腾讯大幅降低存储成本可搜索快照是如何办到的
作者: 腾讯 高斌龙
导语 | Elasticsearch 7.10 版本最近发布,该版本有一个重磅特性:Searchable snapshots (可搜索快照功能),可以大幅度地降低存储成本。那么 Searchable snapshots 的使用方式和实现效果是怎样的呢,下面就让我们来一探究竟吧!本文作者:高斌龙,腾讯云大数据研发工程师。
一、功能介绍
在 Searchable snapshots 可搜索快照功能发布之前,通过调用 _snapshot API 对索引打的快照,不管是存储在 S3 还是 HDFS 或者是腾讯云的对象存储 COS上,都是不能够直接进行查询的。
快照只能用于数据的冷备份,如果要查询的话需要先调用 API 把快照恢复到集群中,当快照中的索引初始化完成后,才可以去查询。
而可搜索快照功能就使得存储在远端 S3、HDFS、COS 中的快照能够满足查询的需求了,ES 的数据文件不是只能存储在本地文件系统上,还可以支持存储在远端的 S3、HDFS、COS 等存储介质上,实际上实现了存储与计算的分离。
Searchable snapshots 可搜索快照功能预计会给 ES 带来新的繁荣,因为有非常多的用户使用 ELK 架构构建日志系统。日志的数据量是非常大的,但是查询的频率一般比较低,所以用户的痛点是:在满足基本查询需求的条件下同时降低 ES 的存储成本。
现在基于 Searchable snapshots 可搜索快照功能,可以把大量的比较旧的索引都存储到 S3/COS 上,真正需要查询的时候可以去查询 S3/COS 中的数据。因为 S3/COS 本身成本是非常低的,大约只有 SSD 磁盘的十分之一,所以使用 ES 存储数据的成本大大降低了。
另外一方面,可搜索快照功能也可以提高集群的稳定性,可以仅仅使用一个较小规模的集群支撑最近一段时间热索引的读写即可,老的索引都可以存放在 S3/COS 中,真正需要查询的时候再去查 S3/COS 中的数据,因为集群规模小,不至于出现一个超大规模的集群存储所有的数据,从而导致集群不稳定的现象发生。
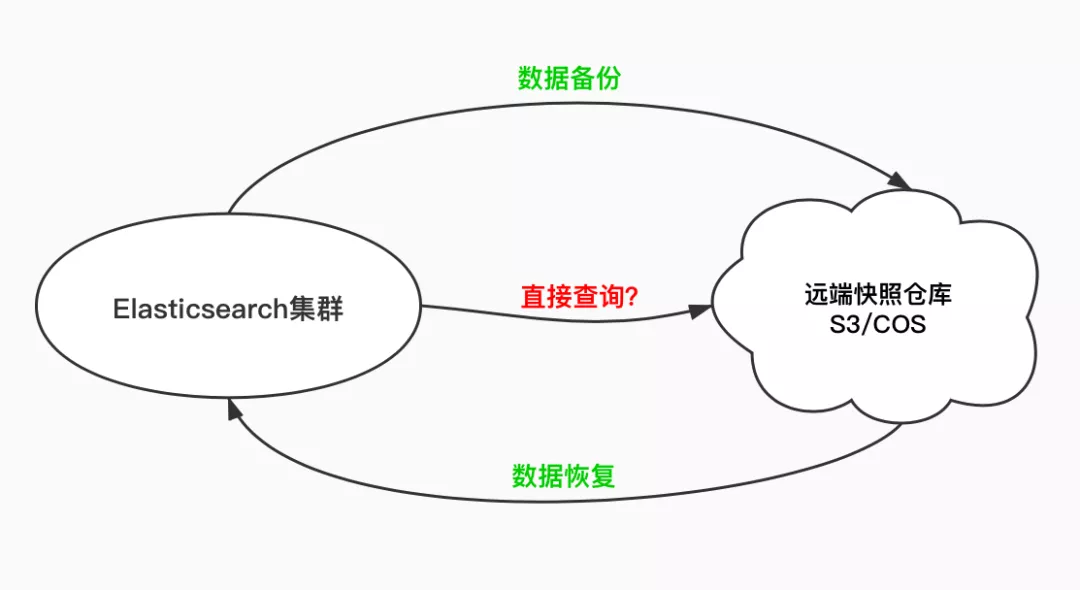
不过就当前 7.10 版本的可搜索快照功能的特点来看,没有我们预想的可以完全实现存储计算分离。
因为当把一个存储在 S3/COS 上的快照 mount 到一个集群中时,需要先执行快照恢复,把快照中的文件从 S3/COS 读取到集群的本地磁盘上,快照中的索引先进行初始化,索引所有的数据文件恢复完毕后该索引才变为 green。
看起来和我们手动去从快照中恢复索引没有什么两样,区别在于 Searchable snapshots 可搜索快照功能时,在执行快照恢复的这段过程中索引仍然是可以查询的。如果集群本地磁盘上的索引文件不存在的话就直接去 S3/COS 中去读,只不过读的过程会比较慢。
而为什么需要先把数据文件从 S3/COS 恢复到本地呢?官方的解释是这样可以保证查询性能,在一个可搜索快照中的索引完全初始化完成后,读取该索引和读取普通的索引的性能几乎没有差别。实际上可搜索快照类型的索引在集群的本地磁盘上存放了完整的一份数据文件,只不过命名规则和普通的索引不一样。
因为当前 7.10 版本的可搜索快照功能,数据还需要从 S3/COS 中恢复到集群的本地磁盘上缓存一份,所以该功能真正的用处在于可以节省最多一半的存储空间。
可搜索快照类型的索引在集群中默认副本数为 0, 数据的可靠性以及弹性完全交由 S3/COS 来保证,不需要额外给索引增加副本,从而可以降低一半的存储成本。
当集群中可搜索快照类型的索引的分片因为节点故障不可用时, ES 会自动地从 S3/COS 中读取分片对应的数据文件进行恢复,从而保证数据的可靠性;如果需要提高可搜索快照类型的索引的副本数量,也是直接从 S3/COS 中读取数据,而不是从本地磁盘上复制主分片的数据文件。
利用当前版本的可搜索快照功能,我们可以对一些老的查询频率非常低的索引,先备份到 S3/COS,之后删除,然后再把备份好的快照 mount 到集群中,使得这些索引下需要的时候仍然可以查询。
在极端情况下,实际上只需要对这些老的查询频率非常低的索引,只进行备份,真正需要查询的时候再 mount 到集群上,当然,需要容忍缓慢的查询过程。
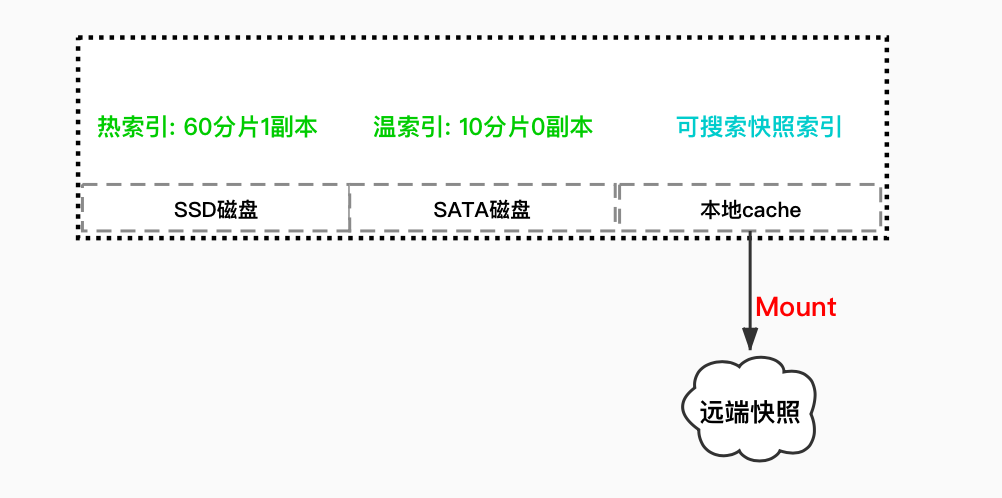
当前 7.10 版本的可搜索快照功能的为 Beta 版,社区里也给出了该功能的路线图,会在将来的版本中实现完全的计算存储分离,直接去访问 S3/COS 中的索引数据完成查询, 而不是像当前这个版本需要先恢复到本地磁盘中。
所以总的来说,当前 7.10 版本的可搜索快照功能,一方面可以降低一半左右的存储空间,大大的节省了成本;另外一方面保证了从快照中恢复到集群上的索引的查询性能,使得应用层不必感知到这种新的存储方式带来的变化。
二、使用方式
可搜索快照的使用方式比较简单,我们可以选择通过手动调用 API 来把远端的快照 mount 到集群中,也可以在 ILM中 使用。
1. 手动mount快照
直接调用API:
POST /_snapshot/my_repository/my_snapshot/_mount?wait_for_completion=true
{
"index": "test",
"renamed_index": "test1",
"index_settings": {
"index.number_of_replicas": 0
},
"ignored_index_settings": [ "index.refresh_interval" ]
}
上述操作把快照 my_snapshot 中的 test 索引挂载到集群中,重命名为 test1, 挂载后的索引副本数设置为 0, 同时忽略掉旧索引中设置的 index.refresh_interval 参数。
在执行完上述操作后,可以看到集群中出现了一个新的索引 test1, 集群当前状态为 yellow,test 索引的分片执行初始化,初始化完成后,test1 索引状态变为 green。
此时查看新索引 test1 的 settings,发现其和普通的索引有以下不同点:
{
"test1":{
"settings":{
"index": {
"blocks":{
"write":"true"
},
"recovery":{
"type":"snapshot_prewarm"
},
"store":{
"type":"snapshot",
"snapshot":{
"snapshot_name":"test",
"index_uuid":"p1Opq7gdQz6WTeKgiIEaTw",
"index_name":"test-aggregation-2020-11-25-02",
"repository_name":"my_repository2",
"snapshot_uuid":"Muy7vsiLSWKbQf3mJALfLw"
}
}
}
}
}
}
- index.blocks.write 默认为 true,也即可搜索快照索引默认是只读的;
- index.recovery.type 为 snapshot_prewarm, 意味着数据是从快照中恢复的;
- index.store.type 为 snapshot,区别于普通索引的 fs 方式。
另外需要注意的是,索引 test1 恢复到 green 后,除了索引的部分元数据和底层的数据文件命名方式与普通的索引不同,索引自身的一些数据结构如 FST 也是常驻内存的,并不会在查询完毕后自动释放掉内存,所以此时已经和普通的索引区别不大了。当然,新索引test1也是可以冻结的,冻结的执行过程和普通的索引相同。
2. 在ILM中使用
在 ILM 索引生命周期管理中也可以使用可搜索快照功能,通过 API 使用该功能的基本用法如下:
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"cold": {
"actions": {
"searchable_snapshot" : {
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E5%A4%A7%E5%B9%85%E9%99%8D%E4%BD%8E%E5%AD%98%E5%82%A8%E6%88%90%E6%9C%AC%E5%8F%AF%E6%90%9C%E7%B4%A2%E5%BF%AB%E7%85%A7%E6%98%AF%E5%A6%82%E4%BD%95%E5%8A%9E%E5%88%B0%E7%9A%84/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


