贝壳找房语言模型系列原理篇二从到
上一篇 贝壳找房【语言模型系列】原理篇一:从 one-hot 到 Word2vec 讲到了 word2vec 存在”一词多义“的问题,其主要原因在于 word2vec 生成的词向量是“静态”的,每一个词固定的对应着一个词向量表示,也就是说在 word2vec 训练好之后,在使用单词的向量表示的时候,不论该词的上下文是什么,这个单词的向量表示不会随着上下文语境的变化而改变。历史的车轮滚滚向前,”一词多义“的问题也被各种思路清奇的算法所解决,这篇文章我们从解决”一词多义“问题的 ELMo 说起,逐一介绍现在大火的预训练模型。
一、ELMo
首先我们讲一个预训练模型 ELMo,这个算法出自《Deep contextualized word representation》,ELMo 的全称是“Embeddings from Language Models”,其核心的点在于可以根据上下文动态调整当前词的词向量表示,比如有下面两个句子:
I like to eat apple.(我喜欢吃苹果)
I like apple products.(我喜欢苹果的产品)
在 ELMo 这个模型中,会根据”苹果“这个词的上下文去推断其向量表示,最终第一个”苹果“的向量表示代表水果,第二个”苹果“的向量表示代表苹果公司,其词向量表示是完全不同的。
那么 ELMo 是怎么做到的呢?下面一起来看一看~
1.1 ELMo 的核心原理
ELMo 之所以能够动态的生成词向量,主要原因是由于该模型有两个阶段。第一个阶段是在具体任务训练之前,利用大量语料预训练一个语言模型,这个语言模型相当于一个 动态词向量生成器,用于给具体任务生成词向量;第二个阶段是做下游任务,也就是利用第一阶段的动态词向量生成器产生的词向量,将其作为新特征加入到下游任务中,进行具体任务的训练。所以,这个算法比较重要的是第一个阶段,也就是预训练阶段,这个阶段存在的目的就是为了解决“一词多义”的问题。
首先来看第一阶段,ELMo 第一阶段的目的就是得到一个动态词向量生成器,该生成器的输入是一个 query,输出是该 query 的向量表示(词向量 or 句向量)。所以输入的 query 不同,其输出的向量表示肯定也不同,这就是动态词向量的核心点啦。
也就是说,我先预训练好一个语言模型,这个语言模型能够对当前的输入进行向量表示,同时,这个向量表示是根据整个 query 的不同而改变的。比如 bank 在 query1 中表示的是银行,在 query2 中表示的是岸边,那么 query1 和 query2 输入到这个语言模型中时,该模型根据 query 中的内容,也就是 bank 的上下文,来决定当前的 bank 的向量表示。下面是这个语言模型的结构,我们来看一下这个语言模型是怎么训练得到的。
ELMo 模型:
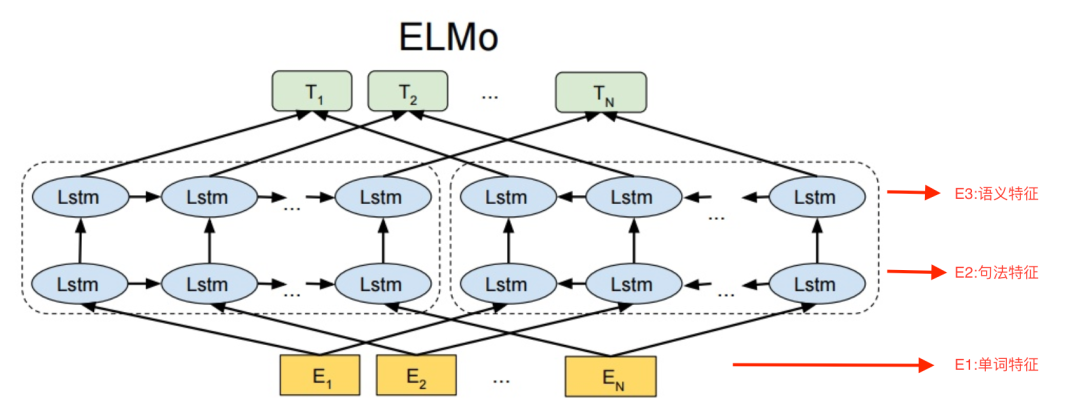
这个语言模型的输入是最下面一层的(E_1,E_2,…,E_N),代表一句话中 N 个词的初始词向量,这个初始词向量是利用字符卷积(char-cnn)得到的,这一点在图中没有体现。
和大多数的语言模型一样,该语言模型训练过程中的输出是最上面一层的(T_1,T_2,…,T_N),其中,T_i是一个 m 维向量,m 为词表大小,所以T_i代表每个词的出现概率。
这个网络结构最重要的部分就是采用双向 LSTM,所谓双向 LSTM 就是前向 LSTM 和后向 LSTM 的结合。
给定 N 个 tokens (E_1,E_2,…,E_N),前向 LSTM 通过给定前面的k-1个位置的 token 序列计算第 k 个 token 出现的概率:
p(E_1,E_2,…,E_N)=\prod_{k=1}^Np(E_k|E_1,E_2,…,E_{k-1})
后向 LSTM 通过反向的 k-1 个位置的 token 序列计算该 token 出现的概率:
p(E_1,E_2,…,E_N)=\prod_{k=1}^Np(E_k|E_{k+1},E_{k+2},…,E_{N})
所以双向 lstm 在训练过程中的目标函数就是:
L=\sum_{k=1}^N(logp(t_k|t_1,t_2,…,t_{k-1};\Theta _x,\Theta^{\rightarrow}_{lstm},\Theta_s) +logp(t_k|t_{k+1},t_{k+2},…,t_{N});\Theta _x,\Theta^{\leftarrow}_{lstm},\Theta_s)
对于每一个输入的 token t_k,ELMo 利用 L 层的双向 LSTM 将其表示成 2L+1 个向量。比如上图是一个两层的双向 LSTM,即 L=2,每一层都会有一个前向 LSTM 向量输出,一个后向 LSTM 向量输出,所以加上第一层的单词特征,那就会有 5 个表示向量。当然,在使用时会将双向 LSTM 层的前向输出和后向输出进行 拼接,作为这一层的输出向量。所以,最终输出了三个向量,E1,E2,E3。
那 ELMo 有了这么多向量之后如何 使用 呢?也就是 ELMo 的第二阶段如何进行?
论文中的实验表明,ELMo 中的每一层输出向量都有其不同的含义,比如图中的 E1 是单词特征,E2 是句法特征,E3 是语义特征,那么下游任务在使用动态词向量生成器产生的词向量时,将每一层双向 LSTM 产生的向量乘以权重参数,作为下游任务的一种特征输入,将该特征与下游任务的词向量进行拼接,构成最终的词向量进行任务的训练。
用公式总结一下就是:
ELMo_k^{task}=\gamma^{task}\sum_{j=0}^Ls_j^{task}h_{k,j}^{LM}
INPUT_{k}^{task}=[E_k;ELMO_k^{task}]
其中ELMo^{task}_k是 ELMo 第 k 个位置输出的词向量,h^{LM}_{k,j}是每一层前向后向拼接后的输出,s^{task}_j是每一层输出向量的权重,这个参数可进行训练得到,\gamma^{task}是对 ELMO 输出向量的一个缩放参数,可手动设置,INPUT^{task}_k是具体任务使用的词向量,即原始词向量和 ELMo 输出向量的拼接。
另外,这里的向量构建方法也不一定固定不变,可以尝试多种方法,比如把每一层的输出直接进行拼接,前向后向进行加权拼接等等,可以尝试在不同任务中的效果。
1.2 现在谈 ELMo
ELMo 采用动态词向量的方法解决了一词多义的问题,现在来看,该模型也有其不足之处。最明显的一点就是没有使用抽取特征能力更强的 transformer。
二、Transformer
所以,插播一下 Transformer 这个神奇的”特征抽取器“。Transformer 是了解常用预训练模型之前,绝对绕不过去的一个算法模型。Transformer 出自论文名字就霸气侧漏的《Attention is all you need》,这篇文章掀起了对以往常用的 CNN、RNN 类特征抽取器的革命和挑战,而且以压倒式的优势获得了胜利。
2.1 Transformer 的核心原理
Transformer 模型:
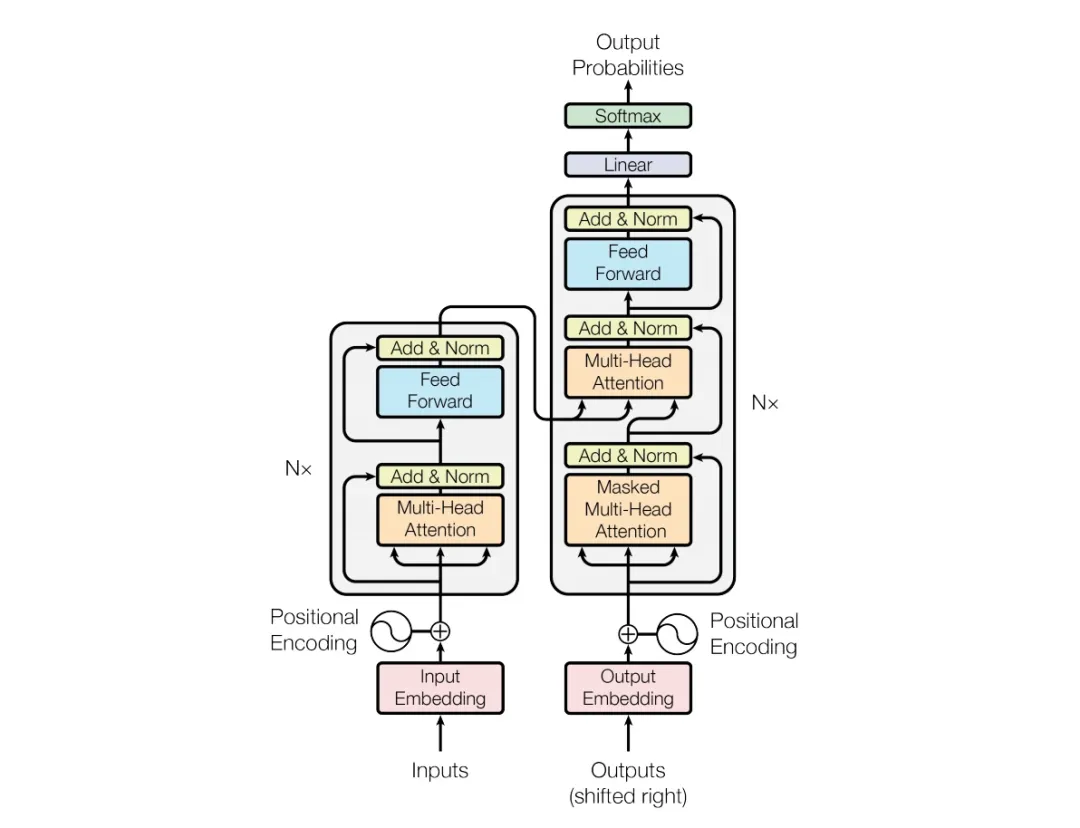
2.1.1 整体框架
Transformer 和常见的 seq2seq 的模型类似,主要由 encoder 和 decoder 组成。上图的左半边用 Nx 框起来的,代表一层 encoder,右半边用 Nx 框起来的代表一层 decoder,论文中取 Nx=6,也就是 encoder 和 decoder 都是由 6 个 layer 组成的。
encoder 的输入部分是输入序列 Inputs 经过 embedding 后,得到 Input Embedding,再和 Positional Encoding 相加,输入到 encoder 中。这里的 Positional Encoding 采用的是绝对位置编码,至于为什么需要 Positional Encoding,以及 Positional Encoding 是怎么得到的,我们待会儿再讲。
decoder 的输入部分是输出序列 Output 经过 Embedding 后,得到 Output Embedding,再和 Positional Encoding 相加,输入到 decoder 中,同时中间还将 encoder 的输出作为 decoder 的输入。
整个模型的输出就是 decoder 的输出经过一个线性层,再经过一个 softmax,和大多数语言模型一样,当前时刻的输出是一个 m 维向量,m 是词库大小,该向量表示当前时刻输出每个词的概率。
下面打开黑盒子,看看里面的具体实现~
2.1.2 encoder
首先来看 encoder 部分,encoder 的 layer 是由两个 sub_layer 组成的,也就是图中的 Multi-Head Attention 和 Feed Forward,同时每个 sub_layer 还添加了残差网络和归一化,也就是图中的 Add&Norm。Feed Forward 是为了将得到的特征向量投影到更大空间,方便提取信息,这一块先不管它,主要关注 Multi-Head Attention 和 Add&Norm。
2.1.2.1 Multi-Head Attention
Multi-Head Attention 是由 attention 到 self-attention,再到 Multi-Head Attention 一步步发展来的,所以先来回顾一下啥是 attention。
了解 attention 机制的同学应该明白,所谓的 attention 就是为了得到一个权重信息,用来给当前 query 的每个词分配不同的权重。举个栗子,比如我们要做一个机器翻译的任务,输入”你好老师“,分词后为两个 token”你好“,”老师“,对应译文是”hello teacher“,attention 机制就是在预测”hello“的时候,利用E^K_{hello} \cdot E^Q_{你好}和E^K_{hello} \cdot E^Q_{老师}得到两个权重e_1和 e_2,然后用e_1 * E^V_{你好} + e_2 * E^V_{老师}作为当前时刻的特征向量z_1,利用该特征向量去预测”hello“。同理可得z_2,利用z_2去预测”teacher“,这里的E^K, E^Q, E^V分别代表乘以权重矩阵W^K, W^Q, W^V得到的向量。由于”hello“和”老师“在语义上是对应的,所以e_1应该大于e_2,这样在预测”hello“的时候,注意力就更多的集中在”你好“这个 token 上,同时还考虑了上下文。当然,这里得到权重e_1和 e_2的方式有很多种,这里只提到常用的点乘。矩阵形式的操作如下图所示,其中 X 代表输入序列的 embedding,这里简化为 4 维,实际维度是 512,W^Q的维度简化为 3,实际维度是 64,最终的输出 Z 由z_1, z_2组成。
attention 过程演示:
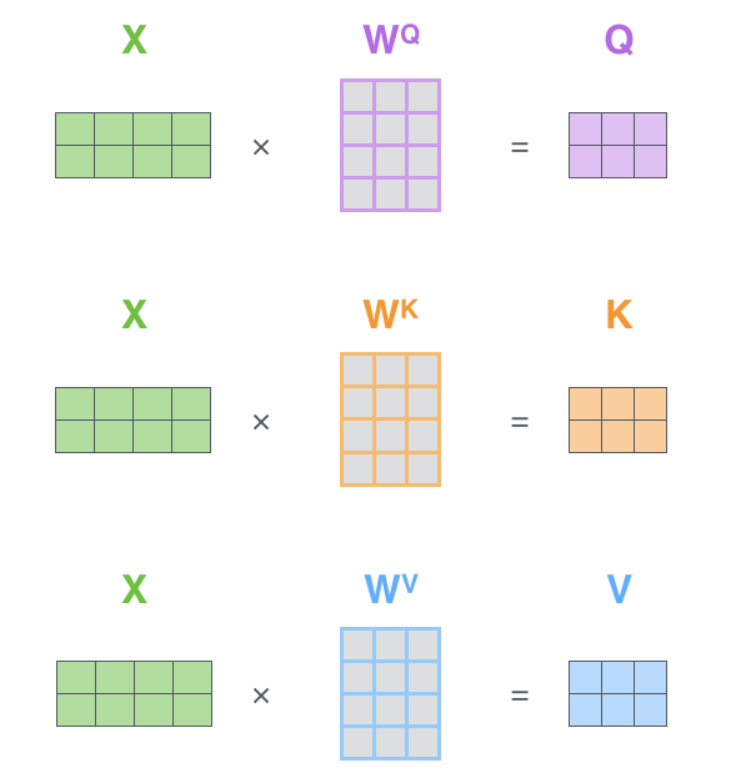
那么什么是 self-attention?看名字就知道,就是自己和自己进行点乘,以获得当前位置的权重。也就是说上图中的W^Q=W^K,这就是 self-attention。为啥要有 self-attention 呢?因为 encoder 只有这一个输入啊,只能自己和自己玩喽~
那么什么又是 Multi-Head Attention 呢?看名字也知道,其实就是多个 attention 结果的拼接。还是上面那个例子,相当于有了多个权重矩阵,即存在W^K_1, W^Q_1, W^V_1, W^K_2, W^Q_2,W^V_2 ….,论文中存在 8 个 head,这样就得到 8 个输出z_1, z_2,….,z_8,维度都是 2*3,然后按行拼接z_i,维度变成 2 * 24,再乘以一个额外的权重矩阵W^Q,维度为 24 * 4,得到Z,维度为 2 * 4。所以 Multi-Head Attention 的输入 X 和最终的输出 Z 的维度大小是一致的。
这里为什么选择进行 Multi-Head Attention 呢?直接用一个 head 不可以吗?我个人理解这么做的目的其实是为了获取不同维度下的特征,或者说为了扩大模型的 capacity。那为什么不直接调大 Nx 呢?原因在于扩充 head,没有层与层之间的依赖,其操作可以进行并行化,可以提升效率。
2.1.2.2 Add&Norm
得到 Multi-Head Attention 的输出Z之后,再经过残差网络和归一化,用公式表示一下:
sub_layer_output=LayerNorm(X+Z)
其中 LayerNorm 代表归一化,X+Z代表加入的残差网络。
2.1.3 decoder
看完 encoder 部分,再来看 decoder 就比较容易理解了。前面说了,decoder 的输入有两个部分,一个是 Output Embedding+Positional Encoding,另一个来自 encoder 的输出。decoder 主要有三个 sub_layer:Masked Multi-Head Attention、MUlti-Head Attention 以及 Feed Forward。
2.1.3.1 Masked Multi-Head Attention
这个 sub_layer 引入了 MASK 机制,其作用是为了消除未知信息对当前时刻预测的影响。比如当预测”teacher“这个位置时,需要把”teacher“这个信息给 MASK 掉,不让模型看见。其具体做法就是在得到权重系数之后,将该时刻以后的权重系数加上负无穷,然后再经过 softmax,这样该时刻之后的值基本就是 0 了。
2.1.3.2 Multi-Head Attention
这个 sub_layer 的原理和 encoder 一样,其主要区别在于这里的 attention 不是 self-attention,这个 Multi-Head Attention 输入的 K 和 V 来自 encoder,Q 来自 Masked Multi-Head Attention 的输出。
2.1.4 Feed Forward
这个 sub_layer 就是简单全连接层,而且是对每一个位置都各自进行相同的操作,其输入是 Multi-Head Attention 层每个位置上的输出。用公式表达就是
FFN(x)=max(0,xW_1 + b_1)W_2 + b_2
由以上的介绍可以知道,Multi-Head Attention 每个位置上的输出x \in \mathbb{R}^{1*512},同时这里W_1 \in \mathbb{R}^{512*2048},W_2 \in \mathbb{R}^{2048*512},所以这个 sub_layer 单个位置的输出维度仍然是 1 * 512。
另外可以看出来,这个操作就相当于先升维,再降维,其目的在于扩大容器的 capacity。
2.1.5 Positional Encoding
模型的输入为什么要加入一个 Positional Encoding?原因是单纯的 attention 机制没有考虑位置信息,也就是说”北京到上海的机票“和”上海到北京的机票“这两个 query 对于 attention 机制来说是相同的,这显然不合理,所以需要加入位置信息加以区分。
Transformer 中的 Positional Encoding 采用正弦位置编码,论文中的公式为:
PE(pos,2i)=sin(pos/10000^{\frac{2i}{d_{model}}})
PE(pos,2i+1)=cos(pos/10000^{\frac{2i}{d_{model}}})
比如一句话中第三个 token 的 Positional Encoding 是
(sin(3/10000^{\frac{0}{512}}),cos(3/10000^{\frac{1}{512}}),
sin(3/10000^{\frac{2}{512}}),….,cos(3/10000^{\frac{511}{512}}))
三、GPT
在了解完 Transformer 之后,我们可以继续进行探寻预训练模型啦~首先讲一个和 ELMo 极其相似的模型–GPT。
GPT 是《Improving Language Understanding by Generative Pre-Training》这篇文章提出的一种预训练算法,和 ELMo 很像,GPT 也分为两个阶段,第一阶段是利用语言模型进行预训练,不同的是,GPT 的第二阶段不再是重新搞一个具体任务的模型,而是直接在预训练模型的基础上进行微调(fine-tuning),完成具体任务的训练。
3.1 GPT 的核心原理
GPT 和 ELMo 的不同之处主要在于:
- 特征抽取器由双向 LSTM 替换成 transformer
- 特征抽取时只使用单向信息,即该语言模型只使用上文预测当前词,而不使用下文
- 将预训练和 fine-tuning 的结构进行了统一,进行下游任务时,直接在预训练模型上进行改造,而不是将得到的词向量输入到具体任务的模型
GPT 模型:
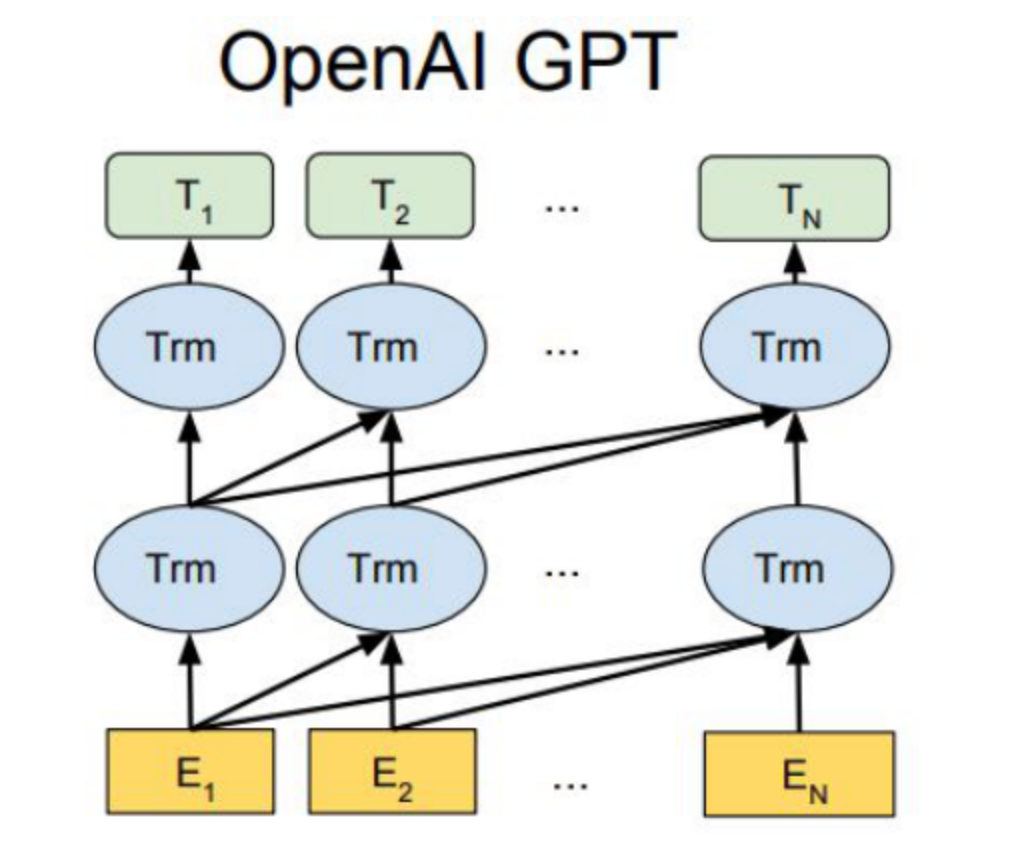
对于第一阶段,首先,输入向量是词向量和位置向量的组合,然后特征提取层使用 Transformer 的 decoder 变体进行特征提取,然后根据输出的特征向量进行语言模型的训练。搬出论文中的公式:
h_0=UW_e+W_p
h_l=transformer(h_{l-1})
P(u)=softmax(h_nW_e^T)
L_1(U)=-\sum_ilogP(u_i|u_{i-k},…,u_{i-1};\Theta)
其中,U=u_1,u_2,…,u_n代表输入的单词 token,U \in \mathbb{R}^{n*m},W_e \in \mathbb{R}^{m*d}代表词向量矩阵,m是词表大小,d是隐层维度大小,W_p \in \mathbb{R}^{n*d}代表位置向量矩阵,h_0就代表此时输入的序列特征,即图中的[E_1,E_2,…,E_N],n 代表 transformer 的层数,$P(u) \in \mathbb{R}^{n*m}代表每个位置出现某个单词的概率。
对于第二阶段,在预训练模型准备好后,就可以通过构造不同的输入,利用 transformer 最后一层的输出进行不同任务的 fine-tuning。
拿简单分类任务举例,假设我们有带标签的数据集C,对于输入序列[x_1,x_2,…x_m]以及标签 y,首先将输入序列喂到预训练模型中,得到 transformer 最后一层的输出h^m_n,然后再经过全连接层与 softmax,得到预测的概率。注意这里是拿了最后一层的最后一个 token 作为输出,源码里就是这么写的。简单分类任务的目标函数是
L_2(C)=\sum_{x,y}logP(y|x_1,x_2,…,x_m)
p(y|x_1,x_2,…,x_m)=softmax(h_l^mW_y)
论文在具体微调时结合了语言模型的部分,即:
L(C)=L_2(C)+\lambda L_1(C)
不同的任务有着不用的输入构造方式,但大同小异,如下图所示。
GPT 的下游任务改造:
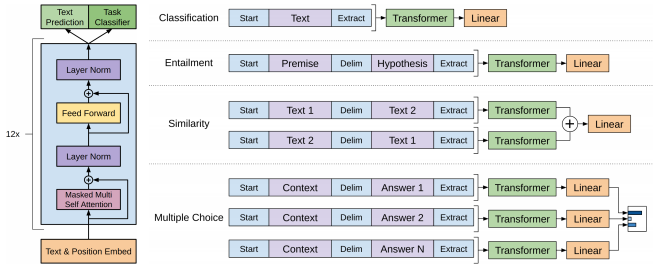
3.2 GPT 中的 Transformer
前面说到,GPT 中的 Transformer 是正规 Transformer 模型的 decoder 部分的变体,也就是说 GPT 的 Transformer 部分是由 Masked Multi-Head Attention+Add&Norm+Feed Forward+Add&Norm 构成的。同时,论文中采用 Nx=12 层的 Transformer 结构。
GPT 的 Transformer 变体:
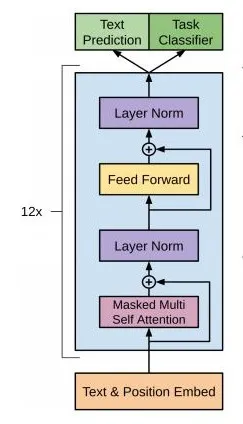
有前面的介绍可以知道,Masked Multi-Head Attention 是只利用上文进行当前位置的预测,所以 GPT 被认为是单向语言模型。
另外,在 Transformer 输入的构造中,GPT 的 Position Encoding 不再使用正弦位置编码,而是有一个类似于词向量表的位置向量表,该表可在训练过程中进行更新。
四、BERT
GPT 在特征抽取上使用了 transformer,但是语言模型构建过程中只利用了上文信息,没有利用下文信息,这样白白丢掉了很多信息,这使得 GPT 在一些类似于阅读理解任务中的应用场景受到限制。这也让 BERT 有了大火的机会,如果 GPT 使用了双向 transformer,估计现在 NLP 领域的里程碑事件就不是 BERT,而是 GPT 了。
4.1 BERT 核心原理
BERT 模型:
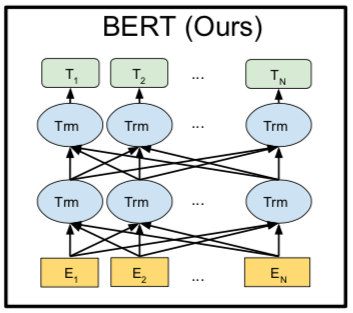
BERT 和 GPT 在结构上更是极为相似,其主要区别是:
- BERT 采用 transformer 的 encoder 变体作为特征抽取器,且考虑双向,在预测当前词时,既考虑上文,也考虑下文,语言模型的预训练过程中采用 MASK 方法
- 语言模型训练过程中添加了句子关系预测任务
4.1.1 BERT 的输入构造
由于 BERT 添加了句子关系预测任务,所以 BERT 的模型输入构建上有一点改变,添加了一个 segement embedding,用来表示当前 token 属于哪一个句子,如下图所示:
BERT 输入构造:
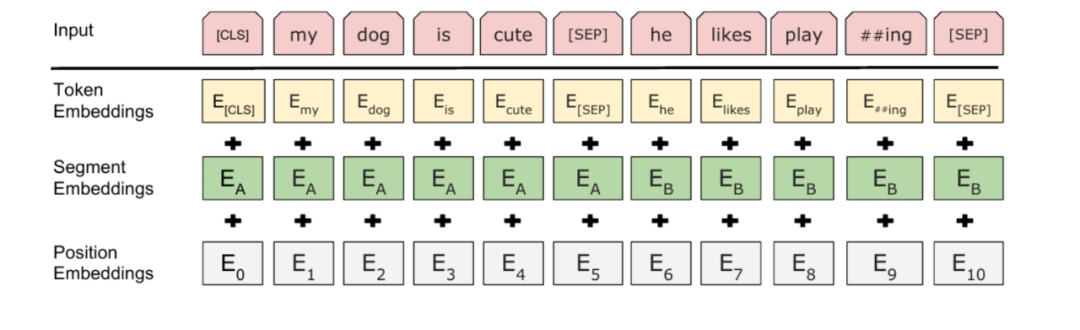
Token Embeddings 是词向量,第一个单词是 CLS 标志,一般都会拿该位置的输出进行分类任务的微调。
Segment Embeddings 用来区别两种句子,因为预训练不光做语言模型的训练,还要做以两个句子为输入的分类任务。
Position Embeddings 和 GPT 一样,通过对位置向量表进行 look-up 获得位置向量。
4.1.2 BERT 的 MASK 机制
前面我们提到了 BERT 是一个采用双向 Transformer 的模型,我们知道 transformer 内 encoder 部分的主要结构是 self_attention,并不是类似于 LSTM 那种串行结构,而是一个并行结构。对于串行结构,我们可以正向输入,依次预测每个词,构成前向 LSTM,也可以反向输入,依次预测每个词,构成后向 LSTM,这样就构成了一个双向 LSTM,那么对于并行结构该如何实现”双向“这个概念呢?这个方法就是 BERT 用到的 MASK 机制,其原理和上一篇讲的 word2vec 的训练原理有些类似。
这个 MASK 方法的核心思想就是,我随机将一些词替换成[MASK],然后训练过程中让模型利用上下文信息去预测被 MASK 掉的词,这样就达到了利用上下文预测当前词的目的,和我们了解的 CBOW 的核心原理的区别就是,这里只预测 MASK 位置,而不是每个位置都预测。但是,直接这么做的话会有一些问题,训练预料中出现了大量的[MASK]标记,会让模型忽视上下文的影响,只关注当前的[MASK]。
举个栗子,当输入一
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E6%89%BE%E6%88%BF%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E7%B3%BB%E5%88%97%E5%8E%9F%E7%90%86%E7%AF%87%E4%BA%8C%E4%BB%8E%E5%88%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


