Flink系列-第07讲:Flink 常见核心概念分析
在 Flink 这个框架中,有很多独有的概念,比如分布式缓存、重启策略、并行度等,这些概念是我们在进行任务开发和调优时必须了解的,这一课时我将会从原理和应用场景分别介绍这些概念。
分布式缓存
熟悉 Hadoop 的你应该知道,分布式缓存最初的思想诞生于 Hadoop 框架,Hadoop 会将一些数据或者文件缓存在 HDFS 上,在分布式环境中让所有的计算节点调用同一个配置文件。在 Flink 中,Flink 框架开发者们同样将这个特性进行了实现。
Flink 提供的分布式缓存类型 Hadoop,目的是为了在分布式环境中让每一个 TaskManager 节点保存一份相同的数据或者文件,当前计算节点的 task 就像读取本地文件一样拉取这些配置。
分布式缓存在我们实际生产环境中最广泛的一个应用,就是在进行表与表 Join 操作时,如果一个表很大,另一个表很小,那么我们就可以把较小的表进行缓存,在每个 TaskManager 都保存一份,然后进行 Join 操作。
那么我们应该怎样使用 Flink 的分布式缓存呢?举例如下:
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.registerCachedFile("/Users/wangzhiwu/WorkSpace/quickstart/distributedcache.txt", “distributedCache”);
//1:注册一个文件,可以使用hdfs上的文件 也可以是本地文件进行测试
DataSource<String> data = env.fromElements(“Linea”, “Lineb”, “Linec”, “Lined”);
DataSet<String> result = data.map(<span class="hljs-keyword">new</span> RichMapFunction<String, String>() {
<span class="hljs-keyword">private</span> ArrayList<String> dataList = <span class="hljs-keyword">new</span> ArrayList<String>();
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title">open</span><span class="hljs-params">(Configuration parameters)</span> <span class="hljs-keyword">throws</span> Exception </span>{
<span class="hljs-keyword">super</span>.open(parameters);
<span class="hljs-comment">//2:使用该缓存文件</span>
File myFile = getRuntimeContext().getDistributedCache().getFile(<span class="hljs-string">"distributedCache"</span>);
List<String> lines = FileUtils.readLines(myFile);
<span class="hljs-keyword">for</span> (String line : lines) {
<span class="hljs-keyword">this</span>.dataList.add(line);
System.err.println(<span class="hljs-string">"分布式缓存为:"</span> + line);
}
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> String <span class="hljs-title">map</span><span class="hljs-params">(String value)</span> <span class="hljs-keyword">throws</span> Exception </span>{
<span class="hljs-comment">//在这里就可以使用dataList</span>
System.err.println(<span class="hljs-string">"使用datalist:"</span> + dataList + <span class="hljs-string">"-------"</span> +value);
<span class="hljs-comment">//业务逻辑</span>
<span class="hljs-keyword">return</span> dataList +<span class="hljs-string">":"</span> + value;
}
});
result.printToErr();
}
从上面的例子中可以看出,使用分布式缓存有两个步骤。
-
第一步:首先需要在 env 环境中注册一个文件,该文件可以来源于本地,也可以来源于 HDFS ,并且为该文件取一个名字。
-
第二步:在使用分布式缓存时,可根据注册的名字直接获取。
可以看到,在上述案例中,我们把一个本地的 distributedcache.txt 文件注册为 distributedCache,在下面的 map 算子中直接通过这个名字将缓存文件进行读取并且进行了处理。
我们直接运行该程序,在控制台可以看到如下输出:


在使用分布式缓存时也需要注意一些问题,需要我们缓存的文件在任务运行期间最好是只读状态,否则会造成数据的一致性问题。另外,缓存的文件和数据不宜过大,否则会影响 Task 的执行速度,在极端情况下会造成 OOM。
故障恢复和重启策略
自动故障恢复是 Flink 提供的一个强大的功能,在实际运行环境中,我们会遇到各种各样的问题从而导致应用挂掉,比如我们经常遇到的非法数据、网络抖动等。
Flink 提供了强大的可配置故障恢复和重启策略来进行自动恢复。
故障恢复
我们在上一课时中介绍过 Flink 的配置文件,其中有一个参数 jobmanager.execution.failover-strategy: region。
Flink 支持了不同级别的故障恢复策略,jobmanager.execution.failover-strategy 的可配置项有两种:full 和 region。
当我们配置的故障恢复策略为 full 时,集群中的 Task 发生故障,那么该任务的所有 Task 都会发生重启。而在实际生产环境中,我们的大作业可能有几百个 Task,出现一次异常如果进行整个任务重启,那么经常会导致长时间任务不能正常工作,导致数据延迟。
但是事实上,我们可能只是集群中某一个或几个 Task 发生了故障,只需要重启有问题的一部分即可,这就是 Flink 基于 Region 的局部重启策略。在这个策略下,Flink 会把我们的任务分成不同的 Region,当某一个 Task 发生故障时,Flink 会计算需要故障恢复的最小 Region。
Flink 在判断需要重启的 Region 时,采用了以下的判断逻辑:
-
发生错误的 Task 所在的 Region 需要重启;
-
如果当前 Region 的依赖数据出现损坏或者部分丢失,那么生产数据的 Region 也需要重启;
-
为了保证数据一致性,当前 Region 的下游 Region 也需要重启。
重启策略
Flink 提供了多种类型和级别的重启策略,常用的重启策略包括:
-
固定延迟重启策略模式
-
失败率重启策略模式
-
无重启策略模式
Flink 在判断使用的哪种重启策略时做了默认约定,如果用户配置了 checkpoint,但没有设置重启策略,那么会按照固定延迟重启策略模式进行重启;如果用户没有配置 checkpoint,那么默认不会重启。
下面我们分别对这三种模式进行详细讲解。
无重启策略模式
在这种情况下,如果我们的作业发生错误,任务会直接退出。
我们可以在 flink-conf.yaml 中配置:
restart-strategy: none
也可以在程序中使用代码指定:
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
固定延迟重启策略模式
固定延迟重启策略会通过在 flink-conf.yaml 中设置如下配置参数,来启用此策略:
restart-strategy: fixed-delay
固定延迟重启策略模式需要指定两个参数,首先 Flink 会根据用户配置的重试次数进行重试,每次重试之间根据配置的时间间隔进行重试,如下表所示:
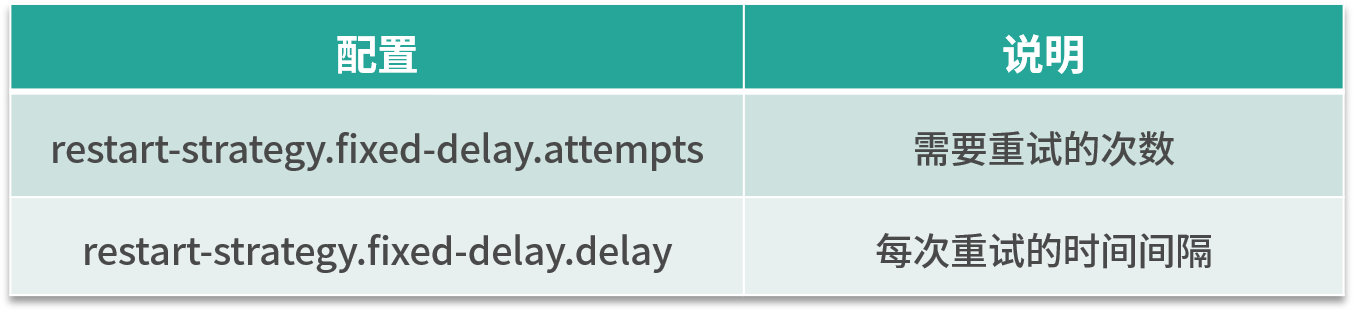
举个例子,假如我们需要任务重试 3 次,每次重试间隔 5 秒,那么需要进行一下配置:
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 5 s
当前我们也可以在代码中进行设置:
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(5, TimeUnit.SECONDS) // 时间间隔
));
失败率重启策略模式
首先我们在 flink-conf.yaml 中指定如下配置:
restart-strategy: failure-rate
这种重启模式需要指定三个参数,如下表所示。失败率重启策略在 Job 失败后会重启,但是超过失败率后,Job 会最终被认定失败。在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
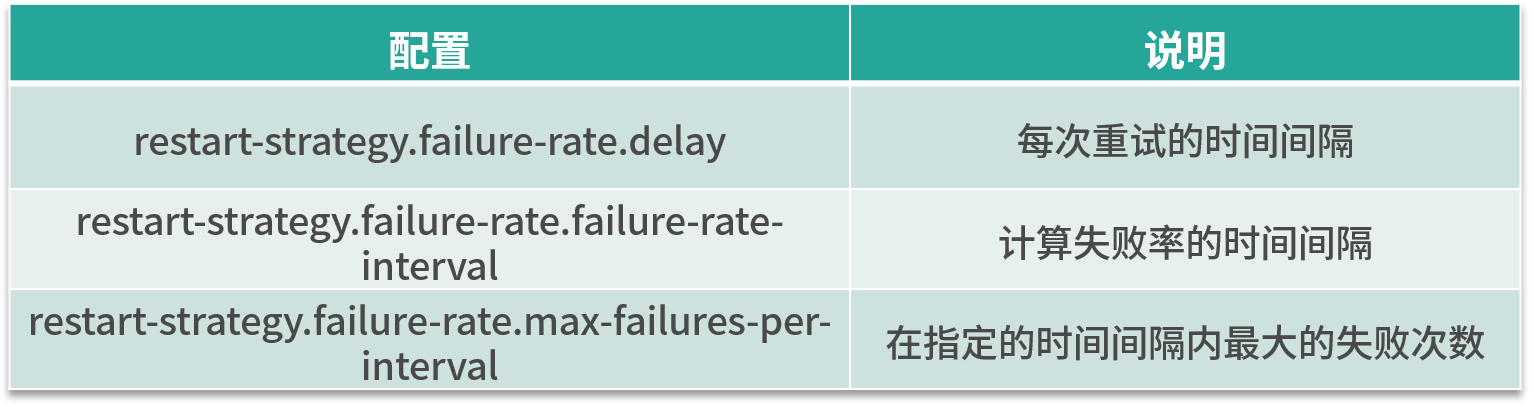
这种策略的配置理解较为困难,我们举个例子,假如 5 分钟内若失败了 3 次,则认为该任务失败,每次失败的重试间隔为 5 秒。
那么我们的配置应该是:
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 5 s
当然,也可以在代码中直接指定:
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个时间间隔的最大故障次数
Time.of(5, TimeUnit.MINUTES), // 测量故障率的时间间隔
Time.of(5, TimeUnit.SECONDS) // 每次任务失败时间间隔
));
最后,需要注意的是,在实际生产环境中由于每个任务的负载和资源消耗不一样,我们推荐在代码中指定每个任务的重试机制和重启策略。
并行度
并行度是 Flink 执行任务的核心概念之一,它被定义为在分布式运行环境中我们的一个算子任务被切分成了多少个子任务并行执行。我们提高任务的并行度(Parallelism)在很大程度上可以大大提高任务运行速度。
一般情况下,我们可以通过四种级别来设置任务的并行度。
-
算子级别
在代码中可以调用 setParallelism 方法来设置每一个算子的并行度。例如:
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new LineSplitter())
.groupBy(0)
.sum(1).setParallelism(1);
事实上,Flink 的每个算子都可以单独设置并行度。这也是我们最推荐的一种方式,可以针对每个算子进行任务的调优。
-
执行环境级别
我们在创建 Flink 的上下文时可以显示的调用 env.setParallelism() 方法,来设置当前执行环境的并行度,这个配置会对当前任务的所有算子、Source、Sink 生效。当然你还可以在算子级别设置并行度来覆盖这个设置。
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(5);
-
提交任务级别
用户在提交任务时,可以显示的指定 -p 参数来设置任务的并行度,例如:
./bin/flink run -p 10 WordCount.jar
-
系统配置级别
我们在上一课时中提到了 flink-conf.yaml 中的一个配置:parallelism.default,该配置即是在系统层面设置所有执行环境的并行度配置。
整体上讲,这四种级别的配置生效优先级如下:算子级别 > 执行环境级别 > 提交任务级别 > 系统配置级别。
在这里,要特别提一下 Flink 中的 Slot 概念。我们知道,Flink 中的 TaskManager 是执行任务的节点,那么在每一个 TaskManager 里,还会有“槽位”,也就是 Slot。Slot 个数代表的是每一个 TaskManager 的并发执行能力。
假如我们指定 taskmanager.numberOfTaskSlots:3,即每个 taskManager 有 3 个 Slot ,那么整个集群就有 3 * taskManager 的个数多的槽位。这些槽位就是我们整个集群所拥有的所有执行任务的资源。
总结
这一课时我们讲解了 Flink 中常见的分布式缓存、重启策略、并行度几个核心的概念和实际配置,这些概念的正确理解和合理配置是后面我们进行资源调优和任务优化的基础。在下一课时中我们会对 Flink 中最难以理解的“窗口和水印”进行讲解。
精选评论
**用户0441:
学习大数据最好是现在,其次是十年后,一元不香,钱上面有汗水,比较臭,其次病毒也多,大家注意洗手。
**雄:
请问老师org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not allocate enough slots within timeout of 300000 ms to run the job. Please make sure that the cluster has enough resources.这个是资源不够吗?我分配的是4G 2CPU
讲师回复:
默认的Flink的Slots配置是1,你的slot个数太多了。修改conf/flink-conf.yaml中的taskmanager.numberOfTaskSlots设置的少一点。本身资源不多。
*熙:
同一个operator的subtask不能分配到同一个taskmanager的同一个solt中
讲师回复:
是的
**明:
请问TaskManager的slot个数和算子的并行度有关系么?
讲师回复:
比如你有2个TaskManager,每个TaskManager有3个slot,那么你算子的并行度最大只能是6.
**彬:
并行度是不是就是同时进行的slot的数量,slot是线程还是进程,我理解slot应该是线程。相当于spark的task。按照课程的描述,如果整个集群slot有10个。提交了一个任务占了10个slot。那么后续的任务提交的时候是直接报错呢。还是会等。这好像跟spark的task有区别,spark的task是根据指定的并行度来动态启动task的。而slot是集群初始化的时候规定死的。flink有没有动态规划slot的机制呢。希望老师对以上问题做解答和勘误。
讲师回复:
首先明确一个概念,slot是资源的集合比如cpu和内存。当然他运行的是线程。如果说你整个集群有10个slot完全被占用,后续任务提交会处于CREATED或者SCHEDULED状态,长时间没有slot会失败。 第二个问题思考的非常好,这个动态指定slot的功能已经有人提出并且实现了:https://cwiki.apache.org/confluence/display/FLINK/FLIP-56%3A+Dynamic+Slot+Allocation
*华:
设置并行度那里,执行环境级别和系统级别的设置,是对所有算子都有效的吗?
讲师回复:
是的,是对所有的算子都有效。
**琳:
请问一下,slot和机器cpu的关系应该怎么理解啊?安逻辑来说,slot跟CPU没有直接关系,但实际创建集群时,现场40cpu,我们一般都是指定40*80%=32个slot。不知道是否合理。辛苦辛苦
讲师回复:
Slot 就是资源的最小单位,经验上讲 Slot 的数量与 CPU-core 的数量一致为好。但考虑到超线程,可以 slot=2*cpuCore。
*朋:
请问一下,分布式缓存和状态的区别,感觉分布式缓存能实现的场景,用state都能实现啊,而且分布式缓存还要存文件,效率是不是也不如state
讲师回复:
还是会有应用的场景,是 Flink 提供的一种可能性。因为分布式缓存从 Hadoop 时期就被实现了,已经默认成大数据框架必备能力了。
*铁:
老师,这个并行度和flink的Slot指定数量有关么?如果指定taskmanager.numberOfTaskSlots:3,然后我们有2个taskmanager节点,那某个任务并行度是最高只能设置成2 * 3 = 6么?我这么理解对么?
讲师回复:
同学,你好,你的理解是对的
**将:
请问一下,Spark里面的广播机制与这里的分布式缓存之间是什么关系呢?有什么异同点?感觉在传递全局变量上,他们很相似。
讲师回复:
非常类型,都是将数据广播出去提供给其他task 使用
**新:
失败率是怎么计算的啊?
讲师回复:
每个时间间隔除以失败次数。
**保:
打卡
zrmmpy:
拉钩的课程是真的“硬菜”,打卡。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2042-%E7%AC%AC07%E8%AE%B2Flink-%E5%B8%B8%E8%A7%81%E6%A0%B8%E5%BF%83%E6%A6%82%E5%BF%B5%E5%88%86%E6%9E%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


