贝壳网相关性计算原理及实践
0 前言
在贝壳找房,房源、小区、看点等涉及到文本搜索的应用都是以ES作为底层搜索和召回组件,经ES相关性计算后粗筛出结果,再对粗筛结果做二次排序。所以,ES的相关性计算好坏对这些应用的用户体验有直接或间接影响,对ES相关性调优是很有必要。本文结合ES在贝壳找房这些应用的实践经验,介绍ES的相关性计算原理,以及如何对相关性调优。
1 ES相关性计算方式
ES的打分机制是基于tf-idf算法进行改进得到的。本节分成三个部分,第一部分简单介绍tf-idf算法,第二部分介绍ES早期基于tf-idf的简单改进,第三部分介绍现阶段使用的打分算法BM25。
1.1 tf-idf算法
tf-idf算法可以分成tf和idf两部分,通过将两部分乘积完成相关性计算。词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率。tf是对词数(term count)的归一化,防止偏向长文档(对于同一个词,通常长文档出现的次数会更多)。通过公式1.1计算得到tf,freq表示词W出现次数,fieldLength表示该文档总词数。
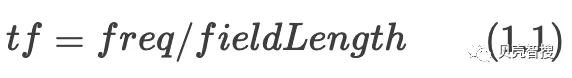
词频能够在一定程度上衡量一个词语的重要性,但是如果简单的用词频衡量相关度是不准确的,对于助词等一些无实际意义的词汇,在每篇文档中出现的次数可能都很多,但是他们和文档的主题并不相关。所以,不能简单用词频来唯一衡量这个词语跟文档的相关度。因此有了逆向文档频率(Inverse Dcument Frequency, 缩写为IDF),利用公式1.2计算得到idf,其中numDocs表示全部文档数,docFreq表示包含词语W的文档数。逆向文档频率表示越多的文档包含这个词,这个词就越不重要。
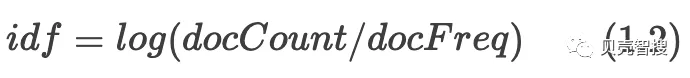
1.2 ES的tf-idf计算方式
ES的打分过程是以TF-IDF为基础,做了简单调整作为默认相似度计算方式,计算公式为1.3:
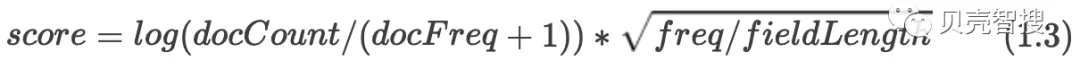
docCount:索引中文档数量;docFreq: 包含关键字的文档数量。在idf中,
ES对docFreq进行加1是为了避免分母为0;在tf中,进行了开根号,是为了减小tf的增速;限制tf的增速,主要是针对多个词进行检索可能出现的问题进行的优化。
一个query分完词后得到ab…n个词语,利用公式1.3以及1.4可以计算得到每个文档针对这个query的相关性。
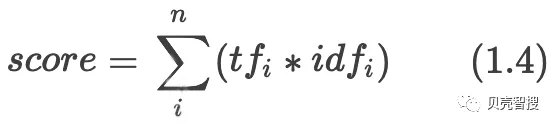
1.3 BM25计算方式
ES新的相关性计算方式(BM25),利用了tf-idf的思想,但具体计算过程和tf-idf有了很大的差异。
BM25在计算tf中增加了一个 常量k(默认取1.2),这个参数控制着词频结果在词频饱和度中的上升速度,过快的上升速度会导致什么问题呢?例如有一个搜索query,分词为abcd,过快的增长速度可能会导致包含较少词的文档相关性比同时包含更多词的相关性更大,这是不符合预期的。
BM25在计算tf过程中里除了引入k外,引入另外两个参数:L和b。avgFieldLength表示文档的平均文档长度,单个文档长度对相关性的影响力与它和平均长度的比值有关系。L是文档长度与平均长度的比值。b是一个常数,这个参数控制着文档长度归一化粒度, 0禁用归一化, 1.0启用完全归一化,默认值为0.75。最终公式为1.6:
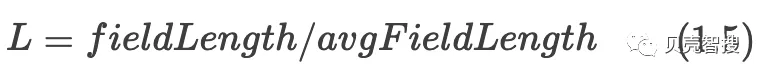
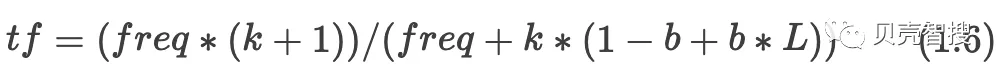
在实践中, k和b的默认值适用于绝大多数文档集合,但最优值还是会因为文档集不同而有所区别,为了找到某个文档集合的最优值,就必须对参数进行反复修改验证。
在BM25中,idf也进行了调整,转换成公式1.7。
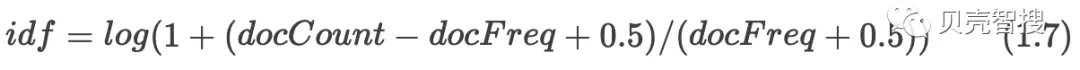
2 相关性调优
2.1 multi_match检索
multi_match打分方式会对每个字段进行 单独打分,待每个字段打分完成后,将结果进行合并,计算方式主要有most_fields、best_fields以及cross_fields三种。
在搜索过程中会对query进行分词,再将分词结果分别和每个字段进行匹配。例如用户输入query“贝壳找房大平台”,分词结果为“贝壳”,“找房”,“大平台”,每个词都对应一个should查询语句。
most_fields和best_fields是一种以字段为中心的检索方式,计算过程如图1所示,fn()分别为sum和max。
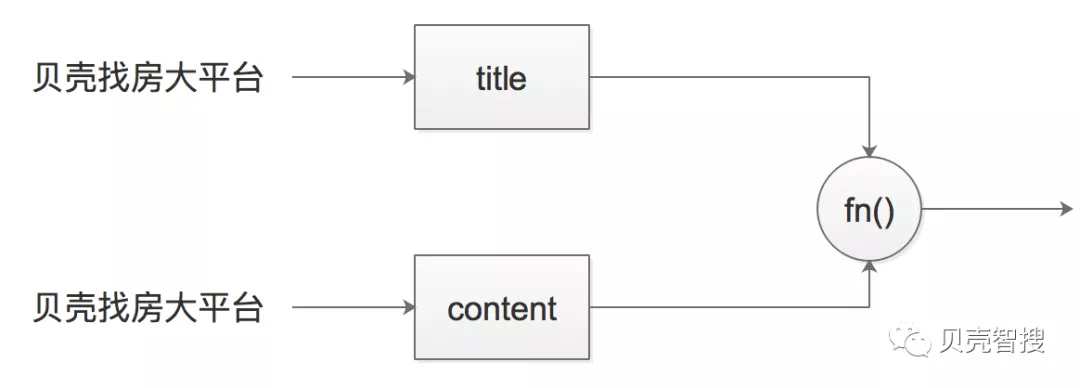
图1
而cross_fields是一种类似于以词为中心的搜索分值计算方式。cross_fields的计算过程是把所有字段合并成一个大的字段进行计算。
2.1.1 most_fields计分方式
对于一个文档有title,overview,content等多个字段,在利用most_fields(多字段匹配)进行检索时,es会单独计算每个字段的得分,然后将结果合并,得分为公式2.1,其中coord为匹配的子条件和总的子条件比值。
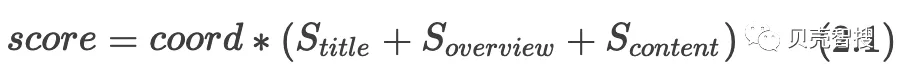
2.1.2 best_fields计分方式
best_fields(最佳字段匹配)的计算方式和most_fields不同,它侧重考虑 分值最高 的字段,计算过程见公式2.2:
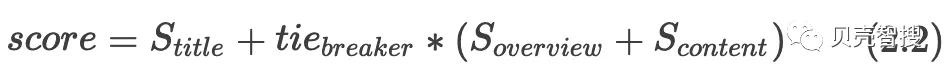
公式2.2中可以指定协调因子(tie_breaker),当tie_breaker的值为0时(默认为0),只考虑得分最高的字段,当值为1时和most_fields计算方式一样。
2.1.3 cross_fields计分方式
cross_fields类型采用了一种类似于以词条为中心(Term-centric)的方法,它将所有的字段视为一个大的字段,然后在这个大字段中搜索每个词条。计算过程可以简化为公式2.3。

以字段为中心的检索可能会导致白象化,而以词为中心的搜索方式能比较好的解决这个问题。接下来我们用一个例子简单介绍下白象化现象,我们在索引中添加两篇文档,如图2所示:

图2
利用query“albino elepahant”进行检索,按照我们的认知,文档2应该更相关,理应排在文档1之前,但是结果却不然,在以字段为中心的检索过程中,两者的得分是一致的,es没有对“albino elepahant”整个词语进行额外的加分,而使用以词为中心的搜索就能解决这个问题。
以字段为中心的检索过程是把query放到每个字段进行匹配的过程,而以词为中心的检索过程则是将检索词逐词和每个字段进行匹配计算,而非整个字符串在每个字段当中进行搜索。
2.1.4 使用
全文搜索是一场查全率(Recall) 以及查准率(Precision)之间的战斗。三种打分类型的选择上,我们可以根据具体使用场景进行抉择。best_fields侧重于查准率;most_fields有利于提升查全率;cross_fields能解决白象化现象(cross_fields只是找到尽可能多的field匹配的文档,而不是某个field完全匹配的文档)。
在es中的使用方式参考代码1。
1. ` {`
2. ` "query": {`
3. ` "multi_match": {`
4. ` "query": "贝壳找房大平台",`
5. ` "fields": ["title","content"],`
6. ` "type": "most_fields",`
7. ` "tie_breaker": 0`
8. ` }`
9. ` }`
10. ` }`
代码1
2.2 query_string检索
利用TF-IDF衡量词的权重时,倾向于给不常见的词赋予高权重。有两个索引字段: first_name、last_name。假设有一篇文档的内容是:“Smith Jones”,其中Smith 在索引的first_name字段,Jones在索引的last_name字段。而根据人类起名字的习惯,很少有人把 词 Smith 作为first_name,当词“Smith”出现在 first_name字段时,相应的文档得分就会异常的高。而现在刚好有个名字 “Smith Jones”,用户查询的是:“Will Smith”,但是返回的最佳匹配文档是:“Smith Jones”,而不是"Will Smith"这个词。这也是一个未给整词进行额外加分造成的白象化现象。
前文介绍到cross_fields是一种类似于以词为中心的检索方式,可以比较好的解决白象化问题,但是cross_fields只是把多个字段拼成一个大的字段,并不是真正意义上的以词为中心的计算方式,接下来介绍query_string打分方式,一种真正意义上的以词为中心的计算过程。具体计算过程如图3所示:
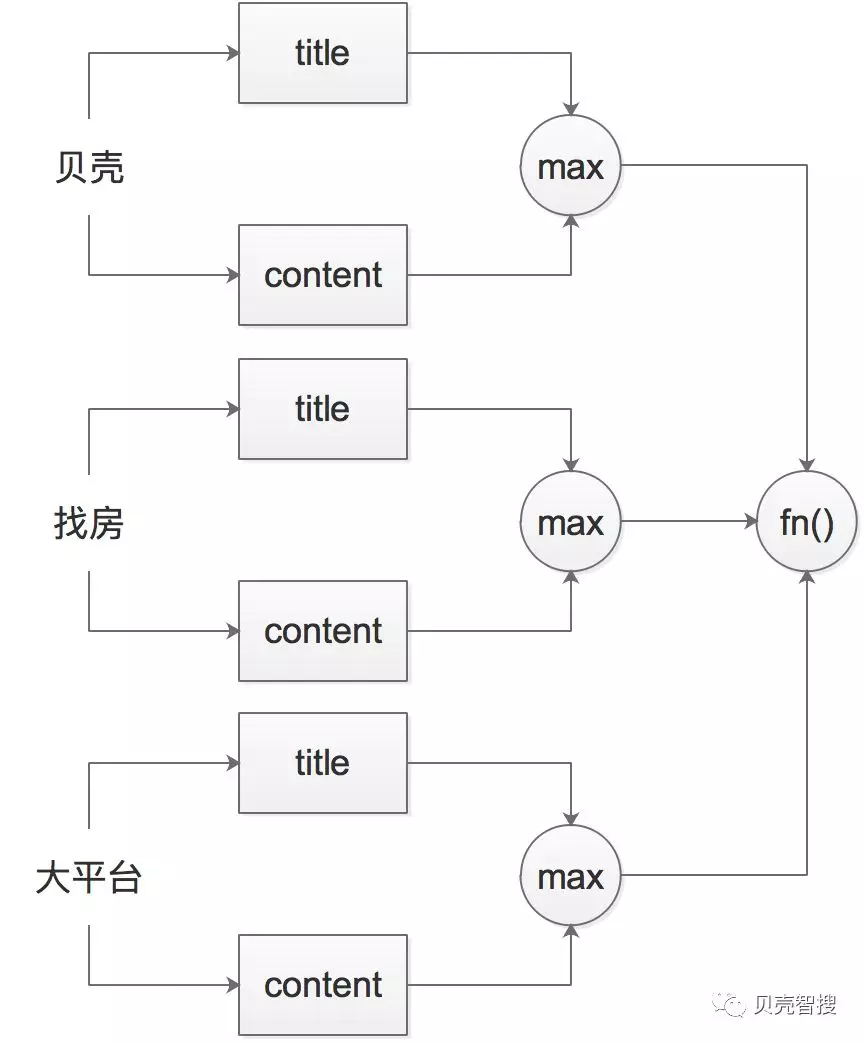
图3
以词为中心的搜索方式是计算每个词在对应字段中的分值,侧重于最大值,这一点与best_fields很像,可以通过设定tie_breaker(新的版本用tie_breaker,一些版本上用dismax字段设置),把其他字段得分纳入考虑,tie_breaker取值为0-1,默认为0。以词为中心的搜索相比于multi_match更灵活,可以在query中拼写条件,query_string默认使用所有字段,也可以在query中指定每个词条对应字段,同时还支持通过analyze_wildcard开启使用通配符功能,在es中的使用方式见代码2:
1. `GET test/_search?explain=true`
2. `{`
3. ` "query": {`
4. ` "query_string": {`
5. ` "query": "贝壳 OR 找房 OR 大平台",`
6. ` "tie_breaker": 0.1,`
7. ` "analyze_wildcard": false`
8. ` }`
9. ` }`
10. `}`
代码2
相比于multi_match,query_string强大了太多,但是在使用的时候需要谨慎,功能的强大同时也意味着更耗性能。同时,支持自定义操作逻辑也意味着可能造成信号冲突,ES是没办法判断输入的OR的一个操作符还是一个词条的。
2.3.字段值放大
在检索的时候,我们可以指定对哪些字段进行检索,ES就会对其中的每一个字段进行打分。标题和摘要相对于内容来说更能体现一篇文档的主题,通常我们希望标题和摘要能给更大的权重。
我们可以通过ES的放大机制针对不同字段赋予不同的权重进行提权。通过前文介绍的计算方式得到某个字段得分,然后乘以boost权重,得到这个字段的最终得分,实现放大的目的。在一次搜索中,检索字段为"title"和"content"搜索query分词完得到A、B两个词,我们对"content"字段进行了放大处理,权重为"boost",用2.4表示词A在字段"content"的相关性得分,则最终得分可以用公式2.5表示。
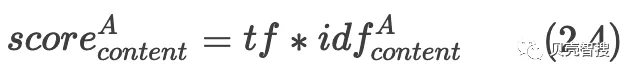
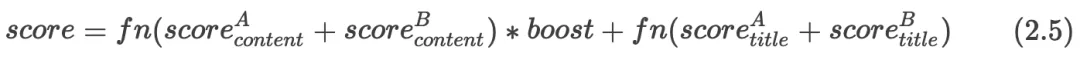
在es中可以使用代码3实现对title的放大。
1. ` {`
2. ` "query": {`
3. ` "multi_match": {`
4. ` "query": "贝壳找房大平台",`
5. ` "fields": [`
6. ` "title^100",`
7. ` "content"`
8. ` ]`
9. ` }`
10. ` }`
11. ` }`
3 ES打分过程解释信息解读
在经过一系列的优化处理后,可能结果还是不符合预期,这时候查看es的打分过程有助于优化相关性。es通过向外提供explain参数来获取具体打分过程,
便于分析。我们就拿白化象的例子简单介绍下怎么看es的打分日志,我们在"test"索引中插入图2的两篇文档。
1. `GET test/_search?explain=true`
2. `{`
3. ` "size": 1,`
4. ` "query": {`
5. ` "multi_match": {`
6. ` "query": "albino elepahant",`
7. ` "fields": ["titele", "content^5"],`
8. ` "type": "best_fields",`
9. ` "tie_breaker": 0.2`
10. ` }`
11. ` }`
12. `}`
便于了解,我们在代码4中利用multi_match的方式进行打分,并且检索query为"albino elepahant",检索的字段为"titele", “content”,并且把content的权重设为5,利用代码4进行请求,得到结果如代码5(篇幅原因,精简部分不必要信息)。
1. `{`
2. ` "_source": {`
3. ` "titele": "albino",`
4. ` "content": "elepahant"`
5. ` },`
6. ` "_explanation": {`
7. ` "value": 1.4959468, ❶`
8. ` "description": "max plus 0.2 times others of:", ❷`
9. ` "details": [ ❸`
10. ` {`
11. ` "value": 1.4384104,`
12. ` "description": "sum of:",`
13. ` "details": [`
14. ` {`
15. ` "value": 1.4384104,`
16. ` "description": "weight(content:elepahant in 0) [PerFieldSimilarity], result of:",❹`
17. ` "details": [`
18. ` {`
19. ` "value": 1.4384104,`
20. ` "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",❺`
21. ` "details": [`
22. ` {`
23. ` "value": 5.0,`
24. ` "description": "boost", ❻`
25. ` "details": [`
27. ` ]`
28. ` },`
29. ` {`
30. ` "value": 0.2876821,`
31. ` "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", ❼`
32. ` "details": [`
33. ` ❽`
34. ` ]`
35. ` },`
36. ` {`
37. ` "value": 1.0,`
38. ` "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", ❾`
39. ` "details": [`
41. ` ]`
42. ` }`
43. ` ]`
44. ` }`
45. ` ]`
46. ` }`
47. ` ]`
48. ` },`
49. ` {`
50. ` "value": 0.2876821,`
51. ` "description": "sum of:",`
52. ` "details": [`
53. ` {`
54. ` "value": 0.2876821,`
55. ` "description": "weight(titele:albino in 0) [PerFieldSimilarity], result of:",`
56. ` "details": [`
57. ` {`
58. ` "value": 0.2876821,`
59. ` "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",`
60. ` "details": [`
61. ` {`
62. ` "value": 0.2876821,`
63. ` "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",`
64. ` "details": [`
66. ` ]`
67. ` },`
68. ` {`
69. ` "value": 1.0,`
70. ` "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",`
71. ` "details": [`
73. ` ]`
74. ` }`
75. ` ]`
76. ` }`
77. ` ]`
78. ` }`
79. ` ]`
80. ` }`
81. ` ]`
82. ` }`
83. `}`
在结果中,展示了搜索结果中第一条结果的打分过程,主要有两部分:"_source"和"_explanation","_source"为源文档信息,"_explanation"为具体的解析信息,在解析信息中每一部分都是由"value",“description"和"details"三部分组成。“value"为这个阶段的得分结果;“description"这个过程的介绍信息;“details"是详细过程。
在”_explanation"中 ❶为最终打分结果;从 ❷可以看出因为用的是"best_fields”,分档最后在各个字段的计算方式为"max of:",但因为使用了"tie_breaker”,非最大分值也会乘以"tie_breaker”,加入总得分中;❸这部分就是详细的计算过程,“details"是一个数组,这里包含了每个字段的详细打分过程;从❹可以看出这部分是对"content"这个字段的计算过程,因为只有一个词在"content"中出现,所以这里的"details"只有一个值;❺这部分包含一些计算过程的统计信息,这部分的得分是通过"product of"计算得到; 因为对"content"加了”^5"所以,这里会有一个"boost";❼ 这部分是描述了idf的计算过程,并且公式中的参数值由❽给出(篇幅原因,❽省略);❾是tf计算过程,与❽类似。
4 可能碰到的问题
4.1 相同请求,主分片和副本之间排序不一样
在使用Elasticsearch搜索的时候很容易碰到:对于同一个搜索请求,多次请求会出现top50返回结果排序不一致的问题,并且翻页后,可能存在重复的问题。那么为什么会出现这样的问题?
这是由Elastcisearch的分布式搜索特性导致的。Elasticsearch在做检索时,会循环的选择主分片和其副本中的一个来计算和返回搜索结果。但是主分片和副本中相关统计信息的不同,导致了同一个搜索串的评分的不一致,从而导致排序不一样。而造成这种主分片和副本统计信息不一致的具体原因,主要是因为在文档删除时造成的。ES删除数据的时候,不会马上删除数据,只是标记了删除,并且只会在下次这个segment被合并的时候才会被删除(这意味着只有在下一次segment合并的时候才会被删除,而在执行合并的时候,并不是所有segment都会被合并,只有在segmengts满足特定条件才会被合并),而实际上,这些已经被删除的文档,也会包含在算分的统计里面。
解决方法:
每个请求有一个唯一标识值,相同请求打到同一个shard,但是这样可能会存在一个问题,对于贝壳找房这样的网站来说,默认列表页的请求量是最大的,这样就会造成副本和主分片的负载不是均衡的。
用一个字符串标识一个用户,这样每个用户的请求都会打到同一个shard,保证同一个用户看到的排序是不变的。
使用方式:
对于java API,可以指定SearchRequest的preference,进而指定访问的分片。
如果直接访问 es 可以通过参数 preference指定: “get YOUINDEX/search?preference=xyzabc123”, 其中xyzabc123可以是用户id等字符串。
preference可以指定的值有:
_primary。搜索只在主分片执行搜索请求,副本不参与搜索;性能会打折扣,不能起到通过扩展节点增加qps。
primaryfirst。优先在主分片执行,如果主分片挂掉,会在副本执行请求。
_local。搜索请求优先于在本地执行。
onlynode:xyz。只在xyz节点执行搜索。
prefernode:xyz。搜索请求优先在节点xyz执行。
shards:2,3。搜索只在分片2、3执行,可以与primary参数一起使用如:shards:2,3;primary。
xyz。指定一个随机字符串,可以保证同样的请求,被分配到同样的副本上面,从而保证同一请求结果的稳定性。
除了统计信息可能导致的排序不一致之外,相关性一致的文档,排序可能也会不一样。这是因为对于相关性一样的文档排序,ES是会根据内部的id进行排序的。但是如果有副本的话,就可能会导致翻页后文档重复的问题,这是因为两个得分相同的文档,在不同副本id是不同的。因此,在检索的时候指定prefrence是很有必要的。
4.2 相同文本内容,不同shard相关性得分不一样
相同文本内容,不同shard相关性得分不一样,或者明明更相关的文本却没有排在更前面。这是因为在检索的时候,每个shard各自负责自己的打分,也就是说,打分的时候统计信息是局部的,是每个shard自己的统计信息,而索引的统计数值对打分影响结果至关重要,通常每个shard各自的统计数值都是不一样的。只有在每个shard的统计数值都一样的情况下,不同shard的对相同内容打分才会一致。特别是在route的时候以索引时间作为routing,查询多个索引或者数据量小的时候特别明显。
ES默认使用query_then_fetch的方式进行检索,第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。
解决方法:
如果数据量小的话,只用一个索引,并且这个索引只有一个shard。
利用route。如果你的数据集可以精确的按照某个字段划分,并且检索的时候,只检索某个类,比如搜索贝壳找房,在特定城市情况下,都是按照城市来检索,那么就可以利用城市作为route,这样每个城市的数据就会都在一个shard上,也就是这个城市的所有房源用相同的统计数据。
利用dfsquerythenfetch的检索方式。这个检索分三个阶段,比querythenfetch多一个阶段,会先把各个shard和这个query相关的统计数据收集起来;之后根据收集的信息按照querythen_fetch进行检索。
使用方式:
直接访问ES可以通过参数searchtype: GET YOUINDEX/search?searchtype=dfsquerythen_fetch
JAVA API通过指定SearchRequest的searchType为DFSQUERYTHEN_FETCH。
5.小结
ES是一个基于Lucene功能强大的搜索引擎包,包含了众多开箱即用的优秀功能。本文从ES相关性计算出发,结合贝壳找房在相关性调优中的一些实践,简单介绍了ES相关性计算过程,几种相关性调优方式以及调优过程中可能发现的问题。要�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E7%BD%91%E7%9B%B8%E5%85%B3%E6%80%A7%E8%AE%A1%E7%AE%97%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


