Flink系列-第25讲:Flink 中 watermark 的定义和使用
第 08 课时我们提过窗口和时间的概念,Flink 框架支持事件时间、摄入时间和处理时间三种。Watermark(水印)的出现是用于处理数据从 Source 产生,再到转换和输出,在这个过程中由于网络和反压的原因导致了消息乱序问题。
那么在实际的开发过程中,如何正确地使用 Watermark 呢?
使用 Watermark 必知必会
Watermark 和事件时间
事件时间(Event Time)是数据产生的时间,这个时间一般在数据中自带,由消息的生产者生成。例如,我们的上游是 Kafka 消息,那么每个生成的消息中自带一个时间戳代表该条数据的产生时间,这个时间是固定的,从数据的诞生开始就一直携带。所以,我们在处理消息乱序的情况时,会用 EventTime 和 Watermark 进行配合使用。
我们只需要一行代码,就可以在代码中指定 Flink 系统使用的时间类型为 EventTime:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
那么为什么不用处理时间(Processing Time)和摄入时间(Ingestion Time)呢?
处理时间(Processing Time)指的是数据被 Flink 框架处理时机器的系统时间,这个时间本身存在不确定性,比如因为网络延迟等原因。
摄入时间(Ingestion Time)理论上处于事件时间(Event Time)和处理时间(Processing Time)之间,可以用来防止 Flink 内部处理数据发生乱序的情况,但是无法解决数据进入 Flink 之前的乱序行为。
所以我们一般都会用 EventTime、WaterMark 和窗口配合使用来解决消息的乱序和延迟问题。
水印的本质是时间戳
水印的本质是一个一个的时间戳,这个时间戳存在 DataStream 的数据流中,Watermark 的生成方式有两种:
-
AssignerWithPeriodicWatermarks 生成周期水印,周期默认的时间是 200ms;
-
AssignerWithPunctuatedWatermarks 按需生成水印。
当 Flink 系统中出现了一个 Watermark T,那么就意味着 EventTime <= T 的数据都已经到达。当 Wartermark T 通过窗口后,后续到来的迟到数据就会被丢弃。
窗口触发和乱序时间
Flink 在用时间 + 窗口 + 水印来解决实际生产中的数据乱序问题,有如下的触发条件:
-
watermark 时间 >= window_end_time;
-
在 [window_start_time,window_end_time) 中有数据存在,这个窗口是左闭右开的。
但是有些业务场景需要我们等待一段时间,也就是接受一定范围的迟到数据,此时 allowedLateness 的设置就显得尤为重要。简单地说,allowedLateness 的设置就是对于那些水印通过窗口的结束时间后,还允许等待一段时间。
如果业务中的实际数据因为网络原因,乱序现象非常严重,allowedLateness 允许迟到的时间如果设置太小,则会导致很多次极少量数据触发窗口计算,严重影响数据的正确性。
Flink 消费 Kafka 保证消息有序
我们在第 23 课时“Mock Kafka 消息并发送”中提过,可以认为 Kafka 中的一个 Topic 就是一个队列,每个 Topic 又会被分成多个 Partition,每个 Partition 中的消息是有序的。但是有的业务场景需要我们保障所有 Partition 中的消息有序,一般情况下需要把 Partition 的个数设置为一个,但这种情况是不能接受的,会严重影响数据的吞吐量。
但是,Flink 消费 Kafka 时可以做到数据的全局有序,也可以多个 Partition 并发消费,这就是 Flink 中的 Kafka-partition-aware 特性。
我们在使用这种特性生成水印时,水印会在 Flink 消费 Kafka 的消费端生成,并且每个分区的时间戳严格升序。当数据进行 Shuffle 时,水印的合并机制会产生全局有序的水印。
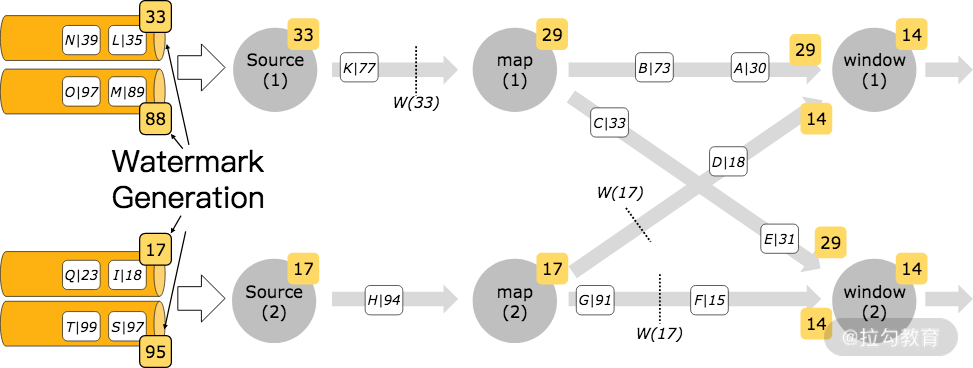
我们从上图中可以看出,每个生成的水印是如何在多个分区的数据中进行传递的。
代码实现如下:
FlinkKafkaConsumer09<MyType> kafkaSource = new FlinkKafkaConsumer09<>("topic", schema, props);
kafkaSource.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<MyType>() {
@Override
public long extractAscendingTimestamp(MyType element) {
return element.eventTimestamp();
}
});
DataStream<MyType> stream = env.addSource(kafkaSource);
Flink 预定义的时间戳提取器和水印发射器
Flink 本身提供了两个预定义实现类去生成水印:
-
AscendingTimestampExtractor 时间戳递增
-
BoundedOutOfOrdernessTimestampExtractor 处理乱序消息和延迟时间
AscendingTimestampExtractor 递增时间戳提取器
AscendingTimestampExtractor 是周期性生成水印的一个简单实现,这种方式会产生严格递增的水印。它的实现如下:
public abstract class AscendingTimestampExtractor<T> implements AssignerWithPeriodicWatermarks<T> {
...
public AscendingTimestampExtractor<T> withViolationHandler(MonotonyViolationHandler handler) {
this.violationHandler = requireNonNull(handler);
return this;
}
@Override
public final long extractTimestamp(T element, long elementPrevTimestamp) {
final long newTimestamp = extractAscendingTimestamp(element);
if (newTimestamp >= this.currentTimestamp) {
this.currentTimestamp = newTimestamp;
return newTimestamp;
} else {
violationHandler.handleViolation(newTimestamp, this.currentTimestamp);
return newTimestamp;
}
}
@Override
public final Watermark getCurrentWatermark() {
return new Watermark(currentTimestamp == Long.MIN_VALUE ? Long.MIN_VALUE : currentTimestamp - 1);
}
...
}
该种水印的生成方式适用于那些数据本身的时间戳在每个并行的任务中是单调递增的,例如,我们上面使用 AscendingTimestampExtractor 处理 Kafka 多个 Partition 的情况。
一个简单的案例如下所示:
DataStream<MyEvent> stream = ...
DataStream<MyEvent> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<MyEvent>() {
@Override
public long extractAscendingTimestamp(MyEvent element) {
return element.getCreationTime();
}
});
BoundedOutOfOrdernessTimestampExtractor 允许特定数量延迟的提取器
我们在上面提过有些业务场景需要等待一段时间,也就是接受一定范围的迟到数据,此时 allowedLateness 的设置就显得尤为重要。这种提取器也是周期性生成水印的实现,接受 allowedLateness 作为参数。
它的实现如下:
public abstract class BoundedOutOfOrdernessTimestampExtractor<T> implements AssignerWithPeriodicWatermarks<T> {
...
private final long maxOutOfOrderness;
public BoundedOutOfOrdernessTimestampExtractor(Time maxOutOfOrderness) {
if (maxOutOfOrderness.toMilliseconds() < 0) {
throw new RuntimeException("Tried to set the maximum allowed " +
"lateness to " + maxOutOfOrderness + ". This parameter cannot be negative.");
}
this.maxOutOfOrderness = maxOutOfOrderness.toMilliseconds();
this.currentMaxTimestamp = Long.MIN_VALUE + this.maxOutOfOrderness;
}
public long getMaxOutOfOrdernessInMillis() {
return maxOutOfOrderness;
}
...
@Override
public final Watermark getCurrentWatermark() {
// this guarantees that the watermark never goes backwards.
long potentialWM = currentMaxTimestamp - maxOutOfOrderness;
if (potentialWM >= lastEmittedWatermark) {
lastEmittedWatermark = potentialWM;
}
return new Watermark(lastEmittedWatermark);
}
@Override
public final long extractTimestamp(T element, long previousElementTimestamp) {
long timestamp = extractTimestamp(element);
if (timestamp > currentMaxTimestamp) {
currentMaxTimestamp = timestamp;
}
return timestamp;
}
}
BoundedOutOfOrdernessTimestampExtractor 的构造器接收 maxOutOfOrderness 这个参数,该参数是指定我们接收的消息允许滞后的最大时间。
案例
下面是一个接收 Kafka 消息进行处理,自定义窗口和水印的案例:
public class WindowWaterMark {
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">static</span> <span class="hljs-keyword">void</span> <span class="hljs-title">main</span><span class="hljs-params">(String[] args)</span> <span class="hljs-keyword">throws</span> Exception </span>{
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
<span class="hljs-comment">//设置为eventtime事件类型</span>
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
<span class="hljs-comment">//设置水印生成时间间隔100ms</span>
env.getConfig().setAutoWatermarkInterval(<span class="hljs-number">100</span>);
DataStream<String> dataStream = env
.socketTextStream(<span class="hljs-string">"127.0.0.1"</span>, <span class="hljs-number">9000</span>)
.assignTimestampsAndWatermarks(<span class="hljs-keyword">new</span> AssignerWithPeriodicWatermarks<String>() {
<span class="hljs-keyword">private</span> Long currentTimeStamp = <span class="hljs-number">0L</span>;
<span class="hljs-comment">//设置允许乱序时间</span>
<span class="hljs-keyword">private</span> Long maxOutOfOrderness = <span class="hljs-number">5000L</span>;
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Watermark <span class="hljs-title">getCurrentWatermark</span><span class="hljs-params">()</span> </span>{
<span class="hljs-keyword">return</span> <span class="hljs-keyword">new</span> Watermark(currentTimeStamp - maxOutOfOrderness);
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">long</span> <span class="hljs-title">extractTimestamp</span><span class="hljs-params">(String s, <span class="hljs-keyword">long</span> l)</span> </span>{
String[] arr = s.split(<span class="hljs-string">","</span>);
<span class="hljs-keyword">long</span> timeStamp = Long.parseLong(arr[<span class="hljs-number">1</span>]);
currentTimeStamp = Math.max(timeStamp, currentTimeStamp);
System.err.println(s + <span class="hljs-string">",EventTime:"</span> + timeStamp + <span class="hljs-string">",watermark:"</span> + (currentTimeStamp - maxOutOfOrderness));
<span class="hljs-keyword">return</span> timeStamp;
}
});
dataStream.map(<span class="hljs-keyword">new</span> MapFunction<String, Tuple2<String, Long>>() {
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Tuple2<String, Long> <span class="hljs-title">map</span><span class="hljs-params">(String s)</span> <span class="hljs-keyword">throws</span> Exception </span>{
String[] split = s.split(<span class="hljs-string">","</span>);
<span class="hljs-keyword">return</span> <span class="hljs-keyword">new</span> Tuple2<String, Long>(split[<span class="hljs-number">0</span>], Long.parseLong(split[<span class="hljs-number">1</span>]));
}
})
.keyBy(<span class="hljs-number">0</span>)
.window(TumblingEventTimeWindows.of(Time.seconds(<span class="hljs-number">5</span>)))
.aggregate(<span class="hljs-keyword">new</span> AggregateFunction<Tuple2<String,Long>, Object, Object>() {
...
})
.print();
env.execute(<span class="hljs-string">"WaterMark Test Demo"</span>);
}<span class="hljs-comment">//</span>
}
在这个案例中,我们使用的 AssignerWithPeriodicWatermarks 来自定义水印发射器和时间戳提取器,设置允许乱序时间为 5 秒,并且在一个 5 秒的窗口内进行聚合计算。
在这个案例中,可以看到如何正确使用 Flink 提供的 API 进行水印和时间戳的设置。
总结
这一课时讲解了生产环境中正确使用 Watermark 需要注意的事项,并且介绍了如何保证 Kafka 消息的全局有序,Flink 中自定义的时间戳提取器和水印发射器;最后用一个案例讲解了如何正确使用水印和设置乱序事件。通过这一课时你可以学习到生产中设置水印的正确方法和原理。
精选评论
**峰:
王老师,请教一下,消费kakfka,分区与分区之间的有序性是如何保证的
讲师回复:
Kafka的单个分区是有序存储的,Flink会顺序消费。但是多个分区之间是不保障有序的。
**蜗牛:
老师,aggregate 和 apply 方法处理计算有何区别的么???
讲师回复:
第一个是用来做增量计算,第二个做全脸聚合。
**飞:
我现在四个topic进行leftjoin关联,采用Stream API中的cogroup进行转换操作。stream_one = A.cogroup(b).where(a).equalTo(b).window(slideeventtimewindow(窗口1小时,滑动1分钟)).apply(逻辑计算);然后 stream_two= stream_one.cogroup(c).where(stream_one).equalTo(c).window(slideeventtimewindow(窗口1小时,滑动1分钟)).apply(逻辑计算);然后 stream_three= stream_two.cogroup(d).where(stream_two).equalTo(d).window(slideeventtimewindow(窗口1小时,滑动1分钟)).apply(逻辑计算);最终得到stream_three进行sink输出。不知道这种写法能否优化,感觉每次关联设置窗口,最终输出延迟时间应该是3分钟,这种多流join上有没有更优的方案?
讲师回复:
事实上我们在生产环境大于2个流进行join时,不会用flink的原生join,存在的问题:1. 快慢流导致state存储过大 2.任务一旦失败,state丢失会造成数据不准确,且无法重跑。我们一般是借助外部存储,比如将4个topic全部用flink任务写入hbase,然后在java中进行关联。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2060-%E7%AC%AC25%E8%AE%B2Flink-%E4%B8%AD-watermark-%E7%9A%84%E5%AE%9A%E4%B9%89%E5%92%8C%E4%BD%BF%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


