Flink系列-第29讲:项目背景和实时处理系统架构设计
从这一课时开始我们进入“Flink 实时统计 PV、UV”项目的学习。本课时先介绍实时统计项目的背景、架构设计和技术选型。
背景
PV(Page View,网站的浏览量)即页面的浏览次数,一般用来衡量网站用户访问的网页数量。我们可以简单地认为,一个用户每次打开一个页面便会记录一次 PV,也就是说,PV 是指页面刷新的次数,刷新一次页面,记录一次 PV。
在互联网项目中,PV 的度量方法是指发起一次请求(Request)从浏览器到网络服务器,网络服务器在接收到请求后会将对应的网页返回给访问者,这个过程就是一次 PV。
UV(Unique Visitor,独立访客次数)是一天内访问某个站点的人数。一天内同一个用户不管有多少次访问网站,那么只记录一次 UV。一般来讲,会通过 IP 或者 Cookie 来进行判断。
如果网站的一个页面有 100 次访问,其中有一些访问者多次访问和点击,那么页面的 UV 一定是小于 100 的。
PV 和 UV 是我们业务中十分常见的场景,对于这种需求一般是通过什么样的技术架构实现呢?
技术选型和整体架构
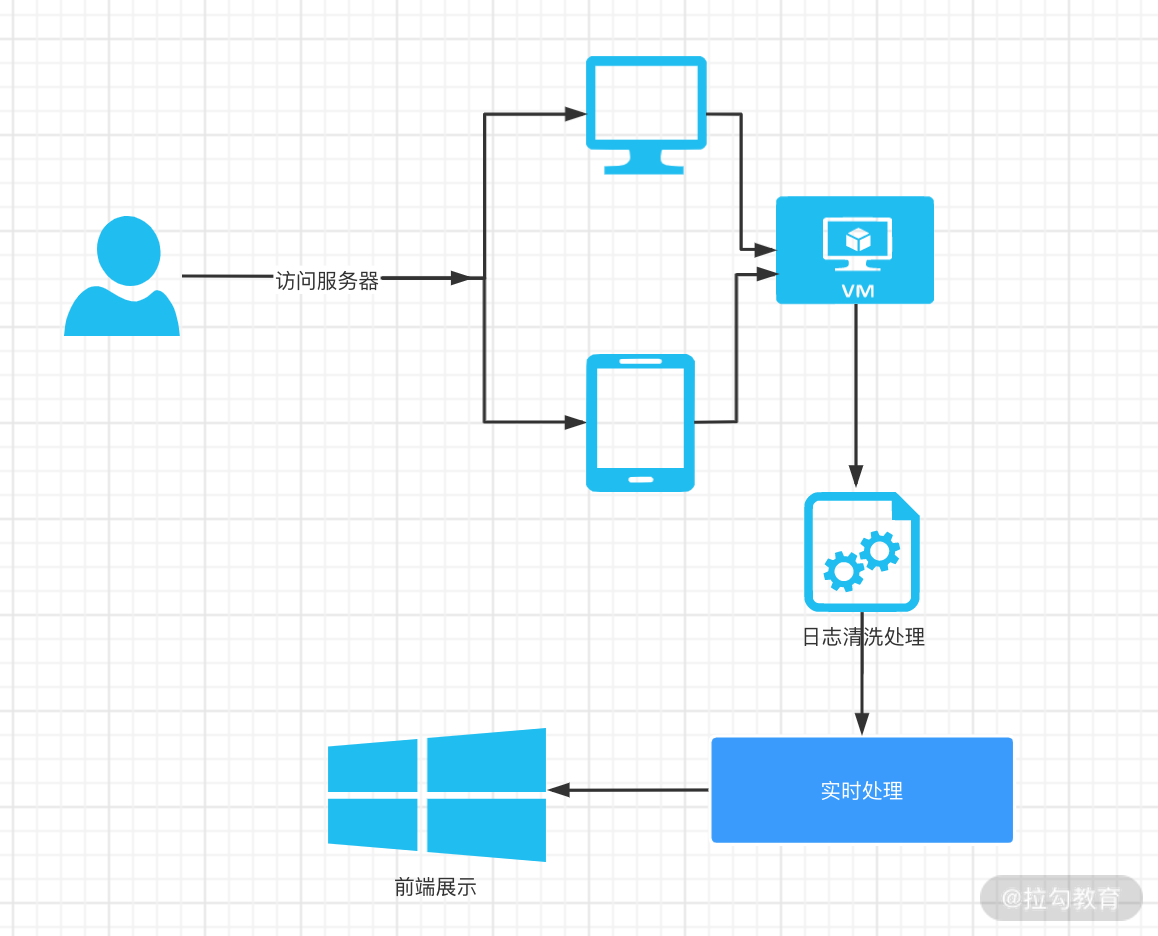
在互联网常见的后端应用中,技术选型可能多种多样,比如基于 Spring、Dubbo、Spring Cloud 等,但是基本的处理框架大同小异。最常见的数据就是日志数据,如果是 Web 应用,那么我们的日志数据就是用户的访问日志或者用户的点击日志等。
从上图中可以看到有几个关键的处理步骤:
-
日志数据如何上报
-
日志数据的清洗
-
实时计算程序
-
前端展示
所以基于以上的业务处理流程,我们常用的实时处理技术选型和架构如下图所示:
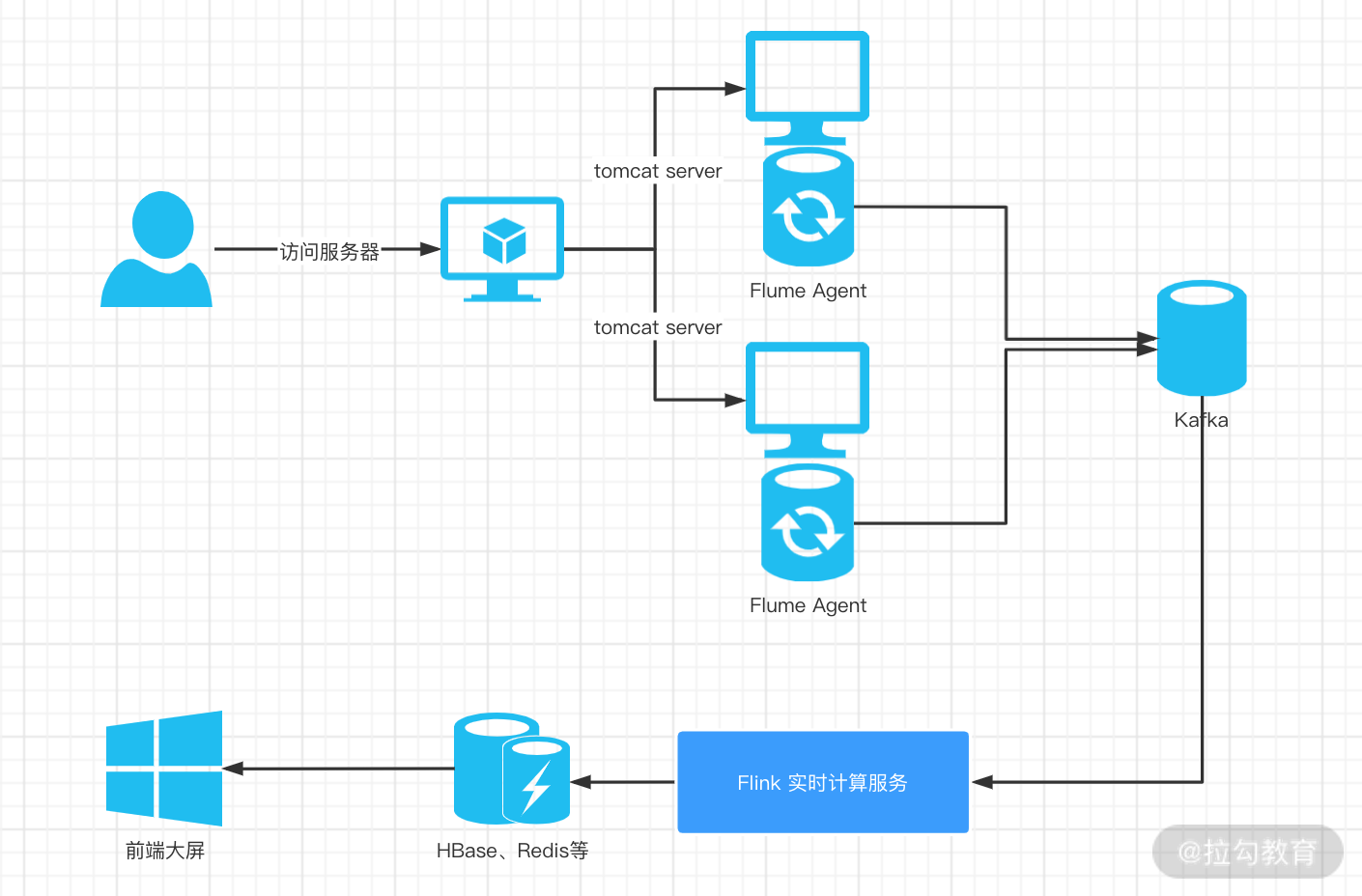
在上图的架构图中,涉及几个关键的技术选型和处理步骤,我们下面一一进行讲解。
日志数据埋点
“埋点”是数据采集领域中的一个术语,特别是采集用户行为数据,针对用户的某些事件和行为进行捕捉、处理并发送的过程。
埋点数据是十分重要的数据,也可用来进行:
-
流量监控、页面访问的热点分析
-
构建用户的行为数据,获取用户整个访问的路径和习惯
-
可以根据用户的访问数据进行偏好分析、个性化推荐
-
AB 测试
-
……
数据埋点的方式多种多样,可以在页面中使用 JavaScript 埋点开发,也可以简单地通过 Nginx 代理服务器进行日志的规范化。
当前大型网站的架构一般都是通过 Nginx 等服务器做网管和代理,Nginx 服务器本身支持日志格式的定制化。
服务端也可以先定义好全局的规范化日志,然后再进行采集,可以更加精细化的定制,满足精细化分析的需求。
我们在本案例中的场景是计算 PV 和 UV 数据,所以数据来源最有可能的是 Nginx 定制化的日志格式,例如:
log_format access $remote_addr - $remote_user [$time_local] "$request"' '$status $body_bytes_sent "$http_referer"' '"$http_user_agent" $http_x_forwarded_for;
Nginx 服务器的配置中跟日志相关的命令主要有 log_format 和 access_log。其中 log_format 可以用来定义日志格式,access_log 则指定了日志的存储路径。
日志数据采集
日志数据的采集需要根据日志的生成方式进行。在这里介绍两款普遍使用的日志收集中间件:
-
Flume
-
Logstash/FileBeat
根据官网的介绍:
Flume 是一个分布式、可靠和高可用的海量日志采集、聚合和传输的系统。Flume 可以采集文件、Socket 数据包等各种形式源数据,又可以将采集到的数据输出到 HDFS、HBase、Hive、Kafka 等众多外部存储系统中。一般的采集需求,通过对 Flume 的简单配置即可实现 Flume 针对特殊场景也具备良好的自定义扩展能力。因此,Flume 可以适用于大部分的日常数据采集场景。
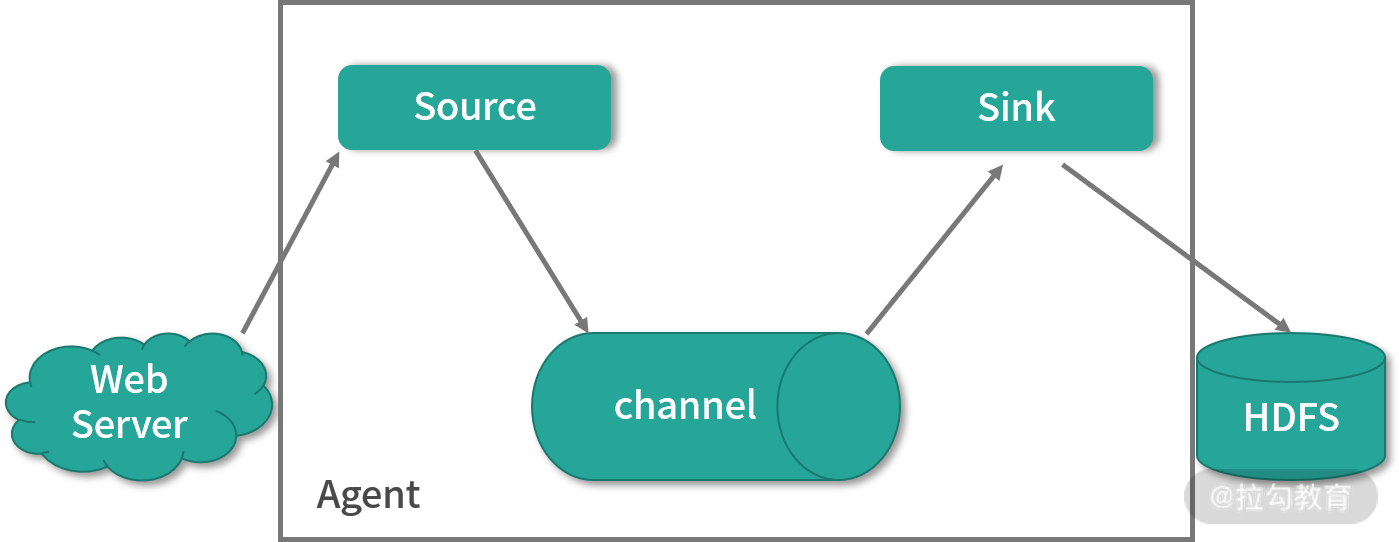
Flume 分布式系统中核心角色是 Agent,整个采集系统由一个个 Agent 进行的串联。我们可以把每个 Agent 想象为一个数据的投递员,它由三个组件构成:
-
Source,用来进行数据采集
-
Channel,数据传输的通道
-
Sink,用于把采集后的数据进行处理
我们同样也可以在官网找到 Logstash 和 FileBeat 的介绍:
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体的处理过程。
Logstash 支持各种输入选择,比如 log4j、Redis 等,可以同时从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从你的日志、指标、Web 应用、数据存储以及各种 AWS 服务中采集数据。
同样 FileBeat 也经常用来进行本地文件的日志数据采集,同时可以监控日志目录或者指定的日志文件,并且进行 tail 等操作,也可以将结果转发给 Elasticsearch 或 Logstatsh 等。
如果你的日志分析架构是 ES 系列技术栈,完全可以使用它们来代替 Flume。
实时计算
我们在上个项目的架构设计中指出了 Flink 的优势,在这里不再过多展开:
-
状态管理
-
丰富的 API
-
生态完善
-
批流一体
但需要注意的是,我们在进行 PV、UV 的统计时,Flink 会被用到两次:
-
日志清洗
-
数据统计
我们采集到的日志数据根据需要先进行清洗,包括丢弃掉不符合要求的数据,对日志数据进行分类,这个过程也会基于 Flink 进行,然后 Sink 到 Kafka 中给下游进行消费。
实时统计主要内容
在本次的案例中,我们不但对 PV 和 UV 进行计算,同时还会讲解 Flume 和 Kafka 的整合,Flink 日志清洗并 Sink 到 Kafka 等。
整个课程的设计包含以下几个部分:
-
Flume 和 Kafka 整合和部署
-
Kafka 模拟数据生成和发送
-
Flink 和 Kafka 整合时间窗口设计
-
Flink 计算 PV、UV 代码实现
-
Flink 和 Redis 整合以及 Redis Sink 实现
总结
本节课我们主要讲解了实时进行 PV、UV 计算的技术架构选型,其中涉及了日志数据埋点、日志数据采集、清洗等。在接下来的课程中,我会一一讲解这些知识点。通过本课时,你将学习到类似 PV、UV 等指标计算的整个流程设计和代码开发,在面对相同业务场景时可以根据课程内容灵活处理。
精选评论
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2064-%E7%AC%AC29%E8%AE%B2%E9%A1%B9%E7%9B%AE%E8%83%8C%E6%99%AF%E5%92%8C%E5%AE%9E%E6%97%B6%E5%A4%84%E7%90%86%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


