黄正杰百度图学习技术与应用

分享嘉宾:黄正杰 百度 资深研发工程师
编辑整理:吴祺尧
出品平台:DataFunTalk
导读: 图是一个复杂世界的通用语言,社交网络中人与人之间的连接、蛋白质分子、推荐系统中用户与物品之间的连接等等,都可以使用图来表达。图神经网络将神经网络运用至图结构中,可以被描述成消息传递的范式。百度开发了PGL2.2,基于底层深度学习框架paddle,给用户暴露了编程接口来实现图网络。与此同时,百度也使用了前沿的图神经网络技术针对一些应用进行模型算法的落地。本次将介绍百度的PGL图学习技术与应用。主要包括以下内容:
- 图来源与建模
- PGL2.2介绍
- 图神经网络技术
- 应用落地
01 图来源与建模
首先和大家分享下图学习主流的图神经网络建模方式。
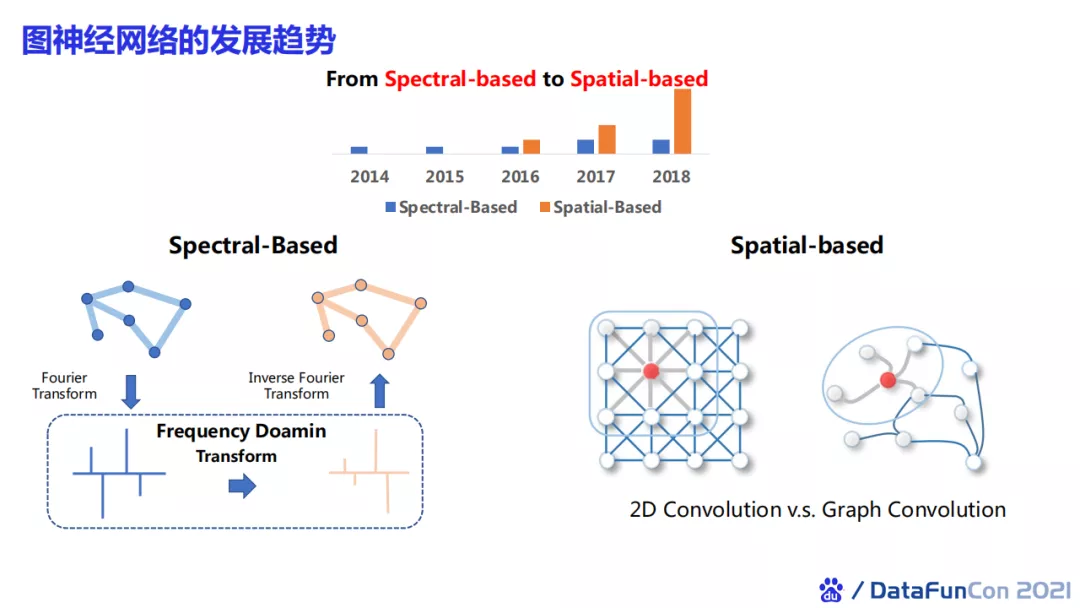
14年左右开始,学术界出现了一些基于图谱分解的技术,通过频域变换,将图变换至频域进行处理,再将处理结果变换回空域来得到图上节点的表示。后来,空域卷积借鉴了图像的二维卷积,并逐渐取代了频域图学习方法。图结构上的卷积是对节点邻居的聚合。
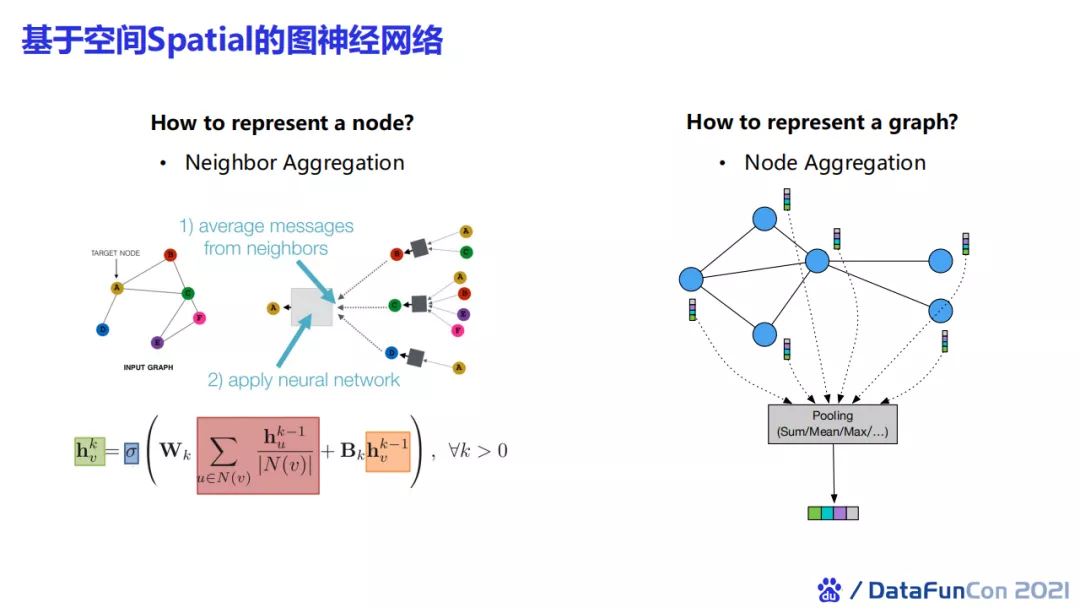
基于空间的图神经网络主要需要考虑两个问题:
- 怎样表达节点特征;
- 怎样表达一整张图。
第一个问题可以使用邻居聚合的方法,第二问题使用节点聚合来解决。
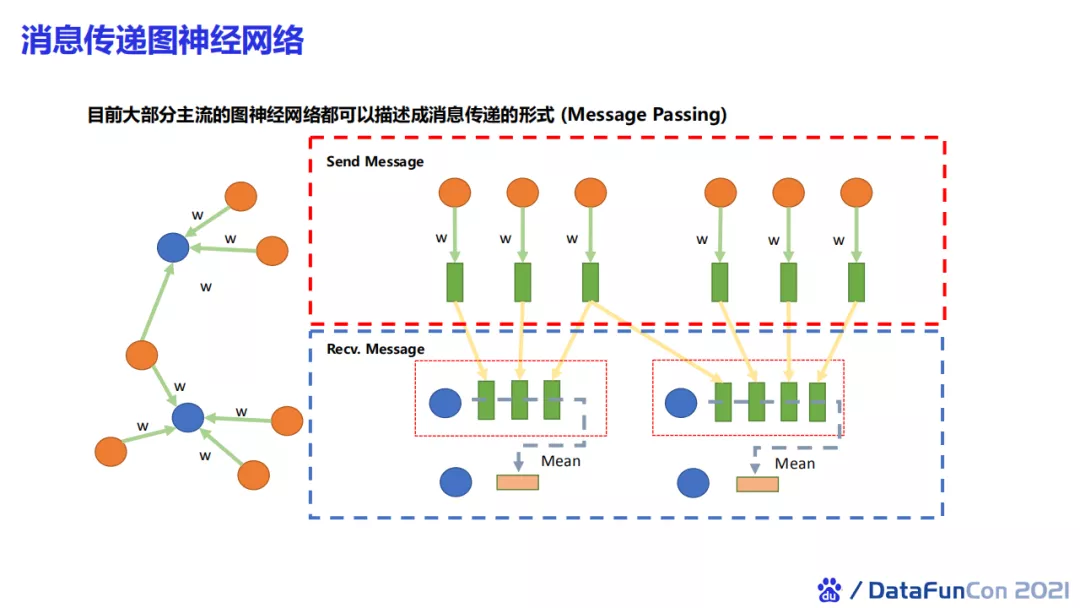
目前大部分主流的图神经网络都可以描述成消息传递的形式。我们需要考虑节点如何将消息发送至目标节点,然后目标节点如何对收到的节点特征进行接收。
02 PGL2.2介绍

PGL2.2基于消息传递的思路构建整体框架。PGL最底层是飞浆核心paddle深度学习框架。在此之上,我们搭建了CPU图引擎和GPU上进行tensor化的图引擎,来方便我们对图进行如图切分、图存储、图采样、图游走的算法。再上一层,我们会对用户暴露一些编程接口,包括底层的消息传递接口和图网络实现接口,以及高层的同构图、异构图的编程接口。框架顶层会支持几大类图模型,包括传统图表示学习中的图游走模型、消息传递类模型、知识嵌入类模型等,去支撑下游的应用场景。
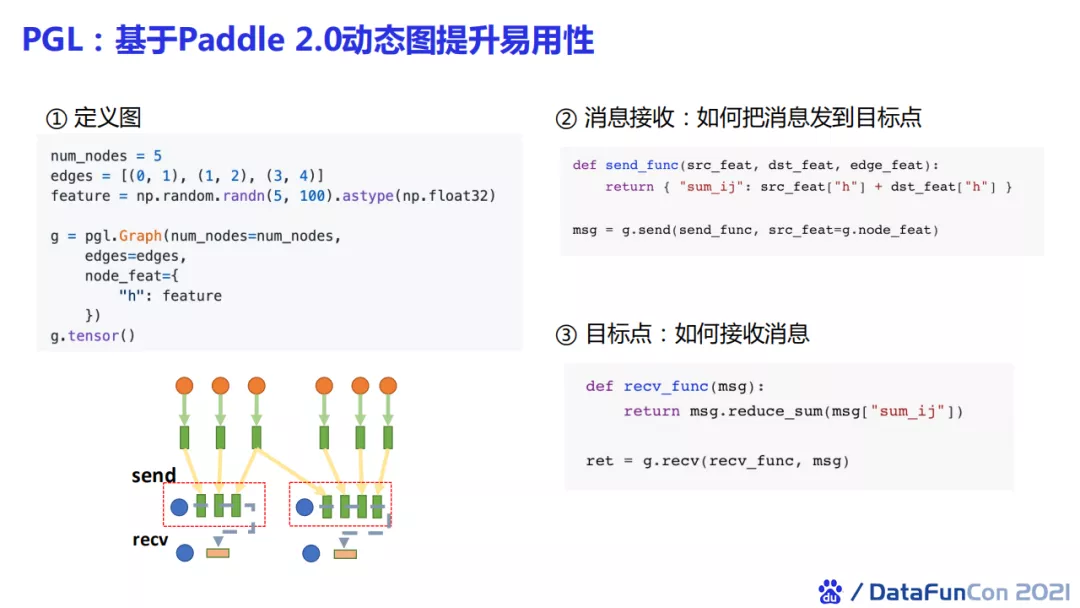
最初的PGL是基于paddle1.x的版本进行开发的,所以那时候还是像tensorflow一样的静态图模式。目前paddle2.0已经进行了全面动态化,那么PGL也相应地做了动态图的升级。现在我们去定义一个图神经网络就只需要定义节点数量、边数量以及节点特征,然后将图tensor化即可。我们可以自定义如何将消息进行发送以及目标节点如何接收消息。
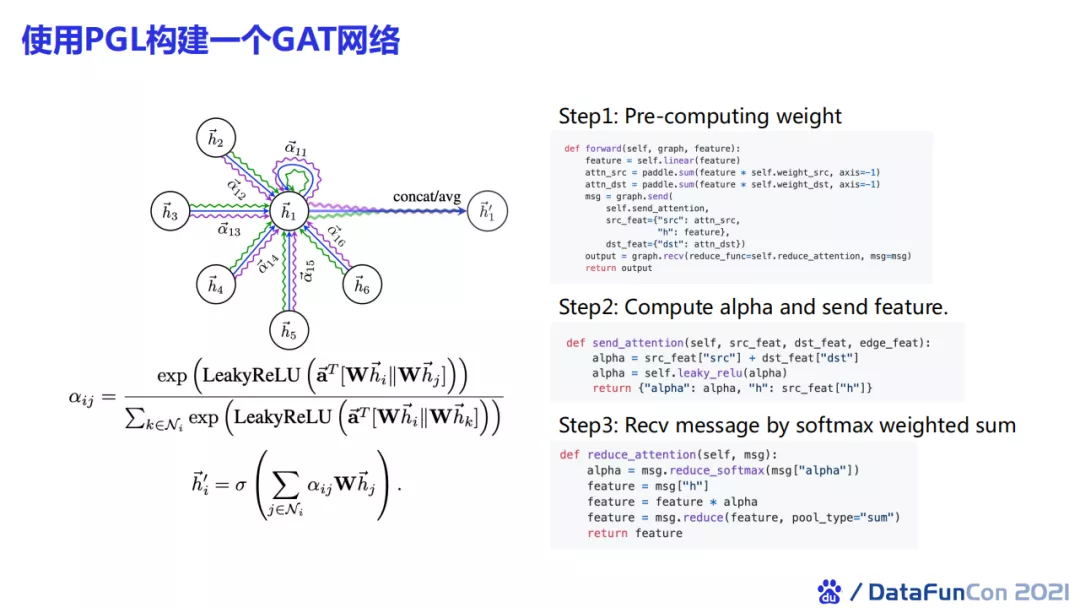
上图是使用PGL构建一个GAT网络的例子。我们最开始会去计算节点的权重,在发送消息的时候GAT会将原节点和目标节点特征进行求和,再加上一个非线性激活函数。在接收的时候,我们可以通过reduce_softmax对边上的权重进行归一化,再乘上hidden state进行加权求和。这样我们就可以很方便地实现一个GAT网络。

对于图神经网络来讲,在构建完网络后,我们要对它进行训练。训练方式和一般机器学习有所不同,需要根据图的规模选择适用的训练方案。
- 小规模
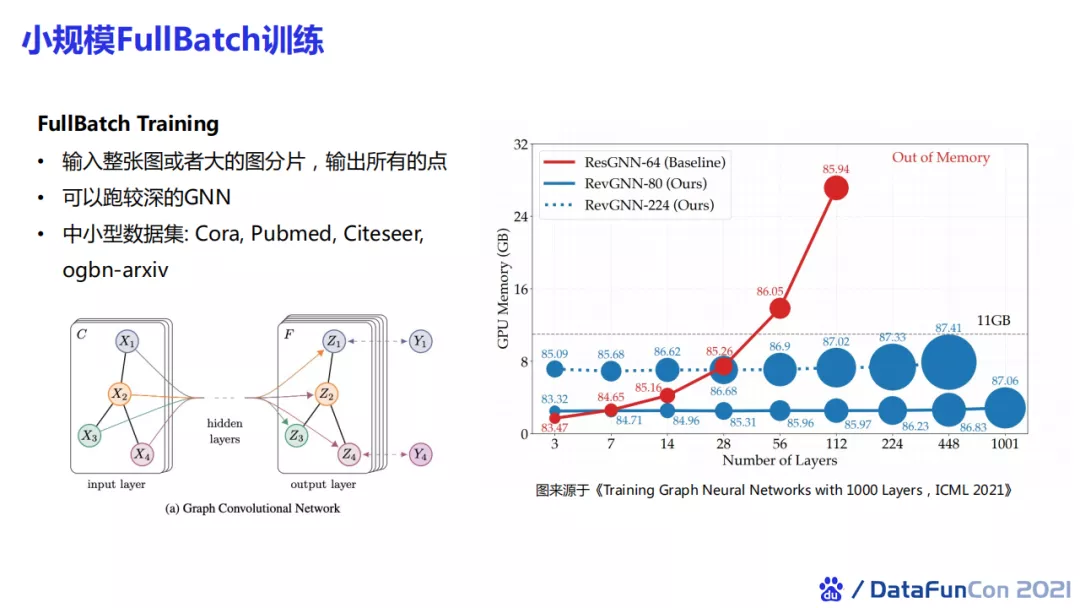
例如在小图,即图规模小于GPU显存的情况下,我们会使用full batch模式进行训练。它其实就是把一整张图的所有节点都放置在GPU上,通过一个图网络来输出所有点的特征。它的好处在于我们可以跑一个很深的图。这一训练方案会被应用于中小型数据集,例如Cora、Pubmed、Citeseer、ogbn-arxiv等。我们最近在ICML上发现了可以堆叠至1000层的图神经网络,同样也是在这种中小型数据集上做评估。
- 中规模
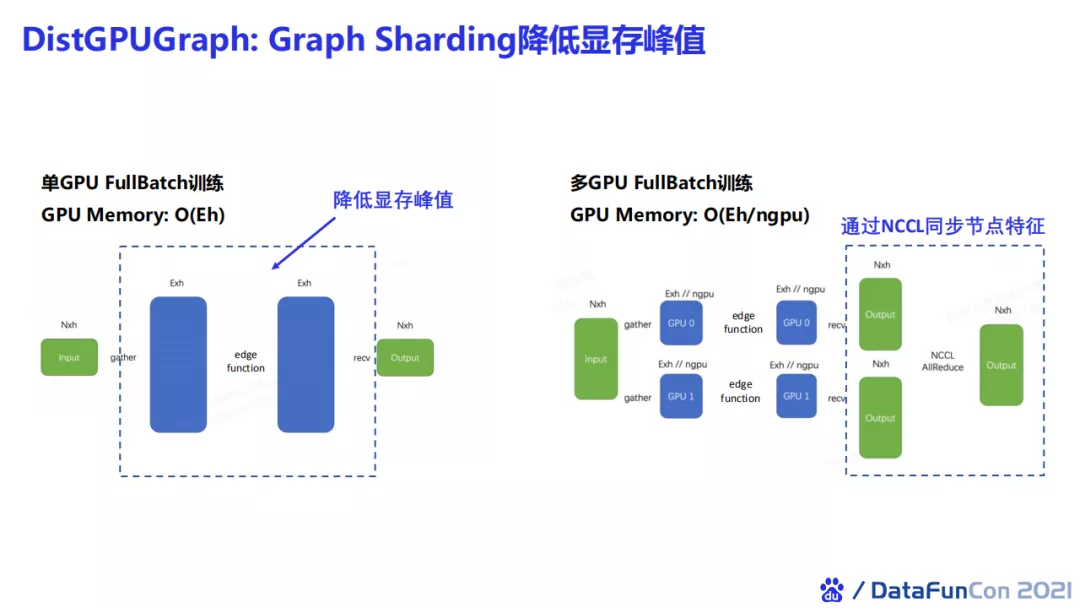
对于中等规模的图,即图规模大于GPU单卡显存,知识可以进行分片训练,每一次将一张子图塞入GPU上。PGL提供了另一个方案,使用分片技术来降低显存使用的峰值。例如对一个复杂图进行计算时,它的计算复杂度取决于边计算时显存使用的峰值,此时如果我们有多块GPU就可以把边计算进行分块,每台机器只负责一小部分的计算,这样就可以大大地减少图神经网络的计算峰值,从而达到更深的图神经网络的训练。分块训练完毕后,我们需要通过NCCL来同步节点特征。

在PGL中,我们只需要一行DistGPUGraph命令就可以在原来full batch的训练代码中加入这样一个新特性,使得我们可以在多GPU中运行一个深层图神经网络。例如我们在obgn-arxiv中尝试了比较复杂的TransformerConv网络,如果使用单卡训练一个三层网络,其GPU显存会被占用近30G,而使用分片训练就可以将它的显存峰值降低。同时,我们还实现了并行的计算加速,例如原来跑100 epoch需要十分钟,现在只需要200秒。
- 大规模
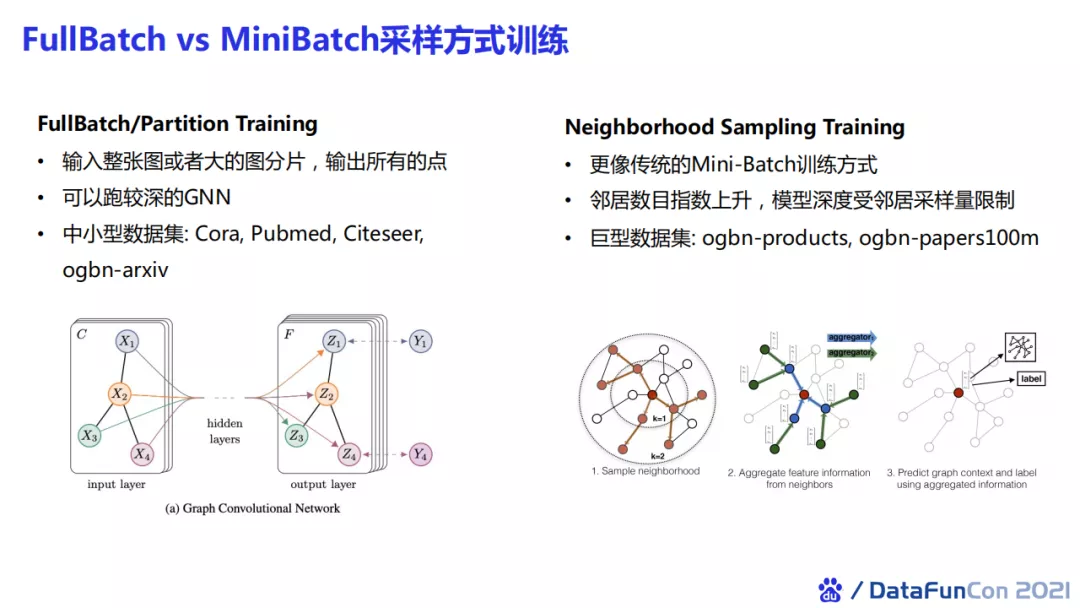
在大图的情况下,我们又回归到平时做数据并行的mini batch模式。Mini batch与full batch相比最主要的问题在于它需要做邻居的采样,而邻居数目的提升会对模型的深度进行限制。这一模式适用于一些巨型数据集,包括ogbn-products和ogbn-papers100m。
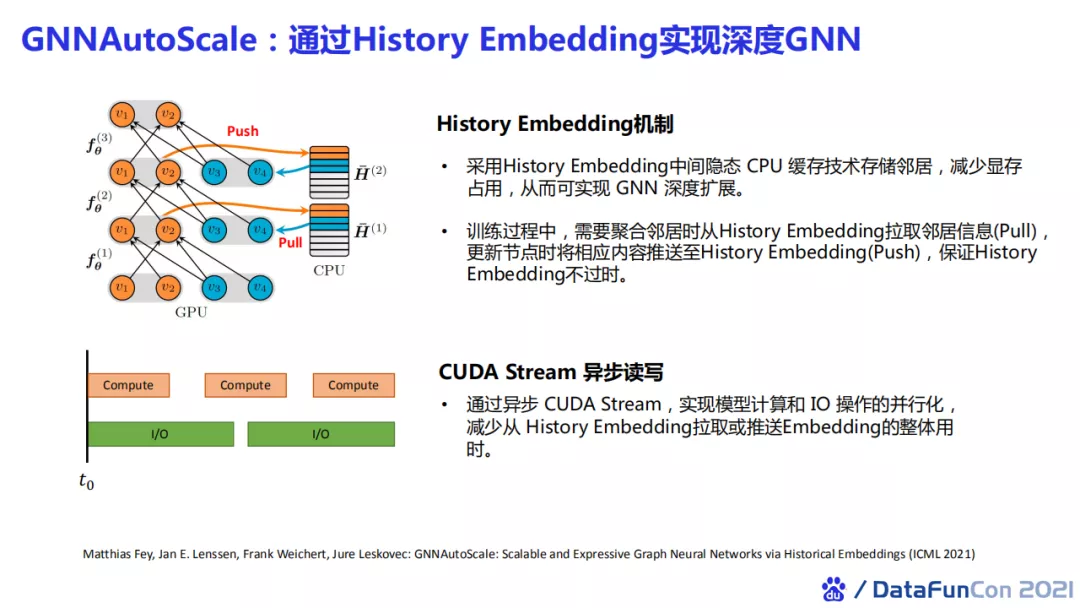
我们发现PyG的作者的新工作GNNAutoScale能够把一个图神经网络进行自动的深度扩展。它的主要思路是利用CPU的缓存技术,将邻居节点的特征缓存至CPU内存中。当我们训练图网络时,可以不用实时获取所有邻居的最新表达,而是获取它的历史embedding进行邻居聚合计算。实验发现这样做的效果还是不错的。
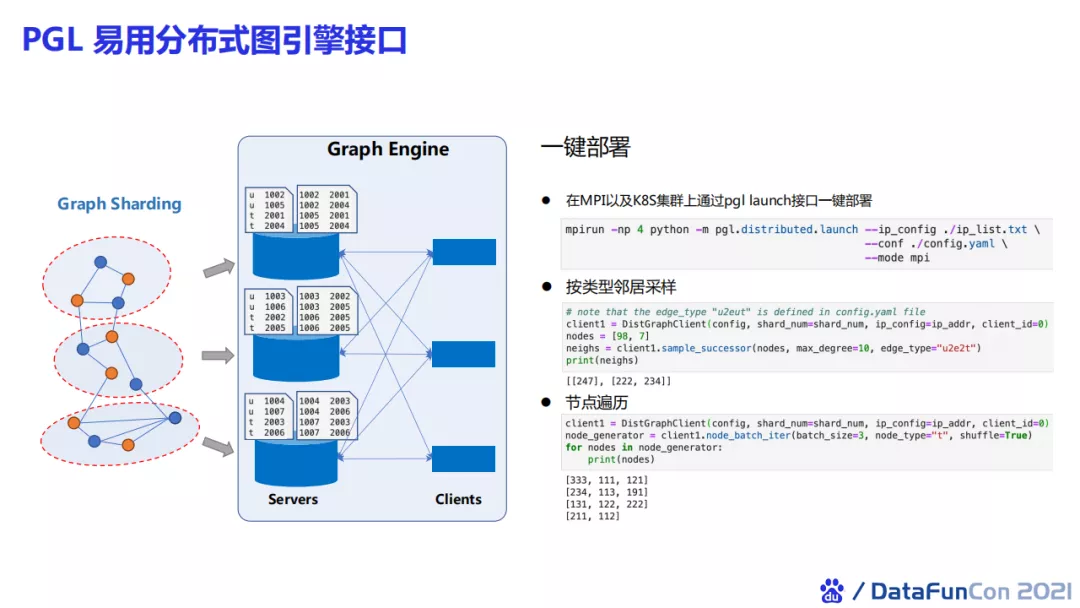
在工业界的情况下可能会存在更大的图规模的场景,那么这时候可能单CPU也存不下如此图规模的数据,这时我们需要一个分布式的多机存储和采样。PGL有一套分布式的图引擎接口,使得我们可以轻松地在MPI以及K8S集群上通过PGL launch接口进行一键的分布式图引擎部署。我们目前也支持不同类型的邻居采样、节点遍历和图游走算法。
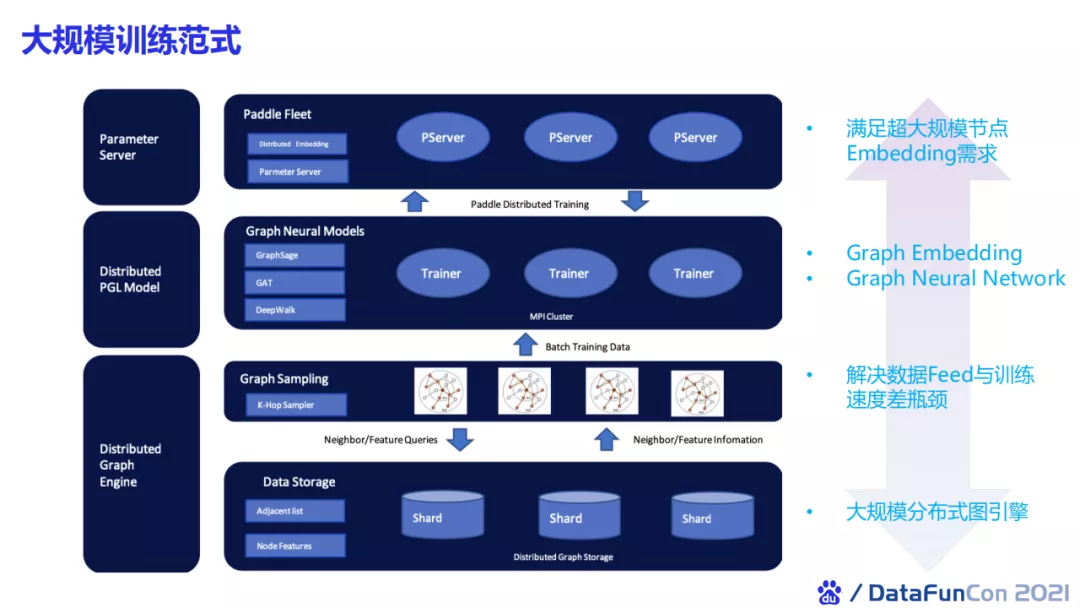
整体的大规模训练方式包括一个大规模分布式图引擎,中间会包含一些图采样的算子和神经网络的开发算子。顶层针对工业界大规模场景,往往需要一个parameter server来存储上亿级别的稀疏特征。我们借助paddlefleet的大规模参数服务器来支持超大规模的embedding存储。
03 图神经网络技术
1. 节点分类任务
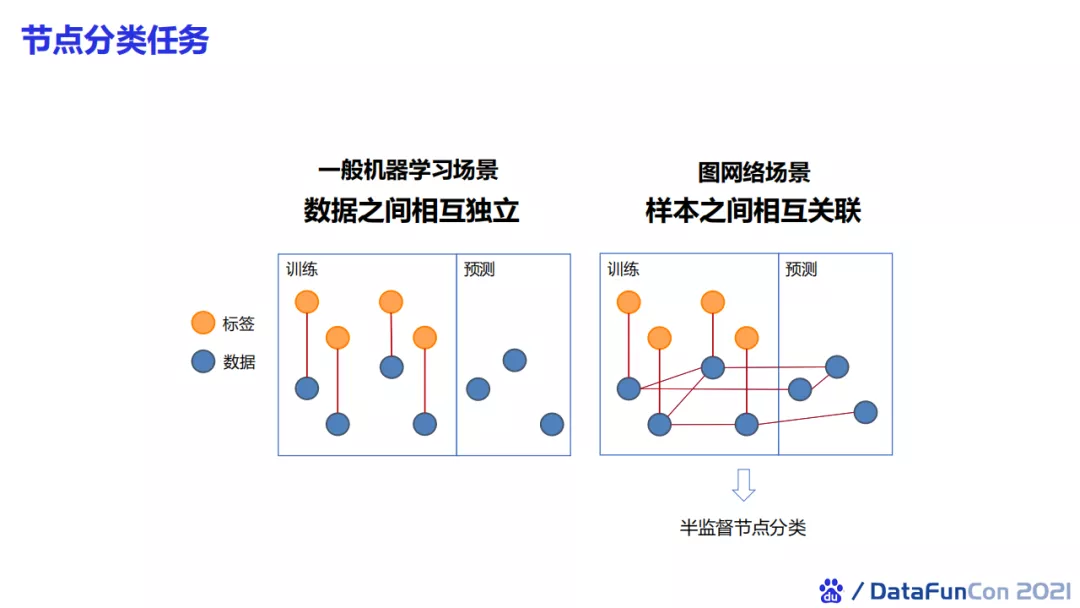
我们团队在算法上也进行了一些研究。图神经网络与一般机器学习场景有很大的区别。一般的机器学习假设数据之间独立同分布,但是在图网络的场景下,样本是有关联的。预测样本和训练样本有时会存在边关系。我们通常称这样的任务为半监督节点分类问题。
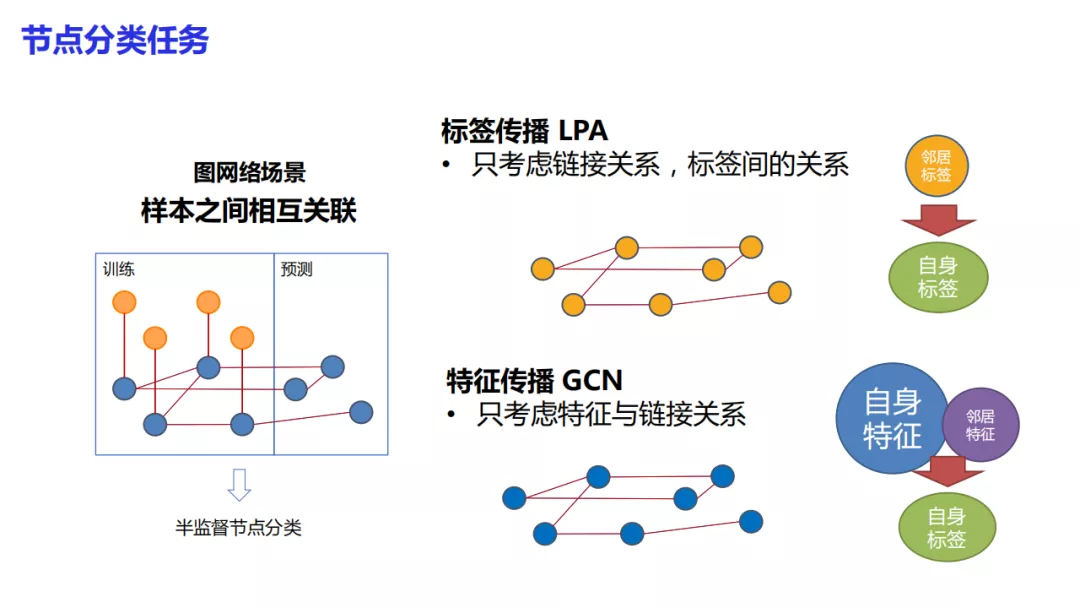
解决节点分类问题的传统方法是LPA标签传播算法,考虑链接关系以及标签之间的关系。另外一类方法是以GCN为代表的特征传播算法,只考虑特征与链接的关系。
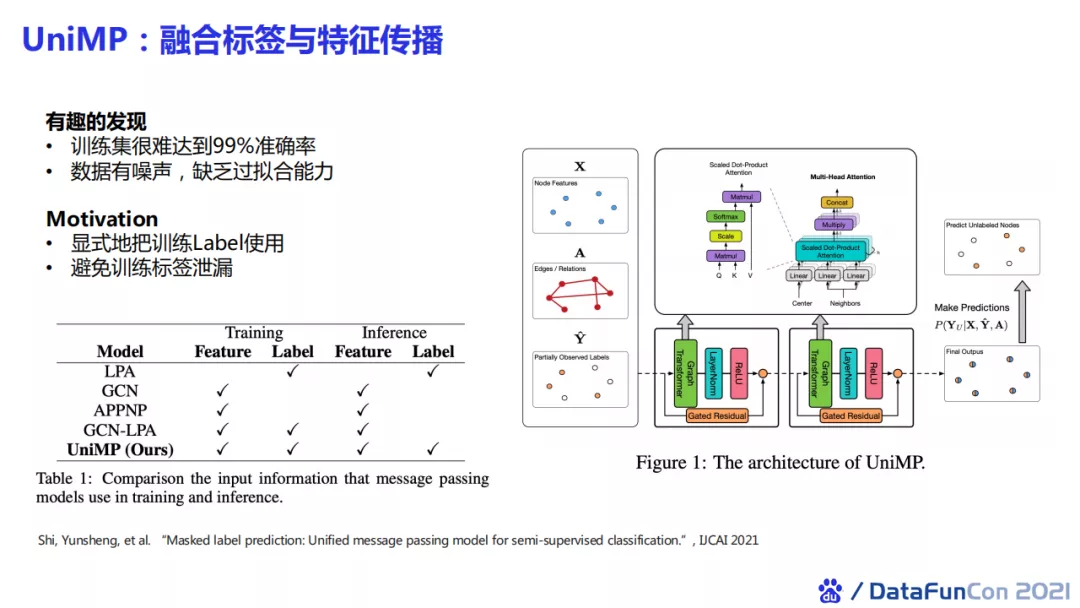
我们通过实验发现在很多数据集下,训练集很难通过过拟合达到99%的分类准确率。也就是说,训练集中的特征其实包含很大的噪声,使得网络缺乏过拟合能力。所以,我们想要显示地将训练label加入模型,因为标签可以消减大部分歧义。在训练过程中,为了避免标签泄露,我们提出了UniMP算法,把标签传播和特征传播融合起来。这一方法在三个open graph benchmark数据集上取得了SOTA的结果。
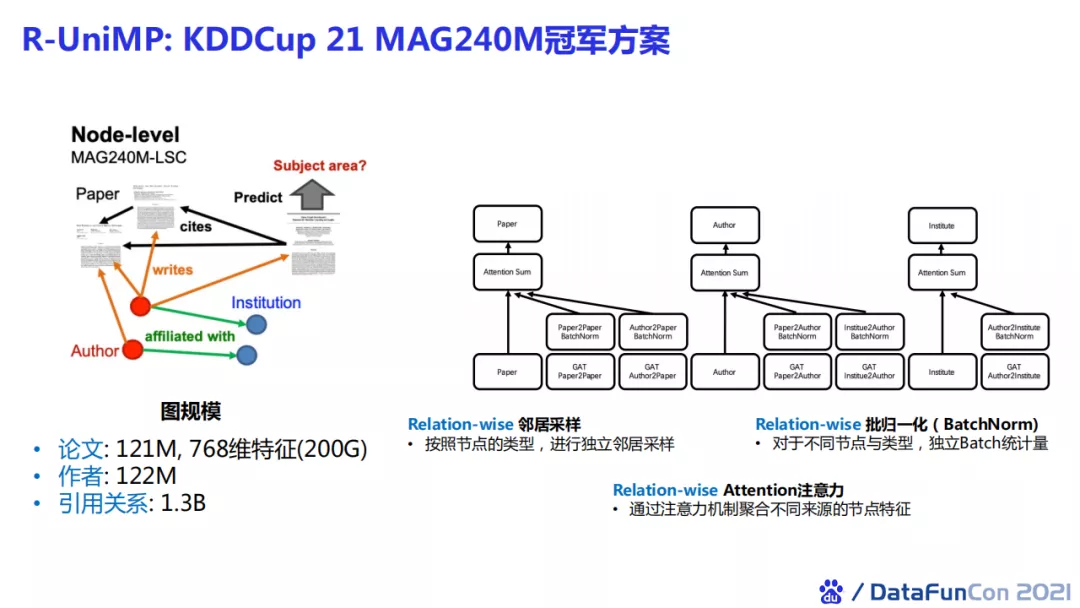
后续我们还把UniMP应用到更大规模的KDDCup 21的比赛中,将UniMP同构算法做了异构图的拓展,使其在异构图场景下进行分类任务。具体地,我们在节点邻居采样、批归一化和注意力机制中考虑节点之间的关系类型。
2. 链接预测任务
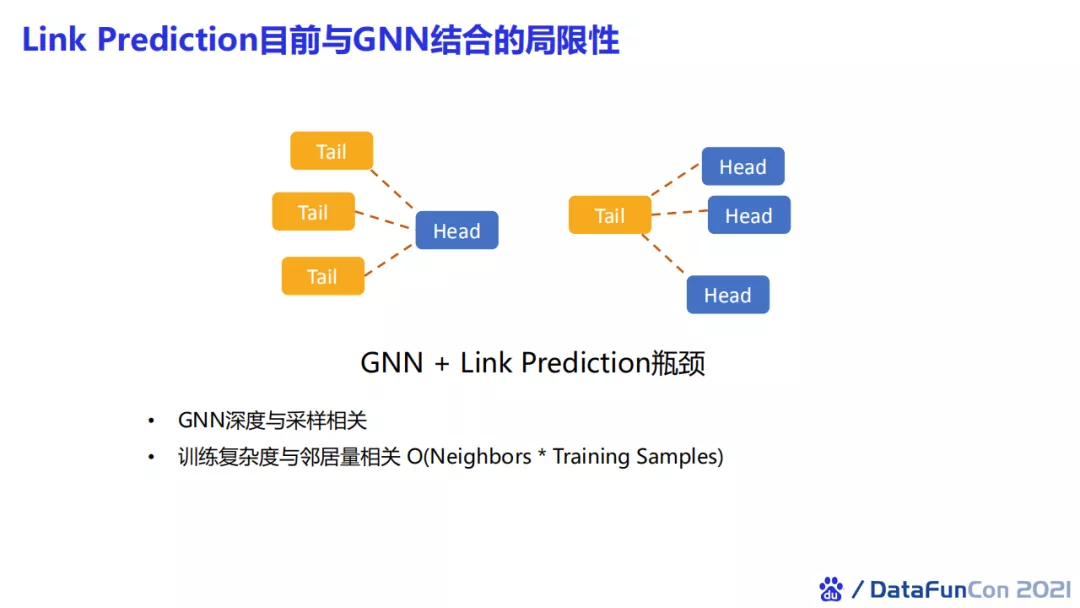
第二个比较经典的任务是链接预测任务。目前很多人尝试使用GNN与link prediction进行融合,但是这存在两个瓶颈。首先,GNN的深度和邻居采样的数量有关;其次,当我们训练像知识图谱的任务时,每一轮训练都需要遍历训练集的三元组,此时训练的复杂度和邻居节点数量存在线性关系,这就导致了如果邻居比较多,训练一个epoch的耗时很长。
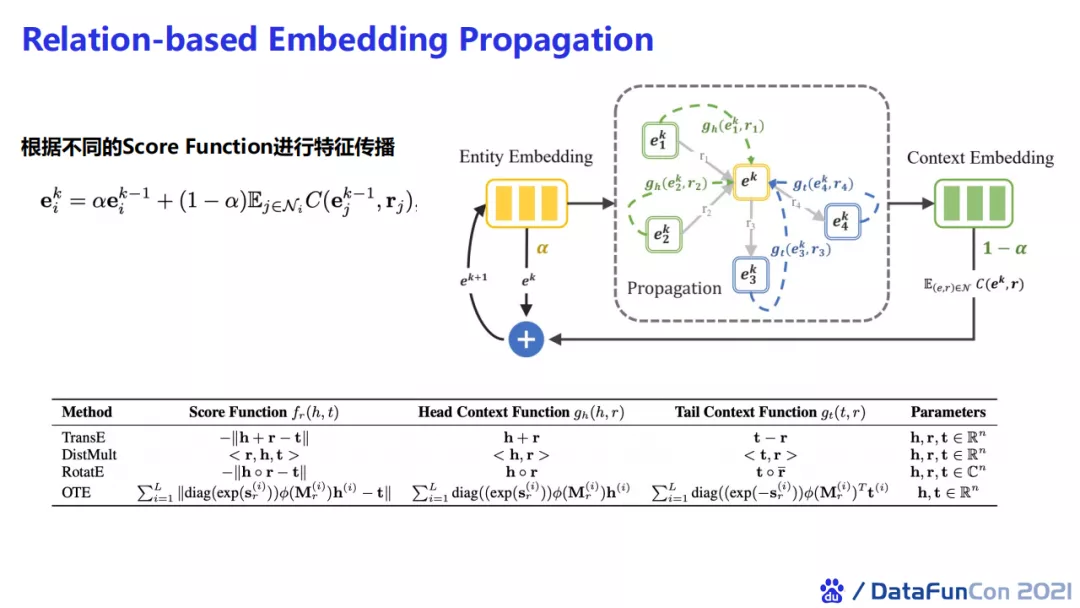
我们借鉴了最近基于纯特征传播的算法,如SGC等图神经网络的简化方式,提出了基于关系的embedding传播。我们发现单独使用embedding进行特征传播在知识图谱上是行不通的。因为知识图谱上存在复杂的边关系。所以,我们根据不同关系下embedding设计了不同的score function进行特征传播。此外,我们发现之前有一篇论文提出了OTE的算法,在图神经网络上进行了两阶段的训练。
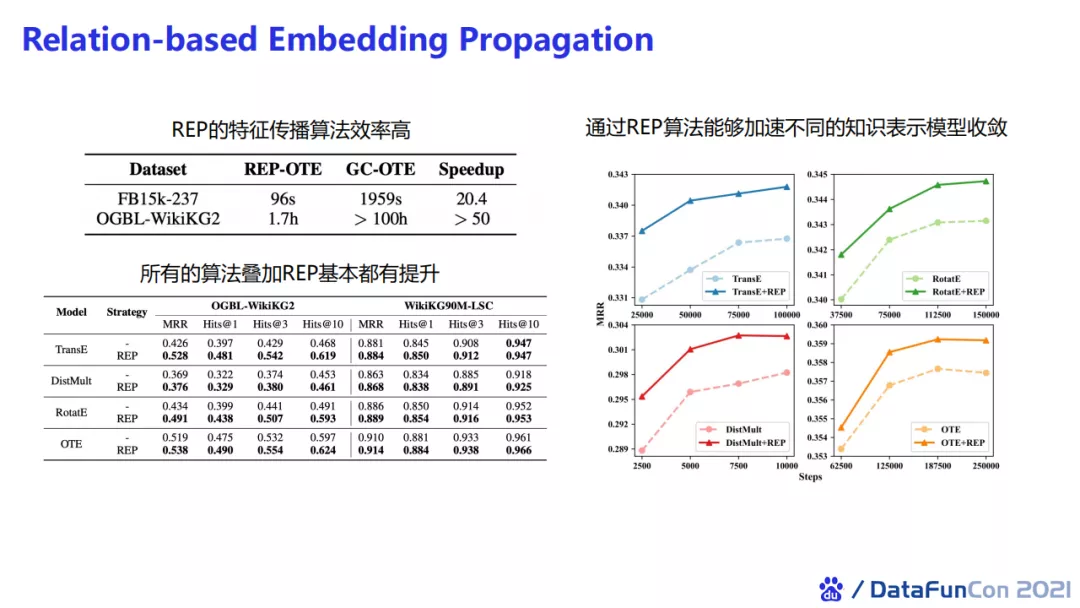
使用OGBL-WikiKG2数据集训练OTE模型需要超过100个小时,而如果切换到我们的特征传播算法,即先跑一次OTE算法,再进行REP特征传播,只需要1.7个小时就可以使模型收敛。所以REP带来了近50倍的训练效率的提升。我们还发现只需要正确设定score function,大部分知识图谱算法使用我们的特征传播算法都会有效果上的提升;不同的算法使用REP也可以加速它们的收敛。
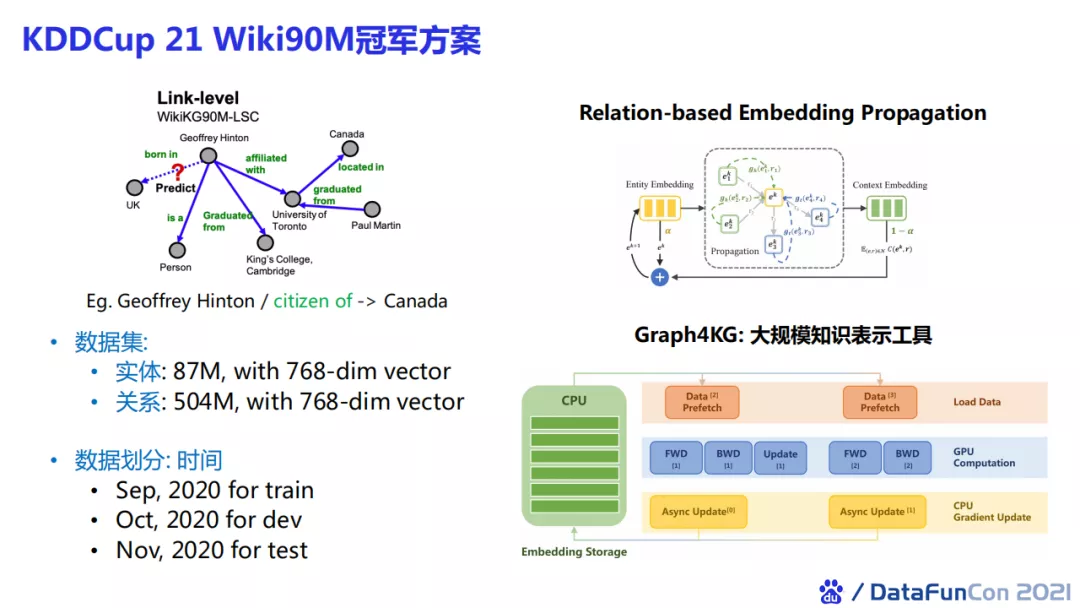
我们将这一套方法应用到KDDCup 21 Wiki90M的比赛中。我们为了实现比赛中要求的超大规模知识图谱的表示,做了一套大规模的知识表示工具Graph4KG,最终在KDDCup中取得了冠军。
04 应用落地

PGL在百度内部已经进行了广泛应用。包括百度搜索中的网页质量评估,我们会把网页构成一个动态图,并在图上进行图分类的任务。百度搜索还使用PGL进行网页反作弊,即对大规模节点进行检测。在文本检索应用中,我们尝试使用图神经网络与自然语言处理中的语言模型相结合。在其他情况下,我们的落地场景有推荐系统、风控、百度地图中的流量预测、POI检索等。
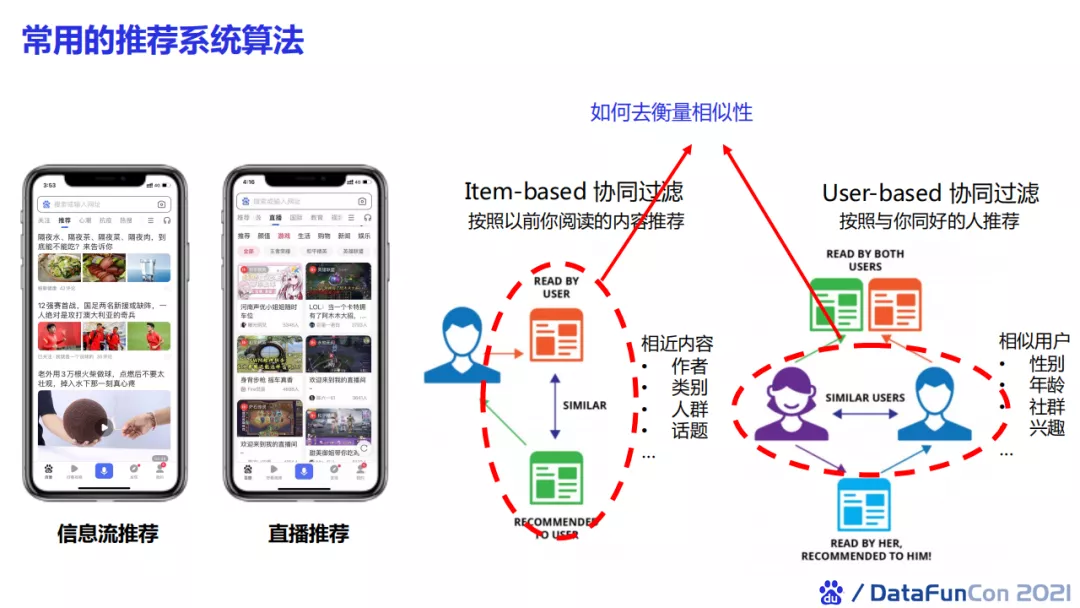
本文以推荐系统为例,介绍一下我们平时如何将图神经网络在应用中进行落地。
推荐系统常用的算法是基于item-based和user-based协同过滤算法。Item-based协同过滤就是推荐和item相似的内容,而user-based 就是推荐相似的用户。这里最重要的是如何去衡量物品与物品之间、用户与用户之间的相似性。
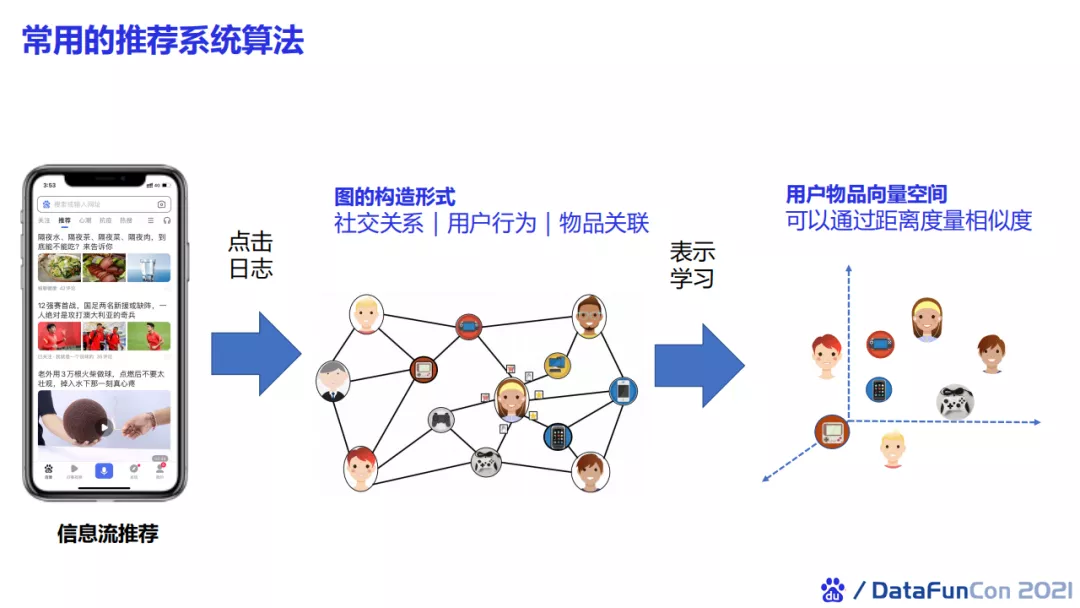
我们可以将其与图学习结合,使用点击日志来构造图关系(包括社交关系、用户行为、物品关联),然后通过表示学习构造用户物品的向量空间。在这个空间上我们就可以度量物品之间的相似性,以及用户之间的相似性,进而使用其进行推荐。
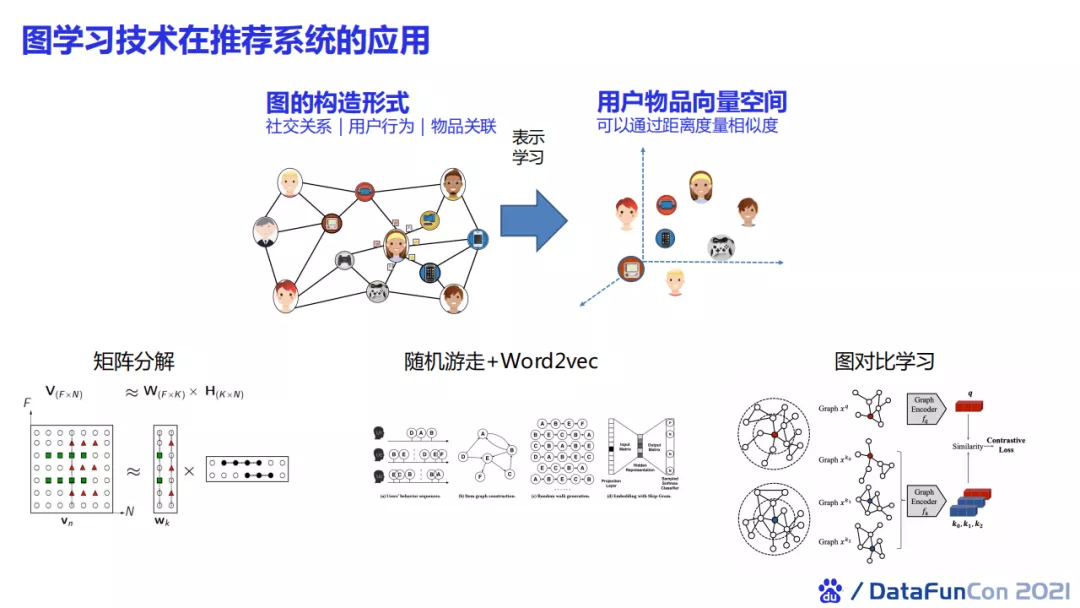
常用的方法有传统的矩阵分解方法,和阿里提出的基于随机游走 + Word2Vec的EGES算法。近几年兴起了使用图对比学习来获得节点表示。
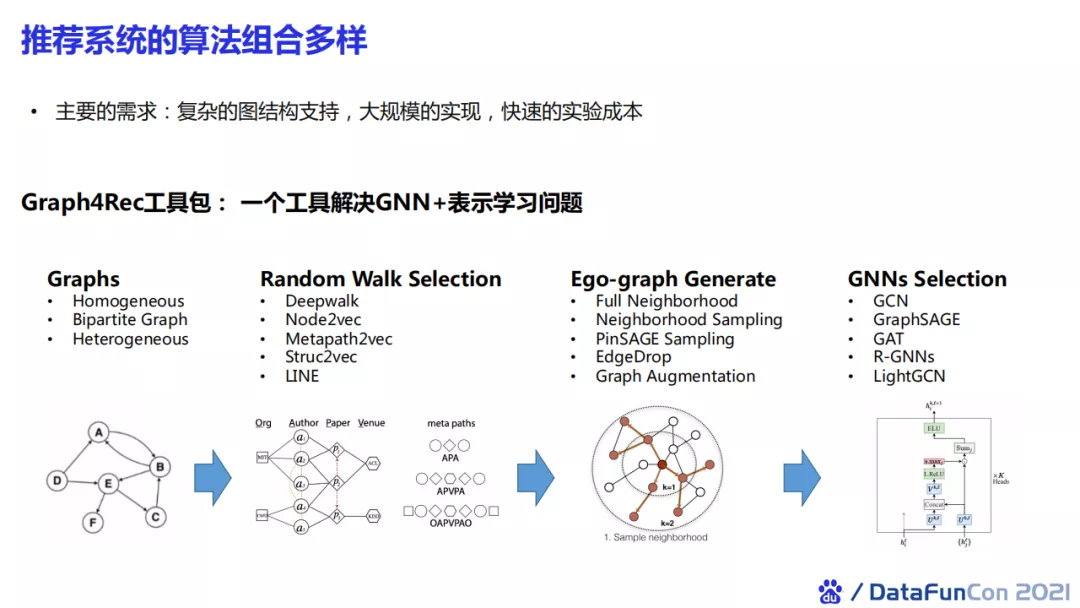
在推荐算法中,我们主要的需求是支持复杂的结构,支持大规模的实现和快速的实验成本。我们希望有一个工具包可以解决GNN + 表示学习的问题。所以,我们对现有的图表示学习算法进行了抽象。具体地,我们将图表示学习分成了四个部分。第一部分是图的类型,我们将其分为同构图、异构图、二部图,并在图中定义了多种关系,例如点击关系、关注关系等。第二,我们实现了不同的样本采样的方法,包括在同构图中常用的node2Vec以及异构图中按照用户自定义的meta path进行采样。第三部分是节点的表示。我们可以根据id去表示节点,也可以通过图采样使用子图来表示一个节点。我们还构造了四种GNN的聚合方式。
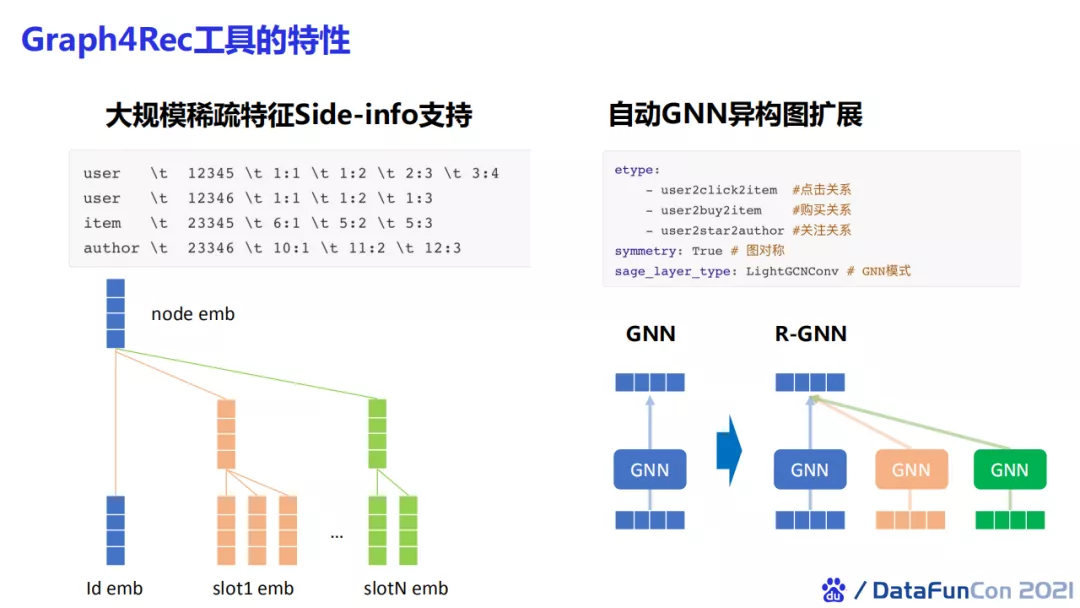
我们发现不同场景以及不同的图表示的训练方式下,模型效果差异较大。所以我们的工具还支持大规模稀疏特征side-info的支持来进行更丰富的特征组合。用户可能有很多不同的字段,有些字段可能是缺失的,此时我们只需要通过一个配置表来配置节点包含的特征以及字段即可。我们还支持GNN的异构图自动扩展。你可以自定义边关系,如点击关系、购买关系、关注关系等,并选取合适的聚合方式,如lightgcn,我们就可以自动的对GNN进行异构图扩展,使lightgcn变为relation-wise的lightgcn。
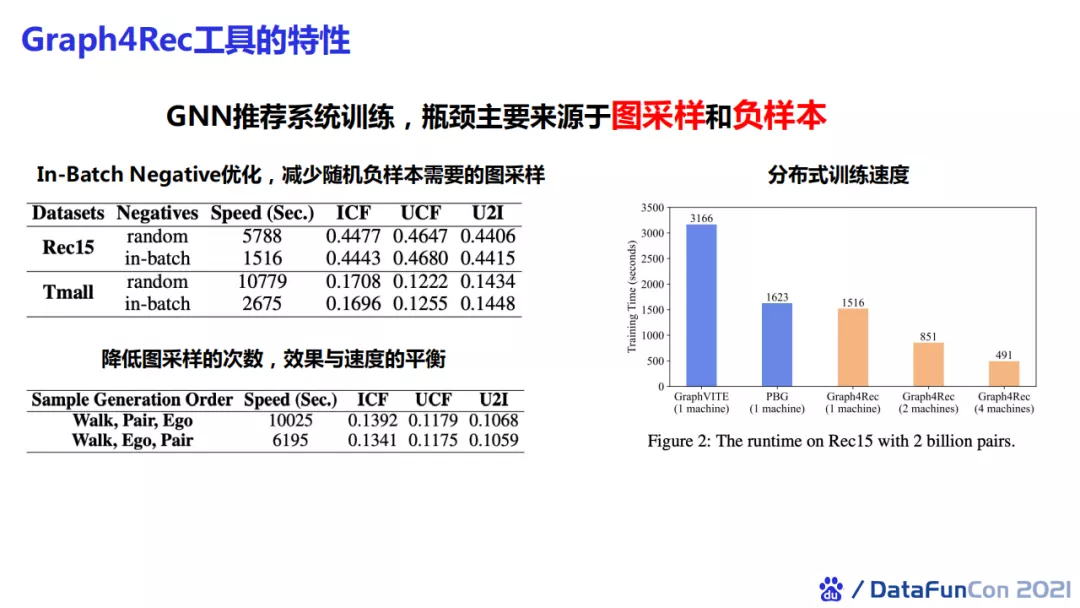
我们对工具进行了瓶颈分析,发现它主要集中在分布式训练中图采样和负样本构造中。我们可以通过使用In-Batch Negative的方法进行优化,即在batch内走负采样,减少通讯开销。这一优化可以使得训练速度提升四至五倍,而且在训练效果上几乎是无损的。此外,在图采样中我们可以通过对样本重构来降低采样的次数,得到两倍左右的速度提升,且训练效果基本持平。相比于市面上现有的分布式图表示工具,我们还可以实现单机、双机、四机甚至更多机器的扩展。
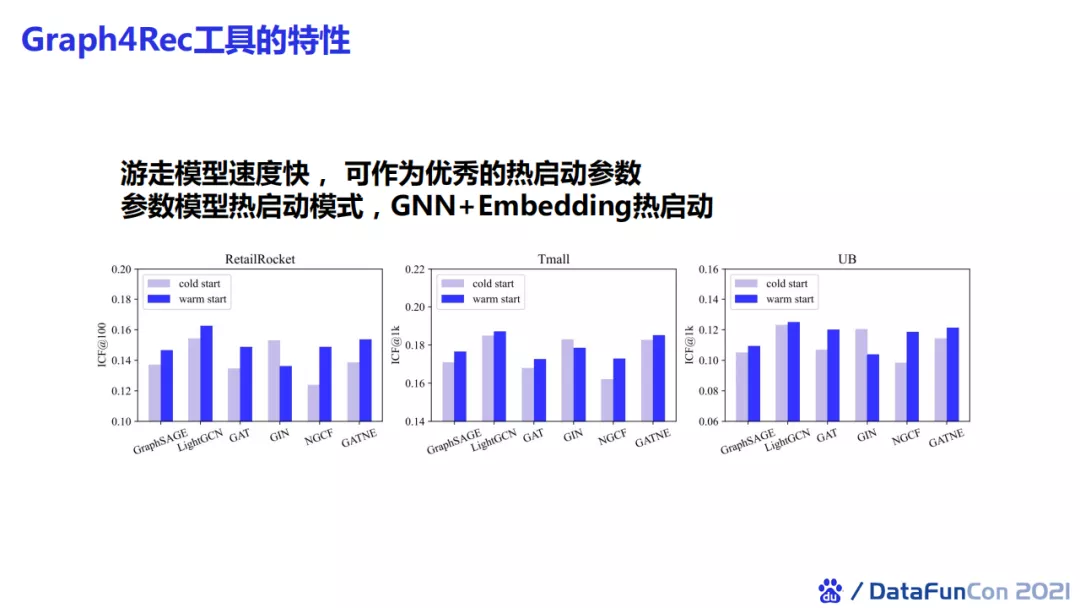
不仅如此,我们还发现游走类模型训练速度较快,比较适合作为优秀的热启动参数。具体地,我们可以先运行一次metapath2Vce算法,将训练得到的embedding作为初始化参数送入GNN中作为热启动的节点表示。我们发现这样做在效果上有一定的提升。
05 精彩问答
Q1:在特征在多卡之间传递的训练模式中,使用push和pull的方式通讯时间占比大概有多大?
A:通讯时间的占比挺大的。如果是特别简单的模型,如GCN等,那么使用这种方法训练,通讯时间甚至会比直接跑这个模型的训练时间还要久。所以这一方法适合复杂模型,即模型计算较多,且通讯中特征传递的数据量相比来说较小,这种情况下就比较适合这种分布式计算。
Q2:图学习中节点邻居数较多会不会�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%BB%84%E6%AD%A3%E6%9D%B0%E7%99%BE%E5%BA%A6%E5%9B%BE%E5%AD%A6%E4%B9%A0%E6%8A%80%E6%9C%AF%E4%B8%8E%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


