要提升微信看一看推荐混排的长期收益试试深度强化学习
导语
相比于传统的监督学习方法,强化学习能够最大化长期收益,正是推荐系统更加需要的。做好当下做好固然重要,但放眼未来才能看得更远。
本文主要是在看一看算法推荐算法过程中的实践,文章主要从强化学习的基本概念、为什么要用强化学习、强化学习在混排中的应用和一些思考四个方面展开论述。
什么是强化学习
(1)基本概念
<A, S, R, P>就是RL中经典的四元组了。A代表的是Agent的所有动作;State是Agent所能感知的世界的状态;Reward是一个实数值,代表奖励或惩罚;P则是Agent所交互世界,也被称为model。
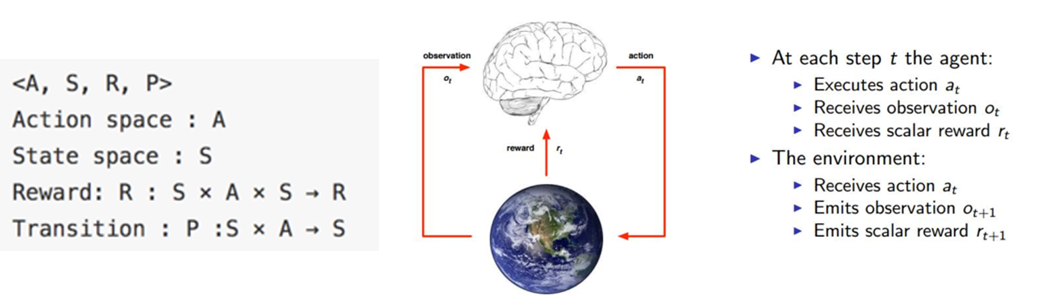
(2)与监督学习,非监督学习的区别

简单来看就是,强化学习与其他最显著的区别就是最大化了长期收益。
(3)Multi-armed bandit 多臂赌博机
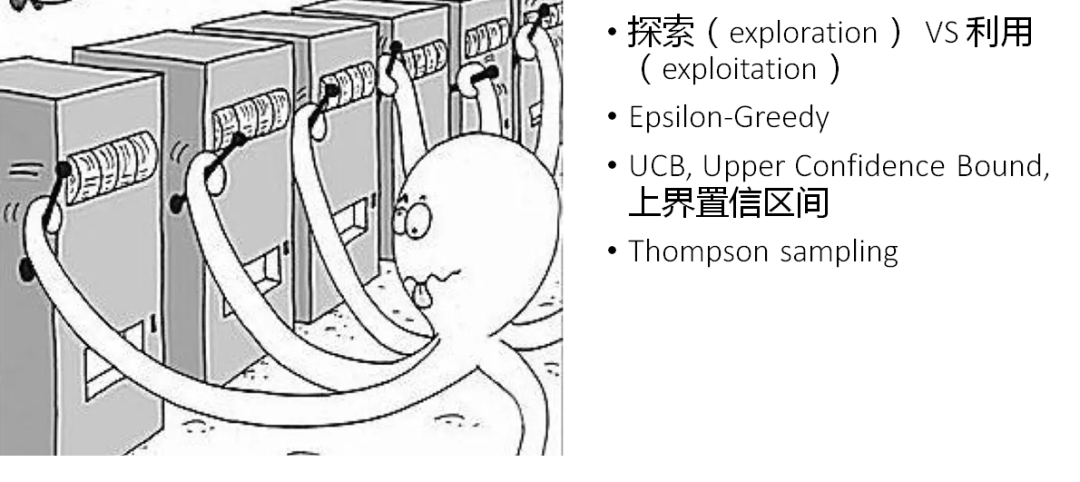
作为大家在推荐算法中最常用的强化学习算法系列,MAB相关算法基本大部分人都很了解,基本思想就是对于未知进行explore,当对于未知有一定认知之后,就用认知到的信息就行exploit。
(4)强化学习的算法和AlphaGo
对于绝大多数的人来说,第一次听说强化学习,还是从AlphaGo战胜李世石了解到的。
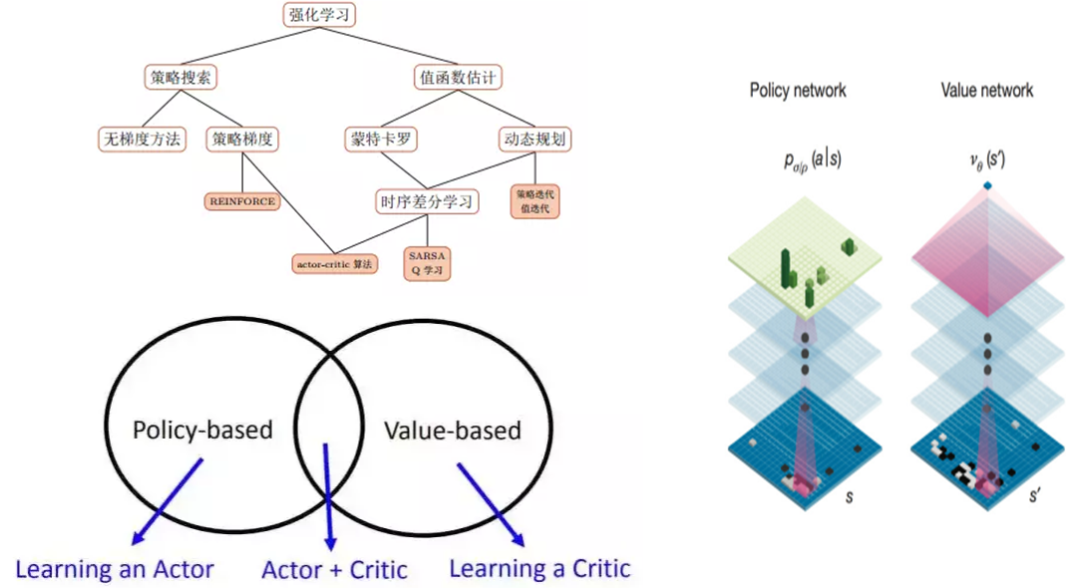
强化学习中常用的算法主要分为两类,policy-based和value-based,而在AlphaGo中就同时应用了这两种类型的网络,分别建立了分析当前局面的值网络和根据当前局面下棋的策略网络。
(5)强化学习实践
如果大家要实践自己的强化学习算法,可以在OpenAI的GYM上去实践。

比如,我们看最经典的CartPole这个游戏:

我们去尝试用经典的QLearning方法来做,


import gym
import random
import numpy
N_BINS = [5, 5, 5, 5]
LEARNING_RATE=0.05
DISCOUNT_FACTOR=0.9
EPS = 0.3
MIN_VALUES = [-0.5,-2.0,-0.5,-3.0]
MAX_VALUES = [0.5,2.0,0.5,3.0]
BINS = [numpy.linspace(MIN_VALUES[i], MAX_VALUES[i], N_BINS[i]) for i in xrange(4)]
def discretize(obs):
return tuple([int(numpy.digitize(obs[i], BINS[i])) for i in xrange(4)])
qv = {}
env = gym.make('CartPole-v0')
print(env.action_space)
print(env.observation_space)
an = env.action_space.n
def get(s, a):
global qv
if (s, a) not in qv:
return 0
return qv[(s, a)]
def update(s, a, s1, r):
global qv
nows = get(s, a)
m0 = get(s1, 0)
m1 = get(s1, 1)
if m0 < m1:
m0 = m1
qv[(s, a)] = nows + LEARNING_RATE * (r + DISCOUNT_FACTOR * m0 - nows)
for i in range(500000):
obs = env.reset()
if i % 1000 == 0:
print i
for _ in range(5000):
s = discretize(obs)
s_0 = get(s, 0)
nowa = 0
s_1 = get(s, 1)
if s_1 > s_0:
nowa = 1
if random.random() <= EPS:
nowa = 1 - nowa
obs, reward, done, info = env.step(nowa)
s1 = discretize(obs)
if done:
reward = -10
update(s, nowa, s1, reward)
if done:
break
for i_episode in range(1):
obs = env.reset()
for t in range(5000):
env.render()
s = discretize(obs)
maxs = get(s, 0)
maxa = 0
nows = get(s, 1)
if nows > maxs:
maxa = 1
obs, reward, done, info = env.step(maxa)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
为什么用强化学习
(1)看一看混排
做混排有几个难点:
数据异构:不同的数据包含不同的特征。
目标不同:不同内容的各自优化目标不同,很难做统一的内容排序。
运算量大:总的计算量高达业务数*每个业务的精排数量。
内容的质量不同:点击率高的优质内容,比如高点击率的视频,会挤压低点击率的业务。
(2)统一的点击率预估排序
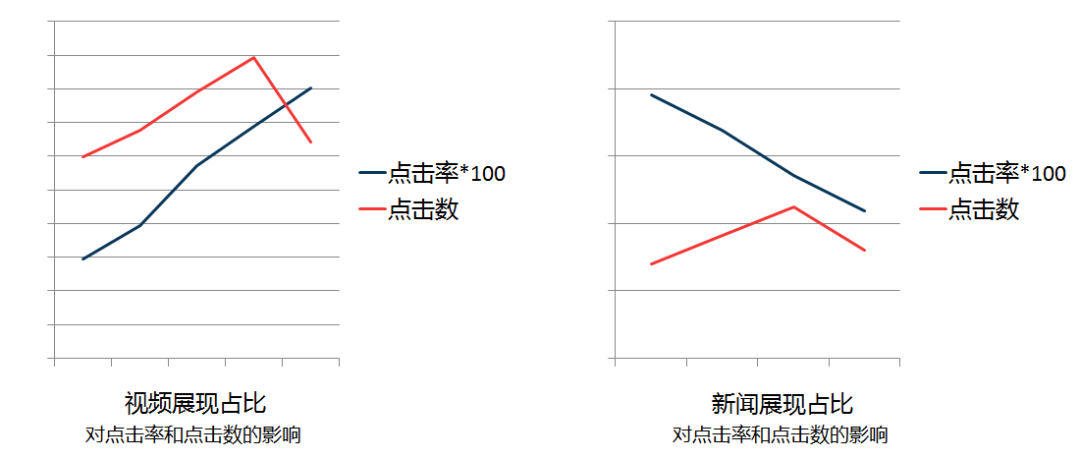
结论:视频是业务中点击率最高的,新闻则是点击率最低的,把点击率高的业务占比提高,点击率低的业务占比降低会提高整体的点击率,但不会提高整体点击数。
(3)强化学习的引入 - 优化长期收益
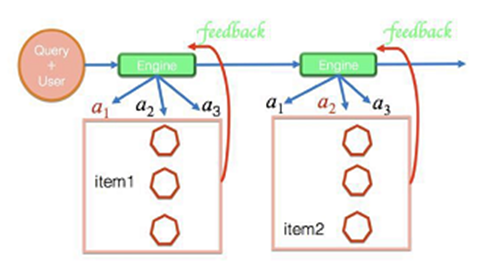
用户在推荐场景浏览可以建模成 Markov Progress。
Agent是我们的推荐系统,Action是我们推荐了什么内容,Reward是反馈信息,包括点击、负反馈、退出等。
每次我们的推荐系统Agent采取某个Action,推荐了内容后,就会收到相应的反馈。
(4)强化学习的优势
为什么强化学习优于监督学习?
混排三路召回,mp,video,news合并
混排三路召回,mp,video,news合并
Case
mp,video,video(0,1,1)
video,mp,mp(1,0,0)
video,video,video(1,0,0)
监督学习预测最优解是第三种,
选择点击率最大的。
强化学习预测最优解是第一种,
选择总收益最大的。
监督学习预测最优解是第三种,
选择点击率最大的。
强化学习预测最优解是第一种,
选择总收益最大的。
强化学习在看一看混排中的应用
(1)Session wise recommendation

(2)Personal DQN
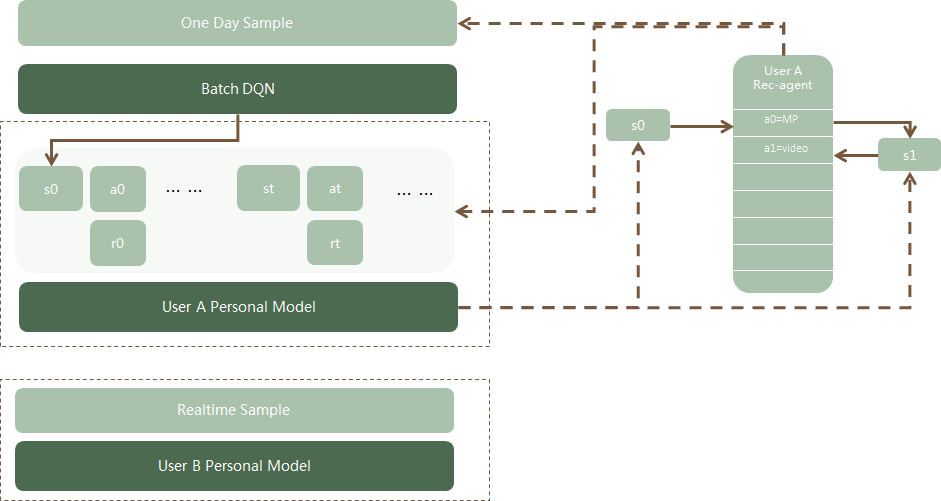
当用户的请求到来时会根据他之前的行为计算隐状态作为此次输入state的一部分,每次选择某个业务作为action,反馈点击作为reward。
(3)离线评估 AUC?
做算法,非常重要的一个环节就是做离线评估,传统的CTR预估用的就是AUC来评价:
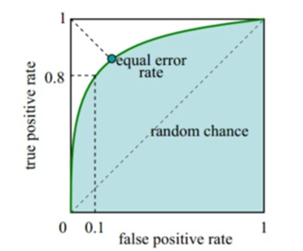
我们先看看传统AUC的意义,传统AUC的意义有两种:假阳率和真阳率画出ROC曲线围成的面积表示了阈值移动情况下真阳假阳的表现。
随机取一个正值和负值,正值的预估值大于负值预估值的概率,即 P(pred(a) > pred(b) | y(a) > y(b))。
利用第二种定义,我们将其进行扩展来定义我们新的AUC:P(Q(a) > Q(b) | sum reward(a) > sum reward(b))。
为什么不像其他很多人一样利用一些模拟器的方式来做评价呢,很多实践表明,模拟器的方式有很大的偏置,利用一些模拟器可能会导致模型学偏。而这里新的AUC表征了实际数据的情况,比起利用模拟器来说更优。
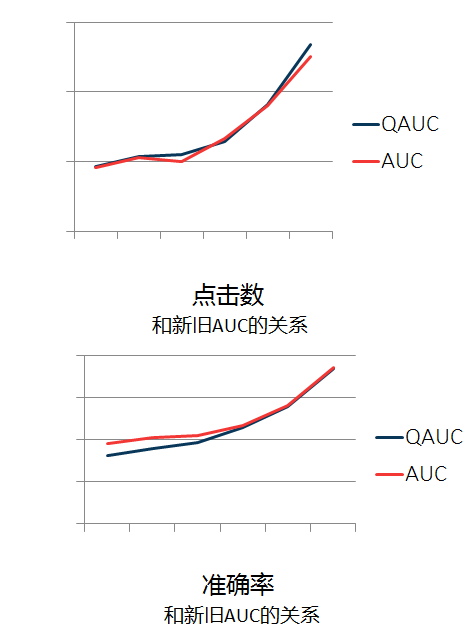
我们可以看到新的AUC更符合我们长期收益的定义,即,最大化总点击数。
(4)线上效果
上线后,我们总的停留时长提高了7%,baseline对比的是规则混排,我们同样对比了相同网络的监督学习的效果,也有1-2%的提升。
(5)模型优化
Session based recommendation
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%A6%81%E6%8F%90%E5%8D%87%E5%BE%AE%E4%BF%A1%E7%9C%8B%E4%B8%80%E7%9C%8B%E6%8E%A8%E8%8D%90%E6%B7%B7%E6%8E%92%E7%9A%84%E9%95%BF%E6%9C%9F%E6%94%B6%E7%9B%8A%E8%AF%95%E8%AF%95%E6%B7%B1%E5%BA%A6%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


