蘑菇街增量学习番外篇三的动态正则实践

作者:美丽联合集团 算法工程师 琦琦 ,
公众号关注:诗品算法
0、引言
这篇文章仍是在蘑菇街 增量学习背景下的实践,增量学习的理论很简单,但实践起来,还是有很多细节和trick的。比如,针对不同的模型结构,我们可以设计不同的优化器承接,其对应的动态正则设计方案也会有所差异。
这篇文章是已受理的一篇专利中的核心内容。
对于增量学习整体框架尚不了解的童鞋,看这里:
蘑菇街首页推荐视频流——增量学习与 wide&deepFM 实践(工程 + 算法)
我们在FM和deep 模型训练中,使用了AdaDelta + 动态weight decay/FTRL + 动态L1正则优化器;在wide模型训练中,使用了FTRL + 动态L1正则优化器。*
以下内容以AdaDelta + 动态weight decay为主,其余自适应学习率优化器的原理类似。FTRL优化器自带L1/L2正则,因此只需实现动态L1正则。
1、何为weight decay?
深度学习中的绝大多数目标函数都很复杂,且通常都是高维的。很多优化问题不存在解析解,只能通过基于数值方法的优化算法找到近似解,即数值解。优化在深度学习中的主要挑战是局部最小值和鞍点,其中鞍点更为常见。梯度下降算法中的超参学习率(lr)通常需要人工设定。如果lr过小,会导致参数更新缓慢,需要经过很多次的迭代才能收敛;如果lr过大,参数可能会越过最优解并逐渐发散。因此出现了一大批优秀的自适应学习率算法,如AdaGrad、RMSProp、AdaDelta、Adam等。
-
上面列出的每一种优化算法,虽然可以自动调整学习率,但是对于正则功能却捉襟见肘。比如,若目标函数有关自变量中某元素的偏导数一直较大(或者说变化很快),那么该元素的学习率将下降较快(分母是偏导数平方的累积),同时也会带来正则系数的快速下降。这意味着什么呢? 梯度快速变化参数的正则力度小于那些梯度缓慢变化参数的正则力度。这显然不符合我们对于正则功能的认知。 因此L2正则在这些自适应学习率算法中,并不是那么有效,因为正则系数被“平均”了。具体原因和细节见:
-
之后出现了weight decay的方式,用来替代L2 regularization,使学习率与weight decay实现解耦。多数使用L2正则的自适应优化器,效果往往不如SGD,因此AdamW(Adam + weight decay)绝对是一个优化技术上的变革。
我们在对deep进行优化时,尝试过Adam/AdaDelta/FTRL等优化器,并在这些优化器的基础上实现了动态weight decay/动态L1正则。
2、何为动态正则/动态weight decay?
固定阈值的特征频次过滤 & 固定正则
我们知道, L2正则化的效果是对原最优解的每个元素进行不同比例的放缩;L1正则化则会使原最优解的元素产生不同量的偏移,并使某些元素为0,从而产生稀疏性。 在经典的优化器实现中,L1/L2正则对所有特征都是一视同仁的。但若每个参数的正则力度都是一致的,则会在一定程度上影响模型性能。在样本构建时,我们一般使用固定阈值过滤低频特征。在我们实现的增量框架下,之前在全量样本构建过程中被全量阈值过滤的特征,其频次会被保留,等到下一次增量到来时,若全量中被过滤的这些特征再次出现,则会将全量+当前增量的频次作为该特征的频次。这种对特征出现频次进行计数,只有达到一定阈值后再进入训练的设计方案会破坏样本完整性,如全量频次99,增量频次1,阈值过滤100,则该特征出现的前99次都被忽略,只会训练该特征出现的一次,导致模型训练结果的稳定性差。
动态weight decay设计
针对自适应学习率优化算法,我们使用weight decay替代L2正则,并使weight decay参数随特征出现频次而动态变化,从而动态调整不同频次特征的正则力度。 以AdaDelta为例,相当于我们对传统AdaDelta优化器进行了两点优化,第一点:使用weight decay替代L2正则;第二点:对于不同的特征来说,根据其出现的频次,设置不同的动态正则系数。
特征频次和参数估计的置信度相关,特征在本次训练样本中出现的频次越低,置信度也越低。 因此我们在纯频率统计的基础上增加一个先验分布(正则项),当频率统计置信度越低的时候,越倾向于先验分布,相应的正则系数会更大。
3、AdaDelta + 动态weight decay
算法流程
以首页推荐视频流为例,以历史推荐的曝光样本对应的视频ID以及用户历史点击序列中的视频ID构建deep字典集合。字典中的每一个视频id都是一维特征,用于后续的deep模型训练。
统计出在当前样本中,每个视频id出现的总频次,计作
 。AdaDelta优化器以权重衰减参数替代正则化项,且在特征门限范围内,权重衰减参数与特征样本中特征出现的频次呈负相关。
。AdaDelta优化器以权重衰减参数替代正则化项,且在特征门限范围内,权重衰减参数与特征样本中特征出现的频次呈负相关。
动态weight decay公式,利用了指数加权平均思路,同时考虑当前频次和历史频次总和的影响,使这两个变量同时影响增量模型训练。其中,历史频次在公式中的系数
 较小,在
较小,在
 时刻的特征频次计算公式如下:
时刻的特征频次计算公式如下:

使用AdaDelta优化器进行动态weight decay的实现步骤如下:
- 计算梯度
 ;
; - 利用权重衰减参数,根据公式:

 更新参数;
更新参数;
- 根据梯度
 ,依据公式
,依据公式
 更新参数。
更新参数。
其中,
 表示利用权重衰减系数对参数
表示利用权重衰减系数对参数
 进行更新得到的参数;
进行更新得到的参数;

表示利用梯度对参数
 进行更新得到的参数。
进行更新得到的参数。
 表示每一个特征对应的权重衰减(weight decay)参数,
表示每一个特征对应的权重衰减(weight decay)参数,
 表示惩罚倍数(参考值1.5),
表示惩罚倍数(参考值1.5),
 表示特征门限(参考值1000),
表示特征门限(参考值1000),
 是当前特征在当前训练样本中的真实出现频次(也可以使用上述指数加权平均的结果替代),从增量样本构建提供给增量训练的hdfs文件里取。
是当前特征在当前训练样本中的真实出现频次(也可以使用上述指数加权平均的结果替代),从增量样本构建提供给增量训练的hdfs文件里取。
小疑问——为什么先实施weight decay?再实施梯度下降?
我们来看看源码实现:


首先计算weight decay:_decay_weights_op(),再实施梯度下降: _apply_dense()。
理论上来说,无论是先进行梯度下降再计算weight decay,还是先计算weight decay再进行梯度下降,对最终结果的影响都不大。无非是对当前参数实施衰减还是对上一步的参数实施衰减的区别。
AdaDelta调参小坑
理论上,AdaDelta是没有lr参数的,但是AdaDelta的tf源码实现函数中有lr形参,且其参数值默认为0.01。实践中最好将其设置为1.0,否则AdaDelta的效果不会很好。在tensorflow的google源码中(如下),lr参数是用来乘以更新后的梯度的。
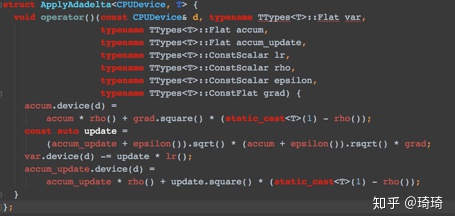
4、AdaDelta + 动态weight decay 代码实现
首先,if_dynamic_regular是一个布尔变量,用来判断是否需要在优化器中加入动态weight decay功能:
|
|
如果选择weight decay功能,核心代码如下:
|
|
其中,emb_matrix表示特征权重矩阵,在wide中,size为feature_size * 1,在deep中,size为feature_size * embedding_size。feat_regular_param与emb_matrix一一对应,表示weight decay/L1正则参数矩阵。
由于emb_matrix在tensorflow中是按照mod方式进行embedding_lookup的,因此feat_regular_param对应的weight decay或L1正则参数矩阵也需要按照mod方式重新排序,保证传给优化器的特征权重矩阵和weight decay/L1正则参数矩阵是一一对应的。
这个矩阵div转mod的设计原则和注意事项见下面的文章:
琦琦:蘑菇街增量学习番外篇一:动态正则之tensorflow中div转mod设计(含代码实现
至此,我们就将蘑菇街增量学习实践中涉及到的相关知识点全部串联起来了。撒花~~~
原创不易,大家多多关注转发点赞收藏!笔芯~
参考:
- [https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/extend_with_decoupled_weight_
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%98%91%E8%8F%87%E8%A1%97%E5%A2%9E%E9%87%8F%E5%AD%A6%E4%B9%A0%E7%95%AA%E5%A4%96%E7%AF%87%E4%B8%89%E7%9A%84%E5%8A%A8%E6%80%81%E6%AD%A3%E5%88%99%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


