贝壳技术响应式编程和协程在语言的应用
作者简介
董骐瑞,2018年加入贝壳找房人工智能技术中心,先后负责推荐系统、搜索推荐,目前是智能匹配组、广告投放工程负责人。
引言
现代编程中,对于高并发场景不可避免地会使用多线程和异步处理,但是多线程的大规模使用并不会无成本地提升运行效率,随着线程数的增加,内存的占用量和上下文切换的开销都不能忽视。
本文针对Java语言的高并发场景,提出了进一步优化性能的技术原理和实现思路,通过WebFlux和Quasar的合理应用,减少硬件资源占用,提高资源利用效率,对于提升服务性能收益显著。
文章也展开介绍了响应式编程和协程技术在Java语言的技术现状、实现方式以及性能表现。
文章最后总结了当前技术背景下,应用该技术的挑战和难度。
概述
WebFlux
为什么使用响应式编程?
首先从CPU说起,CPU的职责是为了解决计算问题,由于CPU的运算速度要比内存读写速度快很多,为了解决这种速度不匹配的矛盾,引入了CPU多级缓存。简单地说,计算机工作时有多个任务,例如A、B、C三个程序,对于计算机来说,可能是三个进程,CPU会把自己的工作划分切片,每个切片处理一段任务,处理完毕时切换到下一个任务,最大化自己的利用效率。对于进程也是如此,为了能同时处理更多任务,充分利用多核CPU的计算能力,会新建很多线程,期望并发编程最大化利用程序可以使用的计算资源。
然而并发不能完全解决问题,Web应用往往伴随着I/O,例如数据库请求或网络调用,这时如果I/O阻塞了当前线程,使其处于等待数据的状态,就很难提高资源的利用效率。当然,可以使用异步回调绕过问题,但不是所有的异步都是非阻塞的,同时,大量的回调不易编写,容易导致代码难以维护和阅读。
此外,并发还涉及到CPU上下文切换的成本。实际上,上下文切换的成本并不低。一般情况下,CPU指令运算只需要0.38ns,而一次上下文切换却需要1500ns。所谓的上下文切换并没有进行任何有效计算,只是切换了不同进程的寄存器和内存状态,此外还破坏了缓存,而这令后续的计算更加耗时。举个例子:把CPU计算想象成自己工作的状态,一天的工作时间不会只做一项事情,可能做A工作1小时,B工作2小时,C工作1小时……如果从事A工作1分钟,保存当前进度后从事B工作2分钟,再切换工作台从事C工作30秒,可能会让人崩溃。
上面提到的上下文切换只是部分成本,多线程本身还有内存成本,所以也是为什么线程数目配置不合理可能会导致OOM。
早期的Java框架将Web请求绑定到Servlet API中的线程使得Web应用可以并行处理请求。但是,这有一个缺点,Java的线程是以系统进程的形式实现的,这就意味着线程的切换会伴随着大量的上下文切换成本。这在早年的Web服务中并不是主要的矛盾,而在企业应用要求苛刻的今天就是一个需要解决的矛盾了。
通过增加线程数来支撑业务的同时,却带来了更多的线程资源占用和更多的上下文切换开销。在这样的背景下,如何增加Web应用的吞吐量?这个时候响应式编程就可以登场了。
什么是响应式编程?
In computing, reactive programming is a declarative programming paradigm concerned with data streams and the propagation of change.
from WIKIPEDIA
响应式编程(Reactive Programming)是一种基于数据流和变化传播的声明式编程范式。
几个关键词:数据流、变化传播、声明式。
先介绍声明式,一个比较形象的例子是Excel,Excel中可以定义单元格C1的公式来自A1+B1,这样A1=1、B1=2时,此时C1=3,但这里定义的并不是赋值C1=3、而是定义C1来自A1+B1的关系;此时修改A1=3时,由于定义的是关系,C1自动地从1+2=3变为3+2=5,这就是变化传播。即:不需要重新赋值一次C1=新的A1(3)+B1(2)=5,由A1从1变更为3触发了C1值的变化。A1、B1作为触发变动的源数据,称为数据流。
命令式编程(Imperative)和声明式编程(Declarative)的区别在于命令式编程主要是告诉机器怎么做拿到结果(命令机器处理一系列逻辑以获取结果);声明式编程是告诉机器要什么结果(让机器自己处理逻辑只关注结果)。后者听起来有点像OKR管理,事实上声明式语言包括:数据库查询语言(SQL)、正则表达式、逻辑编程、函数式编程和组态管理系统。
响应式编程(Reactive)是告诉机器数据和结果的关系,响应式编程强调变化的思想:数据流是不断变化的,但是关系是定义好的,它依赖于事件,通过事件驱动实现处理过程。
举个例子:
命令式编程类似于回到家,打开客厅的灯,换鞋,打开空调,去换衣间开灯,更换睡衣,关掉换衣间的灯,回客厅看电视;
响应式编程类似于回到家(客厅灯光触发开、空调触发开),换鞋,去换衣间更换睡衣(灯光触发开),回客厅看电视(换衣间灯灯光触发关)。
可以感受一下关注的主体。简单的说,通过事件驱动,编程者可以关注于业务的触发逻辑。
为什么响应式编程要强调变化传播?因为这样的计算方式能最大化异步的效果。试想,应用可以处理100个请求,但是由于有同步等待,就会导致很多请求占用的CPU资源被浪费了。如果整个流程不存在同步等待的操作,通过事件驱动,那么CPU的利用效率会更高。
响应式编程通过将CPU核数和处理线程绑定来实现,处理请求的线程并不需要和实际的请求数一一对应,也就是说此前的处理线程数的网络请求数是1:1的关系,基于响应式编程的处理线程数和网络请求数是1:N的关系。实际的业务处理是通过异步实现的。毕竟硬件层面CPU核数不可能和处理线程数达到1:1的关系,此前的业务的处理必然涉及到频繁的上下文切换。如果CPU核数、处理线程数和网络请求数以1:1:N的模型进行,处理多个请求的同时就避免了频繁的上下文切换,此外,使用固定的线程数(一般和CPU核数匹配)替代高并发的线程配置,也减少了内存占用。例如:此前线程数200可以使用8核代替直接减少了192M内存占用(假设未调整-Xss参数,每个线程占用1MB空间)。
响应式编程的设计有些类似多路复用或是观察者模式,是基于回调触发的。但是不同于大量的Callable的应用,因为后者容易产生回调地狱(Callable Heal,所谓回调地狱是指大量的回调函数声明后已经严重影响编码的效率和可维护性)。而通过响应式编程这种基于事件驱动的声明式编程和数据流的订阅发布可以优雅地化解这个问题。
这里有一段来自Reactor 3 Reference Guide的代码示意,主要功能是:在用户界面显示用户的前五个收藏夹、如果没有给出建议结果。如下所示:
userService.getFavorites(userId, new Callback<List<String>>() {
public void onSuccess(List<String> list) {
if (list.isEmpty()) {
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) {
UiUtils.submitOnUiThread(() -> {
list.stream()
.limit(5)
.forEach(uiList::shoW) ;
});
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
} else {
list.stream()
.limit(5)
.forEach(favId -> favoriteService.getDetails(favId,
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
不难看出上述代码想表达的就是回调地狱的编码风格,而使用响应式编程替换上述代码,如下所示:
userService.getFavorites(userId)
.flatMap(favoriteService::getDetails)
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);
很简洁是不是?实际上,还可以给出限定超时时间(题外话:最开始吸引作者研究该技术的正是这个关键词)。
userService.getFavorites(userId)
.timeout(Duration.ofMillis(800))
.onErrorResume(cacheService.cachedFavoritesFor(userId))
.flatMap(favoriteService::getDetails)
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);
再举一个例子,也可以使用CompletableFuture做示例:
CompletableFuture<List<String>> ids = ifhIds();
CompletableFuture<List<String>> result = ids.thenComposeAsync(l -> {
Stream<CompletableFuture<String>> zip =
l.stream().map(i -> {
CompletableFuture<String> nameTask = ifhName(i);
CompletableFuture<Integer> statTask = ifhStat(i);
return nameTask.thenCombineAsync(statTask, (name, stat) -> "Name " + name + " has stats " + stat);
});
List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList());
CompletableFuture<String>[] combinationArray = combinationList.toArray(new CompletableFuture[combinationList.size()]);
CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray);
return allDone.thenApply(v -> combinationList.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList()));
});
List<String> results = result.join();
assertThat(results).contains(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121");
同样用响应式编程的运算符简化代码:
Flux<String> ids = ifhrIds();
Flux<String> combinations =
ids.flatMap(id -> {
Mono<String> nameTask = ifhrName(id);
Mono<Integer> statTask = ifhrStat(id);
return nameTask.zipWith(statTask,
(name, stat) -> "Name " + name + " has stats " + stat);
});
Mono<List<String>> result = combinations.collectList();
List<String> results = result.block();
assertThat(results).containsExactly(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121"
);
仅从代码编写方面看:尽管编码风格改变巨大,但是可读性和编码灵活性大大提升。
什么是WebFlux?
下面循序渐进地介绍一些相关概念。
Reactive Streams:
Reactive Streams is an initiative to provide a standard for asynchronous stream processing with non-blocking back pressure. This encompasses efforts aimed at runtime environments (JVM and JavaScript) as well as network protocols.
Reactive Streams是一项倡议非阻塞、具有背压的异步流处理标准。
它是一套用于构建高吞吐量、低延迟应用的规范。响应式流规范是RxJava等大牛制定的,同时基于该规范对RxJava重构形成了RxJava 2更奠定了它的权威性。然而,RxJava倾向于Android端的响应式开发,基于JVM的响应式开发则依赖于Reactor。
Reactor:
Reactor is a fourth-generation reactive library, based on the Reactive Streams specification, for building non-blocking applications on the JVM.
Reactor是第四代响应式库,基于Reactive Streams规范的实现,旨在构建JVM环境的非阻塞应用。
Reactor属于Pivotal旗下。对于Pivotal可能很多人比较陌生,顺便提一下Pivotal旗下赫赫有名的Spring项目。Reactor是Pivotal推出的支持响应式流规范的Web实现,同样具有非阻塞的基础和背压的支持。
响应式编程中的模型类似发布/订阅模式,但是该模式有个弊端,即当订阅者消费速度较发布者生产速度慢的情况下,容易产生消息堆积,而响应式编程的背压概念就是针对该问题提出的。简单地说,背压(BackPressure)指的是一种反向反馈的方式,订阅者声明其能够处理的消费数量,发布者根据该数量生产消息直至下一次反馈。

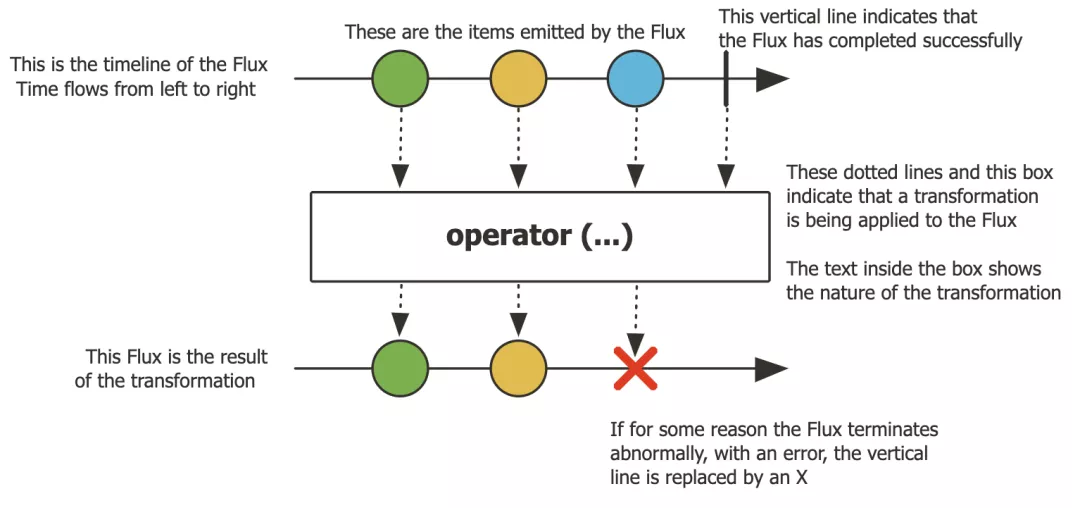
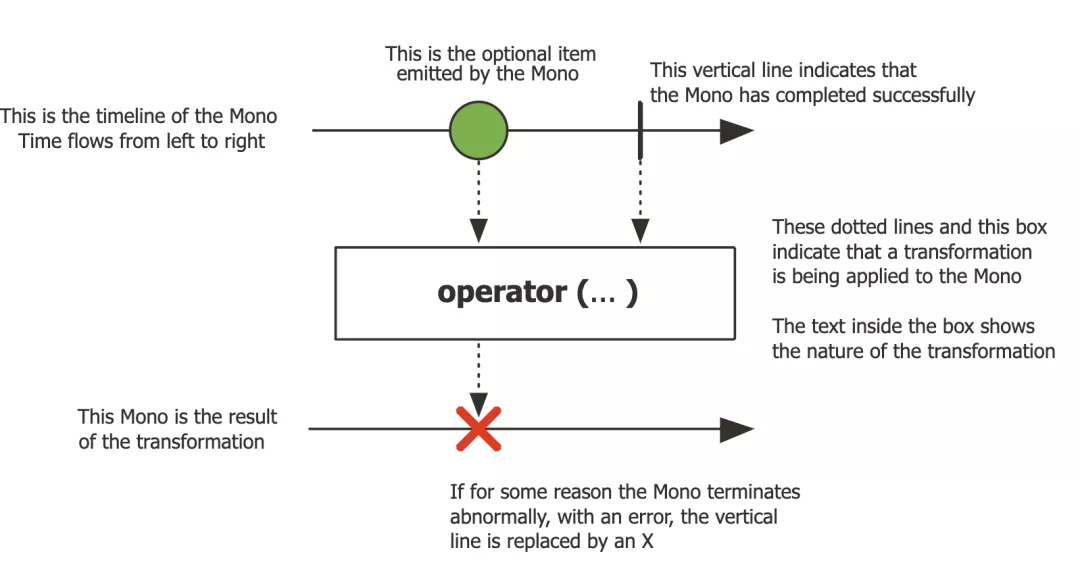
同时,需要掌握两个数据流Publisher:Mono、Flux。其中,Mono指的是0个或1个元素的异步序列,Flux则表示0个到N个元素的异步序列。它们都提供了丰富的操作符,可以像Stream API一样使用map、flatmap、filter、zip等Operator,当然也有onErrorReturn、onErrorResume、onErrorMap等错误处理方式。
下图是Flux处理数据的示意图:
下图是Mono处理数据的示意图:
那么,如何创建一个Flux或Mono并消费呢?可以参考下面的例子:
Flux<String> seq1 = Flux.just("foo", "bar", "foobar");
Flux<String> seq2 = Flux.fromIterable(Arrays.asList("foo", "bar", "foobar"));
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3);
Mono<String> noData = Mono.empty();
Mono<String> data = Mono.just("foo");
WebFlux:
The reactive-stack web framework, Spring WebFlux, was added later in version 5.0. It is fully non-blocking, supports Reactive Streams back pressure, and runs on such servers as Netty, Undertow, and Servlet 3.1+ containers.
WebFlux是Spring Framework 5.0中引入的新的响应式Web框架,与Spring MVC不同,它是一套完全异步非阻塞的Web框架,并且通过Reactor项目实现了Reactive Streams规范。适合使用事件驱动的风格构造Web应用。运行于Netty、Undertow、及Servlet 3.1 以上版本容器中。

并发模型
提到WebFlux,首先对它的并发模型做下简单介绍。
请求线程模型:
这种模型下,用户对于Web服务器的请求由不同线程处理,而在很多数据库请求和网络I/O中是阻塞的。
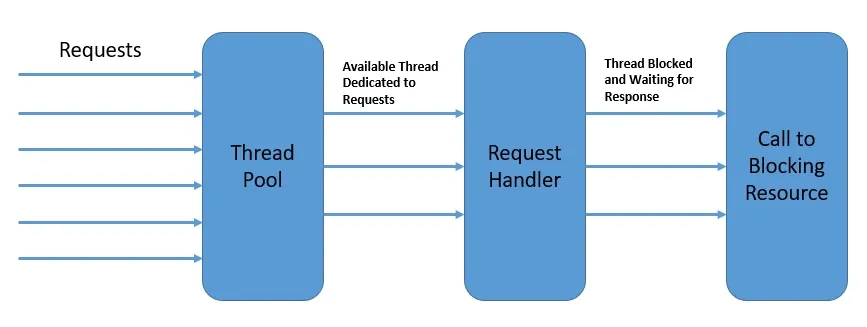
事实上,这种并发模型是主流的实现方式,当然,它有一个弊端:随着请求越来越多,一些阻塞的操作令整体模型表现低于预期。
事件循环模型:
我们反复强调,异步是响应式编程的基础。因此,在这种模型下,编程风格大幅转变,程序结构基于异步事件流进行。
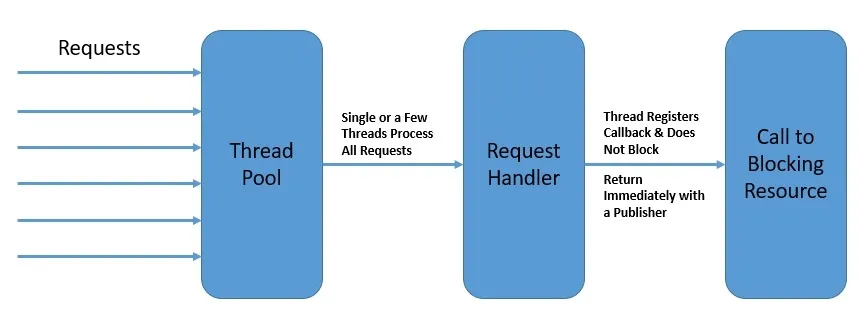
这种并发模型使用了较少的线程处理较多的请求,在每个处理线程中并不会阻塞,而是立即注册回调事件并让出资源。这便是前文提到的事件驱动(Event Driven)
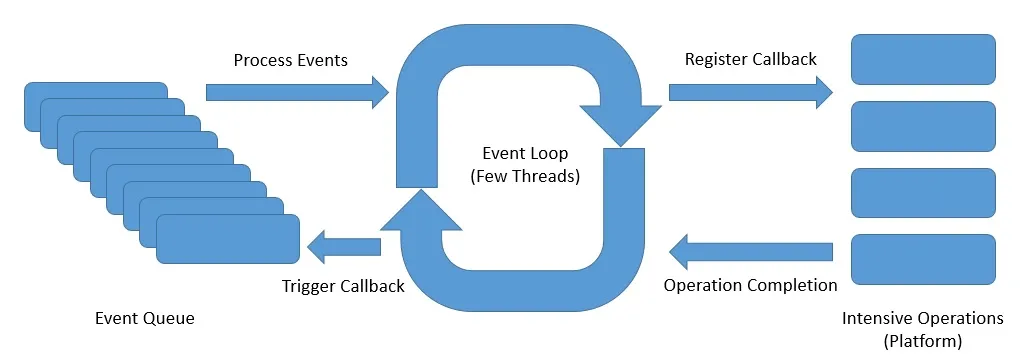
图片给出了事件循环的设计图,可以看出:事件循环依赖少量的线程(通常和实际内核相关,甚至是单线程)进行处理,通过不断的像平台注册事件并立即返回充分利用资源,当触发完成的回调事件后,通知原调用方。
通过这种模型,可以大幅节省处理线程。
如何实现WebFlux?
替换spring-boot-starter为spring-boot-starter-webflux依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
Spring WebFlux关于Controller声明有两种方式:功能性和注释型,基于注释的在Spring MVC中较为常见:
@RestController
@RequestMapping(value = "/dsp")
public class Controller {
@Autowired
private StrategyService strategyService;
@RequestMapping(value = "/routeA", method = RequestMethod.POST)
public ExampleResponse routeA(@RequestBody Map<String, String> requestBody) {
return strategyService.methodA();
}
@RequestMapping(value = "/routeB", method = RequestMethod.POST)
public ExampleResponse routeB(@RequestBody Map<String, String> requestBody) {
return strategyService.methodB();
}
@RequestMapping(value = "/routeC", method = RequestMethod.POST)
public ExampleResponse routeC(@RequestBody Map<String, String> requestBody) {
return strategyService.methodC();
}
}
基于功能性的方式则需要适应。本文作者更推荐尝试该方式,使用这种方式会更清晰:
@Configuration
public class Router {
@Bean
public RouterFunction<ServerResponse> route(StrategyHandler strategyHandler) {
return RouterFunctions
.route(RequestPredicates.POST("/dsp/routeA")
.and(RequestPredicates.accept(MediaType.APPLICATION_STREAM_JSON)), strategyHandler::methodA)
.andRoute(RequestPredicates.POST("/dsp/routeB")
.and(RequestPredicates.accept(MediaType.APPLICATION_STREAM_JSON)), strategyHandler::methodB)
.andRoute(RequestPredicates.POST("/dsp/routeC")
.and(RequestPredicates.accept(MediaType.APPLICATION_STREAM_JSON)), strategyHandler::methodC);
}
}
接着,定义一个示例方法:
public Mono<ServerResponse> methodA(ServerRequest serverRequest) {
return ServerResponse.ok()
.contentType(MediaType.APPLICATION_STREAM_JSON)
.body(exampleService.dealWithRequest(
serverRequest.bodyToMono(String.class), serverRequest),
String.class);
}
由于响应式编程主要是基于异步非阻塞的,这对系统提出了一个较为重要的隐式要求,即:全程不要有阻塞操作,可以使用WebClient、Lettuce、RJDBC等技术,这里以WebClient为例改造项目。
WebClient是随着Spring Framework 5.0推出的支持响应式编程的非阻塞HTTP请求客户端工具,随WebFlux提供,也就是说,不需要引入额外的依赖。
Mono<String> response = null;
switch (method) {
case GET:
response = WebClient.create()
.method(HttpMethod.GET)
.uri(requestUrl)
.header(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.retrieve()
.bodyToMono(String.class);
break;
case POST:
response = WebClient.create()
.method(HttpMethod.POST)
.uri(requestUrl)
.body(Mono.just(requestBody), String.class)
.header(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.headers(headers -> headers.addAll(httpHeaders))
.retrieve()
.bodyToMono(String.class);
break;
default:
break;
}
可以看出使用并不复杂,值得一提的是关于WebClient有几个方法:retrieve()、exchange()、subscribe()、block()。
其中,retrieve和exchange都是处理HTTP请求并返回响应,区别在于retrieve只能拿到body信息;exchange可以获取更多信息、包括状态码、请求头等信息,然而exchange()在5.3版本后由于内存连接泄露被废弃、改为exchangeToMono()、exchangeToFlux()。
subscribe是非阻塞方法,用于异步订阅响应结果,不会阻塞主线程执行;block是阻塞方法,可以获取返回结果,可以在测试中使用,特别注意的是:生产中不建议使用,因为有限的请求资源会被阻塞掉、极大地影响性能表现。
WebClient也可以使用builder模式,例如下面例子实现了读写超时时间的控制,自行尝试即可。
@Bean
public WebClient webClient()
{
HttpClient httpClient = HttpClient.create()
.tcpConfiguration(client ->
client.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 100)
.doOnConnected(conn -> conn
.addHandlerLast(new ReadTimeoutHandler(10))
.addHandlerLast(new WriteTimeoutHandler(10))
)
);
ClientHttpConnector connector = new ReactorClientHttpConnector(httpClient);
return WebClient.builder()
.baseUrl("http://localhost:8080/findAll")
.clientConnector(connector)
.defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.build();
}
使用中,如果出现DataBufferLimitException异常,是由于WebFlux限制了数据缓冲的默认内存限制为256KB,可以尝试调整参数解决:
spring.codec.max-in-memory-size=1MB
事实上,一个成熟的大型项目需要改造的内容远不止这些,由于篇幅有限,不做过多赘述。
Quasar
为什么需要使用协程?
前面提到了使用WebFlux改造项目,但遗憾的是,不是所有的方法都是非阻塞的,可以通过切换技术栈进行改造,但还是不可避免的会遇到无法替代的方案。改成响应式编程后,如果存在同步任务,性能不升反降,需要保证全流程几乎纯异步。
这时候直接有效的方式是使用异步方式处理,可能首先想到的是Future,但即使是Future模式,get的环节也是阻塞处理的,这点需要注意;而JDK1.8加入的CompletableFuture在使用特殊方法如whenComplete是非阻塞的。
如果考虑到编码的复杂度,一定要通过线程等待的话,或者说有些任务就是并发处理的,如何实现呢?我们知道,每个Java线程需要一个栈空间保存挂起状态,64位的环境中默认是1MB,也就是说线程的增加是伴随着内存使用增长的,线程数过多的后果就是OutOfMemoryError。是否可以压缩线程的空间呢,可以通过-Xss调节,但是不具备实际意义,因为递归调用的层次过多会导致StackOverflowError,为了等待这些阻塞的任务执行要浪费N*1MB。那么如何节约这部分资源呢?答案是用轻量的方式实现等待或并发任务,由于使用常规线程做异步等待比较浪费资源,可以考虑使用轻量级的协程做异步等待。即:使用协程。
什么是协程?
协程也可以称为纤程,英文Fiber或Coroutine,主要来自语法层面实现的区别,本文统一称为协程。如果说进程和线程的模型可以看做1:N的关系;线程和协程也可以看做1:N的关系,换言之就是更轻量的线程。
协程的概念并不新鲜,Go语言的协程已经很出名,实际上Java早年也是支持协程的,那时候叫做GreenThread,运行于用户空间,但其尽可以用1:1绑定,不能与系统内核实现M:N绑定,所以后续被线程绑定的模型代替。目前Java语言环境的解决方案有:Parallel Universe公司开发的Quasar,Oracle主导的Project Loom,以及Kotlin的语言支持。由于Loom目前还没有正式完成,Kotlin需要语言混用,本文使用Quasar实现。
协程的原理?
首先了解下栈的作用,栈主要用于保存函数调用之后的返回位置。协程的实现方式从栈的角度区分主要分为两种:Stackless和Stackful。以下是两大实现方式的主流代表:
Stackless:C#、Scala、Kotlin
Stackful:Go、Quasar、Javaflow
主要区别在于是否需要固定的栈内存,如名字含义Stackful是有栈内存的,继续执行任务时从栈的位置执行,而Stackless需要编译器支持、生成代码自定义继续执行的逻辑;至于性能方面Stackful稍微影响CPU的分支预测,继而影响性能,但几乎可以忽略,而Stackless没有影响;内存方面Stack需要固定分配占内存(如4KB),而Stackless几乎不占用内存;实现方面,Stackless的更为复杂,对编译器作者的挑战极高,而Stackful不会像Stackless那么高难度。
Stackful在调用时可以保存栈,暂停和恢复类似线程,主要区别在于调度;而Stackless则通过中断,简单的理解是个挂起点,类似回调实现。可以看出,大体的原理都是保存回调位置,挂起阻塞的任务,通过恢复来快速切换,充分利用计算资源。
那么,应该不难理解协程的轻量级含义了,它几乎没有自己的栈内存,而且不和实际的线程映射,也就不需要处理器的上下文切换。
总结下来,协程的几个好处是以下三点:避免了内核态和用户态切换的成本,在用户空间切换;用更少的栈空间创建类线程。
Quasar的原理?
Quasar的原理主要是通过SuspendExecution来实现的,为什么这么说?它会织入字节码,在方法调用的前后插入代码用于保存和恢复Fiber栈本地变量的状态,记录暂停点,随后park挂起Fiber、抛出SuspendExecution异常,当方法被阻塞的时候,该异常被捕获。当唤醒时,方法被调用,立即跳到那一行。原理不是很简单,但是性能损失仅约为3%~5%。
如何使用Quasar?
首先需要引入依赖,Quasar最新版本是0.8.0支持JDK11及以上,由于公司的JDK环境是1.8,所以使用0.7.*的Quasar版本。
<dependency>
<groupId>co.paralleluniverse</groupId>
<artifactId>quasar-core</artifactId>
<version>0.7.4</version>
<classifier>jdk8</classifier>
</dependency>
Quasar依赖Java的字节码织入,需要修改JavaAgent,增加启动命令:
-javaagent:path-to-quasar-jar.jar
修改JavaAgent也可以用另一种实现:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<!-- Turn off before production -->
<!-- argLine>-Dco.paralleluniverse.fibers.verifyInstrumentation=true</argLine -->
<!-- Enable if using compile-time (AoT) instrumentation -->
<!-- argLine>-Dco.paralleluniverse.fibers.disableAgentWarning</argLine -->
<!-- Quasar Agent for JDK 8 -->
<argLine>-javaagent:${co.paralleluniverse:quasar-core🏺jdk8}</argLine>
</configuration>
</plugin>
Quasar的Fiber使用风格和JDK内置的runnable差别不大,如下:
new Fiber<V>() {
@Override
protected V run() throws SuspendExecution, InterruptedException {
// your code
}
}.start();
如果不需要返回值,则设置泛型V为Void,返回null即可。
new Fiber<Void>(new SuspendableRunnable() {
@Override
public void run() throws SuspendExecution, InterruptedException {
// your code
}
}).start();
当然,可以使用Lambda表达式简化为:
new Fiber<Void>((SuspendableRunnable) () -> {
// your code
}).start();
但无论哪种,一定要允许方法抛出SuspendExecution异常,因为Fiber正是通过捕获该异常控制挂起及恢复的。
项目中建议使用线程池,因此线程池可以改造为Fiber支持的形式:
@Bean(name = EXECUTOR)
public Executor setThreadPoolExecutor() {
/* Do not drop task */
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(getCorePoolSize());
threadPoolTaskExecutor.setMaxPoolSize(getMaxPoolSize());
threadPoolTaskExecutor.setThreadNamePrefix("Executor_");
threadPoolTaskExecutor.setQueueCapacity(200);
threadPoolTaskExecutor.setKeepAliveSeconds(60);
threadPoolTaskExecutor.setAllowCoreThreadTimeOut(false);
threadPoolTaskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
threadPoolTaskExecutor.initialize();
// return threadPoolTaskExecutor;
return new FiberExecutorScheduler("Fiber_", threadPoolTaskExecutor);
}
值得注意的是关于Fiber的逃逸问题,大批量的Fiber逃逸会严重影响性能,可以通过监控避免。
项目中如果大量使用了ThreadLocal或者InheritableThreadLocal,甚至是TransmittableThreadLocal,要尤其注意Fiber下的实际表现。庆幸的是,关于ThreadLocal或者InheritableThreadLocal,Quasar源码中有单元测试可供参考。
技术实践
应用场景
广告投放。广告投放负责承接媒体流量,进行受众定向后,结合广告召回、排序、出价等策略,进行站外投放等目的,最终达到拉活、拉新等站外引流的效果。
技术挑战
由于全网媒体流量众多,广告服务承载的流量高达几百亿每天,QPS也是百万每秒,而媒体给出的RT要求是40~100ms之间,不难看出,广告投放对于响应效率要求极为苛刻。
语言情况
服务语言栈引擎使用Go语言;策略系统使用Java语言。本篇文章改造的目标是策略系统这部分Java语言的应用。
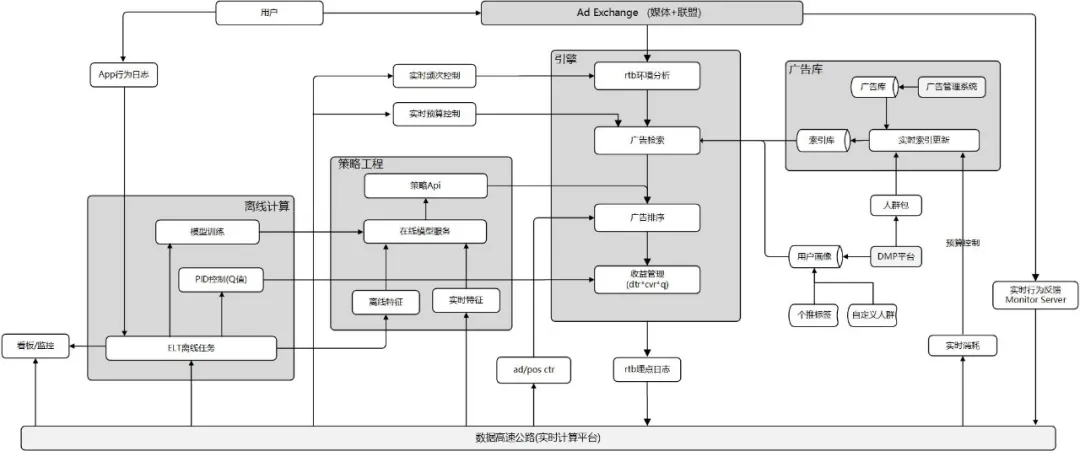
架构简介
效果回收
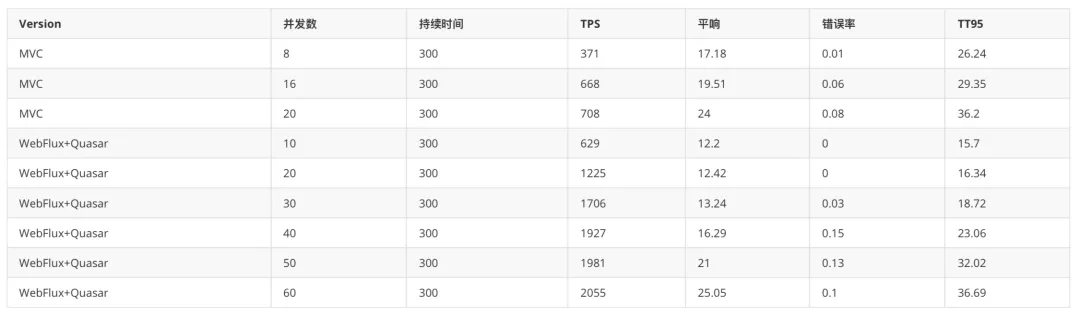
在测试项目进行了迁移实验,可以看到使用了WebFlux+Quasar的TPS提升明显,可以达到此前的294%;平响、错误率、95线几乎持平。
尽管根据预估还有提升空间,但目前的效果已经非常显著,后续将进一步思考如何优化模型调用的性能表现及尽快完成迁移。
迁移成本
JavaWeb有个特点,对于新鲜的技术耳熟能详,但是实际应用上较为保守,所以实际使用案例少之又少,加上响应式编程对于传统编程的区别以及纤程在处理并发细节等问题增加了学习成本,团队推行难度更大,也需要更谨慎。
由于Java的业务众多,难以保证所有的业务场景都能适用,例如,在RJDBC出现前,操作数据库的阻塞问题始终无法解决,也阻碍了一部分开发者切换WebFlux的步伐。
实际项目使用中,要考虑是不是所有的操作都是非阻塞的,这个尤为重要,响应式编程一旦内部流程有阻塞的过程,不但无法提升性能,反而会严重降低性能。所以,如果效果不够理想,建议关注下是否存在阻塞操作及纤程逃逸现象。
综上所述,流程的非阻塞、异步化改造和学习曲线注定会有一定的迁移成本。
结语(总结和展望)
在高并发的场景下,常规的性能优化已经难以满足业务需求。如何深度优化服务吞吐表现以支撑业务发展是持续努力的方向,本文通过使用WebFlux技术解决了高并发场景下吞吐量瓶颈的难题,通过使用Quasar技术解决了并发计算和异步等待的内存消耗和线程切换成本,同时取得了很理想的结果,TPS提升约3倍。
同时不难发现,将一个成熟的项目做文中的升级是极具挑战的,主要体现在学习曲线、业务适用性及技术改造等方面。因此,在实际生产中,项目负责人可以根据情况分析、实验并尝试,但不代表使用了该技术一定是最合适的选择。
尽管如此,我们还是欣喜地看到,该技术应用得当的话,性能提升是令人兴奋的。同时,可以使代码编写更简洁、业务处理更清晰。
无论如何,实现成本是不能被忽视的,本文作
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E6%8A%80%E6%9C%AF%E5%93%8D%E5%BA%94%E5%BC%8F%E7%BC%96%E7%A8%8B%E5%92%8C%E5%8D%8F%E7%A8%8B%E5%9C%A8%E8%AF%AD%E8%A8%80%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


