阿里是如何应对超大规模集群资源管理挑战的
文章作者:丁海洋(临石)
本篇文章来自 微信公众号阿里系统软件技术: 独家解密:阿里是如何应对超大规模集群资源管理挑战的?
欢迎原链接转发,转载请前往
的主页获取信息,盗版必究。
敬请关注和扩散本专栏及同名公众号,会邀请 全球知名学者 陆续发布运筹学、人工智能中优化理论等相关干货、 知乎Live 及行业动态: 『运筹OR帷幄』大数据人工智能时代的运筹学
More Applications in Less Machines
你办得到吗?

互联网应用和现代数据中心
云计算已经火了很多年了,早已开始惠及我们每一个人。今天火热的大数据、机器学习、人工智能、以及我们看到的像淘宝、天猫、优酷等大规模的互联网应用都是运行在云上的。而支撑云的,是大型云计算服务商部署在世界各地的多个数据中心,每个数据中心都有大量的物理服务器。为了有效的管理这些服务器,我们需要集群资源管理系统(Cluster Resource Management System),后面简称资源管理系统。资源管理系统的价值,用一句话说,是Datacenter as a Computer, 像管理和使用一个台电脑一样简单地管理和使用数据中心。
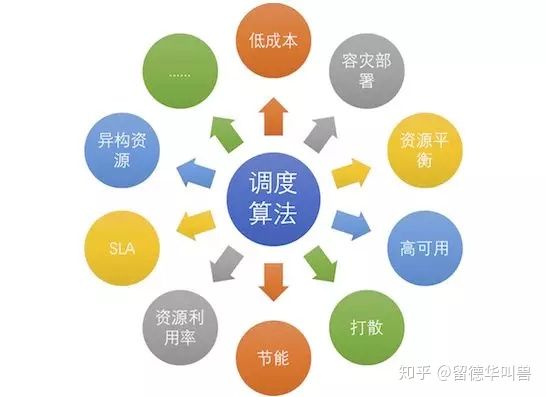
资源管理系统作为将数据中心资源向上抽象的关键一层,需要全面的能力。从保障应用的稳定性、性能(保证SLA,Service Level Agreement)到全面提高数据中心运行的效率,节约能源等等,今天这篇文章,我们重点讲一讲调度算法在资源管理中的作用。
调度算法的价值
调度算法在是整个资源管理系统中的一个重要组成部分,简单的说,调度算法的作用是决定一个计算任务需要放在集群中的哪台机器上面。
在容器化的今天,集群中调度器的调度对象很可能是一个容器实例,Docker或者是PouchContainer。为容器选择合适的宿主机显然是一个值得考虑的问题,这里我们说一说调度算法能够帮助我们实现的价值,这些价值可以从单个容器、到应用、再到数据中心,这三个不同的层面展示出来。
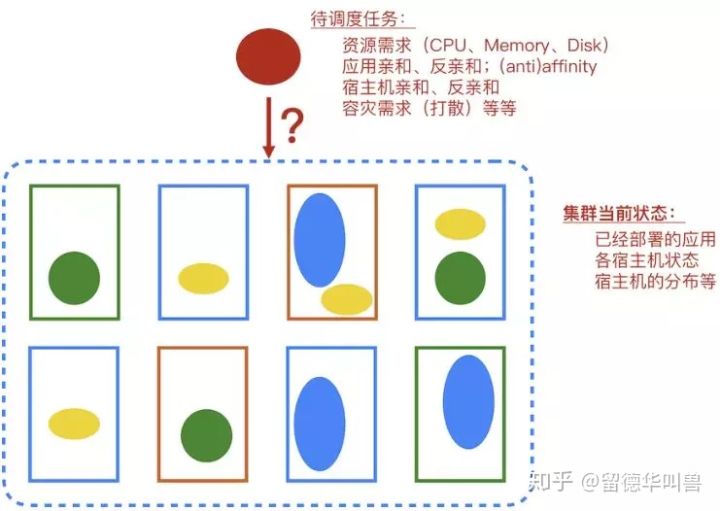
- 单个容器层面
满足容器运行的资源需求:确保每个容器在运行的时候拥有足够的资源,CPU、Memory、Disk、网络带宽等等。除了用数量衡量的资源,很多容器在运行的时候还需要一些特殊的资源,例如特定的操作系统版本、特定的硬件等等。
让容器在更“舒适”的环境下运行:容器之间可能发生资源的抢占现象,例如两个对Memory消耗很大的容器部署在同一台机器上,很容易造成Memory资源的吃紧。虽然我们可以通过容器和内核提供的资源隔离技术降低这种影响,但是最好的办法还是在一开始不让这种“容易吵架的人做邻居”。
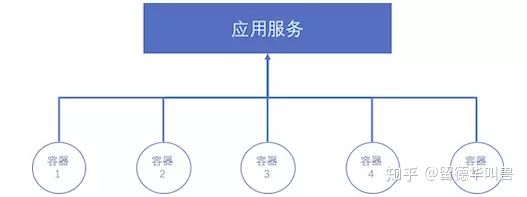
2. 应用层面
每个应用在提供服务的时候往往是多个容器实例同时支持的,调度器需要考虑应用的需求。
应用的高可用:分布式环境下宿主机失败或者单个容器的失败是正常现象,因此我们要保证每个应用同时有多个实例在运行,这样即使有一个实例挂了,整个应用不会受很大影响。
应用的容灾:容灾其实也经常和高可用放在一起,如果一个应用有多个应用实例,但是都部署在一个机房,如果机房断电,那么应用也就不能提供服务了,没有高可用了。解决这个问题需要的容灾部署,也就不同维度的打散。调度算法需要尽量让同一个应用的不同实例部署在不同的宿主机、不同的机架、不同的机房、不同的数据中心、不同的城市、甚至是不同的国家;这种容灾甚至可以体现在更高一层,几个重要应用之间的所有实例,也要尽量打散。
很多应用因为其提供服务特性往往需要调度器做更多的事情,例如:按照一定的顺序调度实例、将计算任务调度到离数据最近的地方,等等,这里不一一列举了。
3. 数据中心层面
降低数据中心的成本:合理的调度能够节省数据中心大量的成本,如果用装箱问题来表示,就是用更少的服务器装下了更多的应用。服务器数目的减少不仅仅是采购成本的下降,服务器的占地、用电、冷却等都是一笔很大的开销,合理的资源调度能够为数据中心节省大量成本。
除了以上这些内容,实际中调度算法要考虑的内容还有很多,例如公平性的问题、应用间的干扰问题、不同应用间资源共享(互相借用)的问题、单机资源的调配问题(超线程、内存带框等)等等。例如,实际管理阿里巴巴集团在线服的资源管理系统Sigma的调度规则,就十分复杂。
为了让更多的学生、研究者能够接触到我们的调度问题,并鼓励他们与我们一起应对挑战,我们举办了“阿里巴巴全球调度算法挑战赛”。这个算法大赛是怎么回事儿呢?让我们介绍一下。
首届阿里全球调度算法大赛
大家可以想象下,阿里巴巴拥有如此大规模的数据中心,1%的资源利用率的提升都将为阿里巴巴自身和整个社会带来可观的能源节约让用户享受更加绿色的计算资源。所以最近我们发起了首届阿里全球调度算法大赛,初赛赛题来自我们生产环境中的一个真实的场景,简化了一些约束条件,方便一些对这个领域刚刚开始了解的同学找到一个求解的方法,但是即使对于在该领域有一定经验的同学、工程师、研究者们,我们也相信这份题目能够让你花费一些精力才能得到一个优化的解。
在这次算法大赛中,我们提供了大约6K个宿主机,68K个实例(其中一部分已经部署,一部分尚未部署),约束类型主要有3类:资源约束、重要应用高可用约束和应用间反亲和约束。
- 资源约束
资源约束是最容易理解的,每个属于不同应用的实例都有不同的计算资源要求。我们本次比赛的一个重要特点是,CPU和Mem的数量约束是以时间曲线的形式给出的。每个应用的对应资源需求的时间曲线是我们通过对该应用下多个实例(一个应用由很多实例组成)的24小时的历史数据进行观察并整理得到的需求曲线,描述了每个应用下面的实例在一天当中每个采样点需要的对应资源的数量。映射的场景是我们假定各个应用的实例的资源需求的有着24小时的变化周期(即98个点的变化周期),第二天、第三天甚至再往后,应用的实例还是按照这个需求长时间存在。注意,这里提到的应用是长应用(Long Running Service),没有特殊原因是不会下线的(例如淘宝网),这种长应用与一些分布式计算中的有限持续时间计算任务是不一样。
这样的时间曲线比普通的标量规定的资源需求具有更多的优化空间,但也带来了更多的复杂度。下面这个图是两个应用在不同时间点的资源需求对于满�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%98%BF%E9%87%8C%E6%98%AF%E5%A6%82%E4%BD%95%E5%BA%94%E5%AF%B9%E8%B6%85%E5%A4%A7%E8%A7%84%E6%A8%A1%E9%9B%86%E7%BE%A4%E8%B5%84%E6%BA%90%E7%AE%A1%E7%90%86%E6%8C%91%E6%88%98%E7%9A%84/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


