腾讯基于兴趣点图谱的内容理解

分享嘉宾:洪婉玲 腾讯 高级研究员
编辑整理:周江兵 360
出品平台:DataFunTalk
导读: 本文将介绍我们如何使用大规模的UGC数据挖掘用户真实的阅读意图,构建兴趣点图谱,并将图谱用于内容理解。最终,使大家了解如何通过构建用于信息流的兴趣点图谱,来提升信息流推荐效果。
01 兴趣点图谱背景介绍
首先和大家分享下兴趣点图谱的背景。
1. 推荐的基本范式
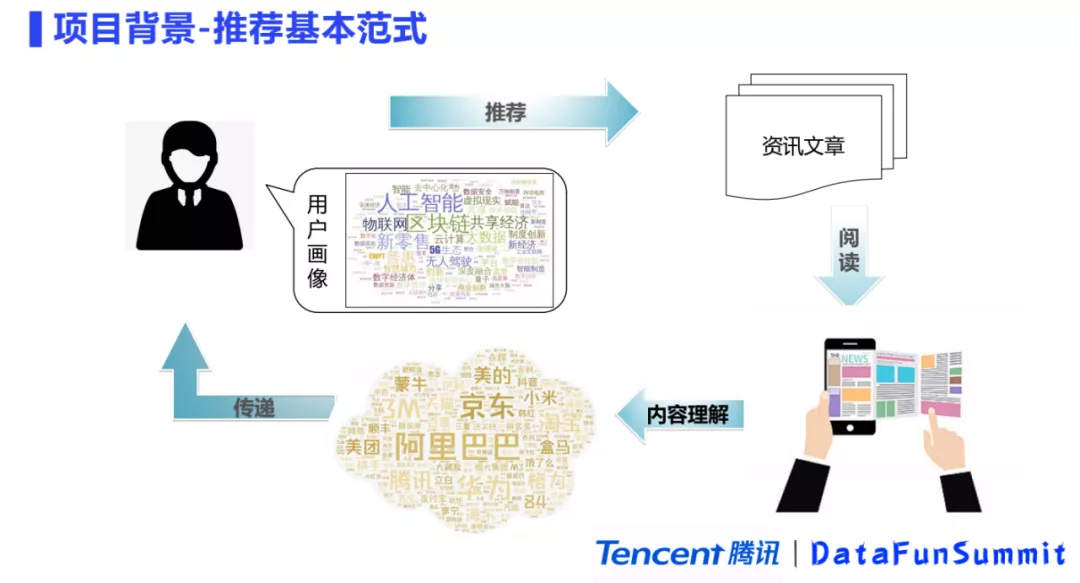
我们的内容理解是服务于信息流推荐的,那什么是信息流呢?简单来说,信息流就是给用户推荐其可能感兴趣的资讯内容。当用户进入系统之后,推荐系统会根据用户的画像,给用户推荐其可能感兴趣的文章,供用户浏览和阅读。系统会对用户历史阅读的文章进行内容理解,从中抽取出一些的兴趣点累积到用户画像中,用于下一次内容的推荐。
2. 推荐不准

目前的推荐系统存在两个问题,分别是推荐不准和信息茧房。推荐不准是信息流推荐中的一个大难点,这里通过比较搜索和推荐的区别来分析这个问题。
搜索的主要任务是给定一个由一系列的词组成query,希望能够找到与query相关的doc返回给用户。因此搜索问题可以转化为召回和排序两个步骤,在召回阶段通过query中的每个term去拉取相关的文章;在排序阶段利用整个query作为完整的上下文对文章进行排序。比如“王宝强马蓉离婚”这个例子,在排序的时候,因为有一个完整的query作为上下文,所以会把“王宝强马蓉离婚”整体相关的文章排在前面。
对于推荐来说,和搜索比较相似,也是给定一个用户,希望能够找到用户感兴趣的一个文章集合。同样,用户也可以看作是由一系列的组词组成,这里将其称之为用户模型。推荐也可以分为召回和排序两个部分。召回和搜索相似,根据用户模型中的每一个term进行文章拉取,生成候选集。但在排序阶段,推荐和搜索就有较大的区别,因为在用户模型中,是把每一个兴趣点单独累积到用户画像里,从而丢失了上下文关系,就无法像搜索一样用完整的上下文信息来进行排序,就会导致推荐不精准。还是“王宝强和马蓉离婚”例子,推荐会把王宝强和马蓉这两个兴趣点分别累积到用户模型中,下一次再给用户推荐文章的时候,就很难把王宝强马蓉离婚最新的文章然后推荐给用户。因此,推荐不准是相关性不足造成的,主要原因是用户画像仅使用词粒度作为用户的兴趣点,从而导致原文词之间关系的丢失。所以内容理解不仅要清楚文章是关于什么的,更需要一个完整粒度的兴趣点。
3. 信息茧房
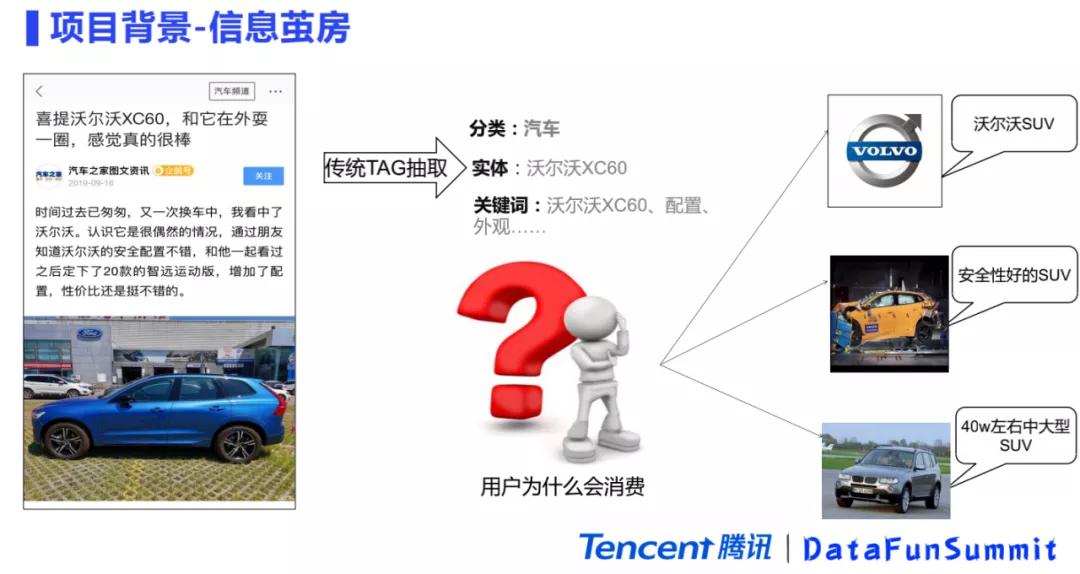
除了推荐不精准外,另外一个问题就是信息茧房。信息茧房也是推荐当中的一个常见问题。先来看一个例子,比如用户阅读了文章之后,传统的标签会给它提取出来分类、实体以及关键词等相关的信息,但这些信息不能能很好地表示用户消费文章的动机,不能很好地表示用户为什么会去读这篇文章。首先是分类,比如这篇文章分类会给它提取出来汽车类别,但是汽车类别的粒度十分粗,并不能精准的刻画用户的兴趣点。其次是实体,对比分类来说,实体的粒度会细很多。比如从文章中提出的“沃尔沃XC60”这个实体,确实能比较好地刻画用户的兴趣点。但如果把这个兴趣点累积到用户模型里,反复不断的去给用户推荐相关的文章,从而使用户获取的内容变得越来越单一,最后造成信息茧房问题。
如果仔细思考一下用户读这篇文章背后的消费动机,就可以做一些合理的推理。比如说用户看了这篇文章,从表面上看他的兴趣点是“沃尔沃XC60”,但是他可能是对沃尔沃相关的SUV都会感兴趣,所以他本质的一个动机可能是对“沃尔沃SUV”这个兴趣点感兴趣,而不只是对“沃尔沃XC60”具体型号的汽车感兴趣。另一方面“沃尔沃XC60”是一个安全性比较好的汽车,所以用户在看这篇文章的时候,会推理出来他还可能感兴趣的是“安全性比较好的SUV”。此外,因为“沃尔沃XC60”是一个40万左右的中大型的车,有可能用户在读的这篇文章的时候,是有一个买车需求的,他其实有一个价位的需求,就是说他想买的是“40万左右的中大型的一个SUV”。
由此可知,用户在消费这些文章的时候,其实有一些消费的动机,需要从背后进行推理,而传统的tag抽取是没有这个能力。所以当前推荐内容单调原因是因为传统的内容理解没有能力去挖掘用户的消费动机。
4. 内容理解相关研究

目前内容理解相关的研究主要分为这五大部分:
第一部分是分类,分类是一个业界比较常用的技术。它的特点是技术比较成熟,但是粒度比较粗,难以精准的刻画用户的兴趣点。一般来说,分类和具体的产品绑定非常紧密,如果整个体系有所变动,代价非常巨大。
实体是第二个常用的技术。相对于分类,实体的粒度会细很多,但它的内容推荐非常单一,容易造成信息茧房问题。同时实体也存在歧义问题,比如“苹果”这一实体,它可能指的是水果,也可能是指苹果公司。这种歧异问题会造成召回的文章相关性不足,可能不能够完整地刻画用户的兴趣点。
第三个技术是关键词。关键词的应用也比较成熟,但很多词不聚焦,不能够作为兴趣点累计。比如类似像“北京”和“配置”这样的词,都是非常不聚焦的,如果是用这种词作为兴趣点的话,语义表示会很模糊。
第四类算法是LDA(Latent Dirichlet Allocation,主题模型)。LDA的粒度与分类差不多,不足之处也和分类类似,粒度较粗,难以精准的刻画用户兴趣点。
最后是NN(Neural Network,神经网络)模型。目前关于神经网络的应用于内容理解的研究和参考方案非常多,它的不足是结果解释性不太好,所以在线上遇到badcase时很难及时的修复。
综上所述,个性化推荐要求内容理解需要做到两点:
第一点,提取兴趣点语义度需要完整。因为推荐系统需要累积到用户模型中,所以必须保证保留完整的上下文的信息;
第二点,要做到了解用户背后真正的消费动机,因此内容理解需要具有推理能力。
5. 兴趣图谱
为了去更好地满足个性化推荐要求,提出了一套基于兴趣点图谱的内容理解算法。兴趣点图谱包括五类节点,首先是业界常用的分类和实体,这两个是业界通用的技术,所以就不再去赘述。在实体层上,我们对实体进行了抽象,提出了概念层。比如说实体“沃尔沃XC60”,可以对它向上泛化出“40万左右的大型SUV”的概念。此外,为了更加精准的描述用户的兴趣点,我们还增加了事件层。例如“王宝强离婚”和“陈羽凡离婚”就是事件,它的特点是能更加精准的刻画用户的兴趣点,提升整体推荐的相关性。如果同一类事件进行去重和泛化,就可以得到一个话题。比如“王宝强离婚”和“陈羽凡离婚”,这两个事件的本质都是明星离婚,我们可以将其抽象成一个话题,就是“明星离婚”。话题层的优点和概念层类似,能够得到更加抽象和泛化的语义表示。
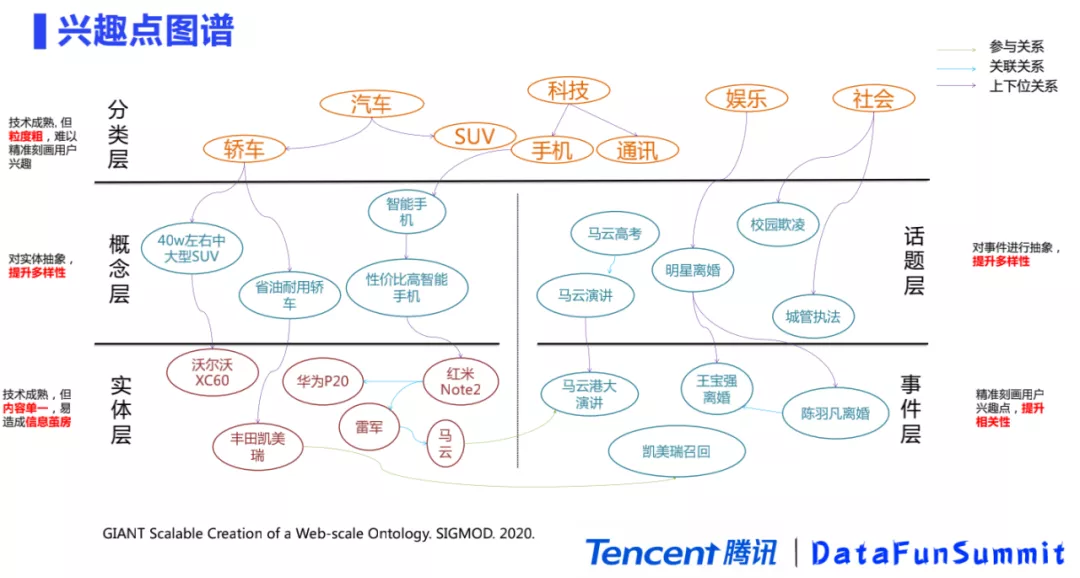
除了这五类节点以外,兴趣点图谱还包括三种关系。第一种关系是上下位关系,例如“红米note2”的上位词是“性价比高的智能手机”。第二种关系是关联关系。例如,在买手机的时候,会经常比较不同的机型,到底是买“华为P20”还是买“红米note2”, 在这个场景下两个实体是有关联的,所以把这种关系叫做关联关系。我们的兴趣图谱和传统的知识图谱不一样,传统知识图谱可能会提取很多属性和类型的关系,例如“刘德华的妻子是朱丽倩“,其中“妻子”是一个比较细的类型。但我们认为在推荐中其实不需要这么细粒度的关系,只需要两个兴趣点之间有一些关系,就可以进行兴趣点探索,让用户去做一些扩展阅读。所以,兴趣图谱的关联关系不做特别的属性区分。第三部分是参与关系的话,比如在“凯美瑞召回”事件中,“凯美瑞”是“凯美瑞召回”的一个参与实体,我们把这种关系叫做参与关系。
02 兴趣点图谱建设
介绍完了整个兴趣点图谱之后,接下来看一下整个兴趣点图谱的建设。
1. 兴趣点挖掘
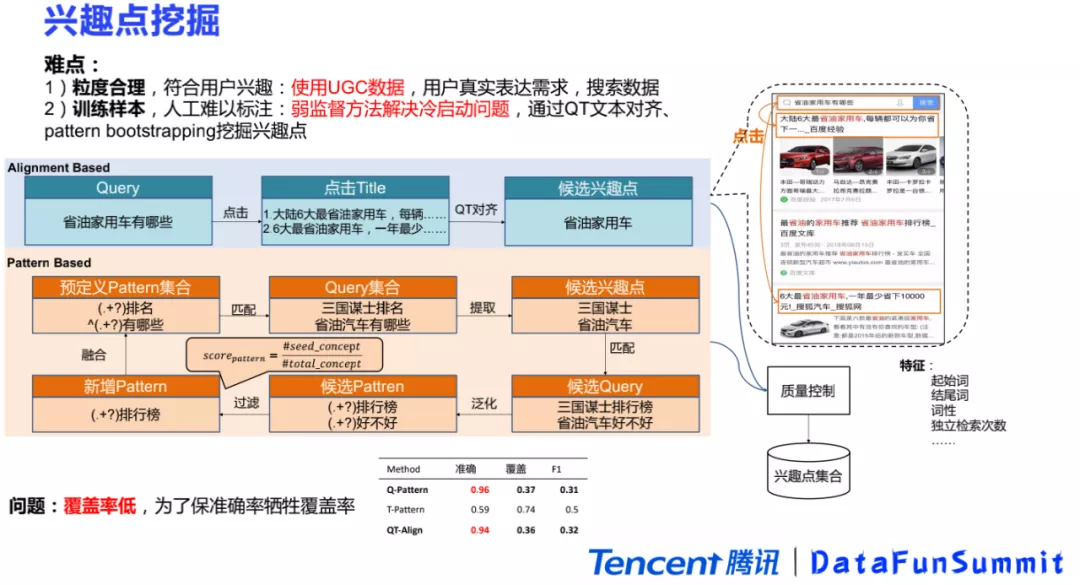
兴趣点图谱包括边和节点,首先介绍一下兴趣点图谱的节点挖掘方法。和上文介绍的一样,兴趣点主要分为五种类型,其中分类和实体是业界常用的类型,这里就不再去介绍,主要关注概念,话题和事件这些兴趣点是怎么挖掘的。兴趣点挖掘的第一个难点在于很难去找到符合用户需求并且粒度合理的兴趣点。除此之外,大量的标注数据成本会特别高,时间周期长,如何获取训练数据成为了另一个难点。最后,兴趣点包括概念、话题和事件等多种类型,如何通过一个统一的框架去同时挖掘不同类型的兴趣点是第三个难点。
针对第一个问题,我们使用了一些UGC(User Generated Content,用户创造)的数据,主要是用户的些搜索和点击的行为数据。因为搜索和点击数据是用户真实需求的一个表达,用户有需求才会去搜索,搜索结果符合要求才会去点击。通过对搜索和点击语料进行挖掘之后,可以找到符合用户需求,并且力度合理的兴趣点。
对于训练样本难以获取的问题,我们采用了两种弱监督的方式来解决冷启动。第一种是基于query和title对齐的方式。用户在搜索query之后会点击相应的篇章,这个时候就可以得到一些(query,title)文本对。将两个文本进行对齐,例如求两个文本的最长公共子序列,就可以得到一些候选的兴趣点。第二种方式是基于pattern的方式。pattern的方式是信息抽取中常用的方法,这里采用的是兴趣点pattern的bootstrap的方式来进行挖掘。bootstrap需要预定义一个pattern集合,利用这些pattern在query集合中召回匹配一些query,并从里面抽取出一些候选的兴趣点。在拿到这些兴趣点之后,可以去把包含这些兴趣点的query都召回出来,再把这些query进行泛化。比如把“三国谋士”进行泛化之后,就可以得到一些新的pattern。这些pattern可能数量会很多,所以需要进行一些质量控制,得到选一些高质量的pattern,最后把它们加入到之前的pattern集合里。通过循环往复的bootstrapping的方式,就可以不断地去获取到更多的pattern和兴趣点。目前基于Query-Pattern的准确率是96%,基于Query-Title对齐的准确率是94%。但这两种方式为了保证高准确率,牺牲了覆盖率,它们的整体覆盖率都很低,只有30%多。
2. 兴趣点挖掘-改进
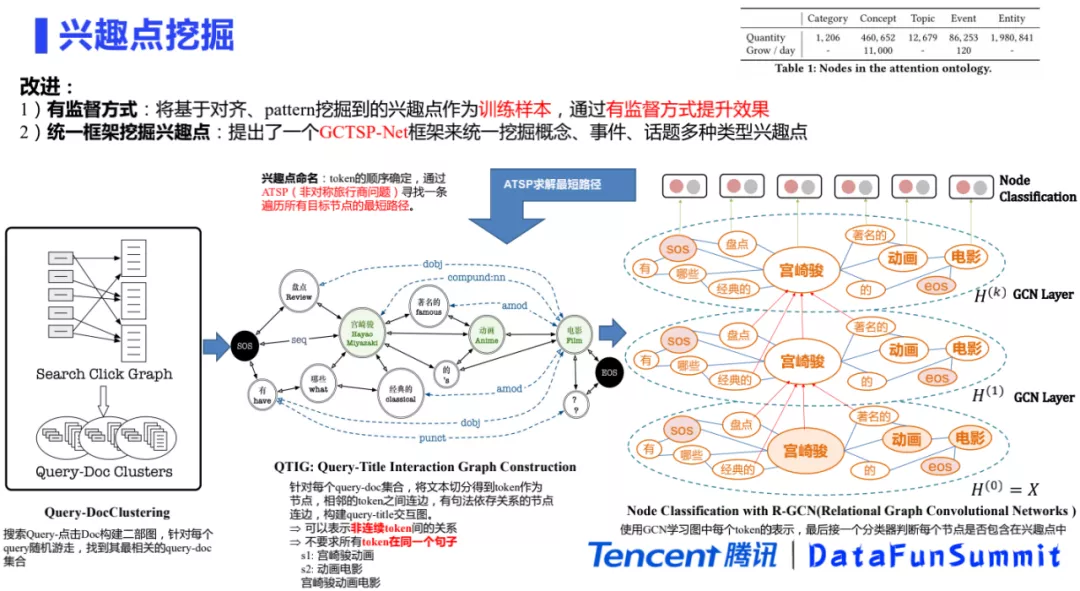
为了提升覆盖率,我们做了以下的优化,发了一篇paper。具体的改进点包括两部分,第一部分是将基于对齐和pattern挖掘到的兴趣点作为训练样本,通过有监督的方式提升效果。除此以外,我们提出了一个GCTSP-net框架统一的挖掘兴趣点。
GCTSP-net第一步将query和搜索点击的title构建一个二部图,针对每一个query进行随机游走,将与当前query最相关的query集合以及最相关的doc集合,构建成query和doc的cluster。
第二步,构成query-title的交互图。对于每一个query-doc集合中的文本切分成token,把token作为一个节点,相邻的token之间连接成边。除了相邻关系,对文本进行句法依存分析,把句法信息也加入到图中。query-title交互图不仅可以表示非连续token之间的关系,而且不要求所有的token出现在同一个句子中。例如用户有两个搜索query分别是“宫崎骏动画”和“动画电影”,这个时候可以通过交互图得出一个“宫崎骏动画电影”的候选,不要求所有的token必须得在同一个句子里共现,因此可以把更多的潜在的候选给挖掘出来。
得到交互图之后,通过GCN一层一层的将上下文信息进行迭代,得到每一个节点的node embedding的表示。对于每一个node,会在上面接一层分类器,分类器的作用是判断当前这个节点是不是目标兴趣点的一个部分。由于一个兴趣点是由多个term组成的,因此需要判断当前graph里面有哪一些term是目标兴趣点的组成部分,我们把这个问题抽象成了一个分类问题。
完成第三步之后,就可以得到一个兴趣点里面包含“宫崎骏”、“ 动画”和“电影”三个token。接下来的难点是如何确定token之间的相对顺序,这里将其转换成旅行商问题进行求解。从图里面找到一条遍历当前所有目标节点的最短路径,把这条最短路径连起来之后,就可以得到最终的兴趣点。例如,我们可以得到“宫崎骏动画电影”就是我们目标挖掘出来的一个兴趣点。
我们的兴趣点图谱一共挖掘了1200个分类,46万个概念,1.2个话题,8.6万个事件和198万个实体。我们把概念和事件都进行了例行更新,每天的都会进行新的挖掘。
3. 关系挖掘-上下位关系挖掘
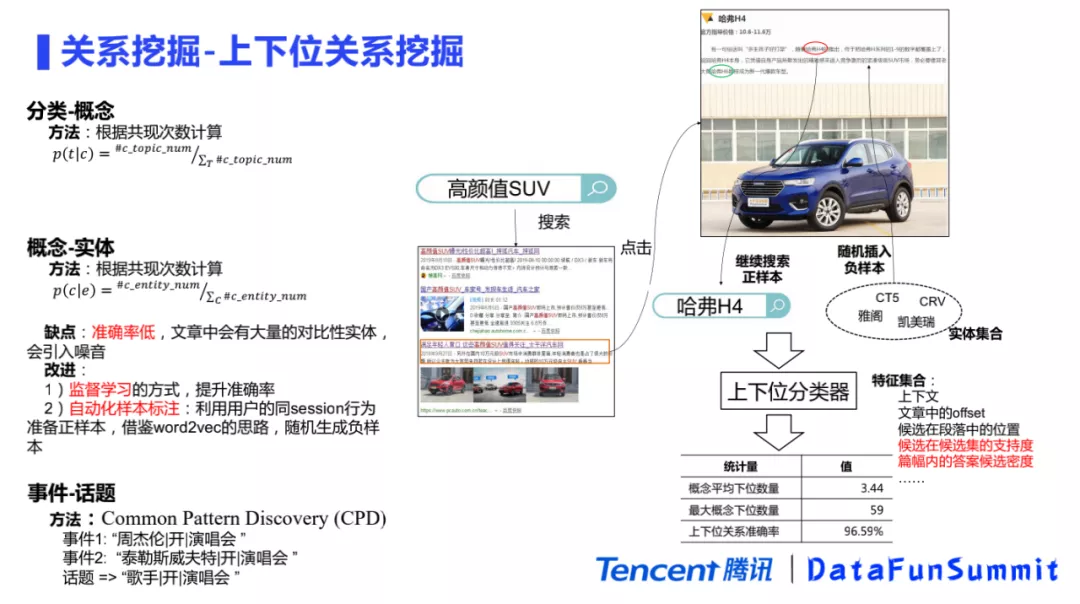
在挖掘完兴趣点之后,下一步就要进行关系挖掘。第一种参与关系主要是事件和实体之间的参与关系,因为这种关系比较简单,就不再做介绍。这一节主要介绍上下位关系,主要包括分类和概念、概念和实体以及事件和话题的上下为关系挖掘。
分类和概念的上下位关系,主要利用分类和概念的共现,计算概念属于某个分类的概率,来判断是否存在上下位关系。如果概念和分类高共现,则可以认为它们可能存在一个潜在的上下位关系。
对于概念和实体的上下位关系挖掘也可以复用上述共现的方法,但是准确率会比较低,因为文章中可能包含大量的对比性实体,从而引入较多的噪声。例如一篇文章主要是讲“宝马XC60的通过性特别好”,但是文章中又枚举了很多通过性不好的车,这个时候就会存在大量的对比实体。可以通过监督学习替换无监督的方式提升准确率。但监督学习标注获取比较困难的,这里提出了自动化的标注样本方式来去获取标注样本。该方法主要是利用用户的同一个session内搜索行为来实现的。例如用户搜索“高颜值的SUV”之后点击了某一篇文章,这个文章里面包含了“哈佛H4”的实体,紧接着用户又把“哈佛H4”放入到搜索引擎里面去搜索。相当于用户同时搜索了“高颜值的SUV”概念和“哈佛H4”实体,因此就可以把“高颜值的SUV”和“哈佛H4”作为一个正样本。负样本的构造借鉴了word2vec的思想,从实体集合中随机采样一些实体插入到文章里面,这些实体和文章大概率是不太相关的,就可以把它们作为负样本。基于构造的样本集训练一个上下位关系来判断实体和概念之间是否存在一个上下位的关系。
另外事件和话题也具有上下位关系,这里采用CPD(Common Pattern Discovery)的方式来进行挖掘。例如有“周杰伦开演唱会”和“泰勒斯威夫特开演唱会”两个事件,我们可以对周杰伦和泰勒斯威夫特进行泛化,他们本质上都是一个歌手,就是他们的上位概念是“歌手”,把这两个事件都进行泛华之后就可以得到“歌手开演唱会”的话题。通过对很多事件进行泛化,可以找出一些频繁的pattern,这个pattern也是一个话题,就可以自然而然地得到事件和话题的一个上下位的关系。
4. 关系挖掘-关联关系挖掘
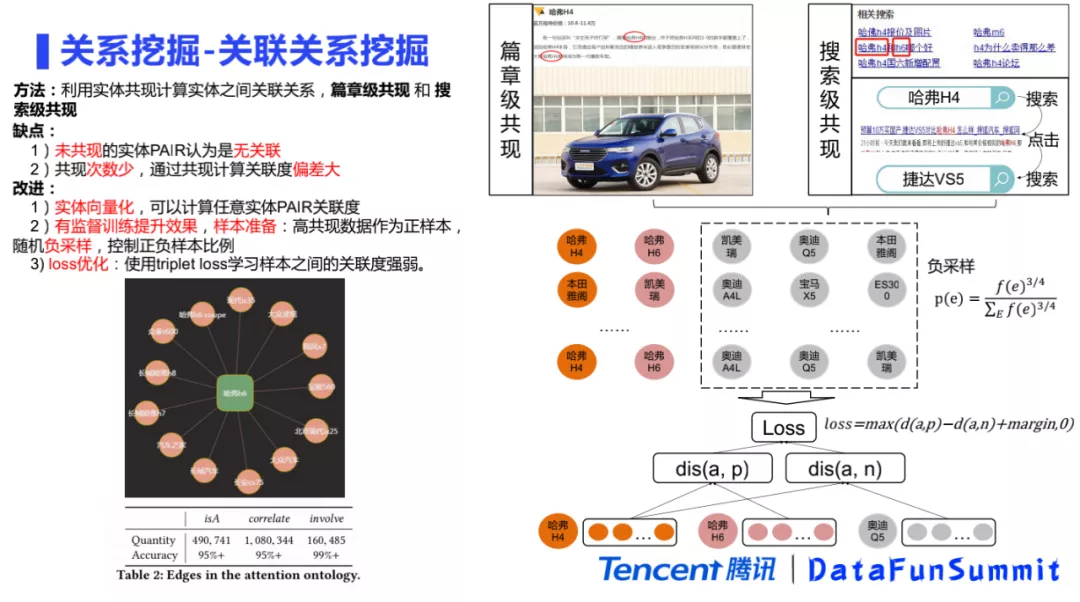
接下来看一下关联关系的挖掘。与上下位关系挖掘思想一致,很容易想到通过计算实体之间的共现来去挖掘关联关系。一种是篇章级共现,如果两个兴趣点经常在同一个篇章里共现,会认为它们之间有关联关系的概率非常高。另外一种是基于搜索级的共现。这里包括两个细类别,第一个类别是在用户搜索的时候,经常会比较两个或多个实体,例如“哈佛H4和H6哪个好”。第二种类别是用户在同一个session中,搜索了A,又搜索了B。这个时候它们之间可能存在一些关联关系,通过共现计算比较简单,是非常容易实现的一个baseline。
当然上述方法也存在了一些问题,如果语料中两个实体的pair对没有共现,就会被认为是无关联的,但实际上很多没有共现的pair对是有关联的。此外,如果共现的次数比较少,通过这种方式去计算关联度的偏差性也会很大。为了解决这些问题,我们又提出了一些改进方式。第一个是把所有的实体进行向量化,这样就可以计算任意两个实体之间是不是存在关联关系。同时可以把之前得到的数据作为训练语料,然后来去进行有监督的训练,从而提升整体模型的泛化效果。在准备训练语料的时候,就是把挖掘得到的高共现的数据作为正样本,负样本则是对一个同类别的实体随机负采样,通过控制正负样本的比例来调整训练语料。最后,选择triplet loss作为损失函数,优点是可以学习到是两个样本之间的关联强度。
兴趣点图谱中上下位关系有49万,关联关系有108万,参与关系有16万,整体的准确率都是在95%以上。
03 兴趣点图谱应用
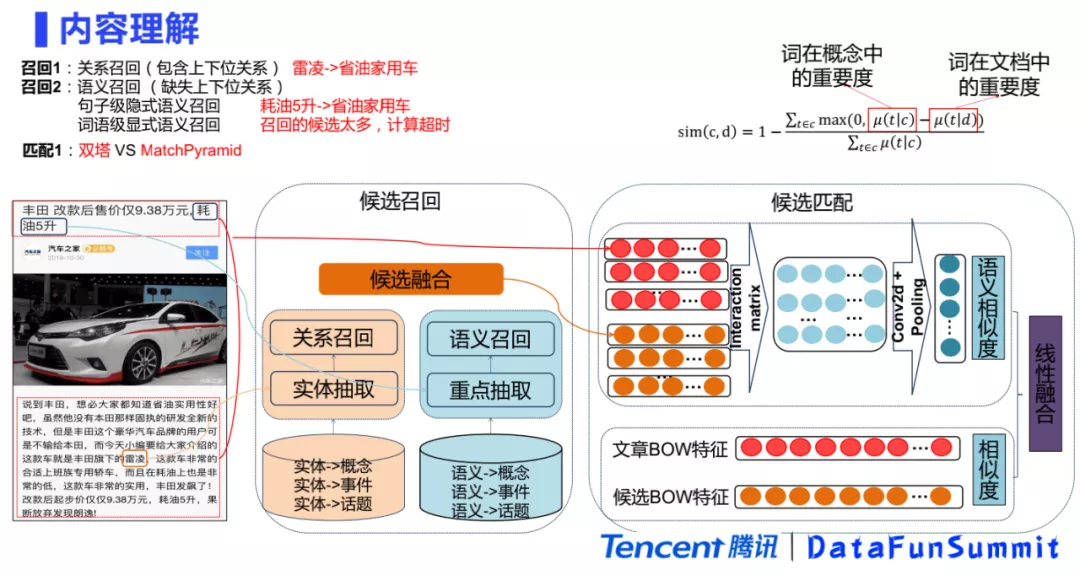
整体介绍完了兴趣点图谱的建设之后,来看一下兴趣点图谱的具体应用。将兴趣点图谱应用于内容理解,对于每一篇文章,希望能预测出适合描述该文章的兴趣点。
上述问题可以拆解成两步,第一步是召回,第二步是匹配。召回又可以分为基于关系的召回和基于语义的召回。基于关系的召回主要是利用图谱中的上下位关系。例如一篇文章中出现了“雷凌”这个实体,它的上位概念是“省油家用车”,就可以把“省油家用车”作为候选的兴趣点召回。由于上下位关系构建可能不全面,或者是有一些文章里面可能没有实体,这时候就需要语义的召回。语义召回包括两种,第一种是句子级别的语义召回,第二种是词语级别的语义召回。例如“丰田改款后售价仅9.38万元,耗油五升”这篇文章,可以把“耗油五升”作为一个句子,通过语义去召回。因为“耗油五升”和“省油家用车”比较相关,所以可以召回“省油家用车”。通过关系召回和语义召回之后,会把所有的候选进行融合,如果候选特别多,匹配的计算量会特别大,很容易造成超时。一个简单的方式是计算document和候选兴趣点的相关度,主要用词在兴趣点的重要度和词在文档中重要度的差异。如果分布的差异比较大,就会认为兴趣点和当前文章相关度不够高。最后,相似度比较高的兴趣点作为最终的候选。
匹配阶段采用的是example的模型。这个模型包含两个部分,第一个部分是Match Pyramid的交互型匹配,它的对语义的焦点把控会比双塔模型更好。双塔模型的主要优点是提可以前计算存储,在线的计算量比较低,但整个模块是偏离线的计算过程,所以可以使用更复杂的交互型匹配。除了语义相似度以外,也会计算文章的BOW特征和候选的BOW特征的相似度,最后把两个相似度融合起来,作为最终的匹配结果。线上的匹配效果显示,概念和事件以及事件和话题的准确率大于87%,概念和话题的覆盖率在30%左右。由于事件会随着热点而变化,覆盖率可能有时会很高,有时很低,它的变化幅度可能是在3% 到15% 之间。
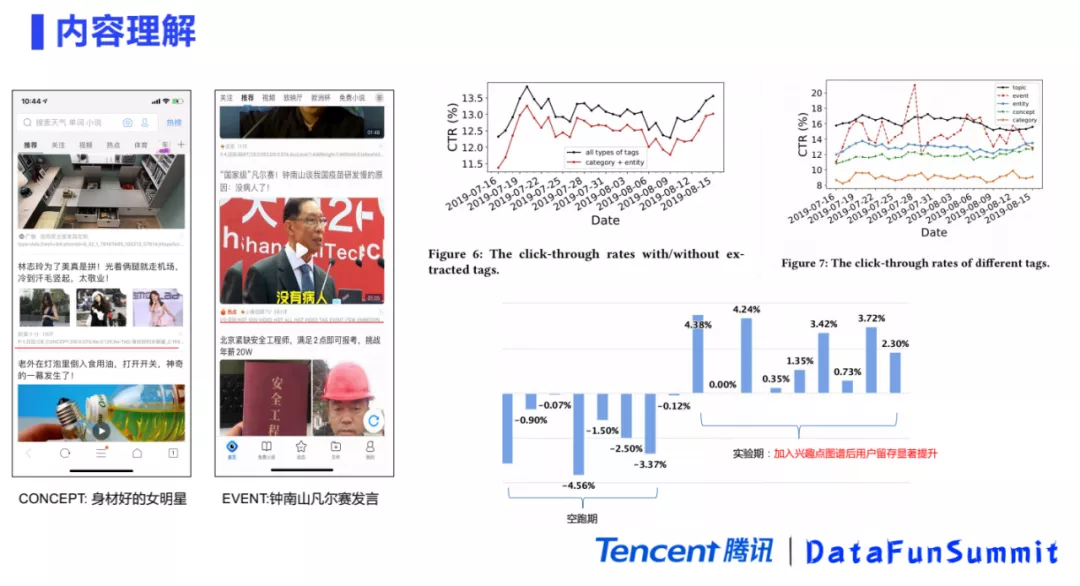
给每个内容提取了兴趣点之后,上面两张图是一个具体的应用的事例。例如,算法提取出来一个概念是“身材好的女明星”,用户有了这个兴趣点之后,就会给他推荐上面“林志玲为了美真的是拼了”这篇文章,可以看出来这两个还是比较相关的。再比如,提取的事件是“钟南山凡尔赛发言”,通过用户累计兴趣点之后,就会给他推荐一个特别聚焦的这样的兴趣召回的事件。
之前提到过信息流有两个问题,第一个问题是推荐不准。第二个问题是信息茧房。为了验证兴趣点图谱的效果,我们进行了ABtest实验。上面两张图是不同类型兴趣点的CTR情况。第一张图上面黑色的曲线是兴趣点图谱的CTR,下面红色的曲线是传统的分类标签的CTR。从这两个曲线可以看出,兴趣点图谱比传统的方式的CTR提高很多,这就能说明图谱对用户的兴趣点刻画得更加精准了,所以用户更愿意去点击,提升了推荐的相关性。
第二张图是兴趣点图谱中不同类型的兴趣点的点击率变化。最底下是分类的CTR,因为分类的粒度非常的粗,它对用户的兴趣点把握是非常不准的,所以CTR就会非常低。上面蓝色的曲线是实体的CTR,因为实体的粒度会比分类的细,所以它的CTR就会比分类高一些。介于它们之间的绿色的曲线是概念的CTR,因为概念是对实体的泛化,所以它的粒度上会比实体粗一点,它对用户的兴趣点刻画粒度相对粗一些,表现在曲线上的CTR也会更低一点点。红色的和黑色的分别是话题和事件,因为话题和事件对比实体来说会更加精准地去刻画用户的兴趣点,所以CTR都会比实体的更高一些。
图中的下面部分是用户留存的指标图,在加入兴趣点图谱之后,用户的留存指标有一个明显的提升,这里就可以推导出兴趣点图谱其实是能推理出用户的消费动机,提升了整体推荐的多样性,缓解了信息茧房问题,所以用户更愿意留在我们的平台去消费更多的咨讯文章。
04 问答环节
Q:兴趣点图谱的概念层和话题层是怎么抽取的,一般采用什么方法?
A:概念层和话题层的提取,首先采用了基于Query-Title对齐的方式。例如用户搜索了“省油家用车”这个query,然后他点击了“大陆6大最省油家用车…”的title,通过文本对齐会发现query和title里都有“省油家用车”,就可以得到一个候选的兴趣点“省油家用车”,也就是一个概念。基于pattern的方式也是类似的,可以通过一些pattern集合来挖掘兴趣点。概念和话题都可以用这两种方式去做挖掘,它们的覆盖率比较低。
为了改进覆盖率低的问题,提供了一个统一的模型去做概念和话题的挖掘。首先会构建query和title的二部图,然后通过二部图把所有query里面的节点节点化,最后利用分类模型去判断当前的token在不在目标兴趣点中。例如用户可能搜索的是“盘点宫崎骏著名的动画电影”和“有哪一些宫崎骏经典的动画电影”,这个时候就可以通过这个模型来判断“宫崎骏”和“动画”和“电影”是概念里面的一些组成部分。得到这些组成部分之后,还要去找它们之间相对的顺序关系,这里将其转化为“旅行商问题”去求一个最短路径,就可以得到“宫崎骏动画电影”这个兴趣点。兴趣点类型包括概念和话题都是通过这种方式去挖的。挖掘完之后,通过后处理去判断这个兴趣点到底是概念还是事件还是话题。可以发现,概念通常是一类实体的统一性的总称,比如电影有“宫崎骏动画电影”、“香港鬼片电影”和“香港警匪电影”,它们共同有“电影”的后缀词,我们就可以认为它可能是一个潜在的概念。事件也有类似的pattern,例如“明星刘德华离婚,其中“离婚”是一个动词,我们发现挖掘的兴趣点如果包含某些构词关系,就可以认为它是事件。话题是对事件进行统一的抽象,比如“刘德华离婚”,我们可以把“刘德华”向上的泛华,可以得到他是一个明星,或者说是演员,这个时候就可以得到一个上位的话题是“演员离婚”。
Q:概念层和话题层除了用搜索日志,还可以用其他方式获取吗?比如直接对文章聚类。
A:这其实是可以的。但是我们发现纯文章和query是有区别的,query是真实表达用户的需求,而文章是表达作者想要让用户看到的内容。所以文章一般会比较长,它表达需求的方式可能会偏创作者的角度,这个时候它可能不能很好的去表达一个比较短的并且符合真实用户需求的粒度。通过文章聚类,可以适当的去找出一些比较聚焦或者比较上层的兴趣点,但聚类完之后,到底什么样的粒度是合理的,用户接不接受这个粒度的兴趣点,就会存在问题。所以我们其实是也用过文章,但是发现query的效果会比文章的效果更好一些。
Q:在内容理解中,词在文档中的重要性是如何向量话的?文档事件是基于规则自动提取的吗?
A:第一个问题“词在文档中的重要性”用的是词频的方式。首先会对document之后进行分词,然后计算每个词的比例。具体就是document中所有的term作为分母,当前的term出现的频次作为分子,去计算它的重要度,其实就是TF-IDF公式。
第二个问题是“如何从一篇文章中自动提取事件”。我们这边的内容理解就是怎么样从文章中去提取各种各样不同类型的兴趣点。其实与话题、事件和概念的提取方式是一样的,都是用这个方式去做匹配。给你一篇文档之后,首先要进行召回,例如事件也有一些关键词,但更多的是基于语义去召回。除非这个事件有一些重要的事情,如果它有一些重要的实体参与,比如“刘德华离婚”,这个事件包含两部分,第一部分因为“刘德华离婚”事件包含了参与实体是“刘德华”,可以通过图谱里面的参与关系关系把“刘德华离婚”的事件召回来。第二部分同样可以基于语义去召回,因为“刘德华离婚”或者“明星离婚”,这个时候“离婚”是一个比较重要的关键词,我们可以把这句子做成embedding表示,图谱里面的每一个兴趣点根据它挖掘的时上下文也会做embedding表示,并构建一个faiss索引库。拿到句子的embedding之后,去faiss库里面检索它跟哪一个事件相关
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E5%9F%BA%E4%BA%8E%E5%85%B4%E8%B6%A3%E7%82%B9%E5%9B%BE%E8%B0%B1%E7%9A%84%E5%86%85%E5%AE%B9%E7%90%86%E8%A7%A3/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


