Flink系列-第31讲:Kafka 模拟数据生成和发送
第 29 课时讲过,在计算 PV 和 UV 的过程中关键的一个步骤就是进行日志数据的清洗。实际上在其他业务,比如订单数据的统计中,我们也需要过滤掉一些“脏数据”。
所谓“脏数据”是指与我们定义的标准数据结构不一致,或者不需要的数据。因为在数据清洗 ETL 的过程中经常需要进行数据的反序列化解析和 Java 类的映射,在这个映射过程中“脏数据”会导致反序列化失败,从而使得任务失败进行重启。在一些大作业中,重启会导致任务不稳定,而过多的“脏数据”会导致我们的任务频繁报错,最终彻底失败。
架构
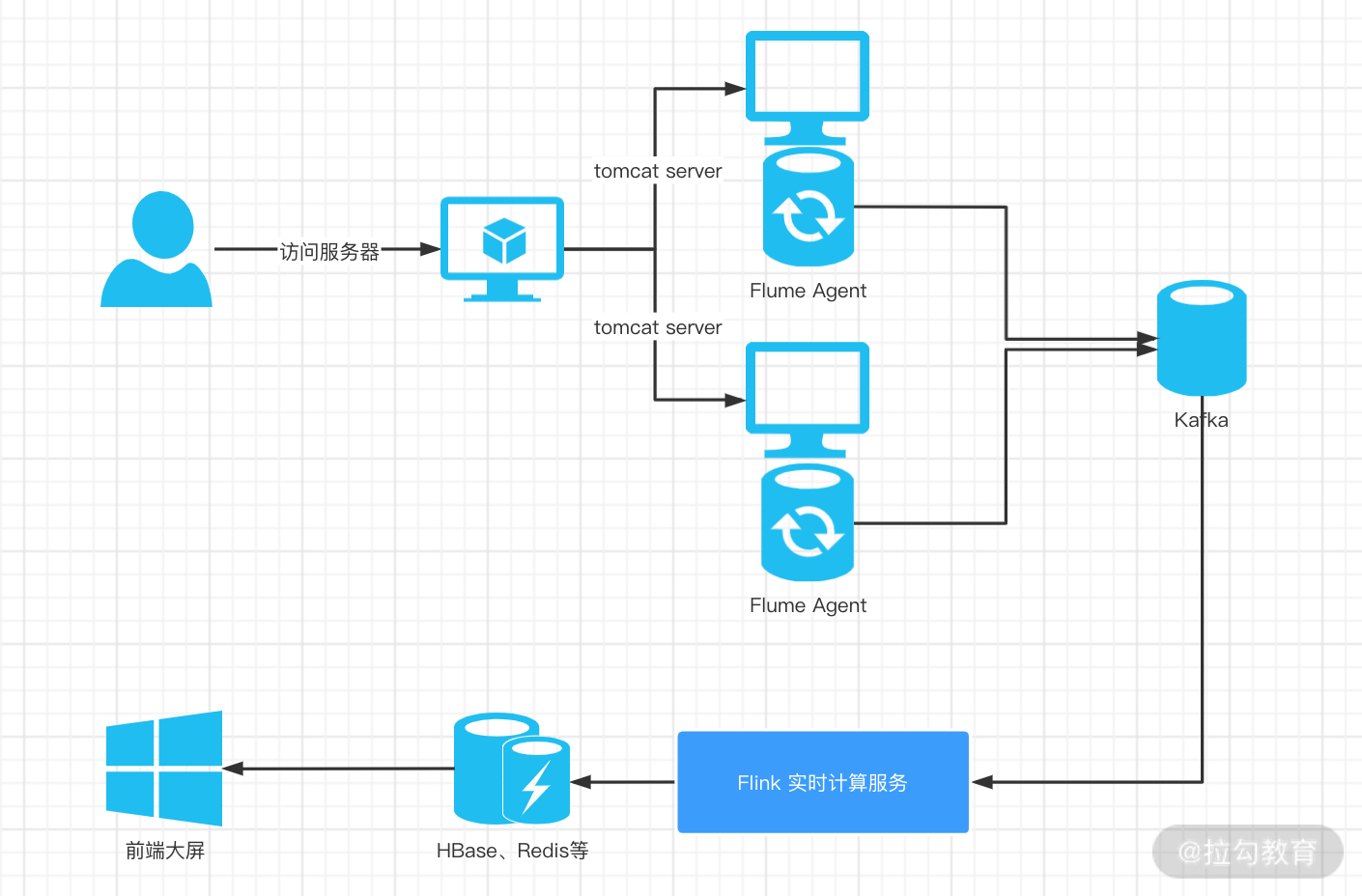
我们在第 30 课时中提过整个 PV 和 UV 计算过程中的数据处理架构,其中使用 Flume 收集业务数据并且发送到 Kafka 中,那么在计算 PV、UV 前就需要消费 Kafka 中的数据,并且将“脏数据”过滤掉。
在实际业务中,我们消费原始 Kafka 日志数据进行处理后,会同时把明细数据写到类似 Elasticsearch 这样的引擎中查询;也会把汇总数据写入 HBase 或者 Redis 等数据库中提供给前端查询展示用。同时,还会把数据再次写入 Kafka 中提供给其他业务使用。
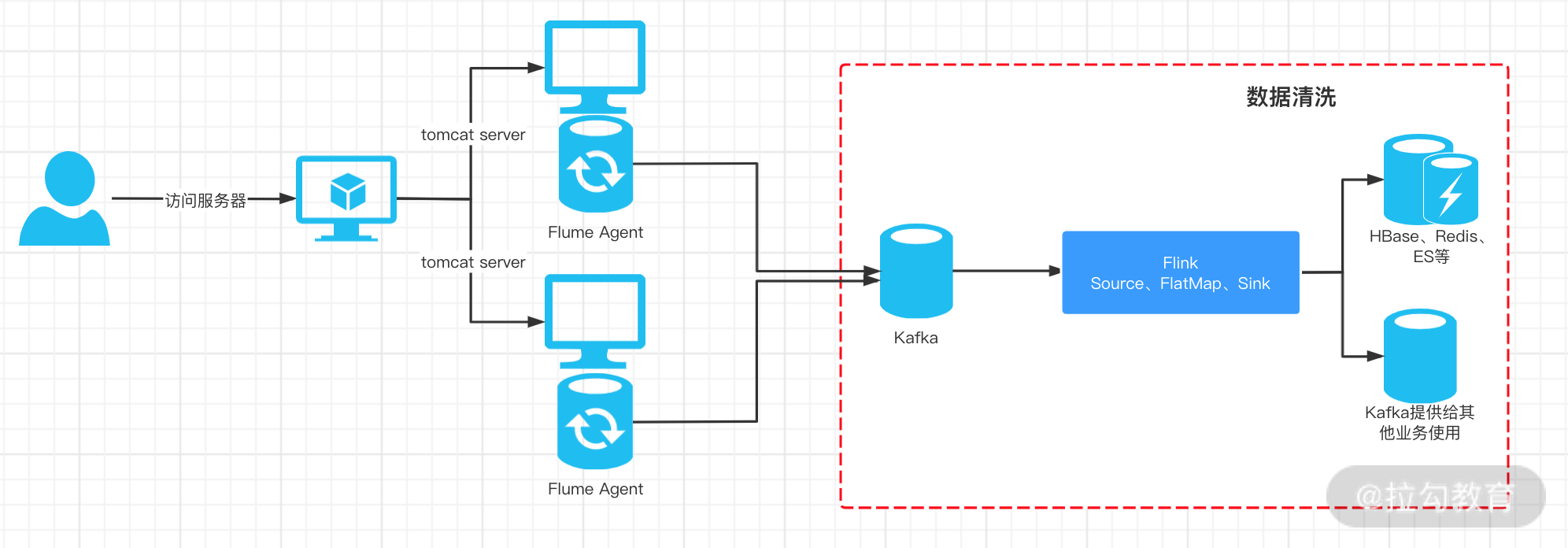
日志清洗
我们的原始数据被处理成 JSON 的形式发送到 Kafka 中,将原始数据反序列化成对应的访问日志对象进行计算,过滤掉一些“不合法”数据,比如访问者 ID 为空等。在这个过程中我们的 Source 是 Kafka Consumer,并且使用处理时间作为时间特征。
首先新建环境,设置检查点等参数:
StreamExecutionEnviro nment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.enableCheckpointing(5000);
接下来介入 Kafka Source,我们在第 30 课时中用 Flume 将收集到的原始日志写到了名为 log_kafka 的 Topic 中,Flume 的配置如下:
#sink配置
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = log_kafka
a1.sinks.k1.brokerList = 127.0.0.1:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
我们构造的 Kafka Consumer 属性如下:
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
//设置消费组
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("log_kafka", new SimpleStringSchema(), properties);
使用 Filter 算子和将不合法的数据过滤。过滤的逻辑是:如果消息体中 userId 为空或者事件消息不是“点击”的事件。
定义的消息格式如下所示:
public class UserClick {
private String userId;
private Long timestamp;
private String action;
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public Long getTimestamp() {
return timestamp;
}
public void setTimestamp(Long timestamp) {
this.timestamp = timestamp;
}
public String getAction() {
return action;
}
public void setAction(String action) {
this.action = action;
}
}
enum UserAction{
//点击
CLICK("CLICK"),
//购买
PURCHASE("PURCHASE"),
//其他
OTHER("OTHER");
private String action;
UserAction(String action) {
this.action = action;
}
}
我们简化后的消息体如上,其中 userId 为用户的 ID,timestamp 是时间戳,UserAction 是用户动作枚举:点击、购买和其他。我们需要其中的“点击”事件。
首先需要过滤掉字符串中明显不合法的数据:
public class UserActionFilter implements FilterFunction<String> {
@Override
public boolean filter(String input) throws Exception {
return input.contains("CLICK") && input.startsWith("{") && input.endsWith("}");
}
}
在实际生产中,我们的日志数据并不像我们想象的那样规范,其中有可能夹杂大量的“非法数据”,这些数据需要根据业务需求进行过滤。
我们在这里只获取那些用户事件为“点击”的消息,并且需要满足 JSON 格式数据的基本要求:以“{" 开头,以 "}”结尾。
然后在 FlatMap 中进一步将日志数据进行处理,过滤掉 userId 为空或者 action 类型为空的数据:
public class MyFlatMapFunction implements FlatMapFunction<String,String> {
@Override
public void flatMap(String input, Collector out) throws Exception {
JSONObject jsonObject = JSON.parseObject(input);
String user_id = jsonObject.getString("user_id");
String action = jsonObject.getString("action");
Long timestamp = jsonObject.getLong("timestamp");
if(!StringUtils.isEmpty(user_id) || !StringUtils.isEmpty(action)){
UserClick userClick = new UserClick();
userClick.setUserId(user_id);
userClick.setTimestamp(timestamp);
userClick.setAction(action);
out.collect(JSON.toJSONString(userClick));
}
}
}
处理完成的数据最后被转成 JSONString 发往下游:
env.addSource(consumer)
.filter(new UserActionFilter())
.flatMap(new MyFlatMapFunction())
.returns(TypeInformation.of(String.class))
.addSink(new FlinkKafkaProducer(
"127.0.0.1:9092",
"log_user_action",
new SimpleStringSchema()
));
当然你也可以在 ProcessFunction 中将所有的过滤转化逻辑放在一起进行处理。
public class UserActionProcessFunction extends ProcessFunction<String, String> {
@Override
public void processElement(String input, Context ctx, Collector<String> out) throws Exception {
if(! input.contains("CLICK") || input.startsWith("{") || input.endsWith("}")){
return;
}
JSONObject jsonObject = JSON.parseObject(input);
String user_id = jsonObject.getString("user_id");
String action = jsonObject.getString("action");
Long timestamp = jsonObject.getLong("timestamp");
if(!StringUtils.isEmpty(user_id) || !StringUtils.isEmpty(action)){
UserClick userClick = new UserClick();
userClick.setUserId(user_id);
userClick.setTimestamp(timestamp);
userClick.setAction(action);
out.collect(JSON.toJSONString(userClick));
}
}
}
我们在上面的例子中将数据发送到了新的 Kafka Topic 中,当然在实际业务中你也可以发往 Elasticsearch、MySQL 等数据库中查询明细。这里我们将处理干净的数据发往了新的 Kafka Topic 中。
到目前为止,我们的数据就被清理干净了,在后续的业务中,可以直接消费新的 Kafka 数据进行 PV 和 UV 的统计了。
总结
这一课时我们学习了使用 Flink 进行数据清洗 ETL 的过程,在实际业务中数据的清洗是必不可少的部分,你可以根据业务需要采用不同的清洗策略,将数据存储到新的数据库中。
精选评论
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/bi/flink/2066-%E7%AC%AC31%E8%AE%B2Kafka-%E6%A8%A1%E6%8B%9F%E6%95%B0%E6%8D%AE%E7%94%9F%E6%88%90%E5%92%8C%E5%8F%91%E9%80%81/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


