Flink系列-第23讲:Mock Kafka 消息并发送
本课时主要讲解 Kafka 的一些核心概念,以及模拟消息并发送。
大数据消息中间件的王者——Kafka
在上一课时中提过在实时计算的场景下,我们绝大多数的数据源都是消息系统。所以,一个强大的消息中间件来支撑高达几十万的 QPS,以及海量数据存储就显得极其重要。
Kafka 从众多的消息中间件中脱颖而出,主要是因为高吞吐、低延迟的特点;另外基于 Kafka 的生态越来越完善,各个实时处理框架包括 Flink 在消息处理上都会优先进行支持。在第 14 课时“Flink Exactly-once 实现原理解析”中提到 Flink 和 Kafka 结合实现端到端精确一次语义的原理。
Kafka 从众多的消息中间件中脱颖而出,已经成为大数据生态系统中必不可少的一员,主要的特性包括:
-
高吞吐
-
低延迟
-
高容错
-
可靠性
-
生态丰富
为了接下来更好地理解和使用 Kafka,我们首先来看一下 Kafka 中的核心概念和基本入门。
Kafka 核心概念
Kafka 是一个消息队列,生产者向消息队列中写入数据,消费者从队列中获取数据并进行消费。作为一个企业级的消息中间件,Kafka 会支持庞大的业务,不同的业务会有多个队列,我们用 Topic 来给队列命名,在使用 Kafka 时必须指定 Topic。
我们可以认为一个 Topic 就是一个队列,每个 Topic 又会被分成多个 Partition,这样做是为了横向扩展,提高吞吐量。
Kafka 中每个 Partition 都对应一个 Broker,一个 Broker 可以管理多个 Partition。举个例子,假如 Kafka 的某个 Topic 有 10 个 Partition、2 个 Broker,那么每个 Broker 就会管理 5 个 Partition。我们可以把 Partition 简单理解为一个文件,在接收生产者的数据时,需要将数据动态追加到 Partition 上。
生产者会决定将数据写入哪个 Partition,消费者自己维护消费数据的位置,我们称为 Offset。
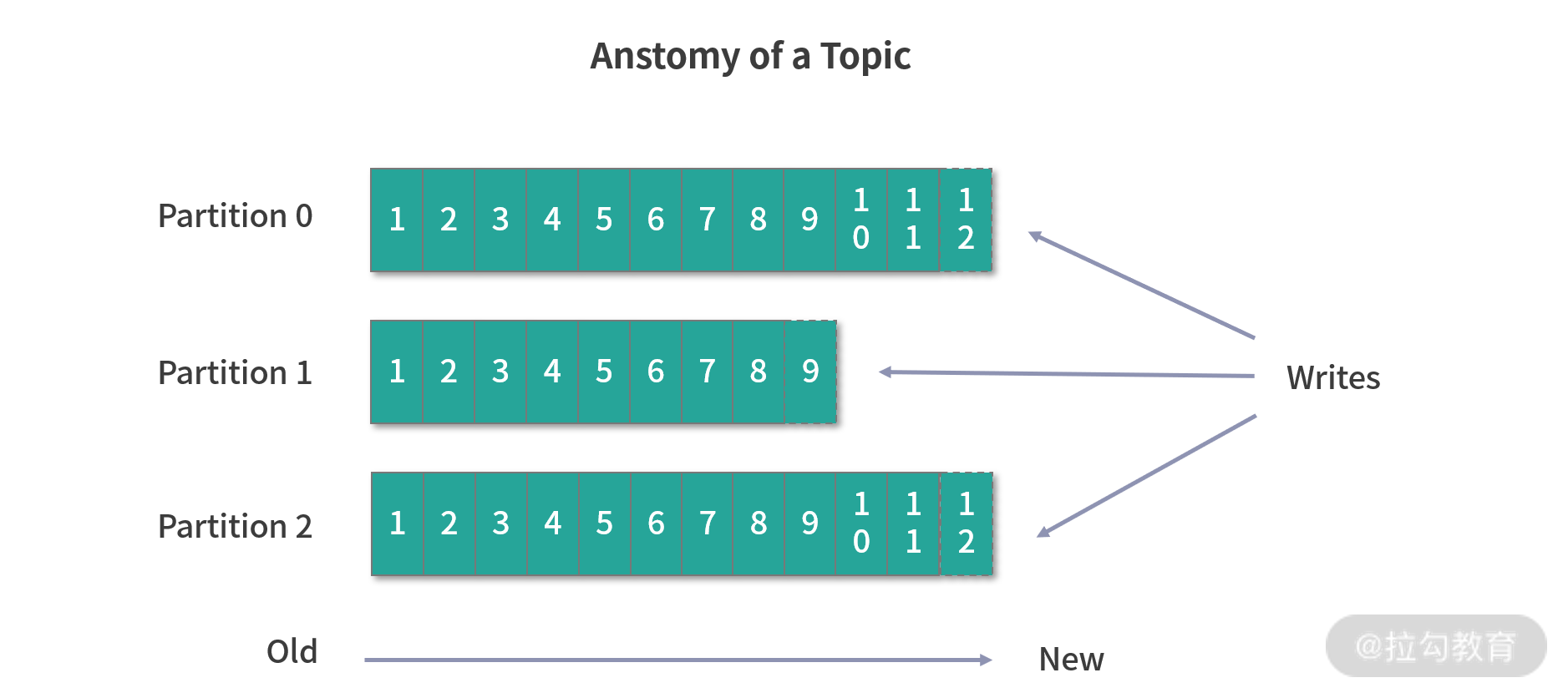
同时,Kafka 提供了时间策略对过期的消息进行处理。
Kafka 的每个消费者都有一个消费组来进行标识,同一个消费组的不同实例分布在多个进程或者多个机器上。
Kafka 的源数据存储在 ZooKeeper 中,其中包含 Broker、Topic、Partition 等信息。在 0.8 版本之前,Kafka 还会将消费的 Offset 存储在 ZooKeeper 中。
此外,ZooKeeper 还负责集群的 Broker 选举,以及所有 Topic 的 Partition 副本信息等。
Kafka 连接 Flink
我们在第 12 课时“Flink 常用的 Source 和 Connector”中提过,Flink 中支持了比较丰富的用来连接第三方的连接器,Kafka Connector 是 Flink 支持的各种各样的连接器中比较完善的之一。
Flink 提供了专门的 Kafka 连接器,向 Kafka Topic 中读取或者写入数据。Flink Kafka Consumer 集成了 Flink 的 Checkpoint 机制,可提供 exactly-once 的处理语义。为此,Flink 并不完全依赖于跟踪 Kafka 消费组的偏移量,而是在内部跟踪和检查偏移量。
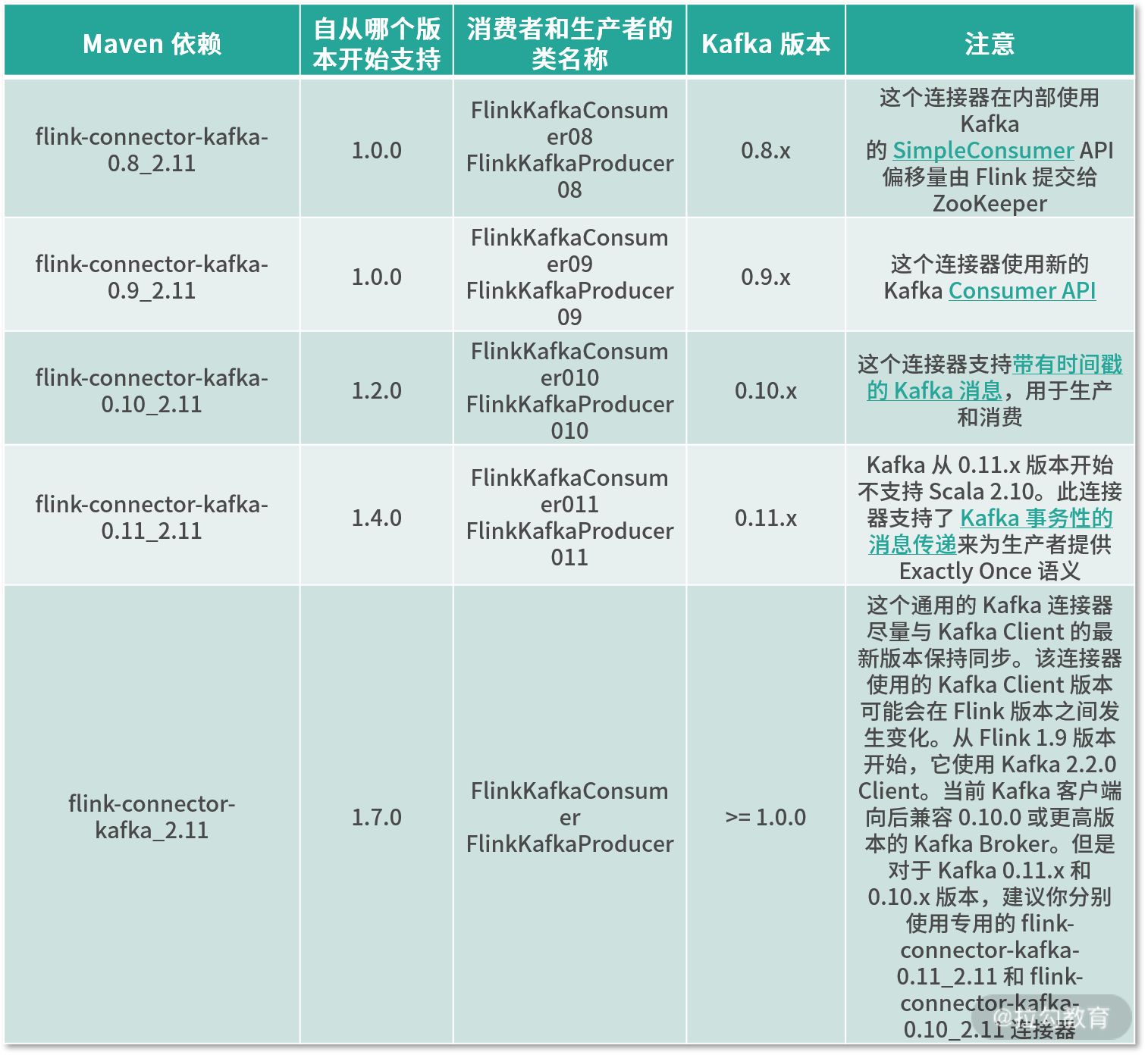
同时也提过,我们在使用 Kafka 连接器时需要引用相对应的 Jar 包依赖。对于某些连接器比如 Kafka 是有版本要求的,一定要去官方网站找到对应的依赖版本。
我在下表中给出了不同版本的 Kafka,以及对应的 Connector 关系:
Kafka 本地环境搭建
我们在本地环境搭建一个 Kafka_2.11-2.1.0 版本的 Kafka 单机环境,然后模拟一些数据写入到队列中。
我们可以在这里下载对应版本的 Kafka,把压缩包进行解压,然后使用下面的命令启动单机版本的 Kafka。
解压:
> tar -xzf kafka_2.11-2.1.0.tgz
> cd kafka_2.11-2.1.0
启动 ZooKeeper 和 Kafka Server:
启动ZK:nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
启动Server:
nohup bin/kafka-server-start.sh config/server.properties &
创建一个名为 test 的 Topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Kafka Producer
首先我们需要新增一个依赖,然后向名为 test 的 Topic 中写入数据。
新增 Maven 依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
向 test 这个 Topic 中写入数据:
public class KafkaProducer {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.enableCheckpointing(5000);
DataStreamSource<String> text = env.addSource(new MyNoParalleSource()).setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
// 2.0 配置 KafkaProducer
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<String>(
"127.0.0.1:9092", //broker 列表
"test", //topic
new SimpleStringSchema()); // 消息序列化
<span class="hljs-comment">//写入 Kafka 时附加记录的事件时间戳</span>
producer.setWriteTimestampToKafka(<span class="hljs-keyword">true</span>);
text.addSink(producer);
env.execute();
}
}
需要注意的是,我们这里使用了一个自定义的 MyNoParalleSource 类,该类使用了 Flink 提供的自定义 Source 方法,该方法会源源不断地产生一些测试数据,代码如下:
public class MyNoParalleSource implements SourceFunction<String> {
//private long count = 1L;
private boolean isRunning = true;
/**
* 主要的方法
* 启动一个source
* 大部分情况下,都需要在这个run方法中实现一个循环,这样就可以循环产生数据了
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<String> ctx) throws Exception {
while(isRunning){
//图书的排行榜
List<String> books = new ArrayList<>();
books.add("Pyhton从入门到放弃");//10
books.add("Java从入门到放弃");//8
books.add("Php从入门到放弃");//5
books.add("C++从入门到放弃");//3
books.add("Scala从入门到放弃");
int i = new Random().nextInt(5);
ctx.collect(books.get(i));
//每2秒产生一条数据
Thread.sleep(2000);
}
}
//取消一个cancel的时候会调用的方法
@Override
public void cancel() {
isRunning = false;
}
}
我们在后面会使用这个方法来模拟生产中的订单数据,并进行接续处理;然后通过下面的命令就可以查看本地 Kafka 的 test 这个 Topic 中的数据:
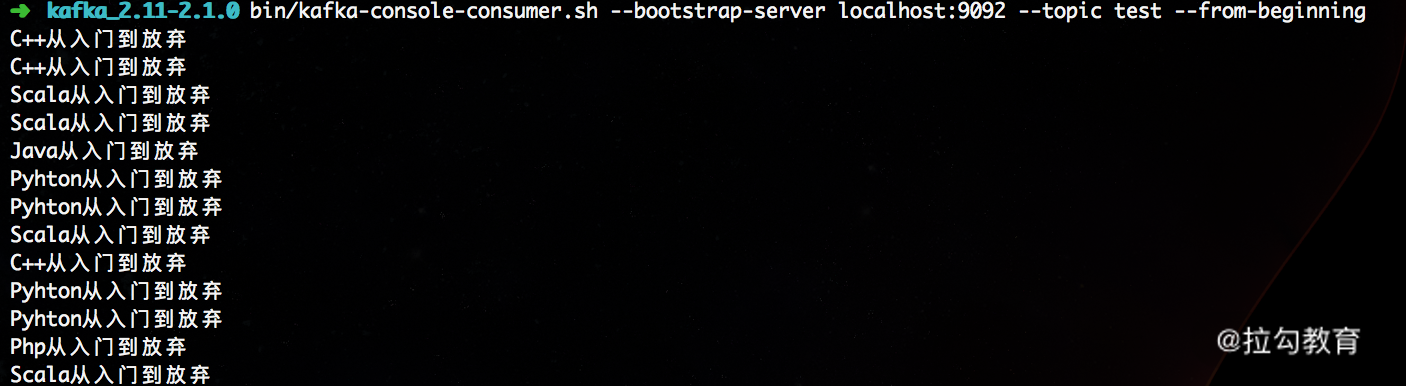
至此,我们就成功地向 Kafka 中写入数据了。
源码解析
FlinkKafkaProducer 的代码十分简洁,首先继承了 TwoPhaseCommitSinkFunction,在第 14 课时“Flink Exactly-once 实现原理解析”中详细讲解过,这个类是 Flink 和 Kafka 结合实现精确一次处理语义的关键。
FlinkProducer 提供了 6 种构造方法,我们可以根据需要选择不同的构造函数:
public FlinkKafkaProducer011(
String brokerList,
String topicId,
SerializationSchema<IN> serializationSchema);
public FlinkKafkaProducer011(
String topicId,
SerializationSchema<IN> serializationSchema,
Properties producerConfig);
public FlinkKafkaProducer011(
String topicId,
SerializationSchema<IN> serializationSchema,
Properties producerConfig,
Optional<FlinkKafkaPartitioner<IN>> customPartitioner);
public FlinkKafkaProducer011(
String brokerList,
String topicId,
KeyedSerializationSchema<IN> serializationSchema);
public FlinkKafkaProducer011(
String topicId,
KeyedSerializationSchema<IN> serializationSchema,
Properties producerConfig);
public FlinkKafkaProducer011(
String topicId,
KeyedSerializationSchema<IN> serializationSchema,
Properties producerConfig,
Semantic semantic);
public FlinkKafkaProducer011(
String defaultTopicId,
KeyedSerializationSchema<IN> serializationSchema,
Properties producerConfig,
Optional<FlinkKafkaPartitioner<IN>> customPartitioner);
public FlinkKafkaProducer011(
String defaultTopicId,
KeyedSerializationSchema<IN> serializationSchema,
Properties producerConfig,
Optional<FlinkKafkaPartitioner<IN>> customPartitioner,
Semantic semantic,
int kafkaProducersPoolSize);
这里有个特别需要注意的属性:FlinkKafkaPartitioner,这个类定义了数据写入 Kafka 的规则,如果用户没有指定,则会默认 FlinkFixedPartitioner,核心处理逻辑如下:
public class FlinkFixedPartitioner<T> extends FlinkKafkaPartitioner<T> {
...
@Override
public int partition(T record, byte[] key, byte[] value, String targetTopic, int[] partitions) {
Preconditions.checkArgument(
partitions != null && partitions.length > 0,
"Partitions of the target topic is empty.");
return partitions[parallelInstanceId % partitions.length];
}
...
}
此外,FlinkProducer 还封装了 beginTransaction、preCommit、commit、abort 等方法,这几个方法便是实现精确一次处理语义的关键。
总结
本课时我们介绍了 Kafka 的核心概念,可以对其有一个全面的了解,并且还搭建了单机版的 Kafka 环境,使用自定义的数据源向 Kafka 中写入数据,最后从源码层面介绍了 FlinkProducer 的核心实现。通过本课时的学习,你可以对 Kafka 有全面的了解,并且能够使用 Kafka 连接器发送消息。
精选评论
**6496:
books的初始化应该放到while的外面吧
*强:
赞~
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2058-%E7%AC%AC23%E8%AE%B2Mock-Kafka-%E6%B6%88%E6%81%AF%E5%B9%B6%E5%8F%91%E9%80%81/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


