阿里妈妈大规模在线分层实验实践
作者: 敖丙
-
少衡
-
见独
-
宏真
2016 年 9 月 19 日
话题:阿里巴巴语言 & 开发架构阿里云
引言
在线服务系统的 AB-test 方法有很多种。搭建多个可服务集群,从物理上对流量进行隔离是比较常见的一种方式。这种方式应用于大型复杂的在线服务系统时,存在部署比较慢的问题。这种方式的典型架构如下图所示。
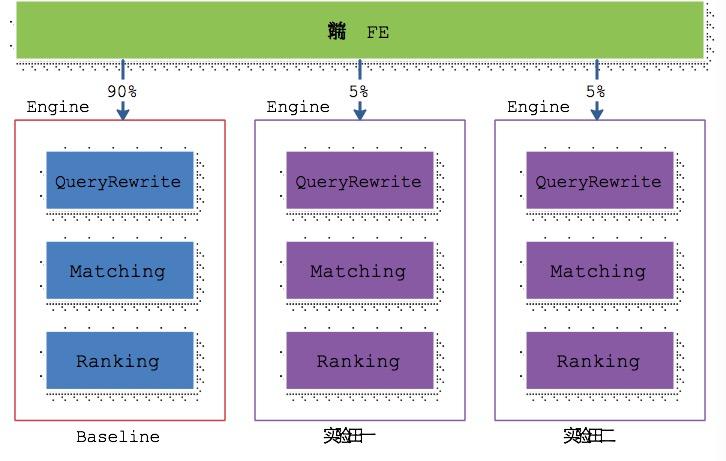
QueryRewrite:改写用户搜索词以期望得到更好的查询结果。
Matching:根据用户搜索词,召回最符合用户意图的那些推广。
Ranking:确定推广的输出顺序,需要兼顾用户体验和搜索平台的收益。
这种架构有两个优点。
-
代码分为了基线和实验代码,实验代码对业务的侵入性比较小。
-
实验田的流量和基线的流量从物理上严格分开,严格控制了实验对业务的影响。
这种架构的缺点同样也很明显,主要有如下几点。
-
增加了运维的复杂性,运维需要维护多套环境。
-
每套环境接入的流量都是由单个实验田集群的物理机器数量固定上限的,不能灵活地验证流量扩大的情景。这会导致对小流量实验效果很好的算法,在基线上有可能无法收到好的效果。
-
实验的流量有限,导致实验的数量变少,而增大实验流量又会影响业务基线。
我们在总结现有的各种实验机制的基础上,结合阿里妈妈的应用场景实践出了一种高效便捷、能充分利用流量、并行多个实验的方法。该方法也能支持系统的灰度发布,有如下几个优点。
-
提高并发:实现多实验并行迭代,加快迭代的速度。
-
公平对比:做到实验效果公平、准确对比评估,即时停止不符预期的实验;随时扩大效果良好的实验的流量。
-
降低门槛:提供实验管理工具,除算法以外,其他有实验需求的如产品、运营、前端等都可以独立申请发布实验。
-
建立闭环:从想法、实验前线下评估、发布实验、实验进行、实验评估、最后实验总结,确保实验结果的质量。
系统架构和模块说明
一. 系统整体架构
架构整体可以划分为三个系统,如下图所示。
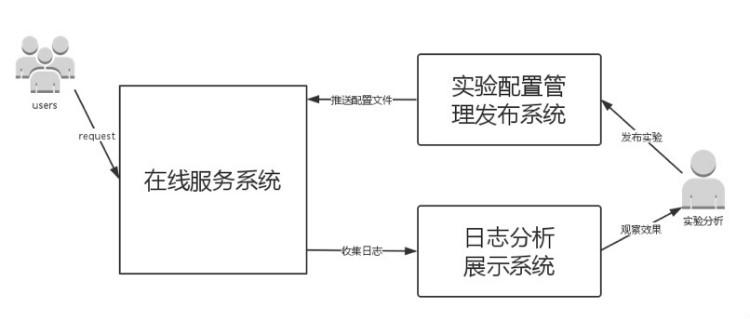
接下来对各个子系统进行详细的介绍。
1. 实验配置管理发布系统
此系统给用户提供便捷的 UI 操作界面,方便用户添加实验配置流量,然后动态地在线发布。为了弥补各种不可预期的错误,该系统支持历史版本的快速回滚。
2. 在线服务系统
根据用户的实验配置文件,进行分流处理,给各个实验分配相应的流量。实验分流模块以库的方式接入在线服务系统。在系统的流量入口处调用此分流库。后续会详细介绍分流的原理和作系统进行实验的方法。
3. 日志分析展示系统
根据在线服务系统记录的日志,统计出各个实验的效果,供系统分析师或实验观察者使用。然后根据实验的效果,使用实验管理系统去调整各个实验流量的占比。
二. 各模块介绍
1. 实验配置管理发布系统
(1) 实验场景。广告系统中,实验是针对某一批广告位或者特定页面进行的。针对 PID(标记广告的位置信息)或页面来对流量进行分类就成了一个强需求。将这样一批广告位定义为一个实验场景。Web 操作页面上需要提供配置实验场景的 UI 界面,用户可以在这个界面上新建一个场景,指定符合某些 PID 要求或者 URL 要求的请求进入相应的实验场景,UI 界面如下所示。
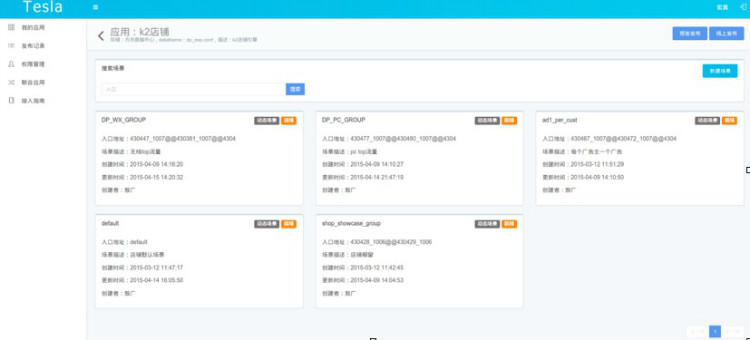
在此页面上,用户可以方便地添加一个新场景,并指定该场景的入口 PID(入口 PID 可以设定多个)。
(2) 实验分层和流量切分。进入某个实验场景后,通过分多层来达到流量的复用。每一层的流量均是流入这个场景流量的一个全集。每一层的流量可以按用户指定的切分标记进行分桶切流。
一层可以看成是多个实验的集合,实验分层的原则如下:
-
相互之间没有影响的实验可以分到不同层。
-
相互之间有影响的实验分到同一层。
由于互不影响的实验被分配到了不同的层,从而达到复用流量的目的。相互之间有影响的实验分到同一层,则保证了同一请求不会去作两个互斥的实验。
2. 在线服务系统
Tesla 以 lib 库的方式接入在线服务系统。没有做成一个服务的形式,主要考虑到接入简单,不增加系统复杂性和运维的工作量。
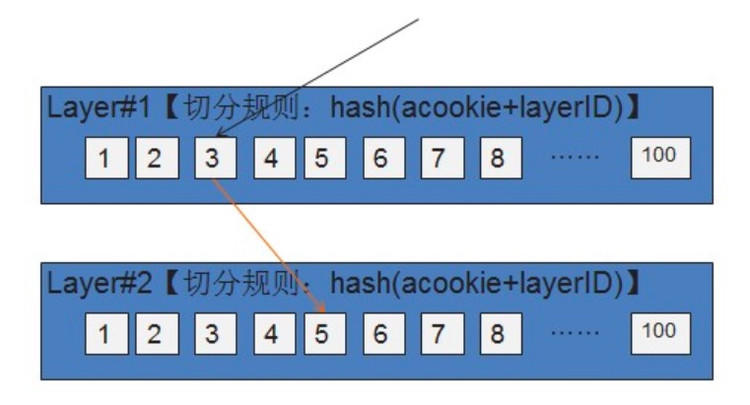
(1) 分流规则。用户可以在各层指定不同的切分标记进行流量切分。系统会根据用户指定的切分标记值来计算 hash 值。计算出的 hash 值对 100 取模再加 1 可以得到分桶号,每个实验占了指定范围的桶号,这样便可以知道该次请求应当进行哪个实验。这里需要注意的是,选取一个偏差较小的 hash 函数,我们在数 10 种 hash 函数中选取了一个最优的 hash 函数,将偏差控制在实验效果统计可以忽略的范围。
假如每一层均使用这样的切分规则,不同层做实验的用户选用相同切分规则时,请求始终落入相同的桶。由于不同层的实验之间毫无关系,为了保证实验效果绝对可信,需要做到不同层的流量正交。为了达到这个目的,引入了 layerID 来作为离散因子。由于每一层 layerID 是固定的,也能保证同一请求两次访问能落到同一个实验,从而不会造成同一用户多次访问,返回结果不一致的困惑。示意图如下。
(2) 实验参数的处理。之前讲述了如何决定一次请求去作哪些实验。这一部分介绍一个具体实验的构成元素,以及系统如何执行实验。一个实验本质上是一堆抽象参数集合。每个请求被分配某个实验之后,系统便会将该实验的抽象参数集合,作为请求的一部分传递至在线服务系统的各个处理模块。
对于系统而言,可以根据请求携带的参数值来决定作哪个实验。这里需要注意的是,为了保证系统的健壮性,如果一个请求缺少了某个实验参数的数值,系统应该设置一个抄底的值。
(3) 实验发布。当某个实验效果非常好时,可以动态调整该实验的流量占比,从而迅速得到收益,并且在大流量上验证该实验的有效性。一旦确认该实验效果非常良好,便可以在全流量上线。这时需要删除该实验,把该实验的参数作用于全部的流量。这是通过在每个场景中设置一个初始化层来实现的。
每个场景的第一层设定为初始化层,该层会初始化需要作用于全流量的所有参数。一旦某个实验需要在全流量上线,便可以删除该实验,将该实验的参数移到初始化层去。这样便可以避免实验数量不断膨胀、层数不断增加的问题,同时也达到了在线全流量发布某个实验的目的。
3. 日志分析展示系统
实验效果统计无疑是系统中非常重要的一个环节。对于简单的 AB-test(物理集群隔离的实验方法),实验数据的统计相对比较容易。对于这种复用流量,在一次请求上作多个实验的方式,统计实验效果相对要复杂一些。这里介绍一种相对简单的实验统计分析方法。每个实验均有一个唯一的实验 ID。对于一次请求,调用分流库后,在返回所有实验参数的同时,会返回一个字符串,该字符串将所有作用于该次请求的实验 ID 以下划线连接起来,例如 Exp1_Exp3_Exp6_Exp8_Exp9。请求同样会把这个字符串携带传输至系统的各个模块,在记录系统日志时将该字符串一并记录下来。
日志分析处理模块以“_”为分割符把该字符串进行分割,得到多个实验 ID,利用 storm 等流式实时处理系统去实时统计分析各个实验的效果,再利用实验发布系统动态调整流量,从而获得了文中提出的一种良性的闭环反馈。
应用实例
下面以一个简单的广告引擎系统接入上述平台的例子,具体说明上述的方法。该系统共有两个实验点(Query Rewrite 和 Rank),因此可以分为两层实验。下面以一次请求的处理流程来简单说明该引擎系统的工作原理。
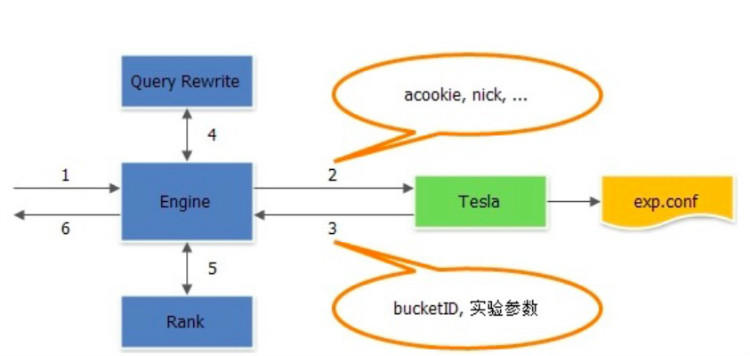
如上图所示,Tesla 以 lib 库的形式接入引擎中。引擎接收到请求后,调用 Tesla 的 lib 库获取对应的实验参数信息,然后依次将实验信息透传给 Query Rewrite 和 Rank。在 Query Rewrite 和 Rank 模块中各取所需实验参数进行相应的实验,最后将 bucketID 记录到投放日志对应的字段中,用于实验效果统计用。
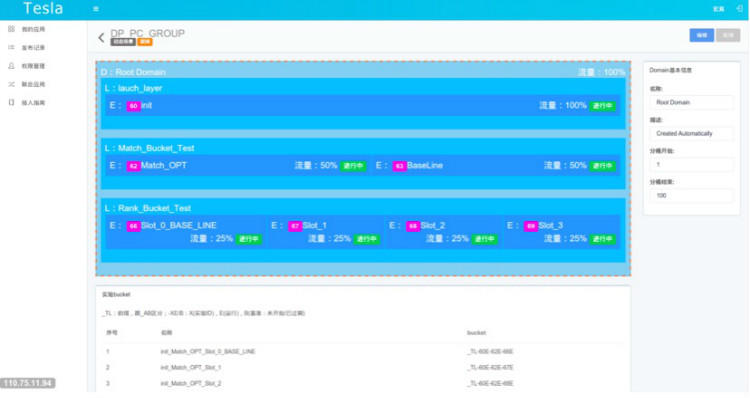
下图是整个实验的配置文件的示意图。
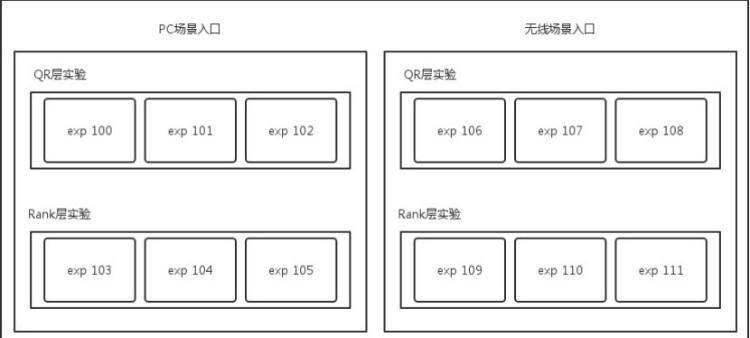
整个引擎的实验根据需要分为了 PC 和无线两种场景,分别进行策略优化和调整。根据算法实验的需要,在两种场景下均分为了两层(QR 和 Rank 层,QR 是 Query Rewrite)。每一层中均包含了三个实验。每个实验均是一些实验参数的集合,例如,exp 100 包含的参数有 qr_plan=5,qr_weight=3。Exp 103 包含的参数为 rank_level=2,rank_stragety=9。
使用这个配置文件,一个用户请求发过来之后,如果根据 acookie 分流计算得出此请求恰好落入 PC 场景的 exp 100 和 exp 103 这两个实验,则返回的 bucketID 应当为 100_103,参数集合为 qr_plan=5,qr_weight=3,rank_level=2,rank_stragety=9。BucketID 可以记录在日志中,后续进行日志统计和分析使用。日志统计分析时按下划线把 BucketID 切割开,然后用 Storm 进行实时统计各个实验的情况,也可以用 Hadoop 进行离线的日志分析处理。对于在线引擎,各个实验点根据实验参数的值决定使用哪种策略和模型参数。
总结
本文参考现有的关于在线服务系统实验方法论文基础上,结合广告系统的特点,实践出了一套有效的可以复用流量支持并行实验的方法。该方法也可以解决灰度发布的问题。该套系统极大提高阿里妈妈所有的业务线应用的实验效率。
未来工作
未来,分层实验平台计划将实验配置系统、实时实验结果分析和离线日志分析系统进行更好地整合,给实验用户带来一站式服务的良好体验,使得配置实验、发布生效、实时观察实验结果在几分钟之内即可完成。同时也在探索将这套系统平台开发给淘宝商家,商家便可以使用这套系统清楚看到两种不同文案设计带来的点击率以及成交率的差别,从而更好地设计自己店面图片和文字。
致谢
Tesla 平台是多个业务线团队通力合作、共同努力的成果。Tesla 平台在开发和应用的过程中得到了多位同事的帮助和支持,包括但不限于如下同事均对 Tesla 平台作出了巨大的贡献。
敖丙参与了 Tesla 平台首版开发,并将其应用到了淘客业务线。
宏真开发了 Tesla 平台配置文件管理系统极大的优化了用户体验,中玄开发了 Java 和 Js 客户端的代码,极大完善了 Tesla 平台的易用性。
凌丘,东垣,沐潇,广传,墨方,怀人,兵乙,敖广,大雨,沥泉,龙宿,萧亮,萧明,福昌,存希,见深,笑楼,韩萱,婉灵,姸芳等人在阿里妈妈各个业务线接入 Tesla 平台的过程付出了极大努力和工作。
钩吻,�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%98%BF%E9%87%8C%E5%A6%88%E5%A6%88%E5%A4%A7%E8%A7%84%E6%A8%A1%E5%9C%A8%E7%BA%BF%E5%88%86%E5%B1%82%E5%AE%9E%E9%AA%8C%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


