题目:zookeeper分布式锁
参考答案:
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。 对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁。 对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
获取分布式锁的流程
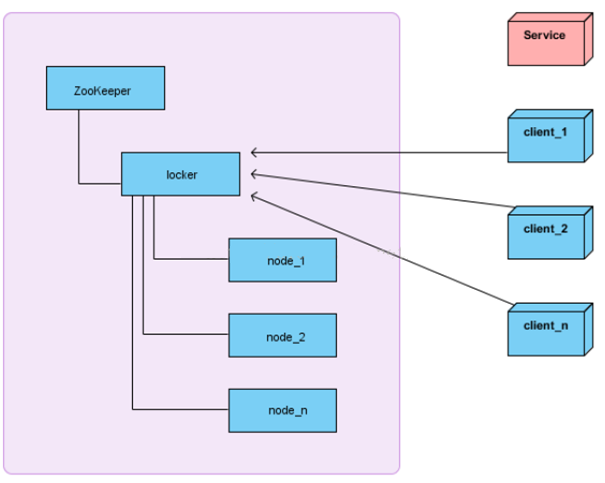
在获取分布式锁的时候在locker节点下创建临时顺序节点,释放锁的时候删除该临时节点。客户端调用createNode方法在locker下创建临时顺序节点, 然后调用getChildren(“locker”)来获取locker下面的所有子节点,注意此时不用设置任何Watcher。客户端获取到所有的子节点path之后,如果发现自己创建的节点在所有创建的子节点序号最小,那么就认为该客户端获取到了锁。如果发现自己创建的节点并非locker所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,然后对其调用exist()方法,同时对其注册事件监听器。之后,让这个被关注的节点删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是locker子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。当前这个过程中还需要许多的逻辑判断。
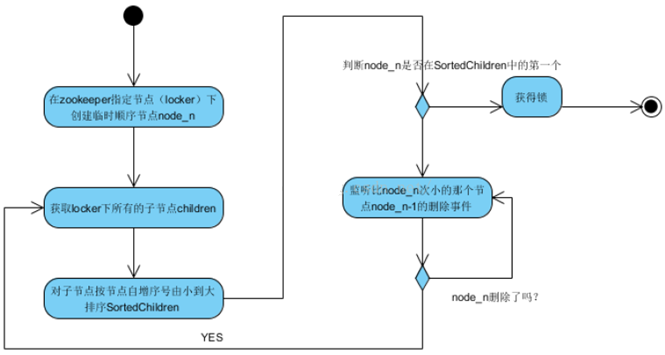
代码的实现主要是基于互斥锁,获取分布式锁的重点逻辑在于BaseDistributedLock,实现了基于Zookeeper实现分布式锁的细节。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E9%9D%A2%E8%AF%95/12.Zookeeper%E7%AF%87/12.1.9-zk%E7%9A%84%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


