Nifi-Apache Nifi-基础指南大全
介绍
Apache NiFi 是基于基于流量编程概念的数据流系统。它支持数据路由、转换和系统调停逻辑的强大且可扩展的定向图形。NiFi 拥有基于 Web 的用户界面,用于设计、控制、反馈和监控数据流。它在服务质量的几个方面具有高度可配置性,例如耐损性与保证交付、低延迟与高吞吐量以及基于优先级的排队。NiFi 为接收、分叉、加入克隆、修改、发送的所有数据提供细粒度的数据来源,最终在达到其配置的最终状态时丢弃。
有关系统要求、安装和配置的信息,请参阅系统管理员指南。安装 NiFi 后,使用支持的 Web 浏览器查看 UI。
浏览器支持
| 浏览器 | 版本 |
|---|---|
| Chrome | Current and Current - 1 |
| FireFox | Current and Current - 1 |
| Edge | Current and Current - 1 |
| Safari | Current and Current - 1 |
Current and Current - 1 表示该浏览器和前一个浏览器当前稳定版本中支持 UI。例如,如果当前的稳定版本为 45.X,则官方支持的版本将是 45.X 和 44.X。
对于 Safari,它发布主要版本的频率要低得多,当前版本和当前 - 1 仅表示两个最新版本。
支持的浏览器版本由 UI 使用的功能及其使用的依赖性驱动。UI 功能将针对支持的浏览器进行开发和测试。使用受支持的浏览器的任何问题应报告给阿帕奇 NiFi。
不受支持浏览器
虽然 UI 可能会在不受支持的浏览器中成功运行,但不会对它们进行主动测试。此外,UI 被设计为桌面体验,目前在移动浏览器中不支持。
以可变大小浏览器查看 UI
在大多数环境中,您的浏览器中都能看到所有的 UI。但是,UI 具有响应式设计,允许您根据需要在较小的浏览器或平板电脑环境中滚动浏览屏幕。
在浏览器宽度小于 800 像素、高度小于 600 像素的环境中,UI 的部分可能不可用。
术语
数据流管理器:数据流管理器 (DFM) 是 NiFi 用户,有权添加、删除和修改 NiFi 数据流的组件。
流文件:流文件表示 NiFi 中的单个数据。流文件由两个组件组成:流文件属性和流文件内容。内容是流文件所表示的数据。属性是提供有关数据的信息或上下文的特征;它们由关键值对组成。所有流文件都有以下标准属性:
- uuid: 一个通用唯一的标识符,将流文件与系统中的其他流文件区分开来。
- 文件名:一种可读的人类文件名,可在将数据存储到磁盘或外部服务时使用
- 路径: 将数据存储到磁盘或外部服务时可用于分级结构值,以便数据不存储在单个目录中
处理器:处理器是用于收听传入数据的 NiFi 组件:从外部来源拉取数据;向外部来源发布数据;以及路线、转换或从 FlowFiles 中提取信息。
关系:每个处理器都为它定义了零或更多关系。这些关系被命名为指示处理 FlowFile 的结果。处理器处理完 FlowFile 后,它会将流文件路由(或"转移")到其中一个关系。然后,DFM 能够将这些关系中的每一个连接到其他组件,以便指定 FlowFile 在每个潜在处理结果下应向下的位置。
连接:DFM 通过将 NiFi 工具栏的组件部分拖动到画布上,然后通过连接将组件连接在一起,从而创建自动数据流。每个连接由一个或多个关系组成。对于绘制的每个连接,DFM 可以确定应用于连接的哪些关系。这允许根据处理结果以不同的方式路由数据。每个连接都设有流文件队列。当 FlowFile 被转移到特定关系时,它被添加到属于关联连接的队列中。
控制器服务: 控制器服务是扩展点,在用户界面中由 DFM 添加和配置后,将在 NiFi 启动时启动并提供供其他组件(如处理器或其他控制器服务)使用的信息。几个组件使用的通用控制器服务是标准SSL文本服务。它提供配置钥匙店和/或信托商店属性一次,并在整个应用程序中重复使用该配置的能力。其理念是,控制器服务不是将此信息配置到每个可能需要这些信息的处理器中,而是将其提供给任何处理器根据需要使用。
报告任务: 报告任务在后台运行,以提供有关 NiFi 实例中发生情况的统计报告。DFM 根据需要在用户界面中添加和配置报告任务。常见的报告任务包括控制器统计报告任务、监视器使用报告任务、监视器记忆报告任务和标准冈利亚报告。
漏斗:漏斗是一个 NiFi 组件,用于将来自多个连接的数据合并为单个连接。
过程组:当数据流变得复杂时,它通常有利于在更高、更抽象的层次上推理数据流。NiFi 允许将多个组件(如处理器)组合到一个处理组中。然后,NiFi 用户界面使 DFM 能够轻松将多个流程组连接到逻辑数据流中,并允许 DFM 进入流程组,以便查看和操作流程组中的组件。
端口:使用一个或多个流程组构建的数据流需要一种方法来将流程组连接到其他数据流组件。这是通过使用端口实现的。DFM 可向流程组添加任意数量的输入端口和输出端口,并适当命名这些端口。
远程处理组:就像数据从处理组中传输到和移出一个处理组一样,有时需要将数据从 NiFi 的一个实例传输到另一个实例。虽然 NiFi 提供了从一个系统传输数据到另一个系统的许多不同机制,但如果将数据传输到 NiFi 的另一个实例,远程处理组通常是实现此目的的最简单方法。
公告: NiFi 用户界面提供了大量有关应用程序当前状态的监控和反馈。除了滚动统计和为每个组件提供的当前状态外,组件还可以报告公告。每当组件报告公告时,该组件上都会显示公告图标。系统级公告显示在页面顶部附近的状态栏上。使用鼠标在该图标上悬停将提供显示公告的时间和严重程度(解密、信息、警告、错误)以及公告消息的工具提示。所有组件的公告也可以在"全球菜单"中的公告板页面中查看和过滤。
模板:通常情况下,数据流由许多可以重复使用的子流组成。NiFi 允许 DFM 选择数据流的一部分(或整个数据流),并创建模板。此模板被赋予一个名称,然后可以像其他组件一样拖到画布上。因此,可以将多个组件组合在一起,形成更大的构建块,从而创建数据流。这些模板也可以作为XML导出并导入另一个 NiFi 实例,允许共享这些构建基块。
流.xml.gz:DFM 放在 NiFi 用户界面画布上的所有内容都实时写在一个称为流的文件中.xml.gz。默认情况下,此文件位于目录中。画布上所做的任何更改都会自动保存到此文件中,而用户无需单击"保存"按钮。此外,NiFi 在更新时会自动在存档目录中创建此文件的备份副本。您可以使用这些存档文件来回滚流量配置。为此,停止 NiFi,替换流.xml.gz所需的备份副本,然后重新启动 NiFi。在聚类环境中,停止整个 NiFi 聚类,替换其中一个节点*的流.xml.gz,并重新启动节点。从其他节点中取出流量.xml.gz。*确认节点以单节点组开始后,启动其他节点。替换的流量配置将在整个集群中同步。流.xml.gz和自动存档行为的名称和位置是可配置的。有关详细信息,请参阅系统管理员指南。nifi/conf
NIFI用户界面
NiFi UI 提供创建自动数据流的机制,以及可视化、编辑、监控和管理这些数据流。UI 可分为多个细分市场,每个细分市场负责应用程序的不同功能。此部分提供应用程序的屏幕截图,并突出显示 UI 的不同部分。稍后在文档中详细讨论了每个部分。
启动应用程序后,用户可以通过访问 Web 浏览器中的默认地址导航到 UI。默认配置生成具有完整系统管理特权的用户名和密码。有关系统安全的信息,请参阅系统管理员指南。https://localhost:8443/nifi
当 DFM 首次导航到 UI 时,会提供一张空白画布,用于构建数据流:
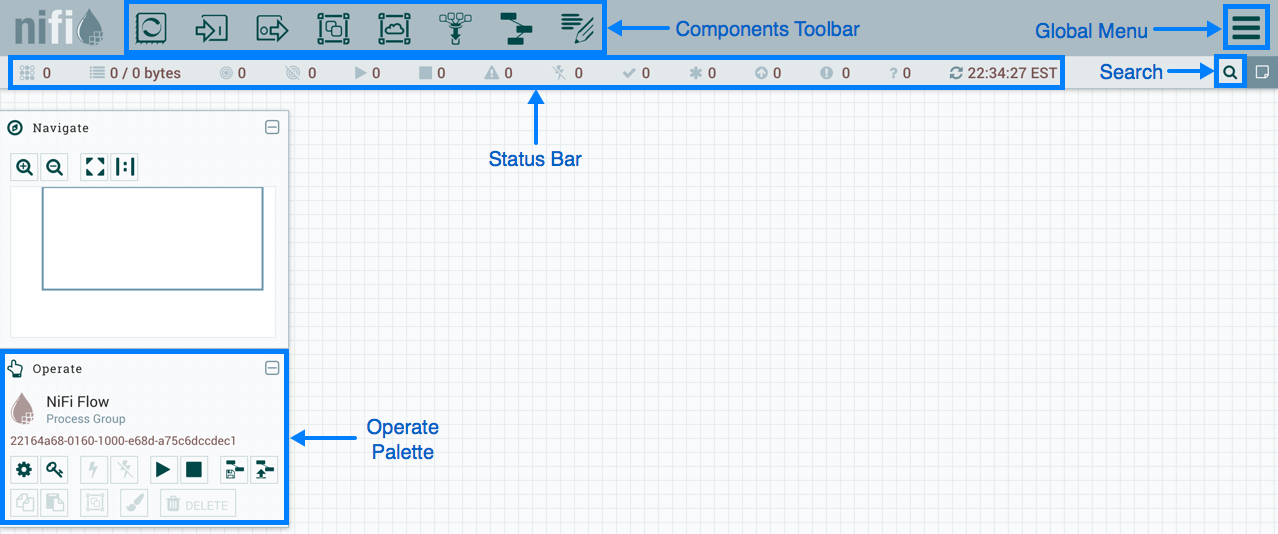
组件工具栏穿过屏幕的左上半部分。它由可以拖动到画布上的组件组成,以构建您的数据流。在构建数据流时,每个组件都进行了更详细的描述。
状态栏位于组件工具栏下。状态栏提供有关当前在流中活跃的线程数、流中目前存在的数据量、每个状态的画布上存在多少远程进程组(传输、不传输)、每个状态的画布上有多少处理器(停止、运行、无效、禁用)的信息 每个状态的画布上有多少版本的过程组(最新、本地修改、过时、本地修改和陈旧、同步故障)以及所有这些信息最后刷新的时间戳。此外,如果对 NiFi 实例进行聚类,则状态条显示组中有多少节点以及当前连接了多少节点。
操作调色板位于屏幕的左侧。它由 DFM 用于管理流量的按钮以及管理用户访问和配置系统属性的管理员(如应向应用程序提供多少系统资源)组成。
画布的右侧是搜索和全球菜单。有关搜索的更多信息,请参阅数据流中的搜索组件。“全球菜单"包含允许您操作画布上现有组件的选项:
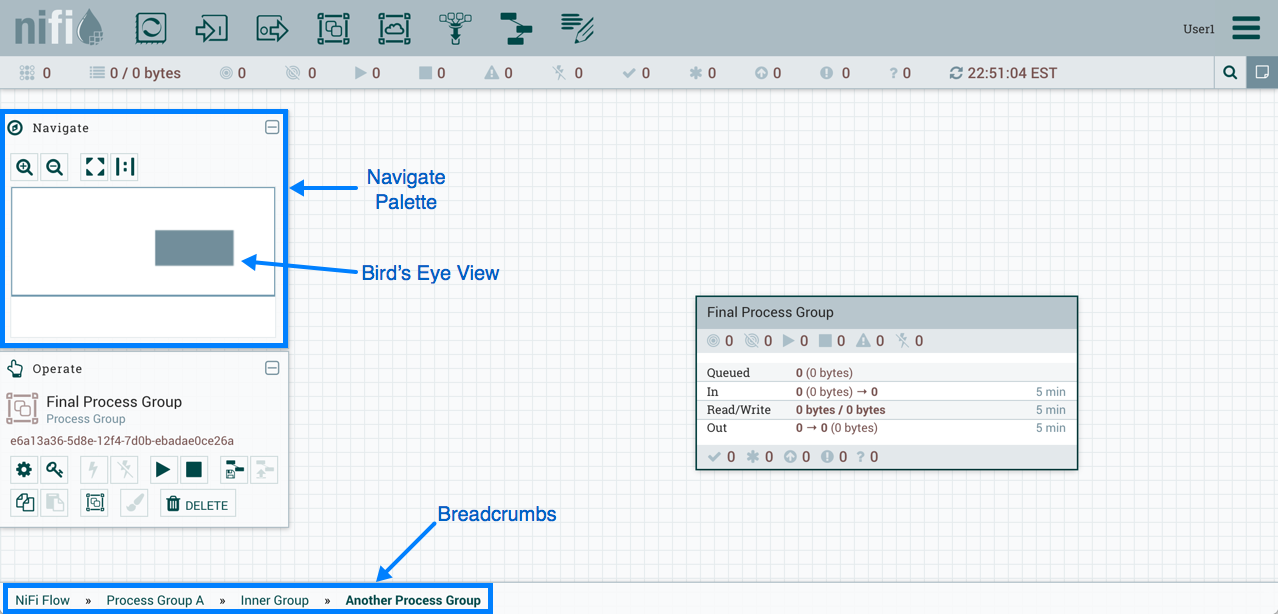
此外,UI 还具有一些功能,让您能够轻松地在画布周围导航。您可以使用导航调色板在画布周围平移,并放大和缩小。数据流的"鸟瞰图"提供了数据流的高级别视图,并允许您平移数据流的很大一部分。您还可以在屏幕底部找到面包屑。当您导航到和离开流程组时,面包屑显示流中的深度,以及您输入的每个流程组以达到此深度。面包屑中列出的每个流程组都是一个链接,将带您回到流中的水平。
通过多租户授权访问 UI
多租户授权使多个用户组(租户)能够命令、控制和观察数据流的不同部分,并具有不同级别的授权。当经过验证的用户尝试查看或修改 NiFi 资源时,系统会检查用户是否具有执行该操作的特权。这些特权由政策定义,您可以将系统范围或应用到各个组件中。这意味着从数据流管理器的角度来看,一旦您访问 NiFi 画布,一系列功能是可见的,并且根据分配给您的特权可供您使用。
可用的全球访问政策包括:
| 政策 | 特权 |
|---|---|
| 查看 UI | 允许用户查看 UI |
| 访问控制器 | 允许用户查看和修改控制器,包括集群中的报告任务、控制器服务和节点 |
| 查询来源 | 允许用户提交来源搜索并请求均匀血统 |
| 访问受限制的组件 | 允许用户创建/修改受限组件,前提是其他权限足够。受限组件可能指示需要哪些特定权限。可授予特定限制的权限,或授予任何限制。如果无论限制如何,都授予许可,用户可以创建/修改所有受限组件。 |
| 访问所有策略 | 允许用户查看和修改所有组件的策略 |
| 访问用户/组 | 允许用户查看和修改用户组 |
| 检索站点到站点的详细信息 | 允许其他 NiFi 实例检索站点到站点的详细信息 |
| 查看系统诊断 | 允许用户查看系统诊断 |
| 代理用户请求 | 允许代理机器代表他人发送请求 |
| 访问计数器 | 允许用户查看和修改计数器 |
可用的组件级别访问策略包括:
| 政策 | 特权 |
|---|---|
| 查看组件 | 允许用户查看组件配置详细信息 |
| 修改组件 | 允许用户修改组件配置详细信息 |
| 查看来源 | 允许用户查看此组件生成的起源事件 |
| 查看数据 | 允许用户在出站连接中的流文件队列中以及通过源事件查看该组件的元数据和内容 |
| 修改数据 | 允许用户在出站连接中清空流文件队列,并通过源事件提交重播 |
| 查看策略 | 允许用户查看可以查看和修改组件的用户列表 |
| 修改策略 | 允许用户修改可以查看和修改组件的用户列表 |
| 通过站点到站点检索数据 | 允许端口接收来自 NiFi 实例的数据 |
| 通过站点到站点发送数据 | 允许端口从 NiFi 实例发送数据 |
如果您无法查看或修改 NiFi 资源,请联系您的系统管理员或查看系统管理员指南中的配置用户和访问策略以获取更多信息。
登录
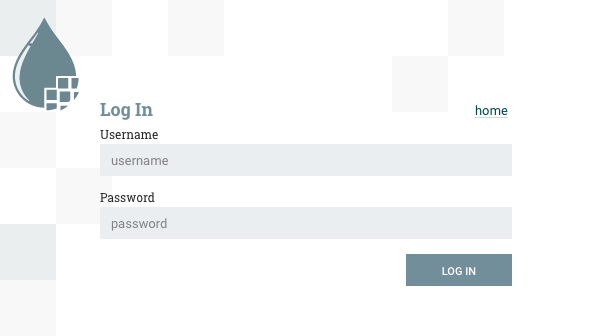
如果 NiFi 被配置为安全运行,用户将能够请求访问数据流。有关配置 NiFi 以安全运行的信息,请参阅系统管理员指南。如果 NiFi 支持匿名访问,用户将获得相应的访问权限,并有权登录。
单击"登录"链接将打开页面中的日志。如果用户正在登录其用户名/密码,则会向用户出示一份表格。如果 NiFi 未配置为支持匿名访问,并且用户正在登录其用户名/密码,则会立即将其发送到绕过画布的登录表单。
构建数据流
DFM 能够使用 NiFi UI 构建自动数据流。只需将组件从工具栏拖动到画布上,配置组件以满足特定需求,并将组件连接在一起。
将组件添加到画布中
上面的用户界面部分概述了 UI 的不同部分,并指出了组件工具栏。此部分查看该工具栏中的每个组件:

 处理器:处理器是最常用的组件,因为它负责数据入口、出口、路由和操纵。有许多不同类型的处理器。事实上,这是 NiFi 中非常常见的扩展点,这意味着许多供应商可以实施自己的处理器来执行其使用案例所需的任何功能。当处理器被拖到画布上时,向用户提供对话,以选择要使用的处理器类型:
处理器:处理器是最常用的组件,因为它负责数据入口、出口、路由和操纵。有许多不同类型的处理器。事实上,这是 NiFi 中非常常见的扩展点,这意味着许多供应商可以实施自己的处理器来执行其使用案例所需的任何功能。当处理器被拖到画布上时,向用户提供对话,以选择要使用的处理器类型:
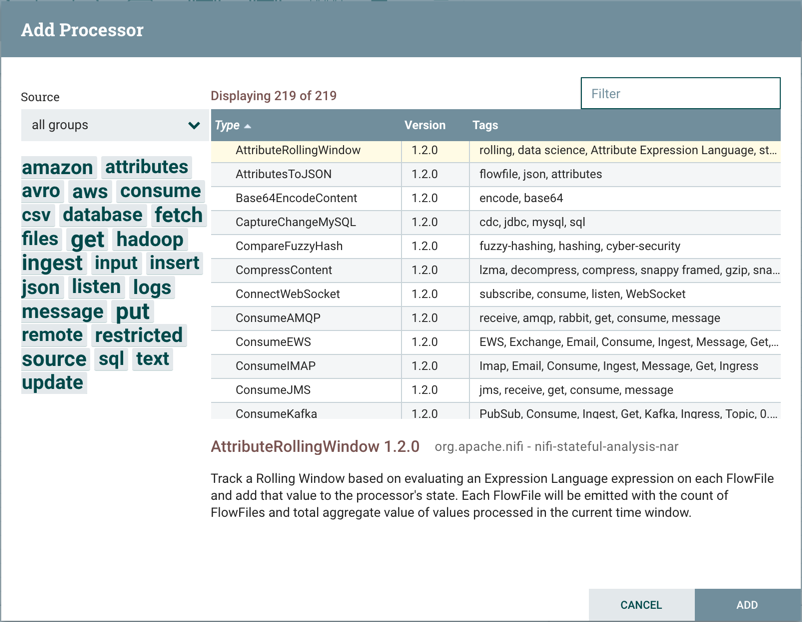
在右上角,用户能够根据处理器类型或与处理器相关的标签筛选列表。处理器开发人员能够将标签添加到其处理器中。这些标签用于此对话进行筛选,并显示在标签云的左侧。与特定标签一起存在的处理器越多,标签在标签云中显示的标记就越大。单击云中的标签将仅将可用的处理器过滤到包含该标签的处理器。如果选择多个标签,则只显示包含所有这些标签的处理器。例如,如果我们只显示那些允许我们收件文件的处理器,我们可以同时选择标签和标签:files``ingest
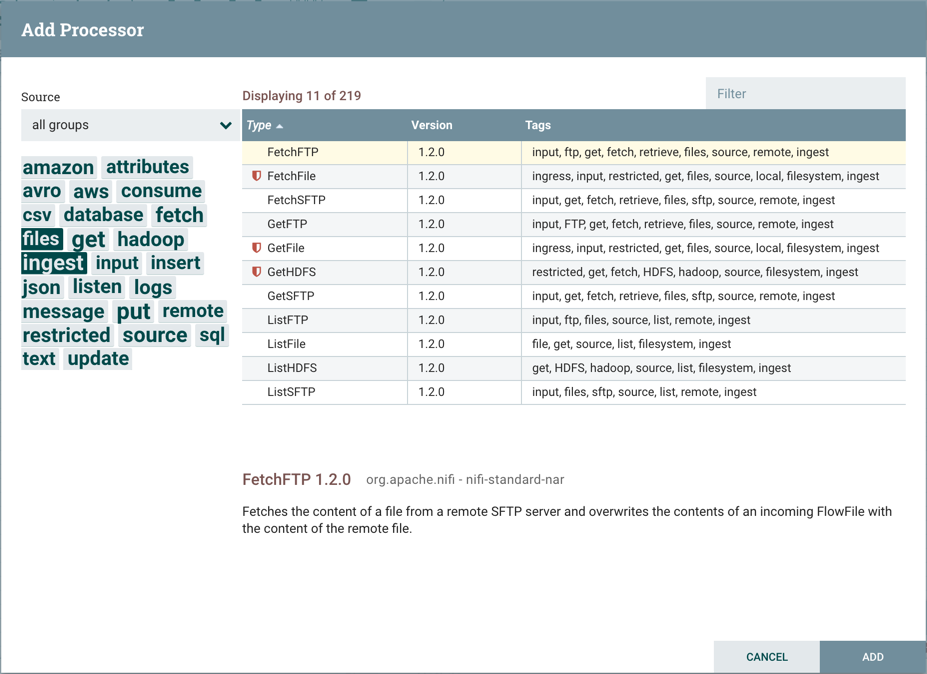
受限组件将标有
 图标旁边他们的名字。这些组件可用于执行操作员通过 NiFi REST API/UI 提供的任意未经消毒的代码,或者可用于使用 NiFi 操作系统凭据获取或更改 NiFi 主机系统上的数据。这些组件可能由其他授权的 NiFi 用户用于超越应用程序的预期使用范围、升级特权,或者可能暴露有关 NiFi 过程或主机系统内部的数据。所有这些功能都应被视为特权,管理员应了解这些功能,并明确启用这些功能,以便为受信任的用户提供子集。在允许用户创建和修改受限组件之前,必须授予用户访问权限。悬停在
图标将显示受限组件所需的特定权限。无论限制如何,都可以分配权限。在这种情况下,用户将有权访问所有受限组件。或者,还可以为用户分配访问特定限制的权限。如果用户已获得组件要求的所有限制,则如果获得足够的权限,他们将有权访问该组件。有关更多信息,请参阅使用多租户授权和版本流量中受限组件访问 UI。
图标旁边他们的名字。这些组件可用于执行操作员通过 NiFi REST API/UI 提供的任意未经消毒的代码,或者可用于使用 NiFi 操作系统凭据获取或更改 NiFi 主机系统上的数据。这些组件可能由其他授权的 NiFi 用户用于超越应用程序的预期使用范围、升级特权,或者可能暴露有关 NiFi 过程或主机系统内部的数据。所有这些功能都应被视为特权,管理员应了解这些功能,并明确启用这些功能,以便为受信任的用户提供子集。在允许用户创建和修改受限组件之前,必须授予用户访问权限。悬停在
图标将显示受限组件所需的特定权限。无论限制如何,都可以分配权限。在这种情况下,用户将有权访问所有受限组件。或者,还可以为用户分配访问特定限制的权限。如果用户已获得组件要求的所有限制,则如果获得足够的权限,他们将有权访问该组件。有关更多信息,请参阅使用多租户授权和版本流量中受限组件访问 UI。
单击"添加"按钮或双击处理器类型将按下该处理器的位置将选定的处理器添加到画布中。
| 对于添加到画布上的任何组件,可以用鼠标选择它,并在画布上移动它。此外,可以通过按住"移位"密钥并选择每个项目,或者按住"移位"密钥,在所需的组件周围拖动选择框,同时选择多个项目。 | |
|---|---|
将处理器拖到画布上后,您可以通过右键单击处理器并从上下文菜单中选择选项来与它进行交互。上下文菜单中可供您使用的选项因分配给您的特权而异。
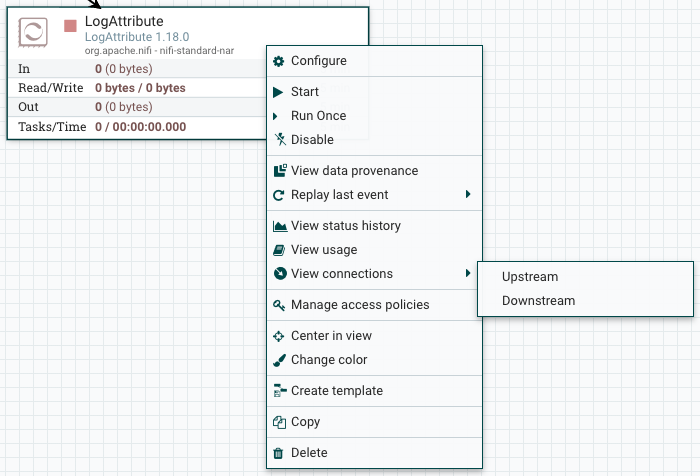
虽然上下文菜单中可用的选项各不相同,但通常在您拥有与处理器合作的完整特权时,可提供以下选项:
- 配置:此选项允许用户建立或更改处理器的配置(参见配置处理器)。
| 对于处理器、端口、远程处理组、连接和标签,可以通过双击所需的组件来打开配置对话。 | |
|---|---|
- 启动或停止:此选项允许用户启动或停止处理器:选项是"开始"或"停止”,具体取决于处理器的当前状态。
- 运行一次:此选项允许用户运行选定的处理器正好一次。如果处理器无法执行(例如,没有传入的流量文件或外向连接已施加背压),则处理器将不会触发。执行设置适用 - 即主节点和所有节点设置将只在主节点上运行处理器一次或在每个节点上运行一次。仅适用于定时器驱动和CRON 驱动的调度策略。
- 启用或禁用:此选项允许用户启用或禁用处理器:选项将启用或禁用,具体取决于处理器的当前状态。
- 查看数据来源:此选项显示 NiFi 数据证明表,其中有关流文件的数据来源事件的信息通过该处理器路由(参见数据证明)。
- 查看状态历史记录:此选项会随着时间的推移打开处理器统计信息的图形表示。
- 查看使用情况:此选项将用户带到处理器的使用文档。
- 查看连接→上流:此选项允许用户查看并"跳转"正在进入处理器的上游连接。当处理器连接到其他处理组和出组时,这尤其有用。
- 查看连接→向:此选项允许用户查看并跳转正在从处理器中流出的下游连接。当处理器连接到其他处理组和出组时,这尤其有用。
- 中心视图: 此选项将画布的视图集中在给定的处理器上。
- 更改颜色:此选项允许用户更改处理器的颜色,从而使大流量的可视化管理更加容易。
- 创建模板:此选项允许用户从选定的处理器创建模板。
- 复制:此选项将选定的处理器副本放在剪贴板上,以便通过右键单击画布并选择粘贴,将其粘贴在画布上的其他地方。复制/粘贴操作也可以使用键击 Ctrl-C (命令-C) 和 Ctrl-V (命令-V) 完成。
- 删除: 此选项允许 DFM 从画布中删除处理器。
 输入端口:输入端口提供了将数据传输到流程组的机制。当输入端口被拖到画布上时,DFM 会提示其命名端口。流程组中的所有端口必须具有唯一名称。
输入端口:输入端口提供了将数据传输到流程组的机制。当输入端口被拖到画布上时,DFM 会提示其命名端口。流程组中的所有端口必须具有唯一名称。
所有组件仅存在于流程组中。当用户最初导航到 NiFi 页面时,用户被放置在根过程组中。如果输入端口被拖入根处理组,输入端口提供了一个机制,通过站点到站点接收来自 NiFi 的远程实例的数据。在这种情况下,如果 NiFi 被配置为安全运行,则可以配置输入端口以限制对相应用户的访问。有关配置 NiFi 以安全运行的信息,请参阅系统管理员指南。
 输出端口:输出端口提供了一个机制,将数据从流程组传输到流程组以外的目的地。当输出端口被拖到画布上时,提示 DFM 命名端口。流程组中的所有端口必须具有唯一名称。
输出端口:输出端口提供了一个机制,将数据从流程组传输到流程组以外的目的地。当输出端口被拖到画布上时,提示 DFM 命名端口。流程组中的所有端口必须具有唯一名称。
如果输出端口被拖入根处理组,输出端口提供了一个机制,通过站点到站点向 NiFi 的远程实例发送数据。在这种情况下,端口充当队列。当 NiFi 的远程实例从端口中拉取数据时,该数据将从传入连接的队列中删除。如果 NiFi 被配置为安全运行,输出端口可以进行配置,以限制对适当用户的访问。有关配置 NiFi 以安全运行的信息,请参阅系统管理员指南。
 流程组:流程组可用于逻辑地对一组组件进行分组,以便数据流更容易理解和维护。当流程组被拖到画布上时,会提示 DFM 命名流程组。然后,流程组将嵌套在该父组中。
流程组:流程组可用于逻辑地对一组组件进行分组,以便数据流更容易理解和维护。当流程组被拖到画布上时,会提示 DFM 命名流程组。然后,流程组将嵌套在该父组中。
将流程组拖到画布上后,您可以通过右键单击流程组并从上下文菜单中选择选项来与它进行交互。上下文菜单中可供您使用的选项因分配给您的特权而异。
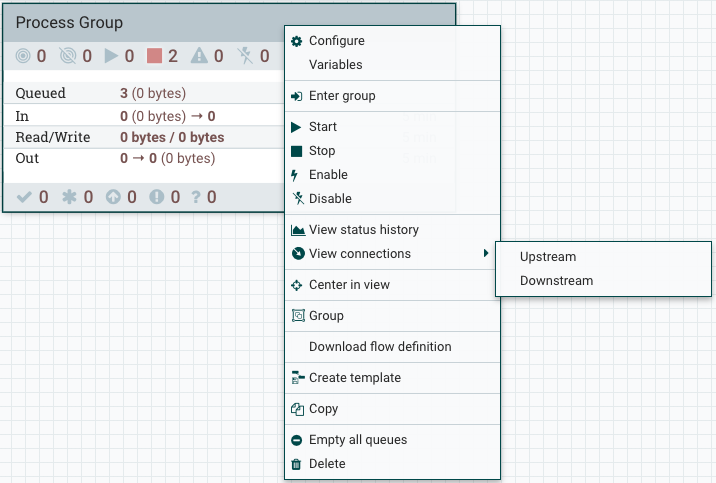
虽然上下文菜单中可用的选项各不相同,但通常在您拥有与流程组合作的完整特权时,可提供以下选项:
- 配置:此选项允许用户建立或更改流程组的配置。
- 变量:此选项允许用户在 NiFi UI 中创建或配置变量。
- 输入组:此选项允许用户输入过程组。
| 也可以双击流程组以进入该组。 | |
|---|---|
- 开始: 此选项允许用户启动过程组。
- 停止: 此选项允许用户停止进程组。
- 启用:此选项允许用户启用流程组中的所有处理器。
- 禁用:此选项允许用户禁用处理组中的所有处理器。
- 查看状态历史记录:此选项会随着时间的推移打开流程组统计信息的图形表示。
- 查看连接→上流:此选项允许用户查看并"跳转"进入流程组的上游连接。
- 查看连接→:此选项允许用户查看并跳转正在退出流程组的下游连接。
- 中心视图:此选项将画布的视图集中在给定过程组上。
- 组:此选项允许用户创建包含选定流程组和画布上选定的任何其他组件的新流程组。
- 下载流量定义:此选项允许用户下载流程组的流量定义作为 JSON 文件。该文件可以用作备份或导入到NIFI注册处使用NiFi CLI。(注:如果为版本化过程组选择"下载流量定义",则下载中没有版本信息。换句话说,无论流程组是否被修改,JSON 文件的生成内容都是相同的。
- 创建模板:此选项允许用户从选定的进程组创建模板。
- 复制:此选项将选定过程组的副本放在剪贴板上,以便通过右键单击画布并选择粘贴,将其粘贴在画布上的其他地方。复制/粘贴操作也可以使用键击 Ctrl-C (命令-C) 和 Ctrl-V (命令-V) 完成。
- 清空所有队列:此选项允许用户清空所选过程组中的所有队列。请求时等待的所有连接中的所有流文件将被删除。
- 删除: 此选项允许 DFM 删除进程组。
 远程过程组: 远程进程组出现并行为类似于进程组。但是,远程处理组 (RPG) 引用了 NiFi 的远程实例。当 RPG 被拖到画布上而不是被提示为名称时,DFM 会被提示为远程 NiFi 实例的 URL。如果远程 NiFi 是聚类实例,则建议添加两个或多个聚类节点网市,以便即使其中一个节点不可用,也可以进行初始连接。多个网线可以以逗号分离格式指定。
远程过程组: 远程进程组出现并行为类似于进程组。但是,远程处理组 (RPG) 引用了 NiFi 的远程实例。当 RPG 被拖到画布上而不是被提示为名称时,DFM 会被提示为远程 NiFi 实例的 URL。如果远程 NiFi 是聚类实例,则建议添加两个或多个聚类节点网市,以便即使其中一个节点不可用,也可以进行初始连接。多个网线可以以逗号分离格式指定。
当数据通过 RPG 传输到 NiFi 的聚类实例时,RPG 将首先连接到远程实例,该实例的 URL 被配置,以确定组集中的哪些节点以及每个节点的繁忙程度。然后,此信息用于加载平衡被推入每个节点的数据。然后定期询问远程实例,以确定从组落到组中或添加到组的任何节点的信息,并根据每个节点的负载重新计算负载平衡。有关更多信息,请参阅站点到站点的部分。
将远程进程组拖到画布上后,您可以通过右键单击远程进程组并从上下文菜单中选择选项来与它进行交互。菜单中可供您选择的选项因分配给您的特权而异。
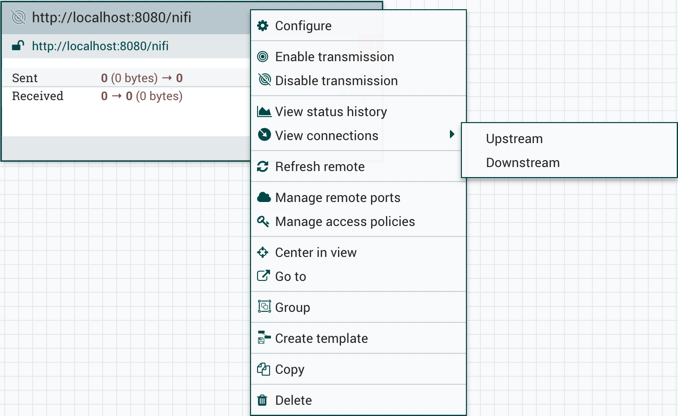
当您拥有与远程处理组合作的全部特权时,通常可提供以下选项:
- 配置:此选项允许用户建立或更改远程进程组的配置。
- 启用传输:使 NiFi 实例之间的数据传输工作活跃(参见远程处理组传输)。
- 禁用传输:禁用 NiFi 实例之间的数据传输。
- 查看状态历史记录:此选项会随着时间的推移打开远程进程组统计信息的图形表示。
- 查看连接→上流:此选项允许用户查看并"跳转"进入远程进程组的上游连接。
- 查看连接→:此选项允许用户查看并跳转正在退出远程进程组的下游连接。
- 刷新远程:此选项刷新远程 NiFi 实例状态的视图。
- 管理远程端口:此选项允许用户查看远程处理组连接到的 NiFi 远程实例上存在的输入端口和/或输出端口。请注意,如果站点到站点配置是安全的,则只能看到连接 NiFi 访问的端口。
- 中心视图: 此选项将画布的视图集中在给定的远程进程组上。
- 去: 此选项打开浏览器的新选项卡中远程 NiFi 实例的视图。请注意,如果站点到站点配置是安全的,则用户必须访问远程 NiFi 实例才能查看该实例。
- 组:此选项允许用户创建包含选定的远程进程组和画布上选定的任何其他组件的新流程组。
- 创建模板:此选项允许用户从选定的远程进程组创建模板。
- 复制:此选项将选定过程组的副本放在剪贴板上,以便通过右键单击画布并选择粘贴,将其粘贴在画布上的其他地方。复制/粘贴操作也可以使用键击 Ctrl-C (命令-C) 和 Ctrl-V (命令-V) 完成。
- 删除: 此选项允许 DFM 从画布中删除远程进程组。
 漏斗:漏斗用于将来自多个连接的数据合并为单个连接。这有两个优点。首先,如果许多连接创建与同一目的地,画布可能会变得杂乱无章,如果这些连接必须跨越一个大的空间。通过将这些连接漏斗到单个连接中,可以绘制该连接来跨越该大空间。其次,可与 FlowFile 优先级器配置连接。来自多个连接的数据可以漏斗到单个连接中,从而提供对该连接上的所有数据进行优先排序的能力,而不是独立地对每个连接上的数据进行排序。
漏斗:漏斗用于将来自多个连接的数据合并为单个连接。这有两个优点。首先,如果许多连接创建与同一目的地,画布可能会变得杂乱无章,如果这些连接必须跨越一个大的空间。通过将这些连接漏斗到单个连接中,可以绘制该连接来跨越该大空间。其次,可与 FlowFile 优先级器配置连接。来自多个连接的数据可以漏斗到单个连接中,从而提供对该连接上的所有数据进行优先排序的能力,而不是独立地对每个连接上的数据进行排序。
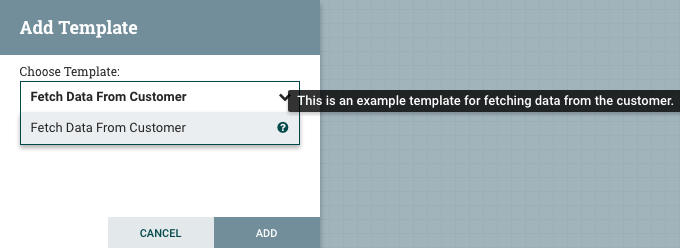
 模板:模板可以由来自流量部分的 DFM 创建,也可以从其他数据流导入。这些模板为快速创建复杂流提供了更大的构建基块。当模板被拖到画布上时,DFM 将提供对话,以选择添加到画布中的模板:
模板:模板可以由来自流量部分的 DFM 创建,也可以从其他数据流导入。这些模板为快速创建复杂流提供了更大的构建基块。当模板被拖到画布上时,DFM 将提供对话,以选择添加到画布中的模板:
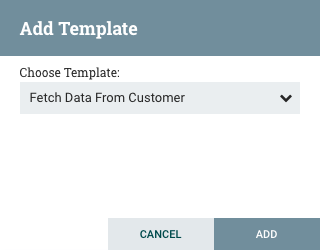
单击下拉框显示所有可用的模板。任何创建带有描述的模板都会显示问号图标,表明有更多的信息。用鼠标悬停在图标上将显示此描述:
 标签: 标签用于向数据流的某些部分提供文档。当标签被丢弃到画布上时,它创建时具有默认大小。然后,通过在右下角拖动手柄来调整标签的调整。最初创建时,标签没有文本。标签的文本可以通过右键点击标签和选择添加。
标签: 标签用于向数据流的某些部分提供文档。当标签被丢弃到画布上时,它创建时具有默认大小。然后,通过在右下角拖动手柄来调整标签的调整。最初创建时,标签没有文本。标签的文本可以通过右键点击标签和选择添加。Configure
组件版本
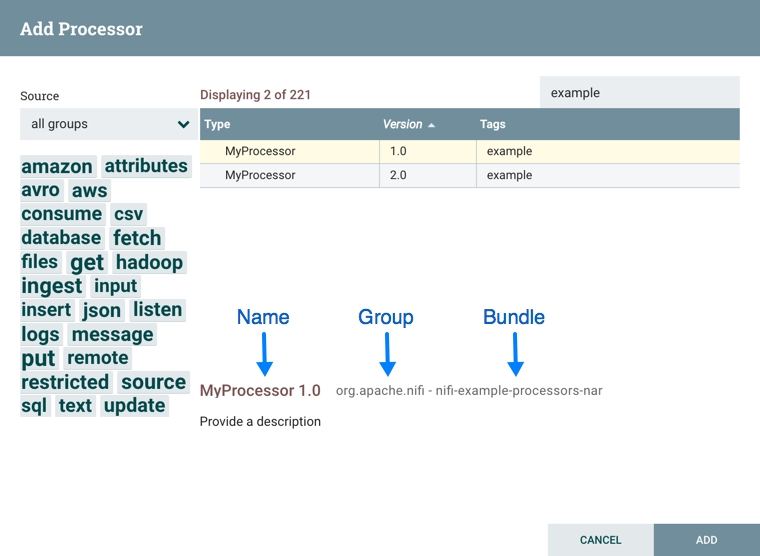
您可以访问有关处理器、控制器服务和报告任务版本的信息。当您在具有多个 NiFi 实例的聚类环境中运行不同版本的组件或已升级到处理器的新版本时,这尤其有用。添加处理器、添加控制器服务和添加报告任务对话包括识别组件版本的列,以及组件的名称、创建组件的组织或组以及包含组件的 NAR 捆绑包。
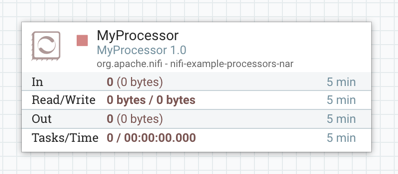
画布上显示的每个组件也包含此信息。
分拣和筛选组件
添加组件时,您可以根据源源对版本编号或筛选进行排序。
要根据版本进行排序,请单击版本列以显示升序或降版顺序。
要根据源组进行筛选,请单击"添加组件"对话左上左下侧的源向下向下,然后选择要查看的组。
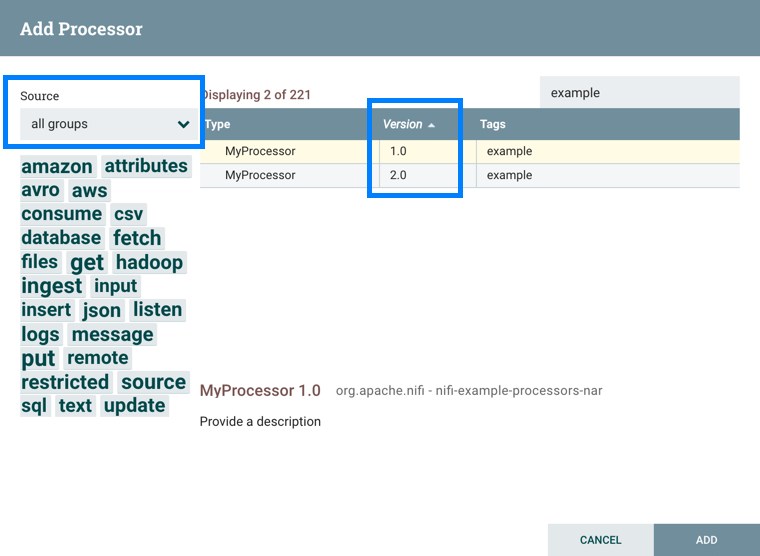
更改组件版本
要更改组件版本,执行以下步骤。
-
右键单击画布上的组件以显示配置选项。
-
选择更改版本。
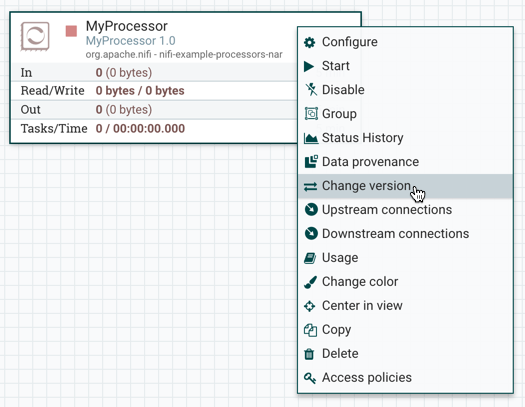
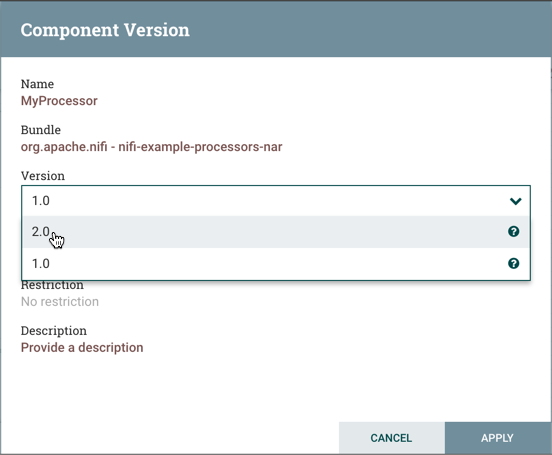
-
在组件版本对话中,选择要从"版本下拉"菜单中运行的版本。
了解版本依赖性
在配置组件时,还可以查看有关版本依赖性的信息。
- 右键单击组件并选择配置以显示组件的配置对话。
- 单击属性选项卡。
- 单击信息图标查看任何版本依赖性信息。
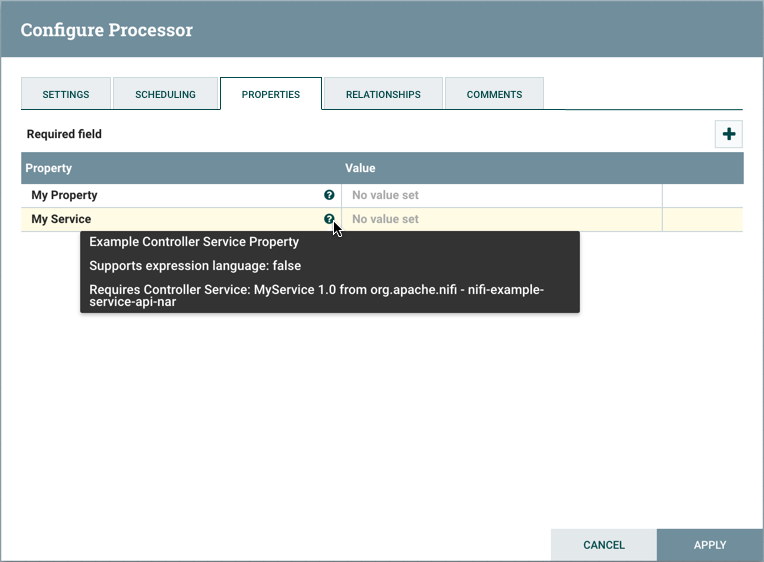
在以下示例中,MyProcesor 版本 1.0 与控制器服务标准服务版本 1.0 进行了正确的配置:
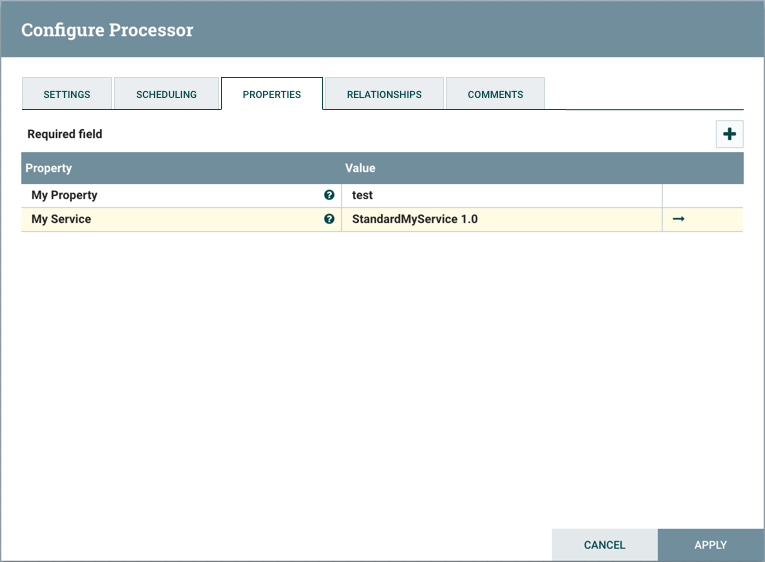
如果 My 处理器的版本更改为不兼容的版本(我的处理器 2.0),则处理器上将显示验证错误:
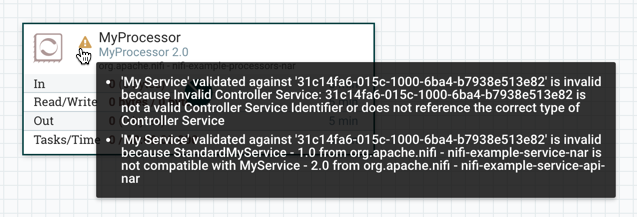
并且由于服务不再有效,处理器的控制器服务配置中将显示错误消息:
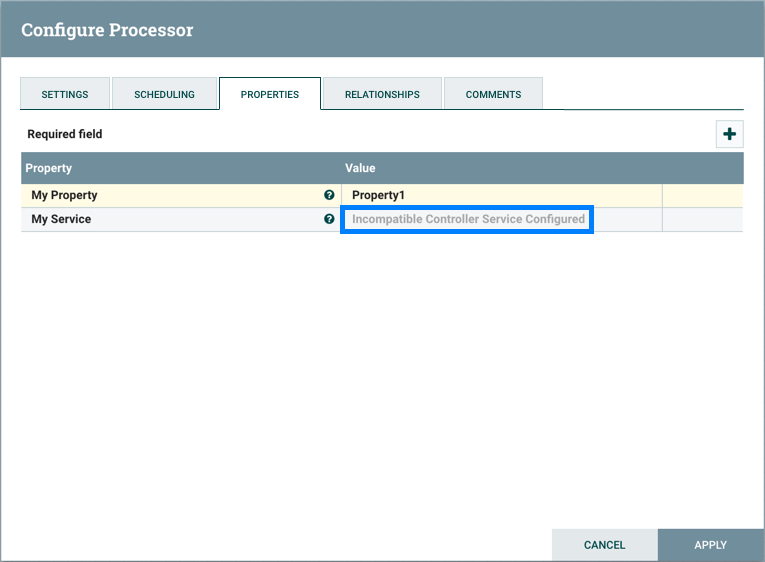
配置处理器
要配置处理器,请右键单击处理器并从上下文菜单中选择选项。或者,只需双击处理器。配置对话以四个不同的选项卡打开,每个选项卡都在下面讨论。完成处理器配置后,您可以单击"应用"应用或单击"取消"来应用更改。Configure
请注意,在处理器启动后,为处理器显示的上下文菜单不再具有选项,而是具有选项。处理器配置在处理器运行时无法更改。您必须首先停止处理器并等待其所有活动任务完成,然后再重新配置处理器。Configure``View Configuration
请注意,输入某些控制字符不被支持,并且在输入时会自动过滤掉。以下字符和任何未修置的 Unicode 代理代码点将不会保留在任何配置中:
[#x0], [#x1], [#x2], [#x3], [#x4], [#x5], [#x6], [#x7], [#x8], [#xB], [#xC], [#xE], [#xF], [#x10], [#x11], [#x12], [#x13], [#x14], [#x15], [#x16], [#x17], [#x18], [#x19], [#x1A], [#x1B], [#x1C], [#x1D], [#x1E], [#x1F], [#xFFFE], [#xFFFF]
设置选项卡
处理器配置对话中的第一个选项卡是"设置"选项卡:
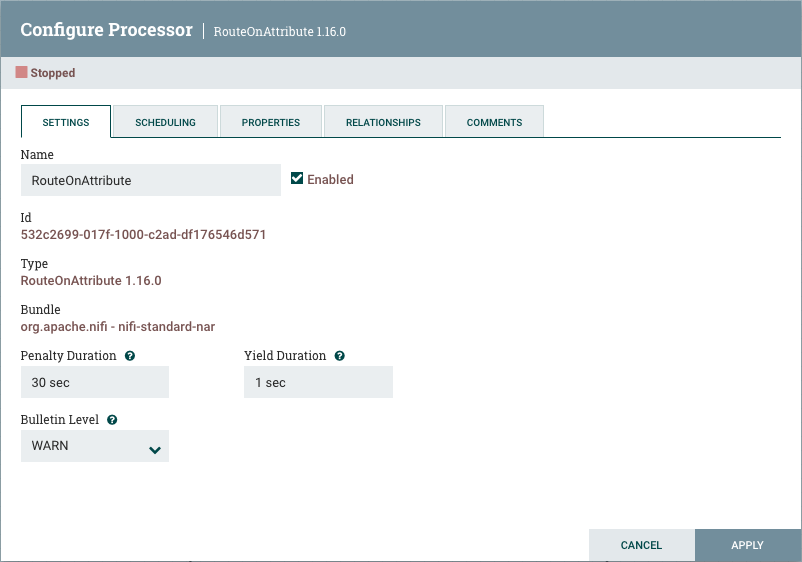
此选项卡包含几个不同的配置项目。首先,它允许 DFM 更改处理器的名称。默认情况下,处理器的名称与处理器类型相同。处理器名称旁边是一个复选框,指示处理器是否已启用。当处理器添加到画布中时,启用了该处理器。如果处理器已禁用,则无法启动。禁用状态用于表示当一组处理器启动时,例如当 DFM 启动整个处理组时,应排除此(禁用)处理器。
在名称配置下面,处理器的独特标识符与处理器的类型和 NAR 捆绑包一起显示。这些值无法修改。
接下来是两个用于配置"惩罚持续时间"和"收益持续时间"的对话。在处理数据(FlowFile)的正常过程中,可能会发生表明此时无法处理数据的事件,但数据可能稍后可以处理。当这种情况发生时,处理器可能会选择惩罚流文件。这将阻止流文件在一段时间内被处理。例如,如果处理器要将数据推送至远程服务,但远程服务已具有与处理器指定的文件名相同的文件,则处理器可能会惩罚 FlowFile。“惩罚期限"允许 DFM 指定流文件应受处罚的时间。默认值是 。30 seconds
同样,处理器可以确定存在某些情况,因此处理器不能再取得任何进展,而不管它正在处理的数据如何。例如,如果处理器要将数据推送至远程服务,而该服务没有响应,则处理器无法取得任何进展。因此,处理器应"产生”,这将阻止处理器在一段时间内被安排运行。该时间段通过设置"收益持续时间"来指定。默认值是 。1 second
设置选项卡左侧的最后一个可配置选项是"公告"级别。每当处理器写到其日志时,处理器也会生成公告。此设置表示应在用户界面中显示的最低级别的公告。默认情况下,公告级别设置为,这意味着它将显示所有警告和错误级别的公告。WARN
“设置"选项卡的右侧包含"自动终止关系"部分。处理器定义的每个关系都列在这里,以及其描述。为了使处理器被视为有效且能够运行,处理器定义的每个关系必须连接到下游组件或自动终止。如果关系是自动终止的,则任何路由到该关系的 FlowFile 将从流中删除,其处理被视为已完成。已连接到下游组件的任何关系都不能自动终止。必须首先从使用该关系的任何连接中删除该关系。此外,对于选择自动终止的任何关系,如果将关系添加到连接中,自动终止状态将被清除(关闭)。
调度选项卡
处理器配置对话中的第二个选项卡是"调度选项卡”:
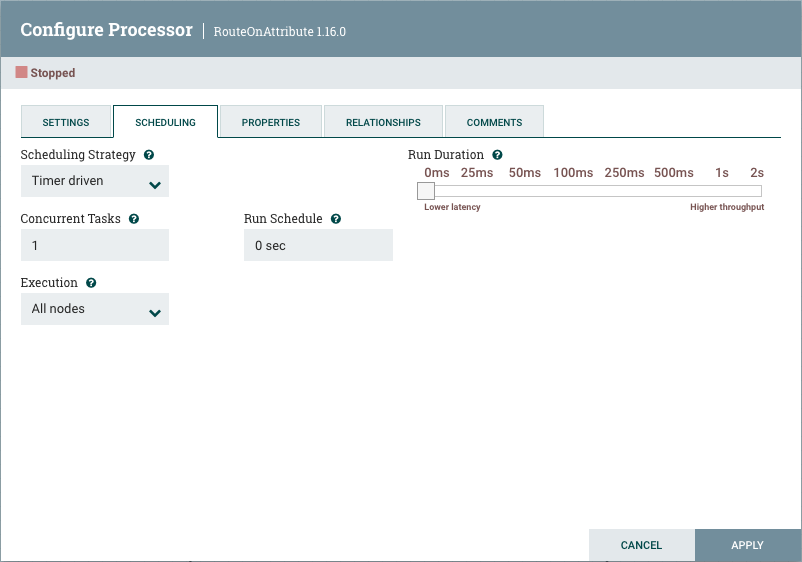
调度策略
第一个配置选项是调度策略。安排组件有三种可能的选项:
时间推送器驱动:这是默认模式。处理器将按常规间隔运行。处理器运行的间隔由"运行计划"选项定义(见下文)。
事件驱动:当选择此模式时,处理器将被触发由事件运行,当 FlowFiles 输入连接以馈送此处理器时,该事件就会发生。此模式目前被视为实验性模式,并非所有处理器都支持该模式。选择此模式时,“运行计划"选项不可配置,因为处理器不是触发定期运行,而是事件的结果。此外,这是"并发任务"选项可以设置为 0 的唯一模式。在这种情况下,线程的数量仅受管理员配置的事件驱动线程池的大小的限制。
| 实验的此实施标记为阿帕奇 NiFi 1.10.0(2019 年 10 月)的实验性。API、配置和内部行为可能会在没有警告的情况下更改,此类更改可能会在小版本期间发生。风险自担。 | |
|---|---|
CRON 驱动:当使用 CRON 驱动调度模式时,处理器计划定期运行,类似于定时器驱动的调度模式。但是,CRON 驱动模式提供了显著增强的灵活性,但牺牲了增加配置的复杂性。CRON 驱动的调度值由六个必需字段和一个可选字段串,每个字段由空间分离。这些字段包括:
| 田 | 有效值 |
|---|---|
| 秒 | 0-59 |
| 纪要 | 0-59 |
| 小时 | 0-23 |
| 月日 | 1-31 |
| 月 | 1-12 或 1 月 1 日至 12 月 |
| 一周中的日子 | 1-7 或周日 |
| 年份(可选) | 空, 1970-2099 |
您通常指定以下方式之一的值:
- 编号: 指定一个或多个有效值。您可以使用逗号分离列表输入多个值。
- 范围: 使用<数>-<数>语法指定范围。
- 增量:使用<启动值>/<增加>语法指定增量。例如,在分钟字段中,0/15 表示分钟 0、15、30 和 45。
您还应注意几个有效的特殊字符:
- * 表示所有值均适用于该字段。
- ?表示未指定特定值。此特殊字符在月天和周天字段中有效。
- L • 您可以将 L 附加到一周中的一个值,以指定该月中这一天的最后一次发生。例如,1L 表示当月的最后一个星期日。
例如:
- 字符串表示您希望安排处理器每天下午 1:00 运行。
0 0 13 * * ? - 字符串表示您希望将处理器安排在每周一到周五下午 2:20 运行。
0 20 14 ? * MON-FRI - 该字符串表示您希望将处理器安排在 2011 年至 2017 年之间每月最后一个星期五上午 10:15 运行。
0 15 10 ? * 6L 2011-2017
并发任务
接下来,调度选项卡提供名为"并发任务"的配置选项。这可以控制处理器将使用多少线程。说另一种方式,这控制多少流文件应该由这个处理器在同一时间处理。增加此值通常允许处理器在相同的时间内处理更多数据。但是,它通过使用系统资源来达到此要求,而其他处理器则无法使用这些资源。这基本上提供了处理器的相对权重 - 它控制系统中有多少资源应分配给此处理器,而不是其他处理器。此字段适用于大多数处理器。但是,有些类型的处理器只能与单个并发任务一起排定。
运行时间表
“运行计划"规定了处理器应安排运行的频率。此字段的有效值取决于选定的调度策略(见上文)。如果使用事件驱动的调度策略,此字段不可用。使用定时器驱动的调度策略时,此值是数字指定的时间持续时间,然后是时间单位。例如,或 .默认值意味着处理器应尽可能频繁地运行,只要它有数据要处理。无论时间单位(即,), 0 的任何时间持续时间都是如此。有关适用于 CRON 驱动调度策略的值的解释,请参阅 CRON 驱动调度策略本身的描述。1 second``5 mins``0 sec``0 sec``0 mins``0 days
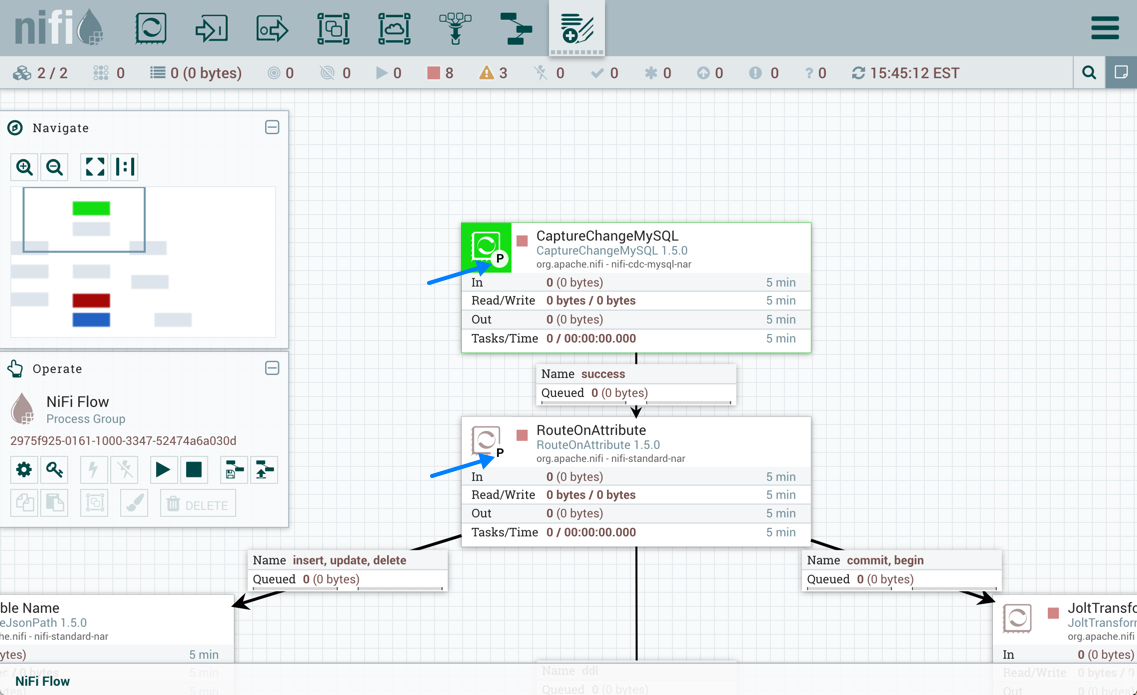
执行
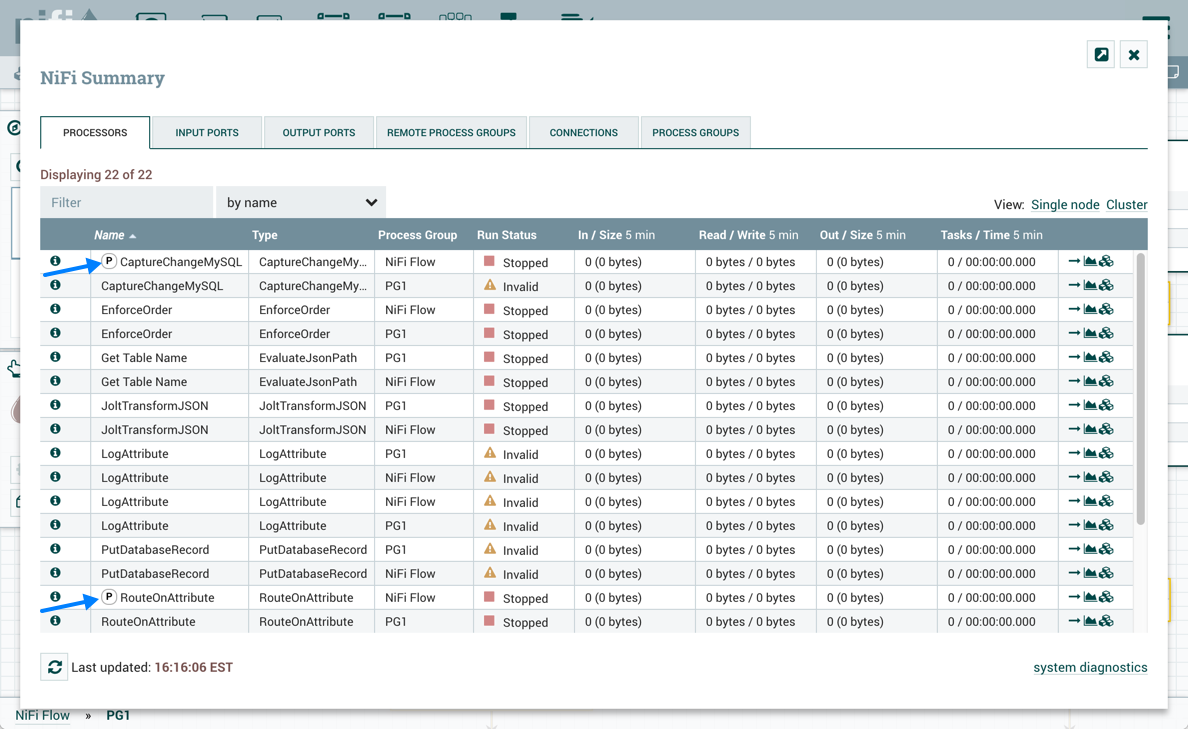
执行设置用于确定处理器将安排执行哪个节点。选择"所有节点"将导致此处理器在组集的每个节点上进行排定。选择"主节点"将导致此处理器仅在主节点上进行排序。已配置为"主节点"执行的处理器由处理器图标旁边的"P"标识:
要快速识别"主节点"处理器,“P"图标也显示在"摘要"页面上的处理器选项卡中:
运行持续时间
“计划"选项卡的右侧包含用于选择"运行持续时间"的滑块。这可控制每次触发处理器时应安排运行多长时间。在滑块的左侧,它被标记为"下延迟”,而右侧标记为"高吞吐量”。当处理器完成运行时,它必须更新存储库,以便将流文件传输到下一个连接。更新存储库的成本很高,因此在更新存储库之前可以同时完成的工作越多,处理器能够处理的工作就越多(吞吐量越高)。但是,这意味着在以前的流程更新此存储库之前,下一个处理器无法开始处理这些流文件。因此,延迟将更长(从头到尾处理 FlowFile 所需的时间将更长)。因此,滑块提供了 DFM 可以选择支持低延迟或更高吞吐量的频谱。
属性选项卡
属性选项卡提供了配置处理器特定行为的机制。没有默认属性。每种类型的处理器必须定义哪些属性对其使用案例有意义。下面,我们可以看到路由属性处理器的属性选项卡:
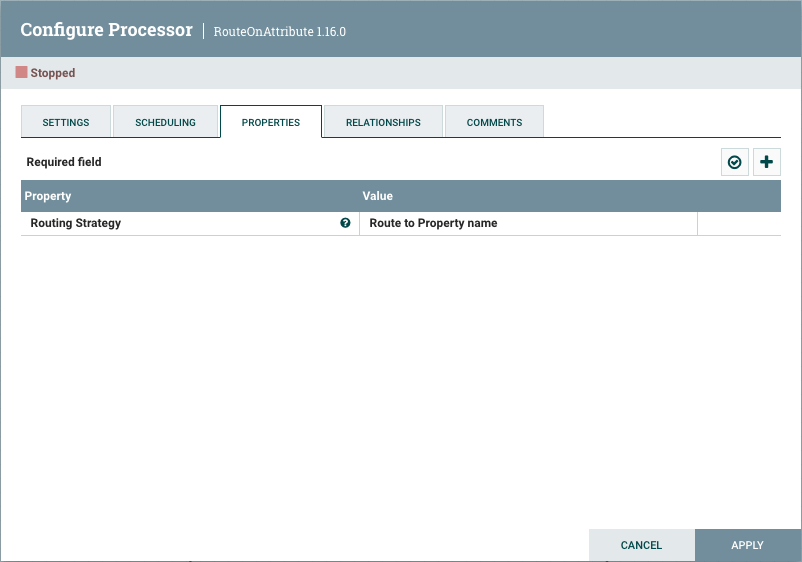
默认情况下,此处理器只有一个属性:“路由策略”。默认值为"属性名称路由”。此属性的名称旁边有一个小问号符号 (
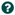 ).此帮助符号在整个用户界面的其他地方可见,它表示有更多信息可用。用鼠标悬停在此符号上将提供有关属性和默认值的附加详细信息,以及已为属性设置的历史值。
).此帮助符号在整个用户界面的其他地方可见,它表示有更多信息可用。用鼠标悬停在此符号上将提供有关属性和默认值的附加详细信息,以及已为属性设置的历史值。
单击属性值将允许 DFM 更改值。根据属性允许的值,用户要么从中获得选择值的下拉,要么被赋予文本区域来键入值:
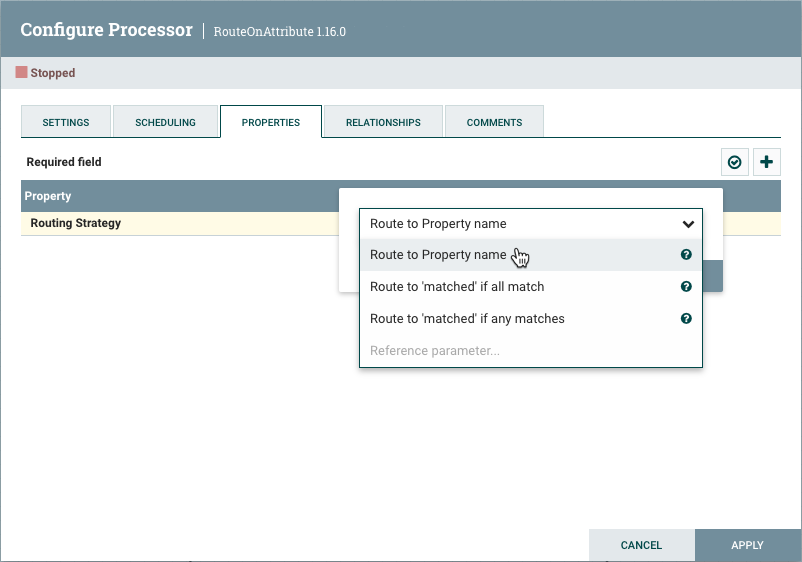
在选项卡的右上角是一个添加新属性的按钮。单击此按钮将为 DFM 提供对话,以输入新属性的名称和价值。并非所有处理器都允许用户定义属性。在不允许它们的处理器中,当应用用户定义属性时,处理器将失效。但是,路由属性允许用户定义属性。事实上,在用户添加属性之前,此处理器将无效。
请注意,添加用户定义属性后,该行的右侧将显示图标 (
 ).单击它将从处理器中删除用户定义的属性。
).单击它将从处理器中删除用户定义的属性。
某些处理器还内置高级用户界面 (UI)。例如,更新属性处理器具有高级 UI。要访问高级 UI,请单击显示在配置处理器窗口底部的"高级"按钮。只有具有高级 UI 的处理器才会有此按钮。
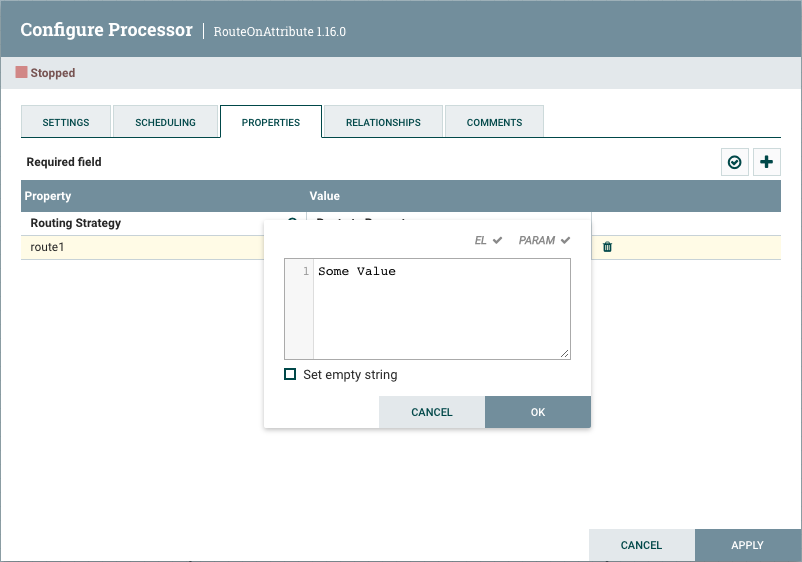
有些处理器具有指其他组件的属性,例如控制器服务,这些组件也需要配置。例如,GetHTTP 处理器具有 SSL 保守服务属性,它指的是标准 SSCONText 服务控制器服务。当 DFM 想要配置此属性但尚未创建和配置控制器服务时,它们可以选择当场创建服务,如下图所示。有关配置控制器服务的更多信息,请参阅控制器服务部分。
评论选项卡
处理器配置对话中的最后一个选项卡是"注释"选项卡。此选项卡仅提供一个区域,供用户包含适合此组件的任何注释。使用注释选项卡是可选的:
其他帮助
您可以通过右键单击处理器并从上下文菜单中选择"使用"来访问有关每个处理器使用情况的其他文档。或者,从 UI 右上角的"全球菜单"中选择"帮助”,以显示包含所有文档的帮助页面,包括所有可用处理器的使用文档。单击所需的处理器查看使用文档。
配置流程组
要配置流程组,请右键单击流程组,并从上下文菜单中选择选项。配置对话打开时有两个选项卡:通用和控制器服务。Configure

一般标签
此选项卡包含几个不同的配置项目。首先是流程组名称。这是显示在画布上的流程组顶部以及 UI 底部的面包屑中的名称。对于根过程组(即最高级别组),这也是显示为浏览器选项卡标题的名称。请注意,此信息对远程连接到此实例的任何其他 NiFi 实例可见(使用远程过程组(又名站点到站点)。
下一个配置元素是流程组参数上下文,用于为流组件提供参数。从此下拉,用户可以选择应绑定到此过程组的参数上下文,并可可选创建一个新的参数上下文以与流程组绑定。有关更多信息,请参阅参数和参数上下文。
配置对话中的第三个元素是流程组注释。这为提供有关流程组的任何有用信息或上下文提供了机制。
下两个要素,流程组流文件货币和流程组出站策略,涵盖在以下部分。
流文件并发
FlowFile 并发用于控制数据如何引入流程组。有三种选择:
- 无限制(默认值)
- 每个节点的单流文件
- 每个节点单批次
当 FlowFile 并发设置为"未绑定"时,流程组中的输入端口将尽可能快地摄入数据,前提是背压不会阻止数据输入。
当流文件并发配置为"每个节点的单流文件"时,输入端口将只允许单个流量文件同时通过。一旦 FlowFile 进入流程组,在所有流文件离开流程组之前(通过从系统/自动终止中删除或通过输出端口退出),不会引入其他流文件。这通常会导致性能变慢,因为它减少了 NiFi 用于处理数据的并行性。但是,用户可能需要使用此方法有几个原因。常见的用例是每个传入的 FlowFile 包含对其他几个数据项目的引用,例如目录中的文件列表。用户可能需要在允许任何其他数据进入流程组之前处理整个列表。
当 FlowFile 并发配置为"每个节点单批次"时,输入端口的行为方式将类似于它们在"每个节点单批次"模式下的行为方式,但当流文件被摄入时,输入端口将继续摄入所有数据,直到所有为输入端口提供源端口的队列被清空。届时,在所有数据完成处理并离开流程组之前,他们不会将更多数据引入流程组(参见连接批次导向流程组)。
| 只有当数据从输入端口拉入流程组时,FlowFile 并发控制。它并不阻止流程组中的处理器从 NiFi 外部收集数据。 | |
|---|---|
出站政策
虽然 FlowFile 并发决定了如何将数据引入流程组,但出站策略控制数据流出流程组。有两种可用选项:
- 可用时流(默认值)
- 批量输出
当将出站策略配置为"可用时流"时,如果不应用背压,到达输出端口的数据将立即从流程组中转移出来。
当输出策略被配置为"批量输出"时,输出端口不会将数据从流程组中转移出来,直到流程组中的所有数据在输出端口排队(即在所有数据完成处理之前,没有数据离开处理组)。无论数据是否都已排在同一输出端口上,或者某些数据是否已排队等待输出端口 A,而其他数据是否已排队等待输出端口 B。在完成流文件处理方面,这些条件都被认为是相同的。
使用"批量输出"的出站策略以及"每个节点的单流量文件"的流文件并发性,用户可以轻松地摄入单个流文件(这本身可能代表一批数据),然后等待,直到该 FlowFile 的所有处理完成,然后继续到数据流的下一步(即, 流程组外的下一个组件)。此外,在使用此模式时,流程组中传输出的每个 FlowFile 将为流程组中的每个输出端口提供一系列属性,称为"批量.输出.<端口名称>"。该值将等于为此批数据路由到该输出端口的 FlowFiles 数量。例如,考虑将单个流文件拆分为 5 个流文件,两个流文件转到输出端口 A,一个流文件转到输出端口 B,两个流文件转到输出端口 C,而没有流文件转到输出端口 D。在这种情况下,每个流文件将有属性, , . .batch.output.A = 2``batch.output.B = 1``batch.output.C = 2``batch.output.D = 0
“批量输出"的出站策略与"未绑定"的 FlowFile 并发同时使用时不提供任何好处。因此,如果 FlowFile 并发设置为"未绑定”,则忽略出站策略。
连接面向批次的流程组
NiFi 中的常用案例是执行一些面向批次的流程,只有在此过程完成之后,才能在同一批数据上执行另一个过程。
NiFi 通过将每个流程封装到自己的流程组中,使此成为可能。第一流程组的出站策略应配置为"批量输出",而流文件并发应为"每个节点的单流文件"或"每个节点的单批次文件"。通过此配置,第一个流程组将处理一整批数据(根据 FlowFile 并发性,这些数据要么是单个 FlowFile,要么是多个流文件),作为一组连贯的数据。当该批数据的处理完成后,数据将一直保存到所有 FlowFiles 完成处理并准备离开流程组。此时,数据可以作为批次从流程组中传输出来。此配置 - 当流程组配置为"批量输出"的出站策略,输出端口与流程组的输入端口直接连接,并具有"每个节点单批次"的流量文件并发时,此配置被视为一个稍微特殊的情况。接收过程组不仅会接收数据,直到其输入队列是空的,而且直到它们是空的,源过程组已经从流程组中传输了该批次的所有数据。这允许将流文件集合作为流程组之间的单批数据传输 - 即使这些流文件分布在多个端口中。
警告
当使用"每个节点单流文件"的流文件并发时,需要考虑几个注意事项。
首先,如果同一节点上的处理组中没有数据排队,则输入端口可以免费将数据带入流程组。这意味着,例如,在 5 节点聚类中,可能同时处理多达 5 个传入的流文件。此外,如果连接被配置为使用负载平衡,则可能会将数据传输到组组中的另一个节点,允许数据在 FlowFile 仍在处理时进入流程组。因此,不建议在未配置为"无限制"FlowFile 并发的流程组中使用负载平衡连接。
在使用"批量输出"的输出策略时,必须考虑背压。考虑在完成所有数据处理之前不会从流程组传输数据的情况。还要考虑与输出端口 A 的连接具有 10,000 流文件(默认值)的背压阈值。如果该队列达到 10,000 阈值,则不再触发上游处理器。因此,数据不会完成处理,流量将陷入僵局,因为输出端口在处理完成之前不会运行,处理器不会运行,直到输出端口运行。为了避免这种情况,如果大量 FlowFile 预计将从单个输入 FlowFile 中生成,则建议以这样种方式配置以输出端口结尾的连接的背压,以便将这些连接的最大预期数量的流文件或背压全部禁用(通过将后压阈值设置为 0)。有关更多信息,请参阅后压。
连接默认设置
流程组配置对话中的最后三个元素是默认流量文件过期、默认后压对象阈值和默认背压数据大小阈值。这些设置在创建新连接时配置默认值。每个连接表示队列,每个队列都有流文件过期、后压对象计数和后压数据大小的设置。此处指定的设置将影响流程组中创建的所有新连接的默认值;它不会影响现有的连接。在配置过程组中创建的儿童处理组将继承默认设置。同样,现有的流程组将不会生效。如果不覆盖这些选项,根处理组将从 nifi.属性获取其默认背压设置,并且具有"0 秒"的默认 FlowFile 到期日,即不过期。
| 将默认流量文件到期设置为非零值可能导致由于 FlowFile 到期而导致数据丢失,因为其时间限制已达到。 | |
|---|---|
控制器服务
流程组配置对话中的控制器服务选项卡包含在数据流添加控制器服务中。
参数
流中属性的值(包括敏感属性)可以使用参数进行参数化。参数在 NiFi UI 中创建和配置。任何属性都可以配置为参考具有以下条件的参数:
- 敏感属性只能引用敏感参数
- 非敏感属性只能引用非敏感参数
- 引用控制器服务的属性不能使用参数
- 参数不能在报告任务或控制器级别控制器服务中引用
UI 表示参数是否可用于属性值。
| 参数比变量有许多优势。除了敏感的价值支持外,参数还对访问策略提供了更精细的控制。此外,引用参数的属性根据替换值进行验证,与使用表达语言引用变量的大多数属性不同。 | |
|---|---|
参数上下文
参数在参数上下文中创建。参数上下文是全球定义/访问的 NiFi 实例。访问策略可以应用于参数上下文,以确定哪些用户可以创建它们。创建后,还可以应用要读取和写入特定参数上下文的策略(请参阅访问参数以获取更多信息)。
创建参数上下文
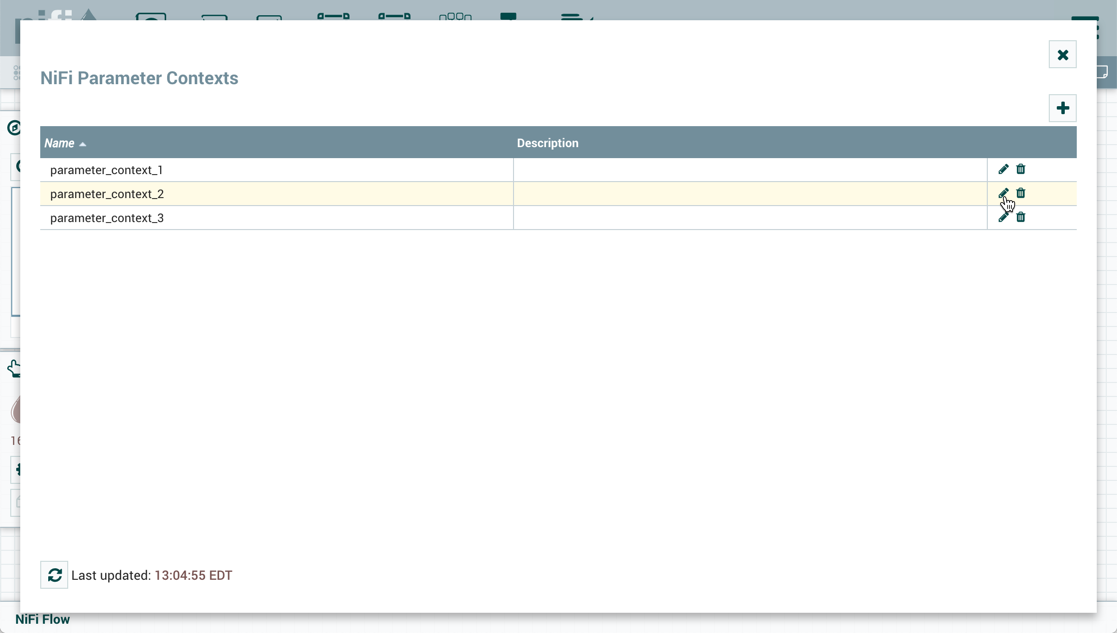
要创建参数上下文,请从全球菜单中选择参数上下文:
在参数上下文窗口中,单击右上角的按钮,并打开"添加参数上下文"窗口。窗口有两个选项卡:设置和参数。+
在"设置"选项卡上,添加参数上下文的名称和说明(如果需要)。选择"应用"以保存参数上下文或选择"参数"选项卡以向上下文添加参数。
在参数上下文中添加参数
参数可在参数上下文创建期间添加或添加到现有参数上下文中。
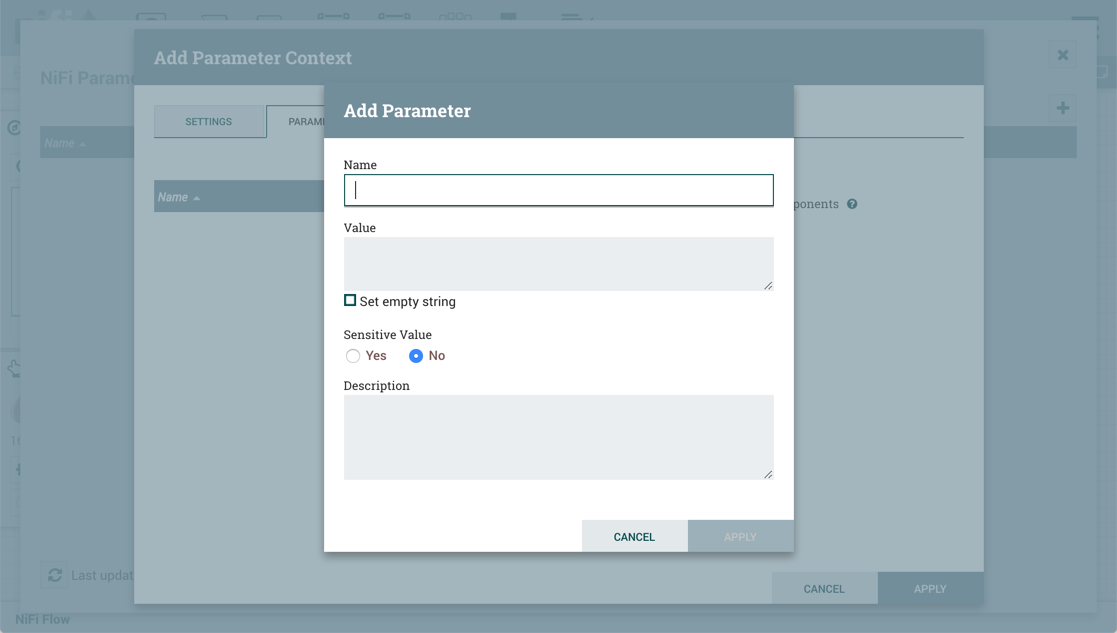
在参数上下文创建过程中,选择"参数"选项卡。单击按钮以打开"添加参数"窗口。+
要将参数添加到现有参数上下文,请打开参数上下文窗口并单击"编辑"按钮 (
 )在所需的参数上下文的行。
)在所需的参数上下文的行。
在"参数"选项卡上,单击按钮以打开"添加参数"窗口。+
添加参数窗口具有以下设置:
- 名称- 用于表示参数的名称。只允许使用字母数字字符(a-z、A-Z、0-9)、连字符(-)、下划线(* )、期间(…
- 值- 引用参数时将要使用的值。如果参数使用表达语言,请务必注意,将根据引用参数的组件对表达语言进行评估。有关更多信息,请参阅下面的参数和表达语言部分。
- 设置空字符串- 检查以明确将参数值设置为空字符串。默认情况下未检查。(注意:如果检查但设置了值,则会忽略复选框。
- 敏感值- 如果参数值应被视为敏感值,则设置为"是"。如果敏感,则一旦应用,参数值将不会在 UI 中显示。默认设置为"否"。敏感参数只能由敏感属性引用,非敏感参数只能由非敏感属性引用。一旦创建参数,其灵敏度标志就无法更改。
- 描述- 说明参数是什么,如何使用参数等。此字段是可选的。
配置这些设置后,选择"应用"。引用组件列出了当前选定的参数所引用的组件。添加附加参数或编辑任何现有参数。
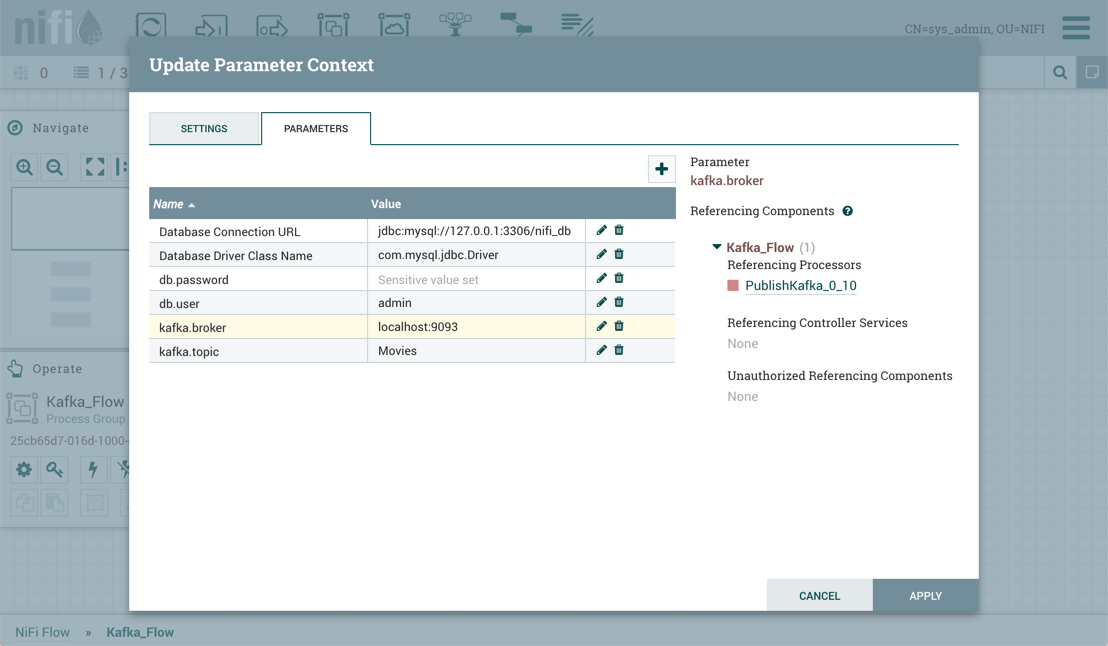
要完成该过程,请从参数上下文窗口选择"应用"。执行以下操作以验证引用添加或修改参数的所有组件:停止/重新启动受影响的处理器、禁用/重新启用受影响的控制器服务、更新参数上下文。
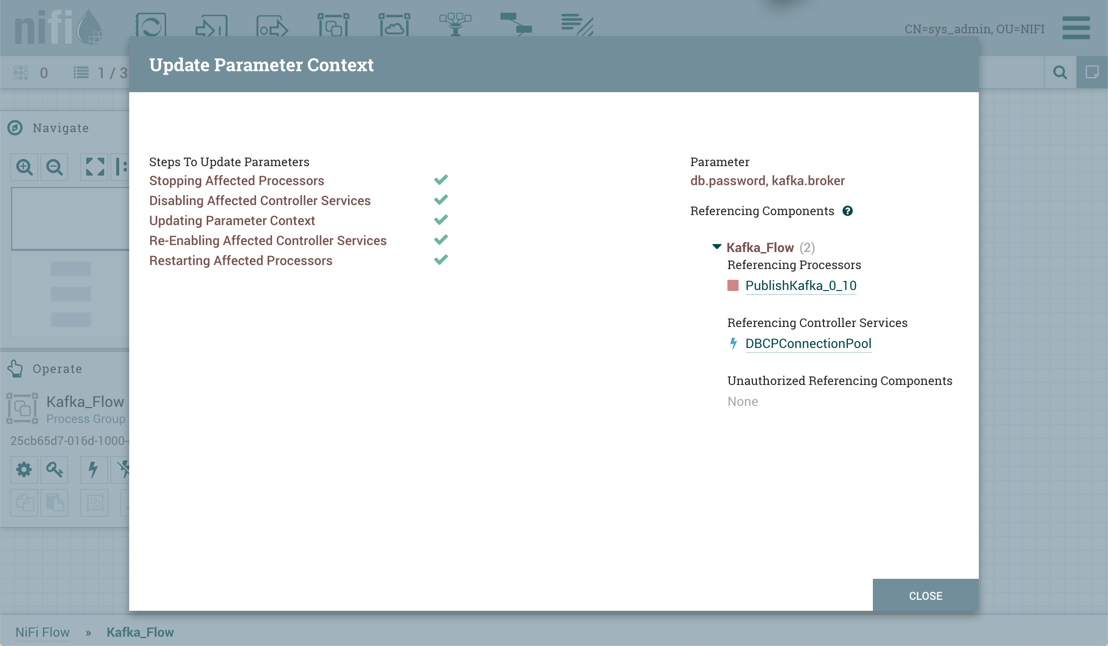
引用组件部分现在列出了由流程组组织添加/编辑/删除的参数集所引用的所有组件的聚合。
参数和表达语言
在添加使用表达语言的参数时,了解评估表达语言的上下文非常重要。该表达式始终在引用参数的流程或控制器服务上下文中进行评估。例如,添加带有名称的参数的方案。表达语言导致呼叫以确定系统评估时间。当作为参数添加时,系统时间不会在添加参数时进行评估,而是当处理器或控制器服务评估表达式时进行评估。即,如果处理器具有其价值设置为该属性的属性,其功能将完全与属性值设置为属性的功能相同。每次引用该属性时,都会生成不同的时间戳。Time``${now()}``#{Time}``${now()}
此外,有些属性不允许表达语言,而另一些属性则允许表达语言,但不根据 FlowFile 属性评估表达式。要帮助理解它是如何工作的,请考虑指定其值的参数。然后考虑三个不同的属性,每个具有不同的表达语言范围和流文件,其文件名是。如果每个属性被设置为,则下表说明结果值。File``${filename}``test.txt``#{File}
| 配置的属性值 | 表达语言范围 | 有效财产价值 | 笔记 |
|---|---|---|---|
| #[文件] | 流文件属性 | 测试.txt | 文件名通过查看属性来解决。filename |
| #[文件] | 仅限可变注册表 | 空字符串 | FlowFile 属性不在范围中,我们假设"文件名"中的可变注册表中没有可变性 |
| #[文件] | 没有 | $[文件名] | 字面文本"$[文件名]“将不被评估。 |
将参数上下文分配给流程组
要使组件引用参数,必须首先为其流程组分配参数上下文。一旦分配,该处理组中的处理器和控制器服务只能引用该参数上下文中的参数。
流程组只能分配一个参数上下文,而给定参数上下文可以分配给多个进程组。
| 用户只能将过程组的参数上下文设置为用户有视图策略的参数上下文之一。此外,为了设置参数上下文,用户必须具有流程组的修改策略。有关更多信息,请参阅访问参数。 | |
|---|---|
要将参数上下文分配给流程组,请单击"配置”,无论是从操作调色板还是从流程组上下文菜单。
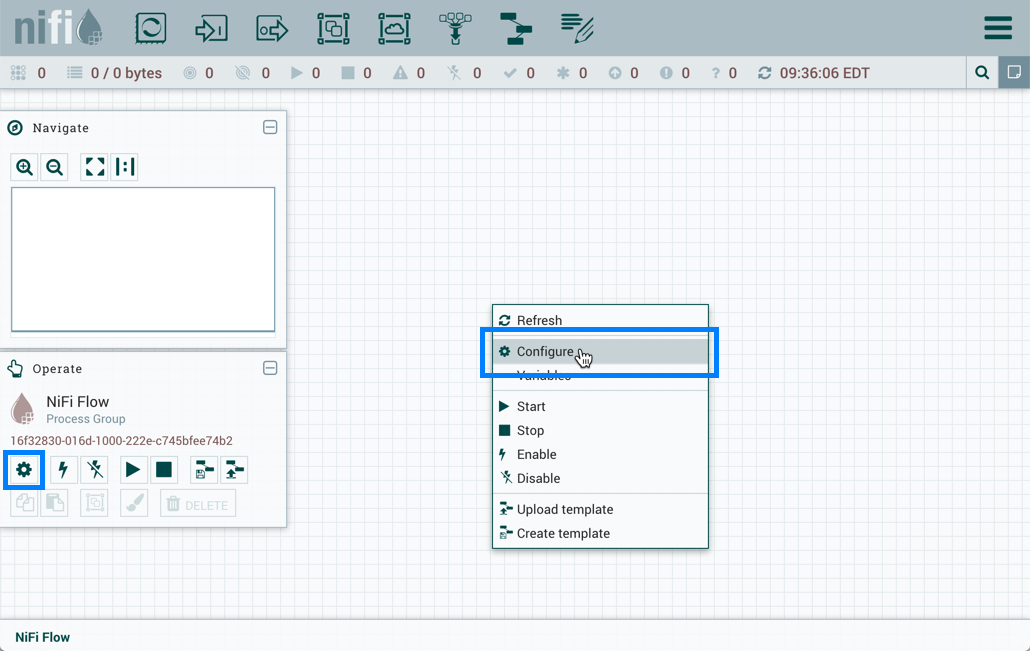
在流配置窗口中,选择"一般"选项卡。从流程组参数上下文下拉菜单中,选择现有的参数上下文或创建新的参数上下文。
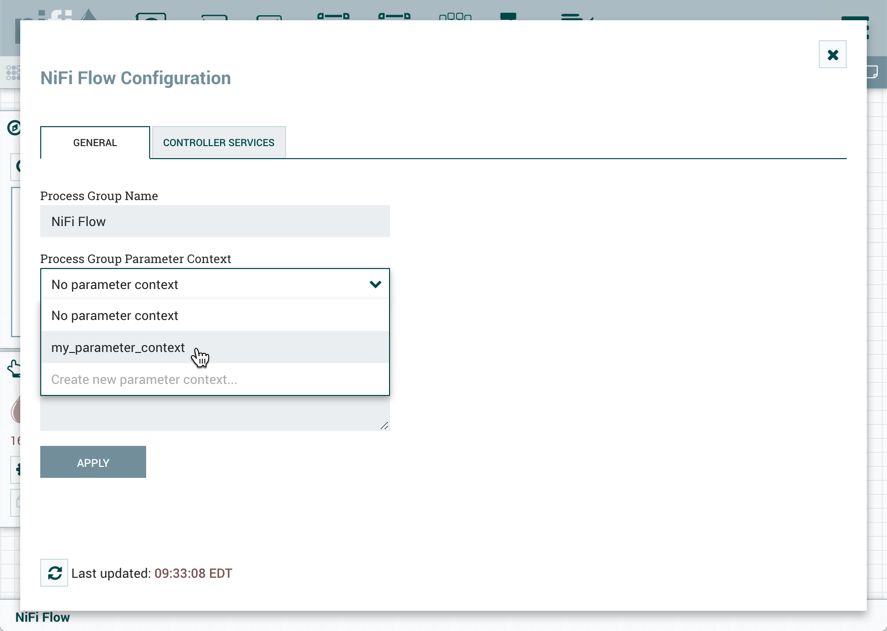
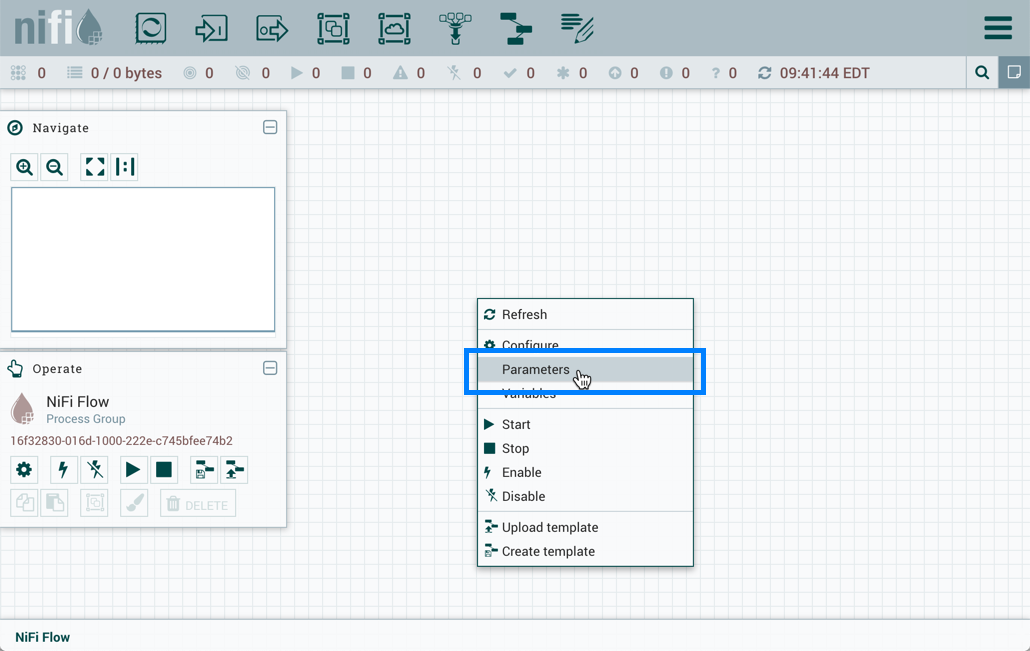
选择"应用"以保存配置更改。流程组上下文菜单现在包含一个"参数"选项,允许快速访问指定参数上下文的更新参数上下文窗口。
如果更改了流程组的参数上下文,则如果组件以前运行并且仍然有效,则将停止、验证和重新启动该过程组中引用任何参数的所有组件。
| 如果参数上下文从过程组中解置,则不会从父级过程组继承参数上下文。相反,无法引用任何参数。任何已经引用参数的组件都将失效。 | |
|---|---|
引用参数
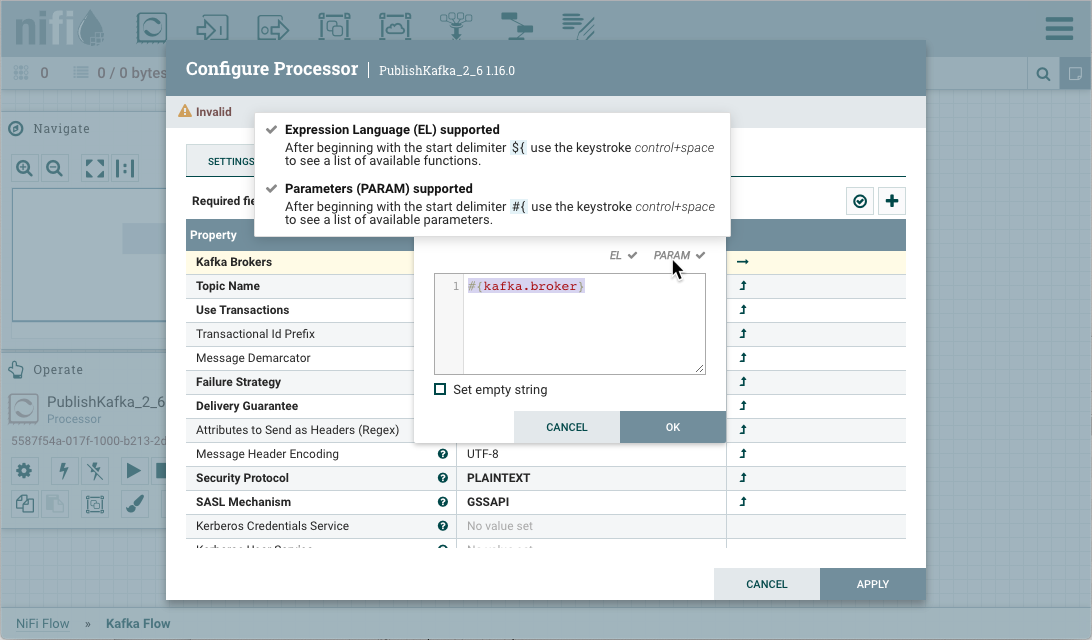
参数参考语法
要配置符合条件的属性以引用参数,请使用该符号作为开头,参数的名称以卷曲大括号为内:#
#{Parameter.Name}
这可以在开始时使用附加字符来逃脱。为了说明这一点,假设参数具有值,参数具有值。然后,以下用户定义的属性值将评估到这些有效值:#``abc``xxx``def``yyy
| 用户输入的字面属性值 | 有效财产价值 | 解释 |
|---|---|---|
#{abc} |
xxx |
简单替换 |
#{abc}/data |
xxx/data |
用额外的字面数据简单替换 |
#{abc}/#{def} |
xxx/yyy |
多重替换与额外的字面数据 |
#{abc |
#{abc |
没有参数替换 |
#abc |
#abc |
没有参数替换 |
##{abc} |
#{abc} |
逃逸 # 用于字面解释 |
###{abc} |
#xxx |
逃逸 # 用于文字解释, 然后是简单的替换 |
####{abc} |
##{abc} |
逃过一劫 # 用于文字解释, 两次 |
#####{abc} |
##xxx |
逃过一劫 # 进行字面解释, 两次, 然后是简单的替换 |
#{abc/data} |
在属性设置操作上抛出的例外 | /不是有效的参数名称字符 |
当从表达语言内部引用参数时,首先评估参数参考。例如,要替换参数:xxx``zzz``abc
${ #{abc}:replace('xxx', 'zzz') }
组件配置中的引用和创建参数
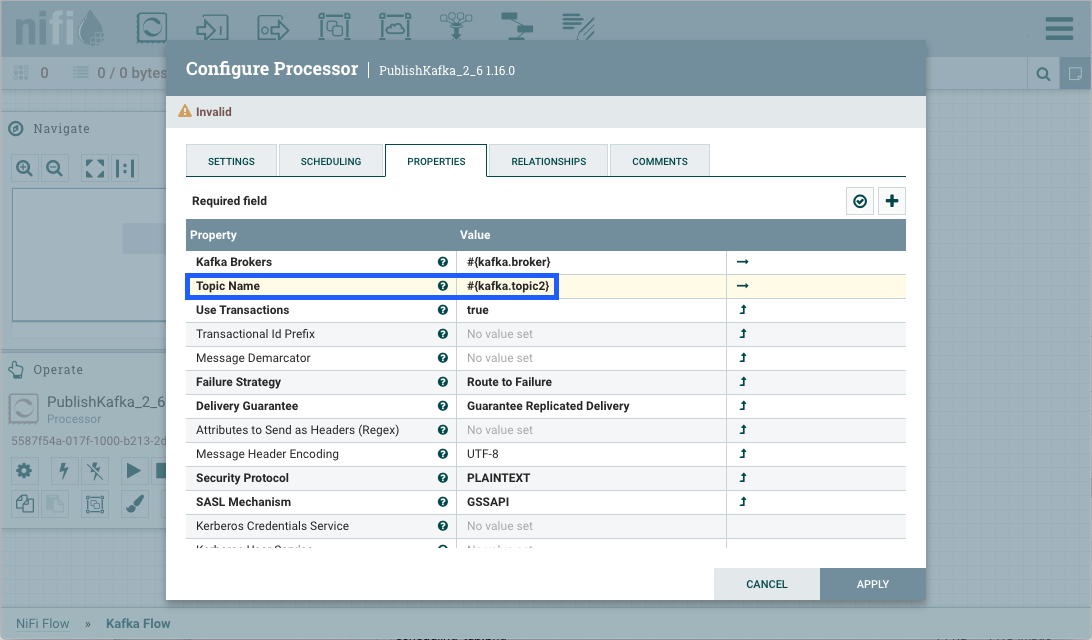
在配置流中的组件时,可以轻松地引用或创建参数。例如,假设一个过程组将参数上下文"Kafka 设置"分配给它。“卡夫卡设置"包含参数和 。kafka.broker``kafka.topic1
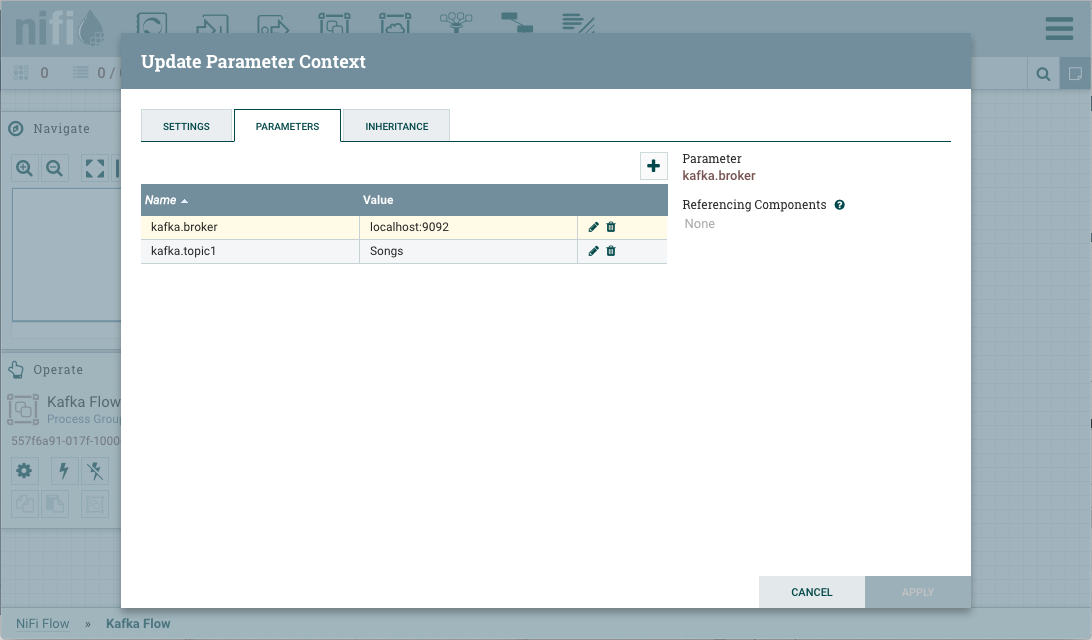
要参考作为"卡夫卡经纪商"属性的价值在发布卡夫卡处理器,清除默认值,并开始一个新的条目与开始划界。接下来使用击键显示可用参数列表:kafka.broker``#{``control+space
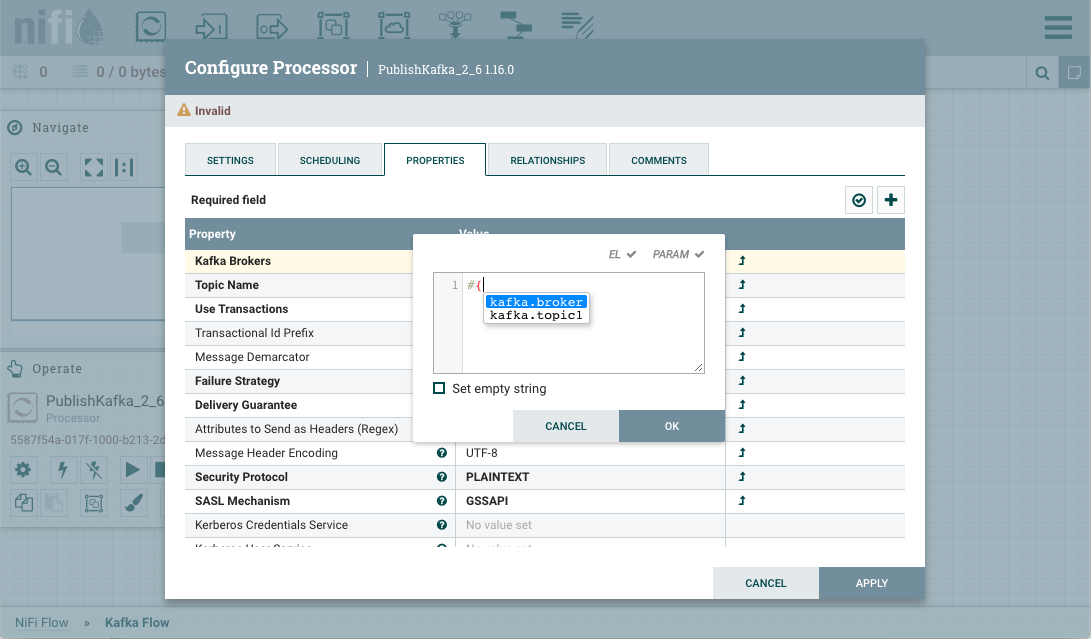
选择并完成与关闭卷曲支架的条目。kafka.broker``}
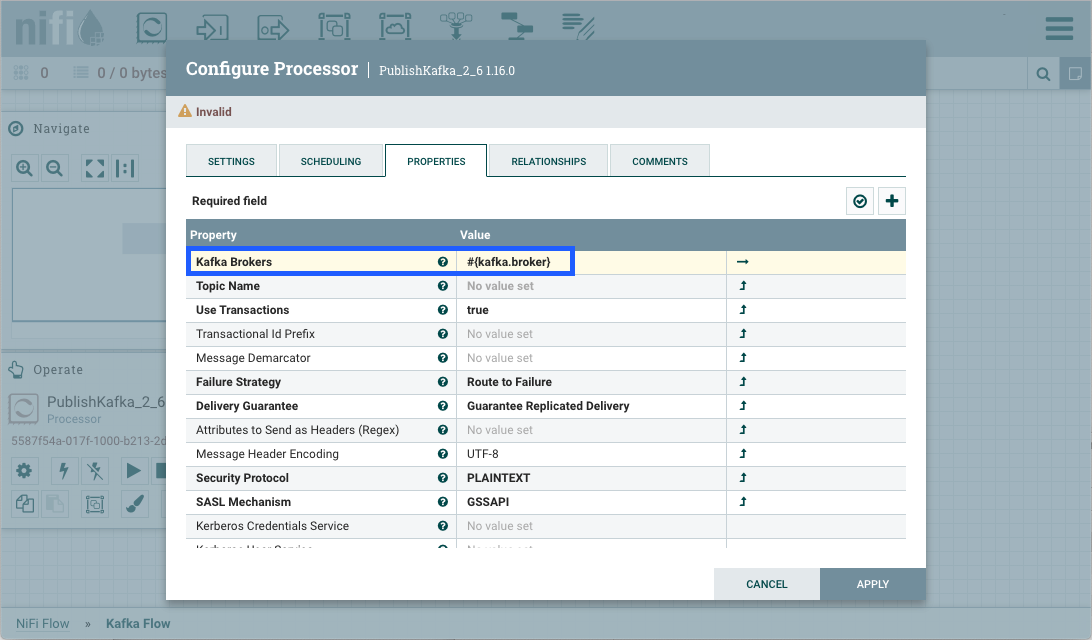
在表达语言和参数资格指标上盘旋时,帮助显示描述此过程的文本。
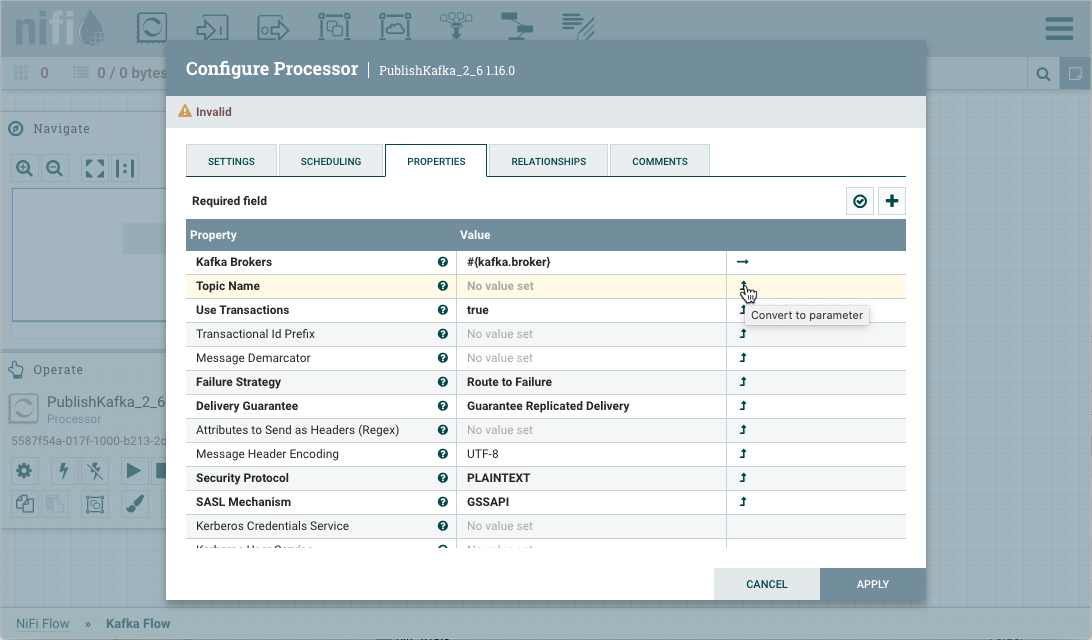
也可以在飞行中创建参数。例如,要创建"主题名称"属性的参数,请选择"转换为参数"图标 (
 )在那家旅馆的行。只有当用户拥有修改参数上下文的适当权限(请参阅访问参数以获取更多信息)时,才能使用此图标。
)在那家旅馆的行。只有当用户拥有修改参数上下文的适当权限(请参阅访问参数以获取更多信息)时,才能使用此图标。
添加参数对话将打开。根据需要配置新参数。
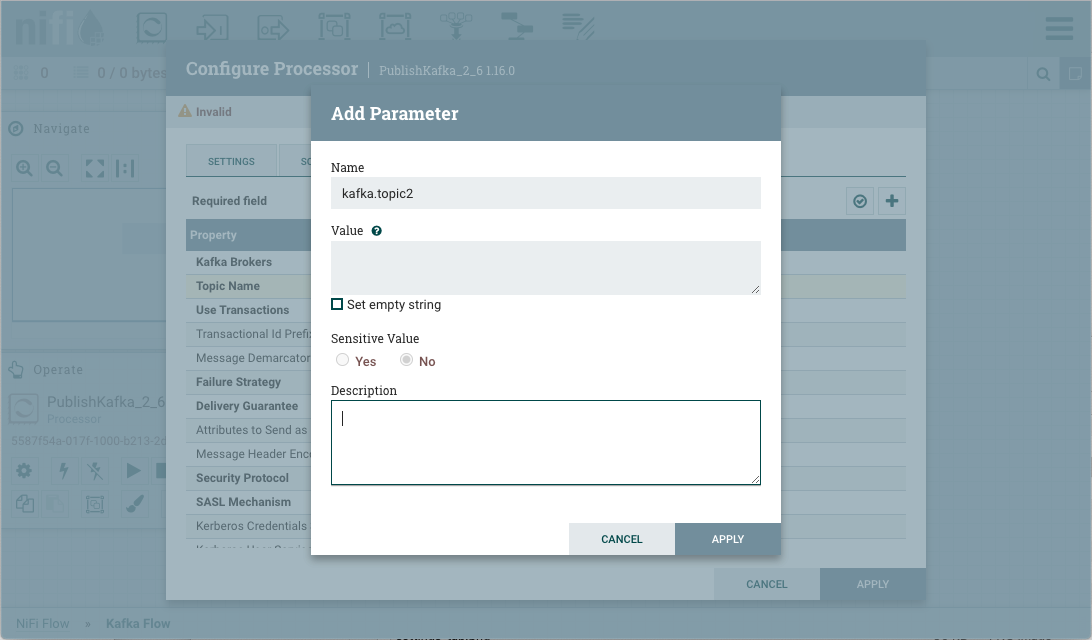
选择"应用”。流程组的参数上下文将更新,新的参数将由属性引用,并自动应用适当的语法。
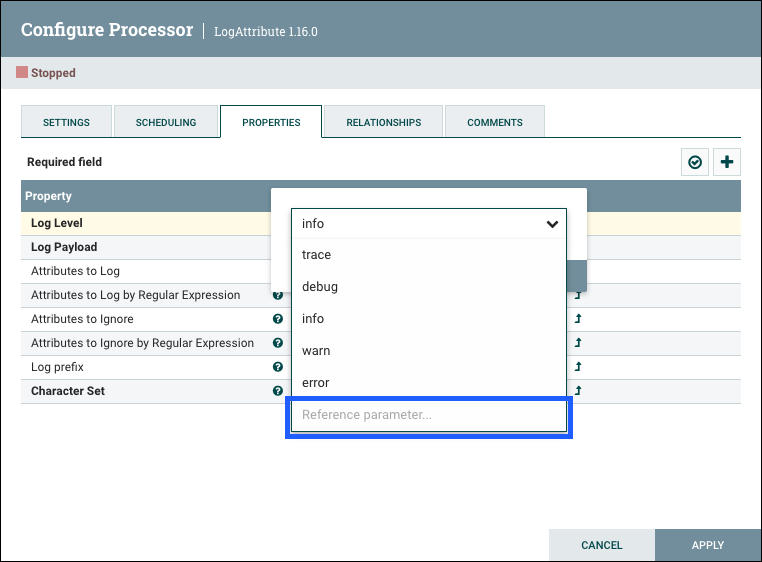
可选择的属性值也可以引用参数。除了应用前面描述的"转换为参数"方法外,还可在值下拉菜单中提供"参考参数"选项。
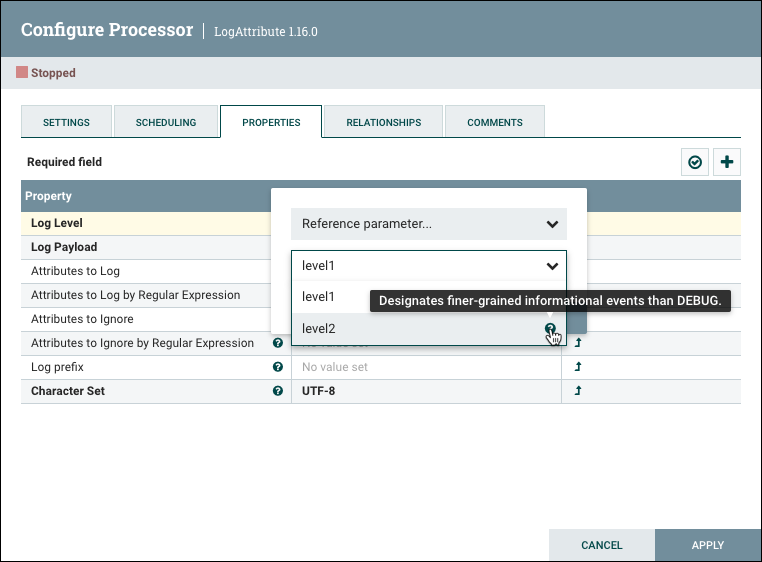
选择"参考参数…“将显示可用参数的下拉列表,该列表由分配给组件过程组的参数上下文和用户的访问策略决定。
悬停在问号图标上 (
) 显示参数的描述。
使用具有敏感属性的参数
敏感属性只能引用敏感参数。这对版本流很重要。敏感参数本身的价值不会发送到流量注册表,只有属性引用敏感参数的事实。有关更多信息,请参阅版本流中的参数。
敏感属性的价值必须设置为单个参数参考。例如,允许和不允许值值发送将导致暴露敏感属性的部分价值。这与非敏感属性(如有效)形成对比。#{password}123``#{password}#{suffix}``#{password}123``#{path}/child/file.txt
访问参数
用户对参数的特权通过以下级别的访问策略进行管理:
- 参数上下文
- 流程组
- 元件
| 有关如何配置访问策略的其他信息,请参阅系统管理员指南中的访问策略部分。 | |
|---|---|
参数上下文访问策略
要让用户查看参数上下文,则必须将参数添加到"访问控制器"视图策略或"访问参数上下文"视图策略中。要使用户修改参数上下文,还必须将参数上下文添加到相应的修改策略中。这些策略通过全球菜单中的"策略"访问。有关更多信息,请参阅系统管理员指南中的“全球访问策略“部分。
| 除非被推翻,“访问参数上下文"策略是从"访问控制器"策略中继承的。 | |
|---|---|
还可以在单个参数上下文上设置查看和修改策略,以确定哪些用户可以查看或添加上下文参数。从全球菜单中选择"参数上下文”。选择"访问策略"按钮 (
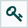 ) 在管理这些策略所需的参数上下文的行中。
) 在管理这些策略所需的参数上下文的行中。
有关更多信息,请参阅系统管理员指南中的组件级别访问策略部分。
流程组访问策略
用户只能将过程组的参数上下文设置为用户有视图策略的参数上下文之一。此外,为了设置参数上下文,用户必须具有流程组的修改策略。流程组访问策略可以通过突出显示流程组并选择"访问策略"按钮() 进行管理
) 从操作调色板。
组件访问策略
要引用参数或将属性转换为组件中的参数,用户需要查看和修改组件的策略。如果用户查看并修改了组件过程组的策略,则这些策略将被继承,但这些策略可以在组件级别上被覆盖。
为了修改参数,用户必须查看和修改该参数所引用的任何和所有组件的政策。这是必要的,因为更改参数需要停止/启动组件,也因为通过采取该操作,用户正在修改组件的行为。
有关更多信息,请参阅系统管理员指南中的组件级别访问策略部分。
使用带有表达语言的自定义属性
您可以使用 NiFi 表达语言来引用 FlowFile 属性,将其与其他值进行比较,并在创建和配置数据流时操作它们的值。有关表达语言的更多信息,请参阅“表达语言指南"。
除了在表达语言中使用 FlowFile 属性、系统属性和环境属性外,您还可以定义表达语言使用的自定义属性。定义自定义属性可为您处理和处理数据流提供更大的灵活性。您还可以为连接、服务器和服务属性创建自定义属性,以便于数据流配置。
NiFi 属性具有在创建自定义属性时应注意的分辨率优先级:
- 处理器特定属性
- 流文件属性
- 流文件属性
- 从可变注册表:
- 用户定义的属性(自定义属性)
- 系统属性
- 操作系统环境变量
当您创建自定义属性时,请确保每个自定义属性包含不同的属性值,以便它不会被现有环境属性、系统属性或 FlowFile 属性覆盖。
使用表达语言使用和管理自定义属性有两种方法:
- 变量: 变量在 NiFi UI 中创建和配置。它们可用于支持表达语言的任何领域。变量不能用于敏感属性。NiFi 自动拾取新的或修改的变量。变量在流程组级别上定义,因此,用于查看和更改变量的访问策略源自流程组的访问策略。有关更多信息,请参阅变量。
- 自定义属性文件: 关键/值对定义在自定义属性文件中,该文件通过nifi.属性中引用。必须重新启动 NiFi 才能获取更新。有关更多信息,请参阅通过 nifi.属性引用自定义属性。
nifi.variable.registry.properties
通过可变和nifi.属性文件的自定义属性仍然支持兼容性,但与参数(如敏感属性的支持)和对谁可以创建、修改或使用的更精细的控制等参数的功率不同。变量和属性将在将来的版本中删除。因此,强烈建议切换到参数。nifi.variable.registry.properties |
|
|---|---|
UI 中表示对属性的表达语言支持。
变量
通过可变和nifi.属性文件的自定义属性仍然支持兼容性,但与参数(如敏感属性的支持)和对谁可以创建、修改或使用的更精细的控制等参数的功率不同。变量和属性将在将来的版本中删除。因此,强烈建议切换到参数。nifi.variable.registry.properties |
|
|---|---|
在 NiFi UI 中创建和配置变量。它们可用于支持表达语言的任何领域。变量不能用于敏感属性。变量在流程组级别上定义,因此,用于查看和更改变量的访问策略源自流程组的访问策略。可变值不能引用其他变量或使用表达语言。
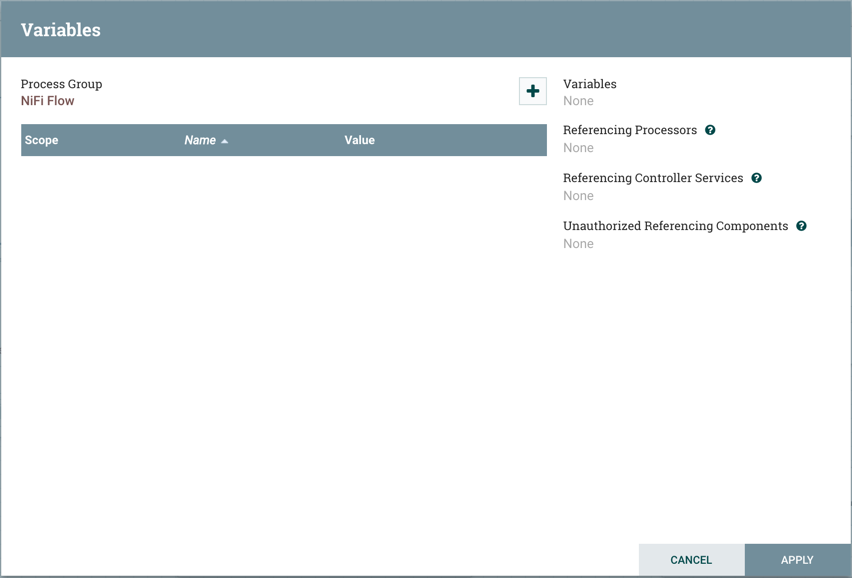
变量窗口
要访问"可变"窗口,请右键单击画布,但未选中:
从上下文菜单中选择"变量”:
当选择流程组时,右键单击上下文菜单中还提供"可变”:
创建可变
在"变量"窗口中,单击按钮以创建新的变量。添加名称:+
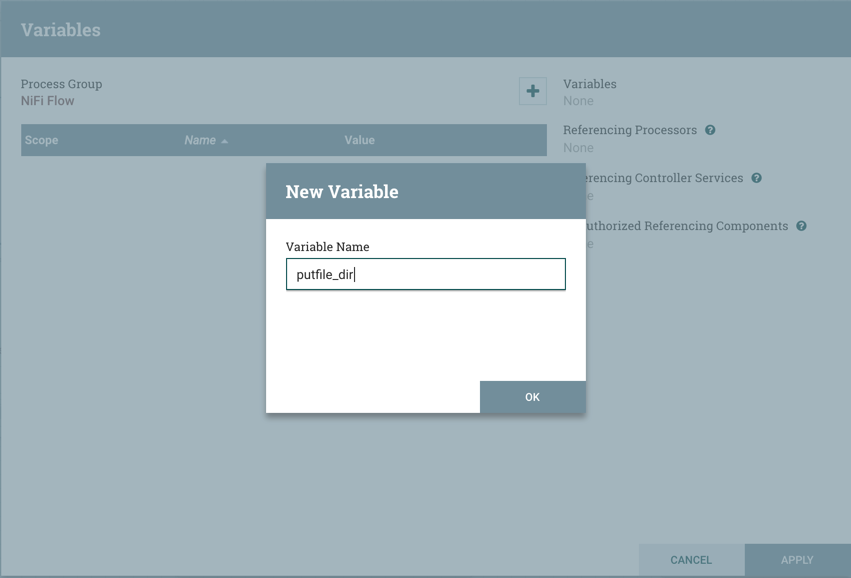
和价值:
选择"应用”:
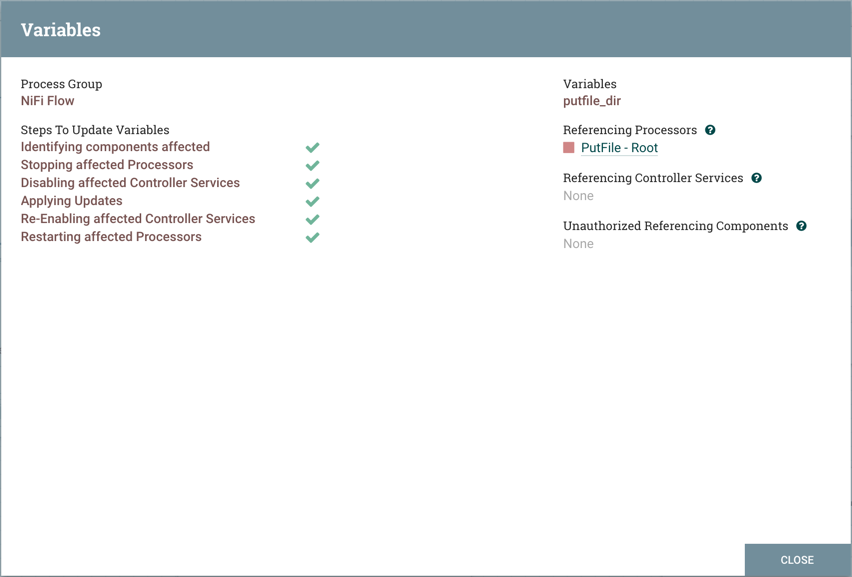
执行更新变量的步骤(识别受影响的组件、停止受影响的处理器等)。例如,参考处理器部分现在列出了"PutFile 根"处理器。选择列表中处理器的名称将导航到画布上的处理器。查看处理器的属性,目录属性引用了:${putfile_dir}
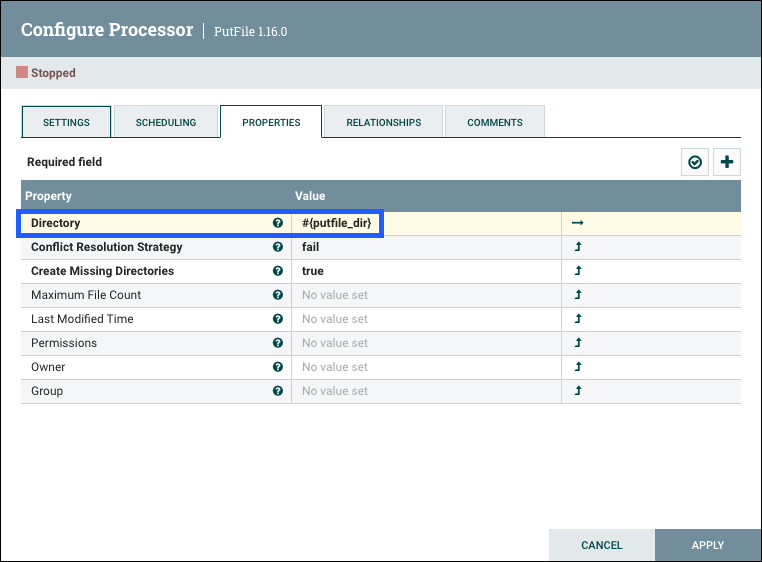
可变范围
变量的范围由它们定义的进程组进行,并且可供该级别和下方定义的任何处理器(即任何后代处理器)使用。
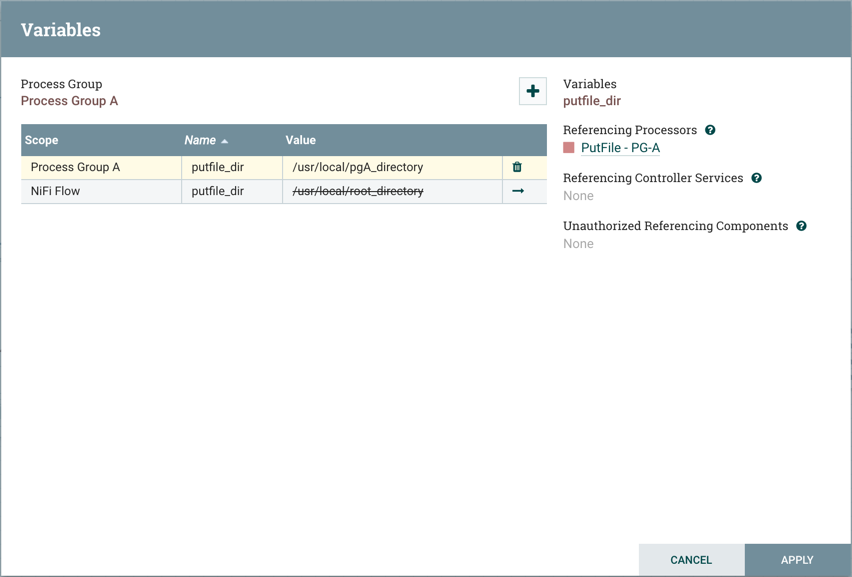
后代组中的变量凌驾于父组值的覆盖。更具体地说,如果变量在根组中申报,并在过程组内声明,则过程组内的组件将使用过程组中定义的价值。x``x
例如,除了根过程组中存在的变量外,假设在过程组 A 中创建了另一个变量。如果流程组 A 引用中的组件之一,则将列出两个变量,但根组将有一个罢工通过,指示该组正在被覆盖:putfile_dir``putfile_dir``putfile_dir``putfile_dir
只能针对创建的过程组修改变量,该组位于变量窗口的顶部。要修改在不同过程组中定义的变量,请选择该变量行中的"箭头"图标:
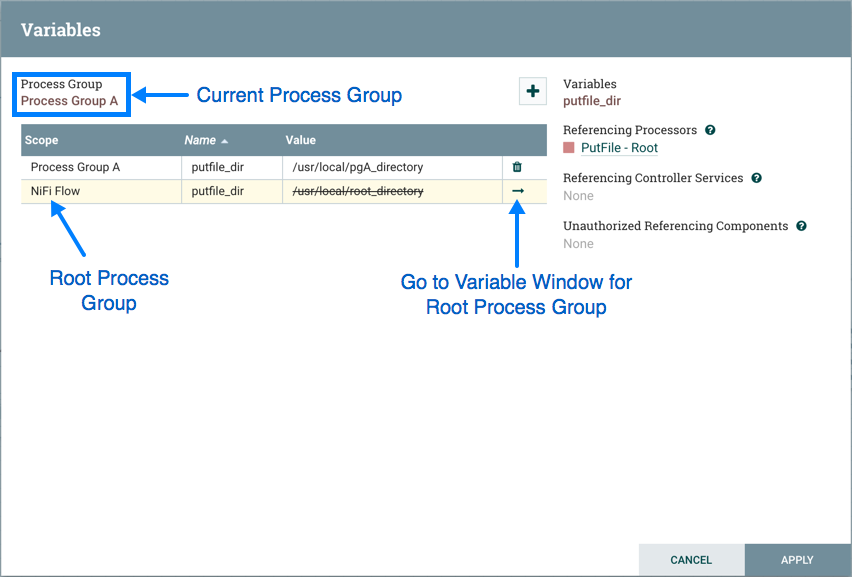
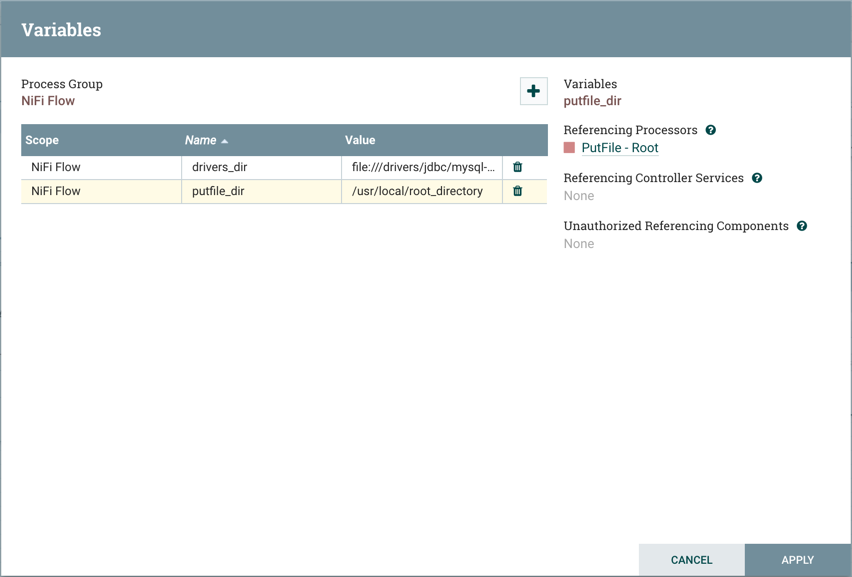
which will navigate to the Variables window for that process group:
可变权限
可变权限仅基于配置在相应流程组上的特权。
例如,如果用户无法访问查看流程组,则无法查看该过程组的"变量"窗口:
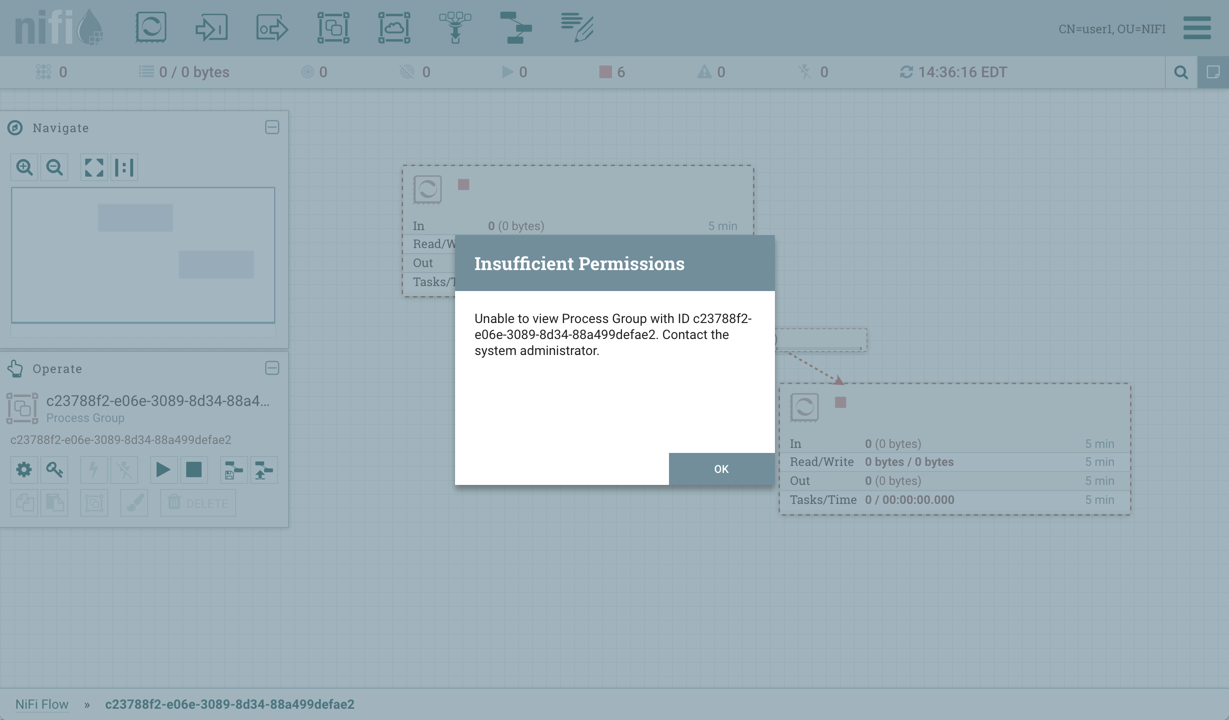
如果用户有权访问"查看"过程组,但无法访问"修改过程组”,则可以查看变量,但不能修改变量。
有关如何管理组件特权的信息,请参阅系统管理员指南中的访问策略部分。
参考控制器服务
除了引用处理器,变量窗口还显示参考控制器服务:
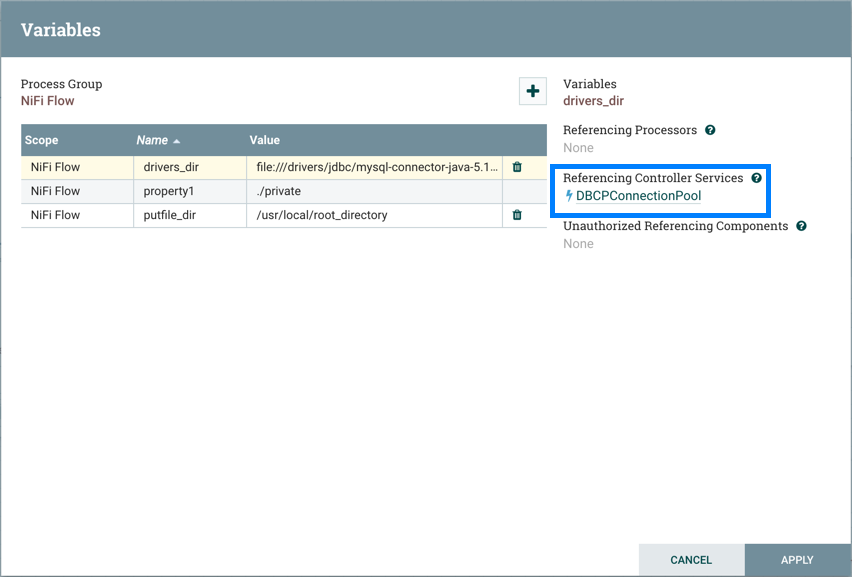
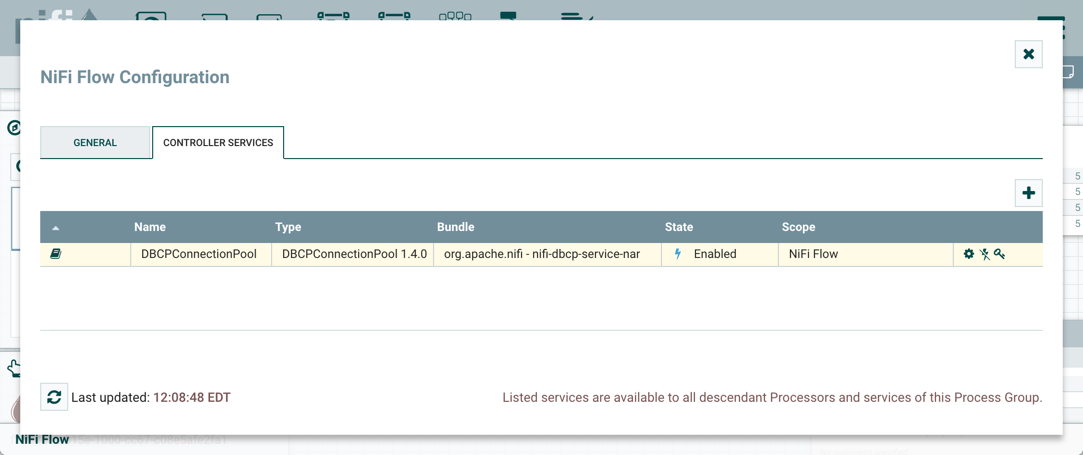
选择控制器服务的名称将导航到配置窗口中的控制器服务:
未经授权的引用组件
如果未向引用变量的组件授予"查看"或"修改"权限,则组件的 UUID 将显示在"变量"窗口中:
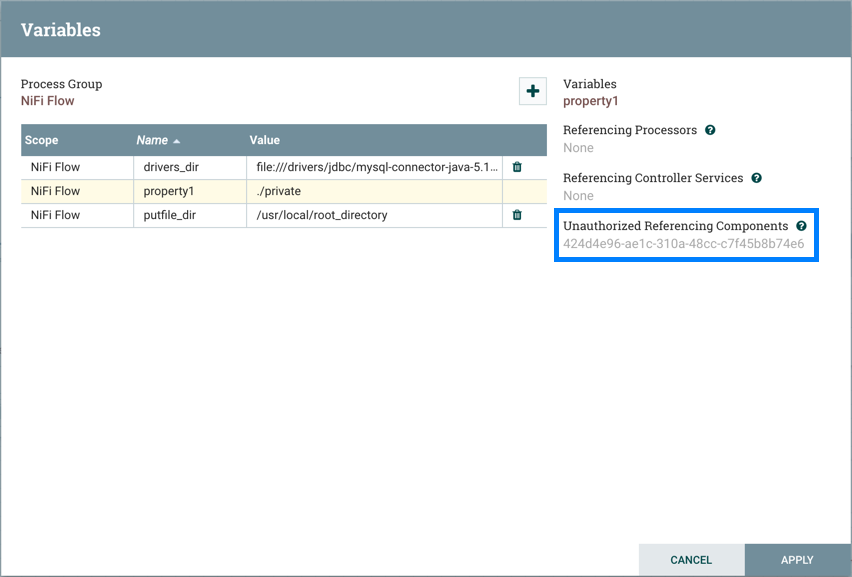
在上述示例中,“用户 1"无法查看的处理器引用了该变量:property1
通过 nifi.属性引用自定义属性
通过可变和nifi.属性文件的自定义属性仍然支持兼容性,但与参数(如敏感属性的支持)和对谁可以创建、修改或使用的更精细的控制等参数的功率不同。变量和属性将在将来的版本中删除。因此,强烈建议切换到参数。nifi.variable.registry.properties |
|
|---|---|
识别一组或多组密钥/值对,并将其交给您的系统管理员。
添加新自定义属性后,确保nifi.属性文件中的字段与自定义属性位置一起更新。nifi.variable.registry.properties
| 必须重新启动 NiFi 才能接收这些更新。 | |
|---|---|
有关更多信息,请参阅系统管理员指南中的自定义属性部分。
控制器服务
控制器服务是共享服务,可用于报告任务、处理器和其他服务,用于配置或任务执行。
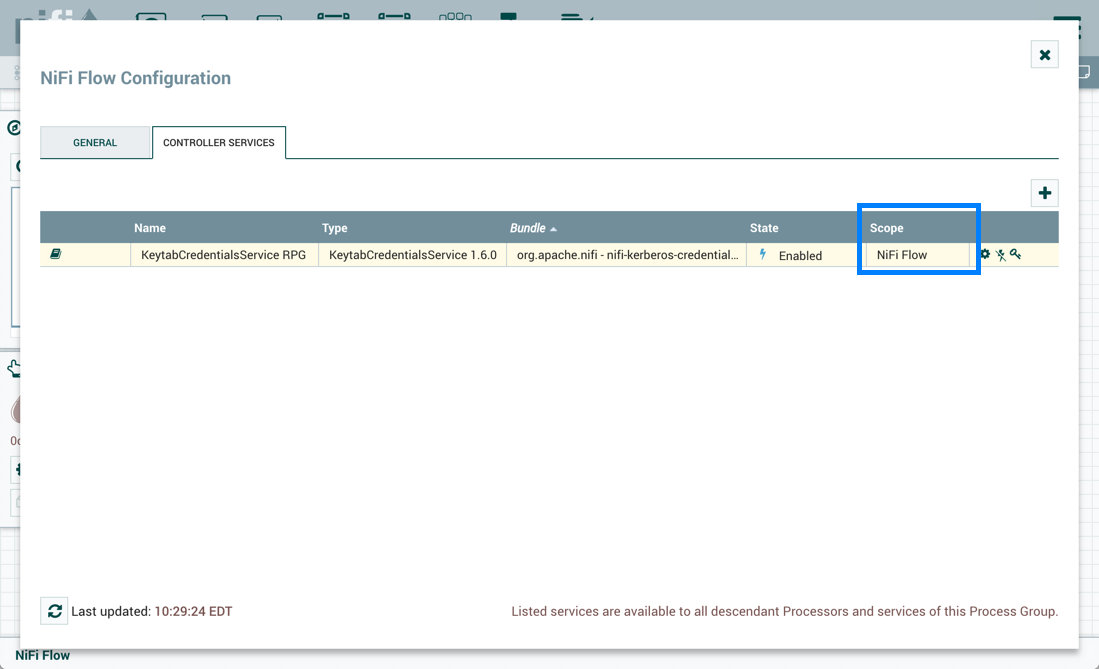
| 控制器级别上定义的控制器服务仅限于报告任务和在那里定义的其他服务。处理器在数据流中使用的控制器服务必须在将要使用的根过程组或子过程组的配置中定义。 | |
|---|---|
| 如果您的 NiFi 实例已得到保护,则查看和添加控制器服务的能力取决于分配给您的特权。如果您无法访问一个或多个控制器服务,则无法在 UI 中查看或访问它。访问特权可基于全球或控制器服务特定分配(参见通过多租户授权访问 UI以获取更多信息)。 | |
|---|---|
为报告任务添加控制器服务
要为报告任务添加控制器服务,请从"全球菜单"中选择控制器设置。
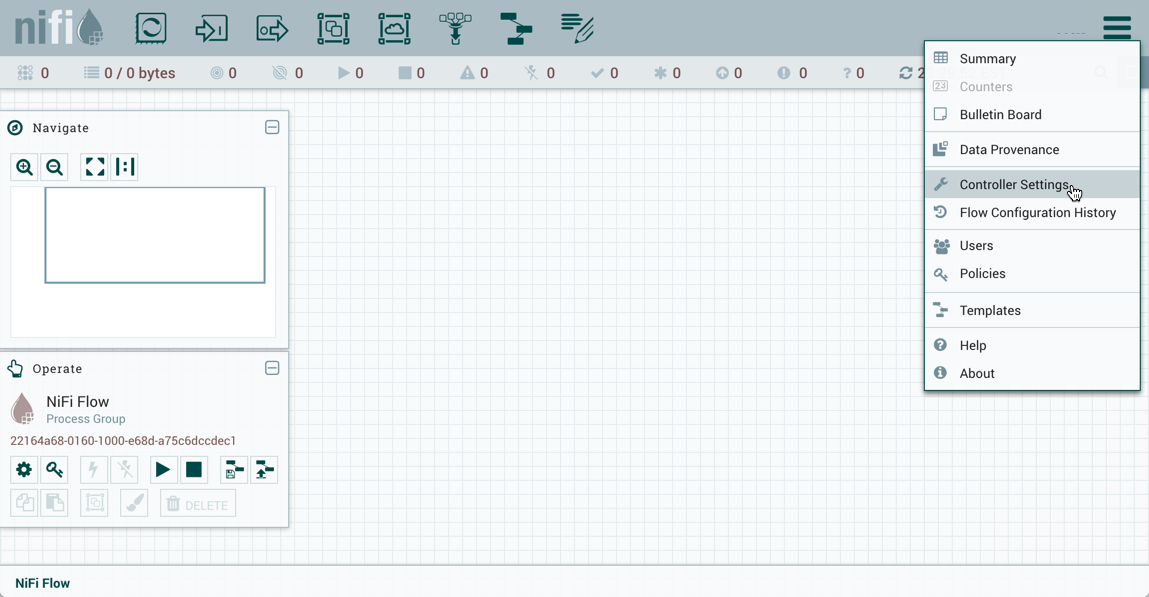
这显示了 NiFi 设置窗口。该窗口有四个选项卡:一般、报告任务控制器服务、报告任务和注册客户。通用选项卡为实例的总体最大线程计数提供设置。
总标签的右侧是报告任务控制器服务选项卡。从此选项卡中,DFM 可能会单击右上角的按钮以创建新的控制器服务。+
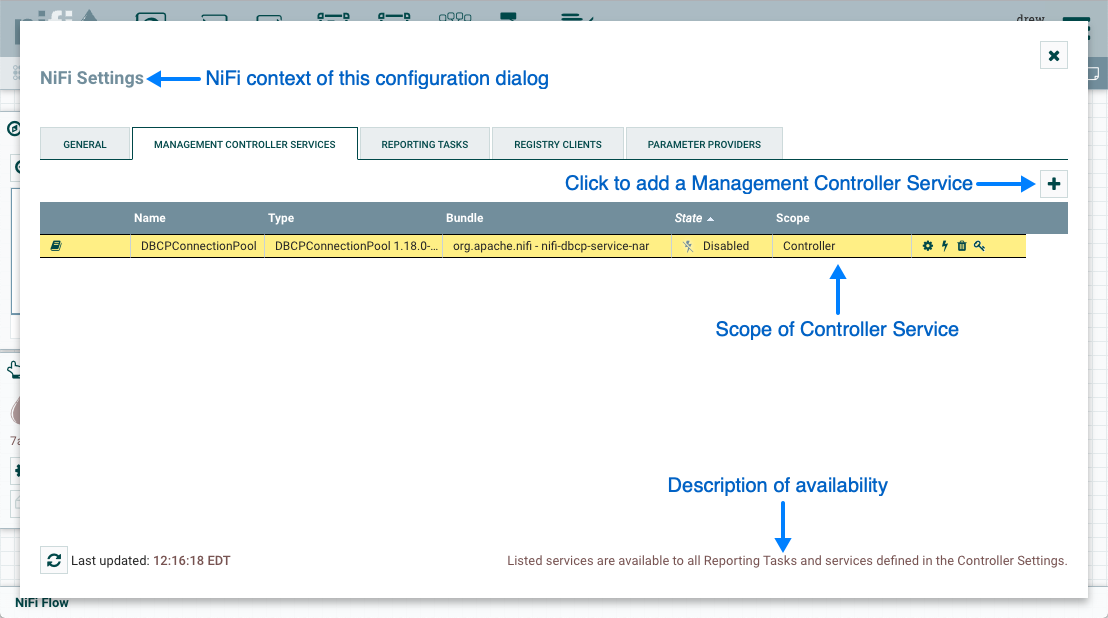
添加控制器服务窗口打开。此窗口类似于添加处理器窗口。它提供了右侧可用控制器服务的列表和标记云,显示左侧用于控制器服务的最常见类别标签。DFM 可以单击标签云中的任何标记,以便将控制器服务列表缩小到符合所需类别的标记。DFM 还可能使用窗口右上角的筛选字段来搜索所需的控制器服务,或使用左上角的源向下筛选创建它们的组的列表。从列表中选择控制器服务后,DFM 可以看到下面的服务说明。选择所需的控制器服务并单击"添加”,或者只需双击服务名称即可添加它。
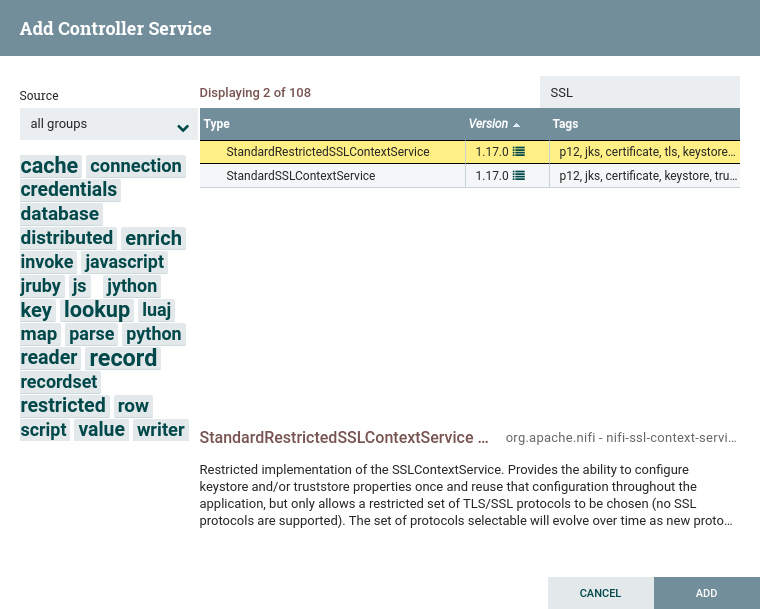
添加控制器服务后,您可以单击极右列中的"配置"按钮来配置它。本列中的其他按钮包括"启用"、“删除"和"访问策略”。

您可以通过单击左侧列中的"使用"和"警报"按钮来获取有关控制器服务的信息。

当 DFM 单击"配置"按钮时,配置控制器服务窗口将打开。它有三个选项卡:设置、属性和注释。此窗口类似于配置处理器窗口。“设置"选项卡为 DFM 提供了一个给控制器服务一个唯一名称(如果需要)的场所。它还列出了该服务的 UUID、类型、捆绑和支持信息,并提供了参考服务的其他组件(报告任务或其他控制器服务)列表。
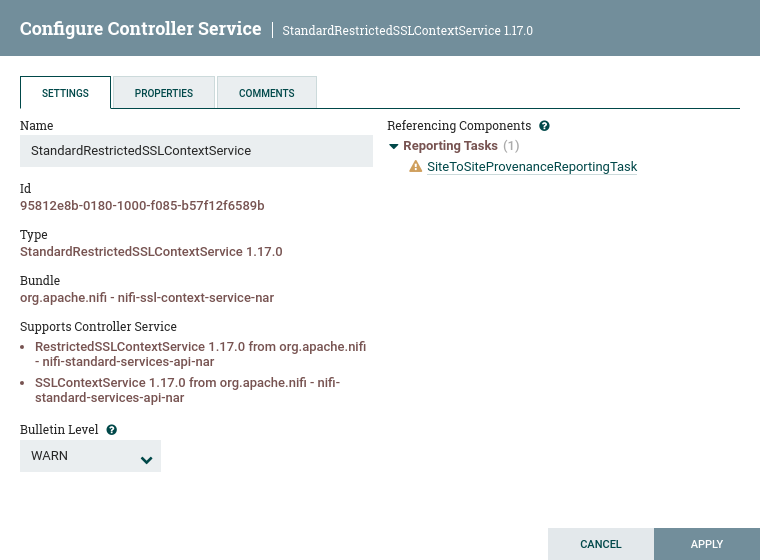
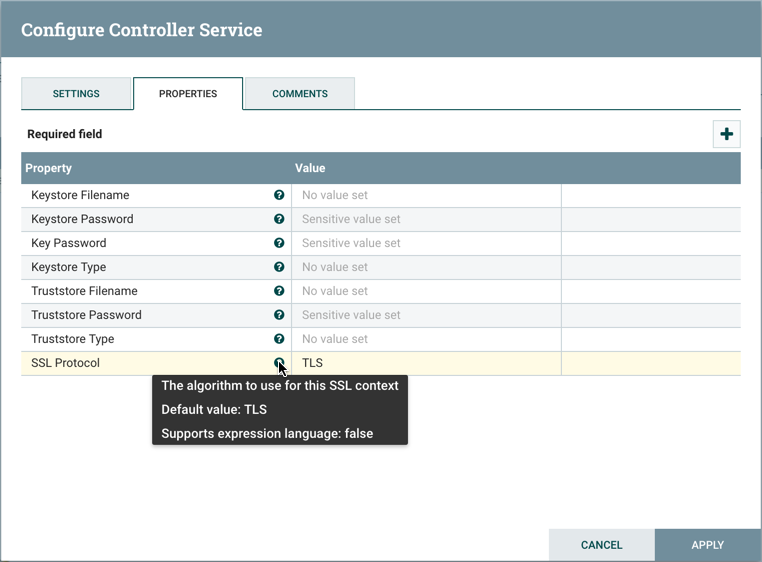
属性选项卡列出适用于特定控制器服务的各种属性。与配置处理器一样,DFM 可能会在问号图标上悬停,以查看有关每个属性的更多信息。
“注释"选项卡只是一个开放文本字段,其中 DFM 可能会包含有关服务的评论。配置控制器服务后,单击"应用"以保存配置并关闭窗口,或单击"取消"以丢弃更改并关闭窗口。
为数据流添加控制器服务
要为数据流添加控制器服务,您可以右键单击"流程组"并选择"配置”,或者单击"操作调色板"中的"配置”。
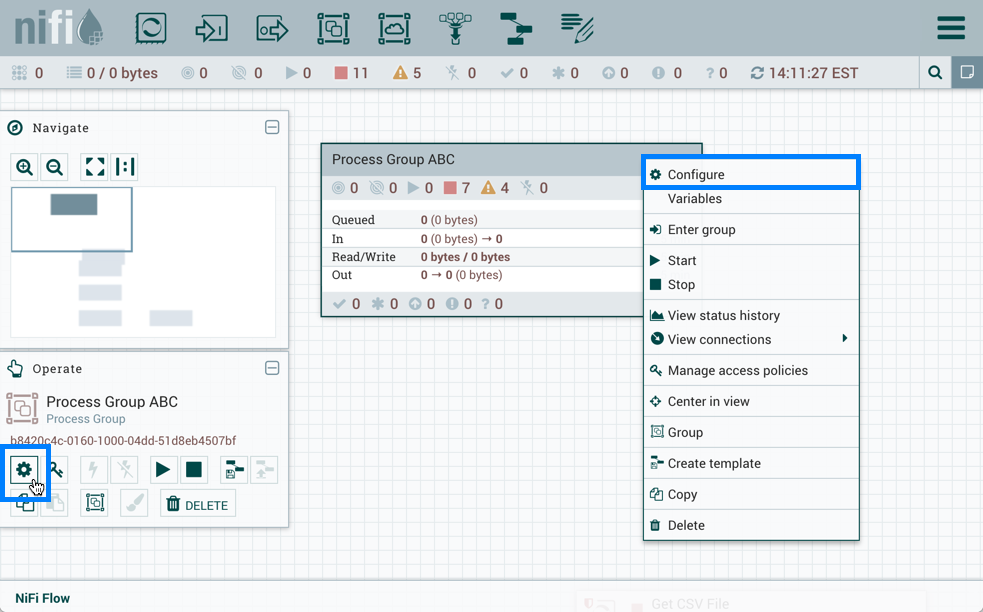
当您单击操作调色板中的配置时,在画布上未选取任何配置,则为根过程组添加控制器服务。然后,控制器服务可用于数据流中的所有嵌套处理组。当您在画布上选择流程组,然后单击操作调色板或流程组上下文菜单中的配置时,该服务将提供给该处理组和下面定义的所有处理器和控制器服务。

使用以下步骤添加控制器服务:
-
单击配置,无论是从操作调色板,还是从流程组上下文菜单。这显示了过程组配置窗口。窗口有两个选项卡:一般和控制器服务。总标签用于与流程组的一般信息有关的设置。
-
从流程组配置页面中选择控制器服务选项卡。
-
单击按钮以显示添加控制器服务对话。
+ -
选择所需的控制器服务,然后单击"添加"。
-
单击配置图标() 执行任何必要的控制器服务配置任务 (
 )在右侧列中。
)在右侧列中。
启用/禁用控制器服务
配置了控制器服务后,必须启用它才能运行。使用"启用"按钮 (
 )在控制器服务选项卡的极右列中。为了修改现有的/运行控制器服务,DFM 需要停止/禁用它(以及所有引用报告任务和控制器服务)。使用"禁用"按钮 (
)在控制器服务选项卡的极右列中。为了修改现有的/运行控制器服务,DFM 需要停止/禁用它(以及所有引用报告任务和控制器服务)。使用"禁用"按钮 (
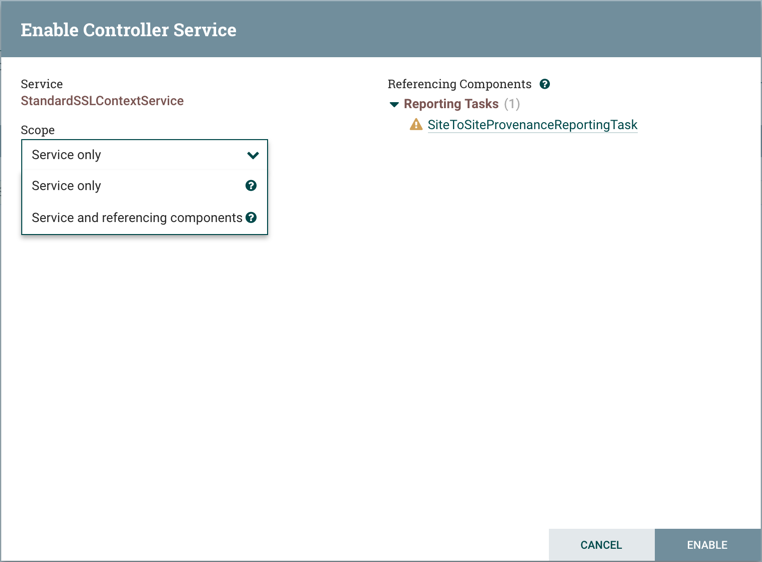
 ).DFM 无需搜索该控制器服务引用的每个组件,而是能够在禁用相关控制器服务时阻止/禁用它们。启用控制器服务时,DFM 可以选择启动/启用控制器服务和所有引用组件,或者仅启动/启用控制器服务本身。
).DFM 无需搜索该控制器服务引用的每个组件,而是能够在禁用相关控制器服务时阻止/禁用它们。启用控制器服务时,DFM 可以选择启动/启用控制器服务和所有引用组件,或者仅启动/启用控制器服务本身。
报告任务
报告任务在后台运行,以提供有关 NiFi 实例中发生情况的统计报告。DFM 添加并配置类似于控制器服务流程的报告任务。要添加报告任务,请从"全球菜单"中选择控制器设置。
这显示了 NiFi 设置窗口。选择"报告任务"选项卡,然后单击右上角的按钮以创建新的报告任务。+
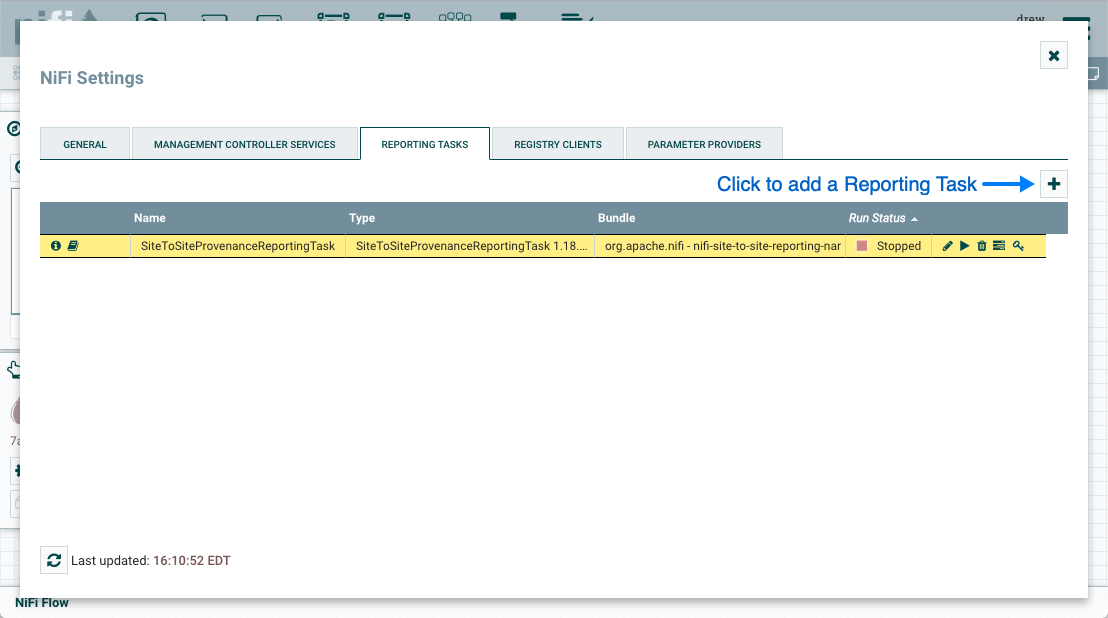
添加报告任务窗口打开。此窗口类似于添加处理器窗口。它提供了右侧可用报告任务列表和标记云,显示左侧用于报告任务的最常见类别标记。DFM 可以单击标签云中的任何标记,以便将报告任务列表缩小到符合所需类别的标记。DFM 还可以使用窗口右上角的筛选字段来搜索所需的报告任务,或者使用左上角的源向下筛选创建它们的组的列表。从列表中选择报告任务后,DFM 可以看到下面任务的描述。选择所需的报告任务并单击"添加",或者只需双击服务名称即可添加它。
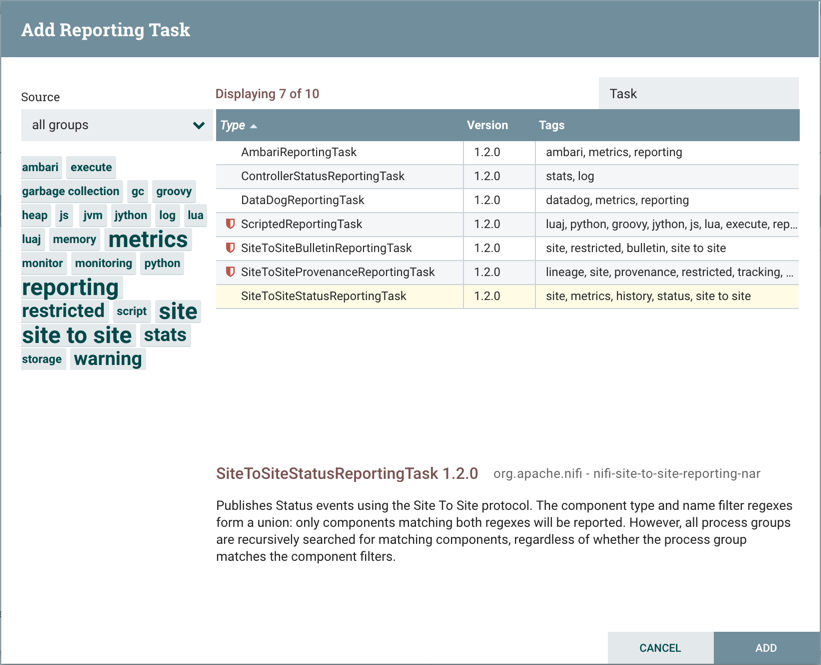
添加报告任务后,DFM 可以通过单击极右列中的"编辑"按钮来配置它。本专栏中的其他按钮包括"开始"、“删除”、“状态"和"访问策略”。
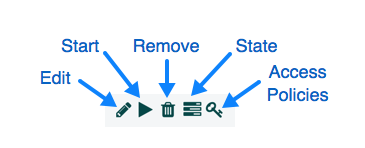
您可以通过单击左侧列中的"查看详细信息"、“使用情况"和"警报"按钮来获取有关报告任务的信息。
当 DFM 单击"编辑"按钮时,配置报告任务窗口将打开。它有三个选项卡:设置、属性和注释。此窗口类似于配置处理器窗口。“设置"选项卡为 DFM 提供了一个给报告任务一个唯一名称(如果需要)的名额。它还列出了任务的 UUID、类型和捆绑式信息,并为任务的调度策略和运行计划(类似于处理器中的相同设置)提供了设置。DFM 可能会将鼠标悬停在问号图标上,以查看有关每个设置的更多信息。
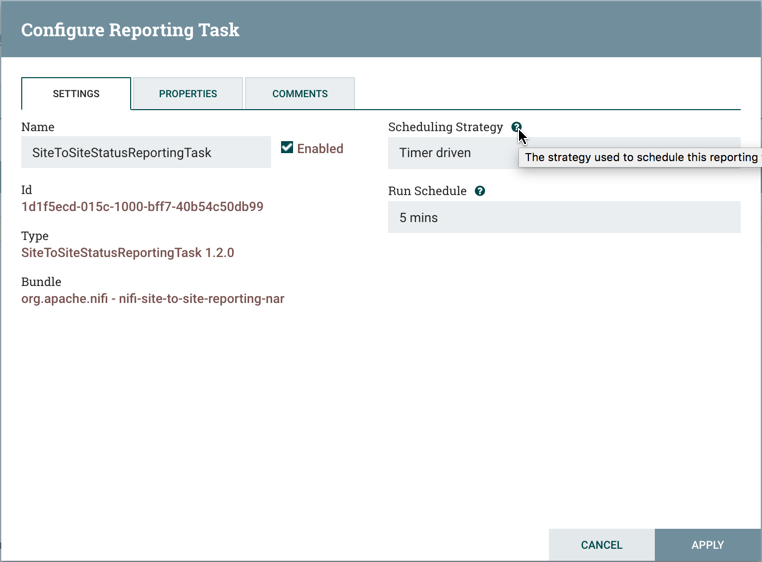
属性选项卡列出了可用于任务配置的各种属性。DFM 可能会将鼠标悬停在问号图标上,以查看有关每个属性的更多信息。
“注释"选项卡只是一个开放文本字段,其中 DFM 可能包含有关任务的评论。配置报告任务后,单击"应用"以保存配置并关闭窗口,或单击"取消"以丢弃更改并关闭窗口。
当您想要运行报告任务时,单击"开始"按钮 (
 ).
).
连接组件
一旦处理器和其他组件被添加到画布和配置中,下一步是将它们连接到彼此,以便 NiFi 在处理完每个 FlowFile 后知道如何处理它们。这是通过在每个组件之间创建连接来实现的。当用户将鼠标悬停在组件的中心时,将新连接图标 (
 ) 显示:
) 显示:
用户将连接气泡从一个组件拖到另一个组件,直到突出显示第二个组件。当用户释放鼠标时,会出现"创建连接"对话。此对话由两个选项卡组成:“详细信息"和"设置”。下面详细讨论了它们。请注意,可以绘制连接,以便它循环回同一处理器。如果 DFM 希望处理器尝试在流文件发生故障关系时重新处理流程文件,则此程序可能很有用。要创建此类型的循环连接,只需将连接气泡拖走,然后返回到同一处理器,直到它被突出显示。然后释放鼠标,并显示相同的"创建连接"对话。
详细信息选项卡
“创建连接"对话的详细信息选项卡提供了有关源和目的地组件的信息,包括组件名称、组件类型和组件所居住的流程组:
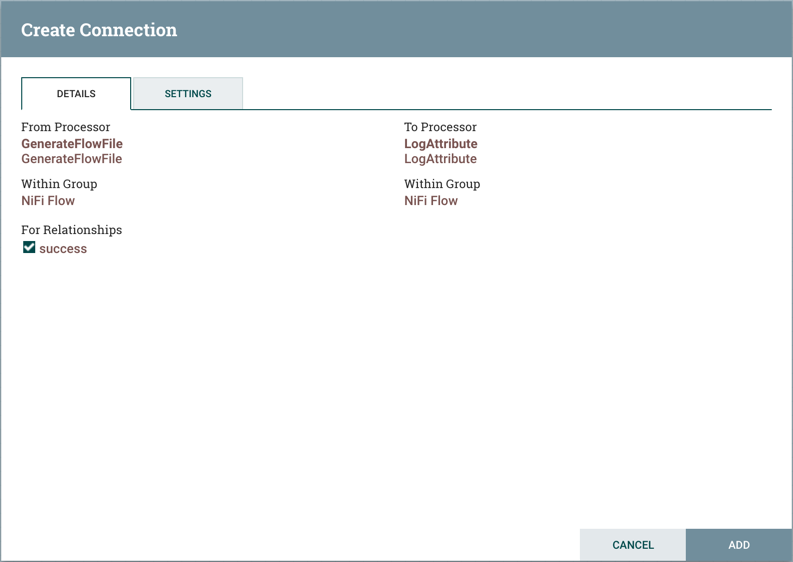
此外,此选项卡还提供了选择应包含在此连接中的关系的权项。必须选择至少一种关系。如果只有一种关系可用,则会自动选择。
| 如果添加多个连接与相同的关系,任何流文件路由到该关系将自动"克隆”,并将向每个连接发送副本。 | |
|---|---|
设置
“设置"选项卡提供配置连接名称、流文件过期、背压阈值、负载平衡策略和优先级的能力:
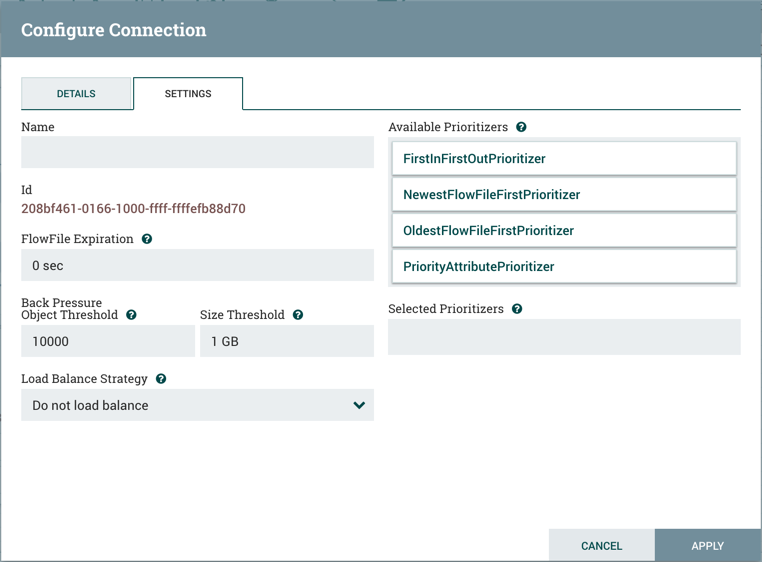
连接名称是可选的。如果没有指定,则为"连接"显示的名称将是为"连接"而活跃的关系的名称。
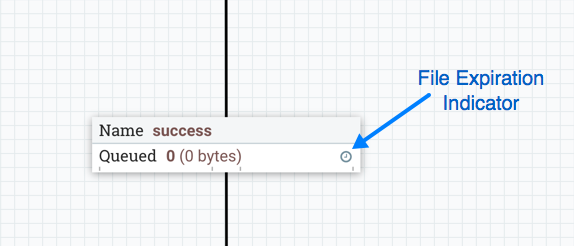
流文件过期
FlowFile 过期是一个概念,通过这个概念,无法及时处理的数据可以自动从流中删除。例如,当数据量预计将超过可发送到远程站点的容量时,这很有用。在这种情况下,到期可以与优先级器一起使用,以确保首先处理最高优先级数据,然后可以丢弃在一定时间段内无法处理的任何数据(例如,一小时)。到期期基于数据输入 NiFi 实例的时间。换句话说,如果给定连接上的文件过期设置为"1 小时”,并且在 NiFi 实例中已使用一小时的文件达到该连接,则该连接将过期。默认值表示数据永远不会过期。设置"0 秒"以外的文件过期时,连接标签上会显示一个小时钟图标,因此 DFM 在查看画布上的流时可以一目了然地看到它。0 sec
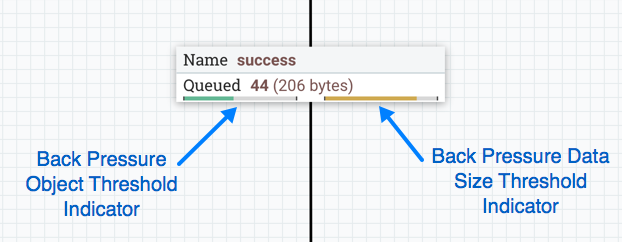
背压
NiFi 为背压提供了两个配置元素。这些阈值表示在连接源的组件不再计划运行之前,应允许在队列中存在多少数据。这样,系统可以避免数据溢出。提供的第一个选项是"后压对象阈值”。这是在施加后压之前可以排队的 FlowFiles 数量。第二个配置选项是"背压数据大小阈值”。这指定了在施加后压之前应排队的最大数据量(大小)。此值通过输入一个数字进行配置,然后输入数据大小(字节、千字节、兆字节、千兆字节或 TB)。B``KB``MB``GB``TB
默认情况下,每个新增连接将有一个默认的背压对象阈值和后压数据大小阈值 。这些默认值可以通过修改nifi.属性文件中的适当属性来更改。10,000 objects``1 GB |
|
|---|---|
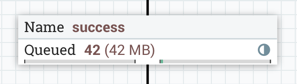
启用后压后,连接标签上会显示小进度条,因此 DFM 在查看画布上的流时可以一目了然地看到它。进度条根据队列百分比更改颜色:绿色(0-60%)、黄色(61-85%)和红色(86-100%)。
将鼠标悬停在栏上会显示确切的百分比。
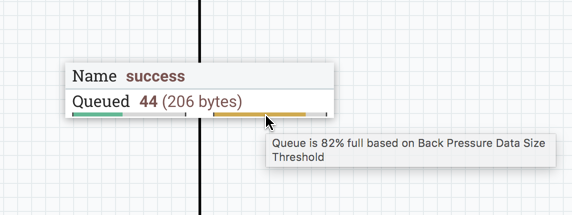
当队列完全满时,连接以红色突出显示。

负载平衡
负载平衡策略
为了在集群中的节点之间以流的方式分配数据,NiFi 提供了以下负载平衡策略:
- 不要负载平衡:不要在组集的节点之间加载平衡流文件。这是默认值。
- 按属性划分:根据用户指定的 FlowFile 属性的值确定向给定 FlowFile 发送给定流量文件的节点。所有具有属性相同值的流文件将发送到组中的相同节点。如果目的地节点与集束断开或无法通信,则数据不会故障到另一个节点。数据将排队,等待节点再次可用。此外,如果节点连接或离开集集,需要重新平衡数据,则应用一致的散热,以避免重新分配所有数据。
- 循环赛:流文件将以循环方式分发到集群中的节点。如果节点与组组断开连接,或者无法与节点通信,则该节点排队的数据将自动重新分配到另一个节点。如果节点无法以最快的速度接收聚类中的其他节点的数据,则节点也可能跳过一次或多个迭代,以便最大限度地提高整个组集集的数据分布吞吐量。
- 单节点:所有流文件将发送到集群中的单个节点。他们发送到哪个节点是无法配置的。如果节点与组断开连接,或者无法与节点通信,则该节点排队的数据将保持排队状态,直到节点再次可用。
| 除了 UI 设置外,还有与负载平衡相关的群集节点属性,这些属性还必须在nifi.属性中配置。 | |
|---|---|
| NiFi 持续在重新启动的集群中的节点。这可防止数据的再分配,直到所有节点都连接起来。如果组集处于关闭状态,并且不打算将节点重新调回,则用户负责通过 UI 中的"集群"对话从组集中删除节点(有关更多信息,请参阅管理节点)。 | |
|---|---|
负载平衡压缩
选择负载平衡策略后,用户可以在集群节点之间传输数据时配置数据是否应压缩。
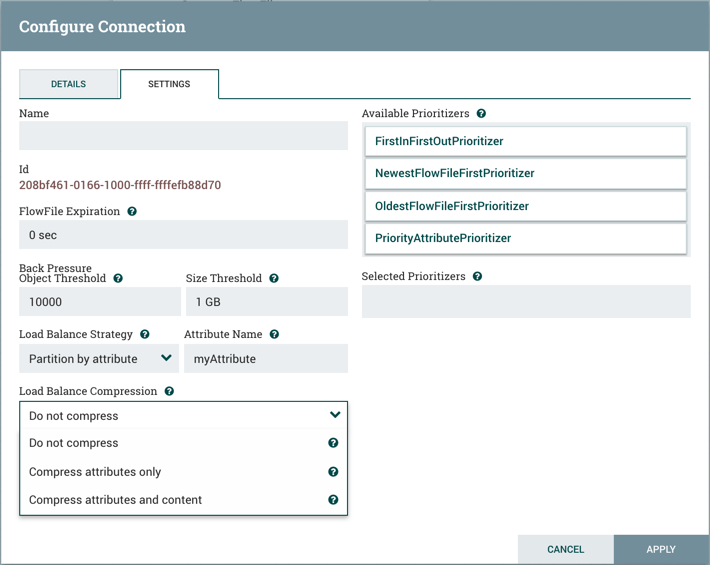
提供以下压缩选项:
- 不要压缩: 流文件不会被压缩。这是默认值。
- 仅压缩属性:流文件属性将被压缩,但流文件内容不会压缩。
- 压缩属性和内容:流文件属性和内容将被压缩。
负载平衡指标
当已实施连接平衡策略时,负载平衡指示器 (
 ) 将出现在连接上:
) 将出现在连接上:
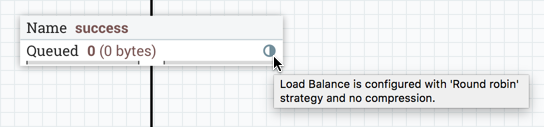
悬停在图标上将显示连接的负载平衡策略和压缩配置。此状态中的图标还表示连接中的所有数据已分布在聚类中。
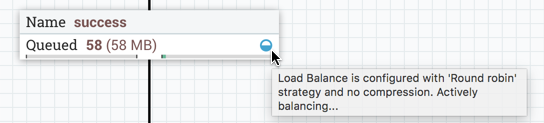
当数据在组集的节点之间主动传输时,负载平衡指示器将更改方向和颜色:
集群连接摘要
要查看数据在集束节点中分布的位置,请从"全球菜单"中选择摘要。然后为源选择"连接"选项卡和"查看连接详细信息"图标:
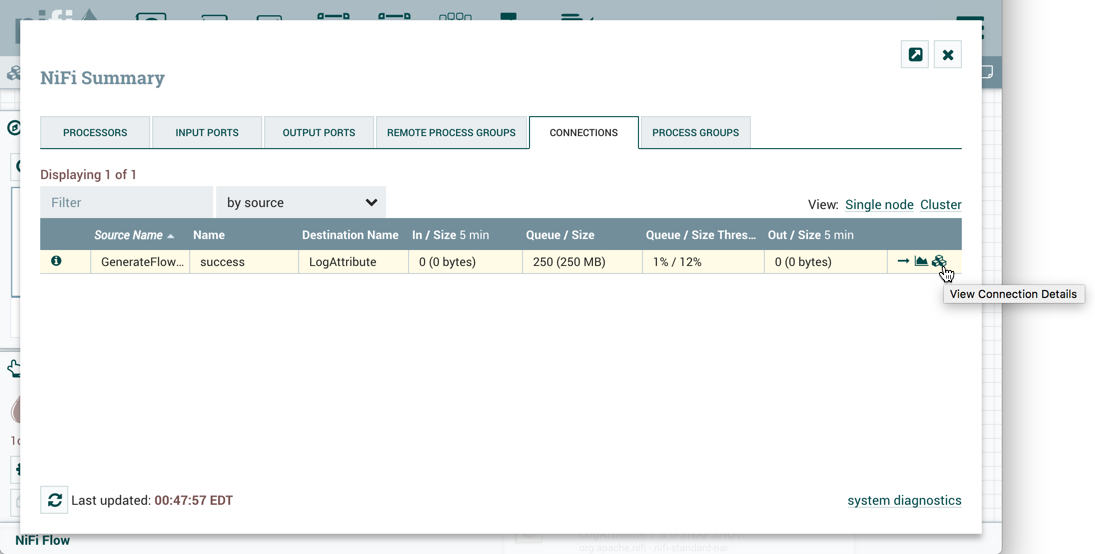
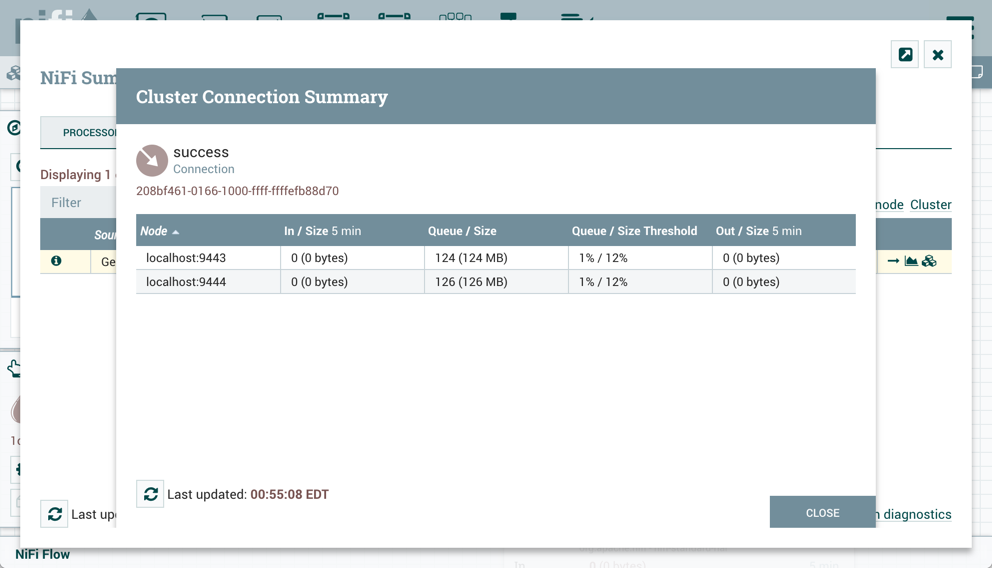
这将打开集束连接摘要对话,该对话显示集群中每个节点上的数据:
优先级
选项卡的右侧提供对队列中的数据进行优先排序的能力,以便首先处理高优先级数据。优先级器可以从顶部(“可用优先级”)拖到底部(“选定的优先级”)。可以选择多个优先级。处于"选定优先级"列表顶部的优先级是最高优先级。如果两个 FlowFile 根据此优先级具有相同的值,则第二个优先级将确定首先处理哪个 FlowFile,依次是。如果不再需要优先级,则可以将其从"选定的优先级"列表拖到"可用优先级"列表。
提供以下优先级:
- 第一首先启动器:如果两个流文件,首先到达连接的流文件将首先处理。
- 最新流文件第一优先:鉴于两个流量文件,数据流中最新的一个将首先处理。
- 最老的流存初审者:给定两个流文件,数据流中最古老的一个将首先处理。“这是默认计划,如果没有选择优先级器,则使用该方案”。
- 优先属性优先级:给定两个流文件,将提取称为"优先级"的属性。优先级值最低的将首先处理。
- 请注意,在流文件达到具有此优先级集的连接之前,应使用更新属性处理器将"优先级"属性添加到 FlowFiles 中。
- 如果只有一个人有这个属性, 它会先走。
- “优先"属性的值可以是字母数字,其中"a"将在"z"之前出现,“1"在"9"之前出现
- 如果不能将"优先级"属性解析为长单码字符串订购将被使用。例如:“99"和"100"将被订购,因此流文件与"99"排在第一位,但"A-99"和"A-100"将排序,所以流文件与"A-100"排在第一位。
| 配置了负载平衡策略,除了本地队列之外,该连接每个节点都有一个队列。优先级器将独立对每个队列中的数据进行排序。 | |
|---|---|
更改配置和上下文菜单选项
在两个组件之间绘制连接后,连接的配置可能会更改,连接可能会移动到新的目的地:但是,在进行配置或目的地更改之前,必须停止连接两侧的处理器。
要更改连接的配置或以其他方式与连接进行交互,请右键单击连接以打开连接上下文菜单。
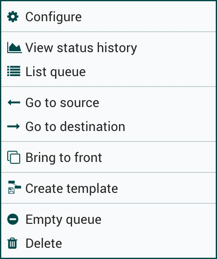
提供以下选项:
- 配置:此选项允许用户更改连接的配置。
- 查看状态历史记录:此选项会随着时间的推移打开连接统计信息的图形表示。
- 列表队列:此选项列出了可能等待处理的 FlowFiles 队列。
- 转到源:如果画布上的连接源和目的地组件之间距离很远,此选项可能很有用。通过单击此选项,画布视图将跳转到连接源。
- 前往目的地:与"去源"选项类似,此选项会更改画布上的目的地组件的视图,如果两个连接组件之间距离较远,则可能很有用。
- 向前:如果其他内容(如其他连接)与画布重叠,此选项将连接到画布前部。
- 空队列:此选项允许 DFM 清除可能等待处理的 FlowFiles 队列。当 DFM 不关心从队列中删除数据时,此选项在测试期间特别有用。选择此选项时,用户必须确认要删除队列中的数据。
- 删除: 此选项允许 DFM 删除两个组件之间的连接。请注意,连接两侧的组件必须停止,连接必须是空的,才能删除。
弯曲连接
要在现有连接中添加弯曲点(或弯头),只需双击您希望弯曲点所在的位置的连接。然后,您可以使用鼠标抓住弯曲点并拖动它,以便连接以所需的方式弯曲。您可以添加尽可能多的弯曲点,如您所欲。您也可以使用鼠标拖动连接上的标签并移动到任何现有的弯曲点。要删除弯曲点,只需再次双击即可。
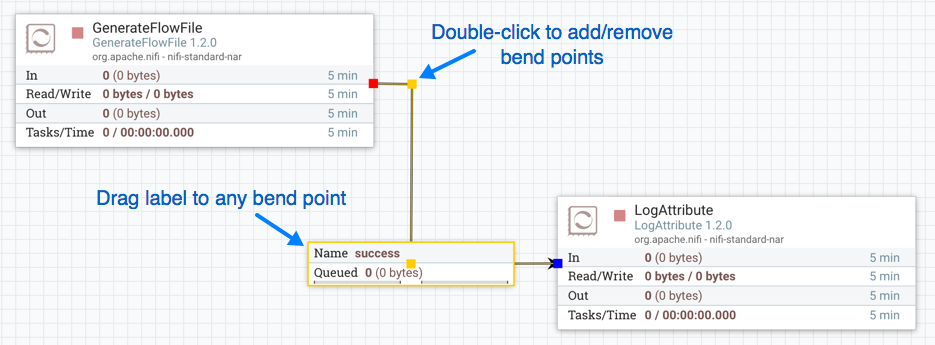
处理器验证
在尝试启动处理器之前,确保处理器的配置有效非常重要。状态指示器显示在处理器的左上侧。如果处理器无效,该指示器将显示带有感叹号的黄色警告指示指示器,指示存在问题:
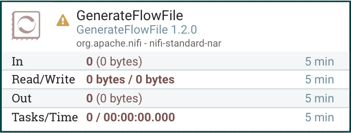
在这种情况下,用鼠标悬停在指示器图标上将提供显示处理器所有验证错误的工具尖。解决所有验证错误后,状态指示器将更改为 Stop 图标,表示处理器有效并准备启动,但目前尚未运行:
站点到站点
当将 NiFi 的一个实例的数据发送到另一个实例时,可以使用许多不同的协议。不过,首选的协议是 NiFi 站点到站点协议。站点到站点使在一个 NiFi 实例中轻松、高效地将数据传输到/从节点,或将生成应用程序的数据传输到另一个 NiFi 实例或其他消耗应用程序中的节点。
使用站点到站点可提供以下好处:
- 易于配置
- 输入远程 NiFi 实例/集群的 URL 后,可自动发现可用端口(端点),并在下拉列表中提供。
- 安全
- 可 伸缩
- 当远程聚类中的节点发生变化时,这些更改会自动检测到,数据会在组集的所有节点中扩展。
- 有效
- 站点到站点允许同时发送一批流文件,以避免在同行之间建立连接和多次往返请求的开销。
- 可靠
- 检查由发件人和接收者自动生成,并在数据传输后进行比较,以确保不发生腐败。如果检查库不匹配,则交易将被取消并再次尝试。
- 自动负载平衡
- 当节点联机或退出远程集群,或节点的负载变重或变轻时,定向到该节点的数据量将自动调整。
- 流文件维护属性
- 当流文件通过此协议传输时,流文件的所有属性都会随之自动传输。这在许多情况下都非常有利,因为 NiFi 的一个实例所确定的所有上下文和丰富性都与数据一起旅行,从而便于路由数据,并允许用户轻松检查数据。
- 适应
- 随着新技术和想法的出现,处理站点到站点通信的协议能够随之改变。当连接到远程 NiFi 实例时,会进行握手,以便协商将使用哪种协议以及使用哪种版本的协议。这允许添加新的功能,同时仍然保持与所有旧实例的向后兼容性。此外,如果在协议中发现漏洞或缺陷,则允许新版本的 NiFi 禁止对协议中受损版本进行通信。
站点到站点是一个协议,在两个 NiFi 实例之间传输数据。两端都可以是独立的 NiFi 或 NiFi 聚类。在此部分中,NiFi 实例启动的通信称为站点到站点客户端 NiFi 实例,另一端称为站点到站点服务器 NiFi 实例,以澄清每个 NiFi 实例需要什么配置。
NiFi 实例可以是站点到站点协议的客户端和服务器,但是,它只能是特定站点到站点通信中的客户端或服务器。例如,如果有三个 NiFi 实例 A、B 和 C。A 将数据推至 B,B 从 C. A 拉数据 • 将数据推→ B ←拉 C。然后 B 不仅是 A 和 B 之间通信中的服务器,也是 B 和 C中的客户端。
了解哪个 NiFi 实例将是客户端或服务器以设计您的数据流,并相应地配置每个实例非常重要。以下是基于数据流方向在哪一侧运行的组件摘要:
- 推送:客户端子将数据发送到远程处理组,服务器使用输入端口接收数据
- 拉拔:客户端子从远程处理组接收数据,服务器通过输出端口发送数据
配置站点到站点客户端NIFI实例
远程进程组:为了通过站点到站点与远程 NiFi 实例进行通信,只需将远程处理组拖动到画布上并输入远程 NiFi 实例的 URL(有关远程过程组组组的更多信息,请参阅本指南的远程处理组传输部分)网址是用于该实例的用户界面或在聚类(集束节点的网址)时使用的相同 URL。此时,您可以拖动连接到或从远程处理组,就像拖动连接到或从处理器或本地进程组一样。拖动连接时,您将有机会选择要连接到哪个端口。请注意,远程处理组可能需要长达一分钟的时间才能确定哪些端口可用。
如果从远程进程组开始拖动连接,则显示的端口将是远程组的输出端口,因为这表明您将从远程实例中提取数据。如果连接在远程进程组上结束,则显示的端口将是远程组的输入端口,因为这意味着您将把数据推至远程实例。
| 如果将远程实例配置为用于使用安全数据传输,则您将只看到授权与之通信的端口。有关配置 NiFi 以安全运行的信息,请参阅系统管理员指南。 | |
|---|---|
运输协议:在远程流程组创建或配置对话中,您可以选择运输协议用于以下图像中的站点到站点通信:
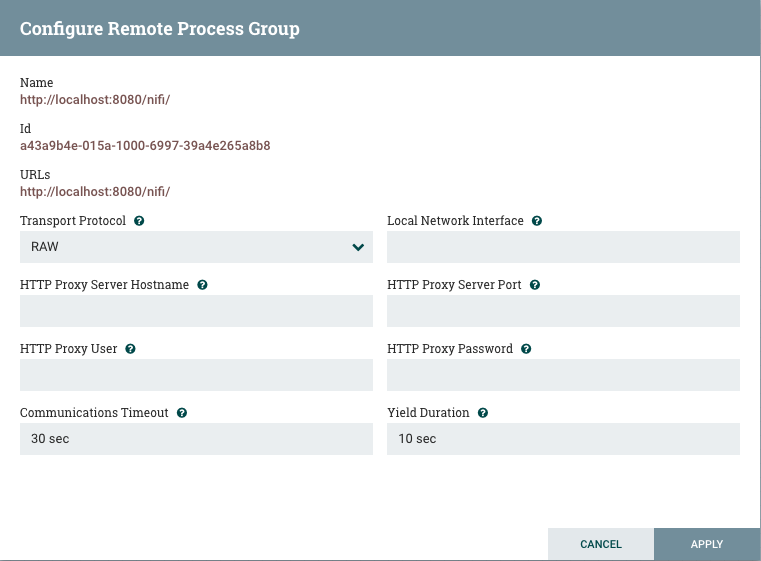
默认情况下,它被设置为RAW,使用使用专用端口的原始插座通信。如果远程 NiFi 实例处于仅允许通过HTTP (S) 协议访问或仅从特定 HTTP 代理服务器访问的限制网络中,HTTP 传输协议尤其有用。要通过 HTTP 代理服务器访问,则支持基本和消化认证。
本地网络接口:在某些情况下,最好选择一个网络接口而不是另一个网络接口。例如,如果存在有线接口和无线接口,则可能会首选有线接口。这可以通过指定要在此框中使用的网络界面的名称进行配置。如果输入的价值无效,远程处理组将无效,并且不会与其他 NiFi 实例进行通信,直到此问题得到解决。
配置站点到站点服务器 NiFi 实例
检索站点到站点的详细信息:如果您的 NiFi 运行安全,以便让另一个 NiFi 实例从您的实例中检索信息,则需要将其添加到 Global Access"检索站点到站点详细信息"策略中。这将允许其他实例查询您的实例的详细信息,如名称、描述、可用对等(聚类时的节点)、统计数据、操作系统端口信息和可用的输入和输出端口。在安全实例中使用输入和输出端口需要以下所述的其他策略配置。
输入端口:为了允许另一个 NiFi 实例将数据推送到本地实例,只需将输入端口拖入画布的根处理组即可。输入端口的名称后,它将添加到您的流中。现在,您可以右键单击输入端口并选择配置,以便调整用于端口的并发任务的名称和数量。
要在儿童处理组中创建"从站点到站点的输入端口”,请输入端口的名称,并从"从下拉到下拉"菜单中选择"远程连接(站点到站点)"。
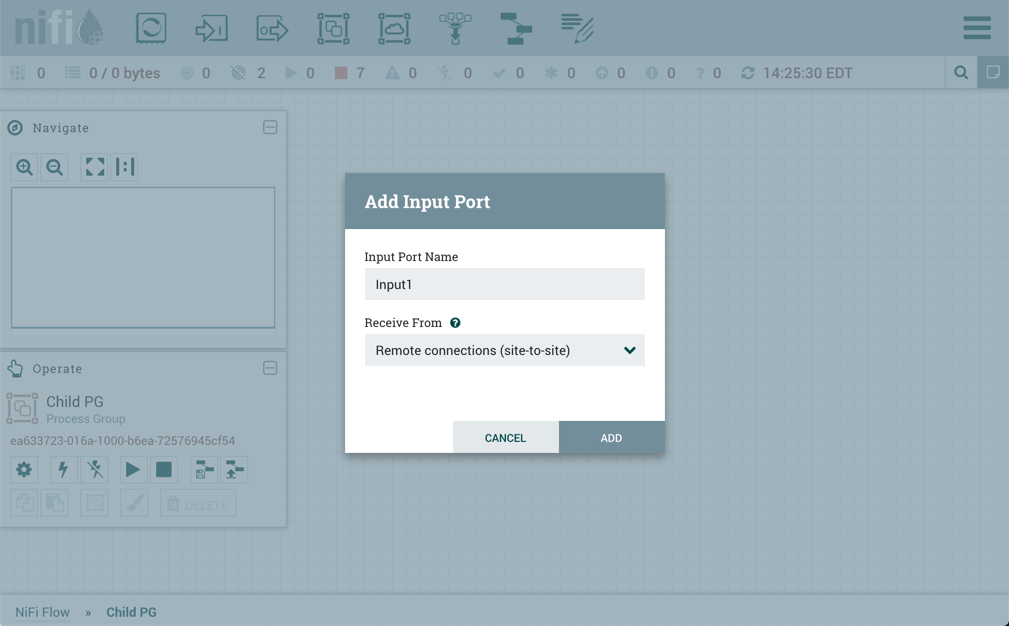
如果"站点到站点"配置为安全运行,则需要管理输入端口的"通过站点到站点接收数据"组件访问策略。只有那些已添加到策略中的用户才能与端口进行通信。
输出端口:与输入端口类似,数据流管理器可以选择在根处理组中添加输出端口。输出端口允许授权的 NiFi 实例远程连接到您的实例并从输出端口中拉取数据。将输出端口拖到画布上后,右键单击并选择配置以调整名称和允许多少并发任务。管理输出端口的"通过站点到站点接收数据"组件访问策略,以控制哪些用户有权从正在配置的实例中获取数据。
要在儿童处理组中创建"站点到站点"输出端口,请输入端口的名称,并从"发送到下拉"菜单中选择"远程连接(站点到站点)"。
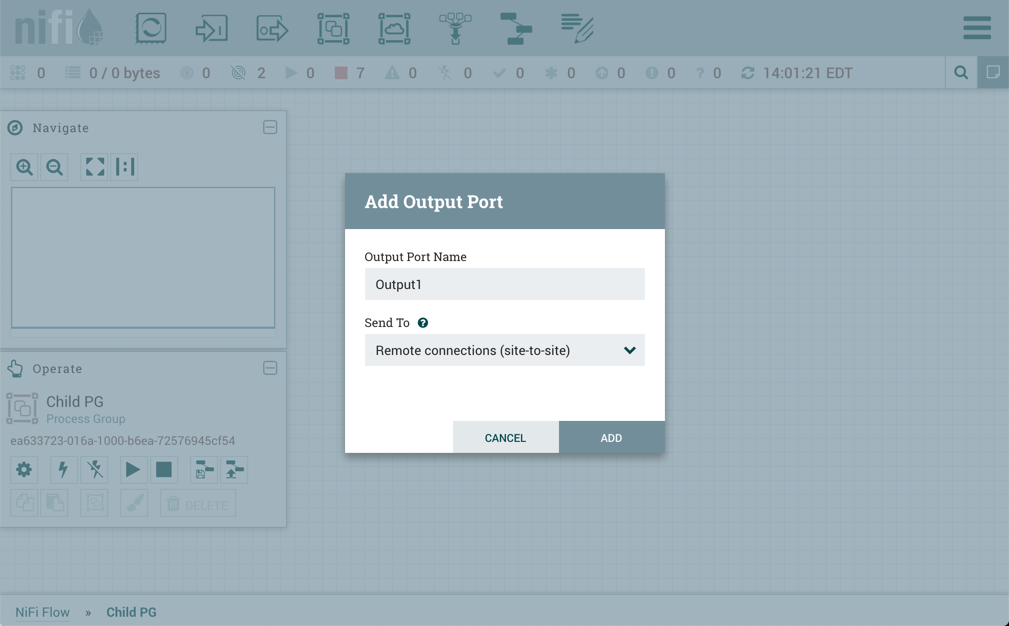
除了 NiFi 的其他实例外,其他一些应用程序还可以使用站点到站点的客户端来将数据推送至 NiFi 实例或接收数据。
| 有关如何在 NiFi 实例上启用和配置站点到站点的信息,请参阅系统管理员指南中的站点到站点属性部分。 | |
|---|---|
| 有关如何配置访问策略的信息,请参阅系统管理员指南中的访问策略部分。 | |
|---|---|
示例数据流
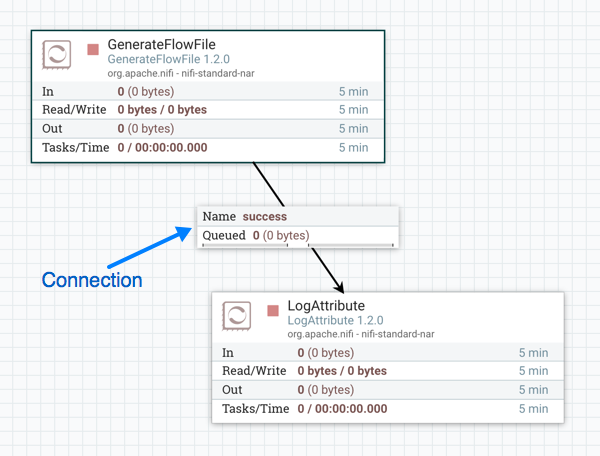
本节描述了构建数据流所需的步骤。现在,把所有的放在一起。以下示例数据流仅由两个处理器组成:生成流文件和日志属性。这些处理器通常用于测试,但它们也可用于构建用于演示目的的快速流,并看到 NiFi 在起作用。
将生成流文件和日志属性处理器拖动到画布并连接它们(使用上面提供的指南)后,将它们配置如下:
- 生成流文件
- 在"调度"选项卡上,将运行计划设置为:5 秒。请注意,生成流文件处理器可以非常快速地创建许多流文件:这就是为什么设置运行时间表很重要, 以便此流不会压倒 Nifi 正在运行的系统。
- 在属性选项卡上,将文件大小设置为:10 KB
- 日志属性
- 在"设置"选项卡上,在自动终止关系下,选择成功旁边的复选框。这将在该处理器成功处理后终止 FlowFiles。
- 此外,在"设置"选项卡上,将"公告"级别设置为"信息”。这样,当数据流运行时,此处理器将显示公告图标(参见处理器的解剖),用户可能会与鼠标一起悬停在它上空,以查看处理器正在记录的属性。
数据流应如下所列:

现在请参阅以下部分,了解如何启动和停止数据流。当数据流运行时,请务必注意显示在每个处理器表面的统计信息(参见处理器的解剖)。
数据流的指挥和控制
当一个组件添加到 NiFi 画布中时,它处于停止状态。为了触发组件,必须启动组件。一旦启动,组件可以随时停止。从停止状态,组件可以配置、启动或禁用。
启动组件
为了启动组件,必须满足以下条件:
- 组件的配置必须有效。
- 组件的所有定义关系必须连接到其他组件或自动终止。
- 必须停止组件。
- 必须启用组件。
- 该组件必须没有活动任务。有关活动任务的更多信息,请参阅”…"数据流监测部分(处理器解剖学、过程组解剖学、远程过程组解剖学)。
组件可以通过选择开始的所有组件,然后单击"开始"按钮开始 (
 )在操作调色板中,或通过右键单击单个组件并从上下文菜单中选择开始。
)在操作调色板中,或通过右键单击单个组件并从上下文菜单中选择开始。
如果启动流程组,则该流程组内的所有组件(包括儿童流程组)将启动,但无效或禁用的组件除外。
一旦开始,处理器的状态指示器将更改为播放符号 (
 ).
).
停止组件
组件在运行时可以随时停止。组件通过右键单击组件和单击上下文菜单中的"停止"或选择组件并单击"停止"按钮() 来停止
 ) 在操作调色板中。
) 在操作调色板中。
如果停止进程组,将停止处理组内的所有组件(包括儿童进程组)。
一旦停止,组件的状态指示将更改为停止符号 (
 ).
).
停止组件不会中断当前运行任务。相反,它停止安排要执行的新任务。活动任务的数量显示在处理器的右上角(有关更多信息,请参阅处理器的解剖结构)。有关如何终止运行任务,请参阅”终止组件“的任务。
终止组件的任务
当组件停止时,它不会中断当前运行的任务。这允许在没有安排新任务的情况下完成当前执行,这在许多情况下是期望的行为。在某些情况下,最好终止运行任务,特别是在任务已挂并不再响应的情况下,或在开发新流程时。
为了能够终止运行任务,必须首先停止组件(参见“停止组件")。一旦组件处于停止状态,只有当仍有任务在运行时,终止选项才会可用(参见处理器的解剖学)。终止选项 (
 ) 可在选择组件时通过上下文菜单或操作调色板访问。
) 可在选择组件时通过上下文菜单或操作调色板访问。
正在被主动终止的任务数将显示在活动任务数(例如)旁边的括号中。
 .例如,如果在选择"终止"时有一个活动任务,这将显示"0 (1)” - 这意味着 0 个活动任务和 1 个任务被终止。
.例如,如果在选择"终止"时有一个活动任务,这将显示"0 (1)” - 这意味着 0 个活动任务和 1 个任务被终止。
任务可能不会立即终止,因为不同的组件可能会对终止命令做出不同的响应。但是,无论是否有仍处于终止状态的任务,组件都可以重新配置和启动/停止。
启用/禁用组件
启用组件后,可以启动组件。例如,当组件是仍在组装的数据流的一部分时,用户可以选择禁用组件。通常,如果组件不打算运行,则组件是禁用的,而不是处于停止状态。这有助于区分故意不运行的组件和可能暂时停止的组件(例如,更改组件的配置)和无意中从未重新启动的组件。
当重新启用组件时,可以通过选择组件并单击"启用"按钮() 启用该组件
 ) 在操作调色板中。只有当选定的组件或组件被禁用时,才能使用此内容。或者,通过检查处理器配置对话设置选项卡中的"已启用"选项旁边的复选框或端口的配置对话,可以启用组件。
) 在操作调色板中。只有当选定的组件或组件被禁用时,才能使用此内容。或者,通过检查处理器配置对话设置选项卡中的"已启用"选项旁边的复选框或端口的配置对话,可以启用组件。
启用后,组件的状态指示将更改为"无效” (
 或停止 (
),取决于该组件是否有效。
或停止 (
),取决于该组件是否有效。
然后,通过选择组件并单击"禁用"按钮() 禁用组件 (
 ) 在操作调色板中,或通过清除处理器配置对话设置选项卡中的"已启用"选项旁边的复选框或端口的配置对话。
) 在操作调色板中,或通过清除处理器配置对话设置选项卡中的"已启用"选项旁边的复选框或端口的配置对话。
只能启用和禁用端口和处理器。
远程过程组传输
远程处理组提供了从 NiFi 的远程实例发送数据或检索数据的机制。当将远程处理组 (RPG) 添加到画布中时,则会添加带有"传输禁用",如图标所示(
![]() )在左上角。禁用传输时,可以通过右键单击 RPG 并单击"启用传输"菜单项来启用传输。这将导致所有有连接的端口开始传输数据。这将导致状态指示器然后更改为"传输启用"图标 (
)在左上角。禁用传输时,可以通过右键单击 RPG 并单击"启用传输"菜单项来启用传输。这将导致所有有连接的端口开始传输数据。这将导致状态指示器然后更改为"传输启用"图标 (
![]() ).
).
如果与远程处理组通信出现问题,则警告指示器 (
) 可能反而出现在左上角。用鼠标悬停在此警告指示器上将提供有关问题的更多信息。
单端口传输
有时,DFM 可能希望启用或禁用远程处理组中仅用于特定端口的传输。这可以通过右键单击远程进程组和选择"管理远程端口"菜单项目来实现。这提供了一个配置对话,可以从中配置端口:
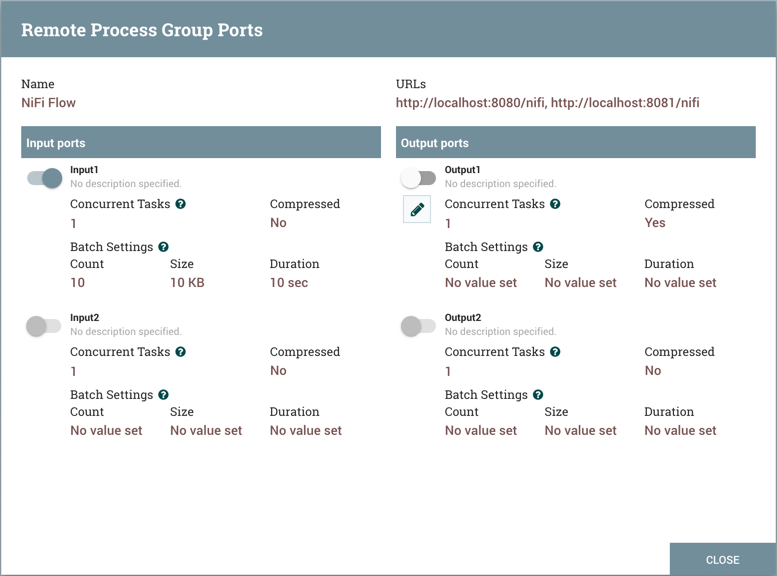
左侧列出了 NiFi 的远程实例允许发送到的所有输入端口。右侧列出此实例能够拉取数据的所有输出端口。如果遥控实例使用安全通信(NiFi 实例的 URL 以此实例开头而不是以)为开头,则不会显示该实例未提供给此实例的任何端口。https://``http://
| 如果此对话中未显示预期显示的端口,则确保实例具有适当的权限,并且远程处理组的流量是最新的。这可以通过关闭远程处理组端口对话和查看远程处理组的左下角来检查。显示流量上次刷新的日期和时间。如果流量似乎已过时,则可以通过右键单击远程处理组并选择"刷新远程"来更新流量。(有关更多信息,请参阅远程进程组的解剖学)。 | |
|---|---|
每个端口都显示其名称、描述、并发任务的配置数量以及发送到该端口的数据是否会被压缩。此外,还显示端口配置的批次设置(计数、大小和持续时间)。此信息的左侧是一个切换开关,可打开或关闭端口。没有连接到它们的端口已变灰:

开/关切换开关提供了一个机制,使远程处理组中的每个端口能够独立地禁用传输。连接但当前未传输的端口可以通过单击铅笔图标进行配置 (
)开/关切换开关下方。单击此图标将允许 DFM 更改并发任务数,无论在向此端口传输数据时是否应使用压缩,以及批次设置。
对于输入端口,批次设置控制 NiFi 在交易中如何向远程输入端口发送数据。NiFi 将传输流文件,因为它们在传入关系中排队,直到满足任何限制(计数、大小、持续时间)。如果没有配置任何设置,默认使用 500 毫秒的批次持续时间。
对于输出端口,批次设置告诉远程 NiFi NiFi 如何喜欢在交易中从远程输出端口接收数据。远程 NiFi 将使用指定的设置(计数、大小、持续时间)来控制流文件的传输。如果没有配置任何设置,默认情况下将使用 5 秒批次持续时间。
在数据流中导航
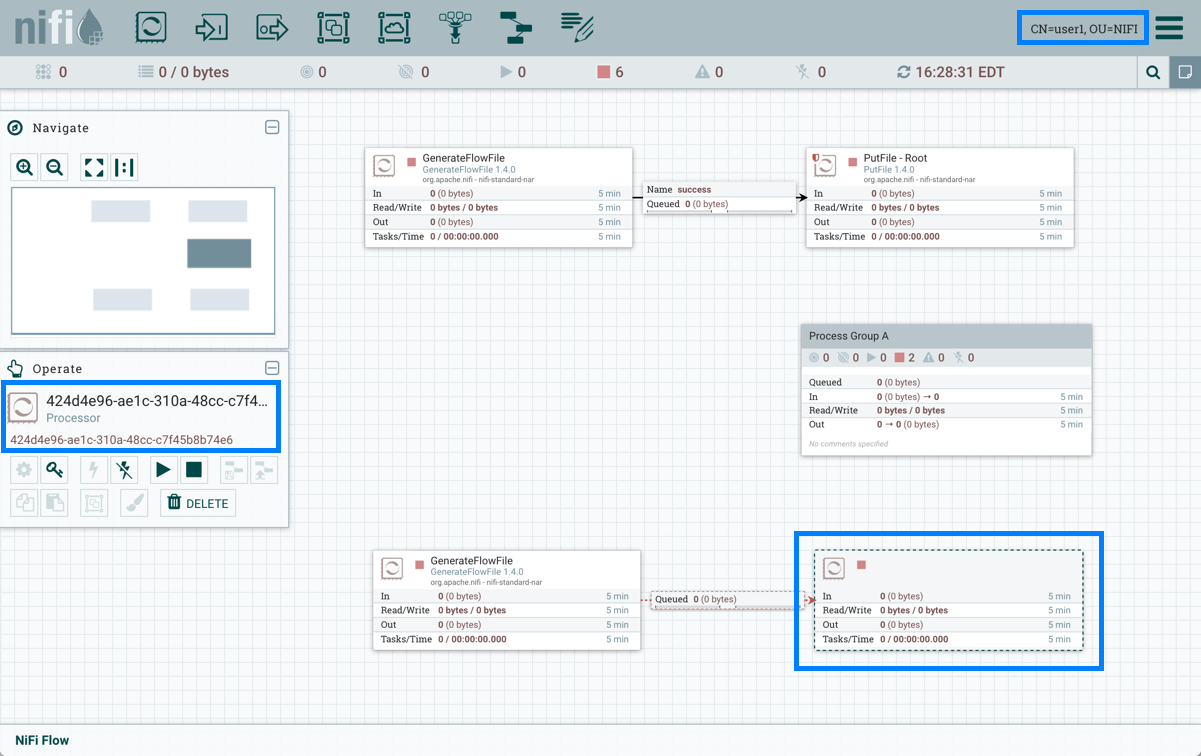
NiFi 提供了各种机制来绕过数据流。NiFi 用户界面部分描述了在 NiFi 画布周围导航的各种方式;但是,一旦画布上存在流,则有其他方法从一个组件到另一个组件。当多个流程组在流中存在时,面包屑会出现在屏幕底部,从而提供在它们之间导航的方法。此外,要输入当前在画布上可见的进程组,只需双击即可,从而"钻入"其中。连接还提供了在流中从一个位置跳到另一个位置的方法。右键单击连接并选择"转源"或"转到目的地",以便跳转到连接的一端或另一端。这在大型复杂数据流中非常有用,因为连接线可能很长,并且跨越画布的大片区域。最后,所有组件都提供在流中向前或向后跳跃的能力。右键单击任何组件(例如处理器、处理组、端口等),然后选择"上游连接"或"下游连接"。对话窗口将打开,显示用户可能跳转到的可用上游或下游连接。当尝试向后跟踪数据流时,这尤其有用。通常很容易从头到尾跟踪数据流路径,深入到嵌套过程组:但是,要跟随数据流向另一个方向发展可能更加困难。
组件链接
超链接可用于直接导航到 NiFi 画布上的组件。当配置多租户授权时,这尤其有用。例如,可以向用户提供 URL,引导他们到他们拥有特权的特定流程组。
NiFI 实例的默认 URL 是指向根过程组。当在画布上选择组件时,网址会以组件的流程组 ID 和组件 ID 的形式进行更新。在以下屏幕截图中,流程组 PG1 中的生成流文件处理器是选定的组件:https://localhost:8443/nifi``https://localhost:8443/nifi/?processGroupId=<UUID>&componentIds=<UUIDs>;
| 支持链接到画布上的多个组件,并限制 URL 的长度不能超过 2000 个字符的限制。 | |
|---|---|
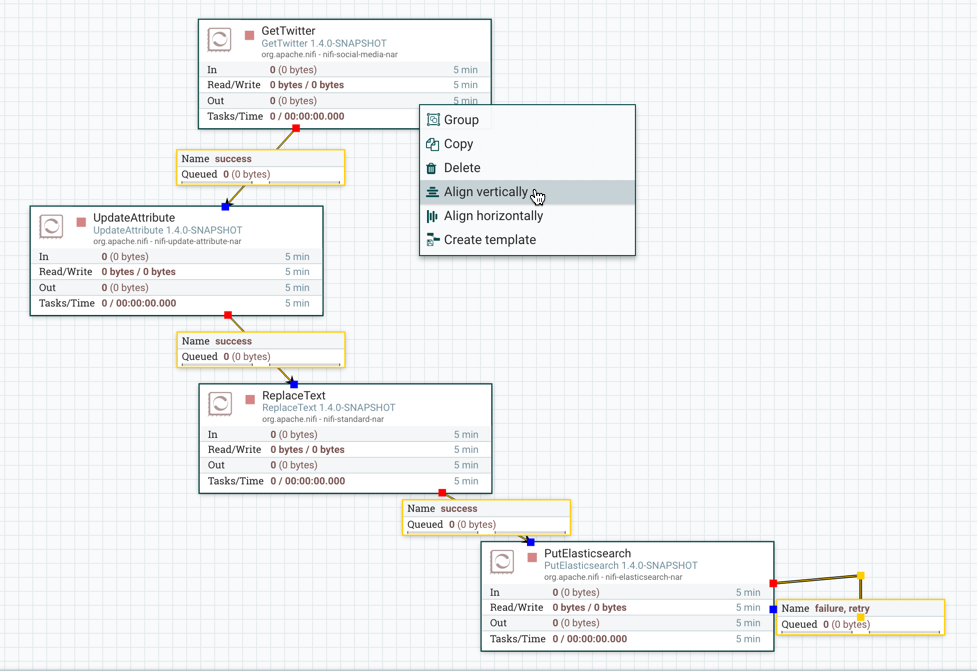
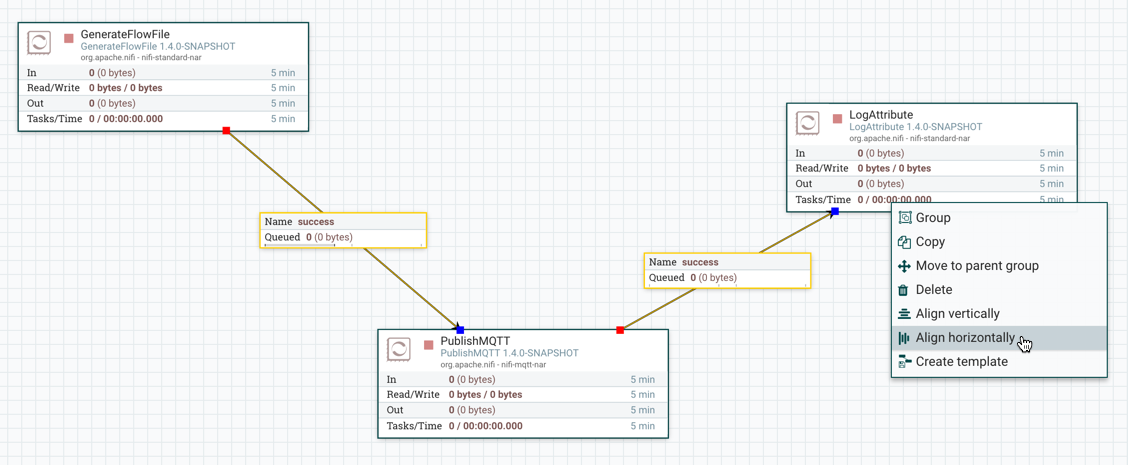
组件对齐
NiFi 画布上的组件可以对齐,以便更精确地排列您的数据流。为此,请首先选择要对齐的所有组件。然后右键单击以查看上下文菜单,并根据您期望的结果选择"垂直对齐"或"水平对齐"。
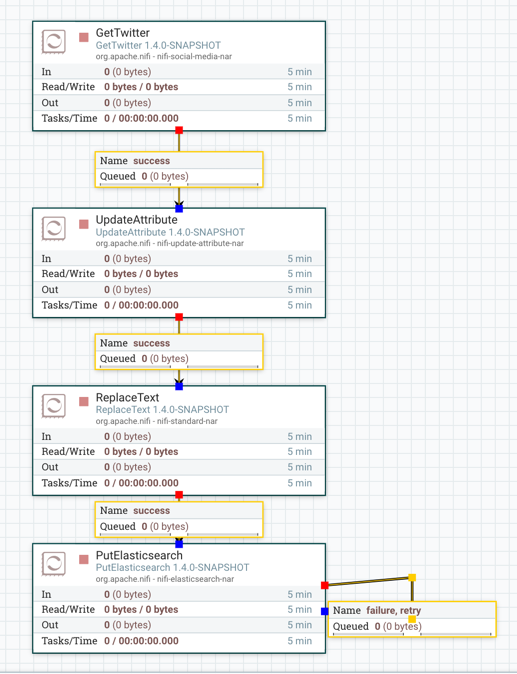
垂直对齐
下面是在画布上垂直对齐组件的示例。选择/突出显示所有组件时,右键单击:
并选择"垂直对齐"以实现以下结果:
水平对齐
下面是在画布上水平对齐组件的示例。选择/突出显示所有组件时,右键单击:
并选择"水平对齐"以实现以下结果:

数据流中的搜索组件
NiFi UI 提供搜索功能,以帮助轻松查找画布上的组件。您可以使用搜索查找组件的名称、类型、标识符、配置属性及其值。搜索还能够根据使用"过滤器"和"关键字"的某些条件对搜索结果进行细化和缩小。
示例 1:结果将包含与"处理器 1"匹配的组件。
处理器 1
过滤 器
筛选器可以添加到搜索框中,作为密钥值对,其中密钥已预定义,并根据给定值检查某些条件。语法是"关键:值"。
示例 2:搜索将在包含其名称或 ID 中的字符串"我的组"的流程组(直接或通过包含的流程组)下执行。结果将包含与"处理器 1"匹配的组件。
组:我的组处理器1
过滤器可以与其他搜索词一起使用,并且可以使用多个筛选器。唯一的限制是搜索必须从过滤器开始。忽略未知过滤器或具有未知值的已知过滤器。如果多次出现相同的筛选密钥,则将使用第一个筛选密钥。不同筛选器的顺序对结果没有影响。
示例 3:搜索将仅限于当前活跃的进程组(以及其中的处理组)。结果将包含匹配"导入"的组件,但将排除属性匹配。
范围:此处属性:排除导入
支持的过滤器如下:
范围: 此筛选器根据用户当前活跃的进程组缩小了搜索范围。唯一的有效值是"这里"。此过滤器的使用类似于"范围:此处"。任何其他值被视为无效,因此在搜索过程中将忽略筛选器。
组:此筛选器根据提供的进程组名称或 ID 缩小了搜索范围。搜索将仅限于与过滤器值相符的组(及其组件 (包括子组及其组件) 的名称或 ID。如果没有组匹配过滤器,结果列表将是空的。
属性:有了这个,用户可以防止属性匹配出现在搜索结果中。有效值为:“否”、“否”、“虚假”、“排除"和"0”。
关键字
用户可以在搜索框中使用预先定义的(对案例不敏感的)关键字,这些关键字将检查某些条件。
示例 4:“禁用"将被视为关键字和常规搜索词。结果将包含禁用端口和处理器作为以任何方式匹配"禁用"的所有其他组件。
禁用
关键字可用于筛选器(见下文),但不能与其他搜索词(否则它们不会被视为关键字),并且一次只能使用一个关键字。但请注意,关键字也将同时被视为一般搜索词。
示例 5:搜索将仅限于当前选定的流程组(及其子过程组)。此处的"无效”(因为过滤器后是单独的)将同时被视为关键字和常规搜索词。结果将包含无效的处理器和端口,以及以任何方式匹配"无效"的所有其他组件。
范围:此处无效
支持的关键字如下:
- 计划状态
- 禁用:将禁用端口和处理器添加到结果列表中。
- 无效: 将端口和处理器添加到组件无效的结果列表中。
- 运行: 将运行端口和处理器添加到结果列表中。
- 停止: 将停止的端口和处理器添加到结果列表中。
- 验证: 将处理器添加到当时验证的结果列表中。
- 调度策略
- 事件: 将处理器添加到计划策略为"事件驱动"的结果列表中。
- 定时器: 将处理器添加到计划策略为"定时器驱动"的结果列表中。
- 执行
- **主要:**将处理器添加到仅设置在主节点上运行的结果列表(无论处理器当前是否运行)。
- 背压
- 背压: 将连接添加到当时施加后压的结果列表中。
- 压力:见"后压"。
- 呼气
- 到期:将连接添加到包含过期流文件的结果列表中。
- 过期:见"到期"。
- 传输
- 不传输: 将远程进程组添加到当时未传输数据的结果列表中。
- 传输: 将远程进程组添加到当时传输数据的结果列表中。
- 传输禁用:请参阅"不传输"。
- 启用传输功能:请参阅"传输"。
数据流监测
NiFi 提供了大量有关数据流的信息,以便监控其健康状况和状态。状态栏提供有关整个系统健康状况的信息(参见NiFi 用户界面)。处理器、流程组和远程处理组提供有关其操作的细粒数详细信息。连接和处理组提供有关其队列中数据量的信息。摘要页面以表格格式提供画布上所有组件的信息,并提供系统诊断,包括磁盘使用、CPU 利用率以及 Java 堆和垃圾收集信息。在聚类环境中,此信息可按节点或整个聚类进行聚合。我们将在下面探索这些监控文物。
处理器的解剖
NiFi 提供了有关画布上每个处理器的大量信息。下图显示了处理器的解剖结构:

图像概述了以下元素:
- 处理器类型: NiFi 提供几种不同类型的处理器,以便执行各种任务。每种类型的处理器都设计用于执行一项特定任务。处理器类型(PutFile,在此示例中)描述了此处理器执行的任务。在这种情况下,处理器将流文件写入磁盘 - 或将流文件"放入"到文件。
- 公告指示器:当处理器记录某些事件发生时,它会生成一个公告,通过用户界面通知正在监控 NiFi 的人。DFM 能够通过更新处理器配置对话的"设置"选项卡中的"设置"字段来配置应在用户界面中显示哪些公告。默认值是,这意味着只有警告和错误将显示在 UI 中。除非此处理器存在公告,否则此图标不存在。当它存在时,用鼠标悬停在图标上将提供一个工具尖,解释处理器提供的消息以及公告级别。如果 NiFi 实例被聚类,它也将显示发出公告的节点。公告在五分钟后自动过期。
WARN - 状态指示器 : 显示处理器的当前状态。以下指标是可能的:
-
运行: 处理器当前运行。
-
已停止:处理器有效且已启用,但未运行。
-
无效: 处理器已启用,但目前无效,无法启动。悬停在此图标上将提供一个工具尖,指示处理器为什么无效。
-
禁用:处理器不运行,在启用之前无法启动。此状态不表示处理器是否有效。
-
- 处理器名称:这是处理器的用户定义名称。默认情况下,处理器的名称与处理器类型相同。在示例中,此值为"复制/审核"。
- 活动任务:此处理器当前执行的任务数。这个数字受处理器配置对话"调度"选项卡中的"并发任务"设置的限制。在这里,我们可以看到处理器目前正在执行一项任务。如果对 NiFi 实例进行聚类,此值将表示当前在组集中所有节点执行的任务数。
- 5 分钟统计:处理器以表格形式显示多个不同的统计数据。这些统计数据都表示过去五分钟内完成的工作量。如果对 NiFi 实例进行聚类,这些值将指示过去五分钟内所有节点组合完成的作业量。这些指标包括:
- 在: 处理器从其传入的连接的队列中提取的数据量。此值表示为 < 计数>(<大小>),其中<计数>是从队列中取出的流文件数量,<大小>是这些 FlowFiles 内容的总大小。在此示例中,处理器从输入队列中提取了 29 个流文件,总计 14.16 兆字节 (MB)。
- 阅读/编写:处理器从磁盘读取并写入磁盘的 FlowFile 内容的总大小。这提供了有关此处理器所需的 I/O 性能的宝贵信息。有些处理器可能只读取数据而不写任何东西,而有些处理器不会读取数据,而只会编写数据。其他人既不会读取也不会写数据,有些处理器将同时读取和写取数据。在此示例中,我们看到在过去五分钟内,此处理器已读取了 4.88 MB 的 FlowFile 内容,并编写了 4.88 MB。这就是我们所期待的,因为此处理器只需将 FlowFile 的内容复制到磁盘中即可。但是,请注意,这与从输入队列中提取的数据量不同。这是因为它从输入队列中提取的一些文件已经存在于输出目录中,并且处理器被配置为在发生此情况时将 FlowFiles 路由为失败。因此,对于输出目录中已经存在的文件,数据既未读取,也不写入磁盘。
- 出:处理器已传输到其出站连接的数据量。这不包括处理器自行删除的流文件,或路由到自动终止的连接的流文件。与上面的"In"指标一样,此值表示为<计数>(<大小>),其中<计数>已转移到出站连接的流量文件数量,<大小>是这些流文件内容的总大小。在此示例中,所有关系都配置为自动终止,因此没有流文件报告为已移出。
- 任务/时间:此处理器在过去 5 分钟内被触发运行的次数,以及执行这些任务所花费的时间。时间的格式是<小时>:<分钟>:<秒>。请注意,所花费的时间可以超过五分钟,因为许多任务可以并行执行。例如,如果处理器计划运行 60 个并发任务,并且每个任务需要一秒钟才能完成,则所有 60 项任务都有可能在一秒内完成。但是,在这种情况下,我们将看到时间指标显示它花了 60 秒,而不是 1 秒。这一次可以被认为是"系统时间",或者换句话说,这个值是60秒,因为如果只使用一个并发任务,那么执行操作需要花费多少时间。
过程组的解剖
流程组提供了一个将组件组合成逻辑结构的机制,以便以更高级别使其更容易理解的方式组织数据流。下图突出了构成过程组解剖学的不同元素:
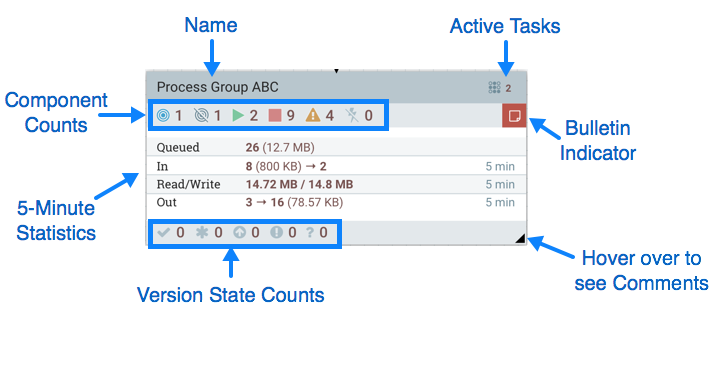
流程组由以下要素组成:
- 名称: 这是流程组的用户定义名称。当流程组添加到画布中时,此名称被设置为此名称。稍后可以通过右键单击流程组并单击"配置"菜单选项来更改名称。在此示例中,流程组的名称是"流程组 ABC"。
- 公告指示:当流程组的儿童组件发出公告时,该公告也会传播给该组件的父级流程组。当任何组件具有活动公告时,将显示此指示器,允许用户与鼠标一起在图标上悬停以查看公告。
- 活动任务:当前由此过程组中的组件执行的任务数。在这里,我们可以看到流程组目前正在执行两项任务。如果对 NiFi 实例进行聚类,此值将表示当前在组集中所有节点执行的任务数。
- 统计: 流程组提供有关流程组过去 5 分钟内处理的数据量以及流程组当前查询的数据量的统计数据。下列要素包括流程组的"统计"部分:
- 排队: 流程组中当前排出的流文件数量。此字段表示为 < 计数>(<大小>),其中<计数>是流程组当前选中流量文件的数量,<大小>是这些 FlowFiles 内容的总大小。在此示例中,流程组目前有 26 个流文件,总尺寸为 12.7 兆字节 (MB)。
- 在: 过去 5 分钟内通过其所有输入端口转入流程组的流量文件数量。该字段表示为 < 计数>/<大小>→ <>其中<计数>是过去 5 分钟内进入流程组的流文件数量,<大小>是这些流文件内容的总大小和<体育>是输入端口的数量。在此示例中,有 8 个 FlowFil 已进入流程组,总尺寸为 800 KB,并存在两个输入端口。
- 读/写:流程组中组件从磁盘读取并写入磁盘的 FlowFile 内容的总大小。这提供了有关此流程组所需的 I/O 性能的宝贵信息。在此示例中,我们看到在过去五分钟内,此过程组中的组件已读取了 14.72 MB 的 FlowFile 内容,并编写了 14.8 MB。
- 输出: 过去 5 分钟内通过输出端口从流程组转移出的流文件数量。该字段表示为<港口>→ <计数>(<大小>),其中<体育>输出端口数量、<计数>是过去 5 分钟内退出流程组的流文件数量,<大小>是这些流文件内容的总大小。在此示例中,有三个输出端口,16 个流文件已退出流程组,其总尺寸为 78.57 KB。
- 组件计数:组件计数元件提供有关流程组中存在多少种类型的信息。下面提供了有关这些图标及其含义的信息:
-
 传输端口:当前配置为将数据传输到 NiFi 的远程实例或从 NiFi 的远程实例中拉取数据的远程处理组端口数量。
传输端口:当前配置为将数据传输到 NiFi 的远程实例或从 NiFi 的远程实例中拉取数据的远程处理组端口数量。 -
 非传输端口:目前连接到此处理组内组件但目前已禁用其传输的远程处理组端口数量。
非传输端口:目前连接到此处理组内组件但目前已禁用其传输的远程处理组端口数量。 -
运行组件:当前在此进程组中运行的处理器、输入端口和输出端口的数量。
-
已停止组件:处理器、输入端口和输出端口的数量,这些端口目前尚未运行,但有效且已启用。这些组件已准备就绪。
-
无效组件:已启用但目前未处于有效状态的处理器、输入端口和输出端口的数量。这可能是由于配置错误的属性或缺少关系。
-
禁用组件:当前禁用的处理器、输入端口和输出端口的数量。这些组件可能有效,也可能无效。如果开始进程组,这些组件不会导致任何错误,但不会启动。
-
- 版本状态计数:版本状态计数元素提供了有关流程组中有多少个版本的进程组的信息。有关更多信息,请参阅版本状态。
- 注释:当流程组添加到画布中时,用户可以选择指定注释,以便提供有关流程组的信息。稍后,可以通过右键单击流程组并单击"配置"菜单选项来更改注释。
远程过程组的解剖
在创建数据流时,通常需要将数据从 NiFi 的一个实例传输到另一个实例。在这种情况下,NiFi 的远程实例可以视为一个过程组。因此,NiFi 提供了远程处理组的概念。从用户界面来看,远程流程组看起来与流程组类似。但是,有关远程进程组的内部工作和状态(如队列大小)的信息,则与 NiFi 实例与远程实例之间的交互有关。

上图显示了组成远程进程组的不同元素。在这里,我们提供有关所提供信息的图标和详细信息的解释。
- 传输状态:传输状态指示当前启用了 NiFi 和遥控实例之间的数据传输。显示的图标将是支持传输的图标 (
) 如果任何输入端口或输出端口当前配置为传输或传输禁用图标 (
)如果当前连接的所有输入端口和输出端口都已停止。
- 远程实例名称:这是遥控实例报告的 NiFi 实例的名称。首次创建远程进程组时,在获取此信息之前,将在此处显示远程实例的 URL。。。
- 远程实例网址:这是远程进程组指向的远程实例的 URL。当远程进程组添加到画布中并且无法更改时,此 URL 会输入。
- 安全指示器:此图标表示与远程 NiFi 实例的通信是否安全。如果与远程实例的通信是安全的,这将由"锁定"图标表示 (
 ).如果通信不安全,这将由"解锁"图标表示 (
).如果通信不安全,这将由"解锁"图标表示 (
 ).如果通信是安全的,NiFi 的此实例将无法与远程实例通信,直到远程实例管理员授予访问权限。每当将远程处理组添加到画布中时,这将自动启动请求,以便用户在远程实例上创建此次序 NiFi。在远程实例上的管理员将用户添加到系统并将"NiFi"角色添加到用户之前,此实例将无法与远程实例进行通信。如果通信不安全,远程处理组能够接收来自任何人的数据,并且数据在 NiFi 实例之间传输时未加密。
).如果通信是安全的,NiFi 的此实例将无法与远程实例通信,直到远程实例管理员授予访问权限。每当将远程处理组添加到画布中时,这将自动启动请求,以便用户在远程实例上创建此次序 NiFi。在远程实例上的管理员将用户添加到系统并将"NiFi"角色添加到用户之前,此实例将无法与远程实例进行通信。如果通信不安全,远程处理组能够接收来自任何人的数据,并且数据在 NiFi 实例之间传输时未加密。 - 5 分钟统计: 远程处理组显示两个统计数据:发送和接收。这两种格式均为<计数>(<大小>),其中<计数>是前五分钟内发送或接收的 FlowFiles 数量,<大小>是这些 FlowFiles 内容的总大小。
- 最后刷新时间:从远程实例中提取并在用户界面中的远程处理组上呈现的信息会定期在后台刷新。此元素表示上次刷新的时间,或者如果信息在相当长的时间内未刷新,则值将更改以指示远程流量不当前。可以通过右键单击远程进程组并选择"刷新远程"菜单项触发 NiFi 来启动此信息的更新。
队列交互
在必要时可以查看连接中所列的流文件。队列列表通过连接的上下文菜单打开。列表将根据配置的优先级返回活动队列中的前 100 个 FlowFile。即使源和目的地正在积极运行,也可以执行列表。List queue
此外,可以通过单击"详细信息"按钮() 查看列表中 Flowfile 的详细信息 (
 )在左边大多数列。从这里,FlowFile 详细信息和属性以及用于下载或查看内容的按钮都可用。只有在已配置内容时,才能查看内容。如果连接的源或目的地正在积极运行,则所需的 FlowFile 有可能不再处于活动队列中。
)在左边大多数列。从这里,FlowFile 详细信息和属性以及用于下载或查看内容的按钮都可用。只有在已配置内容时,才能查看内容。如果连接的源或目的地正在积极运行,则所需的 FlowFile 有可能不再处于活动队列中。nifi.content.viewer.url
在连接中查询的流文件也可以在必要时删除。流文件的删除通过连接的上下文菜单启动。如果源和目的地正在积极运行,也可以执行此操作。Empty queue
如果启用了分析预测功能,则悬停在队列上也会显示关于队列何时可能遇到后压的预测统计数据,无论是由于对象计数还是内容大小满足当前阈值设置。只有当 NiFi 内部存储库中有足够的数据,并且其模型足够准确以广播预测时,才会提供预测。有关更多信息,请参阅系统管理员指南中的分析框架部分。
摘要页面
虽然 NiFi 画布有助于了解配置的数据流是如何布局的,但此视图在尝试识别系统状态时并不总是最佳的。为了帮助用户了解数据流在更高层次上的运行情况,NiFi 提供了一个摘要页面。此页面可在用户界面右上角的"全球菜单"中使用。有关此工具栏位置的更多信息,请参阅NiFi 用户界面部分。
摘要页面通过从全球菜单中选择摘要来打开。这将打开摘要表对话:
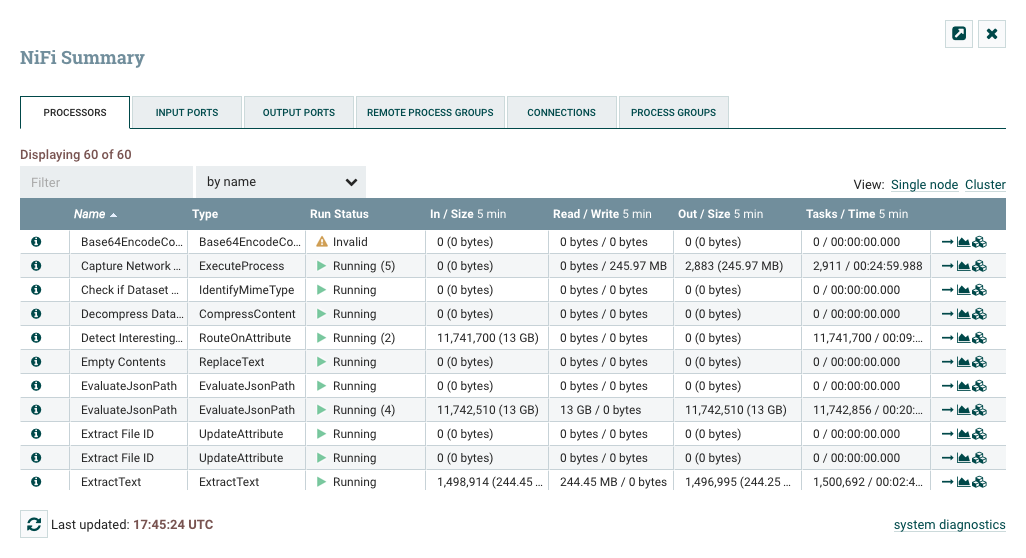
此对话提供了有关画布上每个组件的大量信息。下面,我们注释了对话中的不同元素,以便更容易地讨论对话。
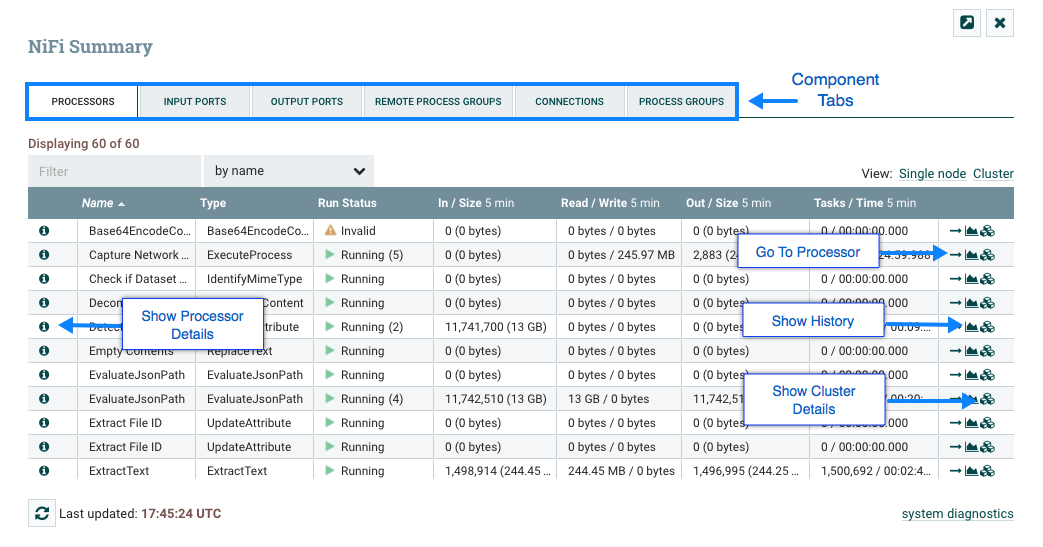
摘要页面主要由一张表格组成,该表提供有关画布上每个组件的信息。此表上方有一组五个选项卡,可用于查看不同类型的组件。表中提供的信息与画布上每个组件提供的信息相同。表中的每个列都可以通过单击列标题进行排序。有关所显示信息类型的更多信息,请参阅上面的处理器解剖部分、过程组解剖学和远程进程组解剖部分。
摘要页面还包括以下元素:
- 公告指示器:与整个用户界面的其他地方一样,当此图标存在时,悬停在图标上将提供有关生成的公告的信息,包括消息、严重程度、公告生成时间以及(在聚类环境中)生成公告的节点。与摘要表中的所有列一样,显示公告的列可以通过单击标题进行排序,以便当前所有现有公告显示在列表顶部。
- 详细信息: 单击"详细信息"图标将为用户提供组件的详细信息。此对话与用户右键单击组件并选择"查看配置"菜单项时提供的对话相同。
- 去: 点击这个按钮将关闭摘要页面,并直接把用户带到 NiFi 画布上的组件。这可能会更改用户当前所处于的流程组。如果"摘要"页面在新的浏览器选项卡或窗口中打开(单击下面描述的"弹出"按钮),则此图标不可用。
- 状态历史记录:单击状态历史图标将打开一个新的对话,显示为此组件呈现的统计数据的历史视图。有关更多信息,请参阅组件的历史统计部分。
- 刷新:“刷新"按钮允许用户刷新显示的信息,而无需关闭对话并再次打开对话。上次刷新信息的时间仅显示在"刷新"按钮的右侧。页面上的信息不会自动刷新。
- 过滤器: 过滤器元件允许用户通过键入某些标准(如处理器类型或处理器名称)的全部或部分来筛选摘要表的内容。可用的筛选器类型因所选选项卡而异。例如,如果查看处理器选项卡,用户可以按名称或类型进行筛选。查看"连接"选项卡时,用户能够按源、名称或目的地名称进行筛选。当文本框的内容被更改时,过滤器会自动应用。文本框下面是表中有多少条目与筛选器匹配的指示,以及表中有多少条目。
- 弹出式:在监控流量时,能够在单独的浏览器选项卡或窗口中打开"摘要"表是很有帮助的。“弹出"按钮(“关闭"按钮旁边)将导致在新的浏览器选项卡或窗口中打开整个"摘要对话”(取决于浏览器的配置)。一旦页面被"弹出”,对话就会在原始浏览器选项卡/窗口中关闭。在新的选项卡/窗口中,“弹出"按钮和"去"按钮将不再可用。
- 系统诊断:系统诊断窗口提供有关系统在系统资源利用方面如何运作的信息。虽然这主要针对管理员,但此视图中提供了它,因为它确实提供了系统的摘要。此对话显示信息,如 CPU 利用率、磁盘的饱满程度以及 Java 特定指标(如内存大小和利用率)以及垃圾收集信息。
组件的历史统计
虽然摘要表和画布显示过去五分钟内与组件性能相关的数字统计数据,但查看历史统计数据通常也很有用。此信息可通过右键单击组件和选择"状态历史记录"菜单选项或单击摘要页面中的状态历史记录(有关更多信息,请参阅摘要页面)获得。
存储的历史信息量可在 NiFi 属性中配置,但默认为 。对于特定配置信息,参考系统管理员指南的组件状态存储库。打开状态历史对话时,它提供了历史统计图:24 hours
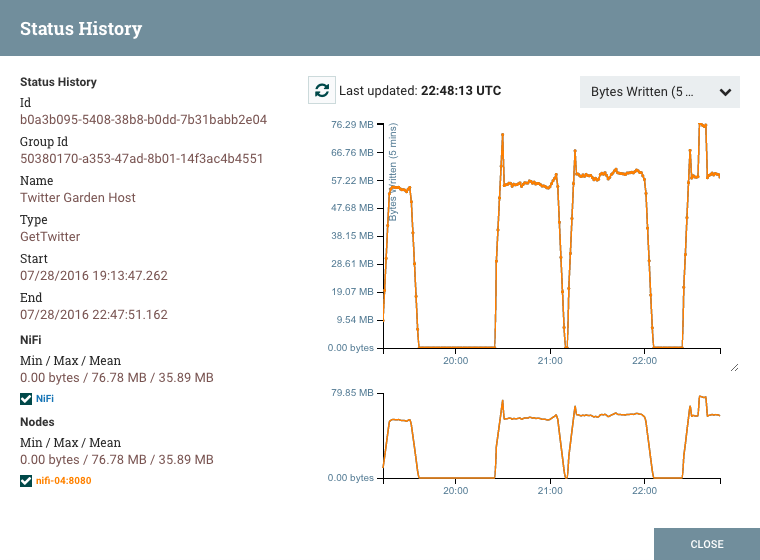
对话的左侧提供了有关统计数据所用组件的信息,以及所绘制的统计数据的文本表示。左侧提供以下信息:
- ID: 显示统计数据的组件的 ID。
- 组 ID: 组件所在流程组的 ID。
- 名称: 显示统计数据的组件名称。
- 组件特定条目:显示每个不同类型的组件的信息。例如,对于处理器,显示处理器的类型。对于连接,将显示源和目的地名称以及 ID。
- 开始:图表上显示的最早时间。
- 结束: 图表上显示的最新时间。
- 最小值/最大值/平均值:显示最小值、最大值和平均值(算术平均值或平均值)值。如果选择了任何时间范围,这些值仅基于所选时间范围。如果对 NiFi 的此实例进行聚类,则这些值将显示为聚类整体以及每个单个节点。在聚类环境中,每个节点都以不同的颜色显示。这也充当图形的图例,显示图形中显示的每个节点的颜色。将鼠标悬停在星团或图中的一个节点上,也会使相应的节点在图形中变得大胆。
对话的右侧提供了在下图中呈现的不同类型的指标的下拉列表。顶部图形较大,以便提供易于阅读的信息渲染。在此图表的右下角是一个小手柄 (
 )可以拖曳以调整图形大小。对话的空白区域也可以拖来拖去移动整个对话。
)可以拖曳以调整图形大小。对话的空白区域也可以拖来拖去移动整个对话。
底部图要短得多,并且能够选择时间范围。在此处选择时间范围将导致顶部图形仅显示所选时间范围,但会以更详细的方式显示。此外,这将导致重新计算左侧的 Min/Max/平均值。一旦通过在图形上拖动矩形创建选择,对选定部分的双击将导致选择在垂直方向上完全展开(即,它将在此时间范围内选择所有值)。无需拖动即可单击底部图将删除选择。
版本数据流
当 NiFi 连接到 NiFi 注册表时,数据流可以在流程组级别上进行版本控制。有关 NiFi 注册表使用和配置的更多信息,请参阅https://nifi.apache.org/docs/nifi-registry-docs/index.html文档。
连接到 NiFi 注册表
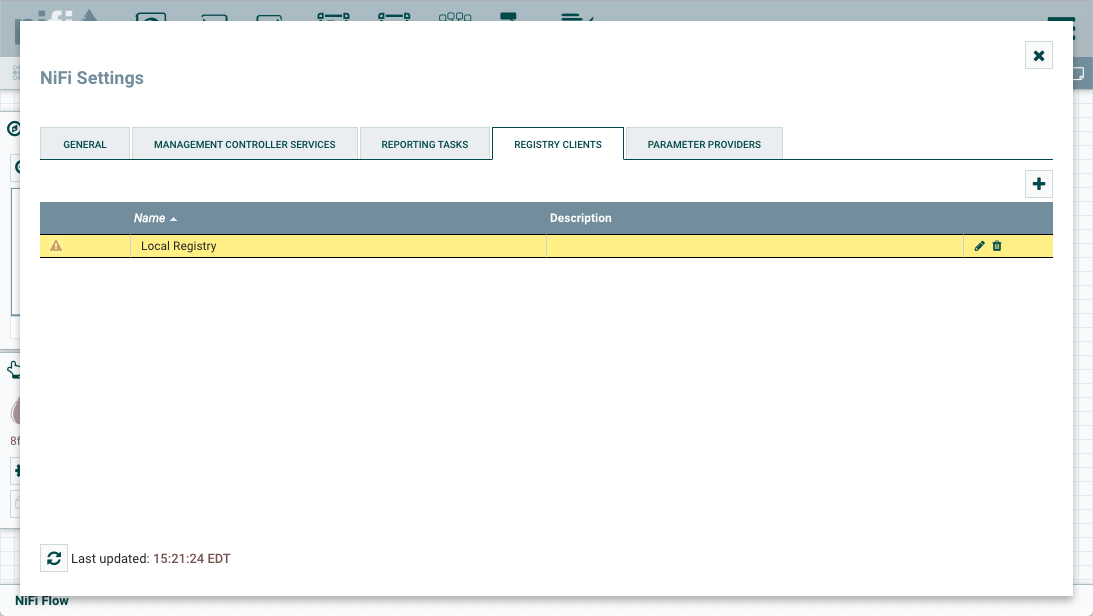
要将 NiFi 连接到注册表,请从全球菜单中选择控制器设置。
这显示了 NiFi 设置窗口。选择注册客户端选项卡,然后单击右上角的按钮注册新的注册客户端。+
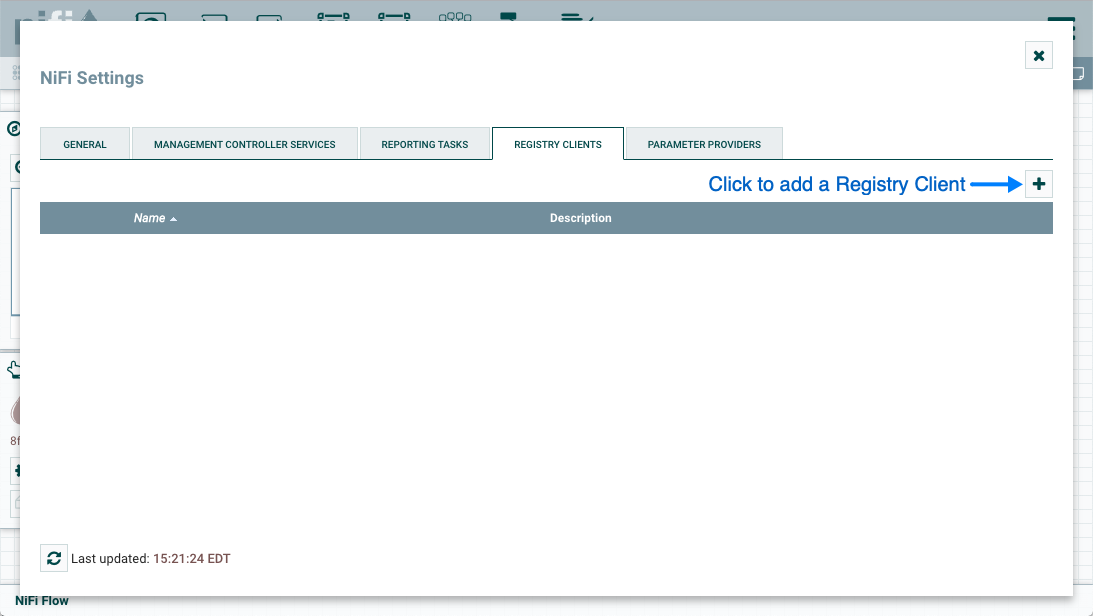
在添加注册表客户端窗口中,提供名称和 URL。
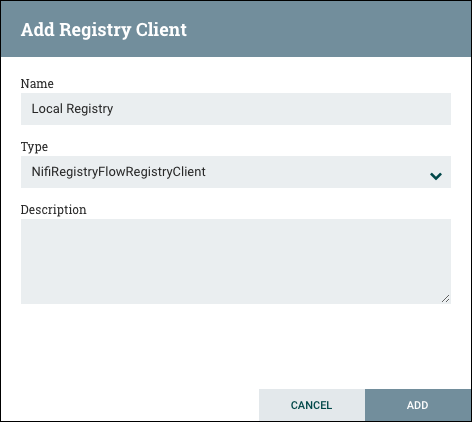
单击"添加"以完成注册。
| 版本流存储并组织在注册存储桶中。由注册管理员配置的存储桶策略和特权确定用户可以导入版本流的存储桶以及用户可以保存版本流到哪些存储桶。有关桶策略和特殊特权的信息可在 NiFi 注册用户指南(https://nifi.apache.org/docs/nifi-registry-docs/html/user-guide.html)中找到。 | |
|---|---|
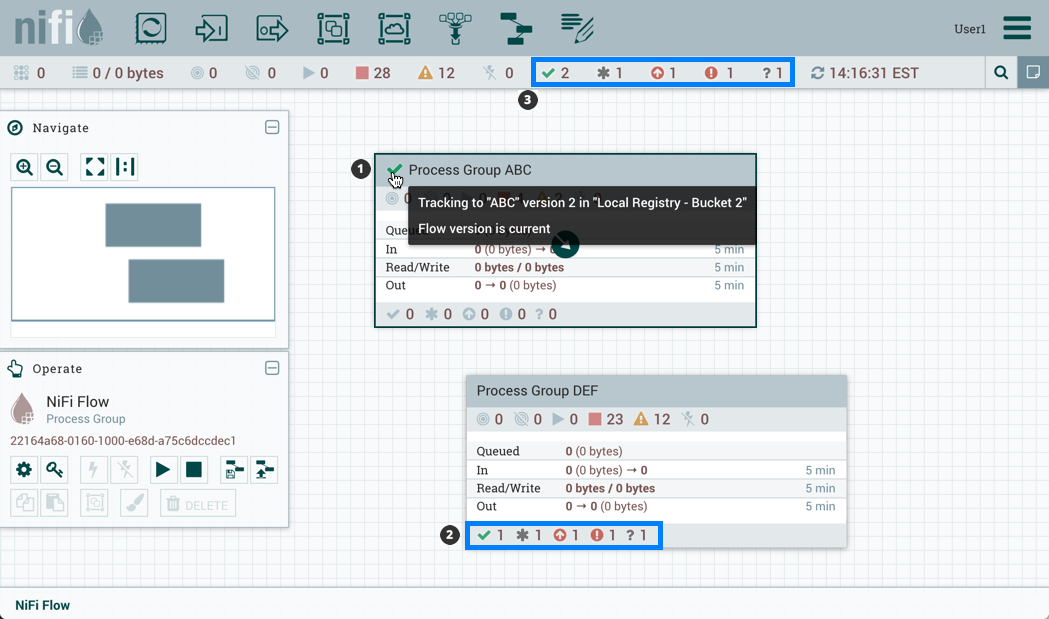
版本状态
版本过程组存在于以下状态中:
-
 最新: 流版本是最新的。
最新: 流版本是最新的。 -
 本地修改: 已进行本地更改。
本地修改: 已进行本地更改。 -
 过时:可提供较新的流量版本。
过时:可提供较新的流量版本。 -
 本地修改和陈旧:已进行本地更改,并提供了较新版本的流量。
本地修改和陈旧:已进行本地更改,并提供了较新版本的流量。 -
 同步故障:无法与注册表同步流量。
同步故障:无法与注册表同步流量。
显示版本状态信息:
- 在流程组名称旁边,用于版本化的流程组本身。悬停在状态图标上会显示有关版本流的其他信息。
- 在过程组的底部,用于流程组中包含的版本流。
- 在 UI 顶部的状态栏中,用于根过程组中包含的版本流。
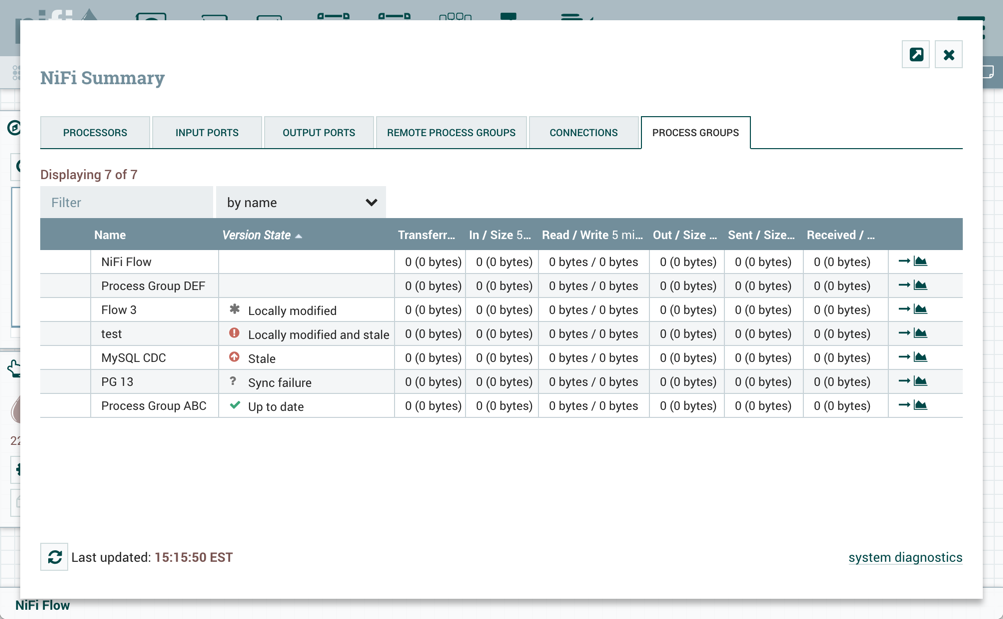
版本状态信息也显示在摘要页面的"过程组"选项卡中。
| 要查看最新版本状态,可能需要右键单击 NiFi 画布,并从上下文菜单中选择"刷新”。 | |
|---|---|
导入版本流
当 NiFi 实例连接到注册表时,将在添加过程组对话中显示"导入"链接。
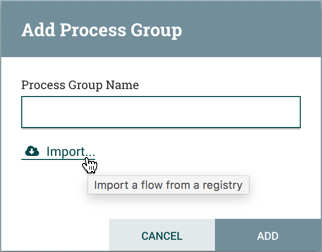
选择链接将打开导入版本对话。
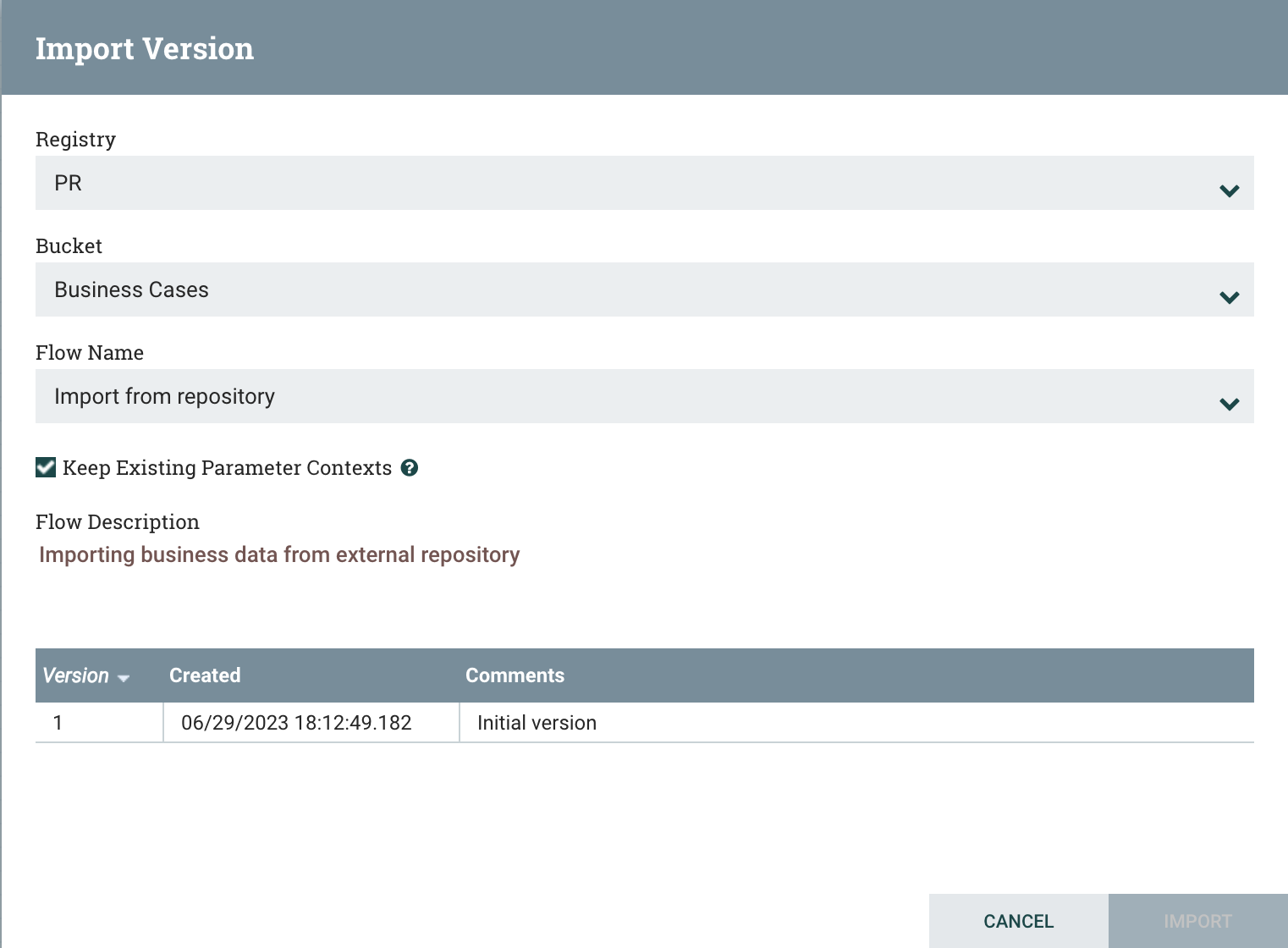
连接的注册表将作为选项显示在注册表下拉菜单中。对于所选注册表,用户有权访问的存储桶将作为选项显示在"桶"下拉菜单中。所选存储桶中的流的名称将作为选项显示在名称下拉菜单中。选择所需的流量版本进行导入,并选择"导入”,以便将数据流放置在画布上。
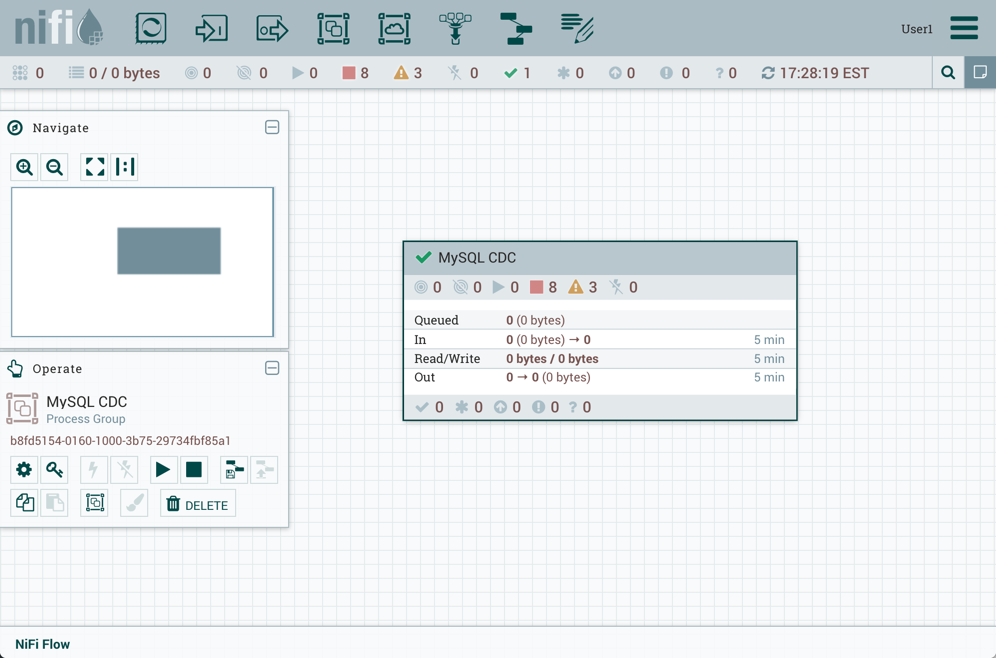
由于此示例中导入的版本是最新版本(MySQL CDC,第 3 版),因此版本过程组的状态为"最新" (
).如果导入的版本是旧版本,则状态将是"过时"的(
).
开始版本控制
要将进程组置于版本控制之下,请右键单击过程组和上下文菜单,选择"版本→启动版本控制"。
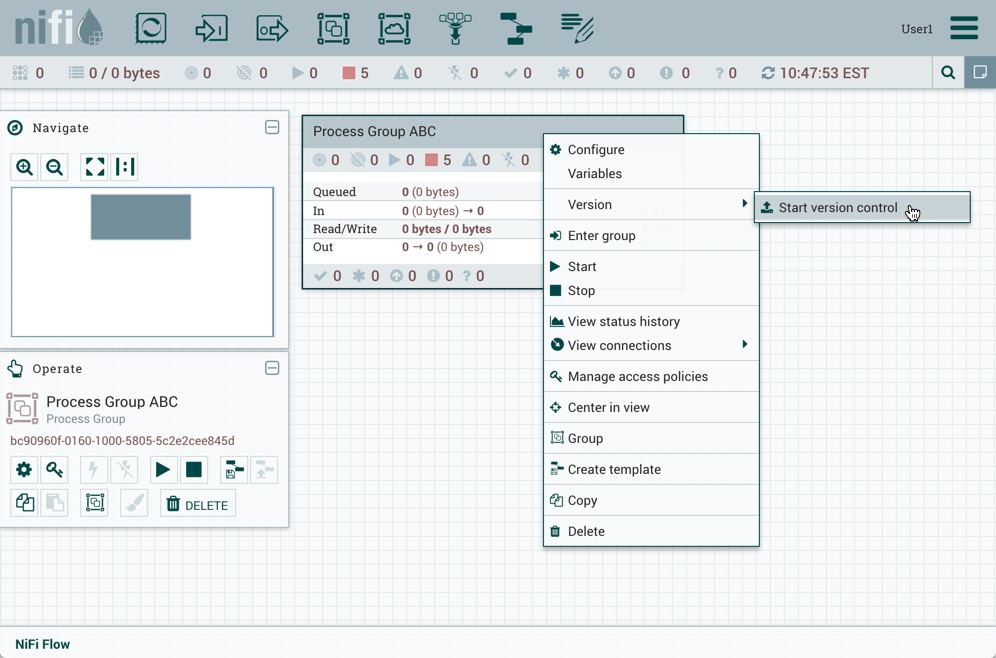
在"保存流"窗口中,选择"注册表"和"存储桶",然后输入"流"名称。如果需要,则添加说明和评论字段的内容。
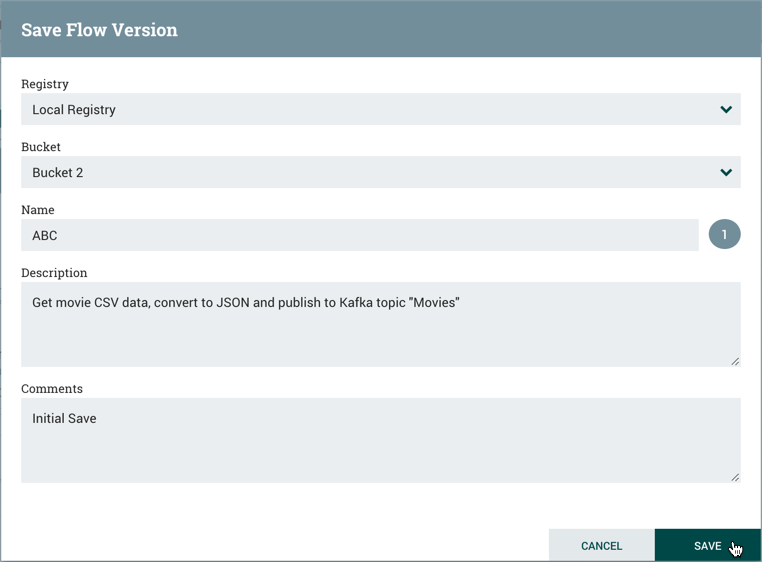
选择保存和保存流量的版本 1。
作为流程的第一个和最新版本,版本过程组的状态是"最新" (
).
| 根过程组不能置于版本控制之下。 | |
|---|---|
管理本地更改
当对版本化的流程组进行更改时,组件状态将更新为"本地修改" (
).DFM 可以显示、恢复或提交本地更改。当右键单击流程组时,这些选项可用于上下文菜单中的选择:
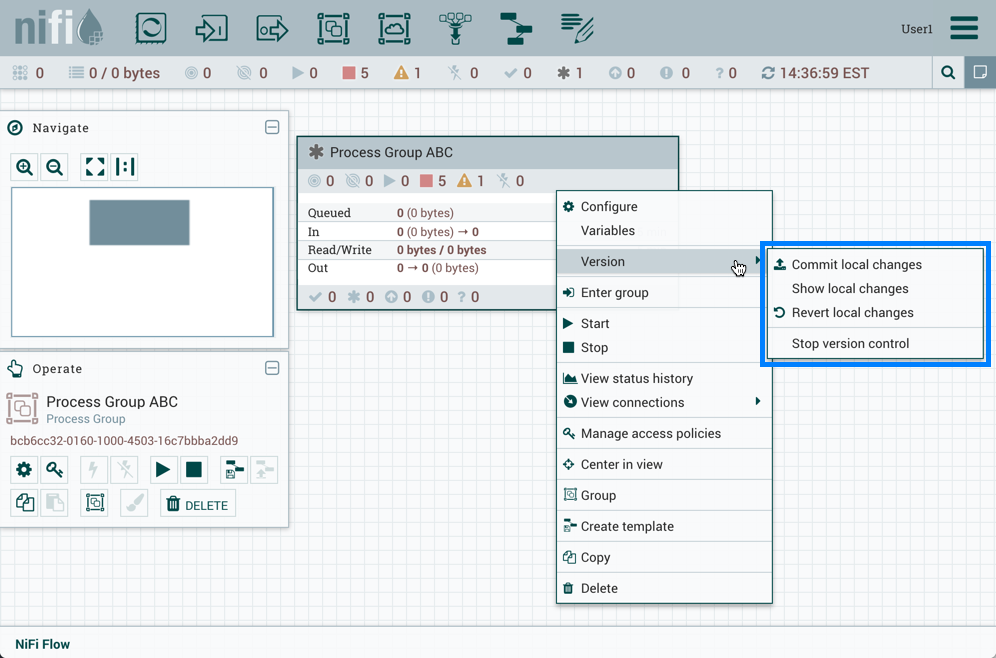
或在流程组内右键单击画布时:
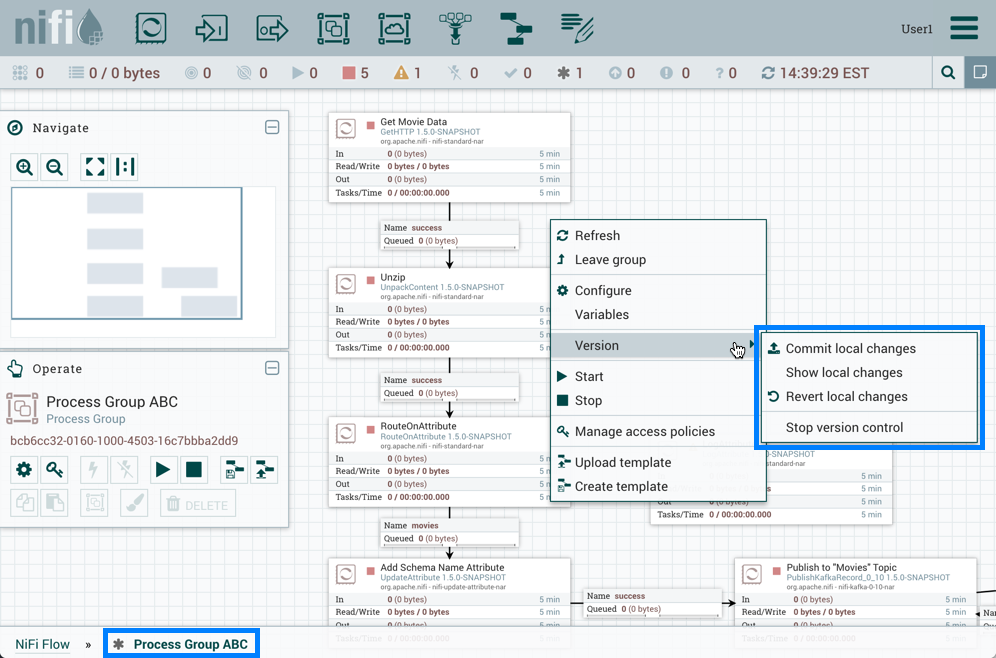
以下行动不被视为本地更改:
- 禁用/启用处理器和控制器服务
- 停止/启动处理器
- 修改敏感属性值
- 修改远程过程组 URL
- 更新引用不存在的控制器服务的处理器,以引用外部可用的控制器服务
- 分配、创建、修改或删除参数上下文
- 创建、修改或删除变量
| 分配或创建参数上下文不会触发本地更改,因为自行分配或创建参数上下文不会改变流程的任何事情。必须创建或修改一个组件,该组件在参数上下文中使用参数,这将触发本地更改。修改参数上下文不会触发局部更改,因为参数在每个环境中都不同。当导入版本流量时,假设需要一次性操作才能设置特定于给定环境的参数。删除参数上下文不会触发本地更改,因为需要修改该参数上下文中引用参数的任何组件,这将触发本地更改。 | |
|---|---|
| 创建变量不会触发本地更改,因为创建变量本身不会改变流过程。必须创建或修改使用新变量的组件,这将触发本地更改。修改变量不会触发本地更改,因为变量值在每个环境中都不同。当导入版本流量时,假设需要一次性操作才能设置特定于给定环境的变量。删除变量不会触发本地更改,因为需要修改引用该变量的组件,这将触发本地更改。 | |
|---|---|
| 变量不支持敏感值,将在对流程组进行版本化时包含。变量仍支持兼容性,但与参数(如敏感属性的支持)和对谁可以创建、修改或使用的更精细的控制等参数的功率不同。变量将在将来的版本中删除。因此,强烈建议切换到参数。 | |
|---|---|
显示本地更改
通过从上下文菜单中选择"版本→显示本地更改",可以在"显示本地更改"对话中查看对版本过程组的本地更改。
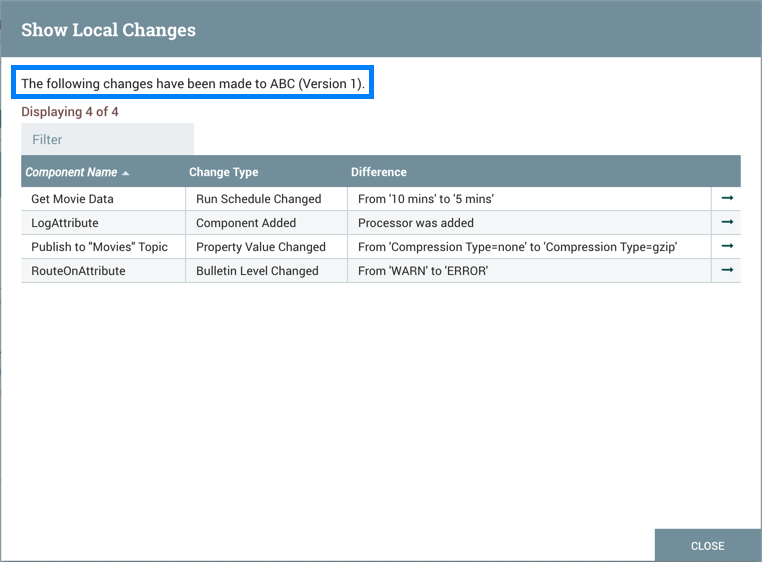
您可以通过选择"去"图标() 导航到组件 (
 )在其行。
)在其行。
| 如管理本地更改部分所述,有些例外行为是可审查的本地更改。此外,对同一属性的多个更改仅显示为列表中的一个更改,因为更改是通过分散流程组的当前状态和显示本地更改对话中注明的流程组的保存版本来确定的。 | |
|---|---|
恢复本地更改
通过从上下文菜单中选择"版本→拒绝本地更改"来恢复对版本过程组的本地更改。恢复本地更改对话显示 DFM 在启动恢复之前需要审查和考虑的本地更改列表。选择"还原"以删除所有更改。
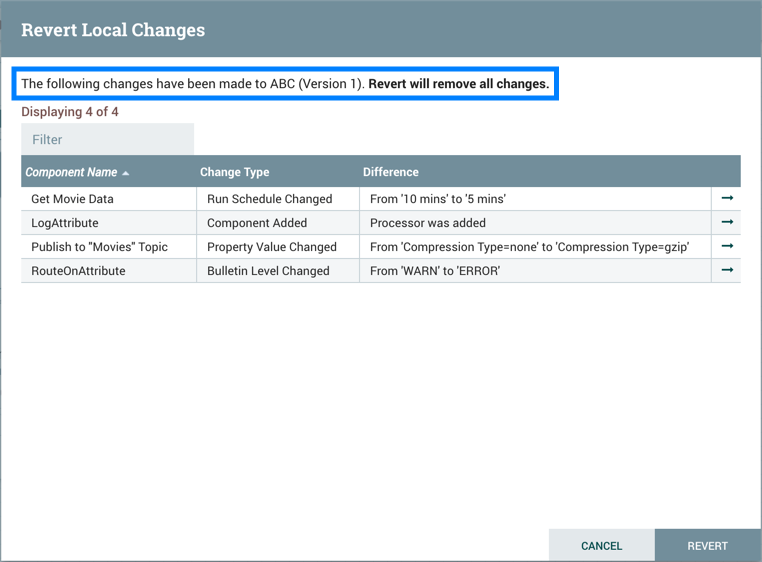
您可以通过选择"去"图标() 导航到组件 (
)在其行。
| 如管理本地更改部分所述,有例外情况是可恢复的本地更改。此外,对同一属性的多个更改仅显示为列表中的一个更改,因为更改是通过分散过程组的当前状态和在"恢复本地更改对话"中指出的流程组的保存版本来确定的。 | |
|---|---|
提交本地更改
要提交和保存流版本,请从上下文菜单中选择"版本→承诺本地更改"。在"保存流"版本对话中,如果需要,请添加注释并选择"保存"。
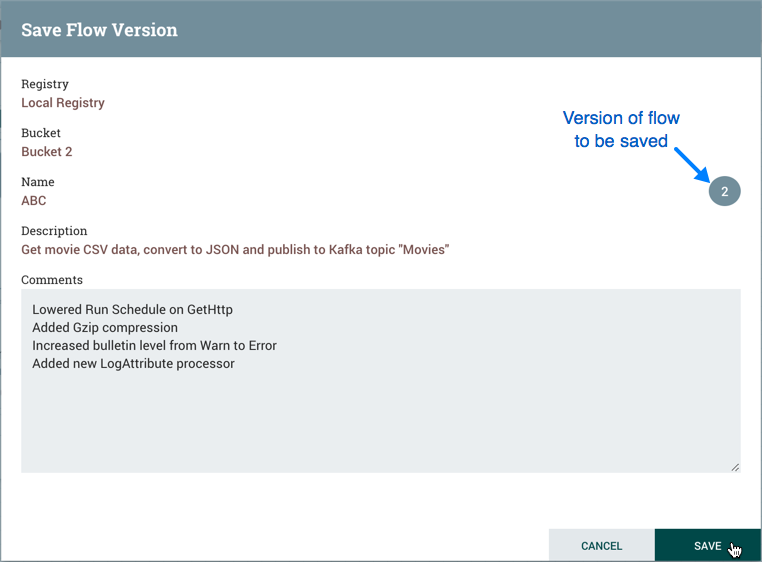
如果已修改的版本不是最新版本,则无法进行本地更改。在这种情况下,版本状态是"本地修改和过时" (
).
更改版本
要更改流的版本,请右键单击版本过程组并选择"版本→更改版本"。
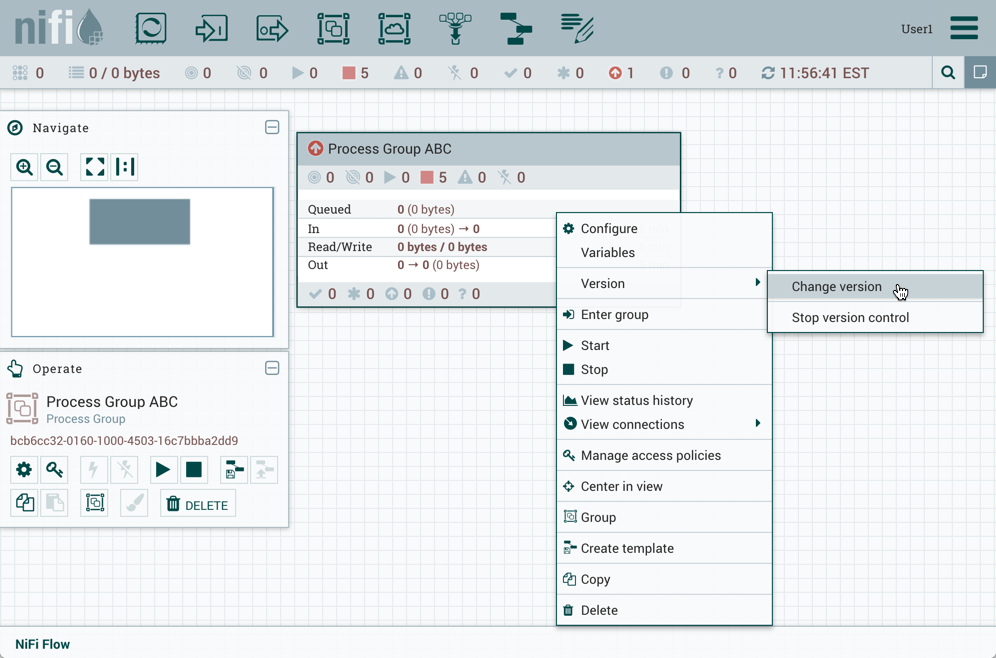
在更改版本对话中,选择所需的版本并选择"更改":
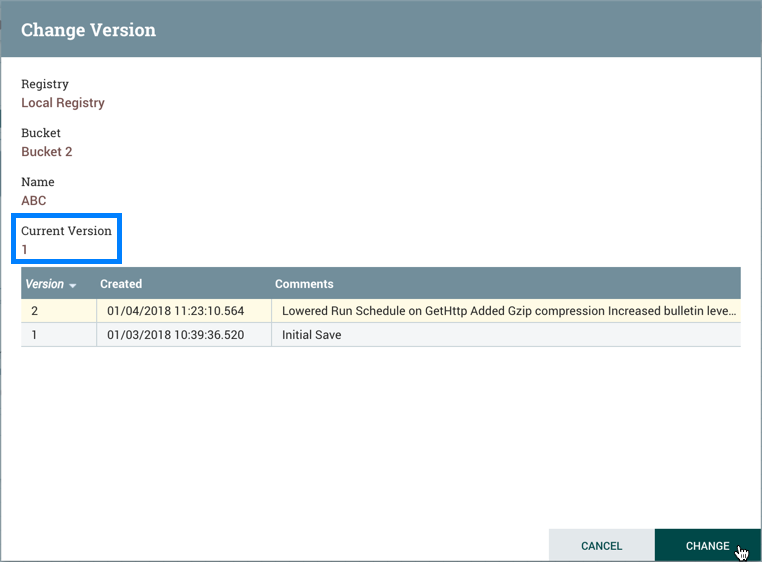
流量的版本已更改:
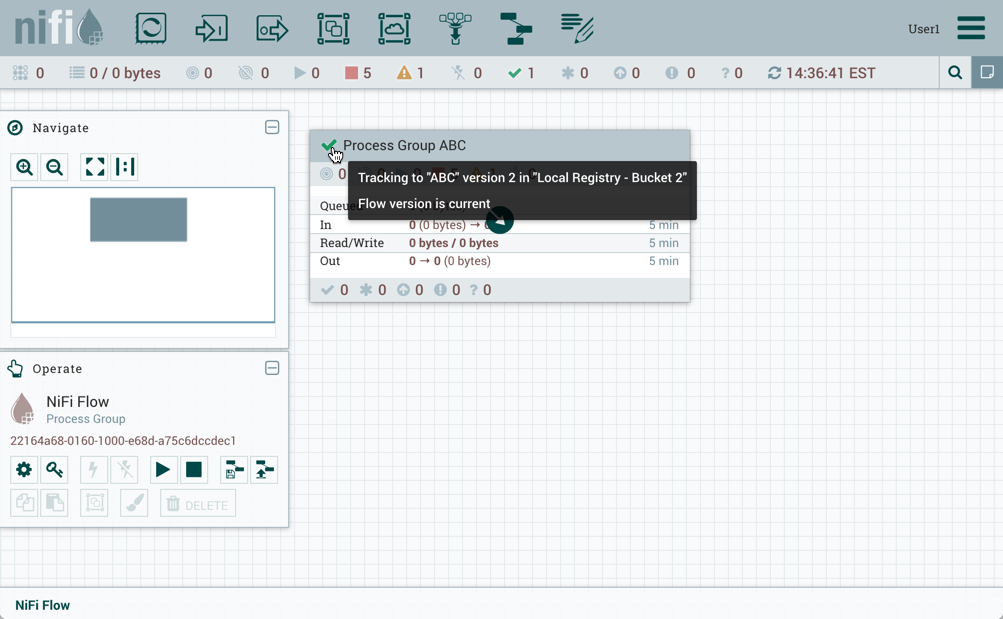
在所示示示中,版本流从旧版本升级为较新的最新版本。但是,版本流也可以回滚到旧版本。
| 要使"更改版本"成为可用的选择,需要恢复对流程组的本地更改。 | |
|---|---|
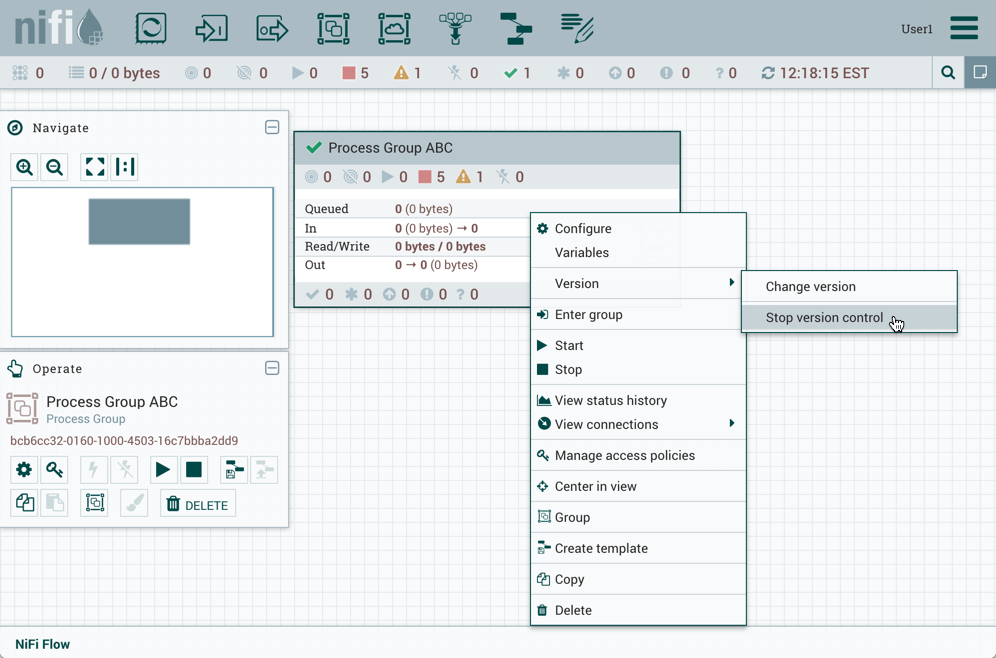
停止版本控制
要停止流中的版本控制,请右键单击版本过程组并选择"版本→停止版本控制":
在"停止版本控制"对话中,选择"断开"。
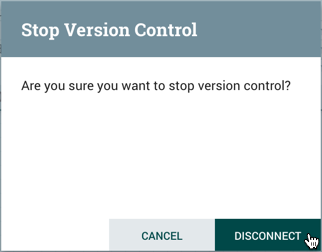
确认从版本控制中删除过程组。

嵌套版本流
版本化的进程组可以包含其他版本的过程组。但是,如果父级流程组包含也具有本地更改的儿童过程组,则无法恢复或保存父级过程组的本地更改。儿童过程组必须首先恢复或承诺更改这些操作,以便在父级流程组上执行这些操作。
已版本流中的参数
当向流注册处输出版本流时,为存储的每个进程组发送参数上下文的名称。参数(名称、描述、值、是否敏感)也随流量存储。但是,未存储敏感参数值。
导入版本流时,将为 NiFi 实例中不存在的每个流量创建参数上下文。当从流注册处导入版本流量时,如果 NiFi 具有同名参数上下文,则值会合并,如下示例所示:
流具有参数上下文"PC1",具有以下参数:
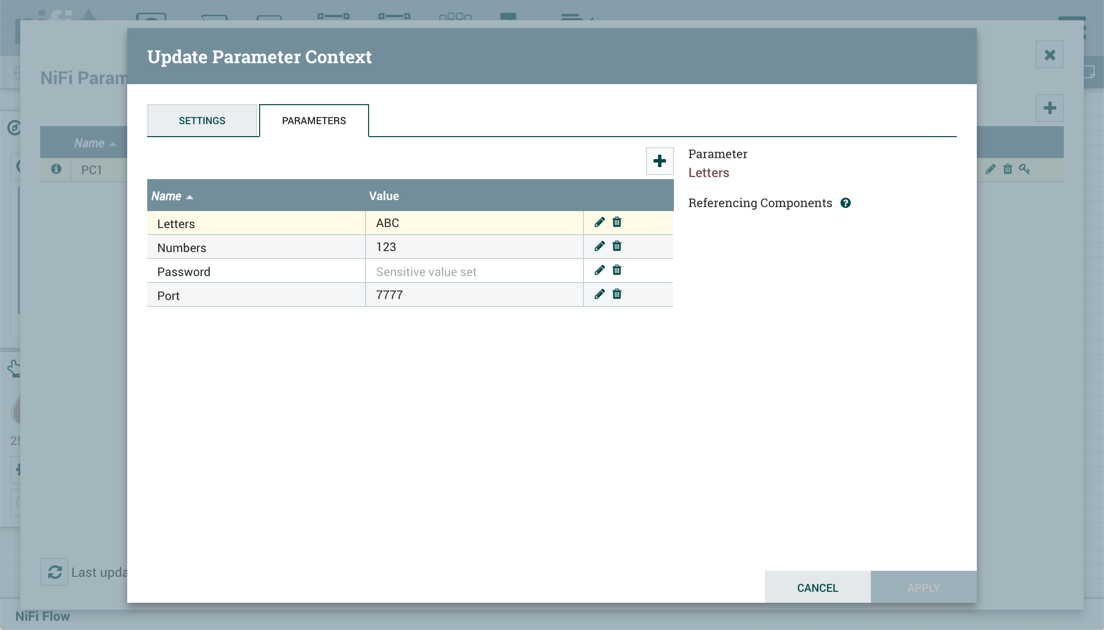
流量被导出并保存到流量注册处。
NiFi 实例具有参数上下文,也命名为"PC1",具有以下参数:
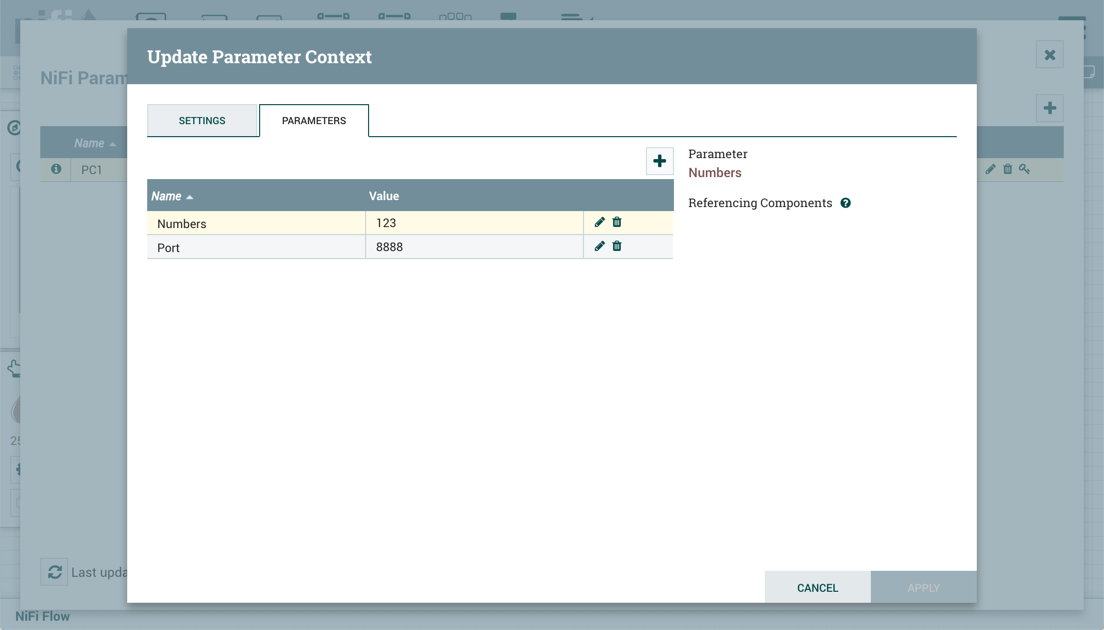
版本流导入到 NiFi 实例中。参数上下文"PC1"现在有以下参数:
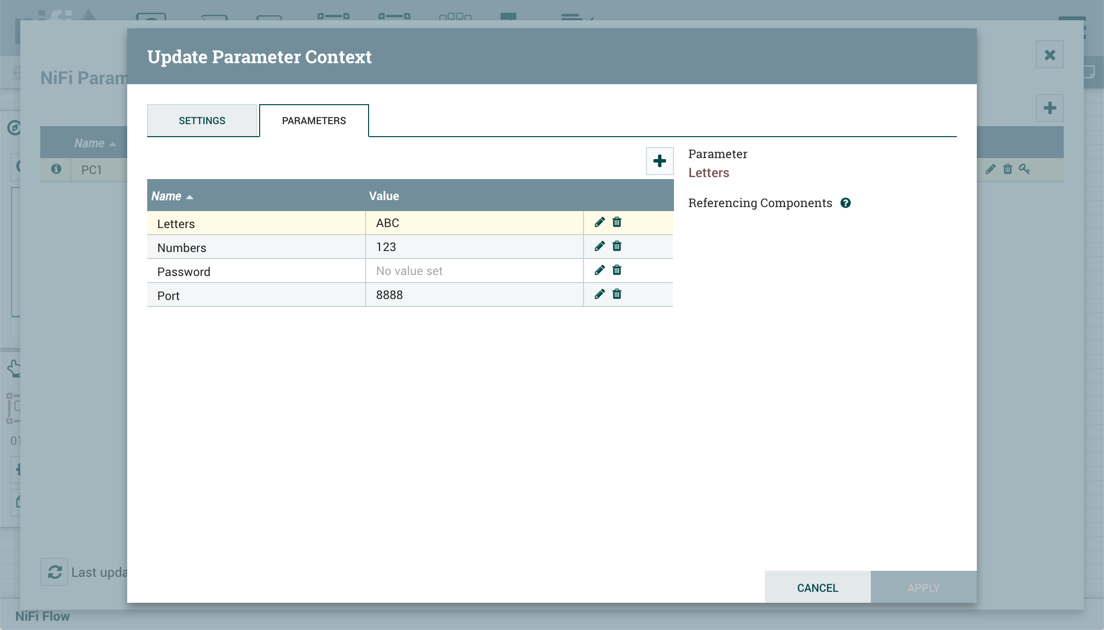
“字母"参数在 NiFi 实例中不存在,并且已添加。“数字"参数存在于具有相同值的版本流和 NiFi 实例中,因此未进行更改。“密码"是 NiFi 实例中缺少的敏感参数,因此它被添加但无价值。“端口"存在于 NiFi 实例中,其值与版本流不同,因此其值保持不变。
当流版本更改时,参数上下文的处理方式类似。考虑以下两个示例:
如果前面引用的版本流更改为其他版本(版本 2),并且版本 2 的参数上下文"PC1"具有"颜色"参数,“颜色"将添加到 NiFi 实例中的"PC1”。
流的 1 版本没有与之相关的参数上下文。新版本(版本 2)确实如此。当流量从版本 1 更改为版本 2 时,将发生以下情况之一:
- 如果尚未存在,则创建新的参数上下文
- 将现有的参数上下文(按名称)分配给过程组,并合并参数上下文的值
已版本流中的变量
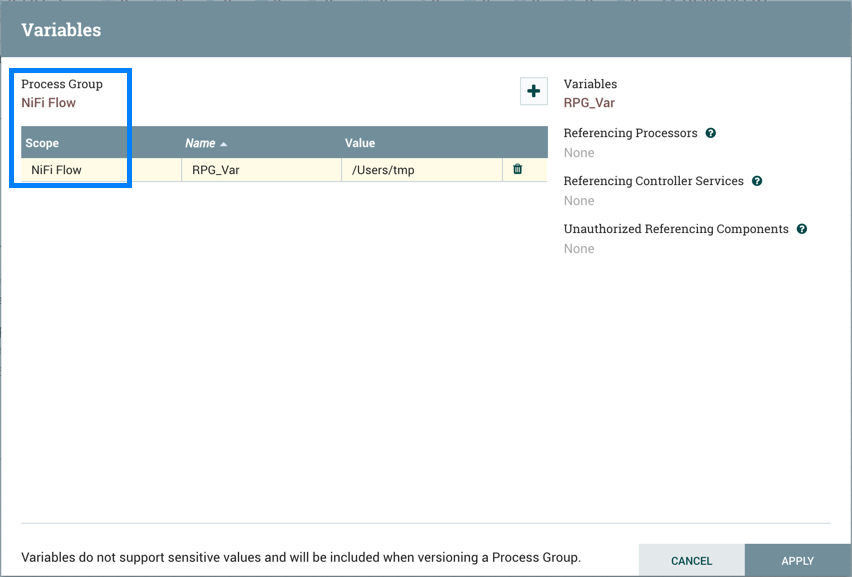
当将流程组置于版本控制之下时,将包含变量。如果导入了引用版本过程组中未定义的变量的版本流,则如果该变量存在,则保留该参考。如果未存在引用的变量,则将在过程组中定义变量的副本。为了说明,假设变量"RPG_Var"在根过程组中定义:
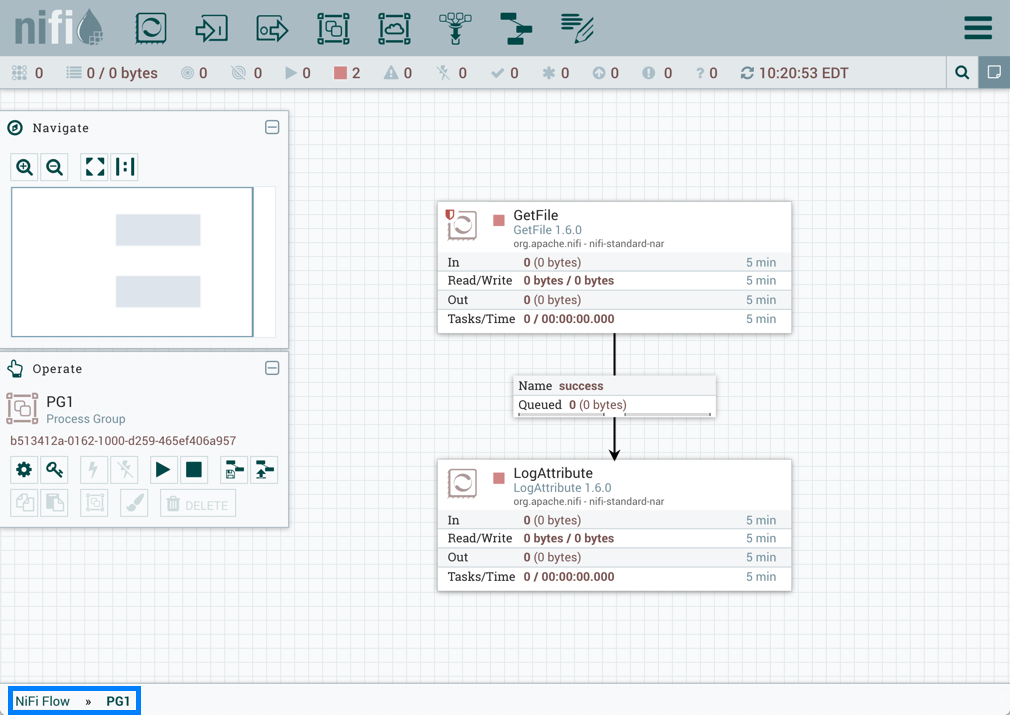
创建过程组 PG1:
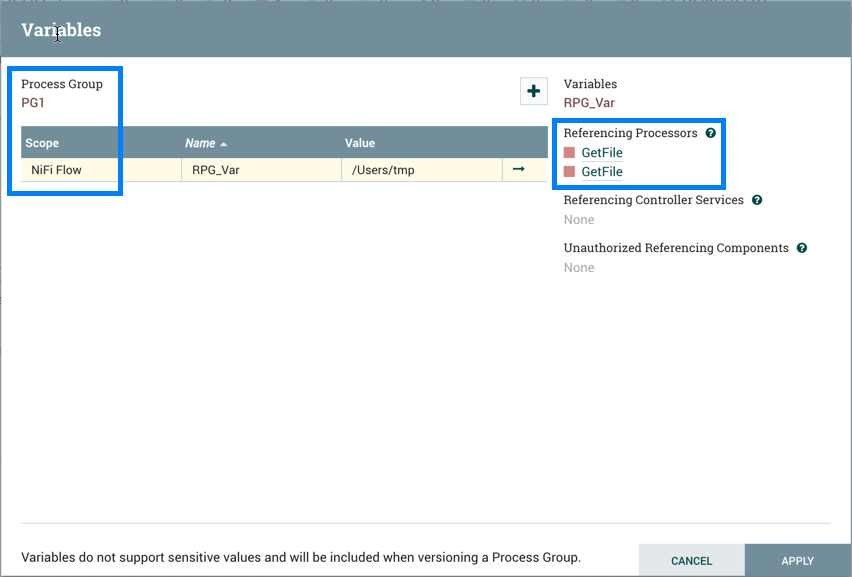
PG1 中的 GetFile 处理器引用了可变"RPG_Var”:
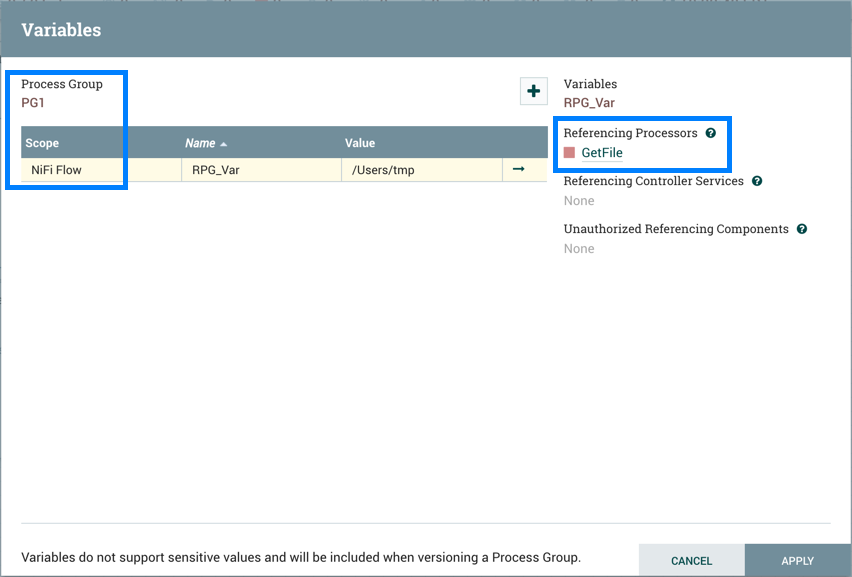
PG1 以版本流为保存:
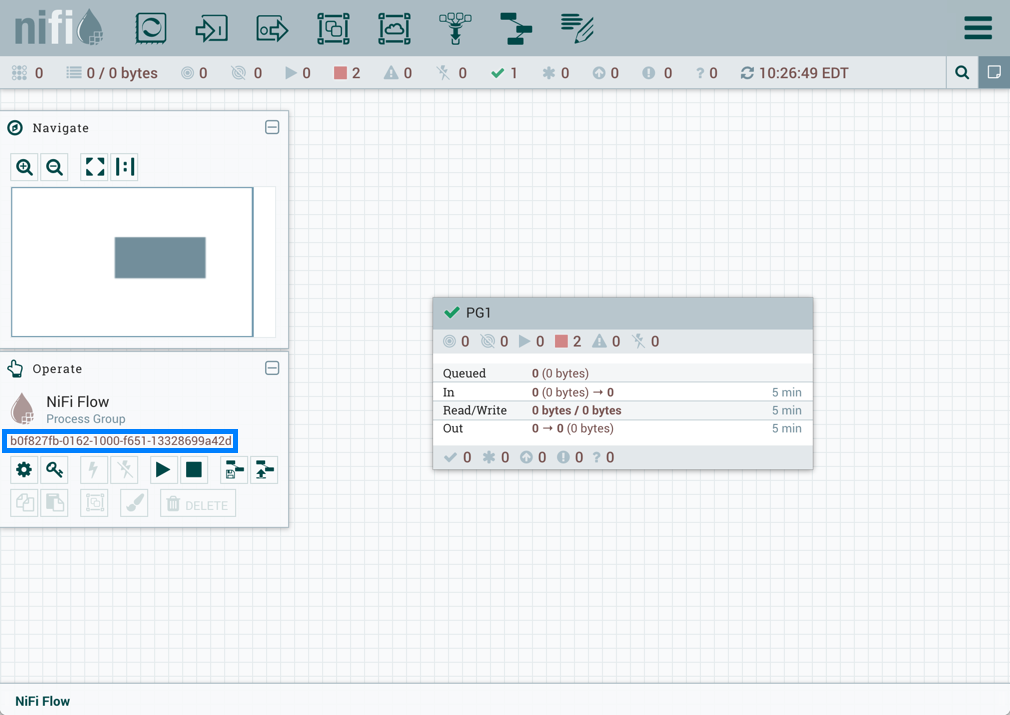
如果 PG1 版本的流量导入到此 NiFi 实例中:
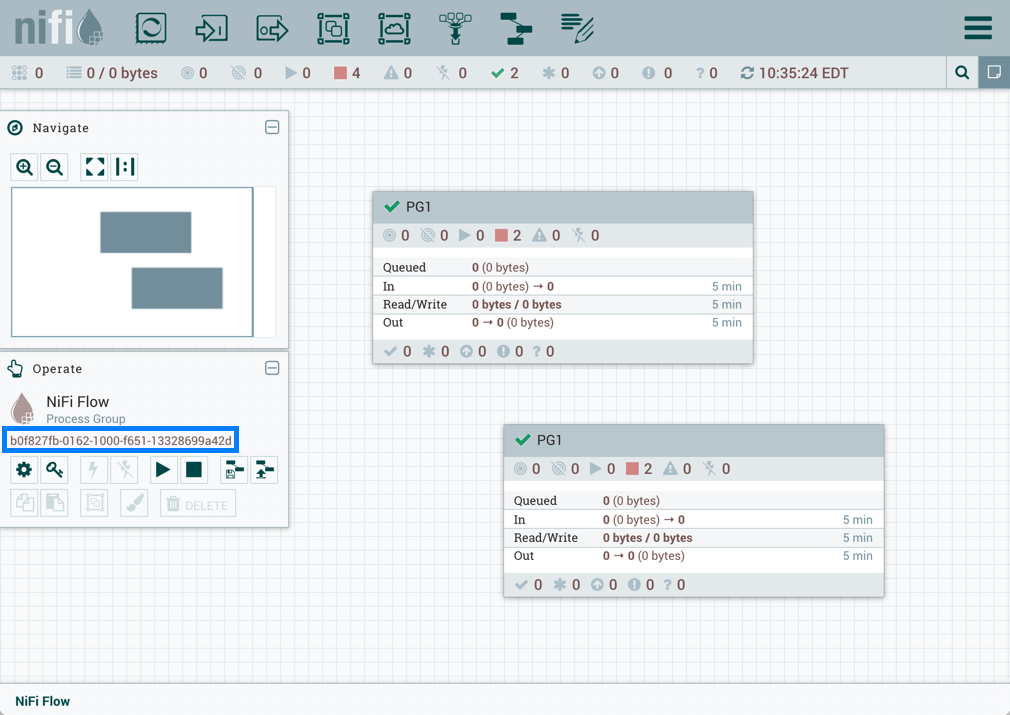
添加的 GetFile 处理器还将引用根过程组中存在的"RPG_Var"变量:
如果 PG1 版本的流量导入到不存在"RPG_Var"的 niFi 示例中:
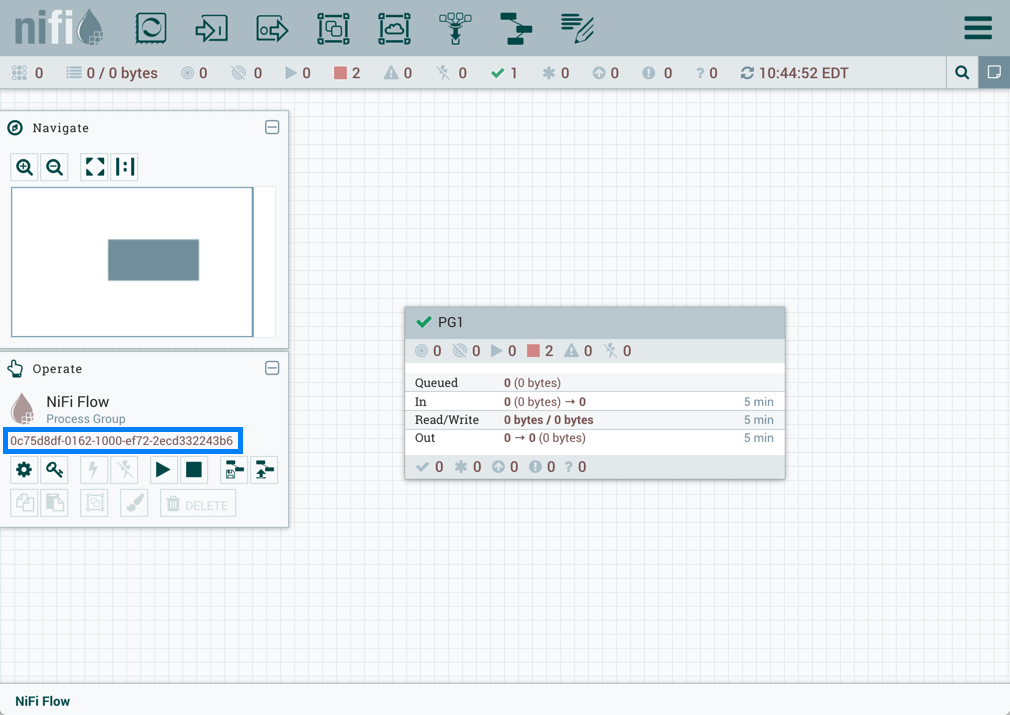
PG1 流程组中创建"RPG_Var"变量:
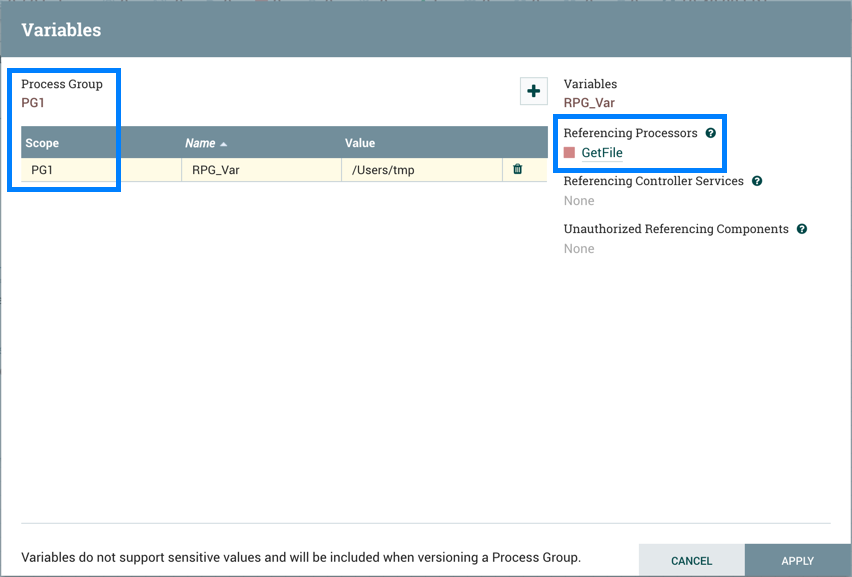
版本流中的受限组件
要导入版本流或在版本流中恢复本地更改,用户必须访问版本流中的所有组件。因此,建议在根过程组级别创建受限组,如果要在版本流中使用这些组件。让我们浏览一些示例来说明此配置的好处。假设如下:
-
有两个用户,“sys_admin"和"test_user"谁可以访问查看和修改根过程组。
-
“sys_admin"可以访问所有受限组件。
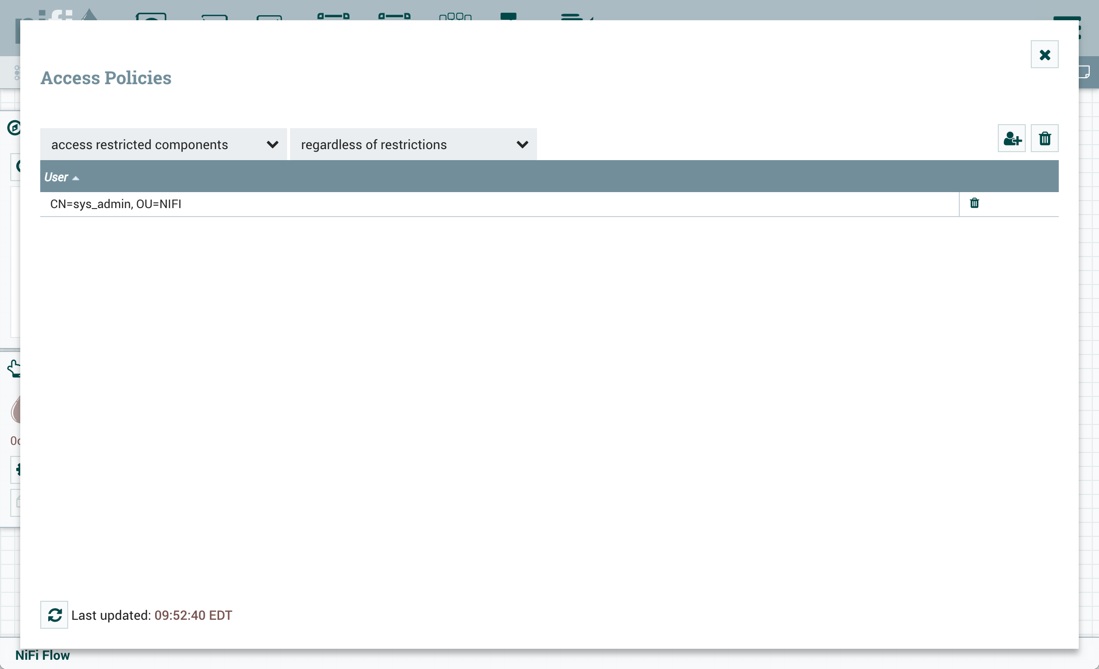
-
“test_user"可以访问需要"读取文件系统"和"编写文件系统"的限制组件。
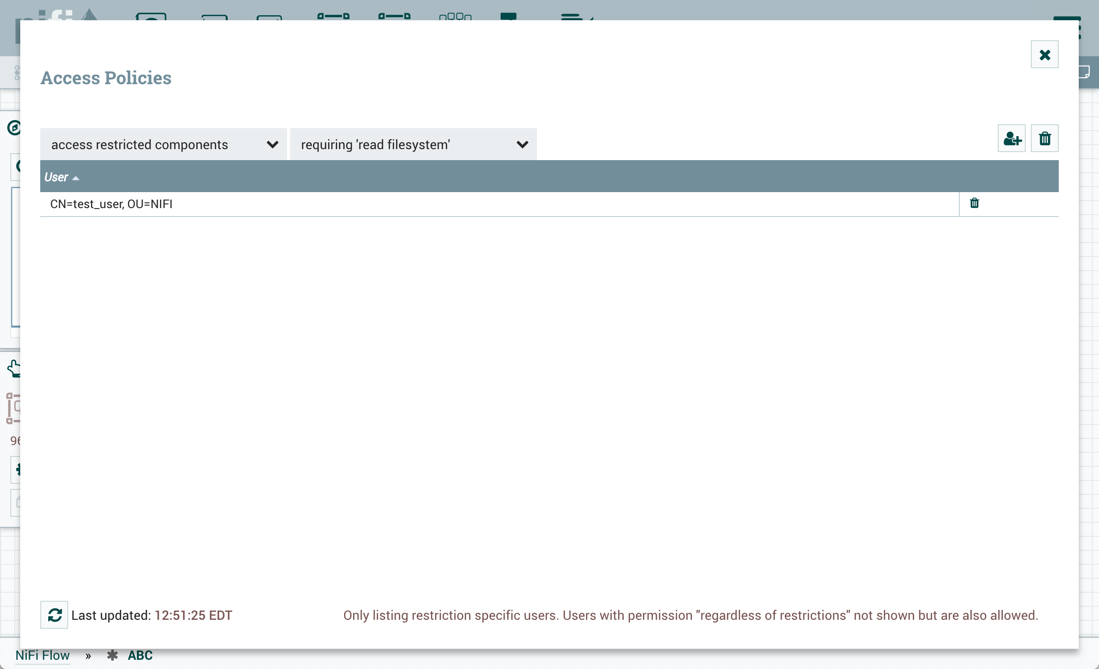
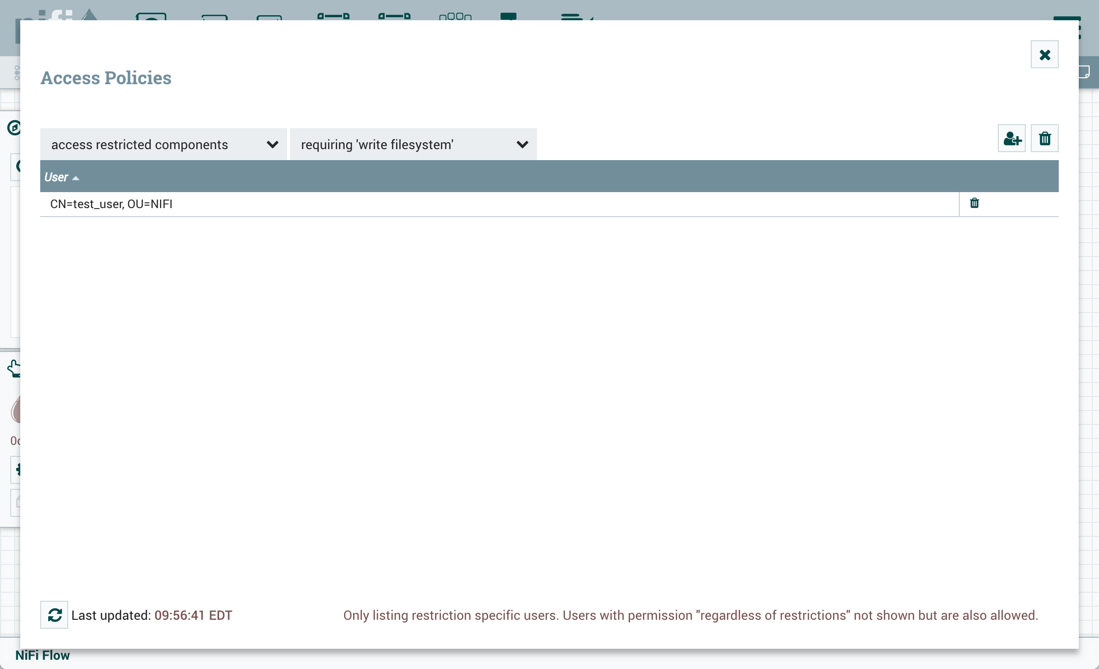
在根处理组中创建的限制控制器服务
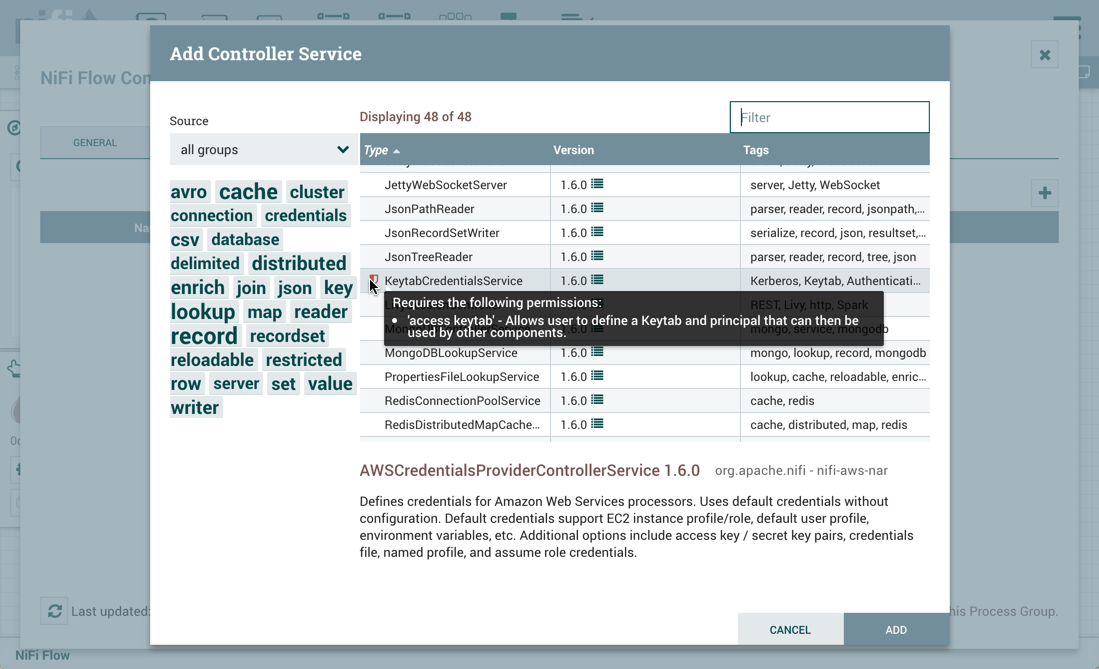
在第一个示例中,sys_admin在根过程组级别创建了基塔布创意服务控制器服务服务。
关键服务控制器服务是一个受限组件,需要"访问密钥塔"权限:
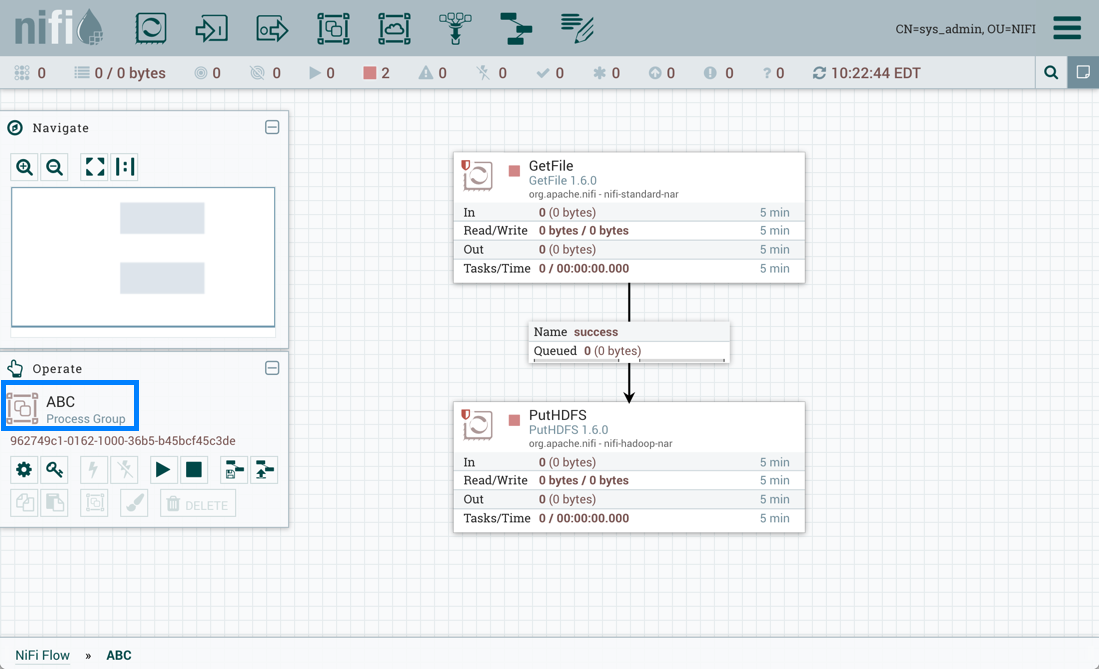
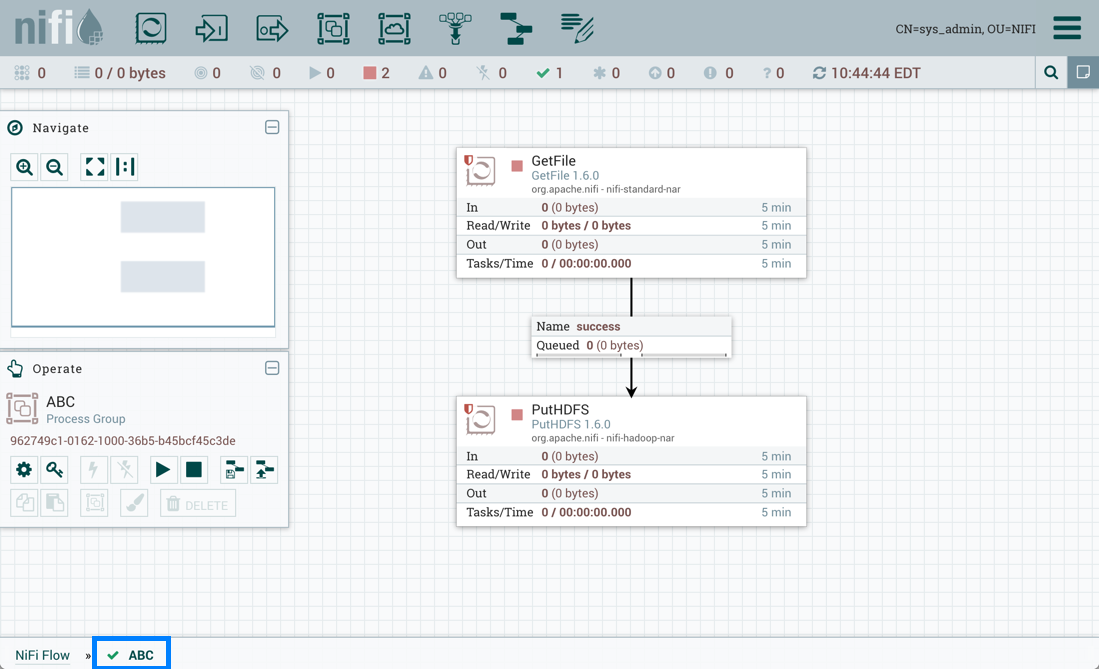
Sys_admin创建一个包含 GetFile 和 PutHDFS 处理器的流程组 ABC:
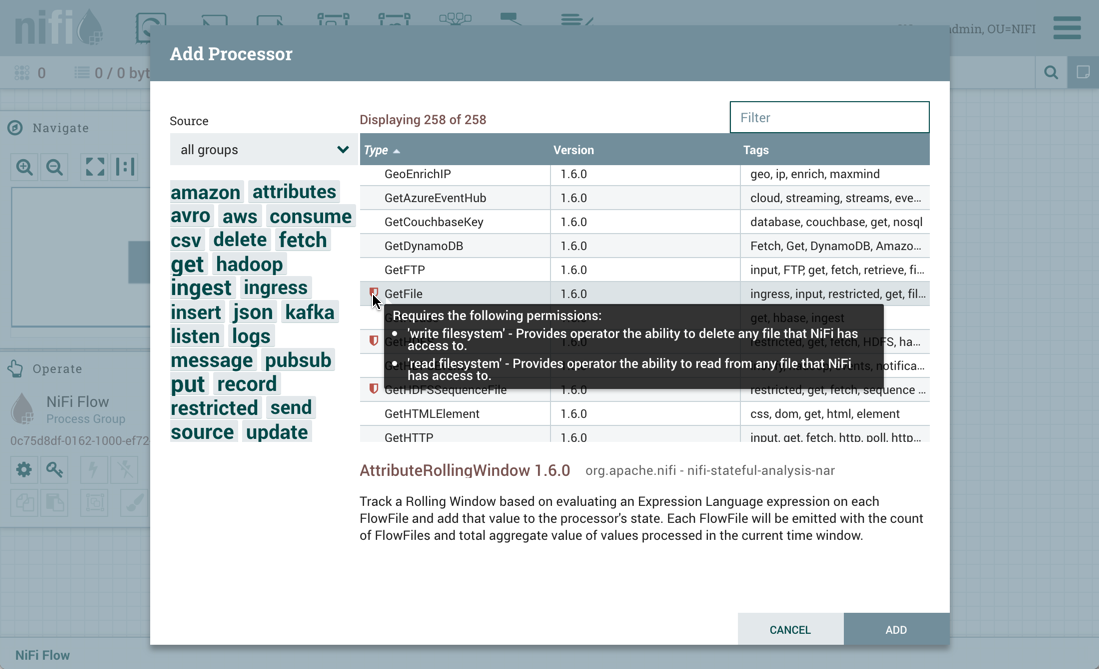
GetFile 处理器是一个受限组件,需要"编写文件系统"和"读取文件系统"权限:
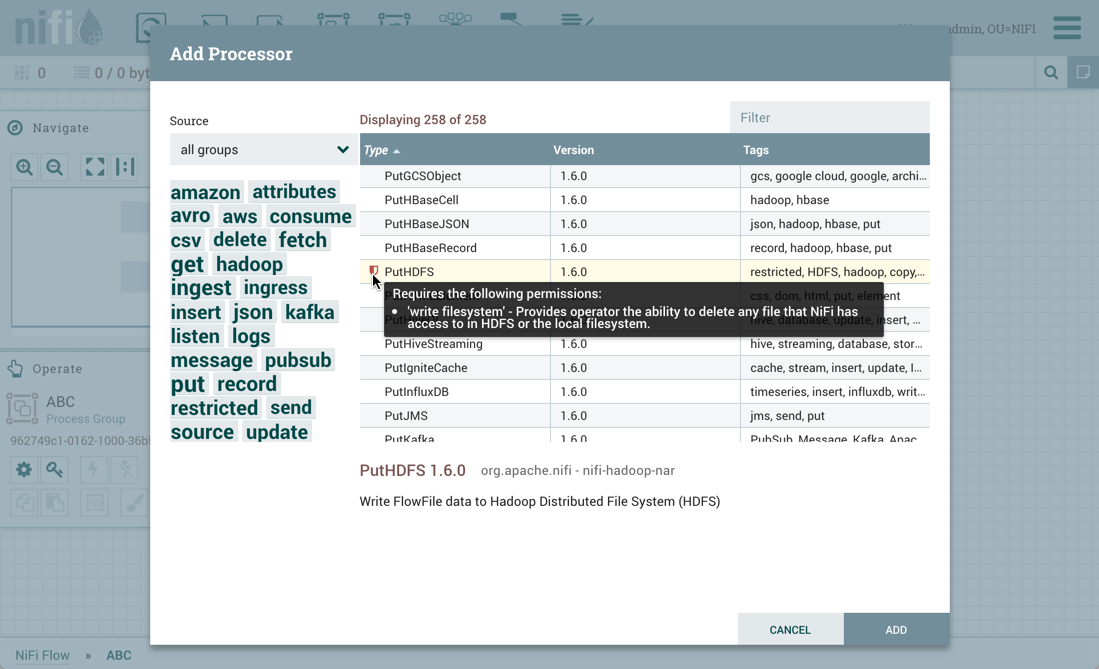
PutHDFS 是一个受限组件,需要"编写文件系统"权限:
PutHDFS 处理器配置为使用根过程组级别的基塔布克雷特服务控制器服务服务:
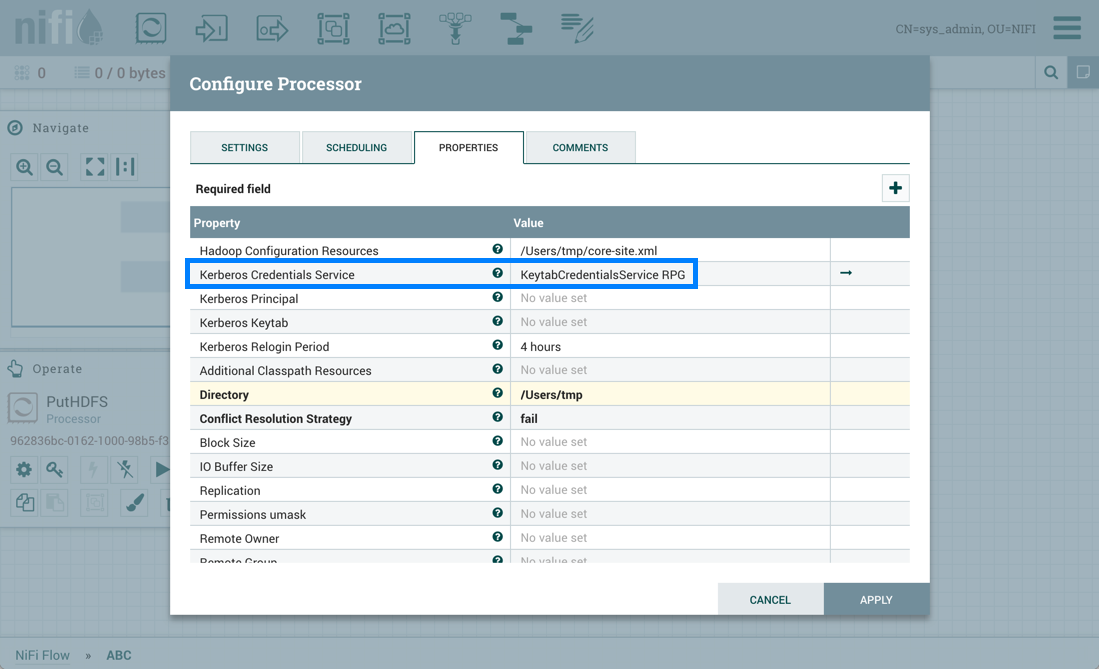
Sys_admin 将流程组保存为版本流:
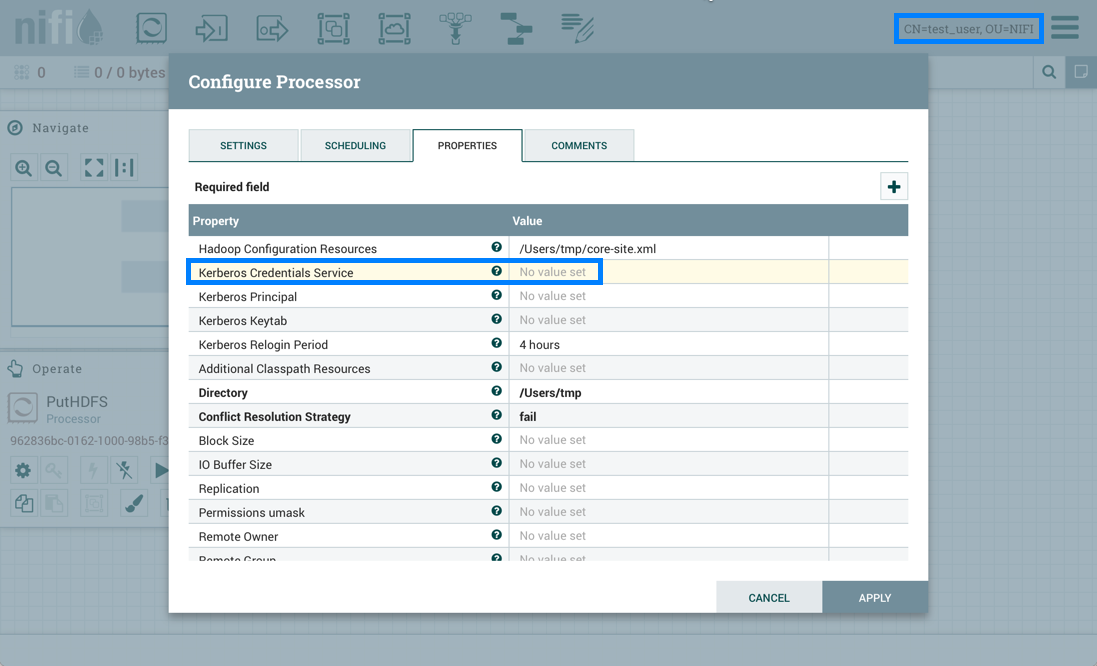
Test_user通过删除基塔布克雷特服务控制器服务来更改流量:
如果test_user选择恢复此更改:
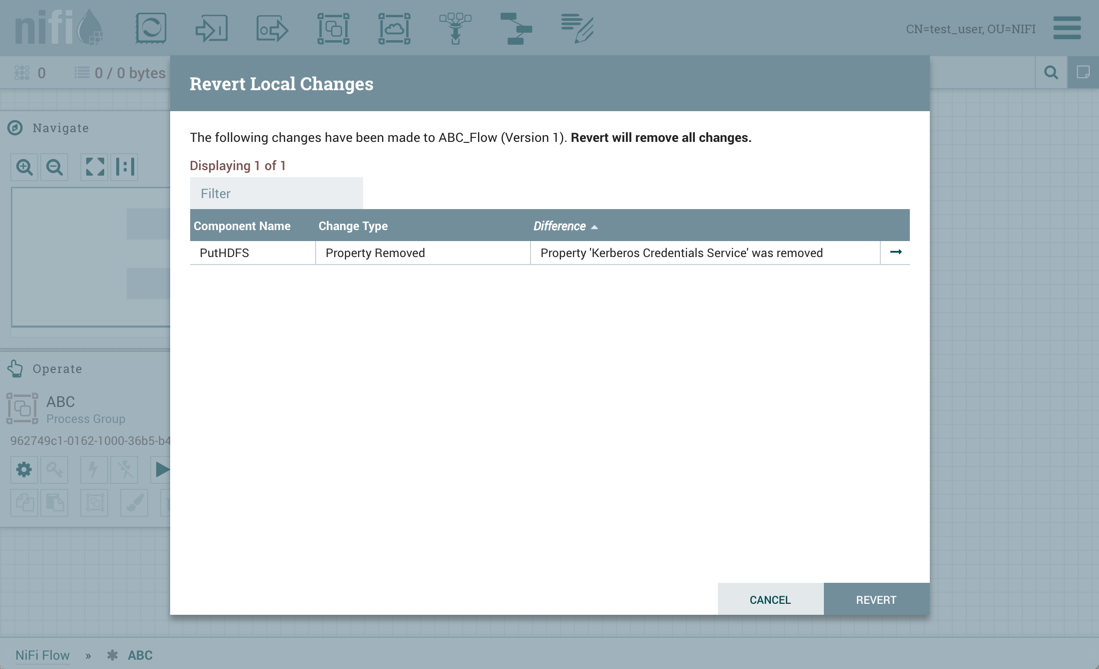
恢复是成功的:
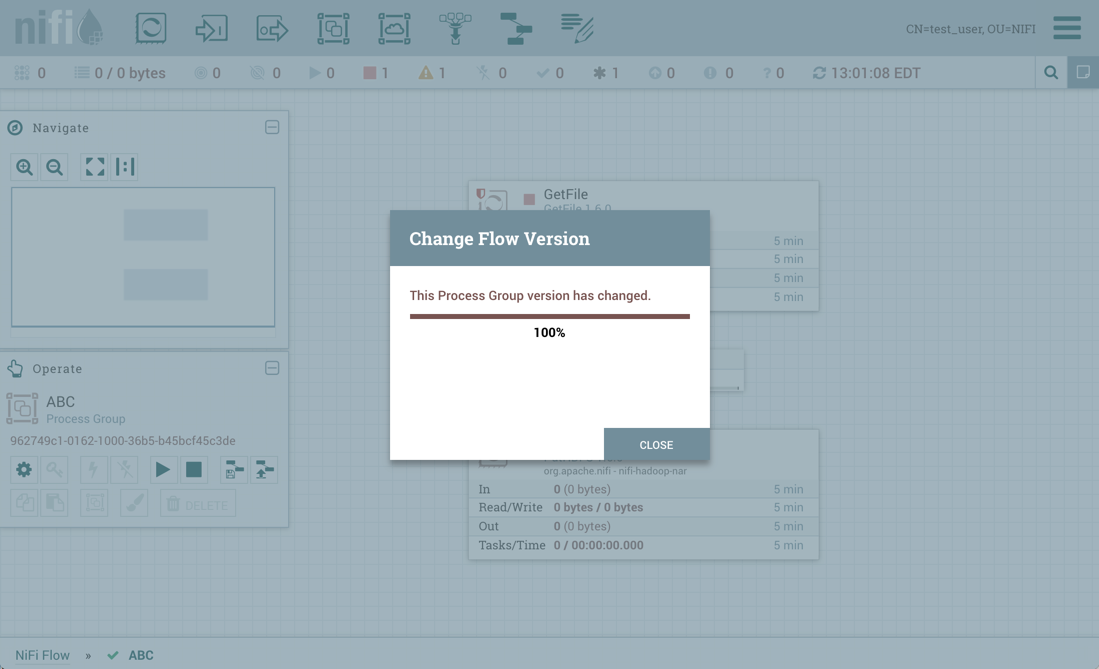
此外,如果test_user选择导入 ABC 版本的流量:
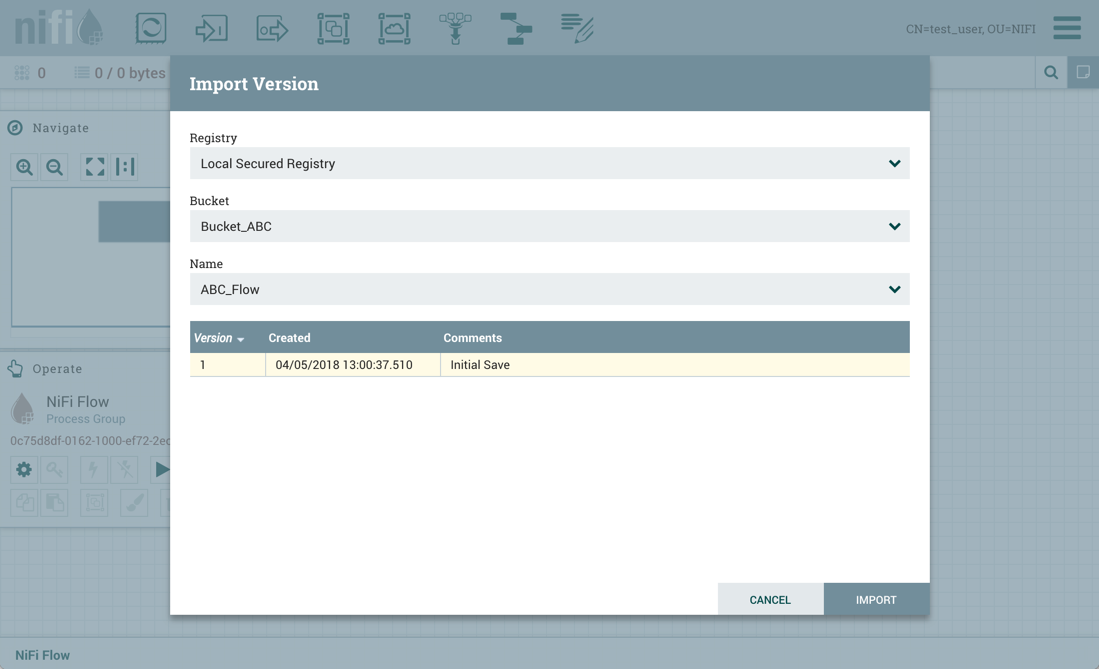
导入成功:
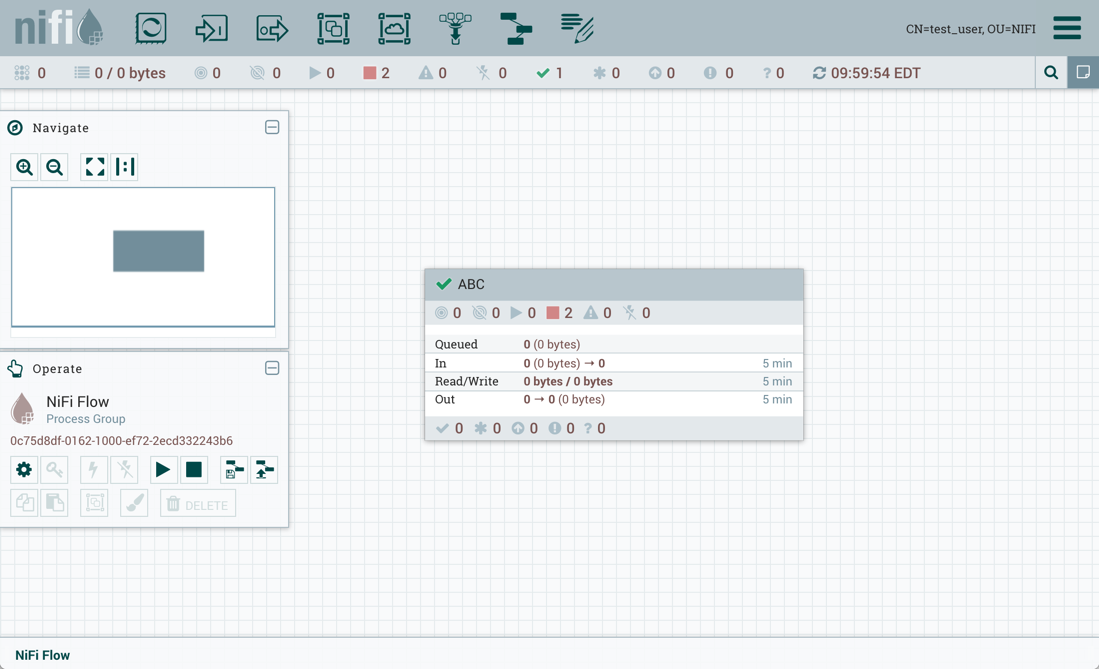
在流程组中创建的限制控制器服务
现在,请考虑在流程组级别创建控制器服务的第二个方案。
Sys_admin 创建流程组 XYZ:
Sys_admin在流程组级别创建关键机密服务控制器服务:
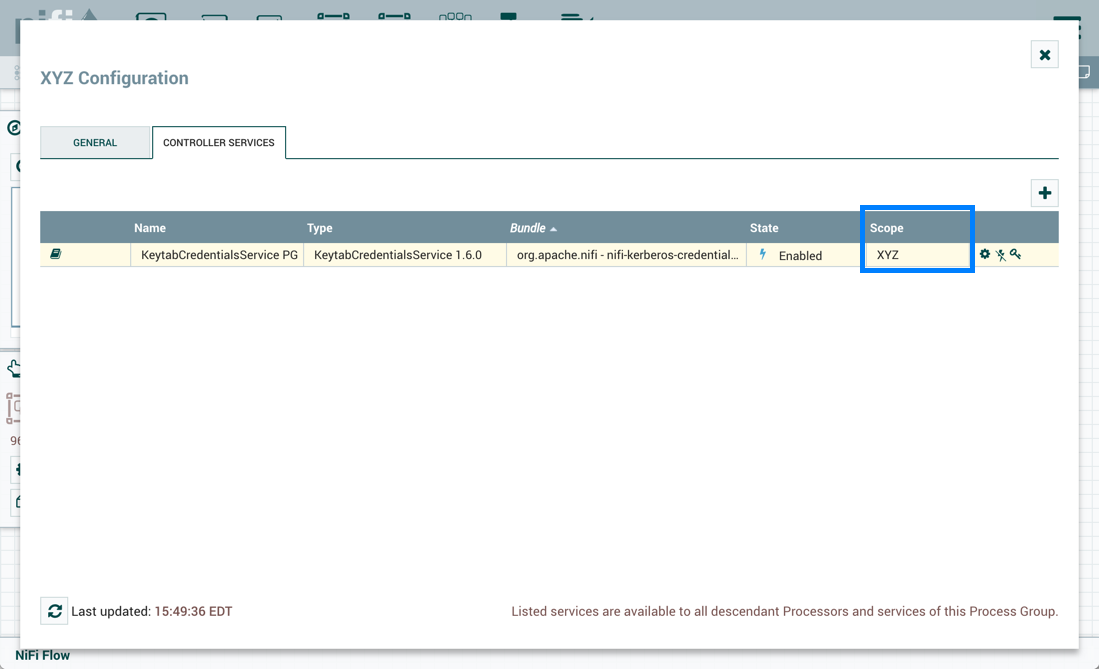
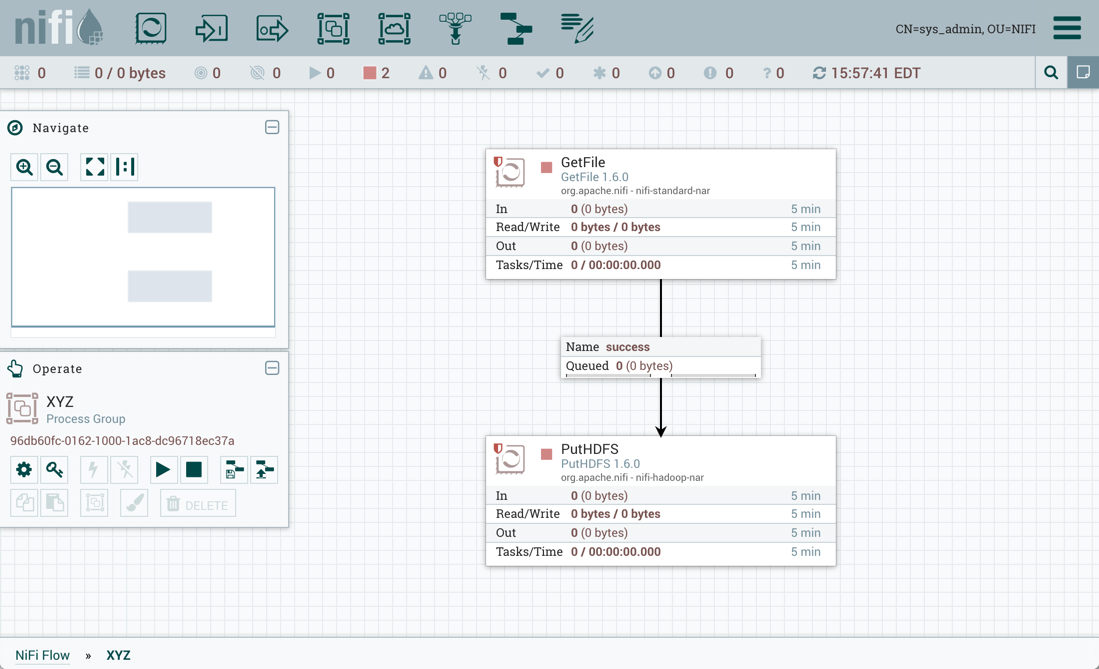
流程组中创建相同的 GetFile 和 PutHDFS 流:
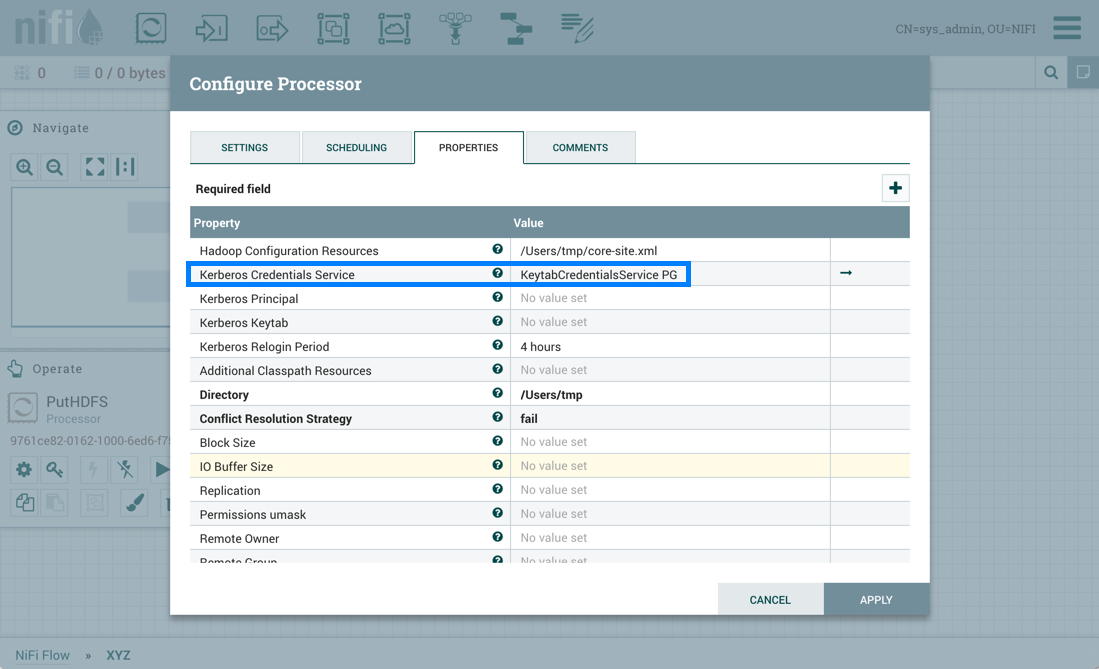
但是,PutHDFS 现在引用了流程组级控制器服务:
Sys_admin将流程组保存为版本流。
Test_user通过删除基塔布克雷特服务控制器服务来更改流量。但是,如果test_user尝试恢复此更改,则此配置将:
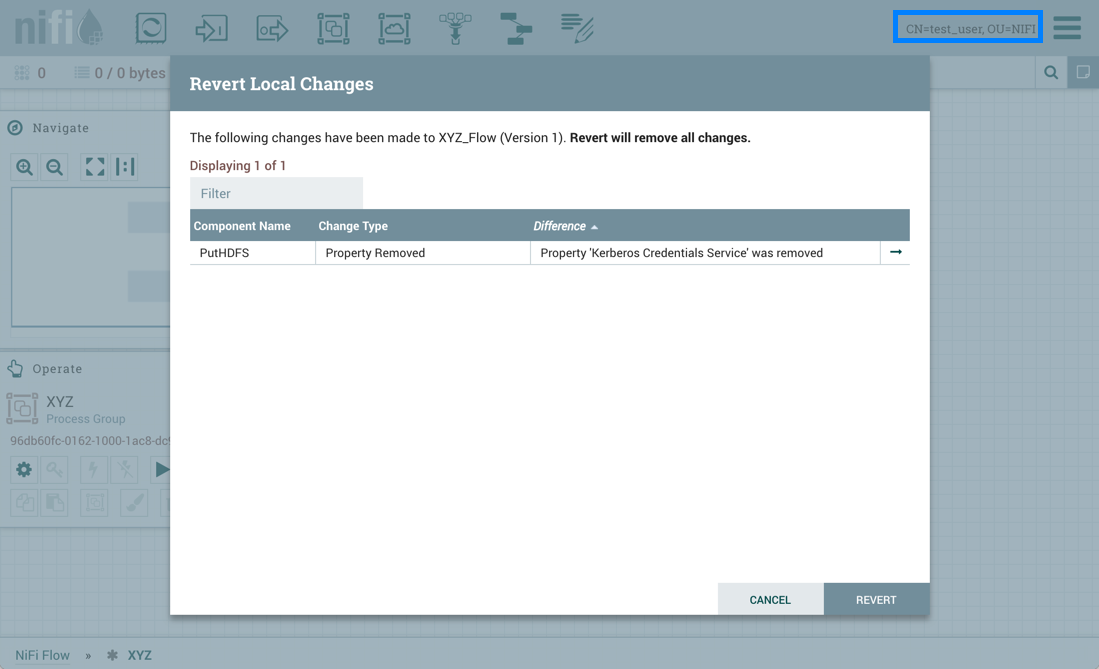
恢复不成功,因为test_user没有 KeytabCred服务控制器服务所需的"访问密钥塔"权限:
同样,如果test_user尝试导入 XYZ 版本的流:
导入失败:
模板
DFM 能够使用 NiFi 构建非常大且复杂的数据流。这是通过使用基本组件实现的:处理器、漏斗、输入/输出端口、流程组和远程处理组。这些可以被认为是构建数据流的最基本构建基块。然而,有时,如果需要重复几次相同的逻辑,使用这些小积木可能会变得乏味。
为了解决这个问题,NiFi 提供了模板的概念。模板是将这些基本构建基块组合成较大积木的一种方式。创建数据流后,可以将其部分形成模板。然后,此模板可以拖到画布上,也可以作为 XML 文件导出并与其他文件共享。然后,从他人那里获得的模板可以导入到 NiFi 实例中并拖到画布上。
创建模板
要创建模板,请选择模板的一部分,然后单击"创建模板” (
 操作调色板中的按钮(请参阅NiFi 用户界面以了解有关操作调色板的更多信息)。
操作调色板中的按钮(请参阅NiFi 用户界面以了解有关操作调色板的更多信息)。
单击此按钮而不选择任何内容将创建包含当前流程组所有内容的模板。这意味着,在 Root 过程组中创建一个没有选择的模板将创建包含整个流的单个模板。
单击此按钮后,提示用户为模板提供名称和可选描述。每个模板必须有一个唯一的名称。输入名称和可选描述后,单击"创建"按钮将生成模板并通知用户模板已成功创建,或在因某些原因无法创建模板时提供适当的错误消息。
| 请务必注意,如果模板中的任何处理器具有敏感属性(如密码),则该敏感属性的价值不包括在模板中。因此,当将模板拖到画布上时,新创建的处理器可能无效,因为它们缺少敏感属性的值。此外,如果连接的源或目的地未也包含在模板中,则在制作模板时选择的任何连接均不包括在模板中。 | |
|---|---|
导入模板
收到从另一个 NiFi 导出的模板后,使用模板所需的第一步是将模板导入 NiFi 的此实例中。您可以在获得适当授权的情况下将模板导入任何流程组。
从操作调色板,单击"上传模板” (
 ) 按钮(有关操作调色板的更多信息,请参阅NiFi 用户界面)。这将显示上传模板对话。单击"查找"图标并使用"文件选择对话"来选择要上传的模板文件。选择文件并单击"打开”。单击"上传"按钮将尝试将模板导入 NiFi 的此实例中。上传模板对话将更新以显示"成功"或错误消息(如果导入模板有问题)。
) 按钮(有关操作调色板的更多信息,请参阅NiFi 用户界面)。这将显示上传模板对话。单击"查找"图标并使用"文件选择对话"来选择要上传的模板文件。选择文件并单击"打开”。单击"上传"按钮将尝试将模板导入 NiFi 的此实例中。上传模板对话将更新以显示"成功"或错误消息(如果导入模板有问题)。
刻例化模板
创建模板(参见创建模板)或导入(参见导入模板)后,它已准备好进行刻录或添加到画布中。这是通过拖动模板图标(
) 从组件工具栏(见NiFi 用户界面)到画布上。
这将提供对话,以选择添加到画布中的模板。选择要添加的模板后,只需单击"添加"按钮即可。模板将被添加到画布上,模板的左上侧将放置在用户丢弃模板图标的位置。
这样,将选择新实例化模板的内容。如果出现错误,并且此模板不再需要,则可能会将其删除。
管理模板
NiFi 模板最强大的功能之一是能够轻松地将模板导出到 XML 文件中,并导入已经导出的模板。这提供了一个非常简单的机制,用于与其他人共享数据流的一部分。您可以从"全球菜单”(参见NiFi 用户界面)中选择模板,以打开显示当前可用的所有模板的对话,筛选模板,仅查看感兴趣的模板、导出和删除模板。
输出模板
创建模板后,可以在模板管理页面中与其他人共享。要导出模板,在表中定位模板。右上角的过滤器可用于帮助查找适当的模板(如果有几个可用)。然后单击"下载"按钮 (
 ).这将将模板作为 XML 文件下载到您的计算机。然后,此 XML 文件可以发送给他人,并导入到 NiFi 的其他实例(参见导入模板)。
).这将将模板作为 XML 文件下载到您的计算机。然后,此 XML 文件可以发送给他人,并导入到 NiFi 的其他实例(参见导入模板)。
删除模板
一旦确定不再需要模板,就可以轻松地从模板管理页面中删除。要删除模板,请将其定位在表中(如果有几个可用,则可用于查找适当的模板过滤器),然后单击"删除"按钮 (
).这将提示确认。确认删除后,模板将从此表中删除,不再可用于添加到画布中。
数据证明
在监控数据流时,用户通常需要一种方法来确定特定数据对象(FlowFile)发生了什么。NiFi 的数据证明页面提供了该信息。由于 NiFi 记录和索引数据来源详细信息,因为对象流经系统,用户可以实时执行搜索、故障排除和评估数据流合规性和优化等内容。默认情况下,NiFi 每五分钟更新一次此信息,但这是可配置的。
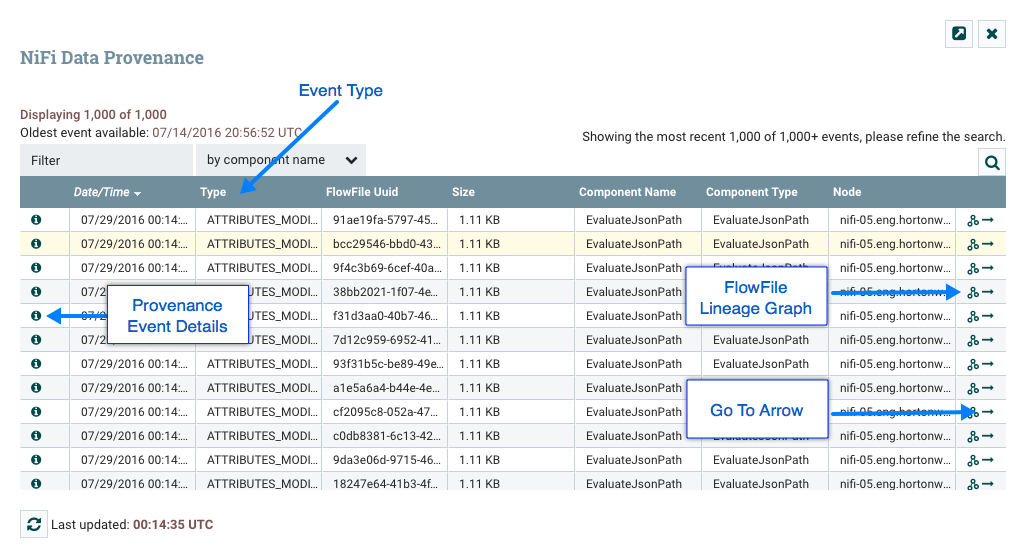
要访问数据证明页面,请从全球菜单中选择"数据证明”。这将打开一个对话窗口,允许用户查看最新的数据证明信息,搜索特定项目的信息,并筛选搜索结果。还可以打开额外的对话窗口,查看事件详细信息,在数据流中的任何点重播数据,并查看数据血统的图形表示,或通过流路径。(以下将深入描述这些功能。
启用授权后,访问数据证明信息需要"查询来源"全球策略以及生成事件的组件的"查看来源"组件策略。此外,访问包含 FlowFile 属性和内容的事件详细信息需要"查看生成事件的组件的数据"组件策略。
证明事件
以某种方式处理 FlowFile 的数据流中的每个点都被视为"证明事件”。根据数据流设计,会发生各种类型的来源事件。例如,当数据被引入流中时,就会发生接收事件,当数据从流中发送时,就会发生发送事件。可能会发生其他类型的处理事件,例如,如果数据被克隆(克隆事件)、路由(ROUTE 事件)、修改(CONTENT_MODIFIED或ATTRIBUTES_MODIFIED事件)、拆分(FORK 事件),与其他数据对象(JOIN 事件)相结合,并最终从流中删除(DROP 事件)。
起源事件类型为:
| 证明事件 | 描述 |
|---|---|
| 阿丁福 | 当添加其他信息(如与新 URI 或 UUID 的新链接)时,指示来源事件 |
| ATTRIBUTES_MODIFIED | 表示流文件的属性以某种方式进行了修改 |
| 克隆 | 表示流文件与其父流文件的精确复制 |
| CONTENT_MODIFIED | 表示流文件的内容以某种方式进行了修改 |
| 创造 | 表示流文件来自未从远程系统或外部过程收到的数据 |
| 下载 | 表示 FlowFile 的内容由用户或外部实体下载 |
| 落 | 表示物体寿命结束的起源事件,原因不是对象过期 |
| 到期 | 表示由于对象未及时处理而导致对象寿命结束的起源事件 |
| 获取 | 表示流文件的内容是使用某些外部资源的内容覆盖的 |
| 叉 | 表示一个或多个流文件来自父流文件 |
| 加入 | 表示单个流文件来自于将多个父流文件连接在一起 |
| 收到 | 指示从外部过程接收数据的来源事件 |
| REMOTE_INVOCATION | 表示请求将远程调用到外部端点(例如删除远程资源) |
| 重播 | 指示重播流文件的起源事件 |
| 路线 | 指示流文件被路由到指定的关系,并提供有关流文件被路由到此关系的信息 |
| 发送 | 指示将数据发送到外部过程的来源事件 |
| 未知 | 表明来源事件的类型未知,因为尝试访问该事件的用户无权知道该类型 |
搜索事件
在数据证明页面中执行的最常见任务之一是搜索给定的 FlowFile 以确定发生了什么。要做到这一点,请单击数据证明页面右上角的"搜索"按钮。这将打开一个对话窗口,其中具有用户可以定义搜索的参数。参数包括感兴趣的处理事件、有关 FlowFile 或产生事件的组件的区分特征、搜索的时间范围以及 FlowFile 的大小。

例如,要确定是否收到了特定的 FlowFile,请搜索"接收"的事件类型,并包括 FlowFile 的标识符,例如其 uuid 或文件名。星号 (*) 可用作任意数量字符的通配符。因此,为了确定在 2016 年 7 月 29 日的任何时间收到文件名中带有"ABC"的 FlowFile,可以执行以下图像中的搜索:

如果需要文件名中任何位置没有"ABC"的所有文件名,请在执行搜索之前单击此条目下方标有"排除搜索结果"的复选框。
事件详情
在数据证明页面的极左列中,每个事件都有一个"查看详细信息"图标 (
).单击此按钮可打开一个对话窗口,其中有三个选项卡:详细信息、属性和内容。
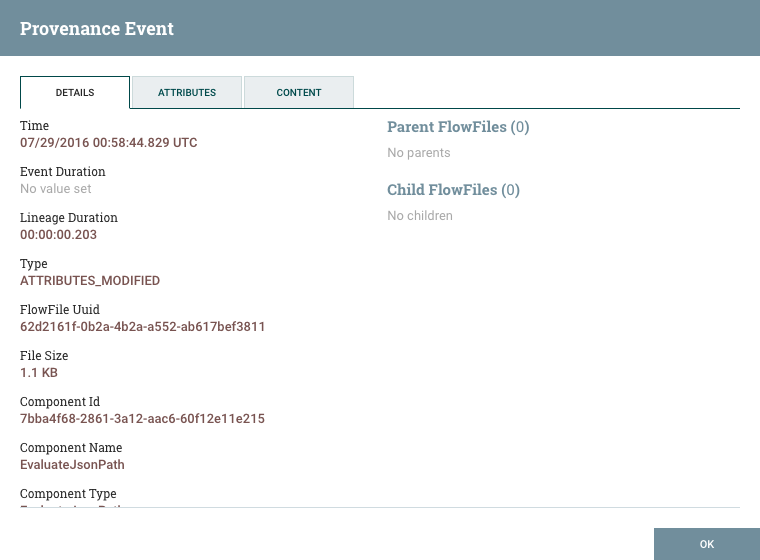
详细信息选项卡显示有关事件的各种详细信息,例如事件发生的时间、事件类型以及产生事件的组件。显示的信息将因事件类型而异。此选项卡还显示有关已处理的 FlowFile 的信息。除了显示在详细信息选项卡左侧的 FlowFile UUID 之外,与流程文件相关的任何家长或儿童的 UUID 都显示在详细信息选项卡的右侧。
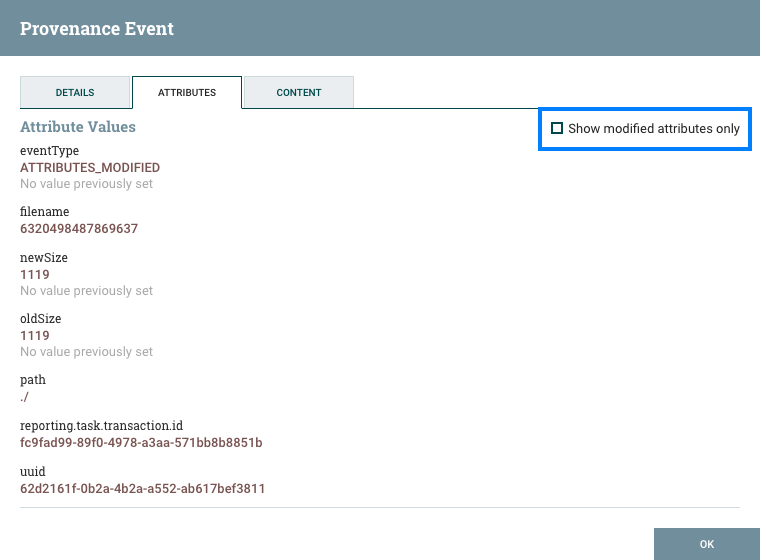
属性选项卡显示流文件中存在的属性,截至流中的该点。为了仅查看因处理事件而修改的属性,用户可以选择属性选项卡右上角"仅显示修改后的"旁边的复选框。
重播流文件
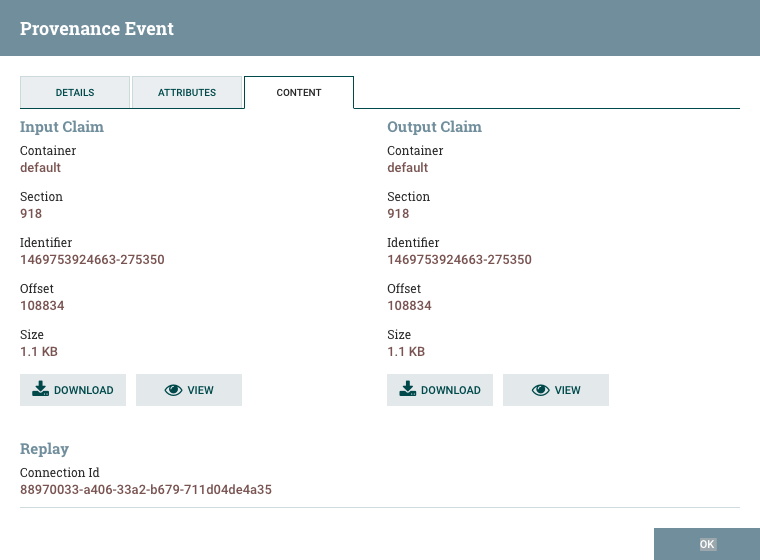
DFM 可能需要在数据流的某个点检查 FlowFile 的内容,以确保其按预期处理。如果处理不当,DFM 可能需要对数据流进行调整,并再次重播 FlowFile。查看详细信息对话窗口的内容选项卡是 DFM 可以做这些事情的地方。内容选项卡显示有关 FlowFile 内容的信息,例如其在内容存储库中的位置及其大小。此外,用户可以单击"下载"按钮来下载 FlowFile 内容的副本,因为它在流的这个点存在。用户还可以单击"提交"按钮,在流的此时重播 FlowFile。单击"提交"后,FlowFile 将发送到连接,以馈送产生此处理事件的组件。
查看流文件血统
查看 FlowFile 在数据流中采取的血统或路径的图形表示通常很有用。要查看 FlowFile 的血统,请单击"显示血统"图标 (
 )在数据证明表的极右列中。这将打开显示流文件的图形 (
)在数据证明表的极右列中。这将打开显示流文件的图形 (
 )和已经发生的各种处理事件。选定的活动将以红色突出显示。可以右键单击或双击任何事件以查看该事件的详细信息(参见事件详细信息)。要查看血统如何随时间演变,请单击窗口左下角的滑块,并将其向左移动,以查看数据流早期阶段的血统状态。
)和已经发生的各种处理事件。选定的活动将以红色突出显示。可以右键单击或双击任何事件以查看该事件的详细信息(参见事件详细信息)。要查看血统如何随时间演变,请单击窗口左下角的滑块,并将其向左移动,以查看数据流早期阶段的血统状态。
查找家长
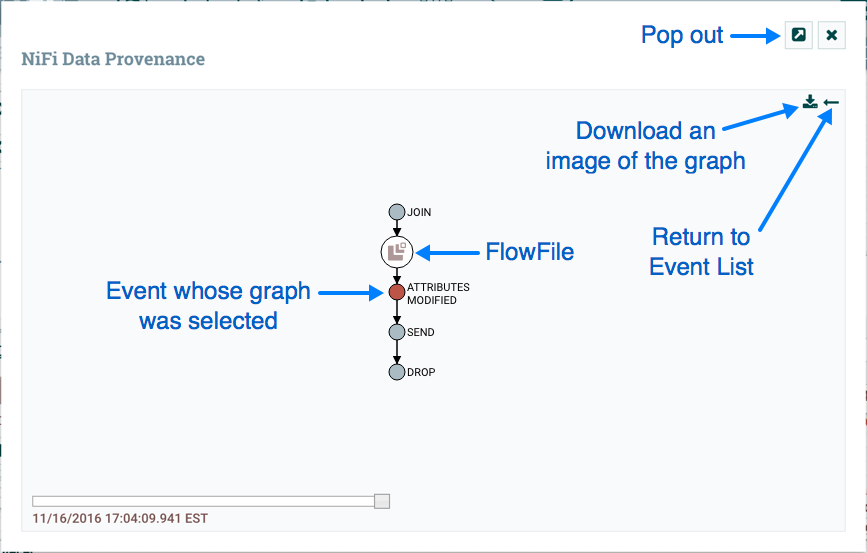
有时,用户可能需要跟踪另一个流文件产生的原始流文件。例如,当发生叉车或克隆事件时,NiFi 会跟踪生成其他流文件的父流文件,并且有可能在血统中找到父流文件。右键单击血统图中的事件,并从上下文菜单中选择"查找父母"。
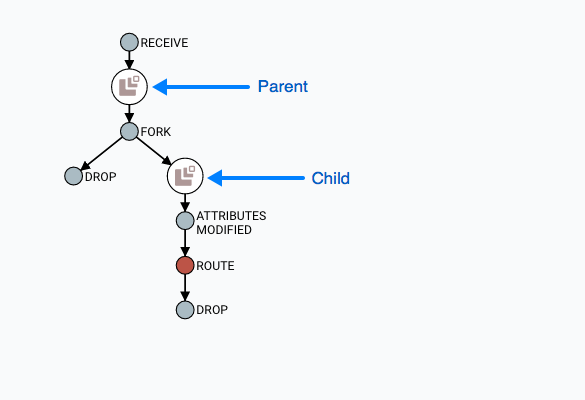
选择"查找父母"后,重新绘制图表以显示父流文件及其血统以及孩子及其血统。
扩展活动
与查找父流文件一样,用户可能还希望确定从给定的 FlowFile 中生成了哪些儿童。为此,请右键单击血统图中的事件,并从上下文菜单中选择"扩展"。
选择"扩展"后,重新绘制图表以显示儿童及其血统。
提前写出证明存储库
默认情况下,证明存储库以持久普罗旺斯配置实现。在 Apache NiFi 1.2.0 中,引入了"提前写"配置,以提供与持久证明相同的功能,但性能要好得多。迁移到"提前写"配置很容易完成。只需将nifi.属性文件中的系统属性设置从默认值更改为重新启动 NiFi。nifi.provenance.repository.implementation``org.apache.nifi.provenance.PersistentProvenanceRepository``org.apache.nifi.provenance.WriteAheadProvenanceRepository
但是,为了增加成功迁移的机会,请考虑以下因素和建议的行动。
向后兼容性
可以使用由 。但是,可能无法读取由 。因此,一旦证明存储库被更改为使用,它就不能更改回不首先删除在证明存储库中的数据。因此,建议在将实施更改为提前编写之前,确保您的 NiFi 版本稳定,以防出现需要回滚到以前版本的 NiFi 不支持的问题。WriteAheadProvenanceRepository``PersistentProvenanceRepository``PersistentProvenanceRepository``WriteAheadProvenanceRepository``WriteAheadProvenanceRepository``PersistentProvenanceRepository``WriteAheadProvenanceRepository
旧版现有 NiFi 版本
如果您要从旧版本的 NiFi 升级到 1.2.0 或更晚版本,建议您在确认流量和环境稳定在 1.2.0 之前,不要将源头配置更改为"提前写"。这减少了升级中的变量数量,如果出现任何问题,可以简化调试过程。
引导. 康夫
虽然 G1 垃圾收集器实现了更好的性能,但 Java 8 错误可能会在"提前写"配置中更频繁地出现。建议在目录中的bootstrap.conf文件中注释以下行:conf
java.arg.13=-XX:+UseG1GC
系统属性
许多相同的系统属性都由"持久"和"提前写"配置支持,但是默认值已选择用于持久证明配置。在更改为"提前写"配置时,应注意以下例外情况和建议:
nifi.provenance.repository.journal.count与提前写入配置无关nifi.provenance.repository.concurrent.merge.threads并且是新的属性。大多数安装应保留螺纹的默认值和频率空白值(即禁用值)。nifi.provenance.repository.warm.cache.frequency``2- 将设置更改为(默认值)和(默认值)到更适合您的生产环境的值
nifi.provenance.repository.max.storage.time``24 hours``nifi.provenance.repository.max.storage.size``1 GB - 从默认值更改为
nifi.provenance.repository.index.shard.size``500 MB``4 GB - 从默认值更改为"提前写"存储库,使其能够更好地缩放
nifi.provenance.repository.index.threads``2``4``8 - 如果处理大量事件,则从默认更改为默认到
nifi.provenance.repository.rollover.time``30 secs``1 min``nifi.provenance.repository.rollover.size``100 MB``1 GB
一旦这些属性更改已更改,重新启动 NiFi。
**注意:**系统属性中可以找到每个属性的详细描述。
加密的证明考虑
上述迁移建议也适用于配置的加密版本。WriteAheadProvenanceRepository``EncryptedWriteAheadProvenanceRepository
下一节有更多有关实施加密证明存储库的信息。
加密的证明存储库
虽然操作系统级别的访问控制可以为存储库中写入磁盘的源数据提供一些安全性,但在某些情况下,数据可能很敏感,存在合规性和监管要求,或者 NiFi 在不在组织直接控制下的硬件上运行(云等)。在这种情况下,来源存储库允许在将所有数据粘附到磁盘之前对所有数据进行加密。
| 实验的此实施标记为阿帕奇 NiFi 1.10.0(2019 年 10 月)的实验性。API、配置和内部行为可能会在没有警告的情况下更改,此类更改可能会在小版本期间发生。风险自担。 | |
|---|---|
性能加密来源存储库的当前实现截获了记录编写器和读卡器,这比旧版具有显著的性能改进,并且使用了在商品硬件上相当出色的算法。在大多数情况下,添加的成本不会显著(在流量上不明显,每秒有数百个起源事件,在流量上中适度可注意到,每秒有数千到数万个事件)。但是,管理员应执行自己的风险评估和绩效分析,并决定如何前进。目前不建议在加密/未加密的实现之间来回切换。WriteAheadProvenanceRepository``PersistentProvenanceRepository``AES/GCM |
|
|---|---|
这是什么?
这是起源存储库的新实现,该存储库在将所有事件记录信息写入存储库之前对所有事件记录信息进行加密。这允许在操作系统级别的访问控制不足以保护数据的系统上存储,同时仍然允许通过 NiFi UI/API 查询和访问数据。EncryptedWriteAheadProvenanceRepository
它是如何工作的?
在NiFi 1.2.0中引入,并提供了一个重构和更快的起源库实施比上一个。加密版本将实现与分别加密和解密序列化字节的记录编写器和读卡器进行包装。WriteAheadProvenanceRepository``PersistentProvenanceRepository
完全合格的类被指定为nifi. 属性中的来源存储库实现值。此外,必须填充新属性,以便成功初始化。org.apache.nifi.provenance.EncryptedWriteAheadProvenanceRepository``nifi.provenance.repository.implementation
静态键提供器
实施直接定义了nifi. 属性中的密钥。单个密钥以六分法编码提供。密钥也可以像nifi. 属性中的任何其他敏感属性一样使用 niFi 工具包中的。/encrypt-config.sh工具包中的任何其他敏感属性进行加密。StaticKeyProvider
以下配置部分将导致一个键提供商具有两个可用密钥,即"Key1"(活动)和"另一个键"。
nifi.provenance.repository.encryption.key.provider.implementation=org.apache.nifi.security.kms.StaticKeyProvider
nifi.provenance.repository.encryption.key.id=Key1
nifi.provenance.repository.encryption.key=0123456789ABCDEFFEDCBA98765432100123456789ABCDEFFEDCBA9876543210
nifi.provenance.repository.encryption.key.id.AnotherKey=0101010101010101010101010101010101010101010101010101010101010101
基于文件的基提供者
实施内容从格式的加密定义文件中读取:FileBasedKeyProvider
key1=NGCpDpxBZNN0DBodz0p1SDbTjC2FG5kp1pCmdUKJlxxtcMSo6GC4fMlTyy1mPeKOxzLut3DRX+51j6PCO5SznA==
key2=GYxPbMMDbnraXs09eGJudAM5jTvVYp05XtImkAg4JY4rIbmHOiVUUI6OeOf7ZW+hH42jtPgNW9pSkkQ9HWY/vQ==
key3=SFe11xuz7J89Y/IQ7YbJPOL0/YKZRFL/VUxJgEHxxlXpd/8ELA7wwN59K1KTr3BURCcFP5YGmwrSKfr4OE4Vlg==
key4=kZprfcTSTH69UuOU3jMkZfrtiVR/eqWmmbdku3bQcUJ/+UToecNB5lzOVEMBChyEXppyXXC35Wa6GEXFK6PMKw==
key5=c6FzfnKm7UR7xqI2NFpZ+fEKBfSU7+1NvRw+XWQ9U39MONWqk5gvoyOCdFR1kUgeg46jrN5dGXk13sRqE0GETQ==
每行定义一个关键 ID,然后根据可用的 JCE 策略,定义 16 字节 IV 的 Base64 编码密码文本,并包装 AES-128、AES-192 或 AES-256 密钥。单个密钥由 AES/GCM 加密使用在 conf/bootstrap.conf中定义的根键进行包裹。nifi.bootstrap.sensitive.key
钥匙店提供者
实施从使用配置的密码加载 AES 密钥条目的标准中读取。KeyStoreKeyProvider``java.security.KeyStore
提供商支持以下钥匙店类型:
- 布克夫克斯
- PCKCS12
钥匙店文件名扩展必须是指示 PKCS12 或指示 BCFKS。.p12``.bcfks
该命令可用于生成存储在 PKCS12 文件中的 AES-256 秘密密钥,用于存储库加密:keytool
…钥匙凳 - 根塞基 - 别名主键 - 键 - 键 - 键大小 256 - 钥匙店存储库. p12 - 存储类型 Pkcs12。
提示时输入钥匙店密码。密钥商店密码和密钥密码必须使用相同的值。钥匙店密码将用于提供商配置属性。
以下配置属性支持使用带有秘密密钥的 PKCS12 钥匙店:
…NIFI. 证明. 存储. 加密.key. 提供商. 实施 = org. apache. nifi. 安全. kms. 关键商店提供者 nifi. 证明. 存储器. 加密.key. 提供商. 位置 ./conf/存储.p12 NIFI.证明.存储.加密.key.提供商.密码=KEYSTORE_PASSWORDNIFI.证明.存储.加密.key.id]主键…
键旋转
只需更新nifi.属性,即可在 。只要该密钥仍可在密钥定义文件中可用,或者当密钥 ID 与加密记录一起序列化时,以前加密的事件仍然可以解密。nifi.provenance.repository.encryption.key.id``nifi.provenance.repository.encryption.key.id.<OldKeyID>
写作和阅读活动记录
一旦存储库被初始化,所有来源事件记录写入操作被序列化根据配置的架构编写器(默认为)到。然后,这些字节使用(唯一当前的实现)进行加密,加密元数据(,,,)被序列化和预支。然后,完整性将正常写入磁盘上的存储库。EventIdFirstSchemaRecordWriter``WriteAheadProvenanceRepository``byte[]``ProvenanceEventEncryptor``AES/GCM/NoPadding``keyId``algorithm``version``IV``byte[]

在记录中读取,过程被反转。加密元数据被解析并用于解密序列化字节,然后将这些字节解密为对象。正常架构记录编写者/读取器的代表团允许"随机访问"(即立即寻求而不解密不必要的记录)。ProvenanceEventRecord
在 NiFi UI/API 中,加密和未加密的产地存储库之间没有可检测到的差异。证明查询操作工作如预期的那样,流程没有变化。
潜在问题
切换实现在实现"家庭"(即)之间切换时 或到), 现有的存储库必须清除从文件系统之前启动 NiFi.像这样的终端命令就足够了。VolatileProvenanceRepository``PersistentProvenanceRepository``EncryptedWriteAheadProvenanceRepository``localhost:$NIFI_HOME $ rm -rf provenance_repository/ |
|
|---|---|
- 在未加密和加密存储库之间切换
- 如果用户有一个未加密的现有存储库(仅非加密),并且将其配置切换到使用加密存储库,则应用程序会向日志写入错误,但会启动。但是,无法通过来源查询界面访问以前的事件,新事件将覆盖现有事件。如果用户从加密存储库切换到未加密存储库,则也会发生同样的行为。自动展期是未来的努力(NIFI-3722),但 NiFi 不是用于长期存储产地事件, 所以影响应该很小。翻滚有两种情况:
WriteAheadProvenanceRepository``PersistentProvenanceRepository- 加密→未加密 - 如果以前的存储库实现已加密,则只要可用的关键提供商仍然具有用于加密事件的密钥(参见“密钥旋转”),这些事件应无缝处理)
- 未加密→加密 - 如果以前的存储库实现未加密,这些事件应无缝处理,因为以前录制的事件只需用便文本架构记录读取器读取,然后用加密的记录编写器重新编写
- 今后还将努力在 NiFi 工具包中提供独立工具,以加密/解密现有来源存储库,使过渡更加容易。翻译过程可能需要很长时间,这取决于现有存储库的大小,能够在应用程序启动之外执行此任务将是有价值的(NIFI-3723)。
- 如果用户有一个未加密的现有存储库(仅非加密),并且将其配置切换到使用加密存储库,则应用程序会向日志写入错误,但会启动。但是,无法通过来源查询界面访问以前的事件,新事件将覆盖现有事件。如果用户从加密存储库切换到未加密存储库,则也会发生同样的行为。自动展期是未来的努力(NIFI-3722),但 NiFi 不是用于长期存储产地事件, 所以影响应该很小。翻滚有两种情况:
- 多个存储库 - 目前没有对多个存储库进行额外的努力或测试。不同物理设备上的存储库可能会/可能发生问题。没有选择提供异质环境(即一个加密的、一个便秘的存储库)。
- 腐败 - 当磁盘被填充或损坏时,有报道称存储库会损坏,并且需要采取恢复步骤。这可能继续是加密存储库的问题,尽管范围仍然局限于单个记录(即由于加密,整个存储库文件无法恢复)。
加密内容存储库
虽然操作系统级别的访问控制可以为存储库中写入磁盘的流文件内容数据提供一些安全性,但在某些情况下,数据可能很敏感,存在合规性和监管要求,或者 NiFi 在非组织直接控制的硬件上运行(云等)。在这种情况下,内容存储库允许在将所有数据粘附到磁盘之前对所有数据进行加密。有关内容存储库内部工作的更多信息,请参阅NiFi 深度内容存储库。
| 实验的此实施标记为阿帕奇 NiFi 1.10.0(2019 年 10 月)的实验性。API、配置和内部行为可能会在没有警告的情况下更改,此类更改可能会在小版本期间发生。风险自担。 | |
|---|---|
性能加密内容存储库的当前实施通过和使用算法拦截内容数据的序列化,该算法在商品硬件上相当有性能。流密码的使用(因为内容以流式处理的方式进行性能操作)不同于使用经过验证的加密算法 (AEAD),如在加密的证明存储库中。在大多数情况下,添加的成本不会很大(在流量中,每秒有数百个内容读/写事件,在流量上每秒有数千到数万个事件,这一点不明显)。但是,管理员应执行自己的风险评估和绩效分析,并决定如何前进。目前不建议在加密/未加密的实现之间来回切换。EncryptedContentRepositoryOutputStream``AES/CTR``AES/GCM |
|
|---|---|
这是什么?
这是内容存储库的新实现,该存储库在将所有内容数据写入存储库之前对所有内容数据进行加密。这允许在操作系统级别的访问控制不足以保护数据的系统上存储,同时仍然允许通过 NiFi UI/API 查询和访问数据。EncryptedFileSystemRepository
它是如何工作的?
该方案在 NiFi 0.2.1 中引入,并提供了唯一的持久内容存储库实现。加密版本将实现与功能包裹起来,以返回到(通常)一个特殊/分别加密和解密序列化字节的专用/解密。这允许所有组件继续以与以前相同的方式与内容存储库界面交互,并继续以流式处理方式对内容数据进行操作,而无需任何更改即可处理数据保护。FileSystemRepository``Session``StandardProcessSession``OutputStream``InputStream
完全合格的类指定为nifi. 属性中的内容存储库实现值。此外,必须填充新属性,以便成功初始化。org.apache.nifi.content.EncryptedFileSystemRepository``nifi.content.repository.implementation
静态键提供器
实施直接定义了nifi. 属性中的密钥。单个密钥以六分法编码提供。密钥也可以像nifi. 属性中的任何其他敏感属性一样使用 niFi 工具包中的。/encrypt-config.sh工具包中的任何其他敏感属性进行加密。StaticKeyProvider
以下配置部分将导致一个键提供商具有两个可用密钥,即"Key1"(活动)和"另一个键"。
nifi.content.repository.encryption.key.provider.implementation=org.apache.nifi.security.kms.StaticKeyProvider
nifi.content.repository.encryption.key.id=Key1
nifi.content.repository.encryption.key=0123456789ABCDEFFEDCBA98765432100123456789ABCDEFFEDCBA9876543210
nifi.content.repository.encryption.key.id.AnotherKey=0101010101010101010101010101010101010101010101010101010101010101
基于文件的基提供者
实施内容从格式的加密定义文件中读取:FileBasedKeyProvider
key1=NGCpDpxBZNN0DBodz0p1SDbTjC2FG5kp1pCmdUKJlxxtcMSo6GC4fMlTyy1mPeKOxzLut3DRX+51j6PCO5SznA==
key2=GYxPbMMDbnraXs09eGJudAM5jTvVYp05XtImkAg4JY4rIbmHOiVUUI6OeOf7ZW+hH42jtPgNW9pSkkQ9HWY/vQ==
key3=SFe11xuz7J89Y/IQ7YbJPOL0/YKZRFL/VUxJgEHxxlXpd/8ELA7wwN59K1KTr3BURCcFP5YGmwrSKfr4OE4Vlg==
key4=kZprfcTSTH69UuOU3jMkZfrtiVR/eqWmmbdku3bQcUJ/+UToecNB5lzOVEMBChyEXppyXXC35Wa6GEXFK6PMKw==
key5=c6FzfnKm7UR7xqI2NFpZ+fEKBfSU7+1NvRw+XWQ9U39MONWqk5gvoyOCdFR1kUgeg46jrN5dGXk13sRqE0GETQ==
每行定义一个关键 ID,然后根据可用的 JCE 策略,定义 16 字节 IV 的 Base64 编码密码文本,并包装 AES-128、AES-192 或 AES-256 密钥。单个密钥由 AES/GCM 加密使用在 conf/bootstrap.conf中定义的根键进行包裹。nifi.bootstrap.sensitive.key
钥匙店提供者
实施从使用配置的密码加载 AES 密钥条目的标准中读取。KeyStoreKeyProvider``java.security.KeyStore
提供商支持以下钥匙店类型:
- 布克夫克斯
- PCKCS12
钥匙店文件名扩展必须是指示 PKCS12 或指示 BCFKS。.p12``.bcfks
该命令可用于生成存储在 PKCS12 文件中的 AES-256 秘密密钥,用于存储库加密:keytool
…钥匙凳 - 根塞基 - 别名主键 - 键 - 键 - 键大小 256 - 钥匙店存储库. p12 - 存储类型 Pkcs12。
提示时输入钥匙店密码。密钥商店密码和密钥密码必须使用相同的值。钥匙店密码将用于提供商配置属性。
以下配置属性支持使用带有秘密密钥的 PKCS12 钥匙店:
…NIFI. 内容. 存储. 加密.key. 提供商. 实施 = org. apache. nifi. 安全. kms. 关键商店提供NIFI. 内容. 存储器. 加密.key. 提供商. 位置] ./conf/存储.p12 NIFI.内容.存储.加密.key.提供商.密码=KEYSTORE_PASSWORDNIFI.内容.存储.加密.key.id]主键…
数据保护与关键保护
即使流文件内容是加密的,使用处理流媒体数据,如果使用配置加密工具或,这些密钥将被保护使用,以提供对密钥材料的认证加密。AES/CTR``FileBasedKeyProvider``AES/GCM
键旋转
只需更新nifi.属性,即可在 。只要该密钥仍可在密钥定义文件中可用,或者当密钥 ID 与加密内容一起序列化时,以前加密的内容声明仍然可以解密。nifi.content.repository.encryption.key.id``nifi.content.repository.encryption.key.id.<OldKeyID>
写作和阅读内容声明
一旦存储库被初始化,所有内容声明编写操作被序列化使用(目前唯一的实现是)到。实际实现是,通过内联加密组件编写的数据,加密元数据(,)被序列化和预支。然后,完整性将正常写入磁盘上的存储库。RepositoryObjectStreamEncryptor``RepositoryObjectAESCTREncryptor``OutputStream``EncryptedContentRepositoryOutputStream``StandardProcessSession``keyId``algorithm``version``IV``OutputStream

在内容声明读取时,过程会相反。加密元数据 () 被解析并用于解密序列化字节,然后将这些字节去隔离到对象中。正常存储库文件系统交互的委托允许"随机访问"(即立即寻求而不解密不必要的内容声明)。RepositoryObjectEncryptionMetadata``CipherInputStream
在 NiFi UI/API 中,加密内容存储库和未加密内容存储库之间没有可检测到的差异。证明查询操作以按预期查看内容工作,而不会更改流程。
潜在问题
切换实现在实现"家庭"(即)之间切换时 或到), 现有的存储库必须清除从文件系统之前启动 NiFi.像这样的终端命令就足够了。VolatileContentRepository``FileSystemRepository``EncryptedFileSystemRepository``localhost:$NIFI_HOME $ rm -rf content_repository/ |
|
|---|---|
- 在未加密和加密存储库之间切换
- 如果用户有一个未加密的现有存储库()并将其配置切换到使用加密存储库,则应用程序会向日志写入错误,但会启动。但是,无法通过来源查询界面访问以前的内容声明,新内容声明将覆盖现有索赔。如果用户从加密存储库切换到未加密存储库,则也会发生同样的行为。自动翻滚是未来的努力(NIFI-6783),但 NiFi 不打算长期存储内容索赔, 所以影响应该很小。翻滚有两种情况:
FileSystemRepository- 加密→未加密 - 如果以前的存储库实现已加密,则只要可用的关键提供商仍然拥有用于加密声明的密钥,这些声明应无缝处理(参见密钥旋转))
- 未加密→加密 - 如果以前的存储库实施未加密,这些声明应无缝处理,因为以前书面声明只需用便条字阅读,然后用
InputStream``EncryptedContentRepositoryOutputStream
- 今后还将努力在 NiFi 工具包中提供独立工具包,以加密/解密现有内容存储库,使过渡更加容易。翻译过程可能需要很长时间,这取决于现有存储库的大小,能够在应用程序启动之外执行此任务将是有价值的(NIFI-6783)。
- 如果用户有一个未加密的现有存储库()并将其配置切换到使用加密存储库,则应用程序会向日志写入错误,但会启动。但是,无法通过来源查询界面访问以前的内容声明,新内容声明将覆盖现有索赔。如果用户从加密存储库切换到未加密存储库,则也会发生同样的行为。自动翻滚是未来的努力(NIFI-6783),但 NiFi 不打算长期存储内容索赔, 所以影响应该很小。翻滚有两种情况:
- 多个存储库 - 目前没有对多个存储库进行额外的努力或测试。不同物理设备上的存储库可能会/可能发生问题。没有选择提供异质环境(即一个加密的、一个便秘的存储库)。
- 腐败 - 当磁盘被填充或损坏时,有报道称存储库会损坏,并且需要采取恢复步骤。这可能继续是加密存储库的问题,尽管范围仍然仅限于个人索赔(即由于加密,整个存储库文件无法恢复)。已对磁盘空间耗尽的场景进行了一些测试。在这种情况下,虽然流量不能再向存储库编写其他内容声明,但 NiFi 应用程序继续正常工作,并且通过证明查询操作仍可成功编写内容声明。停止 NiFi 并删除内容存储库(或将其移动到更大的磁盘)可以解决问题。
加密流文件存储库
虽然操作系统级别的访问控制可以为存储库中写入磁盘的流文件属性和内容声明数据提供一些安全性,但在某些情况下,数据可能很敏感、存在合规性和监管要求,或者 NiFi 在不在组织直接控制下的硬件上运行(云等)。在这种情况文件存储库允许在将所有数据粘附到磁盘之前对所有数据进行加密。有关流文件库内部工作的更多信息,请参阅NiFi 深度 - 流文件存储库。
| 实验的此实施标记为阿帕奇 NiFi 1.11.0(2020 年 1 月)的实验性。API、配置和内部行为可能会在没有警告的情况下更改,此类更改可能会在小版本期间发生。风险自担。 | |
|---|---|
性能加密流文件存储库的当前实施通过该算法截获流文件记录数据的序列化,并使用该算法,该算法在商品硬件上相当出色。此使用经过验证的加密算法 (AEAD) 块密码(因为内容长度有限且已知优先)与加密证明存储库相同,但与加密内容存储库中使用的未经授权的流密码不同。在低容量流文件的情况下,增加的成本将是最小的。但是,管理员应执行自己的风险评估和绩效分析,并决定如何前进。目前不建议在加密/未加密的实现之间来回切换。EncryptedSchemaRepositoryRecordSerde``AES/GCM |
|
|---|---|
这是什么?
这是流文件提前写入日志的新实现,该日志在将所有流文件属性数据写入存储库之前对数据进行加密。这允许在操作系统级别的访问控制不足以保护数据的系统上存储,同时仍然允许通过 NiFi UI/API 查询和访问数据。EncryptedSequentialAccessWriteAheadLog
它是如何工作的?
该文件在 NiFi 1.6.0 中引入,并提供了更快的流文件存储库实现。加密版本将实现与功能包裹起来,以便在文件系统交互过程中透明地加密和解密序列化对象。在所有写到磁盘(交换、快照、日记和检查点)期间,流文件容器根据图文并联,此序列化表单在编写前进行加密。这允许快照处理程序继续以与以前相同的方式与流文件存储库界面交互,并继续以随机访问方式在流文件数据上运行,而无需任何更改即可处理数据保护。SequentialAccessWriteAheadLog``RepositoryRecord
完全合格的类被指定为流文件存储库在nifi. 属性中写入日志实现值。此外,必须填充新属性,以便成功初始化。org.apache.nifi.wali.EncryptedSequentialAccessWriteAheadLog``nifi.flowfile.repository.wal.implementation
静态键提供器
实施直接定义了nifi. 属性中的密钥。单个密钥以六分法编码提供。密钥也可以像nifi. 属性中的任何其他敏感属性一样使用 niFi 工具包中的。/encrypt-config.sh工具包中的任何其他敏感属性进行加密。StaticKeyProvider
以下配置部分将导致一个键提供商具有两个可用密钥,即"Key1"(活动)和"另一个键"。
nifi.flowfile.repository.encryption.key.provider.implementation=org.apache.nifi.security.kms.StaticKeyProvider
nifi.flowfile.repository.encryption.key.id=Key1
nifi.flowfile.repository.encryption.key=0123456789ABCDEFFEDCBA98765432100123456789ABCDEFFEDCBA9876543210
nifi.flowfile.repository.encryption.key.id.AnotherKey=0101010101010101010101010101010101010101010101010101010101010101
基于文件的基提供者
实施内容从格式的加密定义文件中读取:FileBasedKeyProvider
key1=NGCpDpxBZNN0DBodz0p1SDbTjC2FG5kp1pCmdUKJlxxtcMSo6GC4fMlTyy1mPeKOxzLut3DRX+51j6PCO5SznA==
key2=GYxPbMMDbnraXs09eGJudAM5jTvVYp05XtImkAg4JY4rIbmHOiVUUI6OeOf7ZW+hH42jtPgNW9pSkkQ9HWY/vQ==
key3=SFe11xuz7J89Y/IQ7YbJPOL0/YKZRFL/VUxJgEHxxlXpd/8ELA7wwN59K1KTr3BURCcFP5YGmwrSKfr4OE4Vlg==
key4=kZprfcTSTH69UuOU3jMkZfrtiVR/eqWmmbdku3bQcUJ/+UToecNB5lzOVEMBChyEXppyXXC35Wa6GEXFK6PMKw==
key5=c6FzfnKm7UR7xqI2NFpZ+fEKBfSU7+1NvRw+XWQ9U39MONWqk5gvoyOCdFR1kUgeg46jrN5dGXk13sRqE0GETQ==
每行定义一个关键 ID,然后根据可用的 JCE 策略,定义 16 字节 IV 的 Base64 编码密码文本,并包装 AES-128、AES-192 或 AES-256 密钥。单个密钥由 AES/GCM 加密使用在 conf/bootstrap.conf中定义的根键进行包裹。nifi.bootstrap.sensitive.key
钥匙店提供者
实施从使用配置的密码加载 AES 密钥条目的标准中读取。KeyStoreKeyProvider``java.security.KeyStore
提供商支持以下钥匙店类型:
- 布克夫克斯
- PCKCS12
钥匙店文件名扩展必须是指示 PKCS12 或指示 BCFKS。.p12``.bcfks
该命令可用于生成存储在 PKCS12 文件中的 AES-256 秘密密钥,用于存储库加密:keytool
…钥匙凳 - 根塞基 - 别名主键 - 键 - 键 - 键大小 256 - 钥匙店存储库. p12 - 存储类型 Pkcs12。
提示时输入钥匙店密码。密钥商店密码和密钥密码必须使用相同的值。钥匙店密码将用于提供商配置属性。
以下配置属性支持使用带有秘密密钥的 PKCS12 钥匙店:
…NIFI. 流文件. 存储库. 加密.key. 提供商. 实施 = org. apache. nifi. 安全. kms. 关键商店关键提供者 nifi. 流文件. 存储库. 加密.key. 提供商. 位置] ./conf/存储.p12 NIFI.流文件.存储.加密.key.提供商.密码=KEYSTORE_PASSWORDNIFI.流文件.存储.加密.key.id]主键…
键旋转
只需更新nifi.属性,即可在 。只要该密钥仍可在密钥定义文件中可用,或者密钥 ID 与加密记录一起序列化,以前加密的流文件记录仍然可以解密。nifi.flowfile.repository.encryption.key.id``nifi.flowfile.repository.encryption.key.id.<OldKeyID>
写作和阅读流程文件
一旦存储库被初始化,所有流文件记录写入操作都使用(目前唯一的实现是)对所提供的序列化。原始流与临时包装流交换,该流通过内联加密包裹的序列化器/去数据器编写的数据,加密元数据(,)被序列化和预支。然后,完整长度和加密字节将正常写入磁盘上的原始字节。RepositoryObjectBlockEncryptor``RepositoryObjectAESGCMEncryptor``DataOutputStream``EncryptedSchemaRepositoryRecordSerde``keyId``algorithm``version``IV``cipherByteLength``DataOutputStream

在流文件记录读取时,过程被反转。加密元数据 () 被解析并用于解密序列化字节,然后将这些字节去隔离到对象中。RepositoryObjectEncryptionMetadata``DataInputStream
在交换和恢复期间,流文件记录被除隔离和重新隔离,因此,如果活动密钥已更改,流文件记录将重新加密与新的活动密钥。
在 NiFi UI/API 中,加密流文件存储库之间没有可检测到的差异。与流文件的所有框架交互工作如预期的那样,流程没有变化。
潜在问题
切换实现不建议在除要从不同的提供商迁移,请首先迁移到便文本顺序日志,允许 NiFi 自动恢复流文件,然后停止 NiFi 并更改配置以启用加密。NiFi 将自动从存储库中恢复便文本流文件,并在随后的文稿中开始加密它们。SequentialAccessWriteAheadLog``EncryptedSequentialAccessWriteAheadLog |
|
|---|---|
- 在未加密和加密存储库之间切换
- 如果用户有一个未加密(使用)的现有提前写入存储库(),并且将其配置切换到使用加密存储库,应用程序将处理此存储库,并且所有流存记录将在启动时恢复。未来的写作(包括这些相同的流文件的重新序列化)将被加密。如果用户从加密存储库切换到未加密存储库,则无法恢复流文件,建议在此方向切换之前删除现有流文件存储库。自动翻滚是未来的努力(NIFI-6994),但 NiFi 不打算长期存储流存记录, 所以影响应该很小。翻滚有两种情况:
WriteAheadFlowFileRepository``SequentialAccessWriteAheadLog- 加密→未加密 - 如果以前的存储库实现已加密,则只要可用的关键提供商仍然拥有用于加密声明的密钥,这些记录应无缝处理(参见密钥旋转))
- 未加密→加密的当前无缝处理, 但还有其他初始实现可以处理
SequentialAccessWriteAheadLog
- 今后还将努力在 NiFi 工具包中提供独立工具,以加密/解密现有的流文件存储库,使过渡更加容易。翻译过程可能需要很长时间,这取决于现有存储库的大小,能够在应用程序启动之外执行此任务将是有价值的(NIFI-6994)。
- 如果用户有一个未加密(使用)的现有提前写入存储库(),并且将其配置切换到使用加密存储库,应用程序将处理此存储库,并且所有流存记录将在启动时恢复。未来的写作(包括这些相同的流文件的重新序列化)将被加密。如果用户从加密存储库切换到未加密存储库,则无法恢复流文件,建议在此方向切换之前删除现有流文件存储库。自动翻滚是未来的努力(NIFI-6994),但 NiFi 不打算长期存储流存记录, 所以影响应该很小。翻滚有两种情况:
- 多个存储库 - 目前没有对多个存储库进行额外的努力或测试。流文件存储库的当前实现仅允许一个存储库,尽管它可以存储多个卷和分区。不同物理设备上的存储库可能会/可能发生问题。没有选择提供异质环境(即一个加密的、一个便秘的分区/目录)。
- 腐败 - 当磁盘被填充或损坏时,有报道称存储库会损坏,并且需要采取恢复步骤。这可能继续是加密存储库的问题,尽管范围仍然局限于单个记录(即由于加密,整个存储库文件无法恢复)。NiFi 的继续运行非常重要,以确保存储流文件存储库的磁盘不会耗尽可用空间。
实验警告
虽然所有阿帕奇许可代码都提供"在"AS IS"的基础上,没有保证或任何种类的条件,无论是明示或暗示"(见阿帕奇许可证,版本2.0),阿帕奇NiFi的一些功能可以标记实验。实验功能可能:
- 已进行了比标准 NiFi 功能更不广泛的测试
- 与不稳定的外部依赖相互作用
- 受更改(任何暴露的 API不应被视为语义版本的次要释放向后兼容性准则所涵盖))
- 可能导致数据丢失
- 一遇问题,社区不直接支持
每一次尝试都试图提供关于每个功能的实验警告性质的更详细和具体的信息。围绕特定实验功能的问题应直接到阿帕奇NIFI开发人员邮件列表。
其他管理功能
除了摘要页面、数据证明页面、模板管理页面和公告板页面之外,全球菜单中还有其他工具(参见NiFi 用户界面),这些工具对 DFM 有用。选择流配置历史记录以查看对数据流所做的所有更改。历史记录可以帮助故障排除,例如,如果最近对数据流的更改导致问题,需要修复。DFM 可以看到已做出哪些更改,并根据需要调整流量以解决问题。虽然 NiFi 没有"撤消"功能,但 DFM 可以对数据流进行新的更改,以解决问题。
选择节点状态历史记录来查看过去 24 小时内的实例特定指标,或者如果实例运行的时间较短,则自该状态开始运行以来。状态历史记录可以帮助 DFM 排除性能问题,并提供节点健康状况的一般视图。状态历史记录包括有关内存使用和磁盘使用等信息。
全球菜单中的另外两个工具是控制器设置和用户。控制器设置页面提供更改 NiFi 实例名称、添加描述 NiFi 实例的评论以及设置应用程序可用的最大线程数的功能。它还提供选项卡,其中DFM可以添加和配置控制器服务和报告任务。用户页面用于管理用户访问,系统管理员指南中对此进行了描述。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/%E5%A4%A7%E6%95%B0%E6%8D%AE/Nifi-Apache-Nifi-%E5%9F%BA%E7%A1%80%E6%8C%87%E5%8D%97%E5%A4%A7%E5%85%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


