苏宁苏宁易购订单搜索系统架构及实现

背景
随着苏宁易购平台规模的飞速发展,平台的订单量呈现指数级的增长,存储容量已达 TB 级,订单量更是到了万亿级别,尤其在双 11 大促流量洪峰的场景下,面临两个挑战:
1、如何存储如此巨大的数据量
2、如何提供高并发、低延迟、多维度的检索服务
传统关系型数据库无法支撑多维度的模糊检索,为此,我们选用了 elasticsearch 来提供索引服务,原因如下:
1、技术及配套组件成熟
2、有较大的用户群体,且社区活跃
3、提供简便易用的 api 服务,易上手
4、具有快速的水平及垂直扩容能力,具备高可用,高性能的特征
集群整体架构
按查询维度以及目标使用人群,分为以下集群
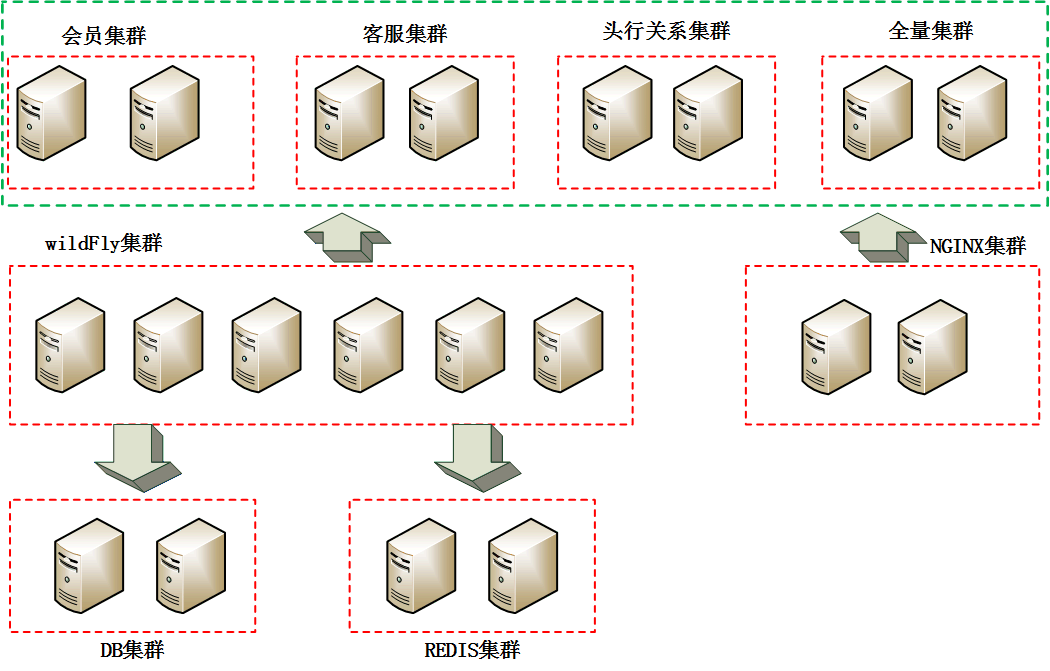
1:全量订单字段集群:保存了全部订单数据,目前主要用于:1)其他索引集群字段初始化时提供数据来源。2)搜索出订单 ID 时,根据 ID 取出该订单所有字段详情,由于订单号即为 docId,所以直接 get 速度很快。数以亿计的订单,不可全由一个索引承载,应进行分索引处理。由于订单号本身就是分段使用的,根据订单号生成规则,我们将这些订单均匀分配到多个索引中,这样可以控制索引大小并有效分散数据。索引规则定下来了,shard 数按照每个 shard 不超过 30G 的原则来分。如果单个 shard 的容量突破 30G 时,可以根据订单号生成的时间维度,建立新的集群,在应用层路由到不同的集群和索引。
Elasticsearch 的正确使用姿势应该只是用于建索引,而不是存储数据,但是该集群由于历史原因一直保存了下来,我们后续会将该部分数据迁移到公司大数据平台上。
2:会员搜索集群: 该集群搜索字段相对较少,每次搜索请求需要附带会员号,主要用于提供给互联网用户搜索“我的订单”时使用。在索引设计上,我们按日期段分索引,以便横向扩展,备份数量根据查询请求量来设计。查询时会带上日期及会员号,根据日期即可定位到索引,按照会员号 routing,能直接定位到某个 shard。由于是按日期分索引,所以当集群规模变得很大时,可以水平无限扩展集群。
3:客服搜索集群:该集群搜索字段相对较多,查询条件不定,为了避免宽泛的搜索条件而对线上顾客查询造成影响,我们单独为客服订单查询建了一套集群。该集群类似会员集群,按日期段分索引,由于该集群对搜索时效没有那么高的要求,所以备份数可以少些。
4:头行关系集群:订单头和订单行关系,高速缓存。
5: Redis 集群:流量高峰时做削峰处理,线性输出且做到对上游系统无感知,以保护 ES 集群
6: wildfly 集群:对外提供 RPC 服务,外界对 ES 发起的查询和数据初始化时一律经过此集群,将查询或写入指令转换成 ES 操作指令,这样屏蔽底层实现,做索引或集群调整时可以做到对上游系统透明,而且可以在接口层灵活控制访问流量。
7: Nginx 集群:提供 ES 插件鉴权服务,防止不受控制的访问 head,kopf 插件及调用 REST 服务,该集群还提供反向代理服务,屏蔽 master 节点 IP(提供 http 服务)。
8: DB 集群:发生错误时,错误指令入 DB,后续做补偿处理。
整体集群示意图如下:
扩容
当系统能力不足时,可选的扩容方案如下:
- 副本数,shard 数都不变,直接添加机器,让 ES 自动再平衡数据,适用于单个节点上有多个分片时。机器数量增加后,单个机器上的索引分片数就相应减少,可以有效降低单个机器的 IO 压力。
2)副本数增加,shard 数不变, 副本数增加后,对写入 tps 会有一定的影响,但是能有效提升读 tps。
3)副本数不变,shard 数增加。
此方案需要重建索引,所以在先期建索引时就需要考虑好数据量及增长速度。
由于集群规模大,扩容时机器数量多,所以使用脚本搭建机器环境,在一台机器上操作所有机器的 JDK,ES 参数的配置。SSH 配置,ES 参数配置及服务启动脚本都是通用的,此处不再赘述。
增加搜索字段处理逻辑
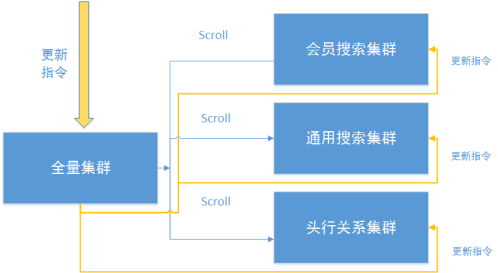
在实际系统运行中,经常会发生需要增加搜索条件的场景(会员搜索集群或客服搜索集群都可能增加索引字段),这时候就需要重新灌数据,需要做好初始化和实时更新的顺序逻辑。
1:当要初始化时,开启初始化模式开关(基于 ZooKeeper 实现的实时配置中心)。
2:从全量集群 scroll 数据集到其他搜索集群。
3:有某个文档的 update 报文过来时,不直接更新搜索集群的目标索引,而是从全量集群 get 出所有目标字段,然后全量覆盖搜索集群中该文档。
这么做是因为初始化灌数据和实时接收报文并更新是不同的线程,如果初始化过程中又接收到更新数据的指令,如果先更新了索引集群,然后再拿到全量集群的初始化数据,而拿到后全量集群又发生了更新,则拿到的初始化数据是旧版本的数据,导致搜索集群和全量集群的数据不一致。
引入 redis 集群
为应对写入高峰,在 wildfly 集群前置了一组 redis 集群,填谷削峰, 用于降低瞬时写压力。
为解决异步问题,在写入请求到来时,先入全量集群再入 redis,成功后再返回上游系统成功,上游系统只有在拿到这个成功标识后才会再次写入后续指令,这样就能保证全量集群的数据正确性。目前这个方案的性能可以满足需求,如果需要进一步提升性能,则写入报文全部入 redis 然后直接返回上游系统成功或失败标识,再开启新线程读取报文到全量集群及其他搜索集群,当然用此方案时需要处理好异步线程之间的关系及缓存中的数据顺序。
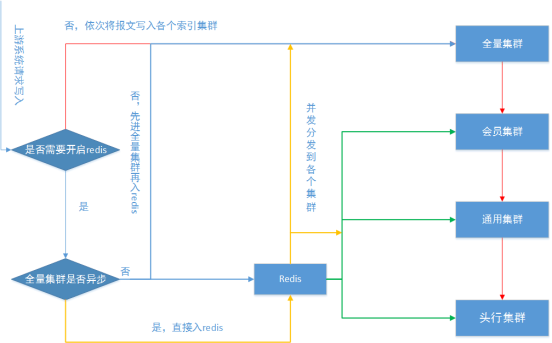
在写入 redis 时既要防止热点分片,也要防止乱序,还要防止数据游离没有线程去消费,为此我们处理逻辑如下:
1:报文先写入全量集群。
2:由于有 10 个 redis 分片,所以取订单号的末位数字,根据此数字找到位于某个分片上的待处理集合(集合名:pending_X),并将订单号塞入该集合。这样可以防止待处理集合产生热点。
3:在 redis 中建立以该单号为 key 的列表,列表中存放的是报文指令(如果列表已存在则直接将报文追加到列表最后)。到此步,上半部分写入就完成了,可以返回上游系统成功标识。
4:新开线程,根据指令对应的订单号,取出待处理集合中的该订单号的 key 并执行 setNx, 如果取到锁,则一直处理该列表中的报文,直到拿不到数据再退出循环。最后删除待处理集合中该订单号,删除后再做一次检验是否有该订单号的列表,防止删除待处理集合中该 key 后又有新的请求过来。
5:定时任务巡检待处理集合中的订单号,如果有某个订单号且 setNx 成功,则说明之前执行队列消费的线程挂掉了,此时定时任务检漏消费。
6:定时任务巡检所有列表,如果某个列表对应的订单号不在待处理集合中,则捡漏消费,防止以上步骤 3 中的最后一步删除了待处理集合中该订单号后又有新数据进来时且消费线程又突然挂掉了。
写入各个集群的示意图如下:
监控及管理
前台应用提供 RPC 服务,当然后端需要有监控管理措施,我们主要做了以下几方面:
安装必要管理插件,包括 marvel,head,kopf,并将插件入口统一集成到 admin 系统,下文有详述。
机器资源使用监控:定时任务请求 ES 自带系统状态服务,拿到各个节点资源使用情况,如有即将达到阈值的资源会及时告警。
缓存监控:监控 redis 中有多少待处理数据,依此判断系统是否有数据积压,以便动态调整消费线程数。
数据修复:如果有数据状态不一致,丢字段的现象发生,则请求上游系统重新下传错误订单数据。
压测数据清理:压测,各个大促节点前必做事项,检测出系统极限能力,判断瓶颈点,以便有针对性的改进。这些数据量大的垃圾数据需要及时清理,释放宝贵系统资源。
此外,为方便运维,减少登录 head 插件的频率,以防误操作,在后台管理系统开发了查询功能。
权限控制
日常运维必用的 head/kopf 插件的安全机制: 默认的 head/kopf 插件是不带权限管理的,任何人只要知道域名就能访问(不能直接访问到 ES 机器,生产办公网段是隔离的),这给生产系统带来极大隐患。在后台管理及插件管理我们先后做了两套方案:
最初方案:在插件域名所在的 nginx 上我们配置了访问权限控制,这个方案运行过一段时间,但是后来发现,权限难免会泄露,对于 head 和 kopf 插件来说还是有一定的隐患,所以用下面的替代方案。
优化后方案:把 head/kopf 插件的源码拿到应用的后台管理系统,访问插件页面时需要输入动态密码(公司内部应用提供的服务),只有配置了认证权限的工号才能访问插件所在页面,对插件页面的请求通过应用服务器发起 http 请求到原先插件域名所在的 nginx 服务器,拿到数据后再在本地展现,原先插件所在域名的 nginx 只有配置了白名单的服务器才能访问,白名单机器限定为应用后台系统的服务器,这样彻底杜绝了权限泄露带来的隐患。
进入集群链接初始页:
点击 marvel 链接后,由于不能操作集群配置,所以还是用原先的 nginx 静态权限:
点击 head 或 kopf 链接后则需要输入动态令牌:
一些需要注意的地方:
ES 对内存的需求较大,设置 java 最大堆时,不要超过 32G,因为一单超过 32G,会有指针压缩问题,不同机器具体阈值不一样,为保险起见,我们设置 -Xmx31g,垃圾回收器我们选择了更适合于大堆内存的 G1。以下是一些我们 的 ES 配置项:
# 数据安全方面,需要防止一次性删除所有索引,可以设置以下配置项:
action.disable_delete_all_indices:true
# 分配 shard 时,考虑磁盘空间:
cluster.routing.allocation.disk.threshold_enabled:true
# 锁定内存,同时也要允许 elasticsearch 的进程可以锁住内存, linux 命令: ulimit -l unlimited
bootstrap.mlockall: true
# 缓存类型设置为 Soft Reference, 最大限度的使用内存而不引起 OutOfMemory
index.cache.field.type: soft
# 设置单播
discovery.zen.ping.multicast.enabled:false
discovery.zen.ping.unicast.hosts: # 所有 master 的 ip:port,
# 防止脑裂,(masterNode 数量 /2) + 1
discovery.zen.minimum_master_nodes:2
# 扩容时,新机器加入集群之前需要关掉自动平衡,机器全部加入集群后再开启自动平衡。
# 关闭自动平衡:
PUT http://xx.xx.xx.xx:9200/_cluster/settings
{“transient”:{“cluster.routing.allocation.enable”:“none”}}
开启自动平衡:
PUT [http://xx.xx.xx.xx:9200/_cluster/setti
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%8B%8F%E5%AE%81%E8%8B%8F%E5%AE%81%E6%98%93%E8%B4%AD%E8%AE%A2%E5%8D%95%E6%90%9C%E7%B4%A2%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E5%8F%8A%E5%AE%9E%E7%8E%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


