Flink系列-第02讲:Flink 入门程序 WordCount 和 SQL 实现
本课时我们主要介绍 Flink 的入门程序以及 SQL 形式的实现。
上一课时已经讲解了 Flink 的常用应用场景和架构模型设计,这一课时我们将会从一个最简单的 WordCount 案例作为切入点,并且同时使用 SQL 方式进行实现,为后面的实战课程打好基础。
我们首先会从环境搭建入手,介绍如何搭建本地调试环境的脚手架;然后分别从DataSet(批处理)和 DataStream(流处理)两种方式如何进行单词计数开发;最后介绍 Flink Table 和 SQL 的使用。
Flink 开发环境
通常来讲,任何一门大数据框架在实际生产环境中都是以集群的形式运行,而我们调试代码大多数会在本地搭建一个模板工程,Flink 也不例外。
Flink 一个以 Java 及 Scala 作为开发语言的开源大数据项目,通常我们推荐使用 Java 来作为开发语言,Maven 作为编译和包管理工具进行项目构建和编译。对于大多数开发者而言,JDK、Maven 和 Git 这三个开发工具是必不可少的。
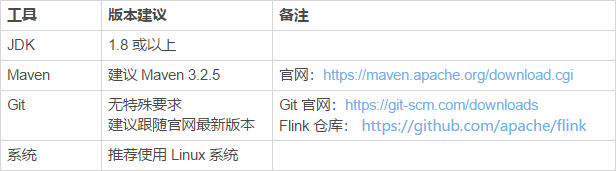
关于 JDK、Maven 和 Git 的安装建议如下表所示:
工程创建
一般来说,我们在通过 IDE 创建工程,可以自己新建工程,添加 Maven 依赖,或者直接用 mvn 命令创建应用:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.10.0
通过指定 Maven 工程的三要素,即 GroupId、ArtifactId、Version 来创建一个新的工程。同时 Flink 给我提供了更为方便的创建 Flink 工程的方法:
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.10.0
我们在终端直接执行该命令:
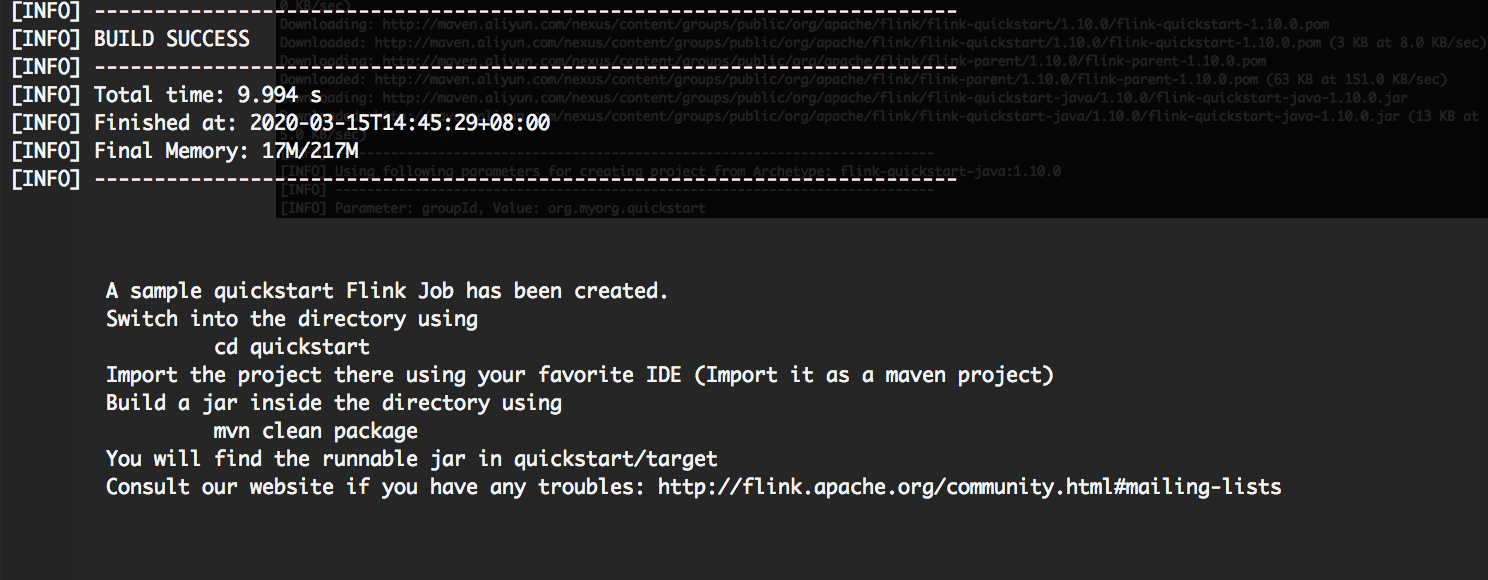
直接出现 Build Success 信息,我们可以在本地目录看到一个已经生成好的名为 quickstart 的工程。
这里需要的主要的是,自动生成的项目 pom.xml 文件中对于 Flink 的依赖注释掉 scope:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
DataSet WordCount
WordCount 程序是大数据处理框架的入门程序,俗称“单词计数”。用来统计一段文字每个单词的出现次数,该程序主要分为两个部分:一部分是将文字拆分成单词;另一部分是单词进行分组计数并打印输出结果。
整体代码实现如下:
public static void main(String[] args) throws Exception {
// 创建Flink运行的上下文环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 创建DataSet,这里我们的输入是一行一行的文本
DataSet<String> text = env.fromElements(
“Flink Spark Storm”,
“Flink Flink Flink”,
“Spark Spark Spark”,
“Storm Storm Storm”
);
// 通过Flink内置的转换函数进行计算
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
//结果打印
counts.printToErr();
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// 将文本分割
String[] tokens = value.toLowerCase().split("\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
实现的整个过程中分为以下几个步骤。
首先,我们需要创建 Flink 的上下文运行环境:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
然后,使用 fromElements 函数创建一个 DataSet 对象,该对象中包含了我们的输入,使用 FlatMap、GroupBy、SUM 函数进行转换。
最后,直接在控制台打印输出。
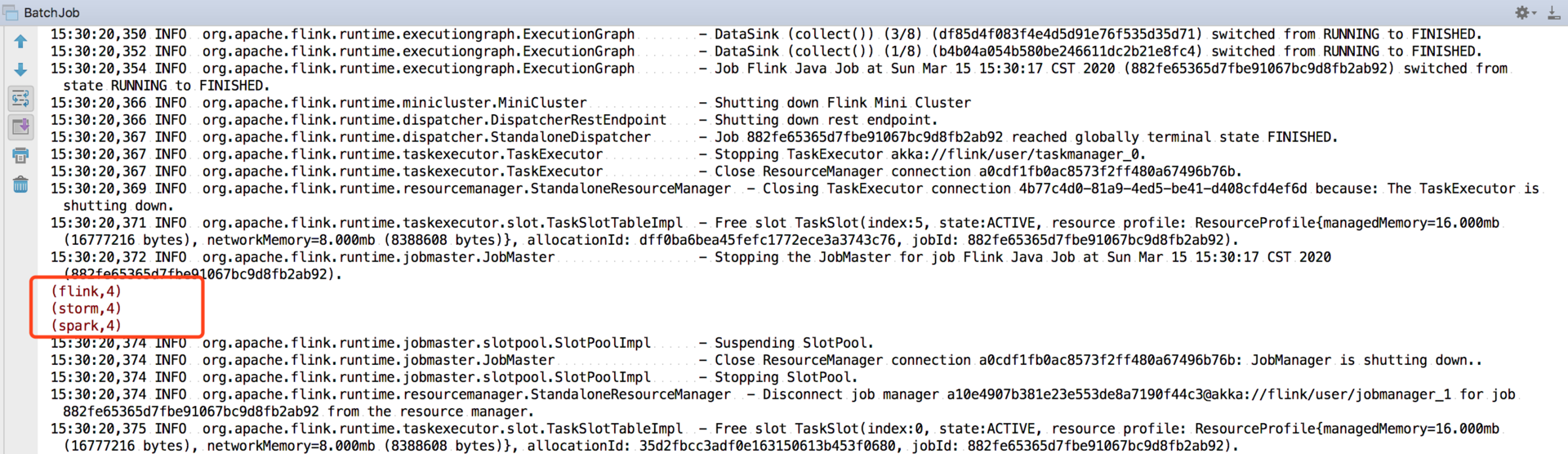
我们可以直接右键运行一下 main 方法,在控制台会出现我们打印的计算结果:
DataStream WordCount
为了模仿一个流式计算环境,我们选择监听一个本地的 Socket 端口,并且使用 Flink 中的滚动窗口,每 5 秒打印一次计算结果。代码如下:
public class StreamingJob {
public static void main(String[] args) throws Exception {
// 创建Flink的流式计算环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 监听本地9000端口
DataStream<String> text = env.socketTextStream(“127.0.0.1”, 9000, "\n");
// 将接收的数据进行拆分,分组,窗口计算并且进行聚合输出
DataStream<WordWithCount> windowCounts = text
.flatMap(new FlatMapFunction<String, WordWithCount>() {
@Override
public void flatMap(String value, Collector<WordWithCount> out) {
for (String word : value.split("\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy(“word”)
.timeWindow(Time.seconds(5), Time.seconds(1))
.reduce(new ReduceFunction<WordWithCount>() {
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount b) {
return new WordWithCount(a.word, a.count + b.count);
}
});
// 打印结果
windowCounts.print().setParallelism(1);
env.execute(“Socket Window WordCount”);
}
// Data type for words with count
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return word + " : " + count;
}
}
}
整个流式计算的过程分为以下几步。
首先创建一个流式计算环境:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
然后进行监听本地 9000 端口,将接收的数据进行拆分、分组、窗口计算并且进行聚合输出。代码中使用了 Flink 的窗口函数,我们在后面的课程中将详细讲解。
我们在本地使用 netcat 命令启动一个端口:
nc -lk 9000
然后直接运行我们的 main 方法:
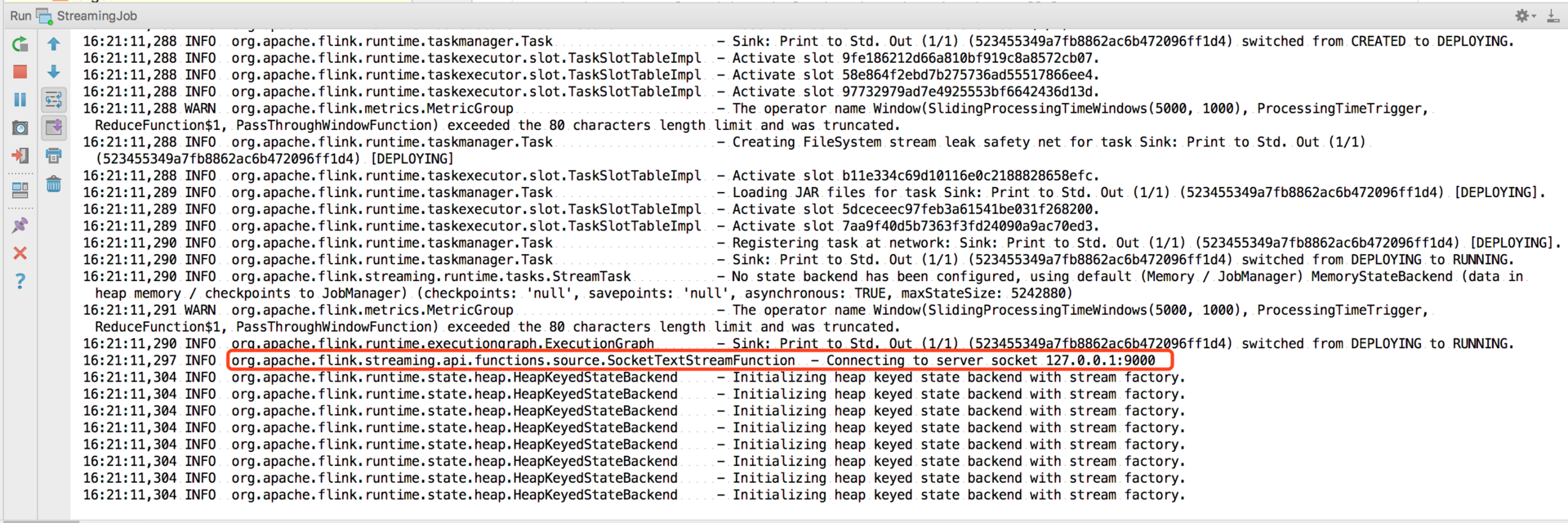
可以看到,工程启动后开始监听 127.0.0.1 的 9000 端口。
在 nc 中输入:
$ nc -lk 9000
Flink Flink Flink
Flink Spark Storm
可以在控制台看到:
Flink : 4
Spark : 1
Storm : 1
Flink Table & SQL WordCount
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
一个完整的 Flink SQL 编写的程序包括如下三部分。
- Source Operator:是对外部数据源的抽象, 目前 Apache Flink 内置了很多常用的数据源实现,比如 MySQL、Kafka 等。
- Transformation Operators:算子操作主要完成比如查询、聚合操作等,目前 Flink SQL 支持了 Union、Join、Projection、Difference、Intersection 及 window 等大多数传统数据库支持的操作。
- Sink Operator:是对外结果表的抽象,目前 Apache Flink 也内置了很多常用的结果表的抽象,比如 Kafka Sink 等。
我们也是通过用一个最经典的 WordCount 程序作为入门,上面已经通过 DataSet/DataStream API 开发,那么实现同样的 WordCount 功能, Flink Table & SQL 核心只需要一行代码:
//省略掉初始化环境等公共代码
SELECT word, COUNT(word) FROM table GROUP BY word;
首先,整个工程中我们 pom 中的依赖如下图所示:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.10.0</version>
</dependency>
第一步,创建上下文环境:
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
第二步,读取一行模拟数据作为输入:
String words = "hello flink hello lagou";
String[] split = words.split("\\W+");
ArrayList<WC> list = new ArrayList<>();
for(String word : split){
WC wc = new WC(word,1);
list.add(wc);
}
DataSet<WC> input = fbEnv.fromCollection(list);
第三步,注册成表,执行 SQL,然后输出:
//DataSet 转sql, 指定字段名
Table table = fbTableEnv.fromDataSet(input, "word,frequency");
table.printSchema();
//注册为一个表
fbTableEnv.createTemporaryView(“WordCount”, table);
Table table02 = fbTableEnv.sqlQuery(“select word as word, sum(frequency) as frequency from WordCount GROUP BY word”);
//将表转换DataSet
DataSet<WC> ds3 = fbTableEnv.toDataSet(table02, WC.class);
ds3.printToErr();
整体代码结构如下:
public class WordCountSQL {
public static void main(String[] args) throws Exception{
//获取运行环境
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
//创建一个tableEnvironment
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
String words = “hello flink hello lagou”;
String[] split = words.split("\W+");
ArrayList<WC> list = new ArrayList<>();
for(String word : split){
WC wc = new WC(word,1);
list.add(wc);
}
DataSet<WC> input = fbEnv.fromCollection(list);
//DataSet 转sql, 指定字段名
Table table = fbTableEnv.fromDataSet(input, “word,frequency”);
table.printSchema();
//注册为一个表
fbTableEnv.createTemporaryView(“WordCount”, table);
Table table02 = fbTableEnv.sqlQuery(“select word as word, sum(frequency) as frequency from WordCount GROUP BY word”);
//将表转换DataSet
DataSet<WC> ds3 = fbTableEnv.toDataSet(table02, WC.class);
ds3.printToErr();
}
public static class WC {
public String word;
public long frequency;
public WC() {}
public WC(String word, long frequency) {
this.word = word;
this.frequency = frequency;
}
@Override
public String toString() {
return word + ", " + frequency;
}
}
}
我们直接运行该程序,在控制台可以看到输出结果:
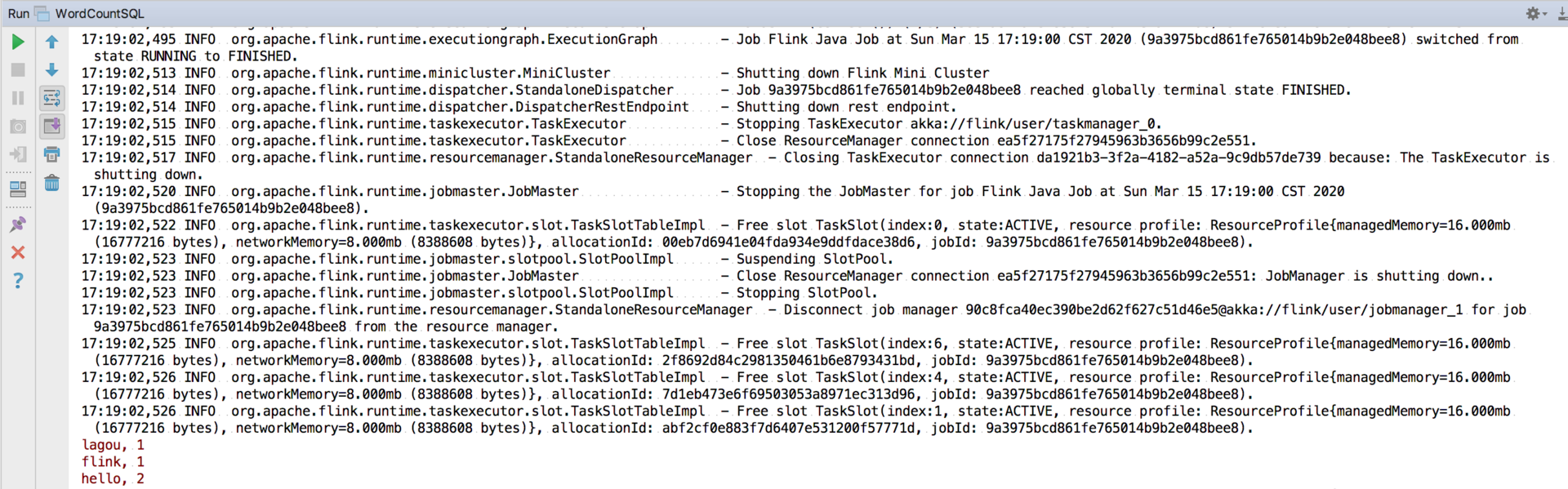
总结
本课时介绍了 Flink 的工程创建,如何搭建调试环境的脚手架,同时以 WordCount 单词计数这一最简单最经典的场景用 Flink 进行了实现。第一次体验了 Flink SQL 的强大之处,让你有一个直观的认识,为后续内容打好基础。
精选评论
**武:
课程案列会上传到Github吗
编辑回复:
会的哦,Flink 源码地址:https://github.com/wangzhiwubigdata/quickstart
**亮:
呃,还是scala代码量少啊
**1633:
感谢,之前看flink的官方文档,虽然有示例。但是由于并没有讲清楚需要依赖的jar包,所以在环境准备上遇到了不少问题。上了这节课,感觉一下子清晰多了!😀
*星:
请问python可开发大数据嘛?
讲师回复:
python不适合,python是脚本语言。在大数据场景下,多用于写一些简单的脚本。
**儒:
使用flink更推荐Java而不是Scala吗
讲师回复:
Flink绝大多数代码是Java开发,Scala是个并不成熟的语言,虽然基于JVM但是性能不稳定,只适合高端玩家。
**滨:
sql的jar包冲突是怎么回事
讲师回复:
用IDEA工具检测一下冲突的原因,可以git pull 一下最新的代码
**一:
老师,课程不是用scala讲的么?
讲师回复:
不建议用scala写flink job
**欢:
紧跟步伐学习,周末在家做一做,看一看源
**彬:
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);老师这个东西,BatchTableEnvironment我看api源码里是个接口啊,为啥有create方法呢,我在ide里没有create方法,请指教啊。
讲师回复:
注意两点, 第一:Flink版本看看是不是和我的一致,最新的版本中Flink的API发生过变动。第二点,虽然是个接口,但是看方法的签名,static default 接口是可以有默认实现方法的,是Java的语法糖。
*靖:
运行 可以出结果,但是总是会有异常产生
**街大亨:
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.12.0 ,1.10.0 没用了
讲师回复:
亲测有效,你可以直接访问:https://flink.apache.org/q/quickstart.sh ,找到代码:-DarchetypeVersion=${1:-1.12.0},这里说的是你指定版本的话就用你指定的版本,不指定的话就用1.12.0版本
*艺:
public static final class LineSplitter implements FlatMapFunction 老师 这个接口总是无法使用,scala 版本2.11 flink版本1.11 这是为什么呢
讲师回复:
不会的,你直接把我工程中的 Flink 版本换掉,然后重新导 maven 依赖,这个 FlatMapFunction 是个最基本的函数。
**武:
本地运行batchJob时 报错:Exception in thread “main” java.lang.RuntimeException: java.util.concurrent.ExecutionException: akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka://flink/user/dispatcher#1330413722]] after [10000 ms]. Message of type [org.apache.flink.runtime.rpc.messages.LocalFencedMessage]. A typical reason for
AskTimeoutExceptionis that the recipient actor didn’t send a reply.请问下是什么原因引起的
讲师回复:
https://issues.apache.org/jira/browse/FLINK-8485 这个是Flink本身的一个bug,我们自己可以把JDK的版本升级到1.8.1 另外有一个配置可以修改下:akka.ask.timeout: 60 s
**用户1554:
我拉下来的源码 右键没有办法执行main函数,可能是什么原因呢?
讲师回复:
用maven编译一下,把依赖全部下载完毕。
*南:
按照课程中的,pom文件中添加依赖后,本地运行,报错:Exception in thread “main” org.apache.flink.table.api.TableException: Create BatchTableEnvironment failed.这个是依赖的版本问题???
讲师回复:
是的,要注意。Flink在1.10版本做过一些较大更新。建议从1.11开始。
**勇:
fbTableEnv.createTemporaryView(“WordCount”, table);createTemporaryView 1.9没有这个方法吗?">registerTable
讲师回复:
把版本更新到1.11吧。1.11又一次较大规模的更新。
**吃雪糕:
flink sql的写法,表的记录数有上限吗?比如上亿的数据数据行性能如何?
讲师回复:
State会变得非常大,性能并不好。我们在SQL或者多个流Join的场景下都会设置State的过期时间。
**田:
本地模式可以直接运行么
讲师回复:
可以
**强:
还不错
**博:
可以用windows系统吗
讲师回复:
最好不要
*熙:
idea本地运行,其实运行时程序本身也会启动了jobmanager,taskmanager的么???
讲师回复:
没错
**磊:
学习这大数据工具,
需要会java web 开发吗
讲师回复:
最好会
**6091:
开始学习
**6631:
老师 帮忙看看一个问题 https://github.com/JSQF/flink10_learn.git
com.yyb.flink10.stream.WordCount报错Error:(64, 10) value build is not a member of ?0possible cause: maybe a semicolon is missing before `value build’?.build()
讲师回复:
value build之前缺少一个括号
**成:
有问题啊,最后的flink sql ,pom文件想复制,不能复制,而且需要的jar包无法下载,最后,使用的是Java代码,可以用Scala实现吗?
讲师回复:
可以复制的,可以用scala但是不建议
lumen:
赞一个,作者大大辛苦啦
**8527:
请教下,sql的window如何使用?用类解析字段的话,未来扩展字段如何解决呢?如果有嵌套的话是不是就更复杂了?
讲师回复:
sql高度抽象,如果掌握不好,出现问题很难排查
*强:
写的很用心,排版很优美,期待更新中😀
**6631:
StreamTable 没有示例啊
讲师回复:
二者API类似,把源换成流即可。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2037-%E7%AC%AC02%E8%AE%B2Flink-%E5%85%A5%E9%97%A8%E7%A8%8B%E5%BA%8F-WordCount-%E5%92%8C-SQL-%E5%AE%9E%E7%8E%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


