Flink系列-第24讲:Flink 消费 Kafka 数据业务开发
在上一课时中我们提过在实时计算的场景下,绝大多数的数据源都是消息系统,而 Kafka 从众多的消息中间件中脱颖而出,主要是因为高吞吐、低延迟的特点;同时也讲了 Flink 作为生产者像 Kafka 写入数据的方式和代码实现。这一课时我们将从以下几个方面介绍 Flink 消费 Kafka 中的数据方式和源码实现。
Flink 如何消费 Kafka
Flink 在和 Kafka 对接的过程中,跟 Kafka 的版本是强相关的。上一课时也提到了,我们在使用 Kafka 连接器时需要引用相对应的 Jar 包依赖,对于某些连接器比如 Kafka 是有版本要求的,一定要去官方网站找到对应的依赖版本。
我们本地的 Kafka 版本是 2.1.0,所以需要对应的类是 FlinkKafkaConsumer。首先需要在 pom.xml 中引入 jar 包依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
下面将对 Flink 消费 Kafka 数据的方式进行分类讲解。
消费单个 Topic
上一课时我们在本地搭建了 Kafka 环境,并且手动创建了名为 test 的 Topic,然后向名为 test 的 Topic 中写入了数据。
那么现在我们要消费这个 Topic 中的数据,该怎么做呢?
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.enableCheckpointing(5000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
// 如果你是0.8版本的Kafka,需要配置
//properties.setProperty("zookeeper.connect", "localhost:2181");
//设置消费组
properties.setProperty("group.id", "group_test");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("test", new SimpleStringSchema(), properties);
//设置从最早的ffset消费
consumer.setStartFromEarliest();
//还可以手动指定相应的 topic, partition,offset,然后从指定好的位置开始消费
//HashMap<KafkaTopicPartition, Long> map = new HashMap<>();
//map.put(new KafkaTopicPartition("test", 1), 10240L);
//假如partition有多个,可以指定每个partition的消费位置
//map.put(new KafkaTopicPartition("test", 2), 10560L);
//然后各个partition从指定位置消费
//consumer.setStartFromSpecificOffsets(map);
env.addSource(consumer).flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
System.out.println(value);
}
});
env.execute("start consumer...");
}
在设置消费 Kafka 中的数据时,可以显示地指定从某个 Topic 的每一个 Partition 中进行消费。
消费多个 Topic
我们的业务中会有这样的情况,同样的数据根据类型不同发送到了不同的 Topic 中,比如线上的订单数据根据来源不同分别发往移动端和 PC 端两个 Topic 中。但是我们不想把同样的代码复制一份,需重新指定一个 Topic 进行消费,这时候应该怎么办呢?
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
// 如果你是0.8版本的Kafka,需要配置
//properties.setProperty("zookeeper.connect", "localhost:2181");
//设置消费组
properties.setProperty("group.id", "group_test");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("test", new SimpleStringSchema(), properties);
ArrayList<String> topics = new ArrayList<>();
topics.add("test_A");
topics.add("test_B");
// 传入一个 list,完美解决了这个问题
FlinkKafkaConsumer<Tuple2<String, String>> consumer = new FlinkKafkaConsumer<>(topics, new SimpleStringSchema(), properties);
...
我们可以传入一个 list 来解决消费多个 Topic 的问题,如果用户需要区分两个 Topic 中的数据,那么需要在发往 Kafka 中数据新增一个字段,用来区分来源。
消息序列化
我们在上述消费 Kafka 消息时,都默认指定了消息的序列化方式,即 SimpleStringSchema。这里需要注意的是,在我们使用 SimpleStringSchema 的时候,返回的结果中只有原数据,没有 topic、parition 等信息,这时候可以自定义序列化的方式来实现自定义返回数据的结构。
public class CustomDeSerializationSchema implements KafkaDeserializationSchema<ConsumerRecord<String, String>> {
//是否表示流的最后一条元素,设置为false,表示数据会源源不断地到来
@Override
public boolean isEndOfStream(ConsumerRecord<String, String> nextElement) {
return false;
}
//这里返回一个ConsumerRecord<String,String>类型的数据,除了原数据还包括topic,offset,partition等信息
@Override
public ConsumerRecord<String, String> deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
return new ConsumerRecord<String, String>(
record.topic(),
record.partition(),
record.offset(),
new String(record.key()),
new String(record.value())
);
}
//指定数据的输入类型
@Override
public TypeInformation<ConsumerRecord<String, String>> getProducedType() {
return TypeInformation.of(new TypeHint<ConsumerRecord<String, String>>(){});
}
}
这里自定义了 CustomDeSerializationSchema 信息,就可以直接使用了。
Parition 和 Topic 动态发现
在很多场景下,随着业务的扩展,我们需要对 Kafka 的分区进行扩展,为了防止新增的分区没有被及时发现导致数据丢失,消费者必须要感知 Partition 的动态变化,可以使用 FlinkKafkaConsumer 的动态分区发现实现。
我们只需要指定下面的配置,即可打开动态分区发现功能:每隔 10ms 会动态获取 Topic 的元数据,对于新增的 Partition 会自动从最早的位点开始消费数据。
properties.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS, "10");
如果业务场景需要我们动态地发现 Topic,可以指定 Topic 的正则表达式:
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(Pattern.compile("^test_([A-Za-z0-9]*)$"), new SimpleStringSchema(), properties);
Flink 消费 Kafka 设置 offset 的方法
Flink 消费 Kafka 需要指定消费的 offset,也就是偏移量。Flink 读取 Kafka 的消息有五种消费方式:
-
指定 Topic 和 Partition
-
从最早位点开始消费
-
从指定时间点开始消费
-
从最新的数据开始消费
-
从上次消费位点开始消费
/**
* Flink从指定的topic和parition中指定的offset开始
*/
Map<KafkaTopicPartition, Long> offsets = new HashedMap();
offsets.put(new KafkaTopicPartition("test", 0), 10000L);
offsets.put(new KafkaTopicPartition("test", 1), 20000L);
offsets.put(new KafkaTopicPartition("test", 2), 30000L);
consumer.setStartFromSpecificOffsets(offsets);
/**
* Flink从topic中最早的offset消费
*/
consumer.setStartFromEarliest();
/**
* Flink从topic中指定的时间点开始消费
*/
consumer.setStartFromTimestamp(1559801580000l);
/**
* Flink从topic中最新的数据开始消费
*/
consumer.setStartFromLatest();
/**
* Flink从topic中指定的group上次消费的位置开始消费,所以必须配置group.id参数
*/
consumer.setStartFromGroupOffsets();
源码解析
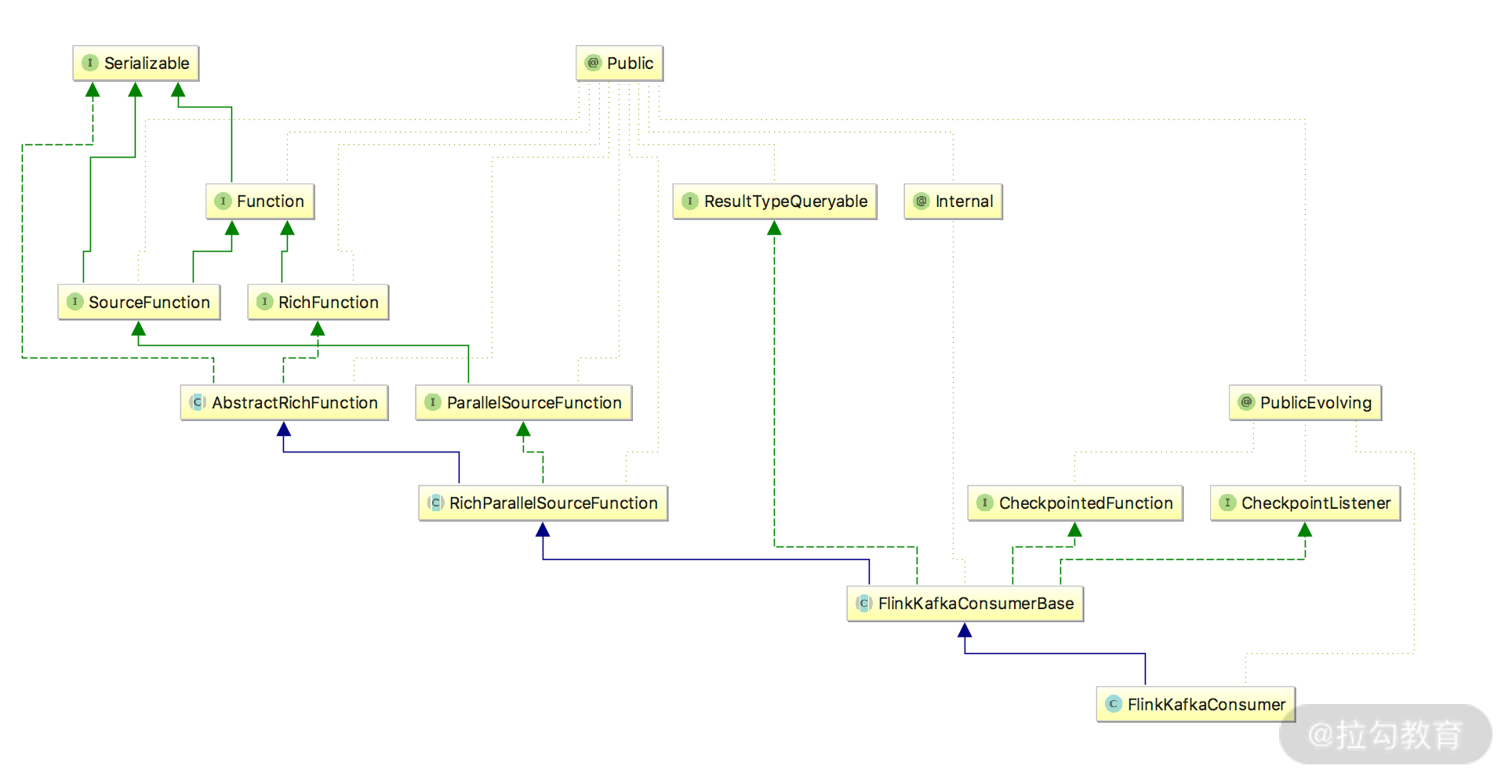
从上面的类图可以看出,FlinkKafkaConsumer 继承了 FlinkKafkaConsumerBase,而 FlinkKafkaConsumerBase 最终是对 SourceFunction 进行了实现。
整体的流程:FlinkKafkaConsumer 首先创建了 KafkaFetcher 对象,然后 KafkaFetcher 创建了 KafkaConsumerThread 和 Handover,KafkaConsumerThread 负责直接从 Kafka 中读取 msg,并交给 Handover,然后 Handover 将 msg 传递给 KafkaFetcher.emitRecord 将消息发出。
因为 FlinkKafkaConsumerBase 实现了 RichFunction 接口,所以当程序启动的时候,会首先调用 FlinkKafkaConsumerBase.open 方法:
public void open(Configuration configuration) throws Exception {
// 指定offset的提交方式
this.offsetCommitMode = OffsetCommitModes.fromConfiguration(
getIsAutoCommitEnabled(),
enableCommitOnCheckpoints,
((StreamingRuntimeContext) getRuntimeContext()).isCheckpointingEnabled());
// 创建分区发现器
this.partitionDiscoverer = createPartitionDiscoverer(
topicsDescriptor,
getRuntimeContext().getIndexOfThisSubtask(),
getRuntimeContext().getNumberOfParallelSubtasks());
this.partitionDiscoverer.open();
subscribedPartitionsToStartOffsets = new HashMap<>();
final List<KafkaTopicPartition> allPartitions = partitionDiscoverer.discoverPartitions();
if (restoredState != null) {
for (KafkaTopicPartition partition : allPartitions) {
if (!restoredState.containsKey(partition)) {
restoredState.put(partition, KafkaTopicPartitionStateSentinel.EARLIEST_OFFSET);
}
}
for (Map.Entry<KafkaTopicPartition, Long> restoredStateEntry : restoredState.entrySet()) {
if (!restoredFromOldState) {
<span class="hljs-keyword">if</span> (KafkaTopicPartitionAssigner.assign(
restoredStateEntry.getKey(), getRuntimeContext().getNumberOfParallelSubtasks())
== getRuntimeContext().getIndexOfThisSubtask()){
subscribedPartitionsToStartOffsets.put(restoredStateEntry.getKey(), restoredStateEntry.getValue());
}
} <span class="hljs-keyword">else</span> {
subscribedPartitionsToStartOffsets.put(restoredStateEntry.getKey(), restoredStateEntry.getValue());
}
}
<span class="hljs-keyword">if</span> (filterRestoredPartitionsWithCurrentTopicsDescriptor) {
subscribedPartitionsToStartOffsets.entrySet().removeIf(entry -> {
<span class="hljs-keyword">if</span> (!topicsDescriptor.isMatchingTopic(entry.getKey().getTopic())) {
LOG.warn(
<span class="hljs-string">"{} is removed from subscribed partitions since it is no longer associated with topics descriptor of current execution."</span>,
entry.getKey());
<span class="hljs-keyword">return</span> <span class="hljs-keyword">true</span>;
}
<span class="hljs-keyword">return</span> <span class="hljs-keyword">false</span>;
});
}
LOG.info(<span class="hljs-string">"Consumer subtask {} will start reading {} partitions with offsets in restored state: {}"</span>,
getRuntimeContext().getIndexOfThisSubtask(), subscribedPartitionsToStartOffsets.size(), subscribedPartitionsToStartOffsets);
} else {
<span class="hljs-keyword">switch</span> (startupMode) {
<span class="hljs-keyword">case</span> SPECIFIC_OFFSETS:
<span class="hljs-keyword">if</span> (specificStartupOffsets == <span class="hljs-keyword">null</span>) {
<span class="hljs-keyword">throw</span> <span class="hljs-keyword">new</span> IllegalStateException(
<span class="hljs-string">"Startup mode for the consumer set to "</span> + StartupMode.SPECIFIC_OFFSETS +
<span class="hljs-string">", but no specific offsets were specified."</span>);
}
<span class="hljs-keyword">for</span> (KafkaTopicPartition seedPartition : allPartitions) {
Long specificOffset = specificStartupOffsets.get(seedPartition);
<span class="hljs-keyword">if</span> (specificOffset != <span class="hljs-keyword">null</span>) {
subscribedPartitionsToStartOffsets.put(seedPartition, specificOffset - <span class="hljs-number">1</span>);
} <span class="hljs-keyword">else</span> {
subscribedPartitionsToStartOffsets.put(seedPartition, KafkaTopicPartitionStateSentinel.GROUP_OFFSET);
}
}
<span class="hljs-keyword">break</span>;
<span class="hljs-keyword">case</span> TIMESTAMP:
<span class="hljs-keyword">if</span> (startupOffsetsTimestamp == <span class="hljs-keyword">null</span>) {
<span class="hljs-keyword">throw</span> <span class="hljs-keyword">new</span> IllegalStateException(
<span class="hljs-string">"Startup mode for the consumer set to "</span> + StartupMode.TIMESTAMP +
<span class="hljs-string">", but no startup timestamp was specified."</span>);
}
<span class="hljs-keyword">for</span> (Map.Entry<KafkaTopicPartition, Long> partitionToOffset
: fetchOffsetsWithTimestamp(allPartitions, startupOffsetsTimestamp).entrySet()) {
subscribedPartitionsToStartOffsets.put(
partitionToOffset.getKey(),
(partitionToOffset.getValue() == <span class="hljs-keyword">null</span>)
KafkaTopicPartitionStateSentinel.LATEST_OFFSET
: partitionToOffset.getValue() - <span class="hljs-number">1</span>);
}
<span class="hljs-keyword">break</span>;
<span class="hljs-keyword">default</span>:
<span class="hljs-keyword">for</span> (KafkaTopicPartition seedPartition : allPartitions) {
subscribedPartitionsToStartOffsets.put(seedPartition, startupMode.getStateSentinel());
}
}
<span class="hljs-keyword">if</span> (!subscribedPartitionsToStartOffsets.isEmpty()) {
<span class="hljs-keyword">switch</span> (startupMode) {
<span class="hljs-keyword">case</span> EARLIEST:
LOG.info(<span class="hljs-string">"Consumer subtask {} will start reading the following {} partitions from the earliest offsets: {}"</span>,
getRuntimeContext().getIndexOfThisSubtask(),
subscribedPartitionsToStartOffsets.size(),
subscribedPartitionsToStartOffsets.keySet());
<span class="hljs-keyword">break</span>;
<span class="hljs-keyword">case</span> LATEST:
LOG.info(<span class="hljs-string">"Consumer subtask {} will start reading the following {} partitions from the latest offsets: {}"</span>,
getRuntimeContext().getIndexOfThisSubtask(),
subscribedPartitionsToStartOffsets.size(),
subscribedPartitionsToStartOffsets.keySet());
<span class="hljs-keyword">break</span>;
<span class="hljs-keyword">case</span> TIMESTAMP:
LOG.info(<span class="hljs-string">"Consumer subtask {} will start reading the following {} partitions from timestamp {}: {}"</span>,
getRuntimeContext().getIndexOfThisSubtask(),
subscribedPartitionsToStartOffsets.size(),
startupOffsetsTimestamp,
subscribedPartitionsToStartOffsets.keySet());
<span class="hljs-keyword">break</span>;
<span class="hljs-keyword">case</span> SPECIFIC_OFFSETS:
LOG.info(<span class="hljs-string">"Consumer subtask {} will start reading the following {} partitions from the specified startup offsets {}: {}"</span>,
getRuntimeContext().getIndexOfThisSubtask(),
subscribedPartitionsToStartOffsets.size(),
specificStartupOffsets,
subscribedPartitionsToStartOffsets.keySet());
List<KafkaTopicPartition> partitionsDefaultedToGroupOffsets = <span class="hljs-keyword">new</span> ArrayList<>(subscribedPartitionsToStartOffsets.size());
<span class="hljs-keyword">for</span> (Map.Entry<KafkaTopicPartition, Long> subscribedPartition : subscribedPartitionsToStartOffsets.entrySet()) {
<span class="hljs-keyword">if</span> (subscribedPartition.getValue() == KafkaTopicPartitionStateSentinel.GROUP_OFFSET) {
partitionsDefaultedToGroupOffsets.add(subscribedPartition.getKey());
}
}
<span class="hljs-keyword">if</span> (partitionsDefaultedToGroupOffsets.size() > <span class="hljs-number">0</span>) {
LOG.warn(<span class="hljs-string">"Consumer subtask {} cannot find offsets for the following {} partitions in the specified startup offsets: {}"</span> +
<span class="hljs-string">"; their startup offsets will be defaulted to their committed group offsets in Kafka."</span>,
getRuntimeContext().getIndexOfThisSubtask(),
partitionsDefaultedToGroupOffsets.size(),
partitionsDefaultedToGroupOffsets);
}
<span class="hljs-keyword">break</span>;
<span class="hljs-keyword">case</span> GROUP_OFFSETS:
LOG.info(<span class="hljs-string">"Consumer subtask {} will start reading the following {} partitions from the committed group offsets in Kafka: {}"</span>,
getRuntimeContext().getIndexOfThisSubtask(),
subscribedPartitionsToStartOffsets.size(),
subscribedPartitionsToStartOffsets.keySet());
}
} <span class="hljs-keyword">else</span> {
LOG.info(<span class="hljs-string">"Consumer subtask {} initially has no partitions to read from."</span>,
getRuntimeContext().getIndexOfThisSubtask());
}
}
}
对 Kafka 中的 Topic 和 Partition 的数据进行读取的核心逻辑都在 run 方法中:
public void run(SourceContext<T> sourceContext) throws Exception {
if (subscribedPartitionsToStartOffsets == null) {
throw new Exception("The partitions were not set for the consumer");
}
this.successfulCommits = this.getRuntimeContext().getMetricGroup().counter(COMMITS_SUCCEEDED_METRICS_COUNTER);
this.failedCommits = this.getRuntimeContext().getMetricGroup().counter(COMMITS_FAILED_METRICS_COUNTER);
final int subtaskIndex = this.getRuntimeContext().getIndexOfThisSubtask();
this.offsetCommitCallback = new KafkaCommitCallback() {
@Override
public void onSuccess() {
successfulCommits.inc();
}
@Override
public void onException(Throwable cause) {
LOG.warn(String.format("Consumer subtask %d failed async Kafka commit.", subtaskIndex), cause);
failedCommits.inc();
}
};
if (subscribedPartitionsToStartOffsets.isEmpty()) {
sourceContext.markAsTemporarilyIdle();
}
LOG.info(“Consumer subtask {} creating fetcher with offsets {}.",
getRuntimeContext().getIndexOfThisSubtask(), subscribedPartitionsToStartOffsets);
this.kafkaFetcher = createFetcher(
sourceContext,
subscribedPartitionsToStartOffsets,
periodicWatermarkAssigner,
punctuatedWatermarkAssigner,
(StreamingRuntimeContext) getRuntimeContext(),
offsetCommitMode,
getRuntimeContext().getMetricGroup().addGroup(KAFKA_CONSUMER_METRICS_GROUP),
useMetrics);
if (!running) {
return;
}
if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) {
kafkaFetcher.runFetchLoop();
} else {
runWithPartitionDiscovery();
}
}
Flink 消费 Kafka 数据代码
上面介绍了 Flink 消费 Kafka 的方式,以及消息序列化的方式,同时介绍了分区和 Topic 的动态发现方法,那么回到我们的项目中来,消费 Kafka 数据的完整代码如下:
public class KafkaConsumer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.enableCheckpointing(5000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
//设置消费组
properties.setProperty("group.id", "group_test");
properties.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS, "10");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("test", new SimpleStringSchema(), properties);
//设置从最早的ffset消费
consumer.setStartFromEarliest();
env.addSource(consumer).flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
System.out.println(value);
}
});
env.execute("start consumer...");
}
}
我们可以直接右键运行代码,在控制台中可以看到数据的正常打印,如下图所示:
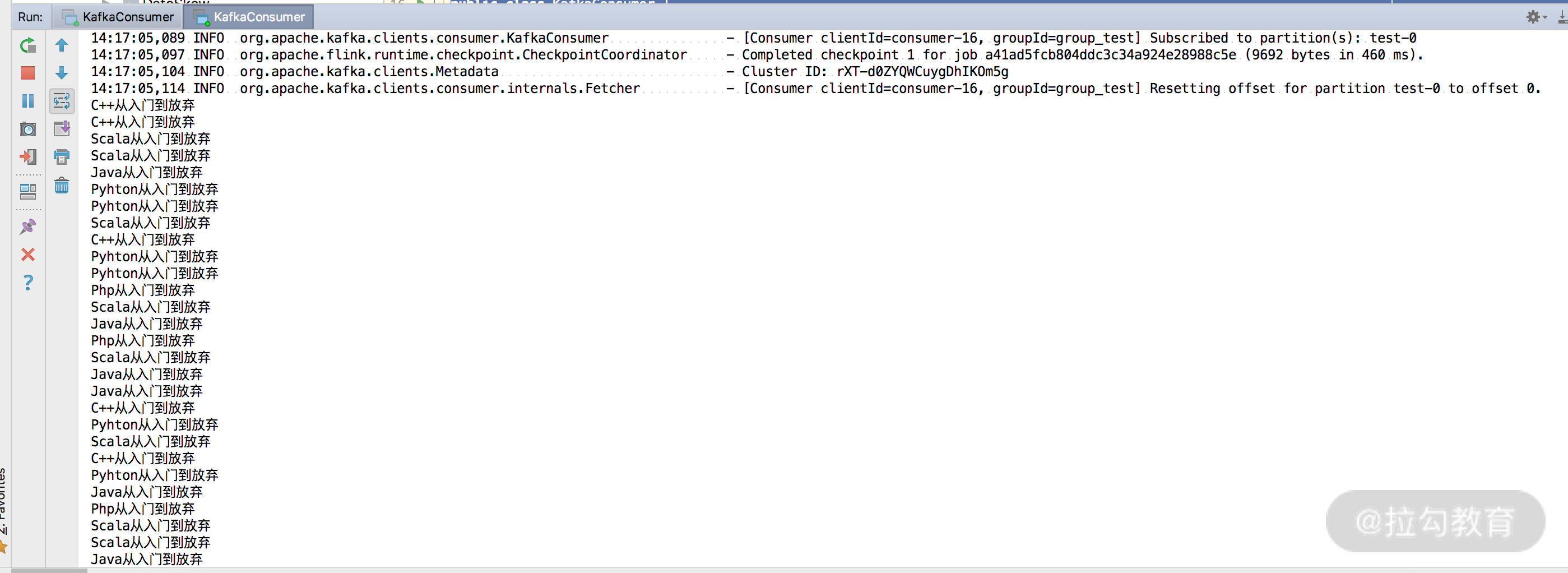
通过代码可知,我们之前发往 Kafka 的消息被完整地打印出来了。
总结
这一课时介绍了 Flink 消费 Kafka 的方式,比如从常用的指定单个或者多个 Topic、消息的序列化、分区的动态发现等,还从源码上介绍了 Flink 消费 Kafka 的原理。通过本课时的学习,相信你可以对 Flink 消费 Kafka 有一个较为全面地了解,根据业务场景可以正确选择消费的方式和配置。
精选评论
**6513:
项目中也是用main方法作为入口吗?有集成springboot的案例吗
讲师回复:
在编写Flink代码时,尽量避免使用spring类的框架,因为没有必要。只要依赖Flink必要的包和一些工具类即可。
**冰:
老师,这里可以从指定offset消费,怎么在程序终止或停止时保存offset,以便启时使用了?
讲师回复:
如果实际情况需要保存位点,那么一般是自己管理位点,每次停止重启后从自己管理的位点消费,比如你可以存储在mysql中,自己去读取
**良:
我是用flink消费Kafka从指定的topic和partition中指定的offset处开始消费,实际结果与预期不一致,消费的分区对不上是啥原因呢?示例代码:Mapoffsets.put(new KafkaTopicPartition(topic, 0), 1L);offsets.put(new KafkaTopicPartition(topic, 1), 2L);offsets.put(new KafkaTopicPartition(topic, 2), 3L);consumer.setStartFromSpecificOffsets(offsets);返回结果:ConsumerRecord(topic=new-topic-config-test, partition=0, offset=10105849, key=, value=Python从入门到放弃!ConsumerRecord(topic=new-topic-config-test, partition=3, offset=10107121, key=, value=Python从入门到放弃!ConsumerRecord(topic=new-topic-config-test, partition=2, offset=10102806, key=, value=Java从入门到放弃!
讲师回复:
从两个原因查询,第一看下并行度的设置要和kafka分区设置保持一致。第二,要保证kafka4个分区都有数据。
*轩:
请问哪里可以下载项目用的数据,不是源码
讲师回复:
在项目中有数据,也可以自己造一些数据
**7324:
flink如何将key相同的数据写入到kafka的同一个partition呢?
讲师回复:
你可以自定义自己的kafka分区器,可以查一下FlinkKafkaPartitioner的用法,但是一般我们不会这么用,如果你需要自定义写入kafka的分区器,要保证数据尽量均匀,不要引起kafka端的数据倾斜
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2059-%E7%AC%AC24%E8%AE%B2Flink-%E6%B6%88%E8%B4%B9-Kafka-%E6%95%B0%E6%8D%AE%E4%B8%9A%E5%8A%A1%E5%BC%80%E5%8F%91/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


