贝壳找房图数据库系列简介篇
系列文章:
贝壳找房—【图数据库系列】之 JanusGraph VS Dgraph:贝壳分布式图数据库技术选型之路
在 上一篇文章 中我们已经对当前流行的几款图数据库做过简单的分析,并介绍了我们为什么使用 Dgraph。从本篇内容开始,我们将开启 Dgraph 之旅,探索这个图数据库方向的新贵。
注:本章内容基于 Dgraph v1.1.0
一、Dgraph 组件
Dgraph 架构简单明了,我们结合自身在实践过程中所搭建的集群架构,来介绍各个组件。
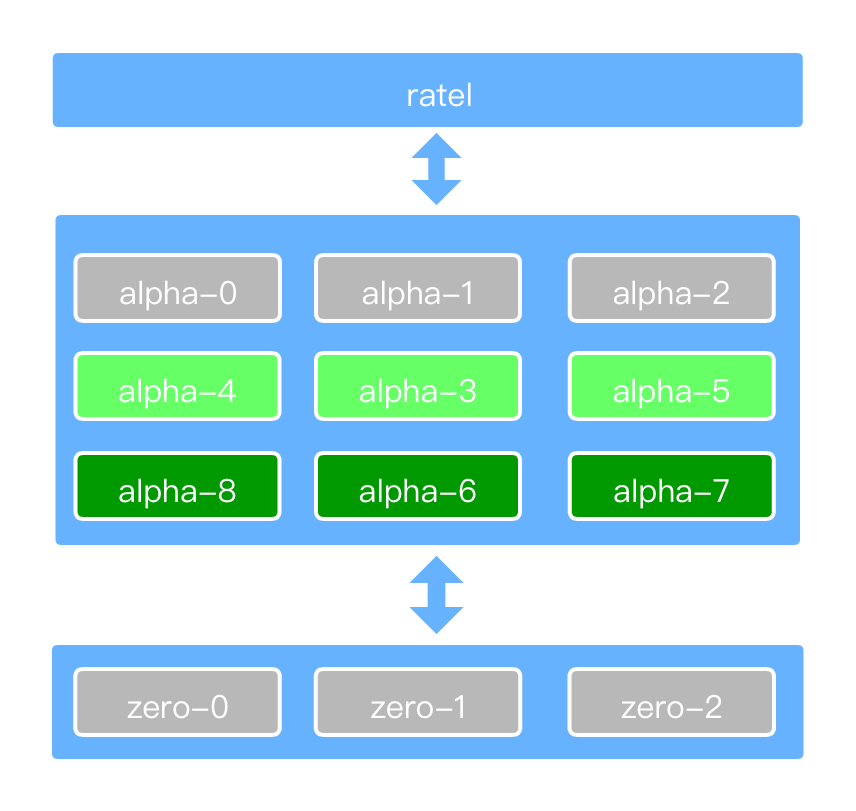
- ratel:提供用户界面来执行数据查询,数据修改及元数据管理。
- alpha:用于管理数据(谓词和索引),外部用户主要都是和 alpha 进行数据交互。
- group:多个 alpha 组成一个 group(即图中同色 alpha),group 中的多个 alpha 通过 raft 协议保证数据一致性。
- zero:用于管理集群,并在 group 之间按照指定频率去均衡数据。
二、Dgraph 数据类型
Dgraph 中所有属性都被称为 predicate,即谓词;每个 predicate 都有确定的数据类型。
数据类型说明defalut默认类型int64 位有符号整数float64 位双精度浮点数bool布尔geo地理位置,目前支持 Point、Polygon、MultiPolygondatetime时间类型,如 2020-02-02string字符串password密码uid边的类型,64 位整形,以 16 进制形式表示,如 0x1,系统默认分配
三、Dgraph 索引及分词器
Dgraph 基于每种数据类型,提供了不同的索引及其分词器。目前,建立索引及分词器的意义在于,建立以后可以使用相应的系统函数。
数据类型可用索引index 索引可用的 tokenizerdefalutlist count index upsertdefalutint同上intfloat同上floatbool同上boolgeo同上geodatetime同上year month day hourstringlist count lang index upsertexact hash term fulltext trigrampassword–uidlist count reverse-
注:
- count 需要和 list 配合使用,即选用 list 后,才可选用 count
- upsert 需要和 index 配合使用,即选用 index 后,才可选用 upsert
- 对于 string 类型使用 tokenizer 时,exact、hash、term 只能任选其一
四、Dgraph 实践
本节,我们将从零开始,教大家如何搭建最简单的 Dgraph 服务,并一步步地进行 Dgraph 的操作。
服务搭建
Dgraph 支持物理机安装及 docker 安装,并且服务搭建非常简单,最小规模只需 1 个 zero 节点,1 个 alpha 节点,1 个 ratel 即可启动一个服务。下面我们以物理机安装为例,介绍服务如何搭建。
- 服务下载
通过
curl https://get.dgraph.io -sSf | bash
或者
wget https://github.com/dgraph-io/dgraph/releases/download/v1.2.0/dgraph-linux-amd64.tar.gz
即可完成安装包下载,两种方式的区别仅在于第一种只可以下载官方最新 release 的版本,第二种可以指定版本。下载完成后,将压缩包解压到指定目录即可,解压后的内容如下:

2、启动 zero
./dgraph zero
更多关于 zero 的参数,可通过。/dgraph zero –help 查看使用方法。
3、启动 alpha
./dgraph alpha --lru_mb 2048 --zero localhost:5080
此处的 5080 端口是 zero 节点启动的默认 grpc 端口。关于 alpha 的更多参数,可通过。/dgraph alpha –help 查看。
4、启动 ratel
./dgraph-ratel
通过 ratel 默认端口 8000,即可访问图形化界面:
至此,Dgraph 服务就启动起来了。
Dgraph 操作
当前,Dgraph 提供 ratel、http、client 三种方式对图数据库进行相应操作。接下来我们将通过 ratel 的方式来介绍 Dgraph 的常规操作。
alter
说明: 操作图数据库元数据,如 schema、type 的新增、修改、删除等。
格式:
< 谓词 >: 类型 索引类型 .
示例:
创建名为 test_name、test_age 的属性及 test_friend 的边
<test_age>: int @index(int) .
<test_name>: string @index(term) .
<test_friend>: [uid] .
http://rna.6aiq.com/image-2f04955a7cd5453b955b4a2f0b52f230.png 执行后通过 schema 界面查看结果如下

可见,我们的 schema 已经建立成功。在 ratel 中,我们还可以直接通过界面来更快捷的操作 schema
mutate
说明: 对图数据进行相应的新增、修改、删除等。
格式:
新增
{
set{
_:任意标识符 < 谓词 > "值" .
}
}
修改
{
set{
<uid> < 谓词 > "新值" .
}
}
删除
{
delete{
<uid> < 谓词 > * .
}
}
示例:
新增两条数据,jack 及 rose,他们为朋友关系
{
set{
_:jack <test_name> "jack" .
_:jack <test_age> "20" .
_:jack <test_friend> _:rose .
_:rose <test_name> "rose" .
_:rose <test_age> "22" .
}
}
执行结果如下图
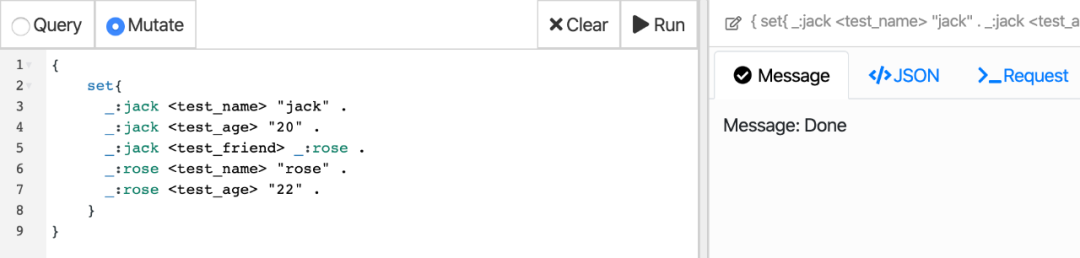
我们查询该数据确认是否执行成功
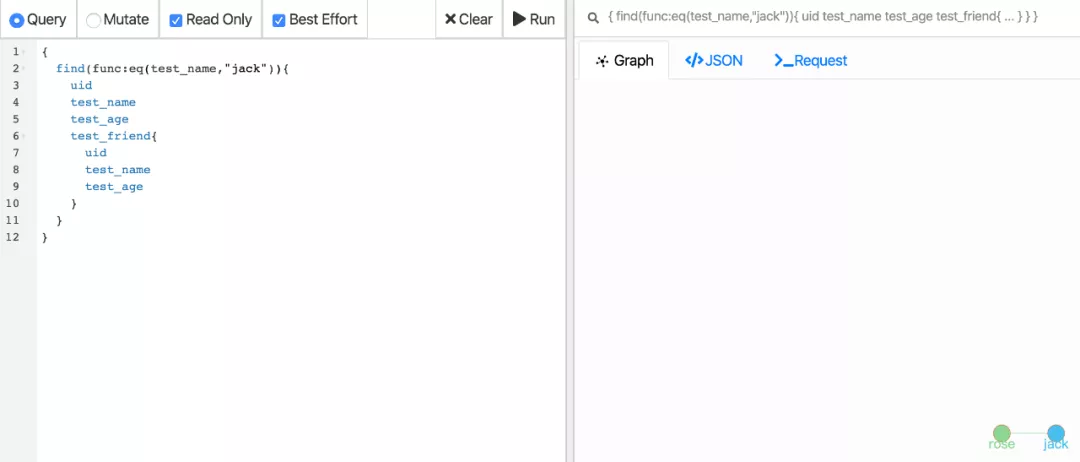
如图中数据所示,我们有 jack 和 rose 两个点,他们之间有一条叫做 test_friend 的边。
我们从数据的角度再看一下
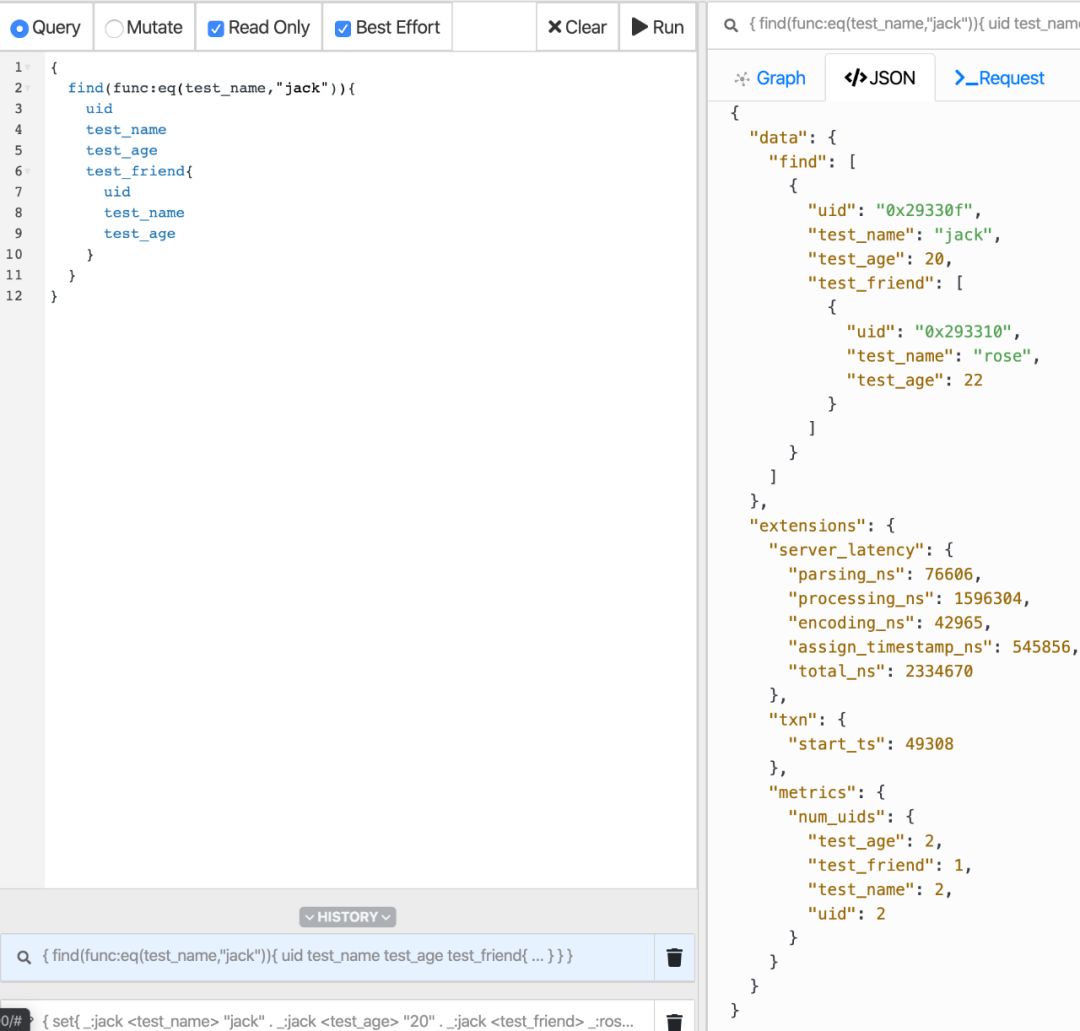
所有数据一览无遗
upsert
说明: 对符合条件的数据进行新增或修改,类似 query+mutate 的组合。
格式:
upsert{
query{
自定义方法名(func:方法){
v as uid //将 uid 赋值给变量 v
}
}
mutation{
set{
uid(v) < 谓词 > "值" .
}
}
}
示例:
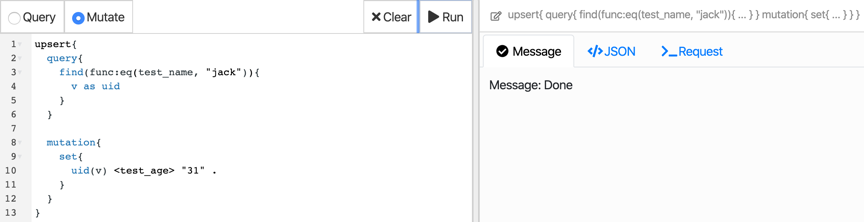
通过 upsert 将 jack 的 test_age 改为 31
upsert{
query{
find(func:eq(test_name, "jack")){
v as uid
}
}
mutation{
set{
uid(v) <test_age> "31" .
}
}
}
执行后界面如下
我们通过查询来确认该条数据已被修改
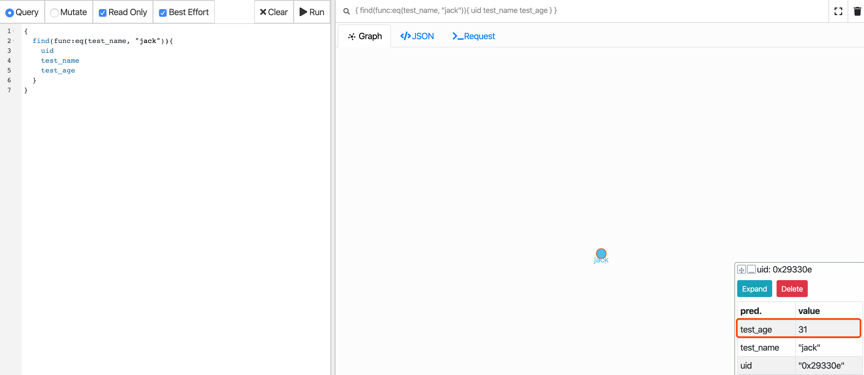
query
说明: 查询图数据库信息,如数据,schema 结构等。
格式:
{
自定义方法名(func:方法){
结果中需要展示的谓词
}
}
我们还可使用一些系统函数来进行查询,如
schema{}
示例:
通过 schema{}查看已经定义的 schema
schema(pred:[test_name,test_age]){}
执行后界面如下
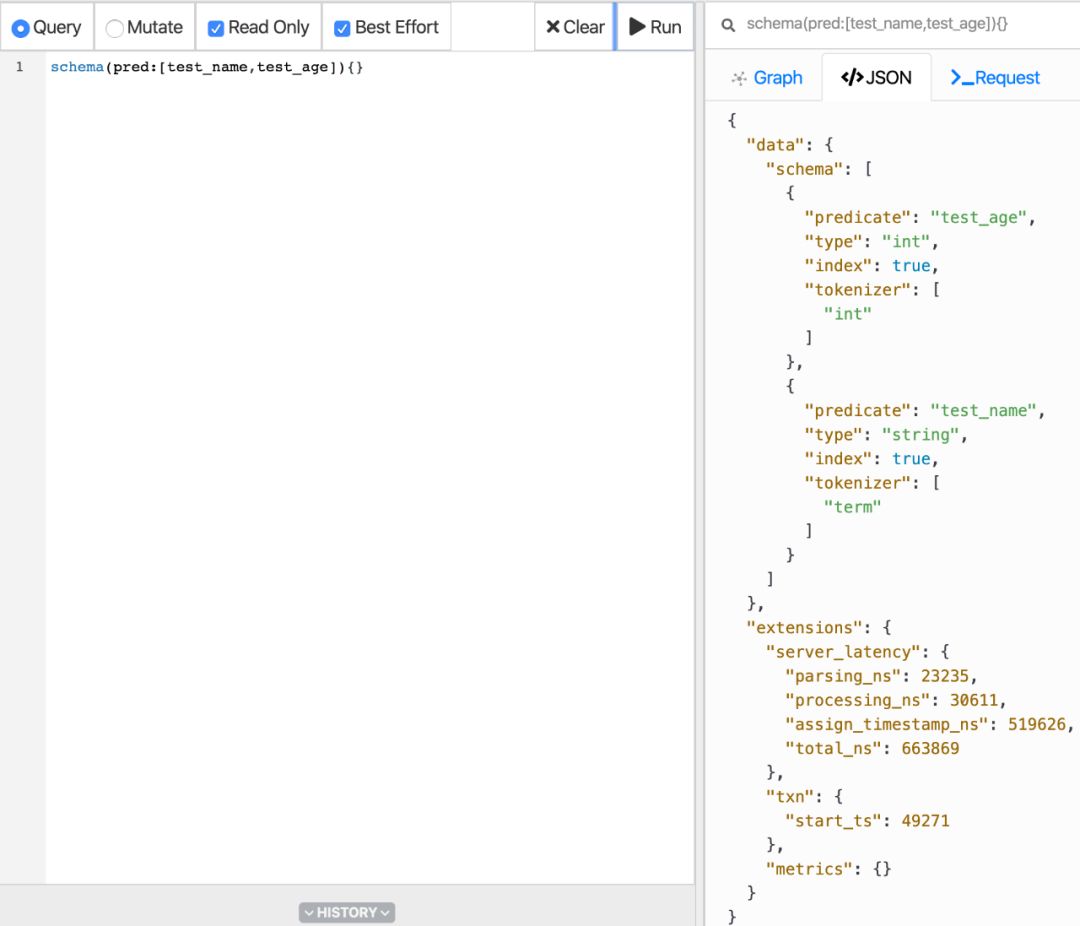
到这里,可能有些人会问,除了讲述 mutate 那里,我们看到两个点及其之间的关系,那么 Dgraph 作为图数据库,是否支持多度关系呢?
答案当然是肯定的,下面我们展示一个简单的二度查询。
示例:
给 rose 添加一个叫做 carl 的朋友
{
set{
<0x293310> <test_friend> _:carl .
_:carl <test_name> "carl" .
_:carl <test_age> "41" .
}
}
执行后界面如下

我们在通过查询语句查看,结果�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E6%89%BE%E6%88%BF%E5%9B%BE%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B3%BB%E5%88%97%E7%AE%80%E4%BB%8B%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com



{kind=link}