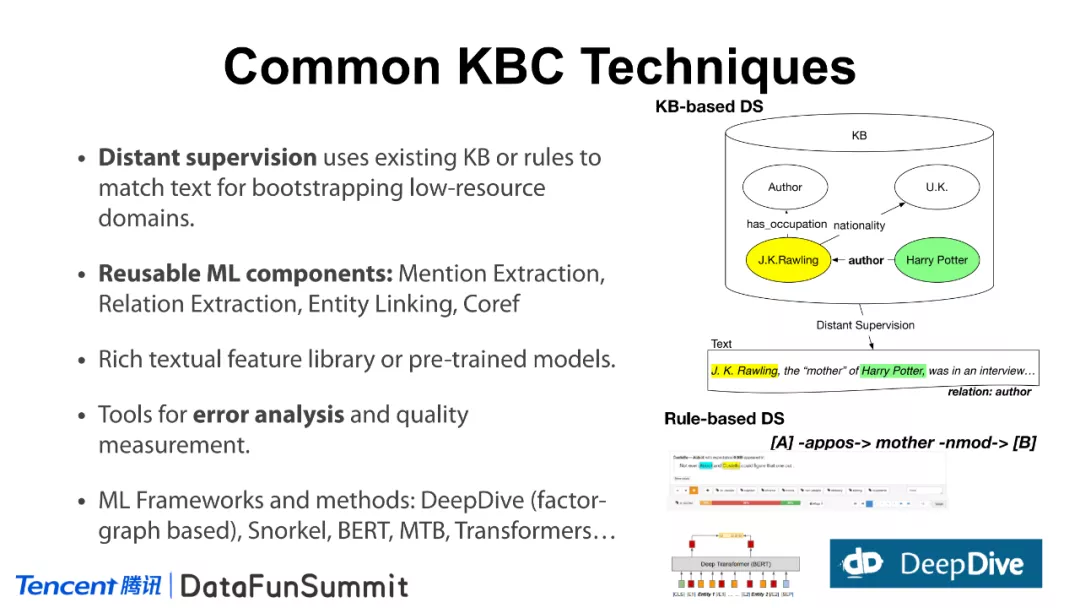
在常用的知识库构建技术中,远程监督(或称为弱监督学习)一般的思路是,利用已有的知识库,一系列文本匹配的规则,语境模板等快速地在文本中去构建训练样本。尤其是在低资源、垂直领域的环境下,普遍采用这种方法,这样可以有效地降低人工标注训练样本的成本。在知识库的构建过程中,常用的组件有:指称项抽取(mention extraction)、关系抽取(relation extraction)、实体链接(entity linking)、指代消解(Coref) 等共性的机器学习组件。当然,工具也是很重要的,在领域上我们需要对模型进行迭代,对于某一版模型的抽取结果而言,我们需要对其进行分析并明确改进的地方。最后是机器学习的框架和方法,例如DeepDive(一个基于概率图模型的工具),Snorkel,BERT,MTB,Transformers等。

下面将会通过一个简单的例子,阐述从文本数据中构建知识库的流程。
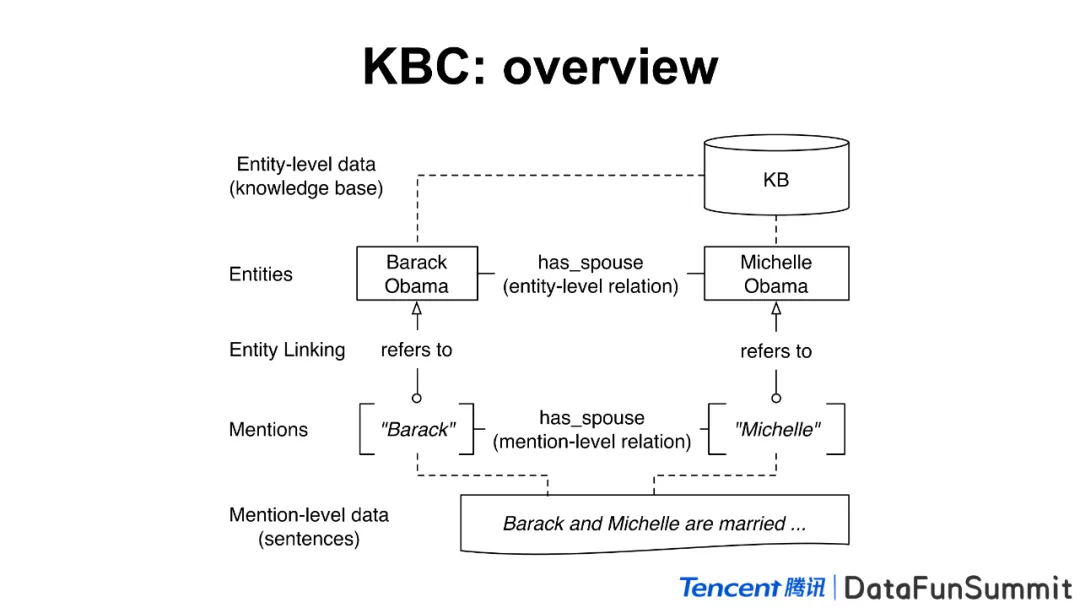
上图只是知识库构建过程中的一个核心部分�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E4%BA%92%E8%81%94%E7%BD%91%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E7%9A%84%E6%9E%84%E5%BB%BA%E5%8F%8A%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


