腾讯布隆过滤器原理与应用
导语 | 开通微信时,系统如何判断你输入的手机号没被注册?如何使用更少的存储空间、更快的速度解决这个问题?对于这个问题,腾讯微信支付数据开发工程师杭天梦带来了她利用Bloom过滤器解决此类问题的思考,向大家分享。本文分享的主要内容为Bloom过滤器的简介、原理、应用和结论等。

“开通微信时,系统如何判断你输入的手机号没被注册?如何使用更少的存储空间、更快的速度解决这个问题?”
对于这个问题,最暴力的方法为:
通过遍历来判断是否被注册。那么时间复杂度为O(n),空间复杂度也是O(n)。
稍微学过算法的同学会说:
使用HashMap,时间复杂度瞬间降到O(1)。
精通算法的同学可能会说:
使用Bitmap,因为Bitmap只需要存储数据的状态信息(0和1),这样空间复杂度为O(max_value)。
下面问题又来了:
如果n=10亿,将会占据多少内存?
假设整数为64bit=8Byte,
Hashmap:10亿整数需要8G的内存
Bitmap:
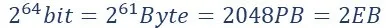
虽然速度提上去了,内存占有量无法想象的…大!
那如何既保证查询效率,又保证低内存占用?
下面我们的主角闪亮登场—— 布隆过滤器。
一、Bloom过滤器的简介
Bloom过滤器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。
它实际上是由一个很长的二进制向量和一系列随机映射函数组成。
它的目标是——占用更小的空间的前提下,检索一个元素是否在一个集合中。
二、原理介绍
下面我从三个方面来介绍布隆过滤器:构造、检索、效果。
1.构造
构造主要包括以下三个步骤:
- 选择k个哈希函数
- 将待检索字符串分别做Hash映射
- 每个映射的值对应的bit数组置为“1”
我举一个简单的例子:
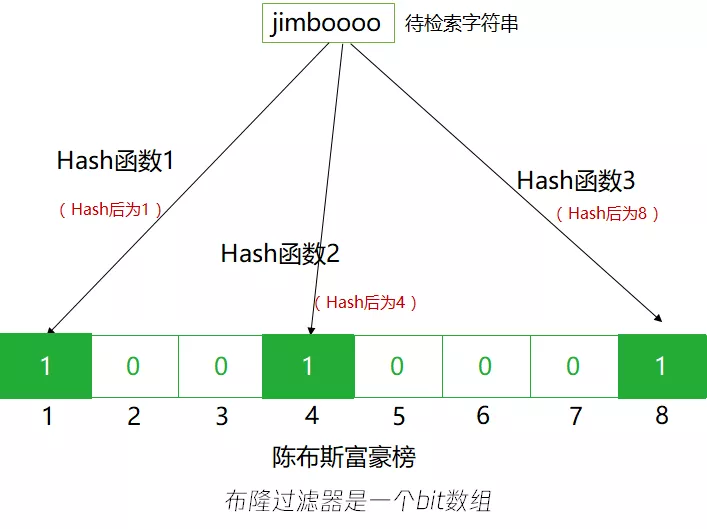
假设我们有3个哈希函数,有两个待检索字符串"jimboooo"和"luckyyyyy"。
对于字符串"jimboooo",经过三个哈希函数映射后,将1,4,8的位置置为“1”。
同理,对于字符串“luckyyyyy",我们经过哈希函数映射后,将位置2,4,7置为“1”。
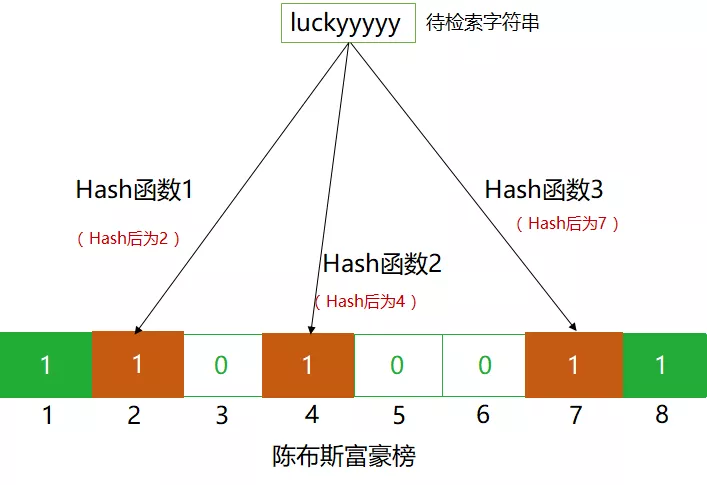
那么,我们的布隆过滤器已经构造完毕了。
2.检索
- 将待检索的字符串通过k个哈希函数映射;
- 查看映射的整数对应的位置是否1,如果都为1,说明待检索字符串是存在的。
下图是我们构造过程得到的数组,如果要检索"jimbooo",哈希映射后是2,4,7,这三个位置都为1,说明此字符串是存在的。如果要检索"fukuoka",映射后是1,3,4,因为3的位置为0,很明显它是不存在的。

3.效果
布隆过滤器的原理已介绍完毕,看起来十分简单。那可能会出现什么问题呢?
如果要检索的字符串(原本不存在)映射后数组每个位置恰好都为1,那就出现了误判!

我们来通过公式了解下它的误判率、布隆过滤器长度以及哈希函数个数之间的关系吧。
先上公式(推理见附录):
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数(待检索元素总数),p 为误报率,
当且仅当:
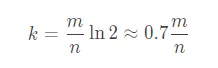
误报率p取得最优解:
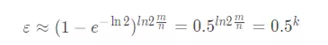
根据公式就可以得到布隆过滤器的长度、误识率、待插入元素个数(待检索
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E5%B8%83%E9%9A%86%E8%BF%87%E6%BB%A4%E5%99%A8%E5%8E%9F%E7%90%86%E4%B8%8E%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


