Flink系列-第05讲:Flink SQL & Table 编程和案例.md
我们在第 02 课时中使用 Flink Table & SQL 的 API 实现了最简单的 WordCount 程序。在这一课时中,将分别从 Flink Table & SQL 的背景和编程模型、常见的 API、算子和内置函数等对 Flink Table & SQL 做一个详细的讲解和概括,最后模拟了一个实际业务场景使用 Flink Table & SQL 开发。
Flink Table & SQL 概述
背景
我们在前面的课时中讲过 Flink 的分层模型,Flink 自身提供了不同级别的抽象来支持我们开发流式或者批量处理程序,下图描述了 Flink 支持的 4 种不同级别的抽象。
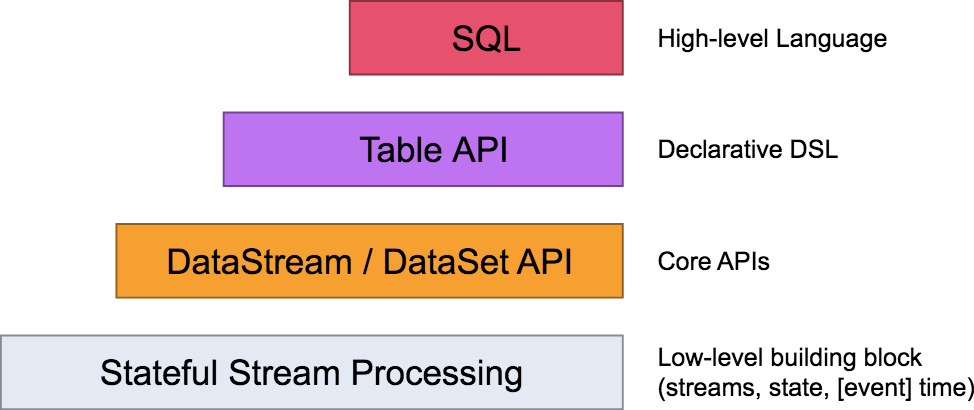
Table API 和 SQL 处于最顶端,是 Flink 提供的高级 API 操作。Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
我们在第 04 课时中提到过,Flink 在编程模型上提供了 DataStream 和 DataSet 两套 API,并没有做到事实上的批流统一,因为用户和开发者还是开发了两套代码。正是因为 Flink Table & SQL 的加入,可以说 Flink 在某种程度上做到了事实上的批流一体。
原理
你之前可能都了解过 Hive,在离线计算场景下 Hive 几乎扛起了离线数据处理的半壁江山。它的底层对 SQL 的解析用到了 Apache Calcite,Flink 同样把 SQL 的解析、优化和执行教给了 Calcite。
下图是一张经典的 Flink Table & SQL 实现原理图,可以看到 Calcite 在整个架构中处于绝对核心地位。
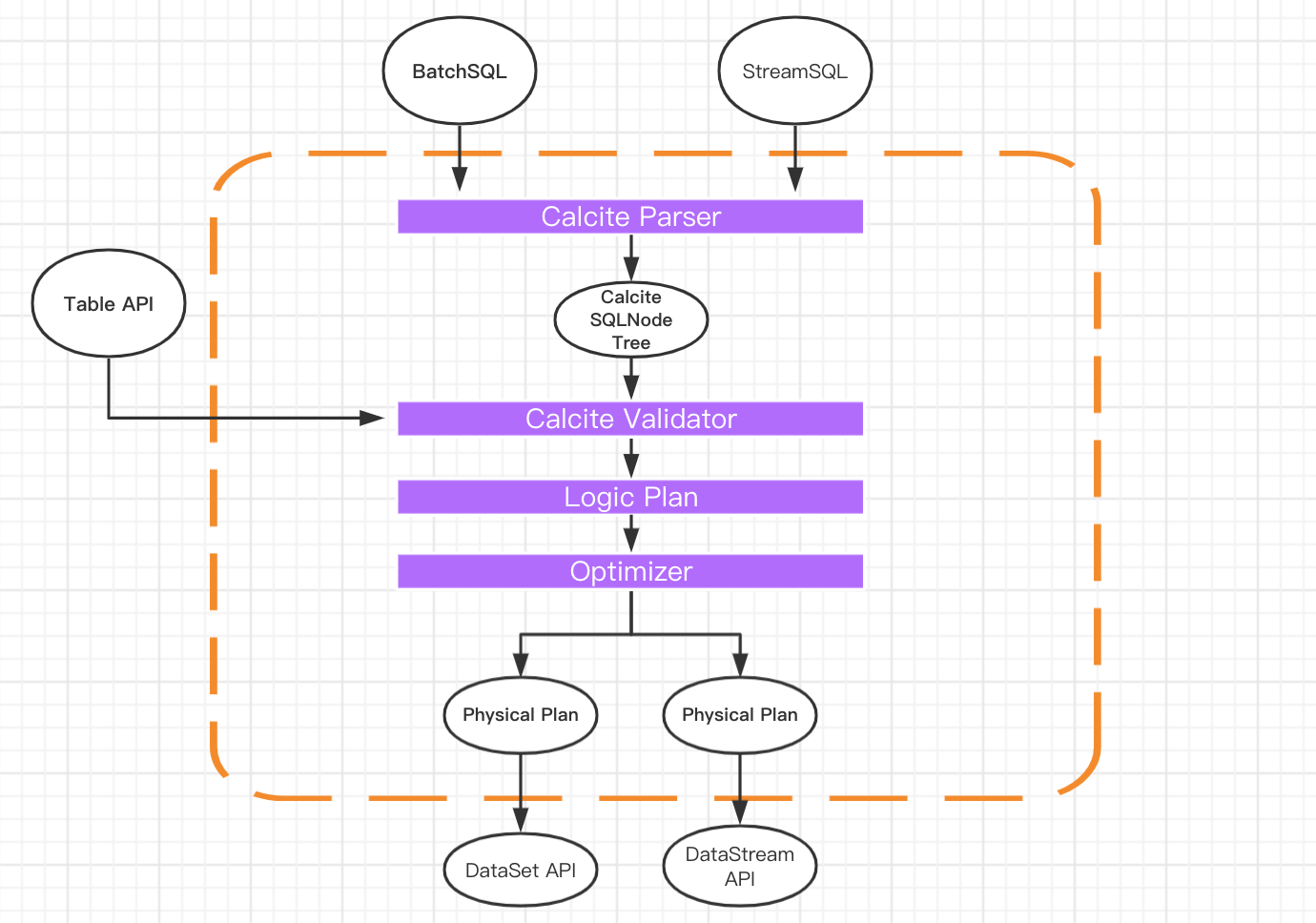
从图中可以看到无论是批查询 SQL 还是流式查询 SQL,都会经过对应的转换器 Parser 转换成为节点树 SQLNode tree,然后生成逻辑执行计划 Logical Plan,逻辑执行计划在经过优化后生成真正可以执行的物理执行计划,交给 DataSet 或者 DataStream 的 API 去执行。
在这里我们不对 Calcite 的原理过度展开,有兴趣的可以直接在官网上学习。
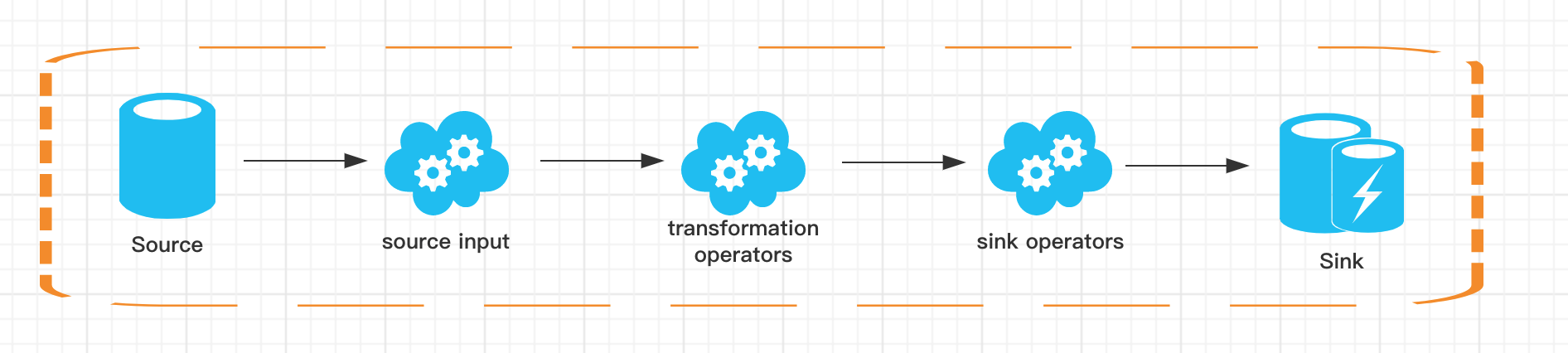
一个完整的 Flink Table & SQL Job 也是由 Source、Transformation、Sink 构成:
-
Source 部分来源于外部数据源,我们经常用的有 Kafka、MySQL 等;
-
Transformation 部分则是 Flink Table & SQL 支持的常用 SQL 算子,比如简单的 Select、Groupby 等,当然在这里也有更为复杂的多流 Join、流与维表的 Join 等;
-
Sink 部分是指的结果存储比如 MySQL、HBase 或 Kakfa 等。
动态表
与传统的表 SQL 查询相比,Flink Table & SQL 在处理流数据时会时时刻刻处于动态的数据变化中,所以便有了一个动态表的概念。
动态表的查询与静态表一样,但是,在查询动态表的时候,SQL 会做连续查询,不会终止。
我们举个简单的例子,Flink 程序接受一个 Kafka 流作为输入,Kafka 中为用户的购买记录:
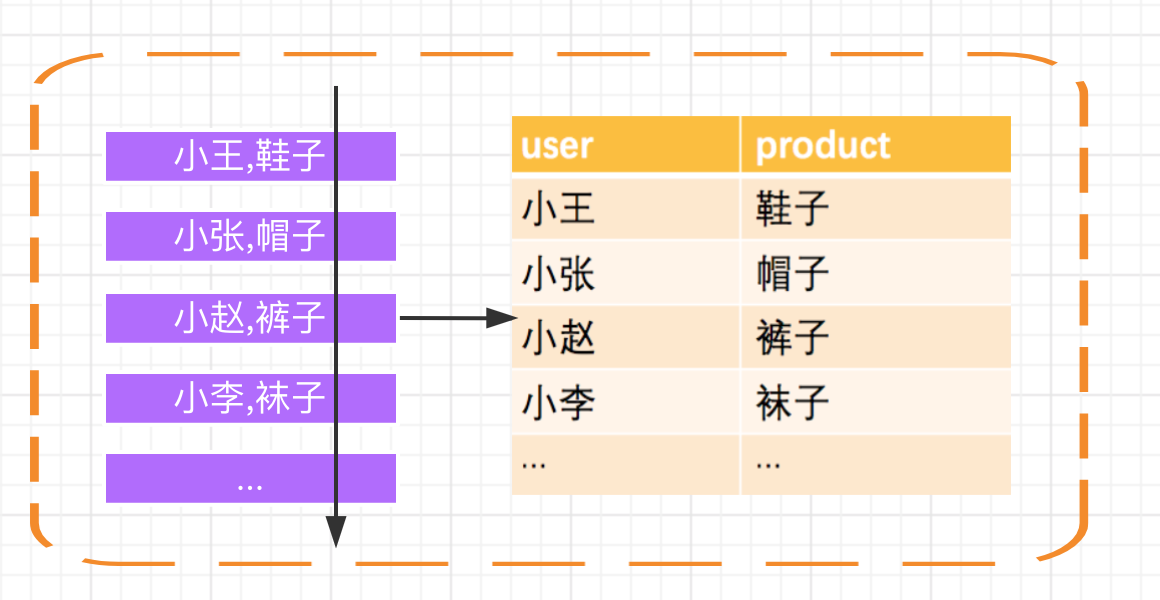
首先,Kafka 的消息会被源源不断的解析成一张不断增长的动态表,我们在动态表上执行的 SQL 会不断生成新的动态表作为结果表。
Flink Table & SQL 算子和内置函数
我们在讲解 Flink Table & SQL 所支持的常用算子前,需要说明一点,Flink 自从 0.9 版本开始支持 Table & SQL 功能一直处于完善开发中,且在不断进行迭代。
我们在官网中也可以看到这样的提示:
Please note that the Table API and SQL are not yet feature complete and are being actively developed. Not all operations are supported by every combination of [Table API, SQL] and [stream, batch] input.
Flink Table & SQL 的开发一直在进行中,并没有支持所有场景下的计算逻辑。从我个人实践角度来讲,在使用原生的 Flink Table & SQL 时,务必查询官网当前版本对 Table & SQL 的支持程度,尽量选择场景明确,逻辑不是极其复杂的场景。
常用算子
目前 Flink SQL 支持的语法主要如下:
query:
values
| {
select
| selectWithoutFrom
| query UNION [ ALL ] query
| query EXCEPT query
| query INTERSECT query
}
[ ORDER BY orderItem [, orderItem ]* ]
[ LIMIT { count | ALL } ]
[ OFFSET start { ROW | ROWS } ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY]
orderItem:
expression [ ASC | DESC ]
select:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
FROM tableExpression
[ WHERE booleanExpression ]
[ GROUP BY { groupItem [, groupItem ]* } ]
[ HAVING booleanExpression ]
[ WINDOW windowName AS windowSpec [, windowName AS windowSpec ]* ]
selectWithoutFrom:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
projectItem:
expression [ [ AS ] columnAlias ]
| tableAlias . *
tableExpression:
tableReference [, tableReference ]*
| tableExpression [ NATURAL ] [ LEFT | RIGHT | FULL ] JOIN tableExpression [ joinCondition ]
joinCondition:
ON booleanExpression
| USING ’(’ column [, column ]* ’)’
tableReference:
tablePrimary
[ matchRecognize ]
[ [ AS ] alias [ ’(’ columnAlias [, columnAlias ]* ’)’ ] ]
tablePrimary:
[ TABLE ] [ [ catalogName . ] schemaName . ] tableName
| LATERAL TABLE ’(’ functionName ’(’ expression [, expression ]* ’)’ ’)’
| UNNEST ’(’ expression ’)’
values:
VALUES expression [, expression ]*
groupItem:
expression
| ’(’ ’)’
| ’(’ expression [, expression ]* ’)’
| CUBE ’(’ expression [, expression ]* ’)’
| ROLLUP ’(’ expression [, expression ]* ’)’
| GROUPING SETS ’(’ groupItem [, groupItem ]* ’)’
windowRef:
windowName
| windowSpec
windowSpec:
[ windowName ]
’(’
[ ORDER BY orderItem [, orderItem ]* ]
[ PARTITION BY expression [, expression ]* ]
[
RANGE numericOrIntervalExpression {PRECEDING}
| ROWS numericExpression {PRECEDING}
]
’)’
…
可以看到 Flink SQL 和传统的 SQL 一样,支持了包含查询、连接、聚合等场景,另外还支持了包括窗口、排序等场景。下面我就以最常用的算子来做详细的讲解。
SELECT/AS/WHERE
SELECT、WHERE 和传统 SQL 用法一样,用于筛选和过滤数据,同时适用于 DataStream 和 DataSet。
SELECT * FROM Table;
SELECT name,age FROM Table;
当然我们也可以在 WHERE 条件中使用 =、<、>、<>、>=、<=,以及 AND、OR 等表达式的组合:
SELECT name,age FROM Table where name LIKE '%小明%';
SELECT * FROM Table WHERE age = 20;
SELECT name, age
FROM Table
WHERE name IN (SELECT name FROM Table2)
GROUP BY / DISTINCT/HAVING
GROUP BY 用于进行分组操作,DISTINCT 用于结果去重。
HAVING 和传统 SQL 一样,可以用来在聚合函数之后进行筛选。
SELECT DISTINCT name FROM Table;
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name HAVING
SUM(score) > 300;
JOIN
JOIN 可以用于把来自两个表的数据联合起来形成结果表,目前 Flink 的 Join 只支持等值连接。Flink 支持的 JOIN 类型包括:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
例如,用用户表和商品表进行关联:
SELECT *
FROM User LEFT JOIN Product ON User.name = Product.buyer
SELECT *
FROM User RIGHT JOIN Product ON User.name = Product.buyer
SELECT *
FROM User FULL OUTER JOIN Product ON User.name = Product.buyer
LEFT JOIN、RIGHT JOIN 、FULL JOIN 相与我们传统 SQL 中含义一样。
WINDOW
根据窗口数据划分的不同,目前 Apache Flink 有如下 3 种:
-
滚动窗口,窗口数据有固定的大小,窗口中的数据不会叠加;
-
滑动窗口,窗口数据有固定大小,并且有生成间隔;
-
会话窗口,窗口数据没有固定的大小,根据用户传入的参数进行划分,窗口数据无叠加;
滚动窗口
滚动窗口的特点是:有固定大小、窗口中的数据不会重叠,如下图所示:
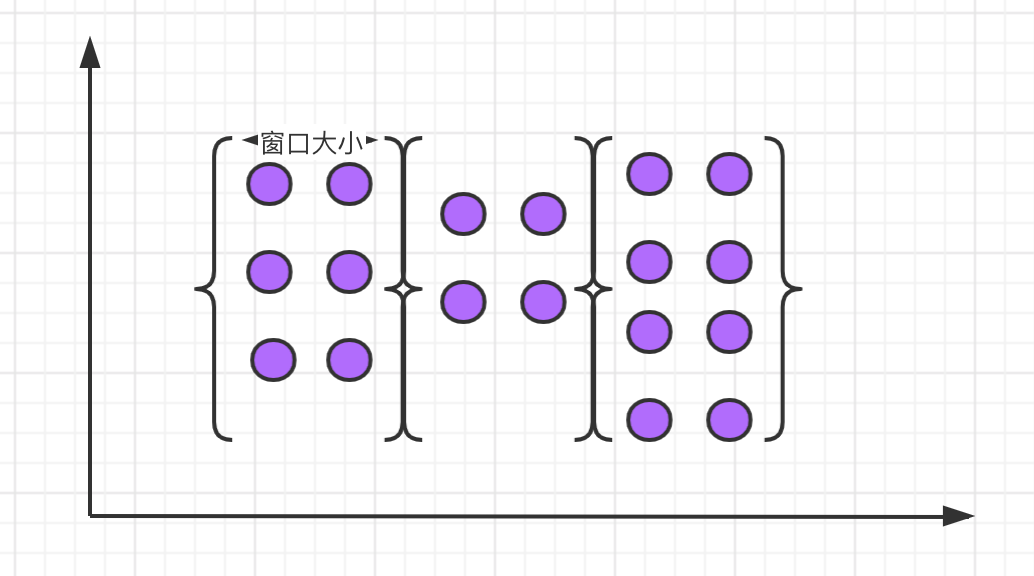
滚动窗口的语法:
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
举例说明,我们需要计算每个用户每天的订单数量:
SELECT user, TUMBLE_START(timeLine, INTERVAL '1' DAY) as winStart, SUM(amount) FROM Orders GROUP BY TUMBLE(timeLine, INTERVAL '1' DAY), user;
其中,TUMBLE_START 和 TUMBLE_END 代表窗口的开始时间和窗口的结束时间,TUMBLE (timeLine, INTERVAL '1' DAY) 中的 timeLine 代表时间字段所在的列,INTERVAL '1' DAY 表示时间间隔为一天。
滑动窗口
滑动窗口有固定的大小,与滚动窗口不同的是滑动窗口可以通过 slide 参数控制滑动窗口的创建频率。需要注意的是,多个滑动窗口可能会发生数据重叠,具体语义如下:
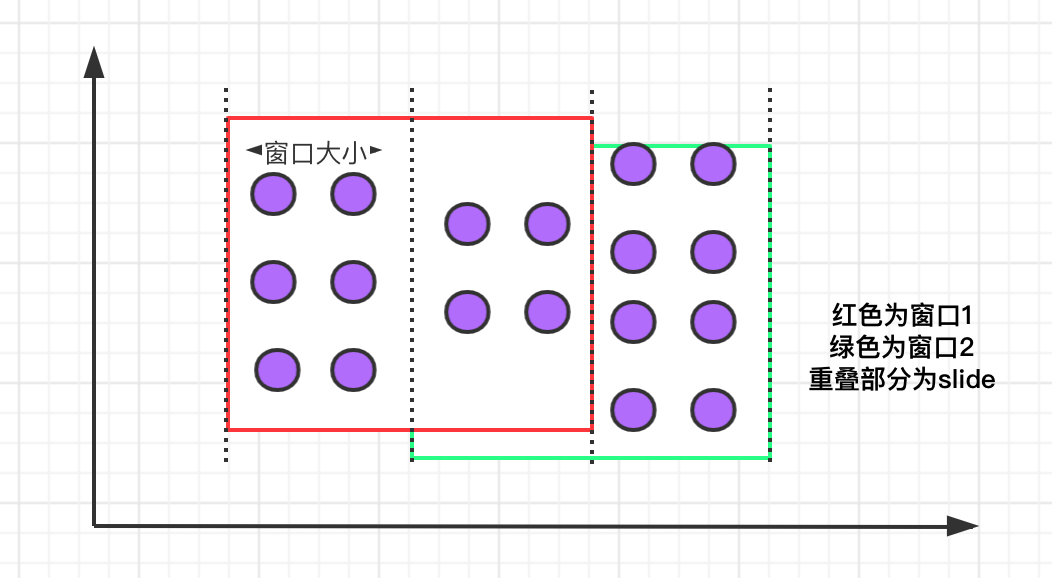
滑动窗口的语法与滚动窗口相比,只多了一个 slide 参数:
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
例如,我们要每间隔一小时计算一次过去 24 小时内每个商品的销量:
SELECT product, SUM(amount) FROM Orders GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '1' DAY), product
上述案例中的 INTERVAL '1' HOUR 代表滑动窗口生成的时间间隔。
会话窗口
会话窗口定义了一个非活动时间,假如在指定的时间间隔内没有出现事件或消息,则会话窗口关闭。
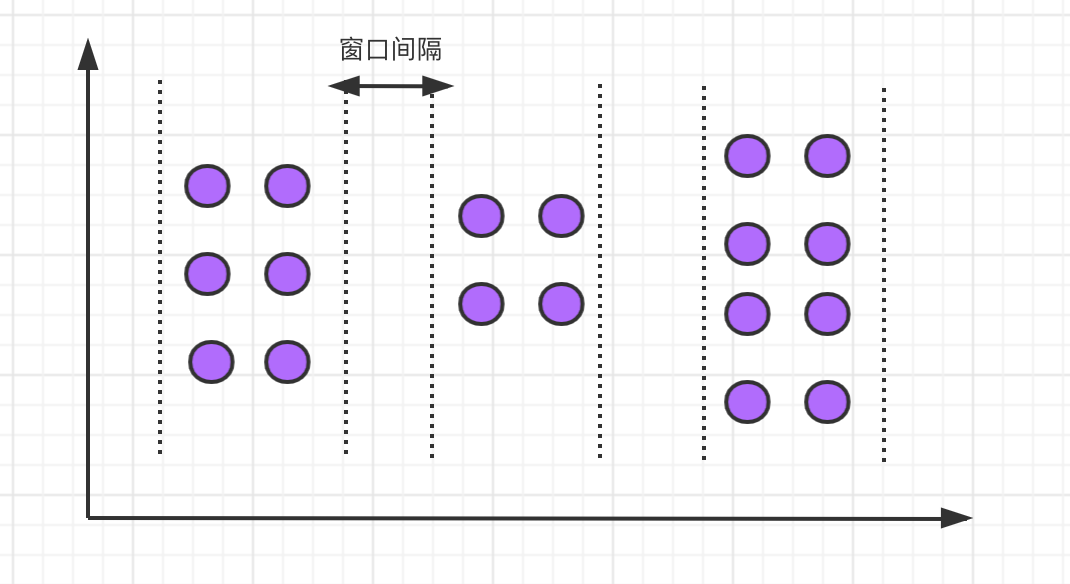
会话窗口的语法如下:
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
举例,我们需要计算每个用户过去 1 小时内的订单量:
SELECT user, SESSION_START(rowtime, INTERVAL '1' HOUR) AS sStart, SESSION_ROWTIME(rowtime, INTERVAL '1' HOUR) AS sEnd, SUM(amount) FROM Orders GROUP BY SESSION(rowtime, INTERVAL '1' HOUR), user
内置函数
Flink 中还有大量的内置函数,我们可以直接使用,将内置函数分类如下:
-
比较函数
-
逻辑函数
-
算术函数
-
字符串处理函数
-
时间函数
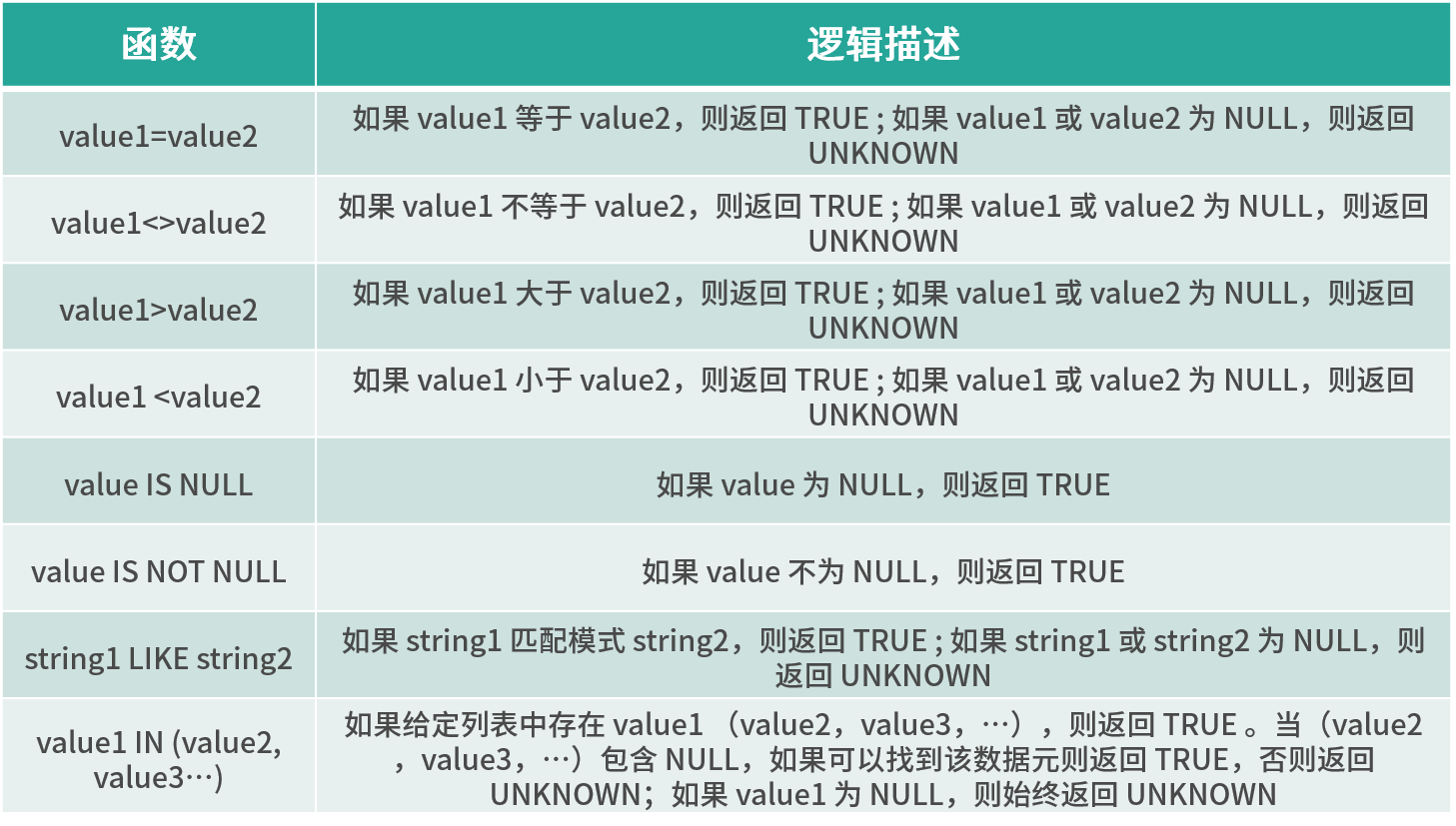
比较函数
逻辑函数

算术函数
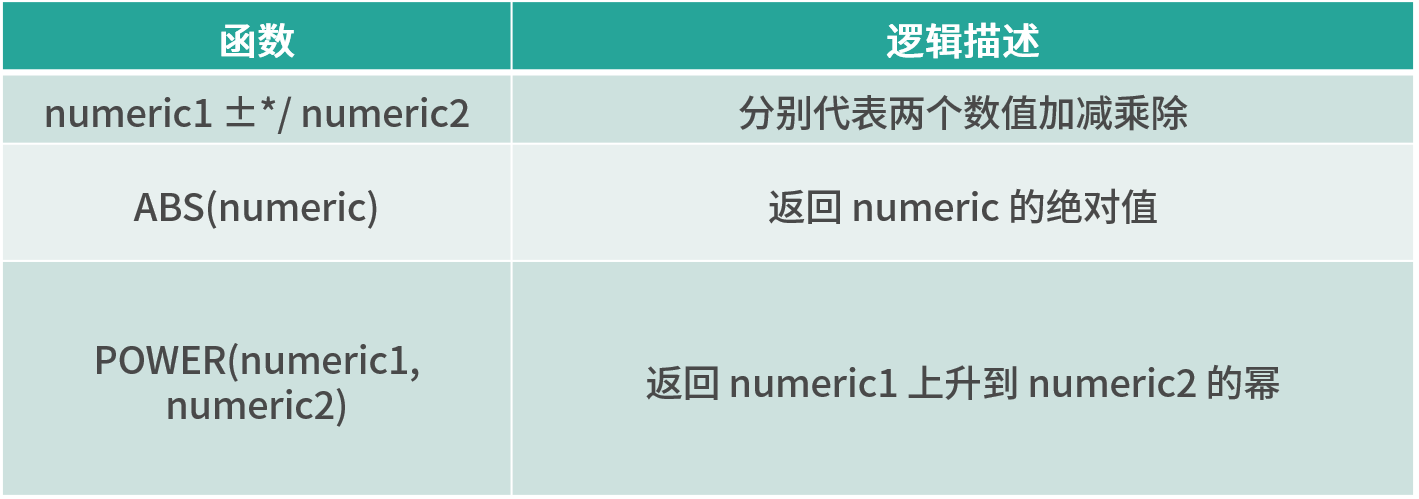
字符串处理函数

时间函数

Flink Table & SQL 案例
上面分别介绍了 Flink Table & SQL 的原理和支持的算子,我们模拟一个实时的数据流,然后讲解 SQL JOIN 的用法。
在上一课时中,我们利用 Flink 提供的自定义 Source 功能来实现一个自定义的实时数据源,具体实现如下:
public class MyStreamingSource implements SourceFunction<Item> {
<span class="hljs-keyword">private</span> <span class="hljs-keyword">boolean</span> isRunning = <span class="hljs-keyword">true</span>;
<span class="hljs-comment">/**
* 重写run方法产生一个源源不断的数据发送源
* <span class="hljs-doctag">@param</span> ctx
* <span class="hljs-doctag">@throws</span> Exception
*/</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title">run</span><span class="hljs-params">(SourceContext<Item> ctx)</span> <span class="hljs-keyword">throws</span> Exception </span>{
<span class="hljs-keyword">while</span>(isRunning){
Item item = generateItem();
ctx.collect(item);
<span class="hljs-comment">//每秒产生一条数据</span>
Thread.sleep(<span class="hljs-number">1000</span>);
}
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title">cancel</span><span class="hljs-params">()</span> </span>{
isRunning = <span class="hljs-keyword">false</span>;
}
<span class="hljs-comment">//随机产生一条商品数据</span>
<span class="hljs-function"><span class="hljs-keyword">private</span> Item <span class="hljs-title">generateItem</span><span class="hljs-params">()</span></span>{
<span class="hljs-keyword">int</span> i = <span class="hljs-keyword">new</span> Random().nextInt(<span class="hljs-number">100</span>);
ArrayList<String> list = <span class="hljs-keyword">new</span> ArrayList();
list.add(<span class="hljs-string">"HAT"</span>);
list.add(<span class="hljs-string">"TIE"</span>);
list.add(<span class="hljs-string">"SHOE"</span>);
Item item = <span class="hljs-keyword">new</span> Item();
item.setName(list.get(<span class="hljs-keyword">new</span> Random().nextInt(<span class="hljs-number">3</span>)));
item.setId(i);
<span class="hljs-keyword">return</span> item;
}
}
我们把实时的商品数据流进行分流,分成 even 和 odd 两个流进行 JOIN,条件是名称相同,最后,把两个流的 JOIN 结果输出。
class StreamingDemo {
public static void main(String[] args) throws Exception {
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
SingleOutputStreamOperator<Item> source = bsEnv.addSource(<span class="hljs-keyword">new</span> MyStreamingSource()).map(<span class="hljs-keyword">new</span> MapFunction<Item, Item>() {
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Item <span class="hljs-title">map</span><span class="hljs-params">(Item item)</span> <span class="hljs-keyword">throws</span> Exception </span>{
<span class="hljs-keyword">return</span> item;
}
});
DataStream<Item> evenSelect = source.split(<span class="hljs-keyword">new</span> OutputSelector<Item>() {
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Iterable<String> <span class="hljs-title">select</span><span class="hljs-params">(Item value)</span> </span>{
List<String> output = <span class="hljs-keyword">new</span> ArrayList<>();
<span class="hljs-keyword">if</span> (value.getId() % <span class="hljs-number">2</span> == <span class="hljs-number">0</span>) {
output.add(<span class="hljs-string">"even"</span>);
} <span class="hljs-keyword">else</span> {
output.add(<span class="hljs-string">"odd"</span>);
}
<span class="hljs-keyword">return</span> output;
}
}).select(<span class="hljs-string">"even"</span>);
DataStream<Item> oddSelect = source.split(<span class="hljs-keyword">new</span> OutputSelector<Item>() {
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Iterable<String> <span class="hljs-title">select</span><span class="hljs-params">(Item value)</span> </span>{
List<String> output = <span class="hljs-keyword">new</span> ArrayList<>();
<span class="hljs-keyword">if</span> (value.getId() % <span class="hljs-number">2</span> == <span class="hljs-number">0</span>) {
output.add(<span class="hljs-string">"even"</span>);
} <span class="hljs-keyword">else</span> {
output.add(<span class="hljs-string">"odd"</span>);
}
<span class="hljs-keyword">return</span> output;
}
}).select(<span class="hljs-string">"odd"</span>);
bsTableEnv.createTemporaryView(<span class="hljs-string">"evenTable"</span>, evenSelect, <span class="hljs-string">"name,id"</span>);
bsTableEnv.createTemporaryView(<span class="hljs-string">"oddTable"</span>, oddSelect, <span class="hljs-string">"name,id"</span>);
Table queryTable = bsTableEnv.sqlQuery(<span class="hljs-string">"select a.id,a.name,b.id,b.name from evenTable as a join oddTable as b on a.name = b.name"</span>);
queryTable.printSchema();
bsTableEnv.toRetractStream(queryTable, TypeInformation.of(<span class="hljs-keyword">new</span> TypeHint<Tuple4<Integer,String,Integer,String>>(){})).print();
bsEnv.execute(<span class="hljs-string">"streaming sql job"</span>);
}
}
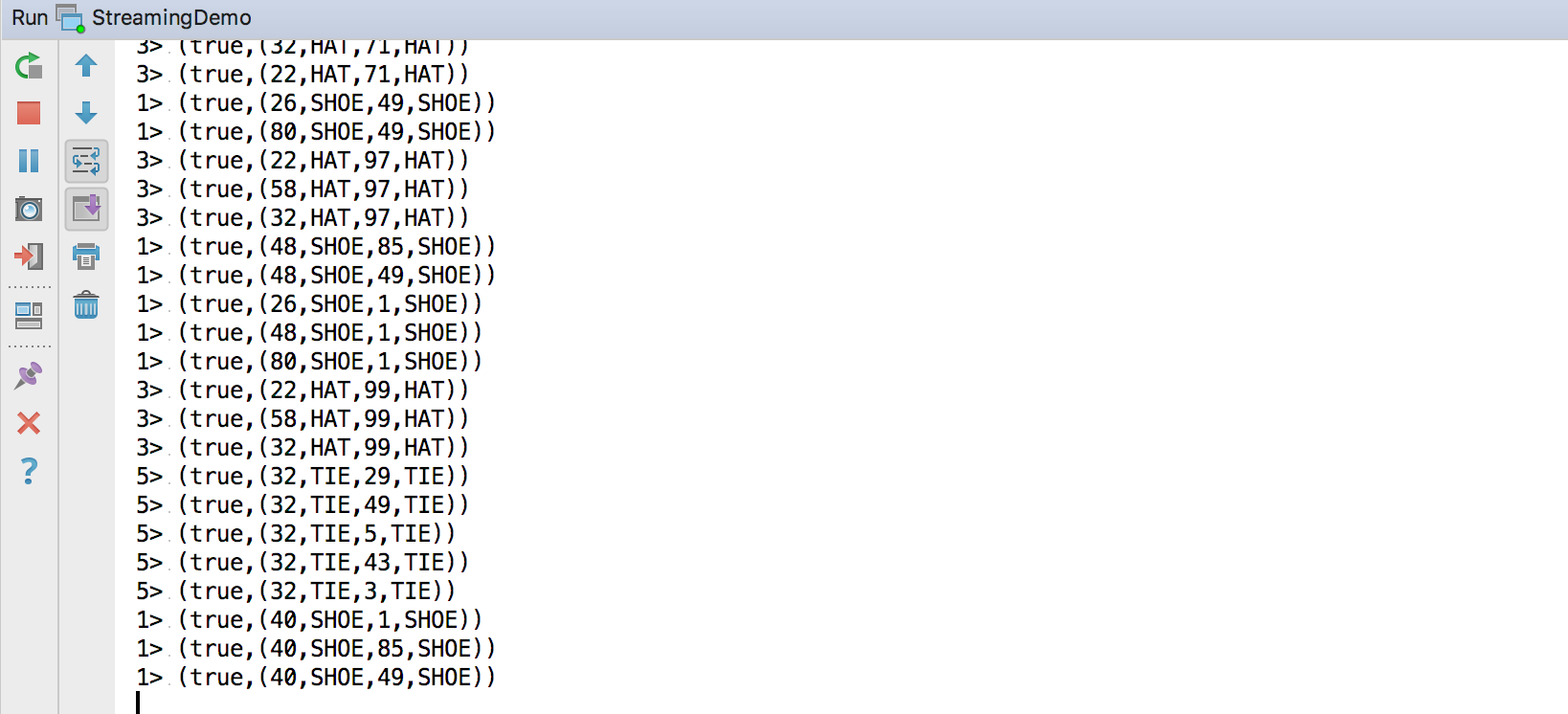
直接右键运行,在控制台可以看到输出:
总结
我们在这一课时中讲解了 Flink Table & SQL 的背景和原理,并且讲解了动态表的概念;同时对 Flink 支持的常用 SQL 和内置函数进行了讲解;最后用一个案例,讲解了整个 Flink Table & SQL 的使用。
精选评论
*磊:
看了好多个拉勾专栏了,flink这个专栏算是最良心的。从循序渐进的课程安排,到细致易懂的内容,到老师热心回复 都很好!感谢这个老师,希望拉勾别的专栏向这个看齐。
编辑回复:
也祝你学习愉快
*铁:
我本地搭建的环境是flink-1.11,我看文档createTemporaryView这个方法在1.11更新了,所以就改了一下示例bsTableEnv.createTemporaryView(“evenTable”, evenSelect, $(“id”), $(“name”)); 不过运行到这里就报错就报错:Too many fields referenced from an atomic type. 求指教!
讲师回复:
如果你使用了Tuple类,记得用flink的tuple。另外你需要使用TypeInformation来指定列的类型。
123:
很赞
*熙:
您好,读完文章,有以下两个问题,还望解答下,感谢~~~1. 意思是sql 和 table api都会经过转换器转换成dataset或datastream api是么?2. 如果1成立的话,那是不是只要掌握dataset或者datastream原理的话,其实就是掌握了sql,table api是么?
讲师回复:
1.是的 2.sql的开发效率远大于原生api
**-4年-大数据开发:
讲师回复: 实际生产中双流join并不提倡,会遇到很多状态问题。一般会把其中一个流放入Hbase这样的存储中再去关联。文中的odd和even两个流是为了模拟join所需的输入。我现在生产有一张用户表,包含用户的基本信息和状态;大概4亿数据存储在hbase;如果把hbase当成维表关联性能怎么样;
讲师回复:
事实上是可以的,HBase 的查询 qps 非常高,如果是维表的话,其实效率是没有问题的。我们在实际生产中 HBase 中的数据大概存半年,超过几十T的数据。
**生:
这个SQL,落地在哪里,如果我要做展示,我应该搞?比如说,我想用展示工具grafana显示结果。应该落地在哪里呢?
讲师回复:
grafna支持的数据源都可以的,例如MySql
*宁:
写的很用心,继续学习ing
Johngo:
这个使用的数据Flink哪个版本,我用1.10.0尝试实现sql相关,总是没办法跑通😔
讲师回复:
开源的Flink的sql是非常不稳定的功能,如果你用了阿里云的Blink就会好些。
**蜗牛:
我有一句不理解:“Flink 自从 0.9 版本开始支持 Table & SQL 功能一直处于完善开发中,且在不断进行迭代。”,是 1.9 还是 0.9 版本???
讲师回复:
0.9就支持了,但是一直在更新
**姐:
bsTableEnv.createTemporaryView(“evenTable”, evenSelect, “name,id”);这行报Too many fields referenced from an atomic type.的错误,Item已经有无参构造器、getter和setter了。
讲师回复:
好好检查一下你的类,需要满足: 1.类必须是公有的。 2.它必须有一个公有的无参构造器(默认构造器)。 3.所有的字段要么是公有的要么必须可以通过 getter 和 setter 函数访问。例如一个名为 foo 的字段,它的 getter 和 setter 方法必须命名为 getFoo() 和 setFoo()。 4.字段的类型必须被已注册的序列化程序所支持。
*航:
count window有类似time window这种SQL里面的TUMBLE写法吗
讲师回复:
目前只支持 TimeWindow,相应的表达语句 TUMBLE、HOP、SESSION,CountWindow 不支持。
**9524:
临时表有100万行 10个字段 占用多少内存
讲师回复:
这个跟每个字段的长度、类型都有关系吧。保守估计应该是几百M。
**发:
在">bsTableEnv.createTemporaryView(“evenTable”, evenSelect, “id,name”); 处报错:Exception in thread “main” org.apache.flink.table.api.ValidationException: Too many fields referenced from an atomic type.开始是Tuple4 类引入错了,后面纠正为Flink的了也不行
讲师回复:
需要给你的Java对象一个无参构造方法,最好加上getter和setter
**用户4300:
Kafka 的消息会被源源不断的解析成一张不断增长的动态表,我想问一下老师,这动态表的大小数量的限制吗?如果源源不断的数据,是怎么存储这些状态的?
讲师回复:
会根据配置,存储在内存或者第三方的数据库中
*少:
老师,我对最后一个例子的执行结果不是很理解。常规sql进行join是一个集合,观察了例子的执行结果是没有重复数据的,这是even和odd两个流增量元素的join结果吗?最后这个例子套用到具体业务上是一个什么样的场景呢?请老师讲解一下。
讲师回复:
实际生产中双流join并不提倡,会遇到很多状态问题。一般会把其中一个流放入Hbase这样的存储中再去关联。文中的odd和even两个流是为了模拟join所需的输入。
**5317:
会话窗口那个例子,实际的含义是在1小时没有用户下单的时候,就计算每个用户的订单量吧
讲师回复:
是当前时间的过去一小时
*军:
createTemporaryView() 方法的使用编译不通过,换成了registerDataStream()可以使用,但是示例运行报错 ‘Exception in thread “main” java.lang.NoSuchMethodError: org.apache.flink.table.catalog.FunctionCatalog.<init>(Lorg/apache/flink/table/catalog/CatalogManager;)V’
是为啥
讲师回复:
重新提交了POM依赖,再试试
**7651:
会话窗口案例,过去一小时的订单量,这个不太能理解
讲师回复:
就是在一个窗口内,计算过去一个小时有多少订单
*曙:
logic plan之后是StreamGraph ,不是生成物理执行计划吧
讲师回复:
是的
*帅:
最后一个例子输出用了toRetractStream,请问这里用toAppendStream/toUpsertStream是不是也可以?
讲师回复:
是的
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2040-%E7%AC%AC05%E8%AE%B2Flink-SQL-Table-%E7%BC%96%E7%A8%8B%E5%92%8C%E6%A1%88%E4%BE%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


