BI-ETL-开始使用Apache Airflow
概述
- 了解Apache Airflow及其部件的需求
- 我们将创建我们的第一个 DAG 获得现场板球得分使用Apache Airflow
介绍
工作自动化在任何行业都发挥着关键作用,是实现功能效率的最快方法之一。但是,我们中的许多人不知道如何自动化一些任务,并结束在手动做同样的事情一次又一次的循环。

我们大多数人必须处理不同的工作流程,如从多个数据库收集数据、预处理数据、上传数据并报告数据。因此,如果我们的日常任务只是自动触发定义的时间,并且所有流程都按顺序执行,那将是伟大的。Apache Airflow是一个这样的工具,可以非常有帮助你。无论您是数据科学家、数据工程师还是软件工程师,您一定会发现此工具很有用。
在本文中,我们将讨论Apache Airflow,如何安装它,我们将创建一个示例工作流,并在 Python 中编码它。
内容表
- 什么是Apache Airflow?
- Apache Airflow的特点
- 安装步骤
- Apache Airflow的组件
- 网络服务器
- 调度
- 执行者
- 元基础
- 用户界面
- 定义您的第一个 DAG
- 结束笔记
什么是Apache Airflow?
Apache 气流是一种工作流引擎,可以轻松地安排和运行复杂的数据管道。它将确保数据管线的每个任务将按正确的顺序执行,并且每个任务都获得所需的资源。
它将为您提供一个惊人的用户界面,以监控和修复任何可能出现的问题。

Apache Airflow的特点
- 易于使用:如果你有一点点蛇的知识,你是很好的去部署在气流。
- 开源:它是免费和开放的来源与许多活跃的用户。
- 强大的集成:它将为您提供随时使用运营商,以便您可以与谷歌云平台,亚马逊 AWS,微软 Azure 等合作。
- 使用标准 Python 编码:您可以使用巨蛇创建简单到复杂的工作流程,具有完全的灵活性。
- 惊人的用户界面:您可以监控和管理工作流程。它将允许您检查已完成和正在进行的任务的状态。
安装步骤
让我们从安装Apache Airflow开始。现在,如果系统中已经安装了点,您可以跳过第一个命令。要在终端中安装 pip 运行以下命令。
sudo apt-get install python3-pip
下一个气流需要一个家在您的本地系统。默认情况下,+/气流是默认位置,但您可以根据您的要求更改它。
export AIRFLOW_HOME=~/airflow
现在,使用以下命令使用点安装气流。
pip3 install apache-airflow
气流需要一个数据库后端来运行您的工作流并维护它们。现在,要初始化数据库,可以运行以下命令。
airflow initdb
我们已经讨论过气流有一个惊人的用户界面。要启动网络服务器,在终端中运行以下命令。默认端口为 8080,如果您将该端口用于其他内容,则可以更改该端口。
airflow webserver -p 8080
现在,使用以下命令在不同的终端启动气流切分。它将一直运行,并监控您的所有工作流程,并按您已分配的触发它们。
airflow scheduler
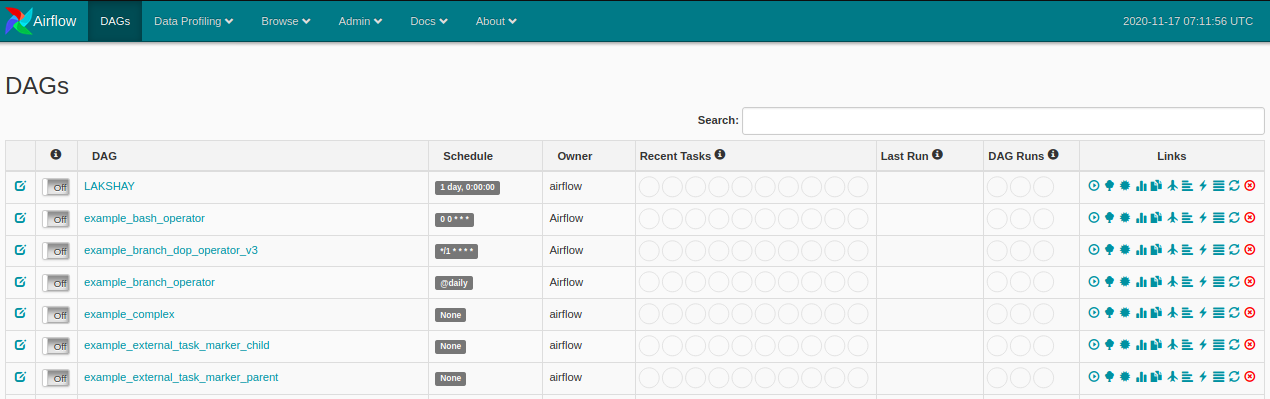
现在,在气流目录中创建一个文件夹名称 dags,在那里您将定义工作流或 DAG 并打开 Web 浏览器并打开:http://localhost:8080/admin/,您将看到类似的东西:
Apache Airflow的组件
- DAG:这是定向循环图 - 您想要运行的所有任务的集合,这是有组织的,并显示不同任务之间的关系。它以巨蛇脚本定义。
- 网络服务器:它是建立在火焰上的用户界面。它允许我们监控 DAG 的状态并触发它们。
- 元数据数据库:气流存储数据库中所有任务的状态,并从这里执行工作流的所有读写操作。
- 调度器:顾名思义,此组件负责安排 DAG 的执行。它检索并更新数据库中任务的状态。
用户界面
现在,您已经安装了气流,让我们快速概述用户界面的某些组件。
DAGS 视图
它是用户界面的默认视图。这将列出系统中的所有 DAGS。它将为您提供 DAGS 的总结视图,如特定 DAG 成功运行的次数、失败次数、上次执行时间以及其他一些有用的链接。

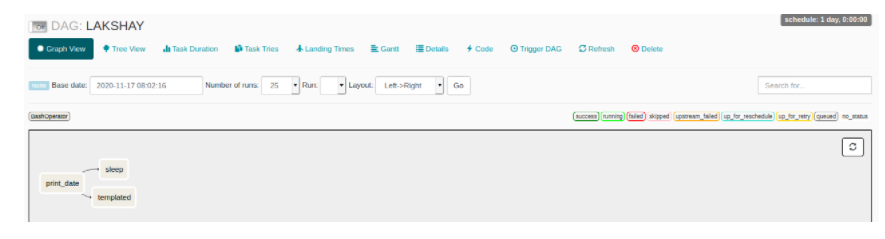
图形视图
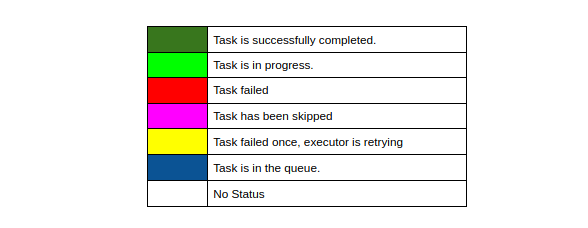
在图形视图中,您可以将工作流程的每一步都与它们的依赖性和当前状态进行可视化。您可以用不同的颜色代码(如:
树景
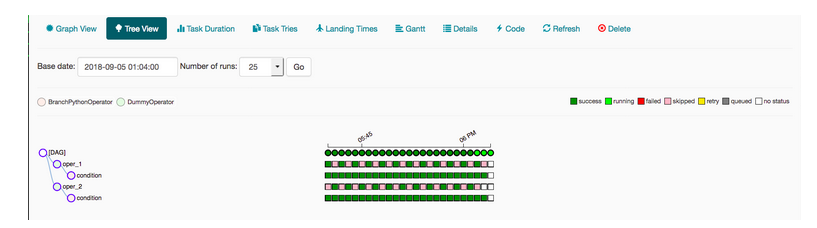
树景也代表 DAG。如果您认为您的管道执行时间比预期的要长,那么您可以检查哪个部分需要很长时间才能执行,然后就可以执行它。
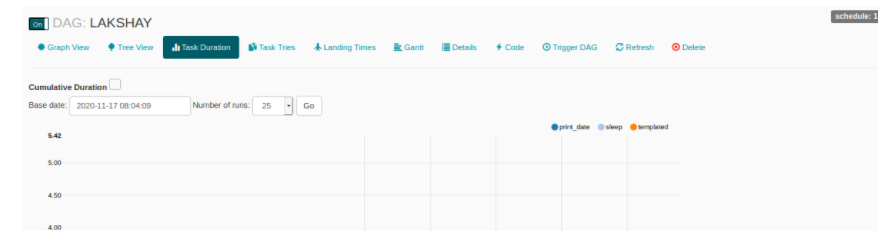
任务期限
在此视图中,您可以比较不同时间间隔运行任务的持续时间。您可以优化算法并在此处比较您的性能。
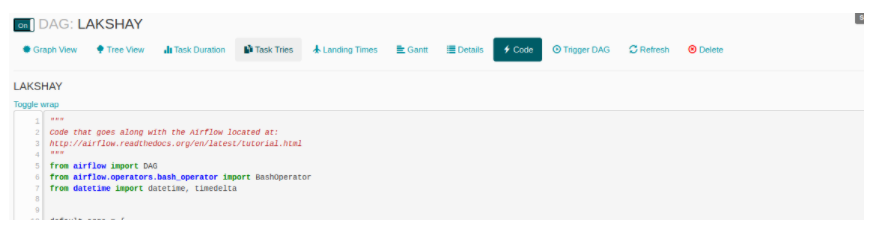
法典
在此视图中,您可以快速查看用于生成 DAG 的代码。
定义您的第一个 DAG
让我们开始并定义我们的第一个 DAG。
在此部分中,我们将创建一个工作流,其中第一步将在终端上打印”获取实时板球分数”,然后使用 API,我们将在终端上打印实时分数。让我们先测试 API,为此,您需要使用以下命令安装板球 - cli库。
sudo pip3 install cricket-cli
现在,运行以下命令并获取分数。
cricket scores
根据您的互联网连接,可能需要几秒钟的时间,并将返回您的输出类似的东西:
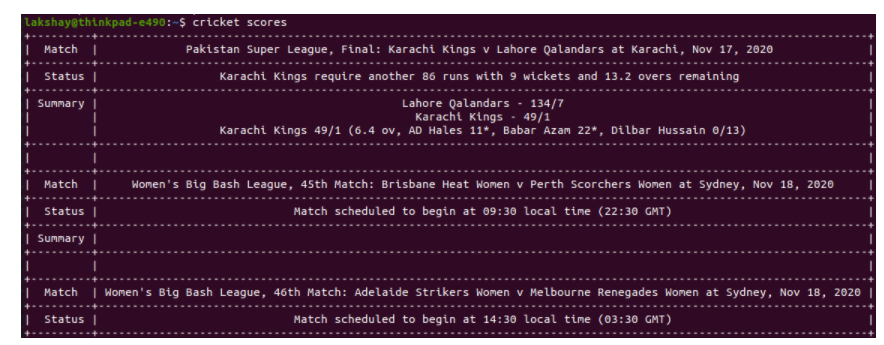
导入图书馆
现在,我们将使用Apache Airflow创建相同的工作流。代码将完全在巨蛇中定义 DAG。让我们从导入我们需要的图书馆开始。我们将只使用巴什操作器,因为我们的工作流程要求 Bash 操作仅运行。
from datetime import timedelta
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate!
from airflow.operators.bash_operator import BashOperator
from airflow.utils.dates import days_ago
定义 DAG 参数
对于每个 DAG,我们需要通过一个参数字典。以下是您可以通过的一些参数的描述:
- 所有者:工作流程所有者的名称,应为字母数字,可以具有下划线,但不应包含任何空格。
- depends_on_past:如果每次运行工作流程时,数据取决于过去的运行情况,则将其标记为”真实”,否则将其标记为”错误”。
- start_date: 工作流程的开始日期
- 电子邮件: 您的电子邮件 ID, 以便您可以收到电子邮件, 每当任何任务因任何原因失败。
retry_delay:如果任何任务失败,那么需要多少时间等待重新尝试。
# You can override them on a per-task basis during operator initialization default_args = { 'owner': 'lakshay', 'depends_on_past': False, 'start_date': days_ago(2), 'email': ['airflow@example.com'], 'email_on_failure': False, 'email_on_retry': False, 'retries': 1, 'retry_delay': timedelta(minutes=5), # 'queue': 'bash_queue', # 'pool': 'backfill', # 'priority_weight': 10, # 'end_date': datetime(2016, 1, 1), # 'wait_for_downstream': False, # 'dag': dag, # 'sla': timedelta(hours=2), # 'execution_timeout': timedelta(seconds=300), # 'on_failure_callback': some_function, # 'on_success_callback': some_other_function, # 'on_retry_callback': another_function, # 'sla_miss_callback': yet_another_function, # 'trigger_rule': 'all_success' }
定义 DAG
现在,我们将创建一个 DAG 对象并通过dag_id这是 DAG 的名称,它应该是独一无二的。传递我们在最后一步中定义的参数,并添加描述和schedule_interval将在指定的时间间隔后运行 DAG
# define the DAG
dag = DAG(
'live_cricket_scores',
default_args=default_args,
description='First example to get Live Cricket Scores',
schedule_interval=timedelta(days=1),
)
定义任务
我们将有两个任务,我们的工作流程:
- 打印:在第一个任务中,我们将使用回声命令在终端上打印”获取实时板球分数!!!“。
- get_cricket_scores:在第二项任务中,我们将使用我们安装的库打印实时板球分数。
现在,在首先定义任务的同时,我们需要为任务选择合适的操作员。在这里,两个命令都是基于终端的,所以我们将使用BashOperator。
我们将通过task_id这是任务的独特标识符,您将在 DAG 的图形视图节点上看到此名称。通过要运行的 bash 命令,最后传递要链接此任务的 DAG 对象。
最后,通过在任务之间添加”>>”操作员来创建管道。
# define the first task
t1 = BashOperator(
task_id='print',
bash_command='echo Getting Live Cricket Scores!!!',
dag=dag,
)
# define the second task
t2 = BashOperator(
task_id='get_cricket_scores',
bash_command='cricket scores',
dag=dag,
)
# task pipeline
t1 >> t2
更新 Web UI 中的 DAGS
现在,刷新用户界面,您将在列表中看到您的 DAG。打开每个 DAG 左侧的切换,然后触发 DAG。

单击 DAG 并打开图形视图,您将看到类似的东西。工作流程中的每一个步骤都将放在一个单独的框中,一旦成功完成,其边框将变成深绿色。
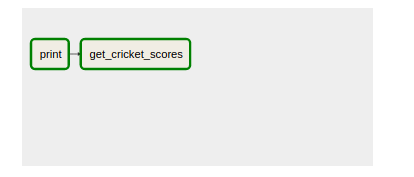
单击节点”get_cricket分数”以获取有关此步骤的更多详细信息。你会看到这样的事情。
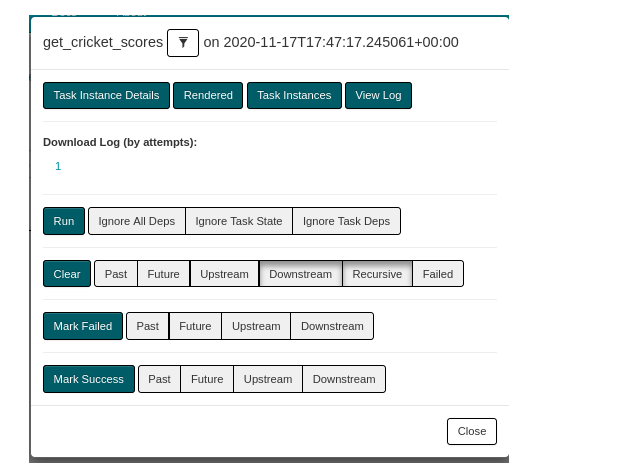
现在,单击”查看日志”以查看代码的输出。
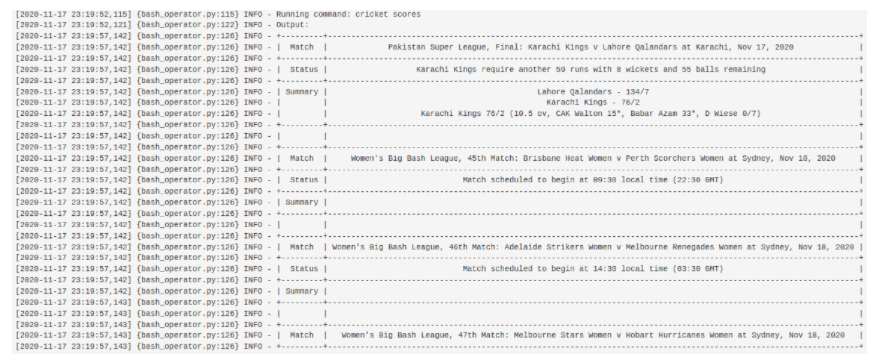
就是这样。您已在Apache Airflow中成功创建了您的第一个 DAG。
结束笔记
在本文中,我们看到了Apache Airflow的特点,其用户界面组件,我们创建了一个简单的DAG。在即将发表的文章中,我们将讨论一些更多概念,如变量、分支,并将创建一个更复杂的工作流程。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/BI-ETL-%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B-101-%E5%BC%80%E5%A7%8B%E4%BD%BF%E7%94%A8Apache-Airflow/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


