Flink系列-第26讲:Flink 中的聚合函数和累加器的设计和使用
我们在第 08 课时中提到了 Flink 所支持的窗口和时间类型,并且在第 25 课时中详细讲解了如何设置时间戳提取器和水印发射器。
实际的业务中,我们在使用窗口的过程中一定是基于窗口进行的聚合计算。例如,计算窗口内的 UV、PV 等,那么 Flink 支持哪些基于窗口的聚合函数?累加器又该如何实现呢?
Flink 支持的窗口函数
我们在定义完窗口以后,需要指定窗口上进行的计算。目前 Flink 支持的窗口函数包含 3 种:
-
ReduceFunction 增量聚合
-
AggregateFunction 增量聚合
-
ProcessWindowFunction 全量聚合
最后还有一种 FlodFunction,但是在 Flink 1.9 版本后已经废弃,推荐使用 AggregateFunction 代替。
下面我们详细讲解以上 3 种窗口聚合函数的定义和使用。
ReduceFunction
ReduceFunction 基于两个类型一致的输入进行增量聚合,我们可以自定义 ReduceFunction 来增量聚合窗口内的数据。
可以这样定义自己的 ReduceFunction,覆写 reduce 方法:
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new ReduceFunction<Tuple2<String, Long>> {
public Tuple2<String, Long> reduce(Tuple2<String, Long> v1, Tuple2<String, Long> v2) {
return new Tuple2<>(v1.f0, v1.f1 + v2.f1);
}
});
其中,我们覆写的 reduce 函数接受两个参数 v1 和 v2,这两个入参的类型一致。本例中返回的是入参的第二个参数的和。
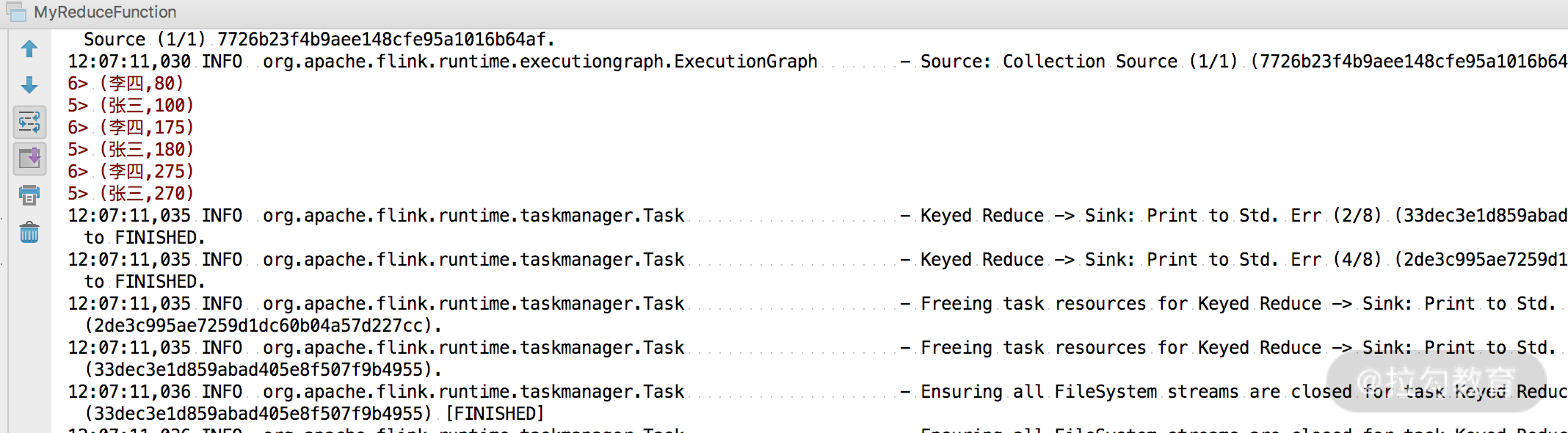
下面举个例子,我们需要计算班级中每个学生的总成绩:
public class MyReduceFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> input = env.fromElements(courses);
DataStream<Tuple2<String, Integer>> total = input.keyBy(0).reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<>(value1.f0, value1.f1 + value2.f1);
}
});
total.printToErr();
env.execute("ReduceFunction");
}
public static final Tuple2[] courses = new Tuple2[]{
Tuple2.of("张三",100),
Tuple2.of("李四",80),
Tuple2.of("张三",80),
Tuple2.of("李四",95),
Tuple2.of("张三",90),
Tuple2.of("李四",100),
};
}
在上面的案例中,将输入成绩按照学生姓名进行分组,然后自定义 ReduceFunction,覆写了其中的 reduce 函数,函数中将成绩进行相加,最后打印输出。
AggregateFunction
AggregateFunction 是 Flink 提供的一个通用的聚合函数实现,用户定义的聚合函数可以通过扩展 AggregateFunction 类来实现。AggregateFunction 更加通用,它有 3 个参数:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。
我们通过实现 AggregateFunction 接口,覆写下面几个方法:
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {
ACC createAccumulator();
ACC add(IN value, ACC accumulator);
OUT getResult(ACC accumulator);
ACC merge(ACC a, ACC b);
}
-
createAccumulator():用来创建一个累加器,负责将输入的数据进行迭代
-
add():该函数是用来将输入的每条数据和累加器进行计算的具体实现
-
getResult():从累加器中获取计算结果
-
merge():将两个累加器进行合并
我们举个例子,自定义一个 AverageAggregate 实现 AggregateFunction 接口:
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
在上面的案例中,我们自定义的 AverageAggregate 用来计算输入数据第二个字段的平均值。
ProcessWindowFunction
ProcessWindowFunction 用来进行全量聚合,窗口中需要维护全部原始数据,当窗口触发计算时,则进行全量聚合。ProcessWindowFunction 中有一个比较重要的对象,那就是 Context,可以用来访问事件和状态信息。但 ProcessWindowFunction 中的数据不是增量聚合,所以会使得资源消耗变大。
我们在自定义 ProcessWindowFunction 时可以实现的函数如下:
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> extends AbstractRichFunction {
private static final long serialVersionUID = 1L;
public abstract void process(KEY key, Context context, Iterable<IN> elements, Collector<OUT> out) throws Exception;
public void clear(Context context) throws Exception {}
public abstract class Context implements java.io.Serializable {
public abstract W window();
public abstract long currentProcessingTime();
public abstract long currentWatermark();
public abstract KeyedStateStore windowState();
public abstract KeyedStateStore globalState();
public abstract <X> void output(OutputTag<X> outputTag, X value);
}
}
举个例子,实现针对窗口的分组统计功能:
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(t -> t.f0)
.timeWindow(Time.minutes(5))
.process(new MyProcessWindowFunction());
public class MyProcessWindowFunction
extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {
long count = 0;
for (Tuple2<String, Long> in: input) {
count++;
}
out.collect(“Window: “ + context.window() + “count: “ + count);
}
}
除了上述的用法,ProcessWindowFunction 还可以结合 ReduceFunction、AggregateFunction,或者 FoldFunction 来做增量计算。
例如,下面的示例是将 ReduceFunction 和 ProcessWindowFunction 结合使用返回窗口中的最小事件以及窗口的开始时间。
DataStream<SensorReading> input = ...;
input
.keyBy(<key selector>)
.timeWindow(<duration>)
.reduce(new MyReduceFunction(), new MyProcessWindowFunction());
private static class MyReduceFunction implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r2 : r1;
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<SensorReading, Tuple2<Long, SensorReading>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<SensorReading> minReadings,
Collector<Tuple2<Long, SensorReading>> out) {
SensorReading min = minReadings.iterator().next();
out.collect(new Tuple2<Long, SensorReading>(window.getStart(), min));
}
}
Flink 中累加器的使用
Accumulator(累加器)主要用来获取不同并行实例中全局指标值。如果没有累加器,我们只能获取单个实例的统计信息和聚合值。Flink 提供了累加器用于作业结束后统计全局信息。
Flink 提供了以下几类累加器供我们使用:
-
IntCounter
-
LongCounter
-
DoubleCounter
-
自定义实现 Accumulator 或 SimpleAccumulator 接口
接下来我们看一下累加器的具体使用案例。
首先需要创建累加器,然后给累加器进行命名,这里需要注意,累加器的名字要全局唯一,接着将累加器注册到 Flink 的上下文中:
dataStream.map(new RichMapFunction<String, String>() {
//第一步:定义累加器
private IntCounter intCounter = new IntCounter();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//第二步:注册累加器
getRuntimeContext().addAccumulator("counter", this.intCounter);
}
@Override
public String map(String s) throws Exception {
//第三步:累加
this.intCounter.add(1);
return s;
}
});
最后当 Flink 程序执行完成后,可以获取累加器的值:
Object counte = jobExecutionResult.getAccumulatorResult("counter");
如果你不需要将最终的值进行持久化存储,那么可以不用获取该结果。因为该结果可以在 Flink UI 中看到。
完整的案例如下,我们计算 9000 端口中输入数据的个数:
public class CounterTest {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> dataStream = env.socketTextStream("127.0.0.1", 9000, "\n");
dataStream.map(new RichMapFunction<String, String>() {
//定义累加器
private IntCounter intCounter = new IntCounter();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//注册累加器
getRuntimeContext().addAccumulator("counter", this.intCounter);
}
@Override
public String map(String s) throws Exception {
//累加
this.intCounter.add(1);
return s;
}
});
dataStream.print();
JobExecutionResult result = env.execute("counter");
//第四步:结束后输出总量;如果不需要结束后持久化,可以省去
Object accResult = result.getAccumulatorResult("counter");
System.out.println("累加器计算结果:" + accResult);
}
}
我们在 9000 端口中输入几行数据:
然后断开端口,可以在控制台中看到输出的结果:

总结
这一课时我们详细讲解了 Flink 支持的窗口聚合函数分类,并且讲解了每个窗口聚合的使用场景,最后还对 Flink 支持的累加器进行了讲解。通过这一课时的学习,我们可以掌握 Flink 中窗口聚合函数和累加器的使用。
精选评论
**强:
这个累加器不知道可不可以跟消费kafka sink 阶段结合使用?
讲师回复:
应该是可以的
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2061-%E7%AC%AC26%E8%AE%B2Flink-%E4%B8%AD%E7%9A%84%E8%81%9A%E5%90%88%E5%87%BD%E6%95%B0%E5%92%8C%E7%B4%AF%E5%8A%A0%E5%99%A8%E7%9A%84%E8%AE%BE%E8%AE%A1%E5%92%8C%E4%BD%BF%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


