达观数据金融知识图谱的构建与应用

分享嘉宾:王文广 达观数据 副总裁
编辑整理:朱瑞杰
出品平台:DataFunTalk、AI启蒙者
导读: 金融机构在过去积累了大量的数据,包括结构化数据和非结构化数据。如何利用这些数据来构建金融知识图谱,并将构造好的知识图谱应用到具体的金融场景下,是一件很有价值的事情。本文将为大家介绍达观金融知识图谱的构建与应用,主要内容包括:
- 人工智能的关键技术
- 领域知识图谱构建技术实践
- 金融知识图谱的应用实践
01人工智能的关键技术
人工智能技术可以划分为四个部分:
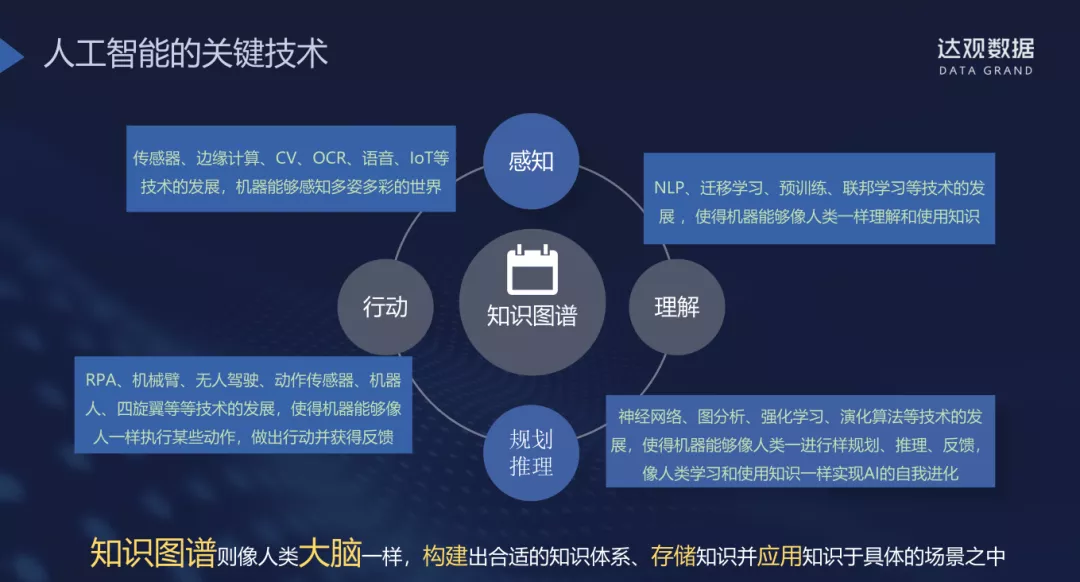
- 感知技术:即以传感器,边缘计算,CV,OCR,语言理解,IoT等使得机器能感知多姿多彩的世界技术,类似于人的感觉系统
- 理解技术:即各类对机器所获取信息建模的,使得机器能够理解和使用知识的技术。比如GPT-3通过超大规模的深度学习语言模型实现了能够理解知识和人类经验
- 规划推理技术:像神经网络、强化学习等使得机器能够像人类一样进行规划、推理的技术,其目标是促进机器能够像人一样用所理解的知识来进行推理和对未来进行规划,最终实现AI的自我进化
- 行动技术:像RPA、机械臂、无人驾驶、双足机器人等使得机器能够像人一样执行某些动作并获得反馈的技术
在这四种关键技术之上,知识图谱则是多种技术的综合体,像人类大脑和神经系统一样,构建出合适的知识体系,存储知识并应用知识于具体的场景之中从数据到知识的转换过程中,让企业的员工更快,更轻松的完成工作。
达观有着一系列的产品对整个流程进行智能化处理:
- 文档智能处理平台:这是一站式文档与资料的智能化处理;常见文档与处理需求包括,行业文档,通用合同,业务文档;与之对应的功能模块包括,通识OCR,关键信息抽取,文档智能审阅,比如说对于年报的结构化抽取和审阅。
- 达观智能RPA:非侵入对接各个业务与流程系统;在上述环节中,第一是感知,自动从文本中获取信息用于理解,第二是行动,使用模型进行推理规划之后,用RPA反作用于各个业务流程,实现办公自动化。
- 渊海知识图谱平台:一站式沉淀领域知识与专家经验
达观渊海知识图谱包括下列特点:
- 数据管理能力:支持结构化数据和非结构化数据的管理,支持mysql,postgreSQL,达梦,csv,Excel等多种数据
- 多图谱管理能力:支持创建,修改和删除任意多图谱,支持图谱的有不同模式,支持按图谱进行数据源,功能,算法,模型和权限管理等。
- 图谱构建和编辑能力:支持结构化映射式构建,三元组构建,抽取式构建,支持对图谱实体的关系数据的编辑,支持增删改查
- 图算法能力:支持spark计算和graphx图计算框架,支持多种图算法,支持基于深度学习的多种算法
- 完整权限能力:基于RBAC的用户权限控制系统,支持按照菜单,数据等权限划分
- 强大的知识抽取能力:支持标柱,训练评估全流程管理,支持实体,关系,事件抽取的任务
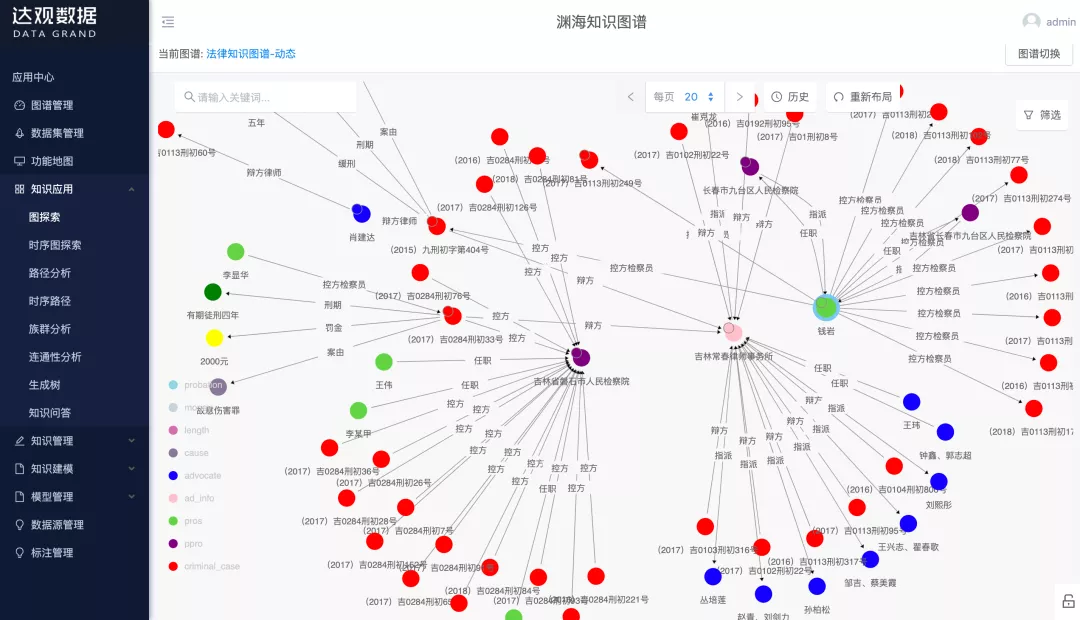
下图为渊海知识图谱平台示例:
02 知识图谱的构建技术
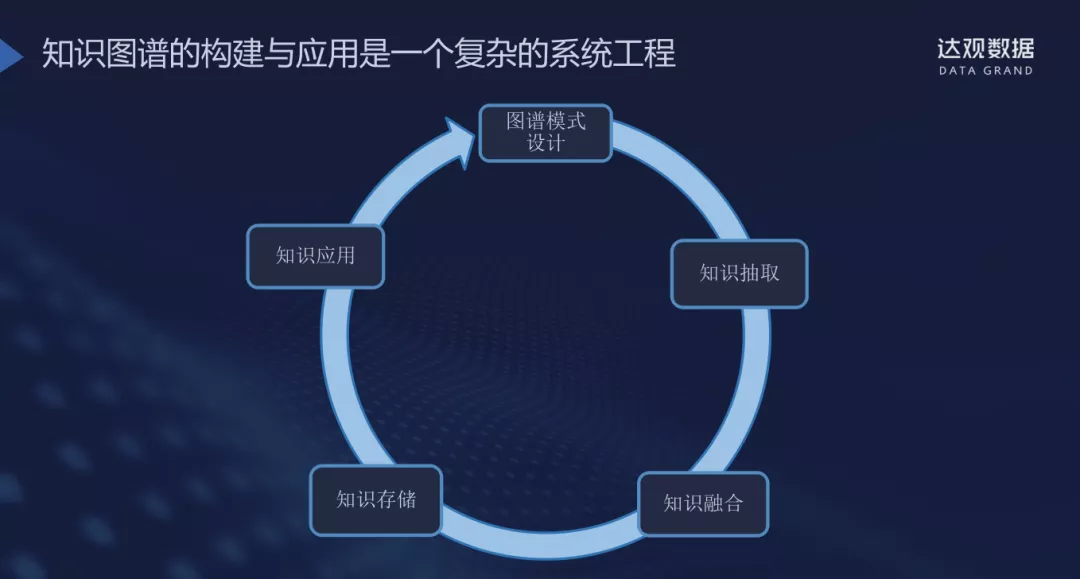
这一过程类似图片所示,需要我们不断循环迭代,是一个十分复杂的过程。
与硅砂到晶片的过程类似,构建的过程就是从海量数据中把我们所需要的有价值的信息抽取出来,从而形成有价值的图谱的过程。原始的数据可能庞杂难以被利用,价值不大;但是经过信息抽取构建图谱形成知识之后,其价值就很十分巨大。
知识图谱的构建与应用是一个复杂的系统工程,不是单纯的算法和算法优化的问题,而是业务和算法的紧密结合。步骤可以分为:
1. 图谱模式设计
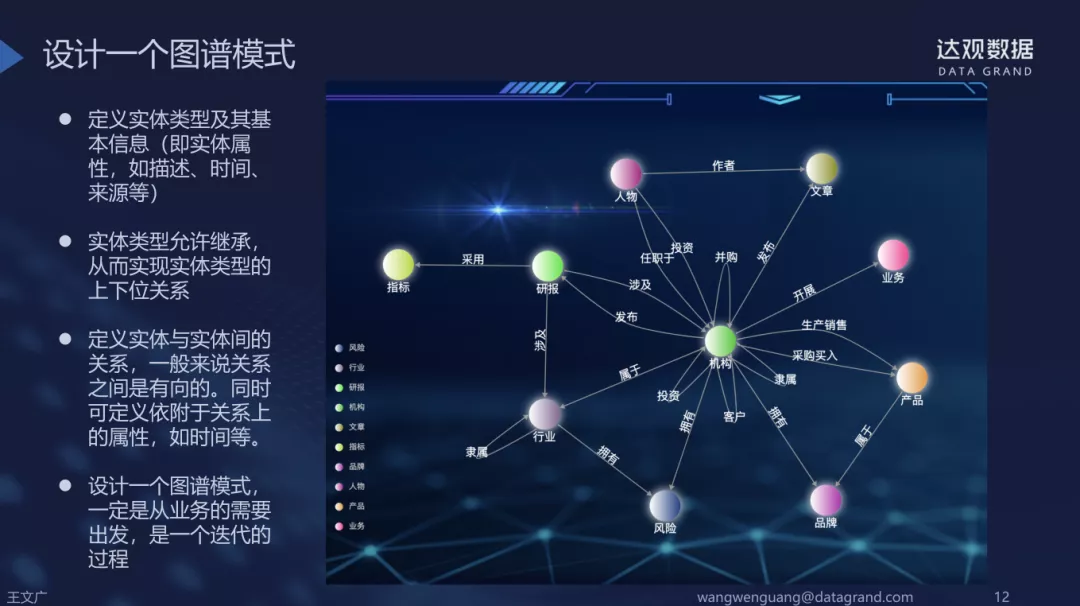
又称Schema设计或者本体设计;首先需要想清楚需要怎样的知识图谱,要和我们的业务相符合,这需要深厚的业务理解和相关领域的知识积累,通常来说,是由领域专家和知识图谱专家一同完成:
- 定义实体类型及其基本信息(即实体属性,如描述,时间,来源等)
- 实体类型允许继承,从而实现实体类型的上下位关系
- 定义实体与实体间的关系,一般来说关系之间的有向的。同时可定义依附于关系上的属性如时间等
- 设计一个图谱模式,一定是从业务的需要出发,是一个迭代的过程
2. 知识抽取
从结构化数据和非结构化数据进行信息抽取
构建技术,从大的方面分为两块:
映射式构建: 从各种各样的结构化数据(包括业务数据,传感器,QA系统,经营性数据,专家规则,统计报表等)里构建知识图谱。金融领域在过去数十年已经积累了大量的结构化数据,比如股票信息,银行资金流水等等,利用达观渊海知识图谱的映射式构建工具可以方便地将这些数据充分利用起来,成为金融知识图谱的一部分。
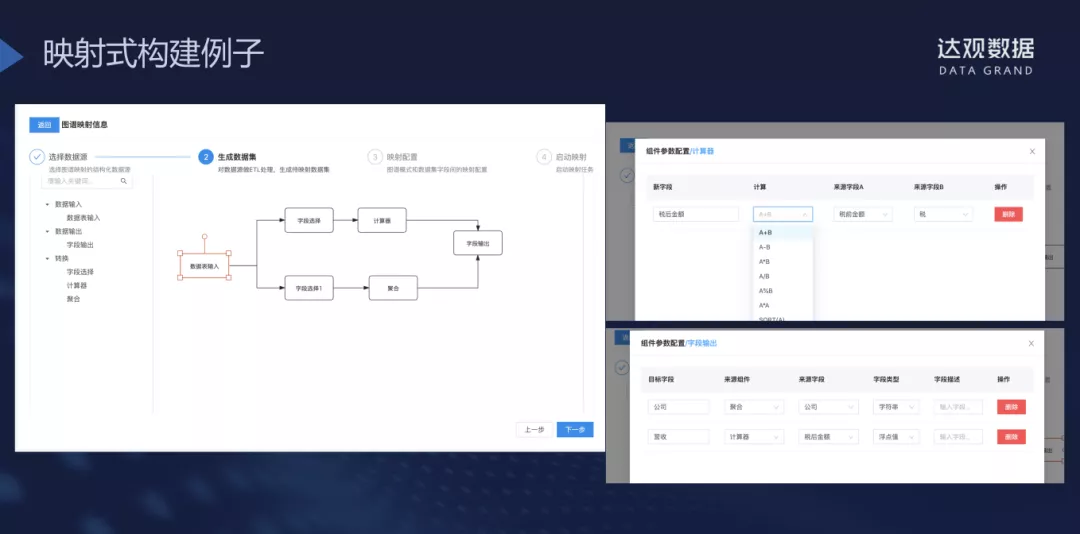
这是一个达观知识图谱的用例,来介绍映射式构建,通过图形化界面来选定数据源进行一些简单的操作,比如加减运算,聚合,以及各种数据库操作,把这类内容和操作规范映射到我们的图谱模式中去,可以一次性批量操作数据,也可以使用定时任务进行增量更新。
抽取式构建: 对于知识图谱更大的信息来源是各类公共文档、即时消息、邮件、新闻、专业文档、书籍、财报、语音识别文本等各类非结构化数据。将这些文本应用各种信息抽取技术来构建图谱,即知识抽取。

知识抽取是业界一大难题,大量模型和算法被用以解决这个问题,首先的问题就是实体识别和关系抽取的问题。
① 命名实体识别
NER(Named Entity Recognition,命名实体识别)又称作专名识别,是自然语言处理中常见的一项任务,使用的范围非常广。命名实体通常指的是文本中具有特别意义或者指代性非常强的实体,通常包括人名、地名、机构名、时间、专有名词等。NER系统就是从非结构化的文本中抽取出上述实体,并且可以按照业务需求识别出更多类别的实体,比如产品名称、型号、价格等。因此实体这个概念可以很广,只要是业务需要的特殊文本片段都可以称为实体。
NER的常见方法包括:基于规则、机器学习、深度学习、混合方式等。
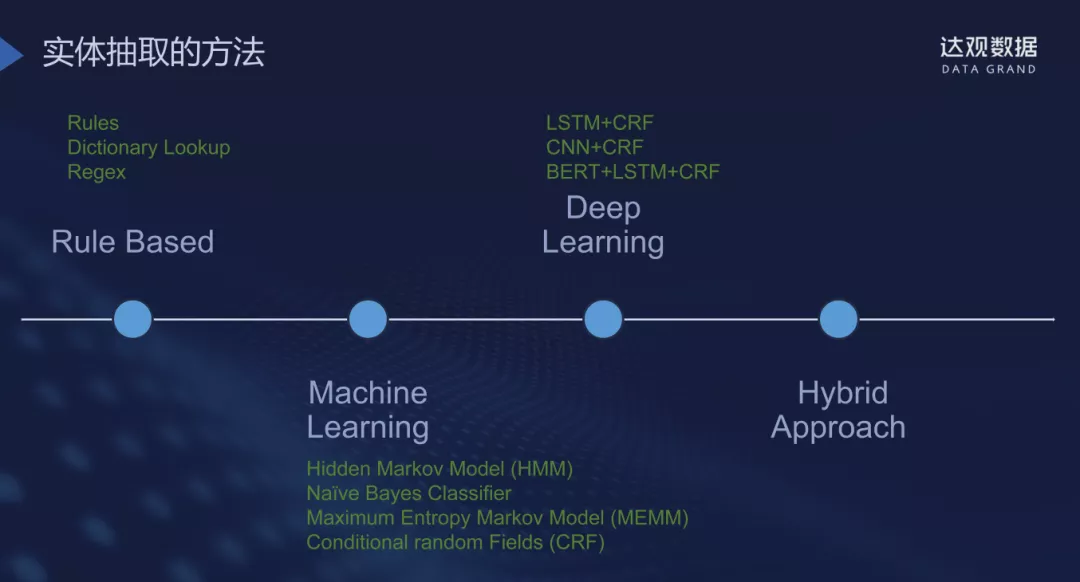
- 基于规则的方法:其优点包括简单,精度高,但是劣势同样明显,低效率,依赖于大量的人工工作,无法泛化,召回率低。
- 序列标注用于实体识别的方法:将信息抽取问题转化为分类问题,经典NLP算法通过采集上下文特征来进行分类,深度学习则通过端到端的自主学习来记录特征,其思路可以广泛运营到各种NLP任务中去。

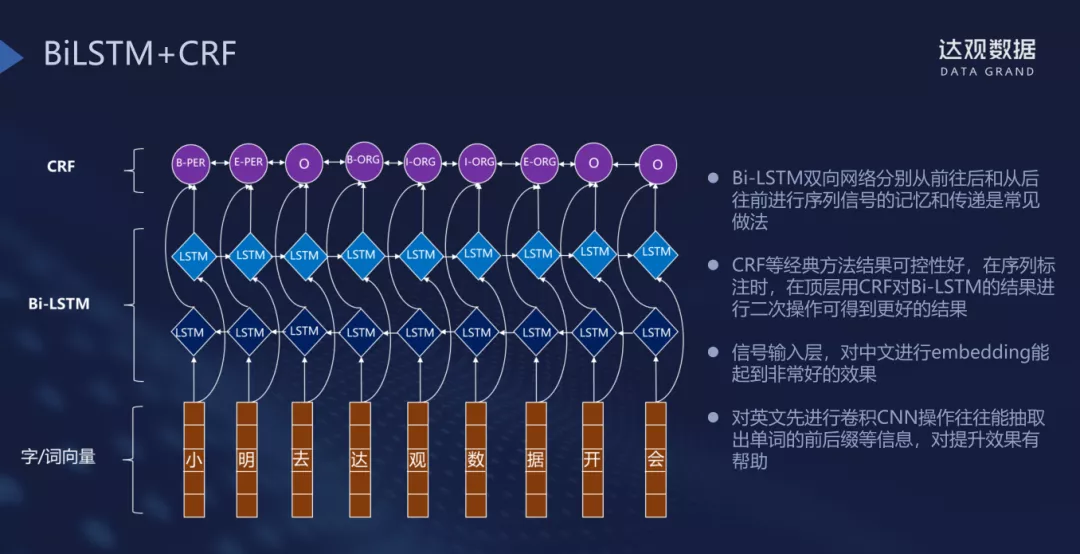
- BiLSTM+CRF:18年之前的主流算法。
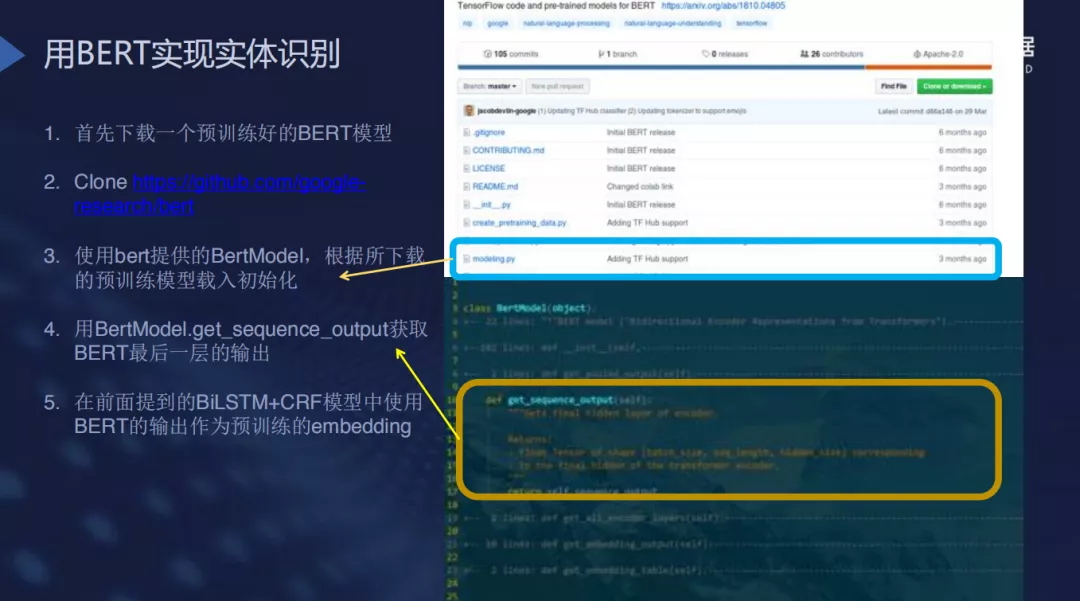
- 基于BERT实现实体识别:这里指的是BERT这一大类预训练模型的使用,包括ALBERT,ERNIE等模型,在此基础上,我们针对领域和任务做一些fine tune,效果会比较显著,通用性也很不错,实现起来也十分容易;BERT+BiLSTM+CRF的方法就是使用预训练模型的finetune以适应NER任务的需求,这是效果比较好且应用广泛。
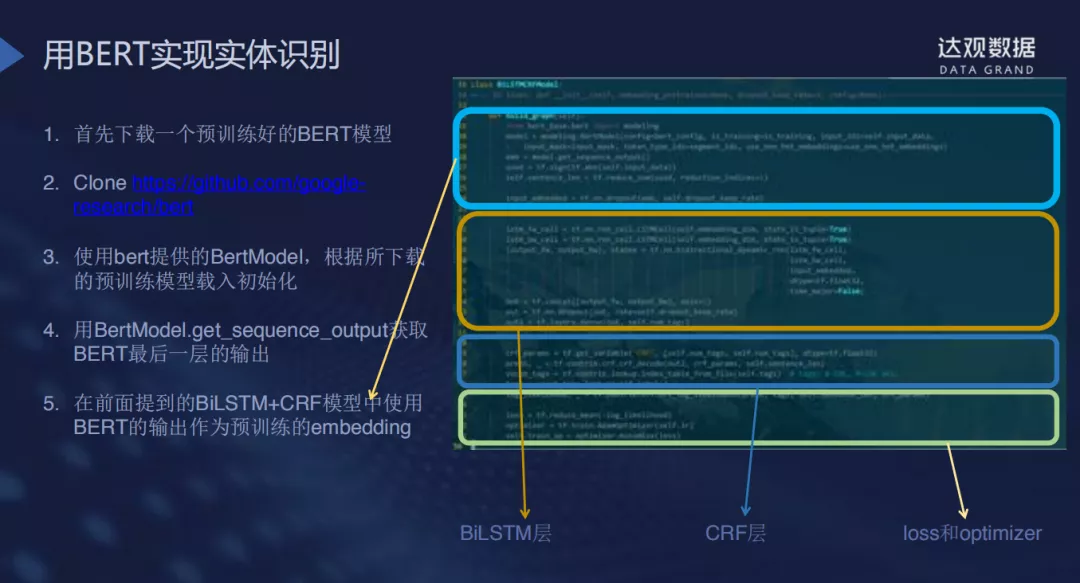
② 关系抽取
关系抽取,是指是从文本中抽取实体对之间的关系,实体可以是预先给定的或者通过实体抽取获得的,从算法角度上说,是把关系识别的问题转化为有监督的分类问题,辅以规则的方法。
方法上有:
-
基于规则的方法:采用手工编写规则,正则表达式或者模板的方法,实现关系抽取。通过简单的规则,即可从大量文本中抽取出非常多的关系,简单有效。需要充分利用实体类型。
-
有监督的机器学习方法
-
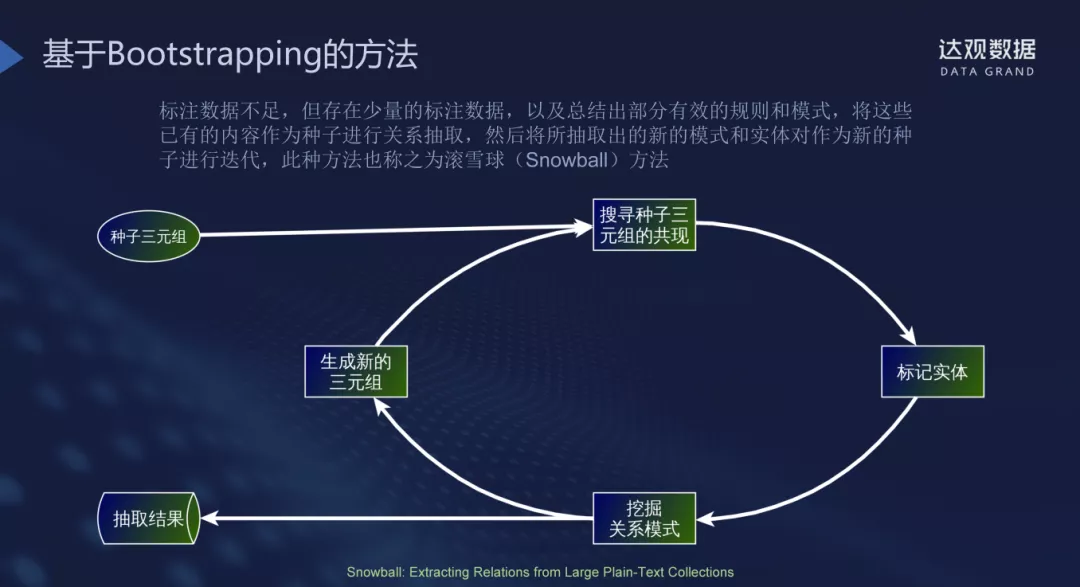
Bootstrapping方法:把规则和工程实践不断进行滚雪球
标注数据不足,但存在少量的标注数据,以及总结出部分有效的规则和模式,将这些已有的内容作为种子进行关系抽取,然后将所抽取出的新模式和实体对作为新的种子进行迭代,此种方法也称之为滚雪球的方法
此方法隐含着一种假设,即已知关系的两个实体仅有一种关系,通过找到这两个实体,就找到了那唯一的关系,这显然是有缺陷的。
-
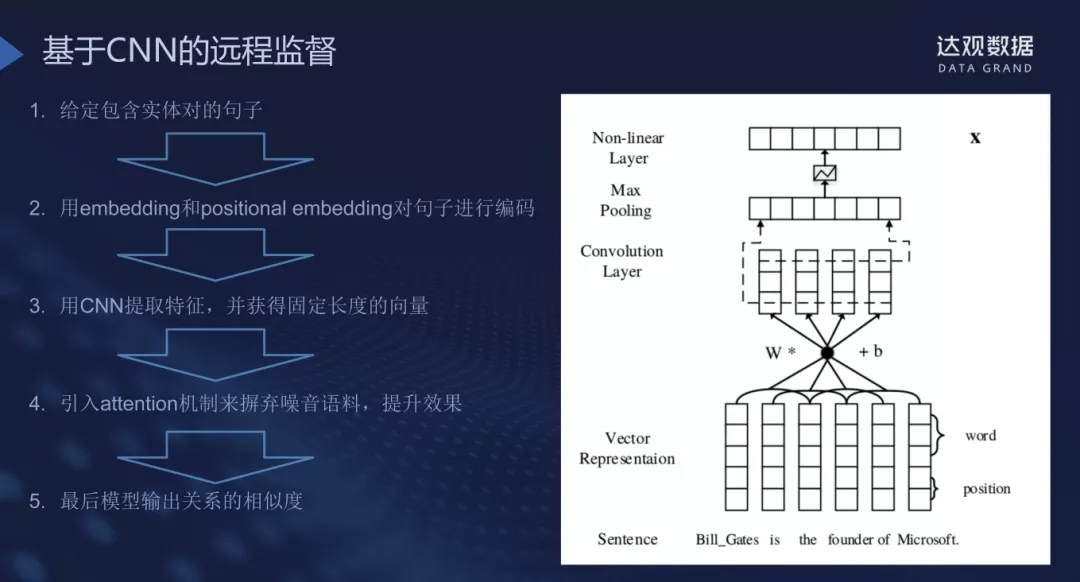
远程监督方法:有监督机器学习+Bootstrapping
用已有的知识图谱代替种子三元组,用来抽取出大量的特征,之后使用有监督的分类器,这就组成远程监督的架构,此方法也是有着和Bootstrapping一样的前提假设,在学术领域应用广泛,例如使用远监督来构建数据集。这里展示基于CNN的远程监督流程:
- 开放域的关系抽取 ( 学术界 ):文本智能处理最大的应用之一就是各类的知识抽取包括实体,关系和属性等的抽取。
上述方案都不会是100%,那么错误怎么办?
- 更高准确率,牺牲召回率
- 多召回,牺牲准确率
- 人工审核
这里展示金融知识图谱的构建的整体流程:
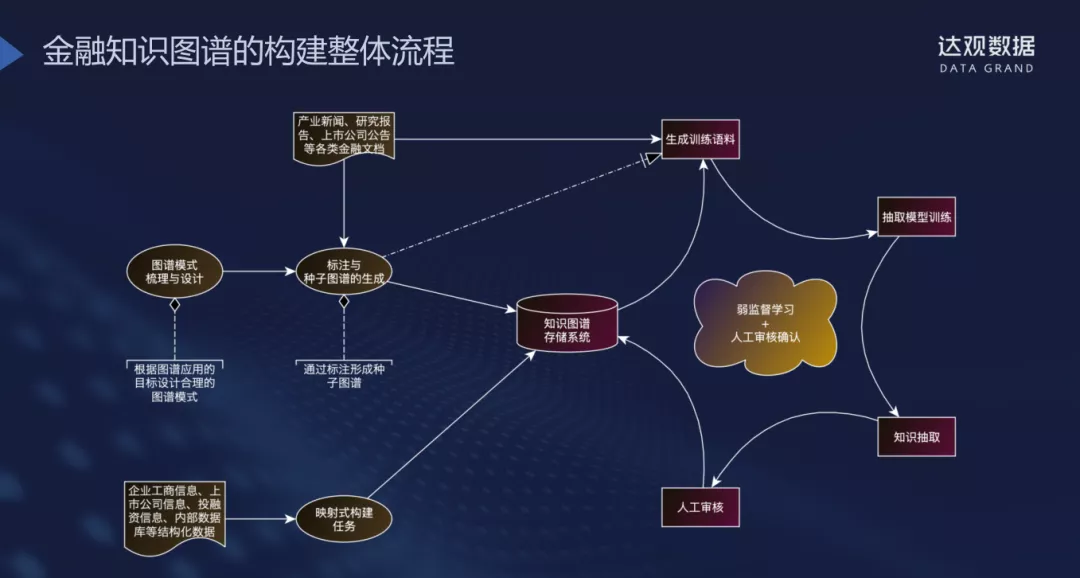
例如,针对企业工商信息,上市公司信息等机构化数据直接使用映射式构建存入知识图谱;抽取式构建推荐使用弱监督学习+人工审核确认的方式来构建图谱;同时,不同的数据源都可以作为构建图谱的原始材料,同一数据源由于业务场景的不同也可以为不同的图谱提供知识来源。
3. 知识融合
由于知识图谱的数据来源多样这就涉及到怎么将结构化数据提取结构和非结构化数据提取结构相融合与合并的过程;另外,对于不同的数据源之间对应相同的知识点的信息也是要进行融合的,既要考虑到语义上的一致,也要考虑到业务上的一致性。
4. 知识存储
需要有相配套的综合的存储方案,需要多图谱管理和平台。知识图谱的存储技术,通常包括大家所熟知的neo4j等图数据库,当数据量较小时,存在mysql等关系数据库里也没问题,但数据量较大时必须要用分布式图数据库存储平台,达观这里以Hbase和JanusGraph为基础平台,融合了ES,Spark,KafKa等一系列技术组合成的混合型存储和计算平台。此外,我们也可以将原始文档储存在HDFS或HBase上,并用ES实现全文检索。
5. 知识应用
这是要与业务相关的,例如各种企业风险控制的判断的应用等等。知识图谱的应用技术,最简单的知识图谱的应用就是语义搜索,推理,推荐系统,问答系统这些通用的技术,可以帮我们辅助理解,比如百度谷歌将知识图谱的应用结果反馈显示到我们搜索的结果中。专业领域中知识图谱也可以应用到问答检索中,让我们更便捷的获取信息。基于知识图谱,我们还可以做一些更复杂的操作,实时报表应用,比如我们构建海关信息的知识图谱,将进出口商提交的信息自动生成海关报表,提交到海关平台上。辅助决策模型也是知识图谱的一大应用,我们利用知识图谱将各种标准文件结构化,辅助决策。建立产业链图谱,基于此图谱,我们可以对某种行为或者实体做风险预测等工作。
03 金融知识图谱的应用实践
1. 基于金融知识图谱的金融资讯智能标签

构建金融领域知识图谱,对每天实时发生的大量金融资讯,基于咨询内容在图谱中关联的相关知识,生成资讯的多维智能标签。对于一段金融文本,由于已有各种金融领域知识图谱,包括产业链图谱,股权图谱,就可以对资讯的标签补充更为丰富信息内容,这些提取的标签可以有很多用途,例如对标签进行检索,另外可以为推荐系统提供有价值的标签。
2. 基于知识图谱的推荐和撮合
知识产权图谱,可以帮助用户从数以亿计的知识产权数据中准确全面的获取到有价值得到情报及其关联信息,具体包括,根据用户画像智能推荐知识产权,知识产权可视化检索和查看,以及智能问答知识产权机器人。
3. 政策图谱
帮助金融机构理解各级政府关于金融的各种各样的政策。
4. 高管潜在投资关系挖掘
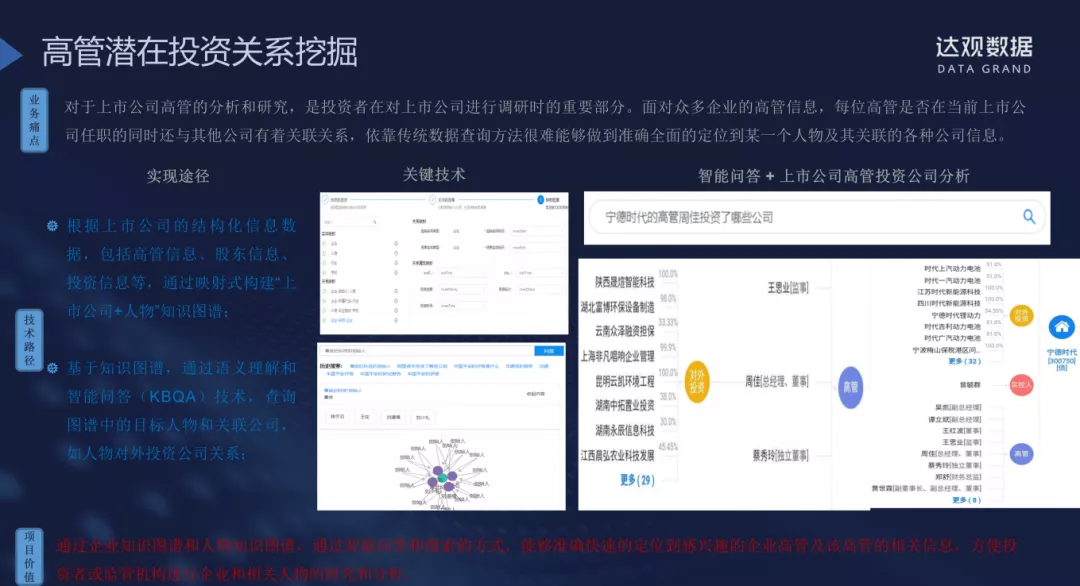
对于上市公司高管的分析和研究,是投资者在对上市公司进行调研时的重要部分。面对众多企业的高管信息,每位高管是否在当前上市公司任职的同时还与其他公司有着关联关系,依靠传统数据查询方法很难做到准确全面的定位到某一个人物机器关联的各种公司信息。
作者介绍
王文广,达观数据副总裁,担任达观数据自然语言处理、知识图谱和OCR等领域的AI技术研发总负责人。浙大大学计算机应用技术硕士,中国计算机学会(CCF)会员,中国人工智能学会(CAAI)会员,拥有OCR、知识图谱、NLP等领域的7项国家发明专利,译著有人工智能教材《深度学习和神经网络》(《智能Web算法》第六章),发表有《基于混合深度神经网络模型的司法文书智能化处理》、《基于知识图谱的通用知识问答系统:体系与方法》、《新用户个性化推荐方法研究》、《Context-aware Ensemble of Multifaceted Factorization Models》等论文,在系统架构设计、CV、NLP和知识图谱等领域有十多年工作经验,在达观数据从零开始打造了渊识OCR和渊海知识图谱两款产品,曾摘取ACM KDD CUP、EMI Hackathon、“中国法研杯”法律智能竞赛等人工智能算法竞赛荣誉。
曾受中国人工智能学会邀请去AIIA人工智能开发者大会分享知识图谱应用实践经验,在CCKS(全国知识图谱与语义计算大会)2019上分享知识图谱在金融领域的应用,并组织了CCKS2020自动化构建金融领域知识图谱的技术评测任务,在GIAC(全球互联网架构大会)2020上担任《人工智能产品落地》专题出品人并分享《知识图谱赋能智能制造》。曾担任金融人工智能公司Kavout.com首席架构师,将NLP、深度学习等技术应用于金融投研和量化分析上,成果获得美国大型基金的认可。此前担任香港易时尚集团CTO,将互联网技术、大数据技术和人工智能技术用于奢侈品跨境电商领域的运营管理上。此前在百
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%BE%BE%E8%A7%82%E6%95%B0%E6%8D%AE%E9%87%91%E8%9E%8D%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E7%9A%84%E6%9E%84%E5%BB%BA%E4%B8%8E%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


