Flink系列-第28讲:TopN 热门商品功能实现
本课时主要讲解 Flink 中的 TopN 功能的设计和实现。
TopN 在我们的业务场景中是十分常见的需求,比如电商场景中求热门商品的销售额、微博每天的热门话题 TopN、贴吧中每天发帖最多的贴吧排名等。TopN 可以进行分组排序,也可以按照需要全局排序,比如若要计算用户下单总金额的 Top 10 时,就需要进行全局排序,然而当我们计算每个城市的 Top10 时就需要将订单按照城市进行分组然后再进行计算。
下面我们就详细讲解 TopN 的设计和实现。
整体设计
我们下面使用订单数据进行讲解,整体的数据流向如下图所示:
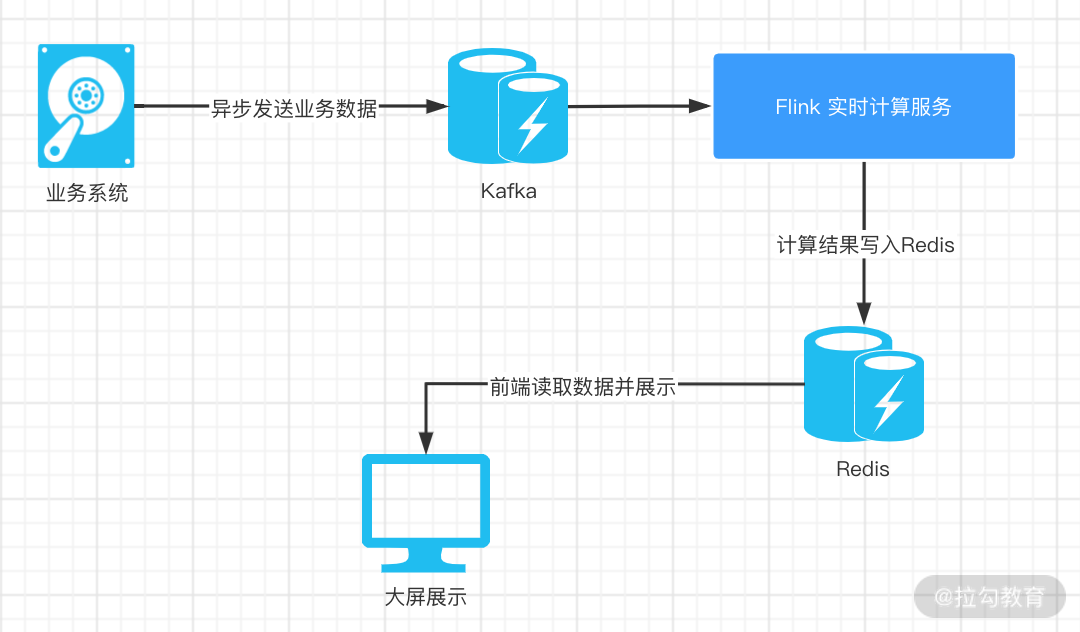
订单数据由业务系统产生并发送到 Kafka 中,我们的 Flink 代码会消费 Kafka 中的数据,并进行计算后写入 Redis,然后前端就可以通过读取 Redis 中的数据进行展示了。
订单设计
简化后的订单数据如下,主要包含:下单用户 ID、商品 ID、用户所在城市名称、订单金额和下单时间。
public class OrderDetail {
private Long userId; //下单用户id
private Long itemId; //商品id
private String citeName;//用户所在城市
private Double price;//订单金额
private Long timeStamp;//下单时间
}
我们采用 Event-Time 来作为 Flink 程序的时间特征,并且设置 Checkpoint 时间周期为 60 秒。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.enableCheckpointing(60 * 1000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(30 * 1000);
Kafka Consumer 实现
我们在第 24 课时“Flink 消费 Kafka 数据业务开发” 中详细讲解过 Kafka Consumer 的实现,在这里订阅 Kafka 消息作为数据源,设置从最早位点开始消费数据:
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("test", new SimpleStringSchema(), properties);
//从最早开始消费
consumer.setStartFromEarliest();
DataStream<String> stream = env
.addSource(consumer);
时间提取和水印设置
因为订单消息流可能存在乱序的问题,我们在这里设置允许乱序时间为 30 秒,并且设置周期性水印:
DataStream<OrderDetail> orderStream = stream.map(message -> JSON.parseObject(message, OrderDetail.class));
orderStream.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<OrderDetail>() {
private Long currentTimeStamp = 0L;
//设置允许乱序时间
private Long maxOutOfOrderness = 5000L;
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentTimeStamp - maxOutOfOrderness);
}
@Override
public long extractTimestamp(OrderDetail element, long previousElementTimestamp) {
return element.getTimeStamp();
}
});
下单金额 TopN
我们在这里要求所有用户中下单金额最多的 Top 10 用户,这里就会用到 windowAll 函数:
DataStream<OrderDetail> reduce = dataStream
.keyBy((KeySelector<OrderDetail, Object>) value -> value.getUserId())
.window(SlidingProcessingTimeWindows.of(Time.seconds(600), Time.seconds(20)))
.reduce(new ReduceFunction<OrderDetail>() {
@Override
public OrderDetail reduce(OrderDetail value1, OrderDetail value2) throws Exception {
return new OrderDetail(
value1.getUserId(), value1.getItemId(), value1.getCiteName(), value1.getPrice() + value2.getPrice(), value1.getTimeStamp()
);
}
});
//每20秒计算一次
SingleOutputStreamOperator<Tuple2<Double, OrderDetail>> process = reduce.windowAll(TumblingEventTimeWindows.of(Time.seconds(20)))
.process(new ProcessAllWindowFunction<OrderDetail, Tuple2<Double, OrderDetail>, TimeWindow>() {
@Override
public void process(Context context, Iterable<OrderDetail> elements, Collector<Tuple2<Double, OrderDetail>> out) throws Exception {
TreeMap<Double, OrderDetail> treeMap = new TreeMap<Double, OrderDetail>(new Comparator<Double>() {
@Override
public int compare(Double x, Double y) {
return (x < y) ? -1 : 1;
}
});
Iterator<OrderDetail> iterator = elements.iterator();
if (iterator.hasNext()) {
treeMap.put(iterator.next().getPrice(), iterator.next());
if (treeMap.size() > 10) {
treeMap.pollLastEntry();
}
}
for (Map.Entry<Double, OrderDetail> entry : treeMap.entrySet()) {
out.collect(Tuple2.of(entry.getKey(), entry.getValue()));
}
}
}
);
这段代码实现略显复杂,核心逻辑如下:
首先对输入流按照用户 ID 进行分组,并且自定义了一个滑动窗口,即 SlidingProcessingTimeWindows.of(Time.seconds(600), Time.seconds(20)),表示定义一个总时间长度为 600 秒,每 20 秒向后滑动一次的滑动窗口。
经过上面的处理后,我们的订单数据会按照用户维度每隔 20 秒进行一次计算,并且通过 windowAll 函数将所有的数据汇聚到一个窗口。
这里需要注意,windowAll 是一个并发度为 1 的特殊操作,也就是所有元素都会进入到一个窗口内进行计算。
那么我们是如何取得 Top 10 的呢?
在这里,我们定义了一个 TreeMap,TreeMap 存储 K-V 键值对,通过红黑树(R-B tree)实现,红黑树结构天然支持排序,默认情况下通过 Key 值的自然顺序进行排序。我们设置的 TreeMap 大小是 10,如果新的数据到来后,TreeMap 的数据已经到达 10个,那么就会进行比较,将较小的删除。
写入 Redis
我们在第 27 课时中讲了 Flink Redis Sink 的实现,把结果存入 Redis 中,结构为 HASH:
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build();
process.addSink(new RedisSink<>(conf, new RedisMapper<Tuple2<Double, OrderDetail>>() {
private final String TOPN_PREFIX = "TOPN:";
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET,TOPN_PREFIX);
}
@Override
public String getKeyFromData(Tuple2<Double, OrderDetail> data) {
return String.valueOf(data.f0);
}
@Override
public String getValueFromData(Tuple2<Double, OrderDetail> data) {
return String.valueOf(data.f1.toString());
}
}));
我们的 RedisSink 通过新建 RedisMapper 来实现,覆写了其中的 getCommandDescription、getKeyFromData、getValueFromData 三个方法。分别用来设定存储数据的格式,Redis 中 Key 的实现和 Value 的实现。
总结
这一课时我们详细讲解了 Flink 中 TopN 功能的实现,用到了之前课时中学习到的 Kafka Consumer、时间戳和水印设置,最后使用 TreeMap 存储计算的结果,并详细讲解和实现了 RedisSink。在一般的大屏业务情况下,大家都可以按照这个思路进行设计和实现。
精选评论
**立:
按照定义的逻辑,TreeMap不是升序吗,pollLastEntry()会删除最大的吧
讲师回复:
因为覆写了comparator,这里的treemap已经是降序排列了。
**发:
我的理解是:SlidingProcessingTimeWindows.of(Time.seconds(600), Time.seconds(20)) 定义的是时间窗口长度10分钟,每20秒往后滑动,这步可对用户维度的10分钟时间粒度进行汇总计算(但是每个窗口里的数据可能会有重复),下一步在windowAll里面做排序存放到treeMap中。在看需求描述:要求所有用户中下单金额最多的 Top 10 用户。这个订单数据是历史全部吧?不是仅仅10分钟内的累计吧?用滑动窗口时,数据已经有重复了。
讲师回复:
通常的需求中,我们在求TOP值是需要进行窗口计算,数据总是需要一个范围。当然如果你的业务场景是历史所有,那么我们只需要一个时间起始点即可,你的理解是正确的。
**宇:
用treeMap存储topN,如果两个用户金额相同,是不是会存在替换的问题呢,这样第一个用户就不会显示了。
讲师回复:
会出现这种情况,在实际生产中,我们一般是倒叙获取一个较长的名单(超过N),然后用sql去查询。这样就把同样金额的一起查出来了。
**东:
请问这里为什么要使用SlidingProcessingTimeWindows呢,前面不是提取的事件时间吗。SlidingProcessingTimeWindows 看代码取的是context.getCurrentProcessingTime()
讲师回复:
这里的需求是计算某一个时间范围呢,比如最近五分钟,那么我们希望每5分钟输出一次结果,slide窗口最合适。代码中的context.getCurrentProcessingTime()代表使用事件时间。
AlvinPower:
public int compare(Double x, Double y) { return (x “>1 : 1;}这个compare规则下,treeMap是按升序排列的,pollLastEntry() 方法是丢弃下标最大的节点。这结果不是把price最大的订单删掉了么
讲师回复:
pollLastEntry() method is used to return and then remove the entry (key-value pair) linked with the largest key element value that exists in this TreeMap. 是先返回,再删除。
**鹏:
没太理解第一个windowall,keyBy之后使用windowAll,根据源码注释内容,这是涵盖a non key grouped的窗口,也就是不区分key的,而且并行度为1的窗口。相反,看window源码文档,这是涵盖a key grouped窗口,也就是key分组的窗口。按照老师的编码逻辑keyby.windowall.reduce直接统计整个窗口所有数据的总和值,而不区分Key。我觉得正常逻辑是keyby.window.reduce统计滑动窗口各用户的总值,再windowall.process把各用户总值汇总提取top10。我认为第一个windoAll是老师写错了,应该window就好。也可能我对算子理解不对,请指正,谢谢各位。
讲师回复:
你的理解是对的,是按照 ID 进行分组,然后把相同 ID 的金额加起来。紧接着,(id,price) 这样的 tuple 统一发到一个 window 里,进行排序取 Top10
**亮:
实测keyBy .windowAll .reduce后的数据只有一条,就是第一次拿到的key,老师解释下?
讲师回复:
这里的keyBy是按照用户id分组,同一个用户的数据进入一个窗口。
**阳:
老师您好,TOPN的生产数据在哪了?我模拟了一下,但是好像TOPN没运行成功
讲师回复:
可以用代码自己生成,照着代码中的数据格式。
*帅:
1、“时间提取和水印设置”中,currentTimeStamp 这个没有给赋值吧,这里应该在extractTimestamp中指定吧?2、TopN中,keyBy之后,窗口是用window就行吧?3、使用滑动窗口(10分钟,20秒),为什么后面还要定义一个20秒的滚动窗口,如果是为了20秒计算一次,定义的滑动窗口本身的机制就是20秒触发一次计算吧?不需要额外定义滚动窗口了吧?
讲师回复:
应该在extractTimestamp中指定。滚动窗口是计算需要,前面的滑动窗口是为了处理kafka中的数据。
*亮:
你好,windowAll中使用滑动窗口,数据会出现重复的吧
讲师回复:
滑动窗口会出现数据重复
**生:
这边进入TreeMap的数据都是汇总好的数据吗?如果不是的话,这个逻辑就有点问题了,举个例子(进入TreeMap的是明细),取TOP2,来了几条数据,分别是(a,10)(b,3)(c,2)(c,2)(c,2)(c,2)(c,2),如果明细是这么来的,那么取TOP2总是取到的是a和b吧,我的理解有问题吗?
讲师回复:
这里定义的treeMap,key是数字,value是OrderDetail,因为覆写了comparator,这里的treemap已经是降序排列了。
**6289:
滚动窗口,这个是不是只能计算一个用户600秒内的总金额。就是一个用户在9:00下单金额1000元,然后在9:30下单2000元, 在9:30统计的时候,是不包含用户9:00下单的1000元的。
讲师回复:
滚动窗口的数据不会重叠,只被计算一次。
*欢:
请教老师两个问题,1.WM为什么不用常规的超过当前才涨一次,而是每次都涨,既然这样和lateless有什么区别呢。2.计算用户20秒的下单总额为什么要windowAll呢,这样后面reduce不就是对所有元素相加吗?直接使用window先统计每个用户20秒总额,然后后面计算topN阶段再使用windowAll这样行不行呢?
讲师回复:
因为我们定义了SlidingProcessingTimeWindows.of(Time.seconds(600), Time.seconds(20)),每次窗口计算就是当前这个窗口的数据。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2063-%E7%AC%AC28%E8%AE%B2TopN-%E7%83%AD%E9%97%A8%E5%95%86%E5%93%81%E5%8A%9F%E8%83%BD%E5%AE%9E%E7%8E%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


