语法中执行顺序探秘
作者: 梁尔舒,李昀晖
写在前面
我们之前应该都了解链表求交、求并的算法,但是很少在实际工作中见过这些算法是怎么体现的,解决了哪些场景下的问题,其实lucene解决链表求交并的算法非常漂亮。最近因为工作中需要排查线上总是出现某些检索DSL执行比较慢,在网上到处找底层具体执行的资料,发现资料少之又少,讲API的文章千篇一律,直到在官网找到一篇 漂亮的文章 还特么全网没找到翻译,便借此机会系统学习了DSL在lucene底层到底是怎么执行的以及 profile API 工具的使用。在这里我把这篇文章的翻译分享给国人,以飨各位长期以来对我的关注和支持!😄
lucene检索执行时序图:
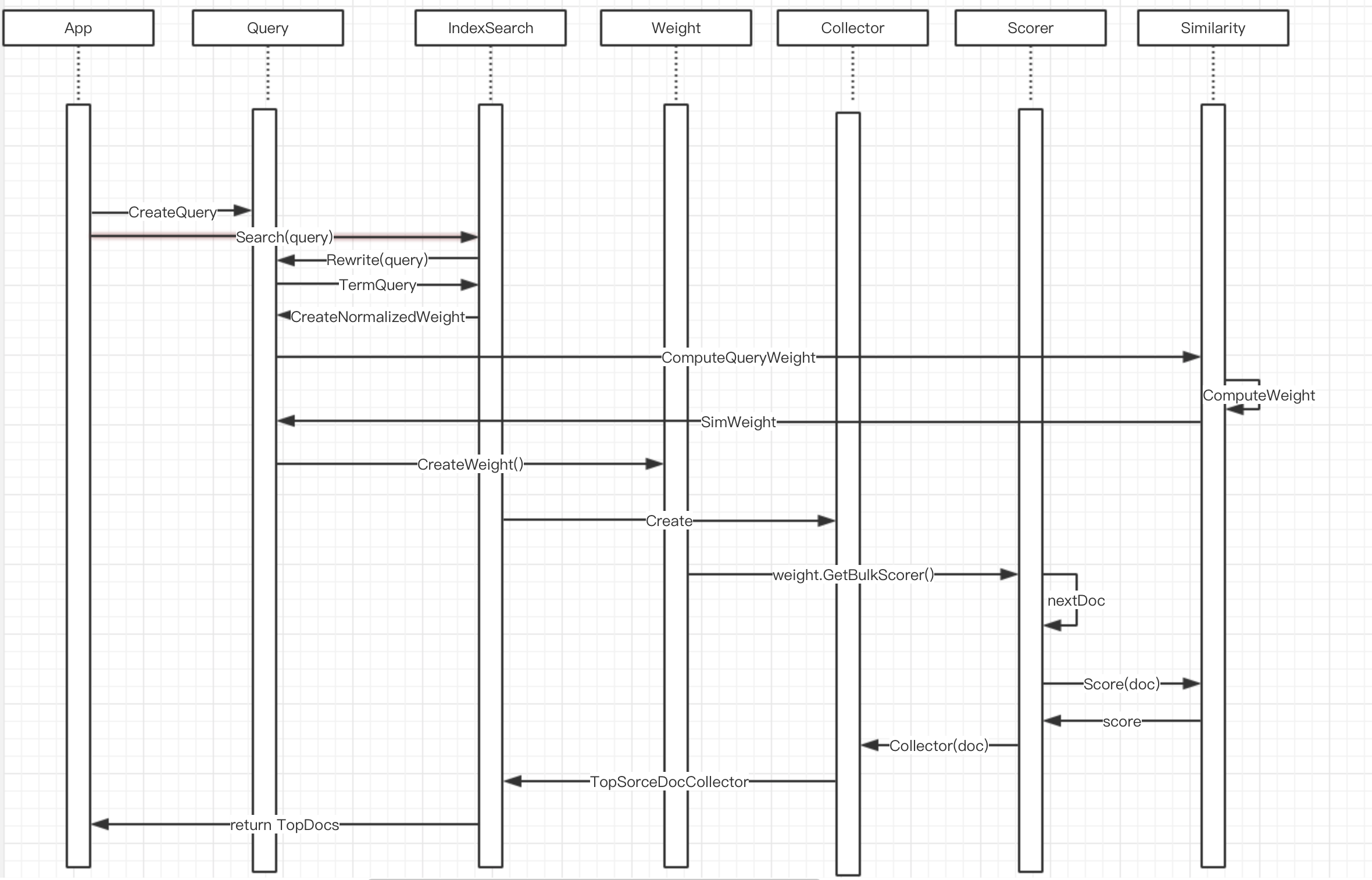
我们现在开始:
我们经常有这样的疑问—— filters 之间执行的顺序是怎么样的,以及filter查询是在query查询之前还是之后,等等这些问题。这确实是非常重要的问题:诀窍就在于执行一个 query 时优先处理 cheap bits(代价更小的比如较短的 posting list)。也许你可能在过去听说或看过 filter 查询的执行优先于 query,因为大家都觉得我们不对不匹配过滤器的文档计算分数。但实际情况要复杂一些。
同样,该问题的措词表明我们要遍历所有文档,并检查 query/ filter 是否一一匹配,而事实则更加微妙:我们的索引结构可以帮助有效地跳过可能不匹配的文档。
查询/过滤器如何运行?
在解释查询如何工作之前,我无法让您深入了解查询的执行顺序。 查询和过滤器具备着以下操作:
cost():查询/过滤器匹配多少文档的近似值。docID():当前文档ID,初始化为-1。advance(target):查找可能匹配的目标之后的第一个文档。(skipList操作)nextDoc(): 查找可能匹配的下一个(按文档ID顺序)文档。 这是Advance(docID()+ 1)的优化版本。*matches():检查当前文档是否匹配。matchCost():调用matches()的成本估算。score():计算当前文档的分数。
这有点复杂,但是存在所有这些操作的充分理由! 在此阶段需要注意的最重要的一点是,匹配的文档分为两个阶段。 首先是一个 approximations 的过程(找到近似匹配的doc),它可以有效地迭代倒排中与查询匹配的文档的超集(超集包含着不匹配的doc),是因为这些超集的迭代是通过 nextDoc / advance 来操作的。 然后,有一个验证阶段,旨在通过 matchs 操作验证当前文档是否与实际匹配。 该设计的目的是确保我们在所有 approximations 之间达成一致后才开始运行代价较大的 posting list,这样理论上整体执行代价最小。 另外,值得注意的是,查询和过滤器之间的唯一区别是我们从不对过滤器调用 score()。
为了更好的理解这些操作,让我实际给你们举一些例子:
Term queries
term 查询是Elasticsearch支持的最有效的查询:它们的匹配项是在倒排索引结构中预先计算的
cost(): 返回doc freq,该doc freq编码在倒排索引中( 在创建Weight时就已从倒排文件中查到)。advance(target): 使用 skip lists 跳转到大于或等于target的位置nextDoc(): 从the postings list返回下一个doc。matches(): 总是返回true.matchCost(): 总是返回0.score(): 根据索引统计信息计算当前文档的分数。
Disjunctions (a OR b OR …)
cost(): 返回子clauses的代价和.advance(target): 在所有子clauses调用advance(target)并返回大于等于target的最小的值nextDoc(): 在所有子clauses调用nextDoc(),返回应该迭代的下一个doc(和advance操作类似)matches(): 基于当前doc id, 迭代所有子clauses,只要有任何一个子clauses为true就返回true,都不匹配返回false
DisjunctionScorer.java 代码片段:
@Override
public boolean matches() throws IOException {
verifiedMatches = null;
unverifiedMatches.clear();
for (DisiWrapper w = subScorers.topList(); w != null; ) {
DisiWrapper next = w.next;
..................
......................
// verify subs that have an two-phase iterator
// least-costly ones first
while (unverifiedMatches.size() > 0) {
DisiWrapper w = unverifiedMatches.pop();
if (w.twoPhaseView.matches()) {
w.next = null;
verifiedMatches = w;
return true;
}
}
return false;
}
matchCost(): 返回sub clauses的match cost总和,以其cost(clauses可能匹配的文档数量)加权(因为与匹配少数文档的clauses相比,我们更可能在匹配多个文档的clauses上调用match())。
if (hasApproximation == false) { // no sub scorer supports approximations
twoPhase = null;
} else {
final float matchCost = sumMatchCost / sumApproxCost;
twoPhase = new TwoPhase(approximation, matchCost);
}
}
score(): 返回匹配当前文档的所有sub clauses的分数加和
因为求并集本质上是关于合并排序的迭代过程,所以 我们使用 heap 来提升效率
Conjunctions (a AND b AND …)
-
cost():返回sub clauses中的最小代价 -
advance(target):- 在具有最小
cost()值的clause上调用advance(target),得到下一个候选的C - 按照
cost()值的升序继续迭代其它的clause,并且在其上调用advance(C),如果这些其都返回C, 那么我们说明当前的C是一个真正匹配的doc。如果返回了其它值,那么将这个值作为新的候选值,并像之前的步骤一样继续迭代其它clause,直到找到下一个匹配。
- 在具有最小
-
nextDoc(): 除了初始化调用nextDoc()时选择在拥有最小的cost()值的clause上,其它和advance(target)调用一样 -
matches(): 按照matchCost()值升序迭代所有的clause,只要出现一个不匹配就返回false, 否则返回true。 -
matchCost(): Return the sum of the match costs of sub clauses.所有sub clauses的match cost总和 -
score(): 返回匹配当前文档的所有sub clauses的分数加和
交替执行子句直到找到共同的匹配项,这有时被称为 “leapfrog” (蛙跳)
Phrase queries
短语查询很有趣,词组查询本质上是一种求交集,在这里我们针对每个文档执行一些其他操作,以检查它们是否匹配。
cost(): 和求交集的含义一样.advance(target): 和求交集的含义一样.nextDoc(): 和求交集的含义一样.matches(): 迭代当前文档的位置,直到在连续位置找到term为止,我们不需要进一步迭代。matchCost(): 公式有点复杂,但是总之,它与短语中使用的term的平均词频成正比。平均词频即:它们在索引中的总出现次数除以包含这些term的文档总数。score(): 保持继续迭代,以查找该短语在当前文档中出现的次数,并使用此短语频率作为分数计算的基础。
这也使您对过滤器为什么比查询性能更好的见解。在这种情况下,过滤器不仅可以跳过得分计算,而且还可以在找到一个匹配项后立�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%AF%AD%E6%B3%95%E4%B8%AD%E6%89%A7%E8%A1%8C%E9%A1%BA%E5%BA%8F%E6%8E%A2%E7%A7%98/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


