风控建模流程以京东群体感知项目为例
导读:本次分享将以群体风险感知为例,从需求挖掘、数据挖掘、建模再到最终的模型部署应用,详细介绍全流程的风控建模方案。下面将从这几个方面出发,详细的讲解具体流程中的概念,同时会给出每个流程中的 目标、实现方法、交付物,让同学们在具体实践的时候有目标,有方法。
▌业务需求挖掘
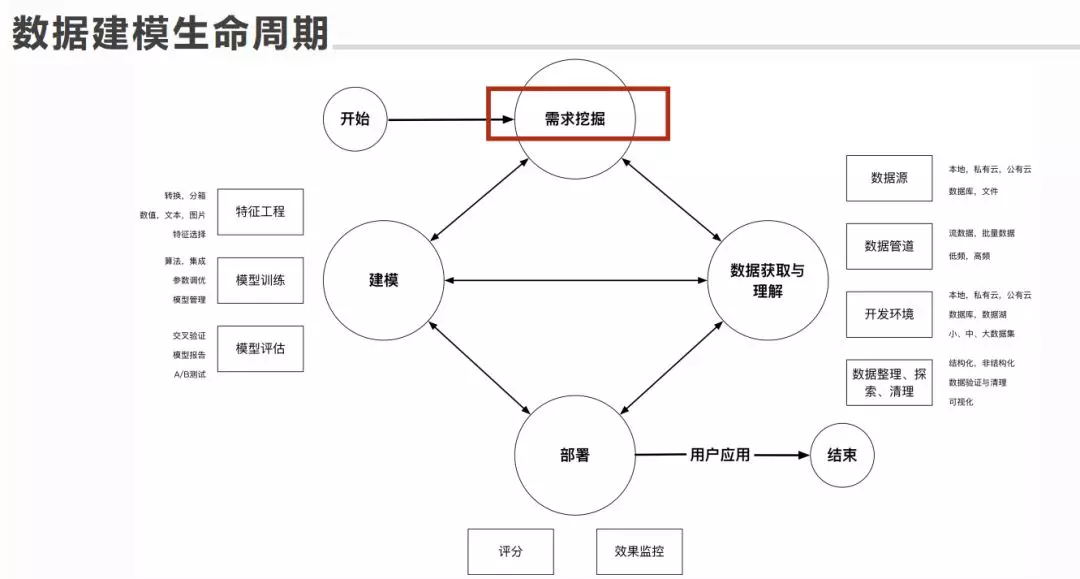
任何项目的起源,都是从需求挖掘开始的,不可能一蹴而就,会经过多次循环。这体现了作为数据分析师和建模人员的功力,可能有的业务要 A,你就给他A,而没有往下深入几个层次进行考虑,** 因为有的时候,可能业务的需求自己也没有想清楚需要的是什么,这和传统的软件工程是一样的,所以宁可在这里多花一点时间,也好过到后面踩坑之后,在回来重新挖掘需求。**
① 目标
-
找出关键变量(与判断项目成功与否的指标相关,最好的方法就是定义几个场景,比如做风控,是坏账率下降,还是机注量下降了,或者其他指标),并把关键变量作为模型目标
-
识别业务已经使用或者需要获取的数据源
② 实现方法
-
定义目标,与用户以及其他利益相关方一起理解,识别业务问题,并构建多个问题(这些问题要能定义出业务目标同时也能作为建模的目标)
-
识别数据源:基于问题找出能帮助回答的数据源,越多越好
**③ ** 交付物
-
项目需求文档(比如 A、B、C 三个场景,机注量下降2%,或者坏账率下降1%等等)
-
数据源梳理,有几张宽表,有几个数据源,都需要弄清楚
④ 业务方的诉求与抱怨

业务方的诉求与抱怨,抽象来说就是多、快、准、省:
-
多: 在风控反欺诈领域,对于抓黑产,召回率越高越好。
-
快: 实时反应,不能等到 T+1 时间过去了才反应,比如拼多多的风控事件,不仅仅需要做到实时,最好做到事前,并且可以发出告警,提示哪个环节被攻击。
-
准: 准确率(auc,roc 曲线)大家都比较熟悉,尤其对于金融风控,准确率要求更高。
-
省: 省心,傻瓜式操作,不需要告诉具体指标的含义。对于模型,只需提供给业务方0或1即可。
所以,对于业务的诉求和抱怨,就在这四个字之中,当我们接到群体风险感知这个 Case 时,我们首先需要做的就是:定义群体风险感知(为什么叫群体而不叫团伙?),明确业务场景,找出业务痛点。
两个场景:
-
一堆人来买我的货,我不会认为他们是坏的人;
-
iphone 新品首发,黄牛带货,对我的品牌或者收益造成损失,这时,我们需要进行控制打压。
所以我们交付的东西,需要是中性的, 把模****型看作一把刀,具体刀用来做什么,由业务来决定。
⑤ 需求分析
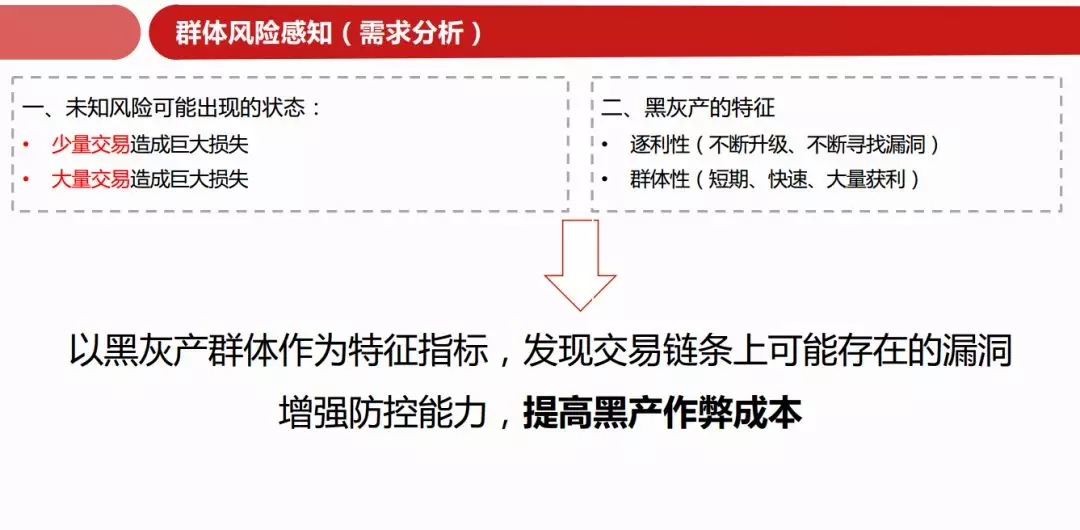
风险未知可能出现的状态:
-
少量交易造成巨大损失(例如:网络舆情事件,诈骗,网络攻击等)
-
大量交易造成巨大损失(例如:拼多多事件,上万个账号薅优惠券,然后快速的变现)
黑灰产的主要特征:
-
**逐利性(**不断升级,不断寻找漏洞):由于他们是在为自己牟利,没有 kpi 没有996,甚至一天可以更新迭代4个版本,他们自己干的很起劲。
-
群体性(短期,快速,大量获利)目前成熟的电商,基本上不会让一个账号短时间内下很多单了,现在的黑产为了达到短期快速大量获利,一般使用群控手机,即用软件控制几百台手机,尤其在6·18和11·11时,给我们造成的压力也是比较大的。
项目的定义:
以黑灰产群体作为特征指标,发现交易链条上可能存在的漏洞增强防控能力,提高黑产成本(黑产本质上是生意,风控人员不是为了消灭黑产,是为了让他们这门生意做不下去,明面上是技术的对抗,实际上 是成本的对抗)。
⑥ 项目目标
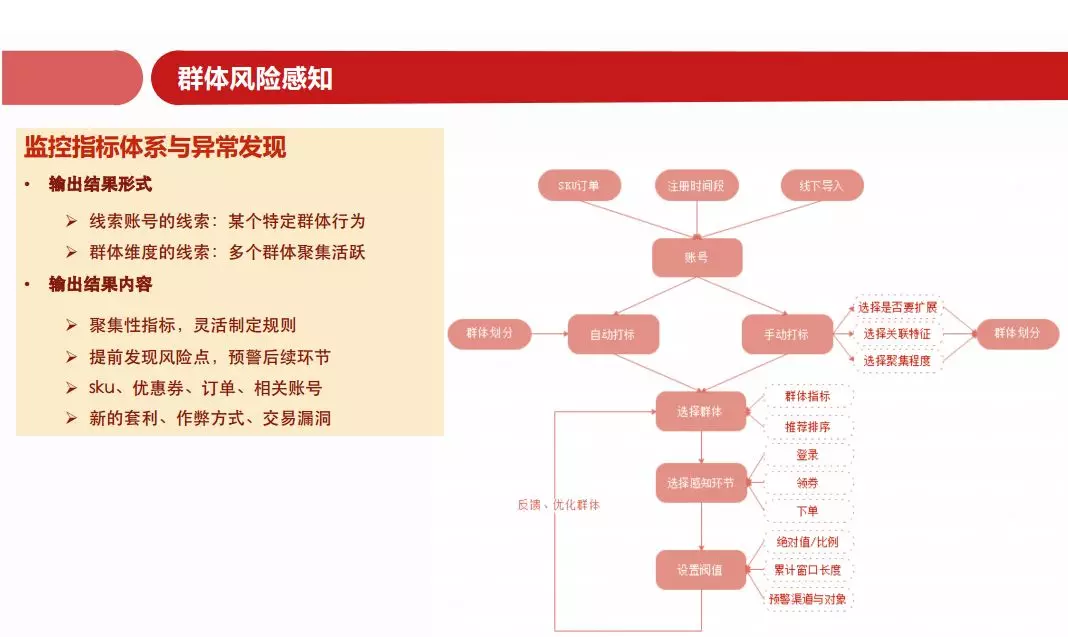
监控指标体系与异常发现(输出结果形式):
-
线索账号的线索: 某个特定群体的行为(观察某个小白鼠在迷宫里的行为特征)
-
群体维度线索: 多个群体聚集情况(观察一群小白鼠在迷宫里的群体共同行为)
监控指标体系与异常发现(输出结果内容):
-
聚集性指标,灵活制定规则(告诉业务方,商品、库存、优惠劵是不是被攻击了)
-
提前发现风险点,预警后续环节(黑产领券之后,会不会有什么大动作,需要提前预警)
-
SKU,优惠券,订单,相关账号(我们有一个评分,一旦被群体模型识别,就打一个黑标签,让风险值变高)
-
新的套利,作弊方式,交易漏洞(将黑产规律输出给分析师,分析黑产的作弊方式以及交易环节的漏洞)
▌数据获取与理解
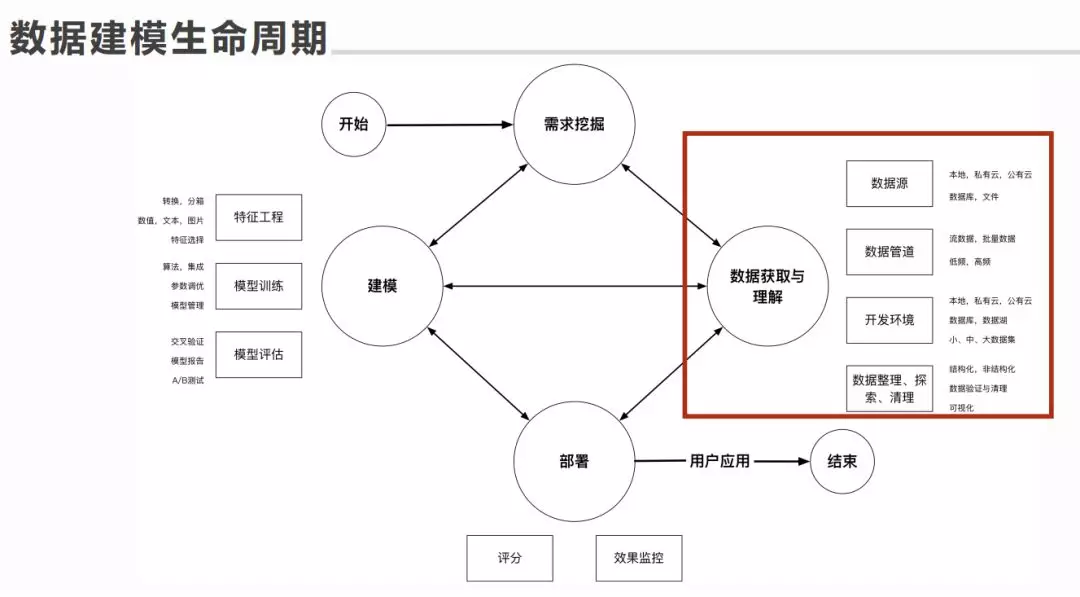
数据获取与理解,主要分四个部分:数据源(在哪分布,可能需要做数据同步,也有可能需要买一些服务,定期做 API 的推送,需要把数据源定义清楚),数据管道(如何做清洗、加工,如何接入到模型中),开发环境(根据数据规模,选择开发环境),数据整理、探索、清理:结构化、非结构化,数据验证与清理,可视化等等。
① 目标\\\**
-
产出一个干净、高质量的数据集,充分的理解数据集和项目目标变量的关系
-
把数据集放置在一个适合开发环境以便进行后续建模
-
开发数据管道的解决方案,定期对数据进行刷新
② 实现方法
-
将数据导入目标分析环境
-
研究数据以确定数据质量是否足以回答项目要解决的问题(PS:前段时间比较火的生物探针技术,可以获取一些黑灰产的特征,但这项技术落地的时候,回收的数据缺失率很高,很难得到应用)
-
设置数据管道来抽取新的数据或者定期刷新数据
③ 交付物
-
数据质量报告
-
数据管道架构
-
可行性评估
④ Tity Data(with Pandas)
具体地址: http://pandas.pydata.org 包含了语法的介绍,重塑,聚合,缺失数据处理,窗口函数,可视化等等。


⑤ 数据维度
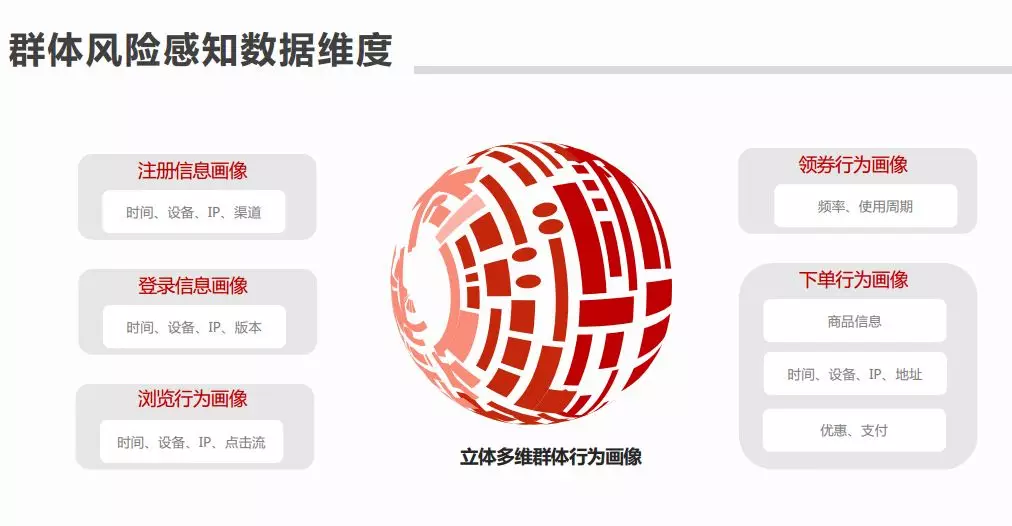
我们从静态数据和动态行为数据俩个角度来构建立体多维群体行为画像:
-
静态数据
-
注册信息画像:时间,设备,ip,渠道
-
登录信息画像:时间,设备,ip,版本
-
动态行为数据
假设 A、B、C 三个账号由同一个人控制,那么每次有活动他们就一起来了,可知道他们是一伙的,如何把这三个人每次活动一起来这件事儿,通过数据来描述好加工出来,供后面的模型使用,这是我们当时研究的重点。
动态行为数据包括:
-
**浏览行为画像:******时间,设备,ip,渠道(同静态相同,但是是账号之间的比较)
-
**下单行为画像:******商品信息,时间信息,设备,ip,地址,优惠券, 支付
-
**领券行为画像:******频率,使用周期
▌建模
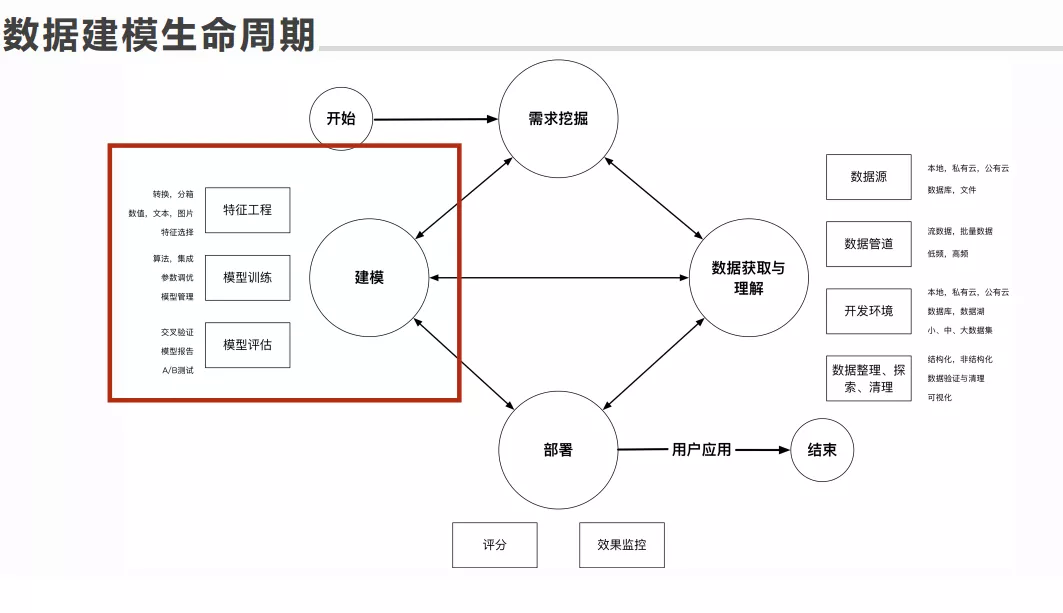
建模的三个主要模块:
-
特征工程: 特征处理,数值,文本,图片,特征选择
-
模型训练: 参数调优,模型管理
-
模型评估: 交叉验证,模型报告,A/B 测试
① 目标
-
确定要输入模型的数据特征
-
选择一个最能满足项目要求的模型(如果这个项目以准确率为最核心的 KPI,可能 A、B、C 三个模型都各有所长,有的效率高、有的速度快、有的召回率高,这时就需要按要求选择)
-
模型参数调优,针对生产环境做优化(A/B TEST)
② 实现方法
-
特征工程
-
模型选择(分类、聚类、有监督、无监督、深度学习、强化学习)
-
模型训练(如何调优)
-
评估模型在生产环境的适应性
③ 交付物
-
特征集
-
模型报告
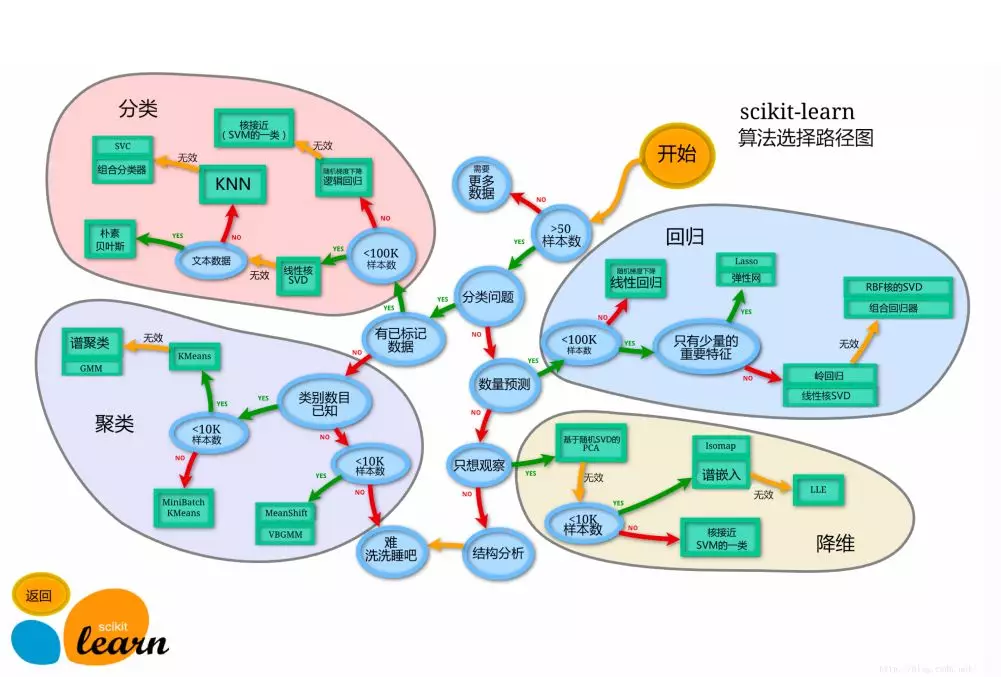
④ 算法模型路径选择
- Sklearn 算法选择路径图(这是目前网上比较流行的模型选择路径,大家可以根据业务的具体需求来选择模型);
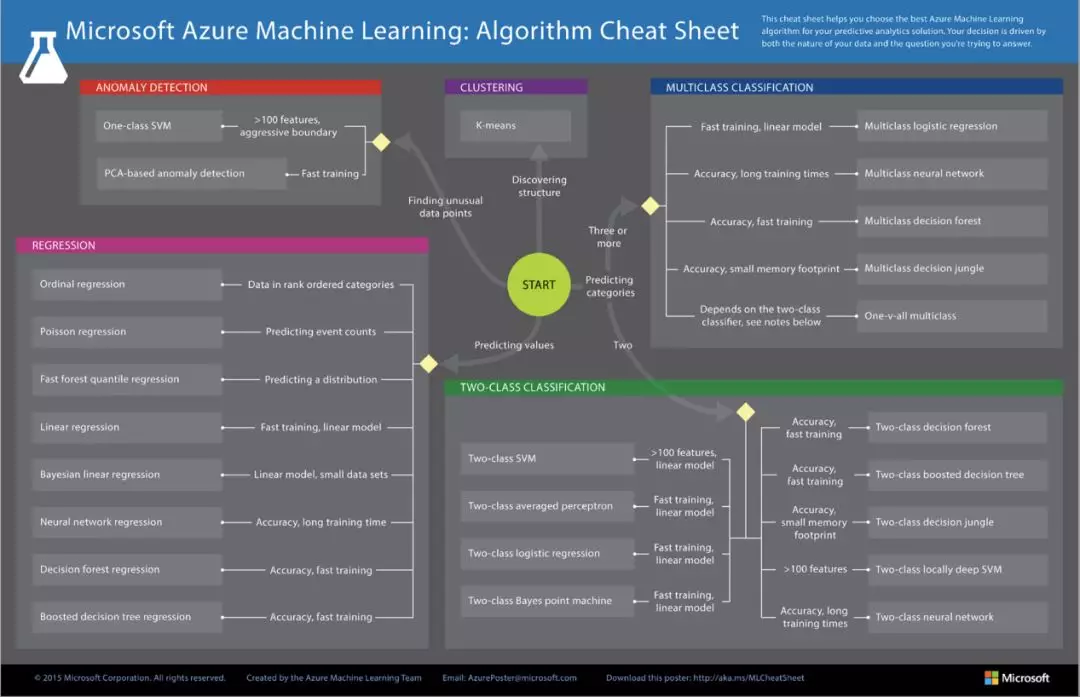
- 微软的模型选择路径:
⑤ 群体风险识别建模
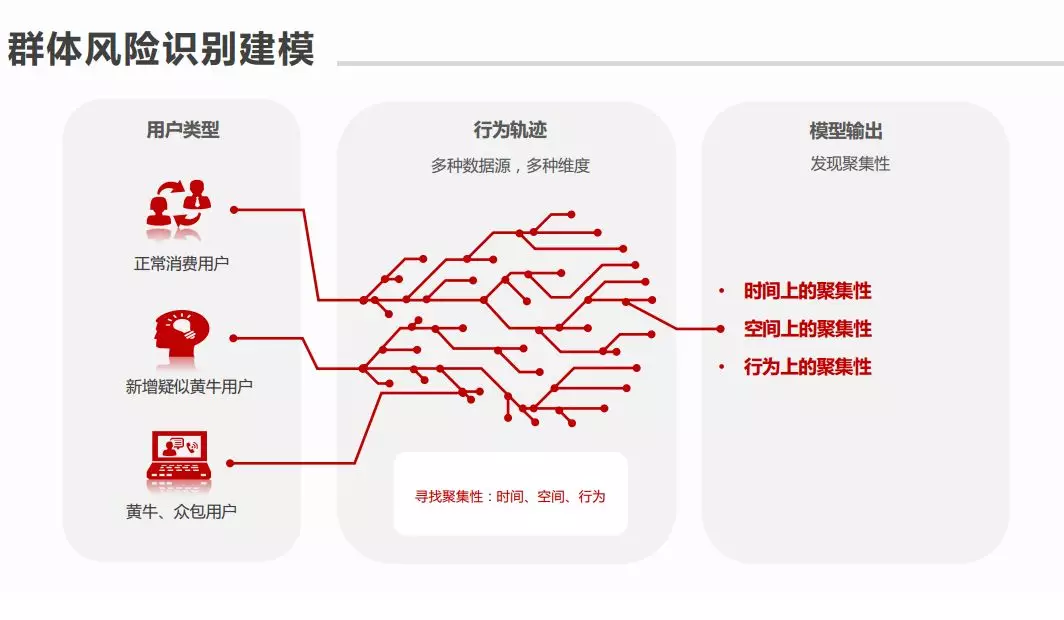
-
**用户类型:******正常消费,新增疑似黄牛用户,黄牛&众包用户
-
**行为轨迹:******多种数据源,多种维度,寻找在时间,空间,行为的聚集性
-
**模型输出:******发现时间,空间,行为上的聚集性
⑥ 静态特征识别
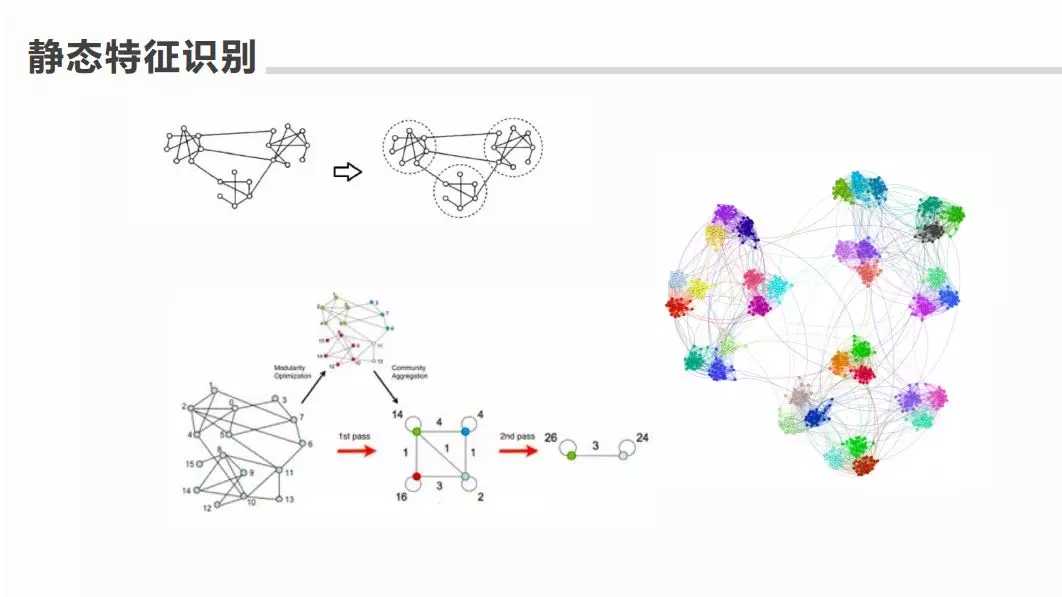
-
关系图,聚类:Louvain,Fast Greedy,Markov Cluster,Info Map,Walktrap。
-
图计算的社区发现(前人的一些经验):
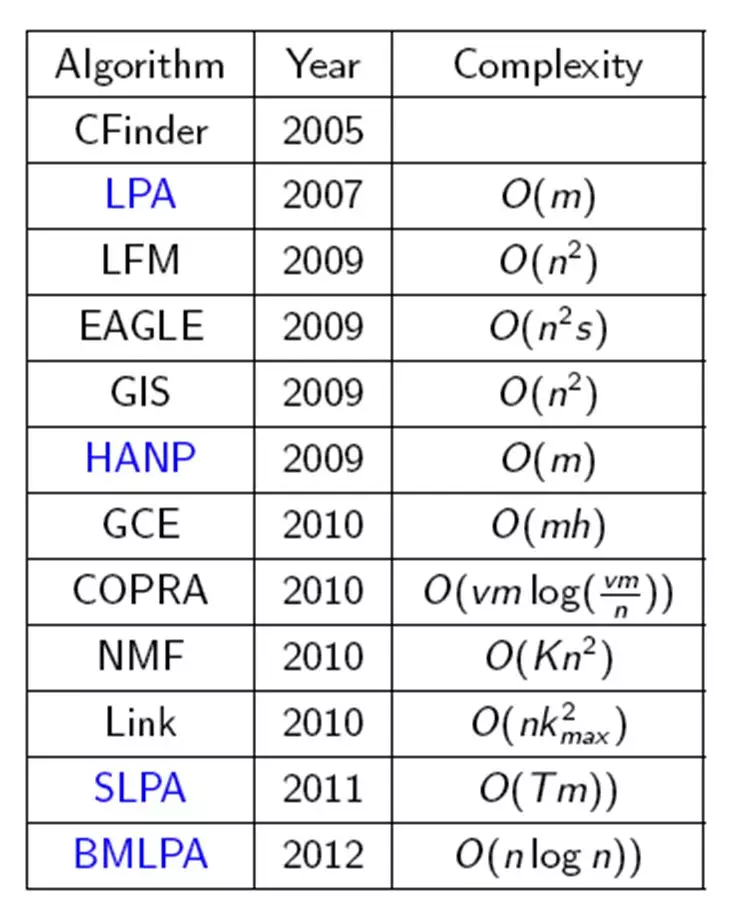
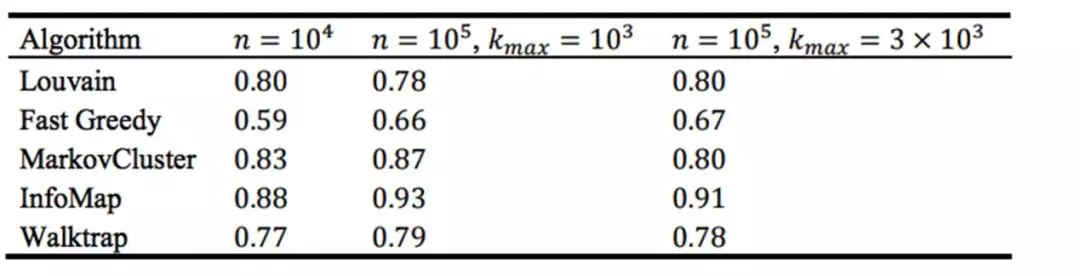
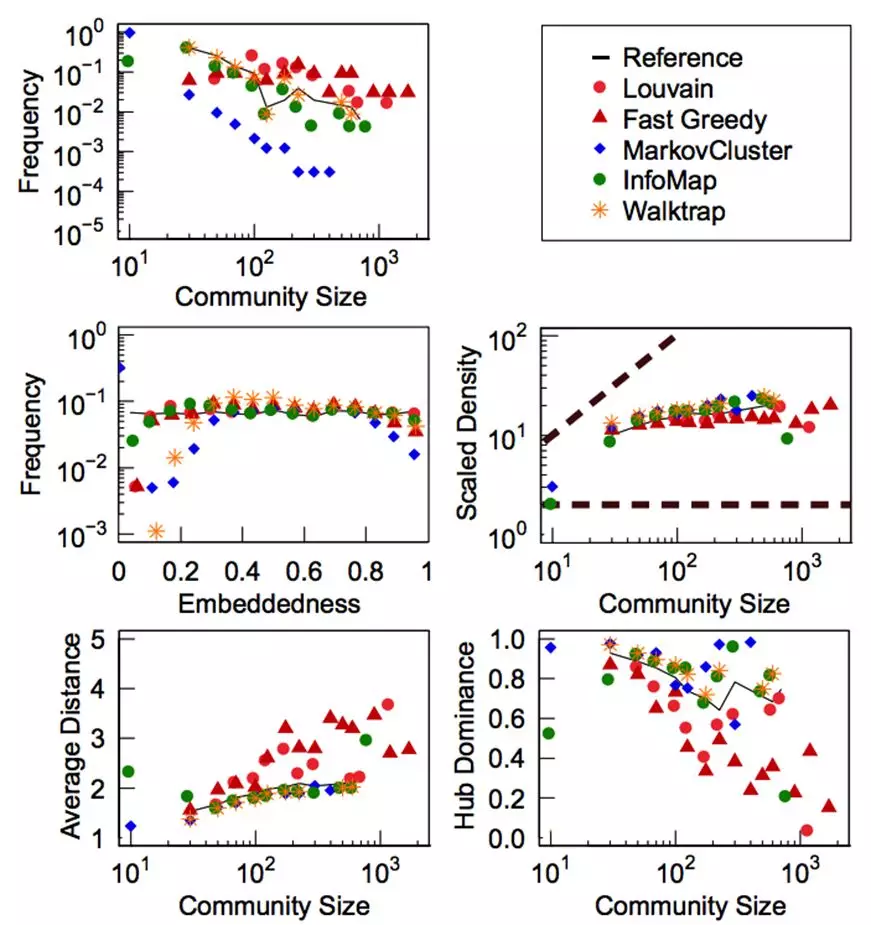
- 常用算法比较:
⑦ 动态特征识别
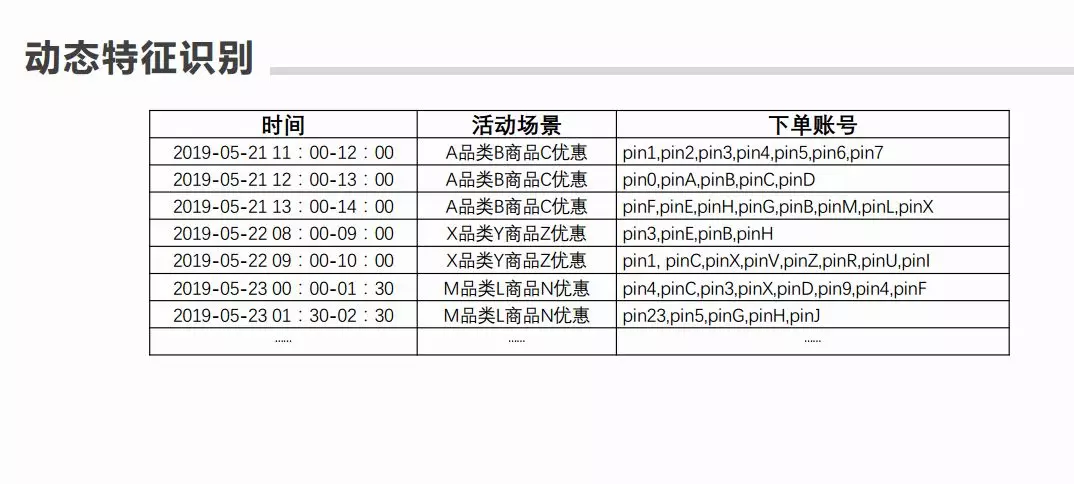
这是我们归结出来的数据底层形式,包括:时间,活动场景,下单账号几个维度。
**群体划分(聚类问题) :距离的选择对聚类的结果影响巨大
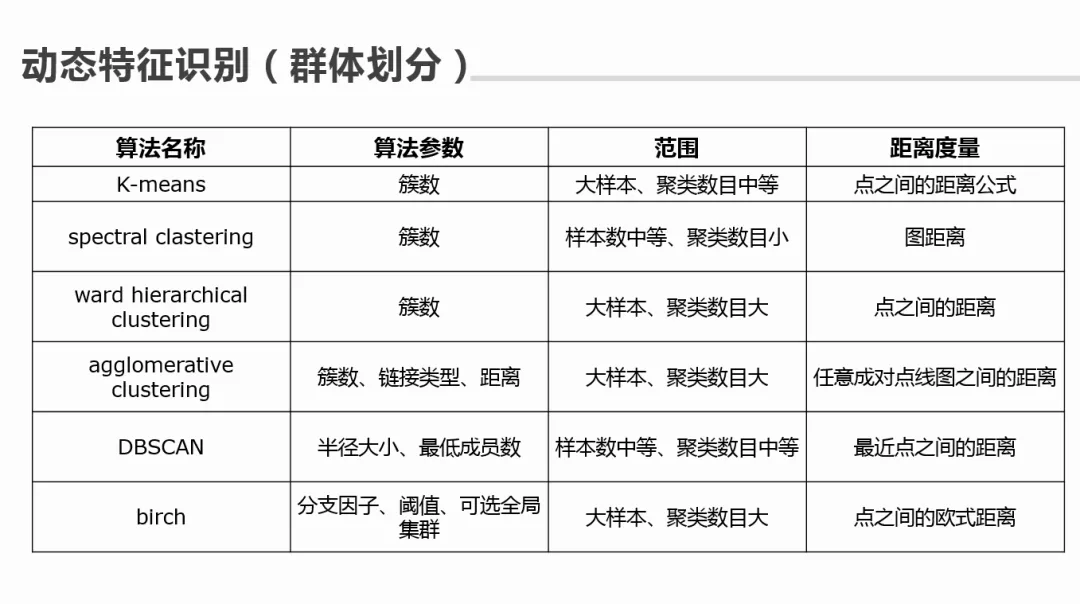
▌部署
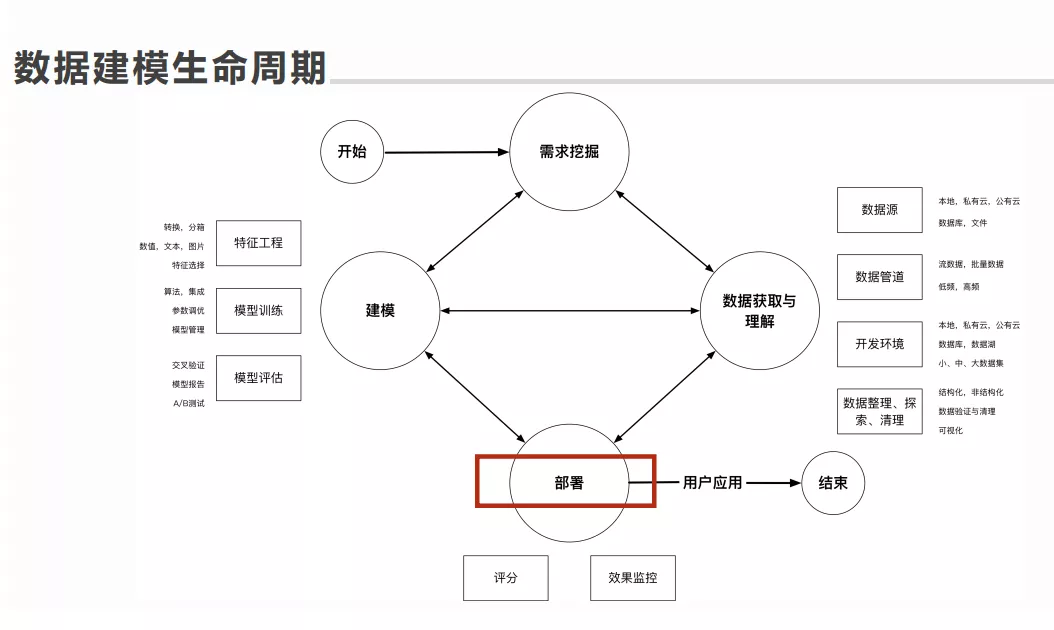
部署的时候需要考虑的两个关键因素: 评分和效果监控。
-
目标:把模型和配套的数据管道部署到生产环境
-
实现方法: 推荐 api 接口形式部署模型\\\**
-
交付物:监控报表,模型说明文档(输出和部署细节),数据管道说明文档
▌用户应用
① 目标
- 完成项目交付
② 实现方法
-
验证部署好的系统的功能性和准确率,满足业务需求
-
所有文档都要完成并进行审阅
-
项目交接工作可能是交给 IT 运维部分或者是用户的数据团队甚至可能是业务团队
③ 交付物
- 项目交付报告
④ 业务应用架构:
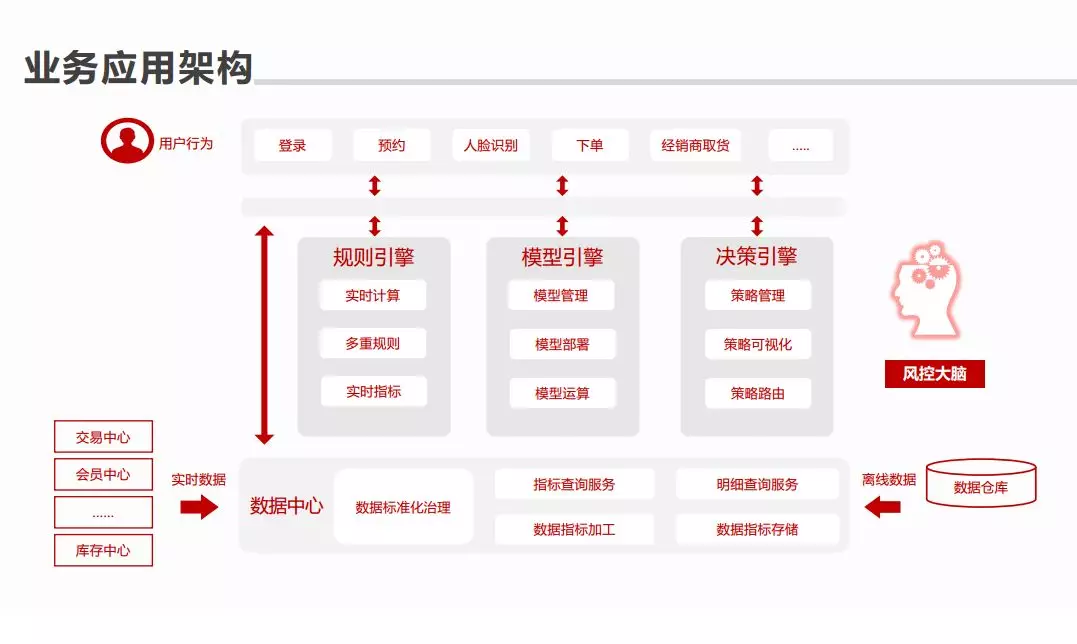
用规则引擎(实时计算、多重规则、实时指标),模型引擎(模型管理、模型部署、模型运算),决策引擎(策略管理、策略可视化、策略路由)连接数据中心和用户行为。****
⑤ 设计多层次风控场景策略\\\**
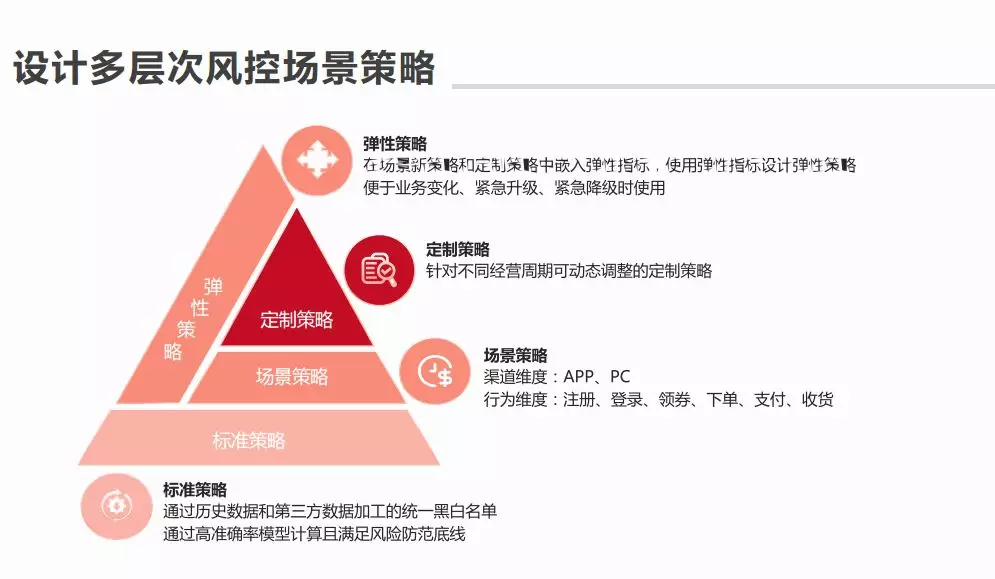
-
标准策略: 标配,黑白名单,评分
-
定制策略: 针对不同的经营周期动态调整策略
-
场景策略: 针对渠道,行为维度
-
弹性策略:场景策略和定制策略中增加弹性指标,用于业务变化,紧急升级和降级
今天的分享就到这里,谢谢大家。

嘉宾介绍
曾军崴,京东集团智�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%A3%8E%E6%8E%A7%E5%BB%BA%E6%A8%A1%E6%B5%81%E7%A8%8B%E4%BB%A5%E4%BA%AC%E4%B8%9C%E7%BE%A4%E4%BD%93%E6%84%9F%E7%9F%A5%E9%A1%B9%E7%9B%AE%E4%B8%BA%E4%BE%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


