达摩院李雅亮大规模预训练模型的压缩和蒸馏

分享嘉宾:李雅亮博士 阿里巴巴
编辑整理:陈东 东南大学
出品平台:DataFunTalk
导读: 本次分享的主题为大规模预训练模型的压缩和蒸馏,主要是从自动机器学习的角度,介绍大规模预训练模型的压缩和蒸馏。将介绍阿里巴巴达摩院关于模型压缩的三个连续承接性的工作:
- 工作1:AdaBERT:Task-AdaptiveBERT Compression with Differentiable Neural Architecture Search. IJCAI’2020.
- 工作2:L2A:Learning toAugment for Data-Scarce Domain BERT Knowledge Distillation. AAAI’2021.
- 工作3:Meta-KD:MetaKnowledge Distillation Framework for Language Model Compression across Domains.ACL’2021.
01 背景介绍
自2018年BERT预训练横空出世,NLP领域出现了一个全新的范式,大规模预训练模型给我们带来了很多新的能力。通俗来讲,我们会先从很多其他语料或者说很多大规模数据里面做一个预训练的模型,然后在具体任务的训练语料微调预训练的模型。基于“预训练-微调“范式,许多任务的性能都得到了极大的提升。如图1,文本分类(Text Classification), 命名实体识别(Named Entity Recognition),基于机器阅读理解的问答(Question Answering, MachineReading Comprehension)等任务的性能得到显著提升。在BERT论文中他们指出BERT在11个经典的自然语言任务中超越当前的state-of-the-art的性能,“一石激起千层浪”,自此之后,大量的预训练模型层出不穷——GPT系列预训练模型,相比BERT炼制更加成熟的RoBERTa, 缓解序列长度的限制XLNET, 融入知识的K-BERT, 领域预训练模型SCIBERT等等。
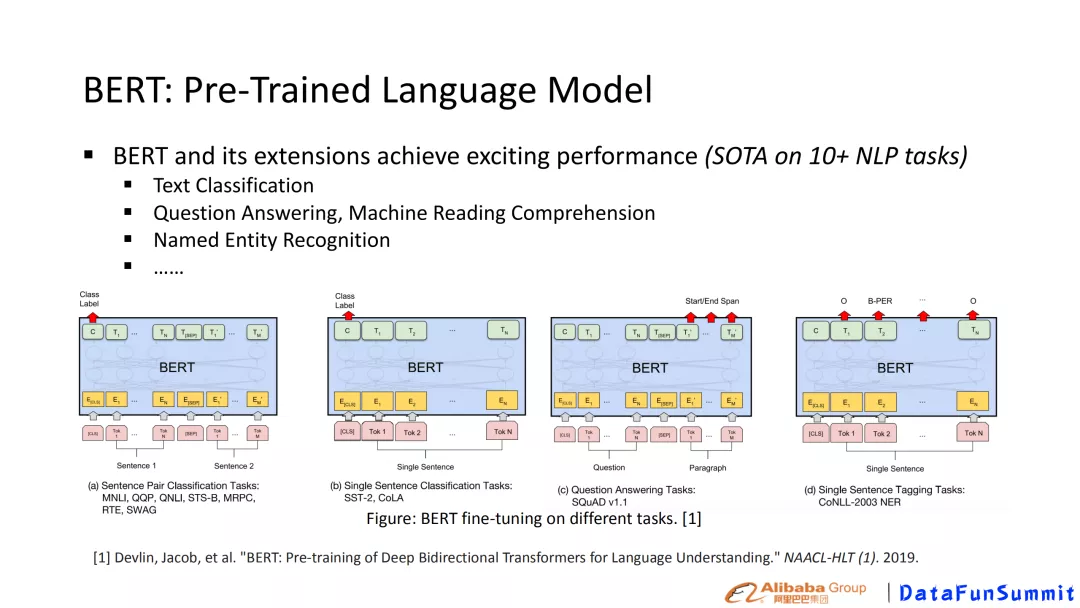
图1 BERT模型在不同任务上微调
然而,预训练的大模型,顾名思义,他们的参数量会非常大,如12层transformer堆叠的wwmpytorch版本的预训练模型大小为400M左右,24层transformer的版本大概1.2G左右。但是在现实生活中,我们的计算资源有限的情况下,至少会引起两个问题,其一,我们设备终端无法加载这么大的模型,其二,参数太多,推断速度太慢。比如说在线搜索这些需要实时响应的应用,或者说我们自己的手机、车载系统,它们的计算资源是非常受限的,所以我们需要有一些小的模型来替代它的功能。
所以,为了解决模型上述的痛点,模型的压缩技术在工业界和学术界应运而生。如图2,现在的BERT预训练模型压缩的基本研究思路如下:
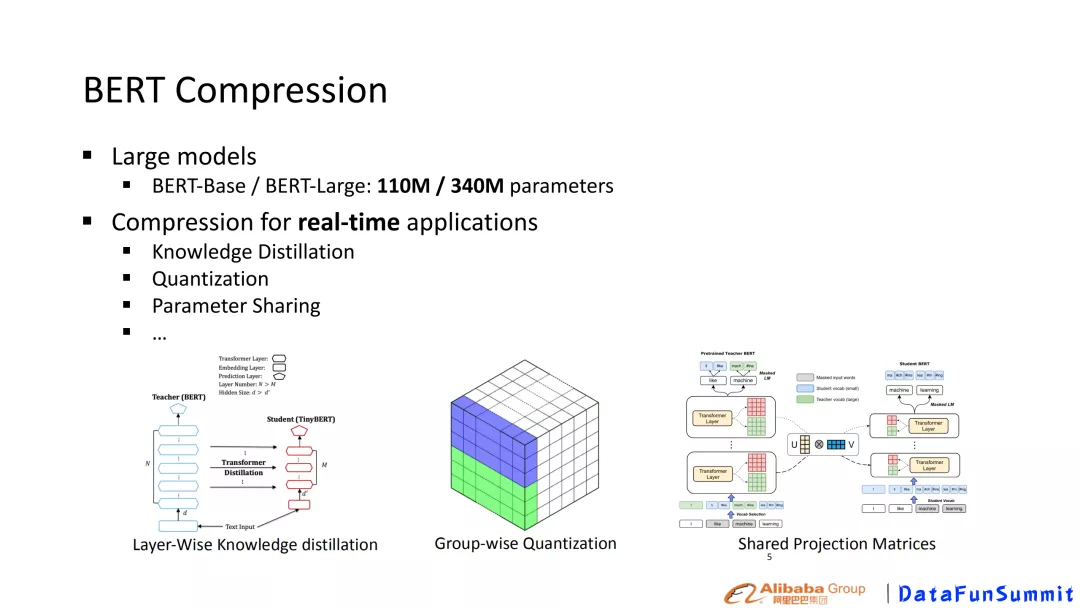
图2 BERT压缩常规研究方法
- 模型蒸馏(distillation):强迫一个小的模型去通过去模仿一个大模型的输入输出,如DistilBERT, TinyBERT, MiniLM等工作。
- 量化(quantization):对整个大模型里面的参数做量化,也就把很多不重要的参数,我们可以用比较少的精度来存储, 如Q-BERT等工作。
- 参数共享(parameter sharing):模型不同的组件(component)之间去共享参数,如ALBERT的工作。
02 AdaBERT介绍
1. 研究动机
上述模型压缩的几个基本的研究思路(distillation,quantization, parameter sharing等)都是和下游任务(downstream)不相关的,即模型压缩的结果都是大模型统一压缩成小模型,然后再利用小模型去微调具体任务。
但是,在2019年,Ian Tenney等人(如图3)揭示了——BERT学的knowledge非常的多,换一句说,BERT学到的非常多的general knowledge,但是不同下游任务需要的knowledge可能不太一样,比如做NER是你可能更关注的是细粒度的信息,做reading comprehension可能关注的是需要一些high level的信息。受此启发,我们提出AdaBERT:针对一个具体的下游任务,通过自动压缩一个小模型,来适配该任务,即小模型是专门为该任务服务的。

图3 自适应任务模型压缩的研究启发
2. 模型介绍
我们利用神经网络结构搜索(NAS)来自动化搜索小模型的网络结构。下面我们从三个方面介绍模型的一些设计。
① 如何定义Search Space
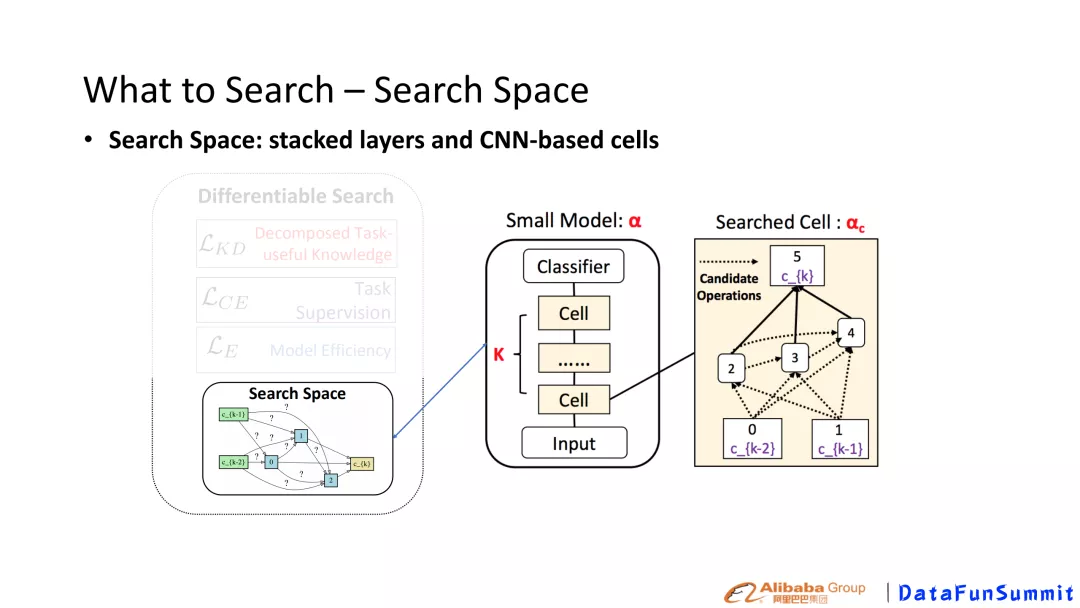
图4 Search space 设计
不同于以往BERT的压缩——将Transformer结构压缩成更少参数transformer的结构。在这里我们采用基于CNN结构的architecture。原因如下:
- 首先,很多场景下的优化,基于CNN的硬件支持可能会更好,有利于实际场景中的部署;
- 另外,主要考虑到在AutoML中NAS研究中关于绝大部分研究都会是和CNN相关的,方便借鉴已有的成果,如differentiable, Gumbel trick。
② Search目标
Search的目标包含两个方面,一方面,需要小模型尽可能保留BERT中有用的knowledge,另一方面,需要权衡推断效率,即小模型的size。权衡保留大模型的有用的knowledge和 efficiency,故总体的Loss设计参见图5。其中L _{CE}为具体下游任务的Loss。,\beta, \gamma是超参数。
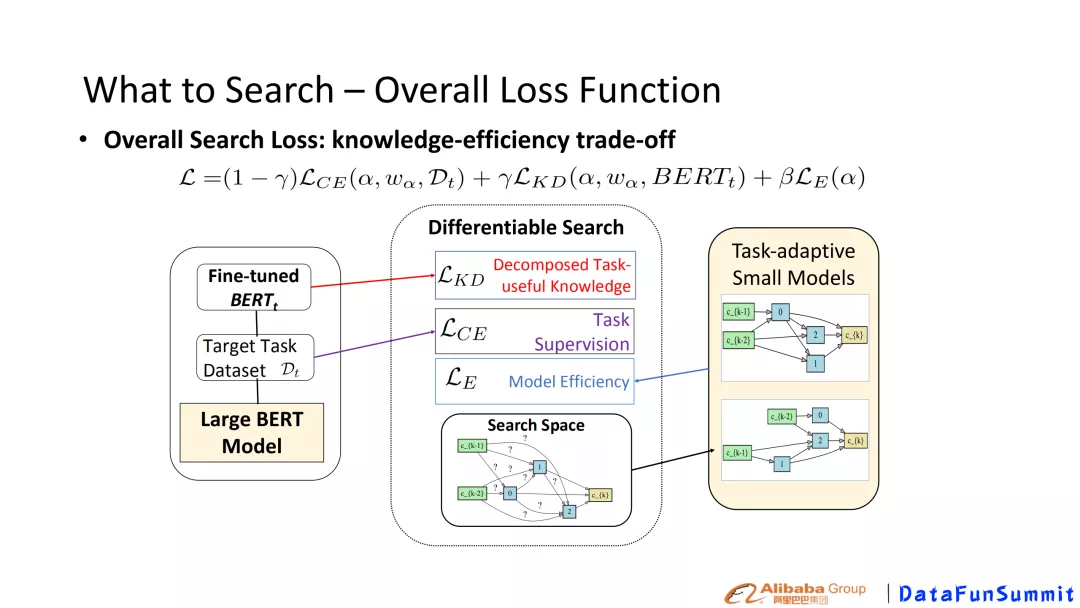
图5 权衡knowledge-efficiency损失函数设计
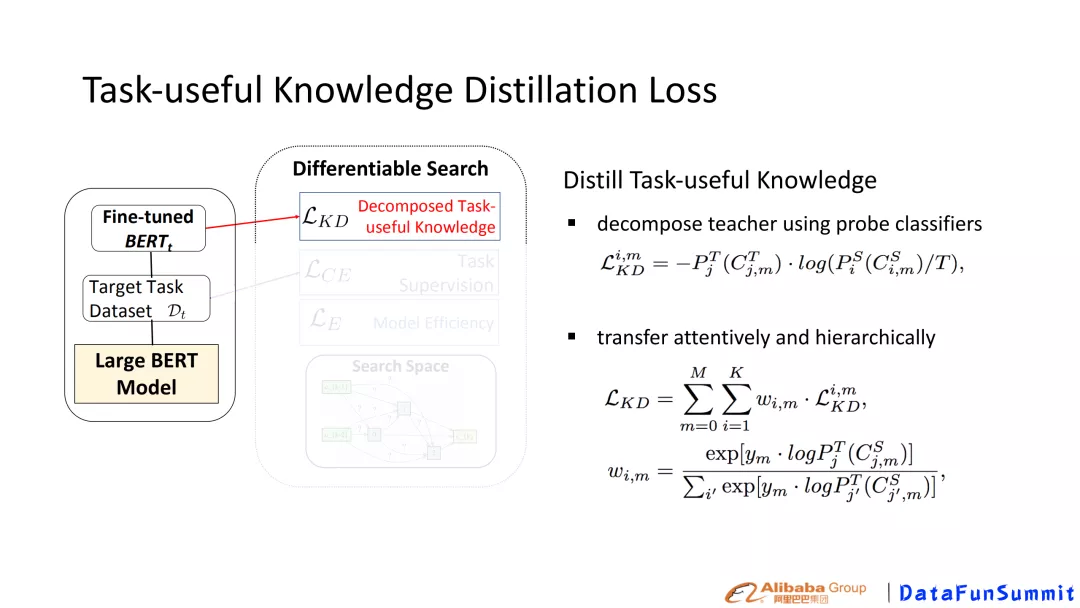
图6 knowledge distillation Loss
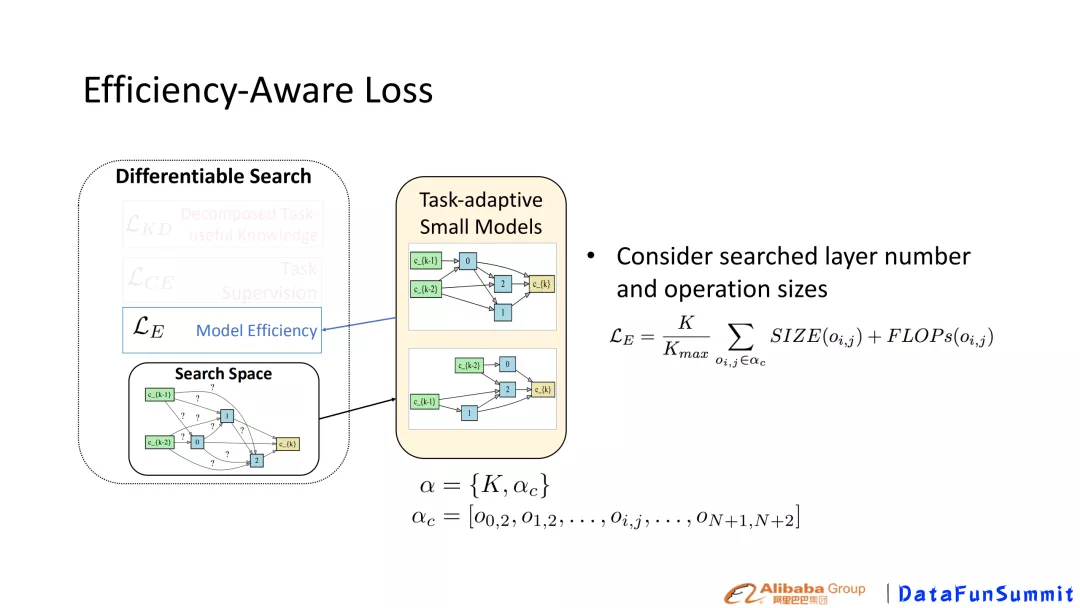
图7 efficiency-aware Loss
③ 如何去搜
因为定义的CNN的网络架构是离散化的,从传统的方法来看的话,如采用随机采样的方式去尝试不同的architecture,费时费力,所以我们利用differential方法去优化。其思想是:首先,我们预定义好一些operation, 对于每个网络层,并行组织所有的operation,形成super net,即每个super net中不是存在一个operation,而是存在所有可能operation的一个集合,通过加权形成所有可能的operation,这样我们就可以用differential的方法去优化整个大网络的结构了。训练architecture的parameters使用Gumbel trick。Differential的更多的具体原理细节,可以参考Liu, Simonyan等人提出DARTS。
3. 实验效果
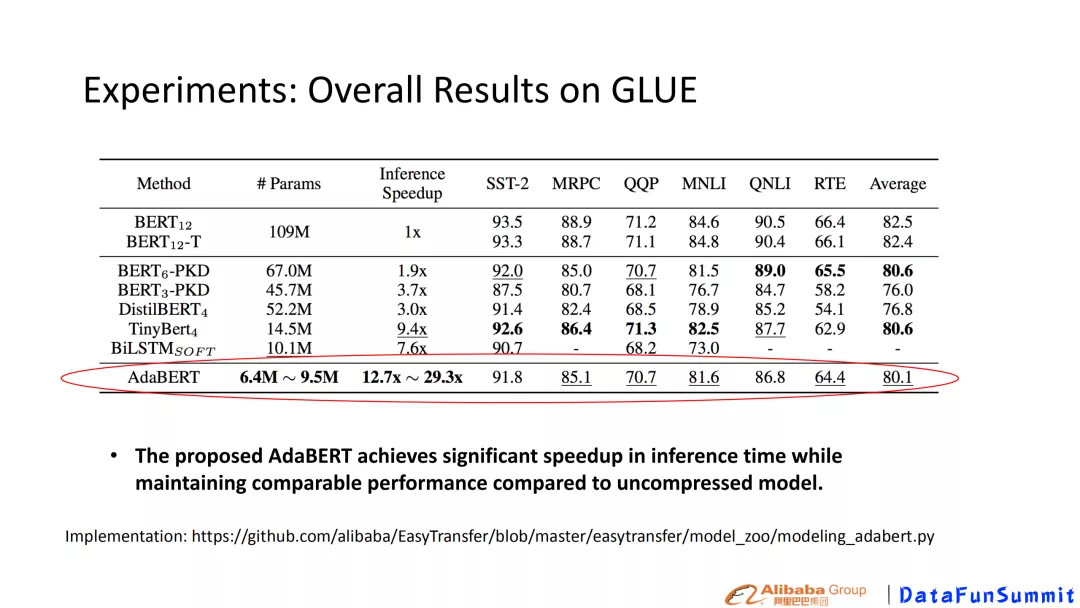
图8 实验结果
可以看出AdaBERT的performance基本都处于次优的结果,而参数量最少,inference speedup有明显提升。

图9 验证Task-AdaBERT的实验
如图9,为了验证网络结果符合任务自适应,将训练的任务自适应的小模型应用到其他任务上,完全符合我们的设想,自适应任务的模型在自己的任务上表现最优。
03 L2A介绍
1. 研究动机
通过上述介绍,AdaBERT可以work的一个前提假设是我们存在大量的领域训练数据,然而,真实世界往往是缺乏训练数据的;如果仍然按照AdaBERT一套做模型蒸馏,在数据稀少的情况下,会导致学生(小)模型性能退化。
对于数据缺乏,NLP领域有大量的data augmentation的方法,如对于真实的文本序列做token 的增,删,改,插或者来回逆向翻译。然而从自动化的角度来看,这些data augmentation的方法需要花费大量时间成本去尝试,所以我们提出一种BERT蒸馏过程中自动学习增强数据缺少领域的方法。
2. 模型介绍
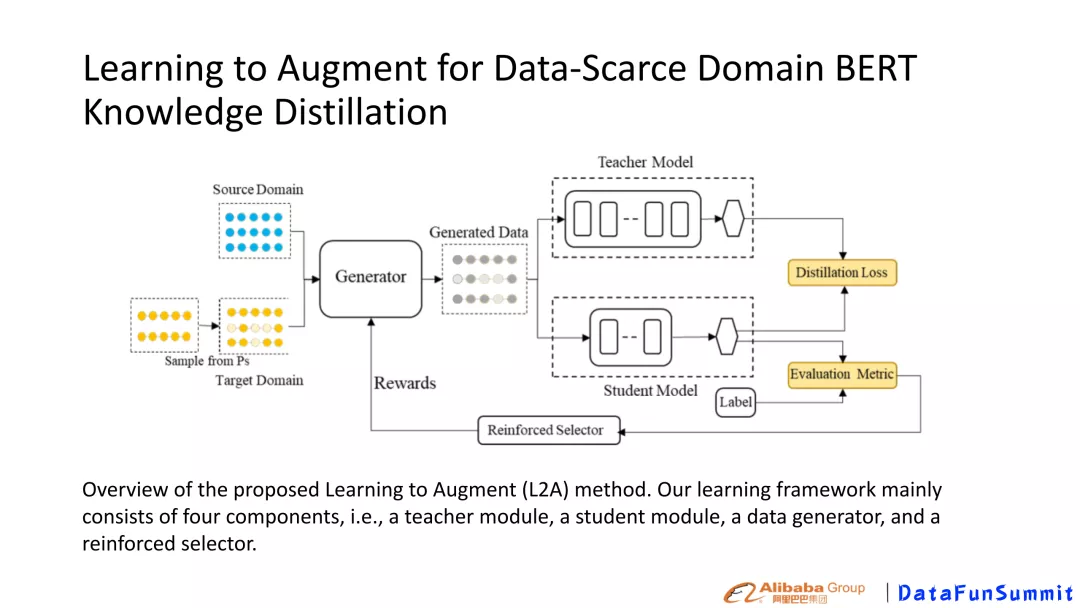
图10 L2A 模型结构
如图10,模型的主要的思想基于transfer learning和对抗网络。我们通过对source Domain 和 target Domain的data generator自动产生generated data,形成的training data�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%BE%BE%E6%91%A9%E9%99%A2%E6%9D%8E%E9%9B%85%E4%BA%AE%E5%A4%A7%E8%A7%84%E6%A8%A1%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B%E7%9A%84%E5%8E%8B%E7%BC%A9%E5%92%8C%E8%92%B8%E9%A6%8F/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


