Flink系列-第01讲:Flink 的应用场景和架构模型
你好,欢迎来到第 01 课时,本课时我们主要介绍 Flink 的应用场景和架构模型。
实时计算最好的时代
在过去的十年里,面向数据时代的实时计算技术接踵而至。从我们最初认识的 Storm,再到 Spark 的异军突起,迅速占领了整个实时计算领域。直到 2019 年 1 月底,阿里巴巴内部版本 Flink 正式开源!一石激起千层浪,Flink 开源的消息立刻刷爆朋友圈,整个大数据计算领域一直以来由 Spark 独领风骚,瞬间成为两强争霸的时代。
Apache Flink(以下简称 Flink)以其先进的设计理念、强大的计算能力备受关注,如何将 Flink 快速应用在生产环境中,更好的与现有的大数据生态技术完美结合,充分挖掘数据的潜力,成为了众多开发者面临的难题。
Flink 实际应用场景
Flink 自从 2019 年初开源以来,迅速成为大数据实时计算领域炙手可热的技术框架。作为 Flink 的主要贡献者阿里巴巴率先将其在全集团进行推广使用,另外由于 Flink 天然的流式特性,更为领先的架构设计,使得 Flink 一出现便在各大公司掀起了应用的热潮。
阿里巴巴、腾讯、百度、字节跳动、滴滴、华为等众多互联网公司已经将 Flink 作为未来技术重要的发力点,迫切地在各自公司内部进行技术升级和推广使用。同时,Flink 已经成为 Apache 基金会和 GitHub 社区最为活跃的项目之一。
我们来看看 Flink 支持的众多应用场景。
实时数据计算
如果你对大数据技术有所接触,那么下面的这些需求场景你应该并不陌生:
阿里巴巴每年双十一都会直播,实时监控大屏是如何做到的?
公司想看一下大促中销量最好的商品 TOP5?
我是公司的运维,希望能实时接收到服务器的负载情况?
......

我们可以看到,数据计算场景需要从原始数据中提取有价值的信息和指标,比如上面提到的实时销售额、销量的 TOP5,以及服务器的负载情况等。
传统的分析方式通常是利用批查询,或将事件(生产上一般是消息)记录下来并基于此形成有限数据集(表)构建应用来完成。为了得到最新数据的计算结果,必须先将它们写入表中并重新执行 SQL 查询,然后将结果写入存储系统比如 MySQL 中,再生成报告。
Apache Flink 同时支持流式及批量分析应用,这就是我们所说的批流一体。Flink 在上述的需求场景中承担了数据的实时采集、实时计算和下游发送。
实时数据仓库和 ETL
ETL(Extract-Transform-Load)的目的是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程。
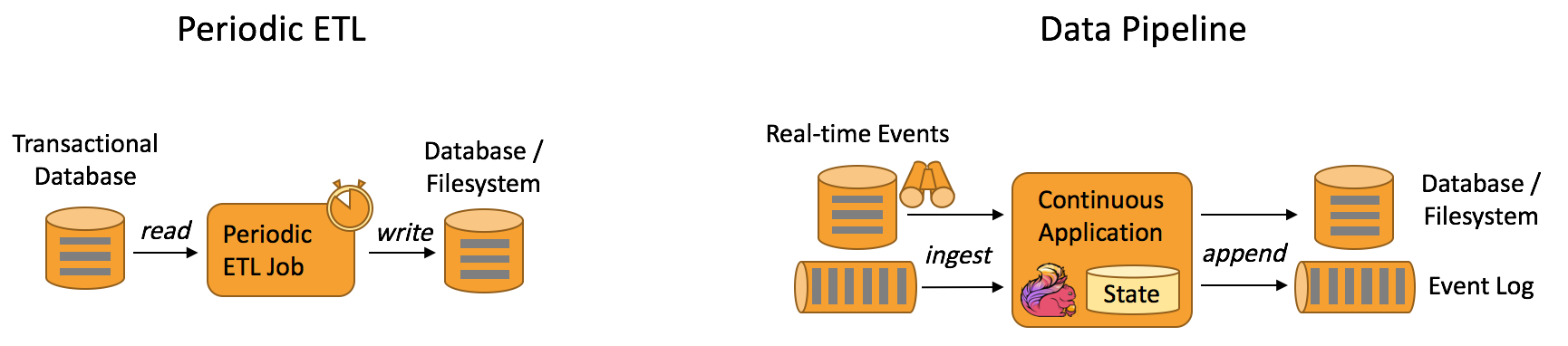
传统的离线数据仓库将业务数据集中进行存储后,以固定的计算逻辑定时进行 ETL 和其他建模后产出报表等应用。离线数据仓库主要是构建 T+1 的离线数据,通过定时任务每天拉取增量数据,然后创建各个业务相关的主题维度数据,对外提供 T+1 的数据查询接口。
上图展示了离线数据仓库 ETL 和实时数据仓库的差异,可以看到离线数据仓库的计算和数据的实时性均较差。数据本身的价值随着时间的流逝会逐步减弱,因此数据发生后必须尽快的达到用户的手中,实时数仓的构建需求也应运而生。
实时数据仓库的建设是“数据智能 BI”必不可少的一环,也是大规模数据应用中必然面临的挑战。
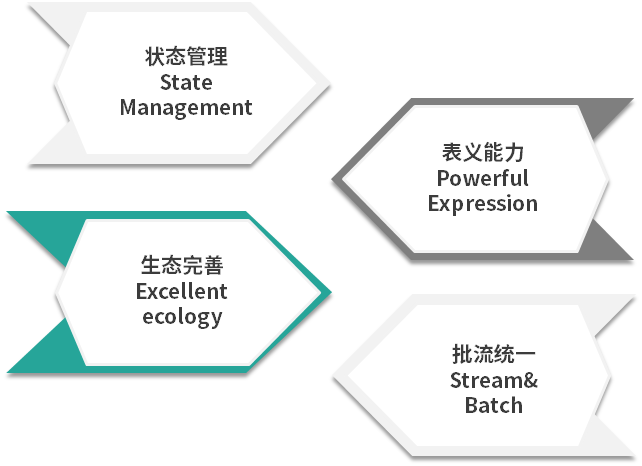
Flink 在实时数仓和实时 ETL 中有天然的优势:
状态管理,实时数仓里面会进行很多的聚合计算,这些都需要对于状态进行访问和管理,Flink 支持强大的状态管理;
丰富的 API,Flink 提供极为丰富的多层次 API,包括 Stream API、Table API 及 Flink SQL;
生态完善,实时数仓的用途广泛,Flink 支持多种存储(HDFS、ES 等);
批流一体,Flink 已经在将流计算和批计算的 API 进行统一。
事件驱动型应用
你是否有这样的需求:
我们公司有几万台服务器,希望能从服务器上报的消息中将 CPU、MEM、LOAD 信息分离出来做分析,然后触发自定义的规则进行报警?
我是公司的安全运维人员,希望能从每天的访问日志中识别爬虫程序,并且进行 IP 限制?
......
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
在传统架构中,我们需要读写远程事务型数据库,比如 MySQL。在事件驱动应用中数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据,所以具有更高的吞吐和更低的延迟。
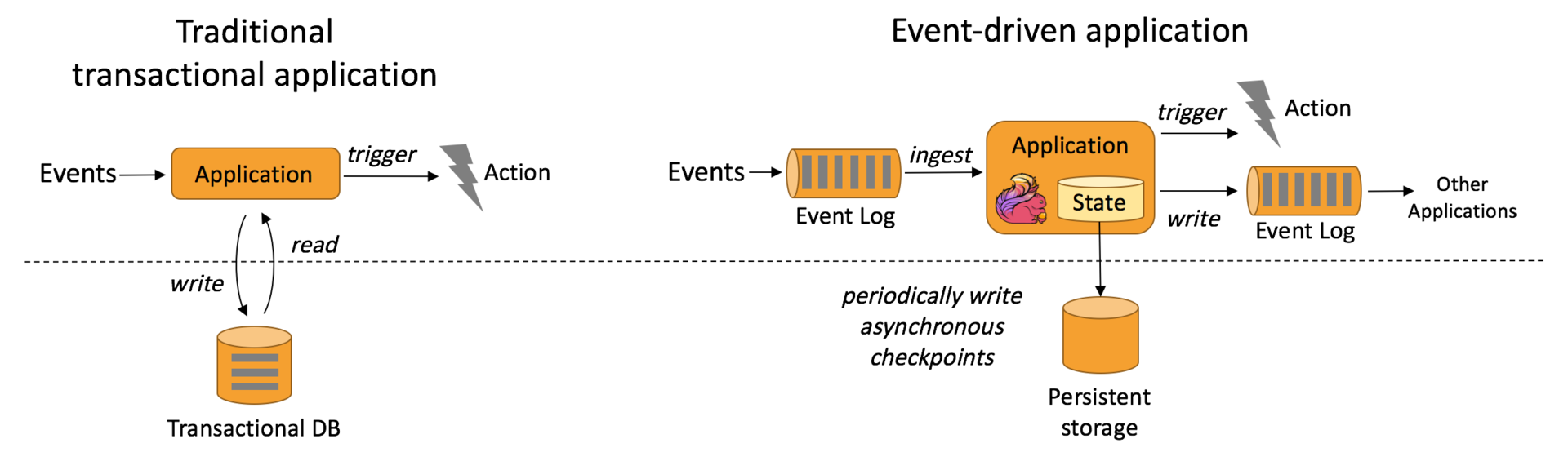
Flink 的以下特性完美的支持了事件驱动型应用:
高效的状态管理,Flink 自带的 State Backend 可以很好的存储中间状态信息;
丰富的窗口支持,Flink 支持包含滚动窗口、滑动窗口及其他窗口;
多种时间语义,Flink 支持 Event Time、Processing Time 和 Ingestion Time;
不同级别的容错,Flink 支持 At Least Once 或 Exactly Once 容错级别。
小结
Apache Flink 从底层支持了针对多种不同场景的应用开发。
Flink 的主要特性包括:批流一体、Exactly-Once、强大的状态管理等。同时,Flink 还支持运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上。阿里巴巴已经率先将 Flink 在全集团进行推广使用,事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。
因此,Flink 已经成为我们在实时计算的领域的第一选择。
Flink 的架构模型
Flink 的分层模型
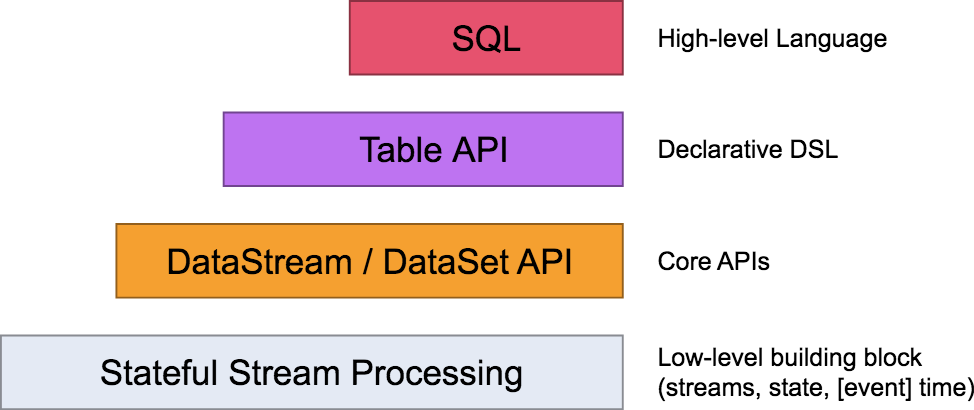
Flink 自身提供了不同级别的抽象来支持我们开发流式或者批量处理程序,上图描述了 Flink 支持的 4 种不同级别的抽象。
对于我们开发者来说,大多数应用程序不需要上图中的最低级别的 Low-level 抽象,而是针对 Core API 编程, 比如 DataStream API(有界/无界流)和 DataSet API (有界数据集)。这些流畅的 API 提供了用于数据处理的通用构建块,比如各种形式用户指定的转换、连接、聚合、窗口、状态等。
Table API 和 SQL 是 Flink 提供的更为高级的 API 操作,Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
Flink 的数据流模型
Flink 程序的基础构建模块是流(Streams)与转换(Transformations),每一个数据流起始于一个或多个 Source,并终止于一个或多个 Sink。数据流类似于有向无环图(DAG)。
我们以一个最经典的 WordCount 计数程序举例:
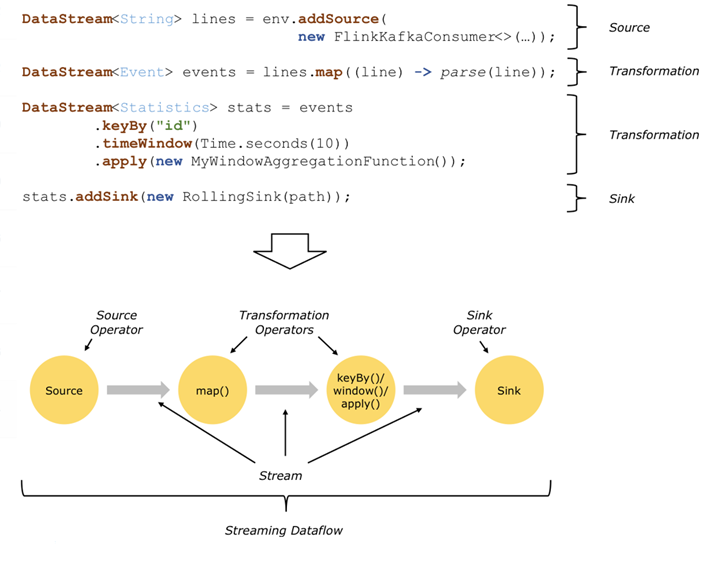
在上图中,程序消费 Kafka 数据,这便是我们的 Source 部分。
然后经过 Map、Keyby、TimeWindow 等方法进行逻辑计算,该部分就是我们的 Transformation 转换部分,而其中的 Map、Keyby、TimeWindow 等方法被称为算子。通常,程序中的转换与数据流中的算子之间存在对应关系,有时一个转换可能包含多个转换算子。
最后,经过计算的数据会被写入到我们执行的文件中,这便是我们的 Sink 部分。
实际上面对复杂的生产环境,Flink 任务大都是并行进行和分布在各个计算节点上。在 Flink 任务执行期间,每一个数据流都会有多个分区,并且每个算子都有多个算子任务并行进行。算子子任务的数量是该特定算子的并行度(Parallelism),对并行度的设置是 Flink 任务进行调优的重要手段,我们会在后面的课程中详细讲解。
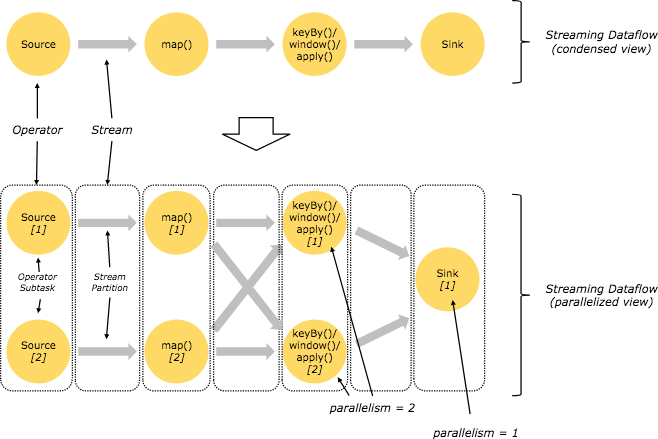
从上图中可以看到,在上面的 map 和 keyBy/window 之间,以及 keyBy/window 和 Sink 之间,因为并行度的差异,数据流都进行了重新分配。
Flink 中的窗口和时间
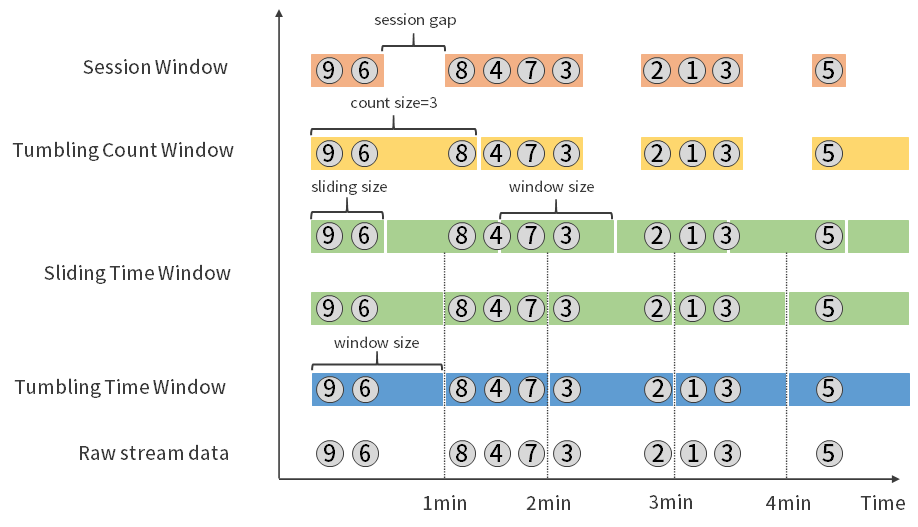
窗口和时间是 Flink 中的核心概念之一。在实际成产环境中,对数据流上的聚合需要由窗口来划定范围,比如“计算过去的 5 分钟”或者“最后 100 个元素的和”。
Flink 支持了多种窗口模型比如滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)及会话窗口(Session Window)等。
下图展示了 Flink 支持的多种窗口模型:
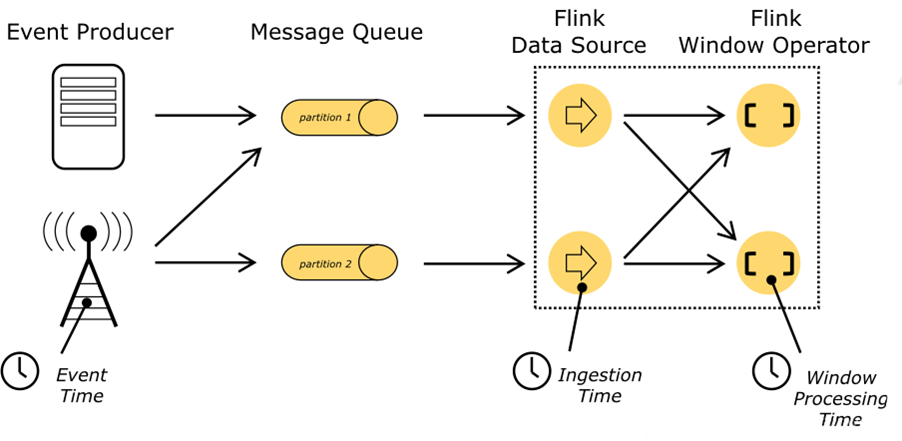
同时,Flink 支持了事件时间(Event Time)、摄取时间(Ingestion Time)和处理时间(Processing Time)三种时间语义用来满足实际生产中对于时间的特殊需求。
其他
此外,Flink 自身还支持了有状态的算子操作、容错机制、Checkpoint、Exactly-once 语义等更多高级特性,来支持用户在不同的业务场景中的需求。
总结
本课时从实时计算的背景入手介绍了当前实时计算的发展历程,Flink 作为实时计算领域的一匹黑马,先进的设计思想、强大的性能和丰富的业务场景支持,已经是我们开发者必须要学习的技能之一,Flink 已经成为实时计算领域最锋利的武器!
精选评论
**雄:
从今天开始学flink 迟来1年后的缘分
编辑回复:
加油喔~
*龙:
flink cdc解决了好多疑难场景
**威:
FlinkX冲
*铮:
让我们一起学习flink
**保:
flink真的是大数据生态圈的万金油产品,做数据采集,做数据分析都可以
**1985:
实时数仓已成为很多组织的刚性需求
*布:
老师,后面有讲平台建设吗?最近准备动手,有好的方案借鉴吗😀
讲师回复:
实战案例有
*凯:
期待实战
你好,欢迎来到第 01 课时,本课时我们主要介绍 Flink 的应用场景和架构模型。
实时计算最好的时代
在过去的十年里,面向数据时代的实时计算技术接踵而至。从我们最初认识的 Storm,再到 Spark 的异军突起,迅速占领了整个实时计算领域。直到 2019 年 1 月底,阿里巴巴内部版本 Flink 正式开源!一石激起千层浪,Flink 开源的消息立刻刷爆朋友圈,整个大数据计算领域一直以来由 Spark 独领风骚,瞬间成为两强争霸的时代。
Apache Flink(以下简称 Flink)以其先进的设计理念、强大的计算能力备受关注,如何将 Flink 快速应用在生产环境中,更好的与现有的大数据生态技术完美结合,充分挖掘数据的潜力,成为了众多开发者面临的难题。
Flink 实际应用场景
Flink 自从 2019 年初开源以来,迅速成为大数据实时计算领域炙手可热的技术框架。作为 Flink 的主要贡献者阿里巴巴率先将其在全集团进行推广使用,另外由于 Flink 天然的流式特性,更为领先的架构设计,使得 Flink 一出现便在各大公司掀起了应用的热潮。
阿里巴巴、腾讯、百度、字节跳动、滴滴、华为等众多互联网公司已经将 Flink 作为未来技术重要的发力点,迫切地在各自公司内部进行技术升级和推广使用。同时,Flink 已经成为 Apache 基金会和 GitHub 社区最为活跃的项目之一。
我们来看看 Flink 支持的众多应用场景。
实时数据计算
如果你对大数据技术有所接触,那么下面的这些需求场景你应该并不陌生:
阿里巴巴每年双十一都会直播,实时监控大屏是如何做到的?
公司想看一下大促中销量最好的商品 TOP5?
我是公司的运维,希望能实时接收到服务器的负载情况?
......
我们可以看到,数据计算场景需要从原始数据中提取有价值的信息和指标,比如上面提到的实时销售额、销量的 TOP5,以及服务器的负载情况等。
传统的分析方式通常是利用批查询,或将事件(生产上一般是消息)记录下来并基于此形成有限数据集(表)构建应用来完成。为了得到最新数据的计算结果,必须先将它们写入表中并重新执行 SQL 查询,然后将结果写入存储系统比如 MySQL 中,再生成报告。
Apache Flink 同时支持流式及批量分析应用,这就是我们所说的批流一体。Flink 在上述的需求场景中承担了数据的实时采集、实时计算和下游发送。
实时数据仓库和 ETL
ETL(Extract-Transform-Load)的目的是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程。
传统的离线数据仓库将业务数据集中进行存储后,以固定的计算逻辑定时进行 ETL 和其他建模后产出报表等应用。离线数据仓库主要是构建 T+1 的离线数据,通过定时任务每天拉取增量数据,然后创建各个业务相关的主题维度数据,对外提供 T+1 的数据查询接口。
上图展示了离线数据仓库 ETL 和实时数据仓库的差异,可以看到离线数据仓库的计算和数据的实时性均较差。数据本身的价值随着时间的流逝会逐步减弱,因此数据发生后必须尽快的达到用户的手中,实时数仓的构建需求也应运而生。
实时数据仓库的建设是“数据智能 BI”必不可少的一环,也是大规模数据应用中必然面临的挑战。
Flink 在实时数仓和实时 ETL 中有天然的优势:
状态管理,实时数仓里面会进行很多的聚合计算,这些都需要对于状态进行访问和管理,Flink 支持强大的状态管理;
丰富的 API,Flink 提供极为丰富的多层次 API,包括 Stream API、Table API 及 Flink SQL;
生态完善,实时数仓的用途广泛,Flink 支持多种存储(HDFS、ES 等);
批流一体,Flink 已经在将流计算和批计算的 API 进行统一。
事件驱动型应用
你是否有这样的需求:
我们公司有几万台服务器,希望能从服务器上报的消息中将 CPU、MEM、LOAD 信息分离出来做分析,然后触发自定义的规则进行报警?
我是公司的安全运维人员,希望能从每天的访问日志中识别爬虫程序,并且进行 IP 限制?
......
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
在传统架构中,我们需要读写远程事务型数据库,比如 MySQL。在事件驱动应用中数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据,所以具有更高的吞吐和更低的延迟。
Flink 的以下特性完美的支持了事件驱动型应用:
高效的状态管理,Flink 自带的 State Backend 可以很好的存储中间状态信息;
丰富的窗口支持,Flink 支持包含滚动窗口、滑动窗口及其他窗口;
多种时间语义,Flink 支持 Event Time、Processing Time 和 Ingestion Time;
不同级别的容错,Flink 支持 At Least Once 或 Exactly Once 容错级别。
小结
Apache Flink 从底层支持了针对多种不同场景的应用开发。
Flink 的主要特性包括:批流一体、Exactly-Once、强大的状态管理等。同时,Flink 还支持运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上。阿里巴巴已经率先将 Flink 在全集团进行推广使用,事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。
因此,Flink 已经成为我们在实时计算的领域的第一选择。
Flink 的架构模型
Flink 的分层模型
Flink 自身提供了不同级别的抽象来支持我们开发流式或者批量处理程序,上图描述了 Flink 支持的 4 种不同级别的抽象。
对于我们开发者来说,大多数应用程序不需要上图中的最低级别的 Low-level 抽象,而是针对 Core API 编程, 比如 DataStream API(有界/无界流)和 DataSet API (有界数据集)。这些流畅的 API 提供了用于数据处理的通用构建块,比如各种形式用户指定的转换、连接、聚合、窗口、状态等。
Table API 和 SQL 是 Flink 提供的更为高级的 API 操作,Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
Flink 的数据流模型
Flink 程序的基础构建模块是流(Streams)与转换(Transformations),每一个数据流起始于一个或多个 Source,并终止于一个或多个 Sink。数据流类似于有向无环图(DAG)。
我们以一个最经典的 WordCount 计数程序举例:
在上图中,程序消费 Kafka 数据,这便是我们的 Source 部分。
然后经过 Map、Keyby、TimeWindow 等方法进行逻辑计算,该部分就是我们的 Transformation 转换部分,而其中的 Map、Keyby、TimeWindow 等方法被称为算子。通常,程序中的转换与数据流中的算子之间存在对应关系,有时一个转换可能包含多个转换算子。
最后,经过计算的数据会被写入到我们执行的文件中,这便是我们的 Sink 部分。
实际上面对复杂的生产环境,Flink 任务大都是并行进行和分布在各个计算节点上。在 Flink 任务执行期间,每一个数据流都会有多个分区,并且每个算子都有多个算子任务并行进行。算子子任务的数量是该特定算子的并行度(Parallelism),对并行度的设置是 Flink 任务进行调优的重要手段,我们会在后面的课程中详细讲解。
从上图中可以看到,在上面的 map 和 keyBy/window 之间,以及 keyBy/window 和 Sink 之间,因为并行度的差异,数据流都进行了重新分配。
Flink 中的窗口和时间
窗口和时间是 Flink 中的核心概念之一。在实际成产环境中,对数据流上的聚合需要由窗口来划定范围,比如“计算过去的 5 分钟”或者“最后 100 个元素的和”。
Flink 支持了多种窗口模型比如滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)及会话窗口(Session Window)等。
下图展示了 Flink 支持的多种窗口模型:
同时,Flink 支持了事件时间(Event Time)、摄取时间(Ingestion Time)和处理时间(Processing Time)三种时间语义用来满足实际生产中对于时间的特殊需求。
其他
此外,Flink 自身还支持了有状态的算子操作、容错机制、Checkpoint、Exactly-once 语义等更多高级特性,来支持用户在不同的业务场景中的需求。
总结
本课时从实时计算的背景入手介绍了当前实时计算的发展历程,Flink 作为实时计算领域的一匹黑马,先进的设计思想、强大的性能和丰富的业务场景支持,已经是我们开发者必须要学习的技能之一,Flink 已经成为实时计算领域最锋利的武器!
精选评论
**雄:
从今天开始学flink 迟来1年后的缘分
编辑回复:
加油喔~
*龙:
flink cdc解决了好多疑难场景
**威:
FlinkX冲
*铮:
让我们一起学习flink
**保:
flink真的是大数据生态圈的万金油产品,做数据采集,做数据分析都可以
**1985:
实时数仓已成为很多组织的刚性需求
*布:
老师,后面有讲平台建设吗?最近准备动手,有好的方案借鉴吗😀
讲师回复:
实战案例有
*凯:
期待实战
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2036-%E7%AC%AC01%E8%AE%B2Flink-%E7%9A%84%E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF%E5%92%8C%E6%9E%B6%E6%9E%84%E6%A8%A1%E5%9E%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


