前端知识点大全
一、简历
简历在找工作过程中是非常非常重要的,无论你是什么途径去面试的,面试你的人一定会看你的简历。
1、重点
- 简历就像高考作文——阅卷时间非常短。
- 内容要简洁。
- 直击重点,表现出自己的优势(只要是符合招人单位要求的都是优势,不是别人不会的你会才叫优势)。
2、简历包含的内容
- 个人信息。
- 专业技能。
- 工作经历。
- 项目经历。
- 社区贡献。
2.1 基本信息
- 必备:姓名 电话 邮箱。
- 年龄(最好写上,在这个行业年龄还是比较重要的),学历(写好是哪一届)。
- 头像无所谓(好看就放上呗)。
- 可以放 github 链接,前提是有内容。
2.2 专业技能
- 表现出自己的核心竞争力(只要是符合招人单位要求的都是优势)。
- 内容不要太多,3、5 条即可。
- 太基础的不要写,例如会用 vscode、lodash。
2.3 工作经历
- 如实写。
- 写明公司,职位,入职离职时间即可,多写无益。
- 如果有空窗期,如实写明即可。
2.4 项目经历
- 写 2-4 个具有说服力的项目(不要什么项目都写,没用)。
- 项目名称,项目描述,技术栈,个人角色。
2.5 社区贡献
- 有博客或者开源作品,会让你更有竞争力。
- 切记:需要真的有内容,不可临时抱佛脚。
3、注意事项
- 界面不能太花哨,简洁明了即可。
- 注意用词,“精通”“熟练”等慎用,可用“熟悉”。
- 不可造假,会被拉入黑名单。
4、面试前准备
- 看 JD,是否需要临时准备一下。
- 打印纸质简历,带着纸和笔(增加好印象)。
- 最好带着自己电脑,现场可能手写代码(带一个帆布包最适合,又优雅又方便)。
- 要有时间观念,如果迟到或者推迟,要提前说。
- 衣着适当,不用正装,也不要太随意。
- 为何离职?—— 不要吐槽前东家,说自己的原因(想找一个更好的发展平台等)。
- 能加班吗?—— 能!除非你特别自信,能找到其他机会。
- 不要挑战面试官,即便他错了(面试一定要保证愉快)。
- 遇到不会的问题,要表现出自己积极的一面(不好意思哈,确实是我的知识盲区,可以跟我说下 xxx 吗,我回去研究一下)。
二、HTML+CSS 面试题
HTML 和 CSS 面试题答不出来基本可以回去了。
1、HTML 面试题
以下是针对 HTML 相关的面试题,一般来说这地方不会出太多题,面试官也不愿意花太多时间在这上面。
1.1 如何理解 HTML 语义化?
- 让人更容易读懂(增加代码可读性)。
- 让搜索引擎更容易读懂,有助于爬虫抓取更多的有效信息,爬虫依赖于标签来确定上下文和各个关键字的权重(SEO)。
- 在没有 CSS 样式下,页面也能呈现出很好地内容结构、代码结构。
1.2 script 标签中 defer 和 async 的区别?
script:会阻碍 HTML 解析,只有下载好并执行完脚本才会继续解析 HTML。async script:解析 HTML 过程中进行脚本的异步下载,下载成功立马执行,有可能会阻断 HTML 的解析。defer script:完全不会阻碍 HTML 的解析,解析完成之后再按照顺序执行脚本。
下图清晰地展示了三种 script 的过程:

推荐文章:
1.3 从浏览器地址栏输入 url 到请求返回发生了什么
先阅读这篇科普性质的:从 URL 输入到页面展现到底发生什么? 先阅读篇文章:从输入 URL 开始建立前端知识体系。
- 输入 URL 后解析出协议、主机、端口、路径等信息,并构造一个 HTTP 请求。
- 强缓存。
- 协商缓存。
-
DNS 域名解析。(字节面试被虐后,是时候搞懂 DNS 了)
-
TCP 连接。
总是要问:为什么需要三次握手,两次不行吗?其实这是由 TCP 的自身特点可靠传输决定的。客户端和服务端要进行可靠传输,那么就需要确认双方的接收和发送能力。第一次握手可以确认客服端的发送能力,第二次握手,确认了服务端的发送能力和接收能力,所以第三次握手才可以确认客户端的接收能力。不然容易出现丢包的现象。
-
http 请求。
-
服务器处理请求并返回 HTTP 报文。
-
浏览器渲染页面。
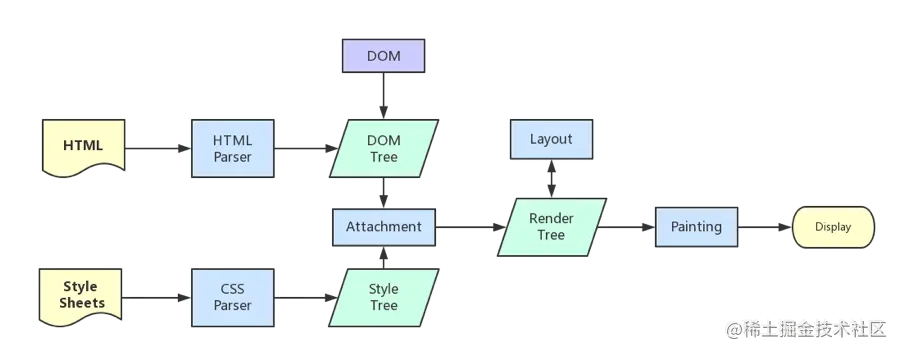
- 断开 TCP 连接。
2、CSS 面试题
以下是针对 CSS 相关的面试题,这些题答不出来会给人非常不好的技术印象。
2.1 盒模型介绍
CSS3 中的盒模型有以下两种:标准盒模型、IE(替代)盒模型。
两种盒子模型都是由 content + padding + border + margin 构成,其大小都是由 content + padding + border 决定的,但是盒子内容宽/高度(即 width/height)的计算范围根据盒模型的不同会有所不同:
- 标准盒模型:只包含
content。 - IE(替代)盒模型:
content + padding + border。
可以通过 box-sizing 来改变元素的盒模型:
box-sizing: content-box:标准盒模型(默认值)。box-sizing: border-box:IE(替代)盒模型。
2.2 css 选择器和优先级
首先我们要知道有哪些选择器:选择器参考表。
常规来说,大家都知道样式的优先级一般为 !important > style > id > class ,但是涉及多类选择器作用于同一个元素时候怎么判断优先级呢?相信我,你在改一些第三方库(比如 antd 😂)样式时,理解这个会帮助很大!
这篇文章写的非常清晰易懂,强烈推荐,看完之后就没啥问题了:深入理解 CSS 选择器优先级。
上述文章中核心内容: 优先级是由 A 、B、C、D 的值来决定的,其中它们的值计算规则如下:
- 如果存在内联样式,那么
A = 1,否则A = 0;- B 的值等于
ID选择器(#id)出现的次数;- C 的值等于
类选择器(.class)和属性选择器(a[href="https://example.org"])和伪类(:first-child)出现的总次数;- D 的值等于
标签选择器(h1,a,div)和伪元素(::before,::after)出现的总次数。
从左至右比较,如果是样式优先级相等,取后面出现的样式。
2.3 重排(reflow)和重绘(repaint)的理解
简单地总结下两者的概念:
- 重排:无论通过什么方式影响了元素的几何信息(元素在视口内的位置和尺寸大小),浏览器需要重新计算元素在视口内的几何属性,这个过程叫做重排。
- 重绘:通过构造渲染树和重排(回流)阶段,我们知道了哪些节点是可见的,以及可见节点的样式和具体的几何信息(元素在视口内的位置和尺寸大小),接下来就可以将渲染树的每个节点都转换为屏幕上的实际像素,这个阶段就叫做重绘。
如何减少重排和重绘?
- 最小化重绘和重排,比如样式集中改变,使用添加新样式类名
.class或cssText。 - 批量操作 DOM,比如读取某元素
offsetWidth属性存到一个临时变量,再去使用,而不是频繁使用这个计算属性;又比如利用document.createDocumentFragment()来添加要被添加的节点,处理完之后再插入到实际 DOM 中。 - 使用 *
\*\*absolute\*\** 或 *\*\*fixed\*\** 使元素脱离文档流,这在制作复杂的动画时对性能的影响比较明显。 - 开启 GPU 加速,利用 css 属性
transform、will-change等,比如改变元素位置,我们使用translate会比使用绝对定位改变其left、top等来的高效,因为它不会触发重排或重绘,transform使浏览器为元素创建⼀个 GPU 图层,这使得动画元素在一个独立的层中进行渲染。当元素的内容没有发生改变,就没有必要进行重绘。
这里推荐腾讯 IVWEB 团队的这篇文章:你真的了解回流和重绘吗,好好认真看完,面试应该没问题的。
2.4 对 BFC 的理解
BFC 即块级格式上下文,根据盒模型可知,每个元素都被定义为一个矩形盒子,然而盒子的布局会受到尺寸,定位,盒子的子元素或兄弟元素,视口的尺寸等因素决定,所以这里有一个浏览器计算的过程,计算的规则就是由一个叫做视觉格式化模型的东西所定义的,BFC 就是来自这个概念,它是 CSS 视觉渲染的一部分,用于决定块级盒的布局及浮动相互影响范围的一个区域。
BFC 具有一些特性:
- 块级元素会在垂直方向一个接一个的排列,和文档流的排列方式一致。
- 在 BFC 中上下相邻的两个容器的
margin会重叠,创建新的 BFC 可以避免外边距重叠。 - 计算 BFC 的高度时,需要计算浮动元素的高度。
- BFC 区域不会与浮动的容器发生重叠。
- BFC 是独立的容器,容器内部元素不会影响外部元素。
- 每个元素的左
margin值和容器的左border相接触。
利用这些特性,我们可以解决以下问题:
- 利用
4和6,我们可以实现三栏(或两栏)自适应布局。 - 利用
2,我们可以避免margin重叠问题。 - 利用
3,我们可以避免高度塌陷。
创建 BFC 的方式:
- 绝对定位元素(
position为absolute或fixed)。 - 行内块元素,即
display为inline-block。 overflow的值不为visible。
推荐文章:可能是最好的 BFC 解析了…
2.5 实现两栏布局(左侧固定 + 右侧自适应布局)
现在有以下 DOM 结构:
|
|
- 利用浮动,左边元素宽度固定 ,设置向左浮动。将右边元素的
margin-left设为固定宽度 。注意,因为右边元素的width默认为auto,所以会自动撑满父元素。
|
|
- 同样利用浮动,左边元素宽度固定 ,设置向左浮动。右侧元素设置
overflow: hidden;这样右边就触发了BFC,BFC的区域不会与浮动元素发生重叠,所以两侧就不会发生重叠。
|
|
- 利用
flex布局,左边元素固定宽度,右边的元素设置flex: 1。
|
|
- 利用绝对定位,父级元素设为相对定位。左边元素
absolute定位,宽度固定。右边元素的margin-left的值设为左边元素的宽度值。
|
|
- 利用绝对定位,父级元素设为相对定位。左边元素宽度固定,右边元素
absolute定位,left为宽度大小,其余方向定位为0。
|
|
2.6 实现圣杯布局和双飞翼布局(经典三分栏布局)
圣杯布局和双飞翼布局的目的:
- 三栏布局,中间一栏最先加载和渲染(内容最重要,这就是为什么还需要了解这种布局的原因)。
- 两侧内容固定,中间内容随着宽度自适应。
- 一般用于 PC 网页。
圣杯布局和双飞翼布局的技术总结:
- 使用
float布局。 - 两侧使用
margin负值,以便和中间内容横向重叠。 - 防止中间内容被两侧覆盖,圣杯布局用
padding,双飞翼布局用margin。
圣杯布局: HTML 结构:
|
|
CSS 样式:
|
|
双飞翼布局: HTML 结构:
|
|
CSS 样式:
|
|
tips:上述代码中 margin-left: -100% 相对的是父元素的 content 宽度,即不包含 paddig 、 border 的宽度。
其实以上问题需要掌握 margin 负值问题 即可很好理解。
2.7 水平垂直居中多种实现方式
- 利用绝对定位,设置
left: 50%和top: 50%现将子元素左上角移到父元素中心位置,然后再通过translate来调整子元素的中心点到父元素的中心。该方法可以不定宽高。
|
|
- 利用绝对定位,子元素所有方向都为
0,将margin设置为auto,由于宽高固定,对应方向实现平分,该方法必须盒子有宽高。
|
|
- 利用绝对定位,设置
left: 50%和top: 50%现将子元素左上角移到父元素中心位置,然后再通过margin-left和margin-top以子元素自己的一半宽高进行负值赋值。该方法必须定宽高。
|
|
- 利用
flex,最经典最方便的一种了,不用解释,定不定宽高无所谓的。
|
|
其实还有很多方法,比如 display: grid 或 display: table-cell 来做,有兴趣点击下面这篇文章可以了解下:
面试官:你能实现多少种水平垂直居中的布局(定宽高和不定宽高)。
2.8 flex 布局
这一块内容看 Flex 布局教程 就够了。
这里有个小问题,很多时候我们会用到 flex: 1 ,它具体包含了以下的意思:
flex-grow: 1:该属性默认为0,如果存在剩余空间,元素也不放大。设置为1代表会放大。flex-shrink: 1:该属性默认为1,如果空间不足,元素缩小。flex-basis: 0%:该属性定义在分配多余空间之前,元素占据的主轴空间。浏览器就是根据这个属性来计算是否有多余空间的。默认值为auto,即项目本身大小。设置为0%之后,因为有flex-grow和flex-shrink的设置会自动放大或缩小。在做两栏布局时,如果右边的自适应元素flex-basis设为auto的话,其本身大小将会是0。
2.9 line-height 如何继承?
- 父元素的
line-height写了具体数值,比如30px,则子元素line-height继承该值。 - 父元素的
line-height写了比例,比如1.5 或 2,则子元素line-height也是继承该比例。 - 父元素的
line-height写了百分比,比如200%,则子元素line-height继承的是父元素font-size * 200%计算出来的值。
三、js 基础
js 的考察其实来回就那些东西,不过就我自己而已学习的时候理解是真的理解了,但是忘也确实会忘(大家都说理解了一定不会忘,但是要答全的话还是需要理解+背)。
1、数据类型
以下是比较重要的几个 js 变量要掌握的点。
1.1 基本的数据类型介绍,及值类型和引用类型的理解
在 JS 中共有 8 种基础的数据类型,分别为: Undefined 、 Null 、 Boolean 、 Number 、 String 、 Object 、 Symbol 、 BigInt 。
其中 Symbol 和 BigInt 是 ES6 新增的数据类型,可能会被单独问:
- Symbol 代表独一无二的值,最大的用法是用来定义对象的唯一属性名。
- BigInt 可以表示任意大小的整数。
值类型的赋值变动过程如下:
|
|

引用类型的赋值变动过程如下:
|
|
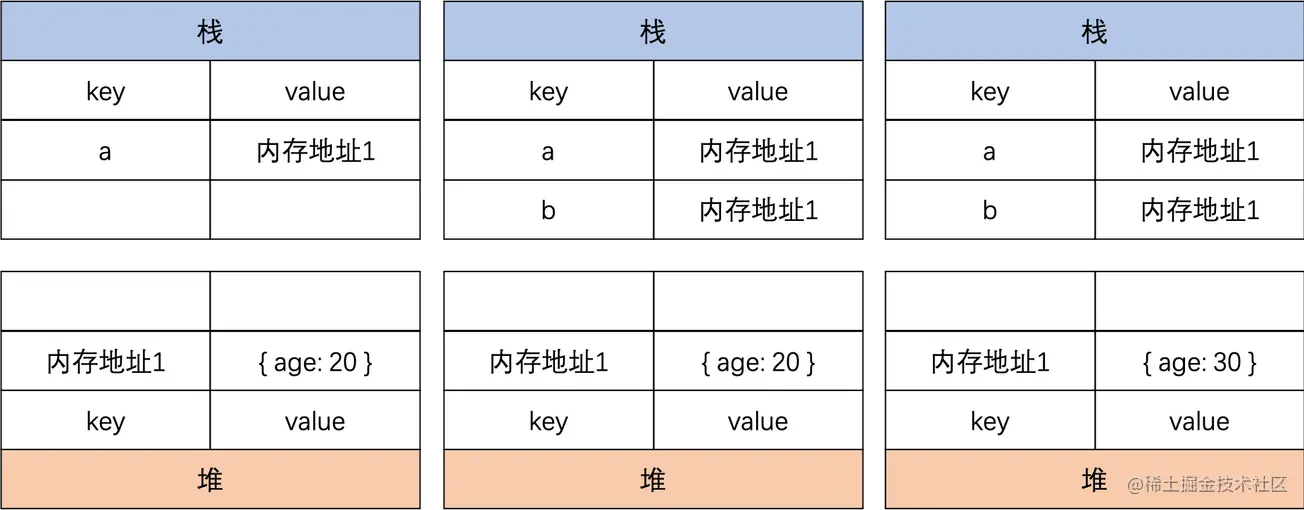
1.2 数据类型的判断
- typeof:能判断所有值类型,函数。不可对 null、对象、数组进行精确判断,因为都返回
object。
|
|
- instanceof:能判断对象类型,不能判断基本数据类型,其内部运行机制是判断在其原型链中能否找到该类型的原型。比如考虑以下代码:
|
|
其实现就是顺着原型链去找,如果能找到对应的 Xxxxx.prototype 即为 true 。比如这里的 vortesnail 作为实例,顺着原型链能找到 Student.prototype 及 People.prototype ,所以都为 true 。
- Object.prototype.toString.call():所有原始数据类型都是能判断的,还有 Error 对象,Date 对象等。
|
|
在面试中有一个经常被问的问题就是:如何判断变量是否为数组?
|
|
1.3 手写深拷贝
这个题一定要会啊!笔者面试过程中疯狂被问到!
文章推荐:如何写出一个惊艳面试官的深拷贝?
|
|
1.4 根据 0.1+0.2 ! == 0.3,讲讲 IEEE 754 ,如何让其相等?
建议先阅读这篇文章了解 IEEE 754 :硬核基础二进制篇(一)0.1 + 0.2 != 0.3 和 IEEE-754 标准。 再阅读这篇文章了解如何运算:0.1 + 0.2 不等于 0.3?为什么 JavaScript 有这种“骚”操作?。
原因总结:
进制转换:js 在做数字计算的时候,0.1 和 0.2 都会被转成二进制后无限循环 ,但是 js 采用的 IEEE 754 二进制浮点运算,最大可以存储 53 位有效数字,于是大于 53 位后面的会全部截掉,将导致精度丢失。对阶运算:由于指数位数不相同,运算时需要对阶运算,阶小的尾数要根据阶差来右移(0舍1入),尾数位移时可能会发生数丢失的情况,影响精度。
解决办法:
- 转为整数(大数)运算。
|
|
这里代码是有问题的,因为最后计算 bigRes 的大数相除(即 /)是会把小数部分截掉的,所以我很疑惑为什么网络上很多文章都说可以通过先转为整数运算再除回去,为了防止转为的整数超出 js 表示范围,还可以运用到 ES6 新增的大数类型,我真的很疑惑,希望有好心人能解答下。
- 使用
Number.EPSILON误差范围。
|
|
Number.EPSILON 的实质是一个可以接受的最小误差范围,一般来说为 Math.pow(2, -52) 。
- 转成字符串,对字符串做加法运算。
|
|
这是 leetcode 上一道原题:415. 字符串相加。区别在于原题没有考虑小数,但是也是很简单的,我们分为两个部分计算就行。
2、 原型和原型链
可以说这部分每家面试官都会问了。。首先理解的话,其实一张图即可,一段代码即可。
|
|
千万别畏惧下面这张图,特别有用,一定要搞懂,熟到提笔就能默画出来。
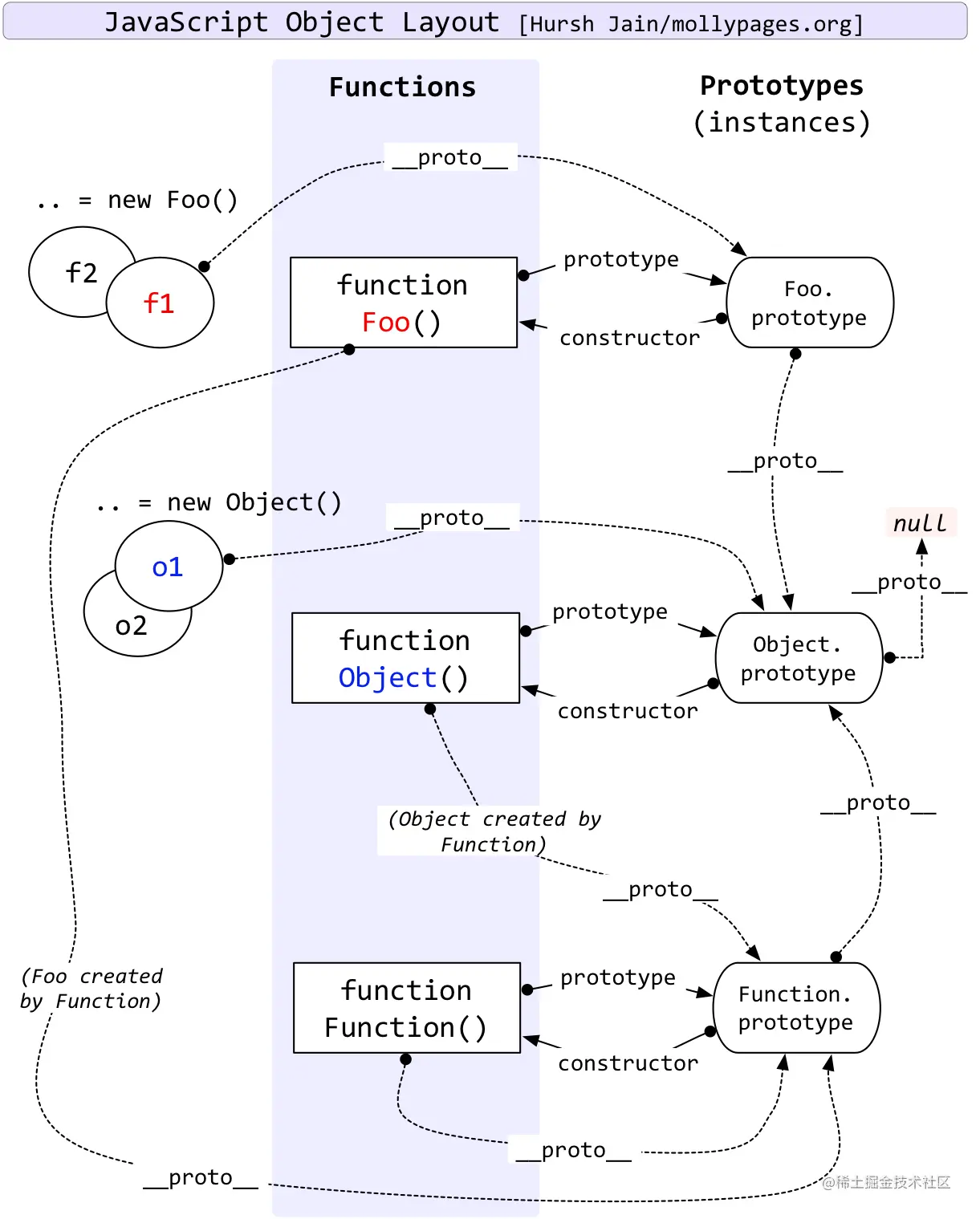
总结:
- 原型:每一个 JavaScript 对象(null 除外)在创建的时候就会与之关联另一个对象,这个对象就是我们所说的原型,每一个对象都会从原型"继承"属性,其实就是
prototype对象。 - 原型链:由相互关联的原型组成的链状结构就是原型链。
先说出总结的话,再举例子说明如何顺着原型链找到某个属性。
推荐的阅读:JavaScript 深入之从原型到原型链 掌握基本概念,再阅读这篇文章轻松理解 JS 原型原型链加深上图的印象。
3、 作用域与作用域链
- 作用域:规定了如何查找变量,也就是确定当前执行代码对变量的访问权限。换句话说,作用域决定了代码区块中变量和其他资源的可见性。(全局作用域、函数作用域、块级作用域)
- 作用域链:从当前作用域开始一层层往上找某个变量,如果找到全局作用域还没找到,就放弃寻找 。这种层级关系就是作用域链。(由多个执行上下文的变量对象构成的链表就叫做作用域链,学习下面的内容之后再考虑这句话)
需要注意的是,js 采用的是静态作用域,所以函数的作用域在函数定义时就确定了。
推荐阅读:先阅读JavaScript 深入之词法作用域和动态作用域,再阅读深入理解 JavaScript 作用域和作用域链。
4、 执行上下文
这部分一定要按顺序连续读这几篇文章,必须多读几遍:
总结:当 JavaScript 代码执行一段可执行代码时,会创建对应的执行上下文。对于每个执行上下文,都有三个重要属性:
- 变量对象(Variable object,VO);
- 作用域链(Scope chain);
- this。(关于 this 指向问题,在上面推荐的深入系列也有讲从 ES 规范讲的,但是实在是难懂,对于应付面试来说以下这篇阮一峰的文章应该就可以了:JavaScript 的 this 原理)
5、 闭包
根据 MDN 中文的定义,闭包的定义如下:
在 JavaScript 中,每当创建一个函数,闭包就会在函数创建的同时被创建出来。可以在一个内层函数中访问到其外层函数的作用域。
也可以这样说:
闭包是指那些能够访问自由变量的函数。 自由变量是指在函数中使用的,但既不是函数参数也不是函数的局部变量的变量。 闭包 = 函数 + 函数能够访问的自由变量。
在经过上一小节“执行上下文”的学习,再来阅读这篇文章:JavaScript 深入之闭包,你会对闭包的实质有一定的了解。在回答时,我们这样答:
在某个内部函数的执行上下文创建时,会将父级函数的活动对象加到内部函数的 [[scope]] 中,形成作用域链,所以即使父级函数的执行上下文销毁(即执行上下文栈弹出父级函数的执行上下文),但是因为其活动对象还是实际存储在内存中可被内部函数访问到的,从而实现了闭包。
闭包应用: 函数作为参数被传递:
|
|
函数作为返回值被返回:
|
|
闭包:自由变量的查找,是在函数定义的地方,向上级作用域查找。不是在执行的地方。 ****
应用实例:比如缓存工具,隐藏数据,只提供 API 。
|
|
6、 call、apply、bind 实现
这部分实现还是要知道的,就算工作中不会自己手写,但是说不准面试官就是要问,知道点原理也好,可以扩宽我们写代码的思路。
call
call() 方法在使用一个指定的 this 值和若干个指定的参数值的前提下调用某个函数或方法。
举个例子:
|
|
通过 call 方法我们做到了以下两点:
call改变了 this 的指向,指向到obj。fn函数执行了。
那么如果我们自己写 call 方法的话,可以怎么做呢?我们先考虑改造 obj 。
|
|
这时候 this 就指向了 obj ,但是这样做我们手动给 obj 增加了一个 fn 属性,这显然是不行的,不用担心,我们执行完再使用对象属性的删除方法(delete)不就行了?
|
|
根据这个思路,我们就可以写出来了:
|
|
apply
我们会了 call 的实现之后,apply 就变得很简单了,他们没有任何区别,除了传参方式。
|
|
bind
bind 返回的是一个函数,这个地方可以详细阅读这篇文章,讲的非常清楚:解析 bind 原理,并手写 bind 实现。
|
|
7、 new 实现
- 首先创一个新的空对象。
- 根据原型链,设置空对象的
__proto__为构造函数的prototype。 - 构造函数的 this 指向这个对象,执行构造函数的代码(为这个新对象添加属性)。
- 判断函数的返回值类型,如果是引用类型,就返回这个引用类型的对象。
|
|
8、 异步
这部分着重要理解 Promise、async awiat、event loop 等。
8.1 event loop、宏任务和微任务
首先推荐一个可以在线看代码流程的网站:loupe。 然后看下这个视频学习下:到底什么是 Event Loop 呢?
简单的例子:
|
|
它的执行过程是这样的:
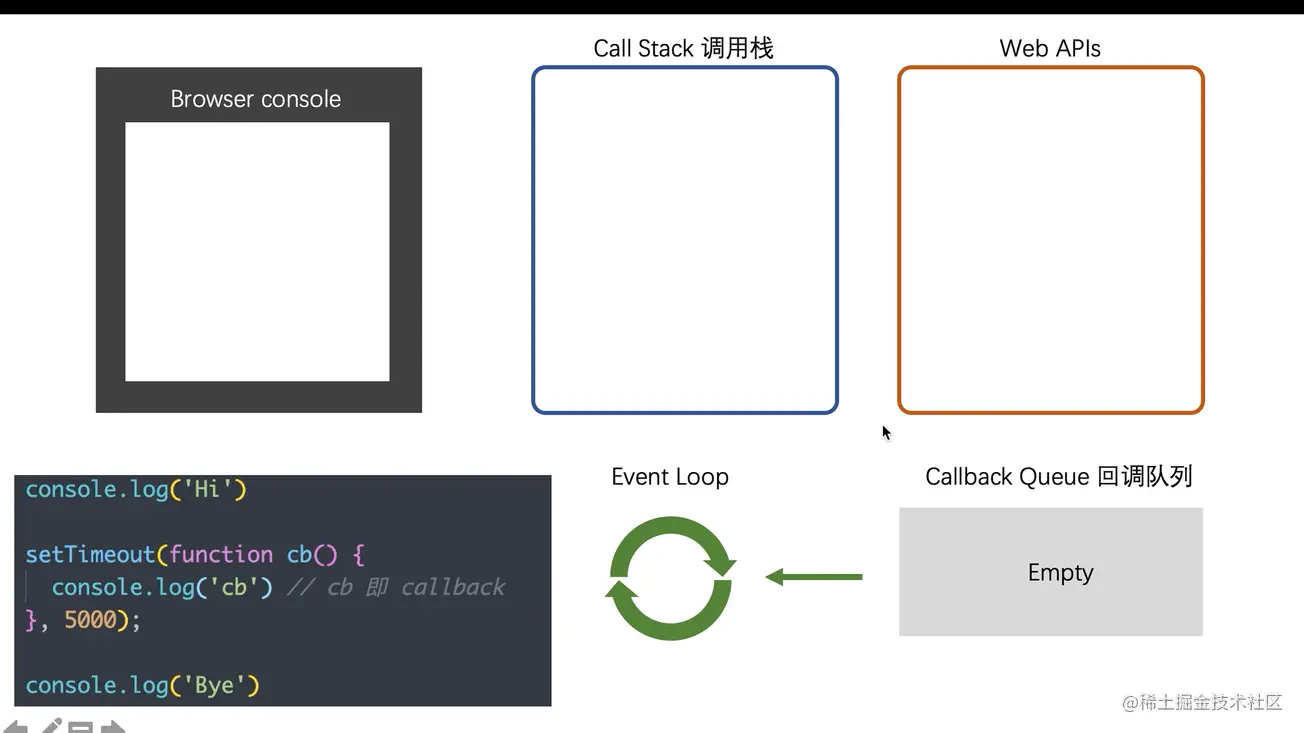
setTimeout 会创建定时器线程,ajax 请求会创建 http 线程。。。这是由 js 的运行环境决定的,比如浏览器。
看完上面的视频之后,至少大家画 Event Loop 的图讲解不是啥问题了,但是涉及到宏任务和微任务,我们还得拜读一下这篇文章:这一次,彻底弄懂 JavaScript 执行机制。如果意犹未尽,不如再读下这篇非常详细带有大量动图的文章:做一些动图,学习一下 EventLoop。想了解事件循环和页面渲染之间关系的又可以再阅读这篇文章:深入解析你不知道的 EventLoop 和浏览器渲染、帧动画、空闲回调(动图演示)。
注意:1.Call Stack 调用栈空闲 -> 2.尝试 DOM 渲染 -> 触发 Event loop。
- 每次 Call Stack 清空(即每次轮询结束),即同步任务执行完。
- 都是 DOM 重新渲染的机会,DOM 结构有改变则重新渲染。
- 然后再去触发下一次 Event loop。
宏任务:setTimeout,setInterval,Ajax,DOM 事件。 微任务:Promise async/await。
两者区别:
- 宏任务:DOM 渲染后触发,如
setTimeout、setInterval、DOM 事件、script。 - 微任务:DOM 渲染前触发,如
Promise.then、MutationObserver、Node 环境下的process.nextTick。
从 event loop 解释,为何微任务执行更早?
- 微任务是 ES6 语法规定的(被压入 micro task queue)。
- 宏任务是由浏览器规定的(通过 Web APIs 压入 Callback queue)。
- 宏任务执行时间一般比较长。
- 每一次宏任务开始之前一定是伴随着一次 event loop 结束的,而微任务是在一次 event loop 结束前执行的。
8.2 Promise
关于这一块儿没什么好说的,最好是实现一遍 Promise A+ 规范,多少有点印象,当然面试官也不会叫你默写一个完整的出来,但是你起码要知道实现原理。
关于 Promise 的所有使用方式,可参照这篇文章:ECMAScript 6 入门 - Promise 对象。 手写 Promise 源码的解析文章,可阅读此篇文章:从一道让我失眠的 Promise 面试题开始,深入分析 Promise 实现细节。 关于 Promise 的面试题,可参考这篇文章:要就来 45 道 Promise 面试题一次爽到底。
实现一个 Promise.all:
|
|
8.3 async/await 和 Promise 的关系
- async/await 是消灭异步回调的终极武器。
- 但和 Promise 并不互斥,反而,两者相辅相成。
- 执行 async 函数,返回的一定是 Promise 对象。
- await 相当于 Promise 的 then。
- tru…catch 可捕获异常,代替了 Promise 的 catch。
9、 浏览器的垃圾回收机制
这里看这篇文章即可:「硬核 JS」你真的了解垃圾回收机制吗。
总结一下:
有两种垃圾回收策略:
- 标记清除:标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁。
- 引用计数:它把对象是否不再需要简化定义为对象有没有其他对象引用到它。如果没有引用指向该对象(引用计数为 0),对象将被垃圾回收机制回收。
标记清除的缺点:
- 内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块。
- 分配速度慢,因为即便是使用 First-fit 策略,其操作仍是一个 O(n) 的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢。
解决以上的缺点可以使用 **标记整理(Mark-Compact)算法 **,标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存(如下图)
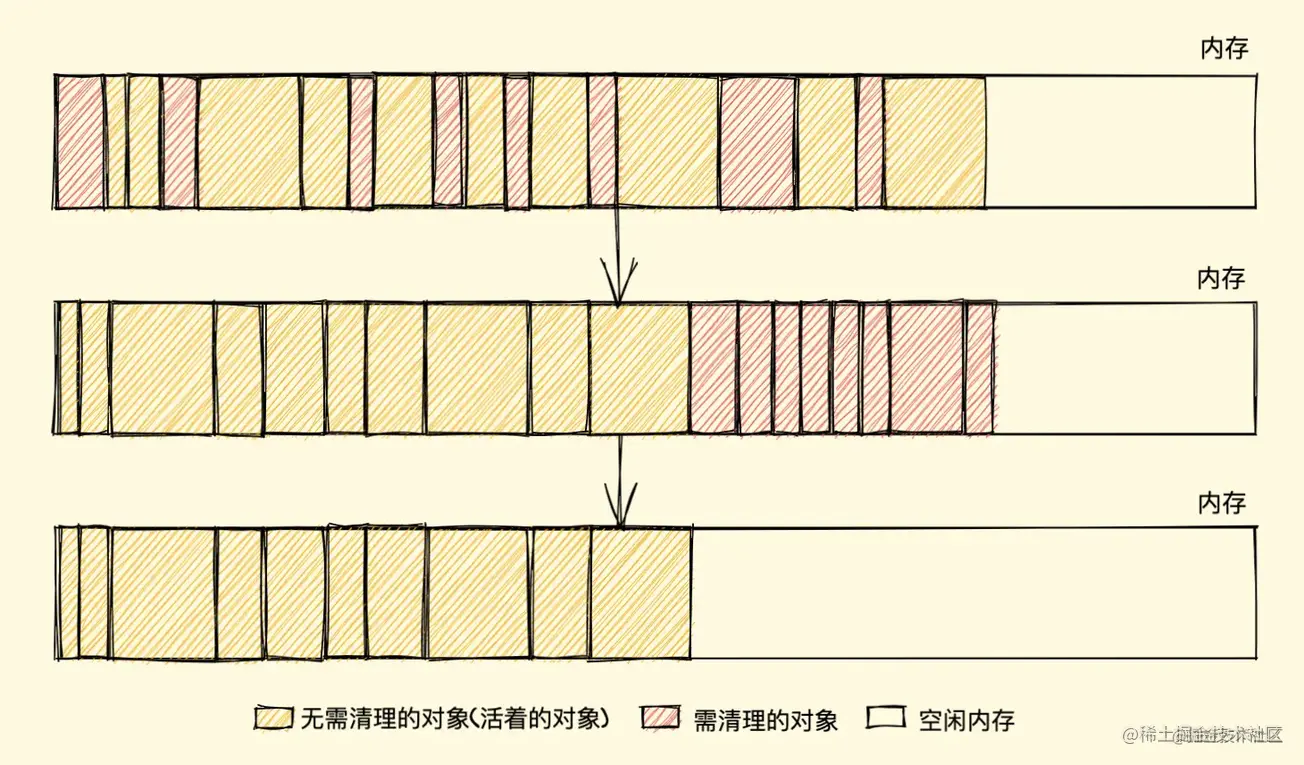
引用计数的缺点:
- 需要一个计数器,所占内存空间大,因为我们也不知道被引用数量的上限。
- 解决不了循环引用导致的无法回收问题。
V8 的垃圾回收机制也是基于标记清除算法,不过对其做了一些优化。
- 针对新生区采用并行回收。
- 针对老生区采用增量标记与惰性回收。
10、 实现一个 EventMitter 类
EventMitter 就是发布订阅模式的典型应用:
|
|
四、web 存储
要掌握 cookie,localStorage 和 sessionStorage。
1、cookie
- 本身用于浏览器和 server 通讯。
- 被“借用”到本地存储来的。
- 可用 document.cookie = ‘…’ 来修改。
其缺点:
- 存储大小限制为 4KB。
- http 请求时需要发送到服务端,增加请求数量。
- 只能用 document.cookie = ‘…’ 来修改,太过简陋。
2、localStorage 和 sessionStorage
- HTML5 专门为存储来设计的,最大可存 5M。
- API 简单易用, setItem getItem。
- 不会随着 http 请求被发送到服务端。
它们的区别:
- localStorage 数据会永久存储,除非代码删除或手动删除。
- sessionStorage 数据只存在于当前会话,浏览器关闭则清空。
- 一般用 localStorage 会多一些。
五、Http
前端工程师做出网页,需要通过网络请求向后端获取数据,因此 http 协议是前端面试的必考内容。
1、http 状态码
1.1 状态码分类
- 1xx - 服务器收到请求。
- 2xx - 请求成功,如 200。
- 3xx - 重定向,如 302。
- 4xx - 客户端错误,如 404。
- 5xx - 服务端错误,如 500。
1.2 常见状态码
- 200 - 成功。
- 301 - 永久重定向(配合 location,浏览器自动处理)。
- 302 - 临时重定向(配合 location,浏览器自动处理)。
- 304 - 资源未被修改。
- 403 - 没权限。
- 404 - 资源未找到。
- 500 - 服务器错误。
- 504 - 网关超时。
1.3 关于协议和规范
- 状态码都是约定出来的。
- 要求大家都跟着执行。
- 不要违反规范,例如 IE 浏览器。
2、http 缓存
- 关于缓存的介绍。
- http 缓存策略(强制缓存 + 协商缓存)。
- 刷新操作方式,对缓存的影响。
4.1 关于缓存
什么是缓存? 把一些不需要重新获取的内容再重新获取一次
为什么需要缓存? 网络请求相比于 CPU 的计算和页面渲染是非常非常慢的。
哪些资源可以被缓存? 静态资源,比如 js css img。
4.2 强制缓存
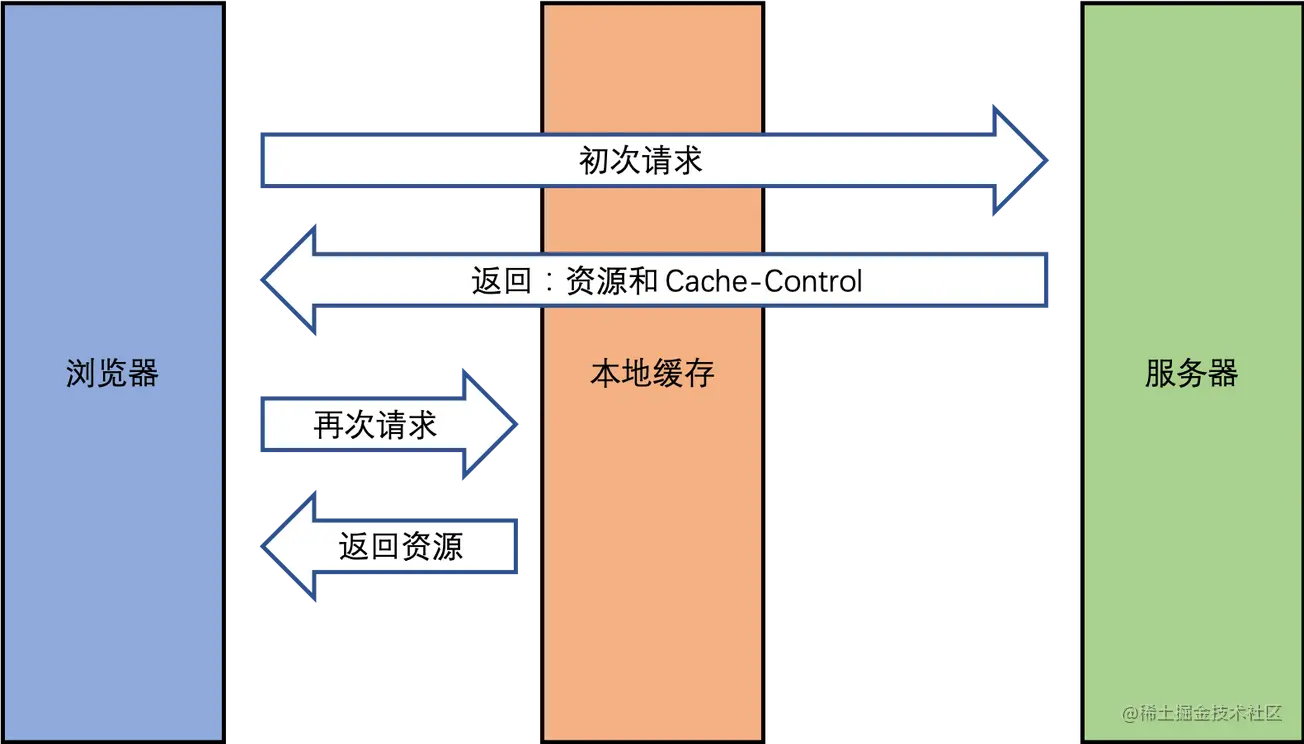
Cache-Control:
- 在 Response Headers 中。
- 控制强制缓存的逻辑。
- 例如 Cache-Control: max-age=3153600(单位是秒)
Cache-Control 有哪些值:
- max-age:缓存最大过期时间。
- no-cache:可以在客户端存储资源,每次都必须去服务端做新鲜度校验,来决定从服务端获取新的资源(200)还是使用客户端缓存(304)。
- no-store:永远都不要在客户端存储资源,永远都去原始服务器去获取资源。
4.3 协商缓存(对比缓存)
- 服务端缓存策略。
- 服务端判断客户端资源,是否和服务端资源一样。
- 一致则返回 304,否则返回 200 和最新的资源。
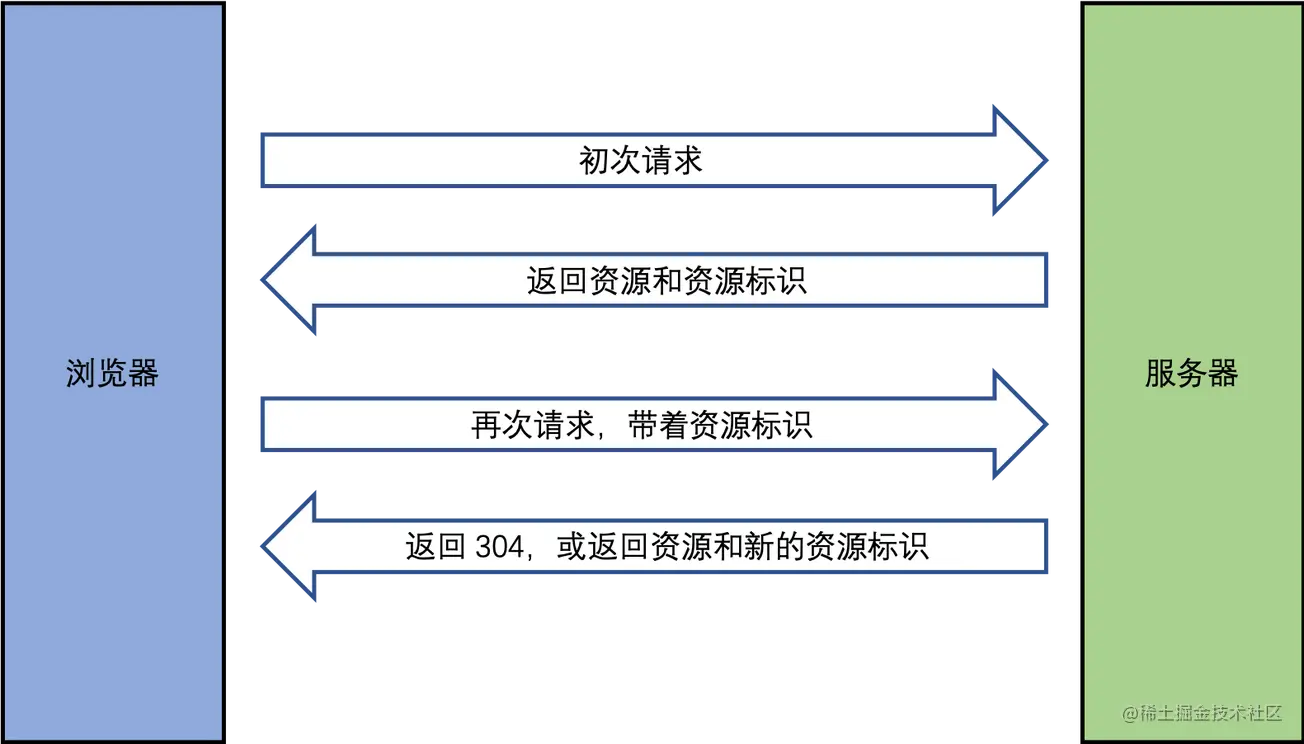
- 在 Response Headers 中,有两种。
- Last-Modified:资源的最后修改时间。
- Etag:资源的唯一标识(一个字符串,类似于人类的指纹)。
Last-Modified:
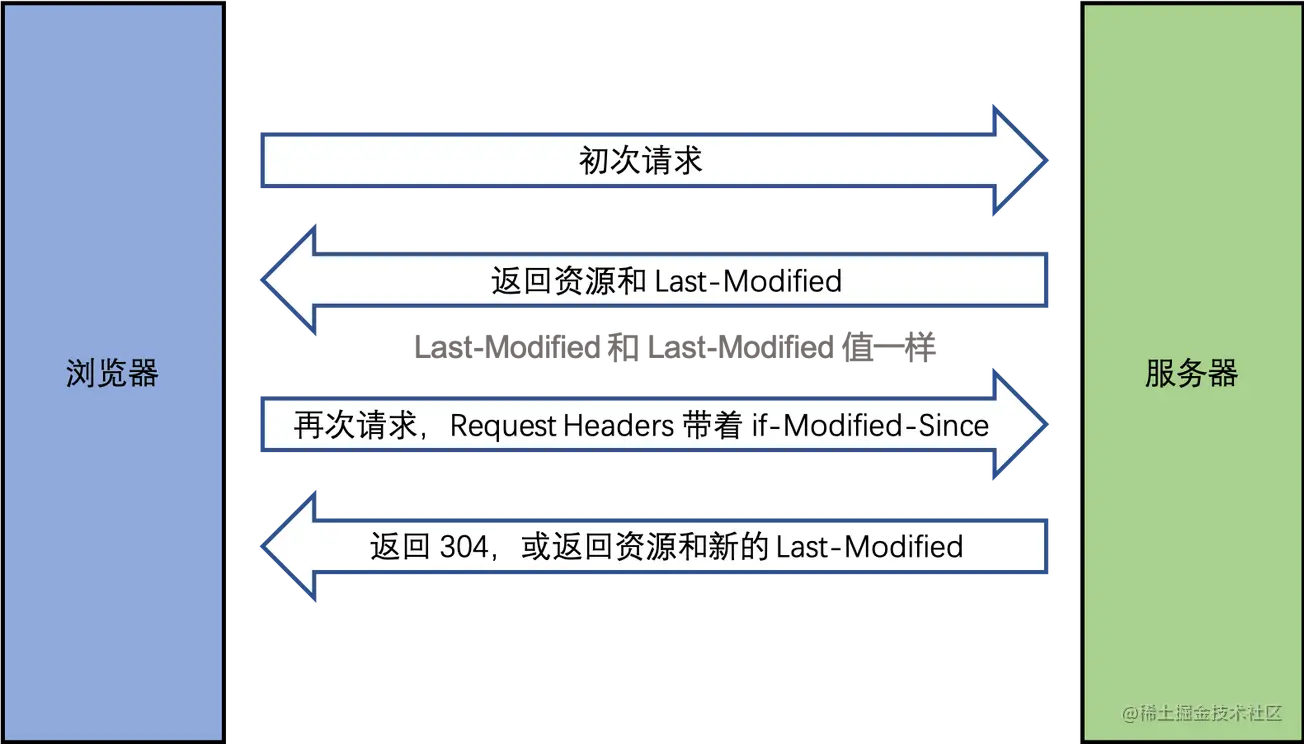
Etag:
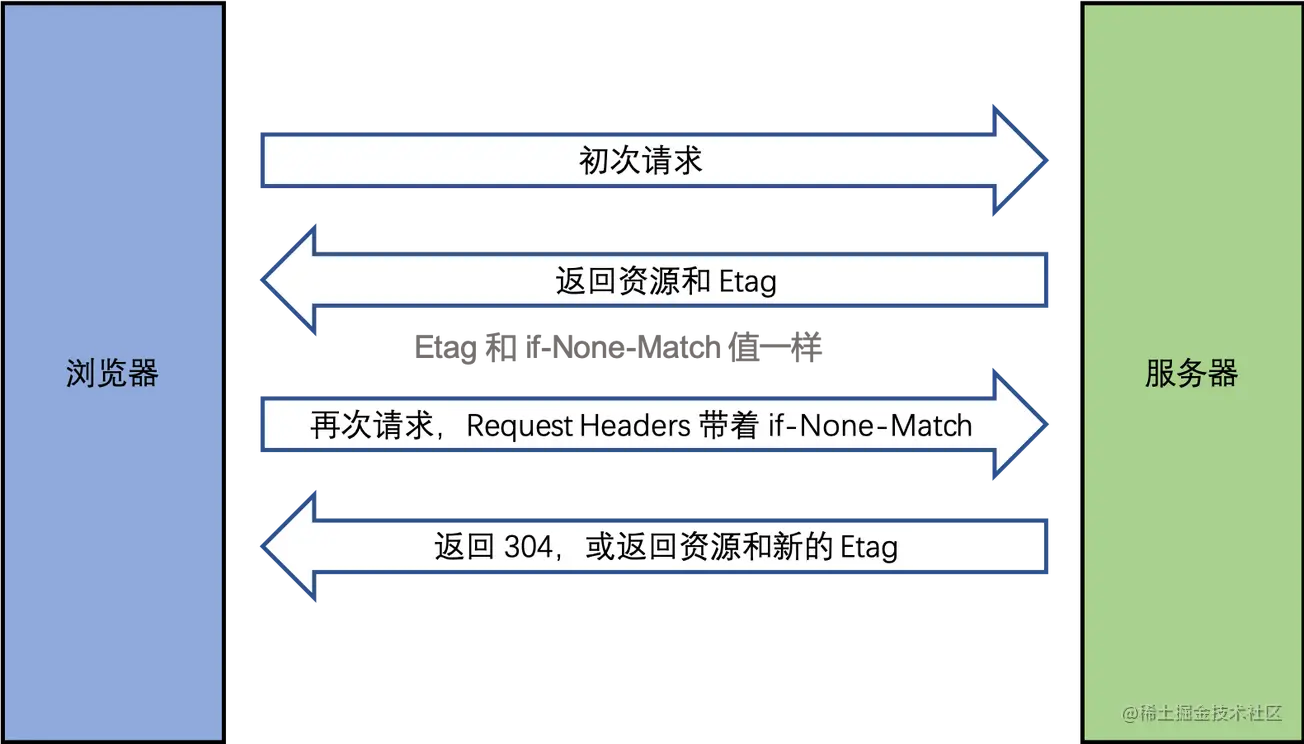
两者比较:
- 优先使用 Etag。
- Last-Modified 只能精确到秒级。
- 如果资源被重复生成,而内容不变,则 Etag 更精确。
4.4 综述
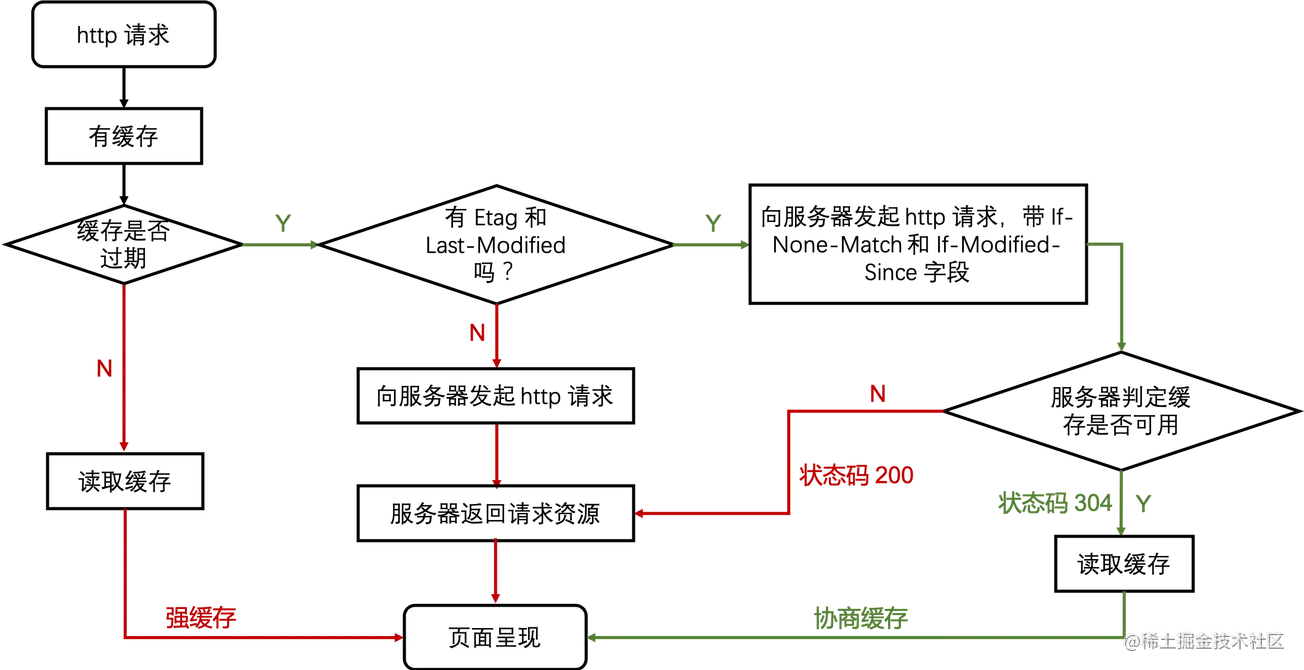
4.4 三种刷新操作对 http 缓存的影响
- 正常操作:地址栏输入 url,跳转链接,前进后退等。
- 手动刷新:f5,点击刷新按钮,右键菜单刷新。
- 强制刷新:ctrl + f5,shift+command+r。
正常操作:强制缓存有效,协商缓存有效。 手动刷新:强制缓存失效,协商缓存有效。 强制刷新:强制缓存失效,协商缓存失效。 ****
3. 面试
对于更多面试中可能出现的问题,我还是建议精读这篇三元的文章:HTTP 灵魂之问,巩固你的 HTTP 知识体系。
比如会被经常问到的: GET 和 POST 的区别。
- 从缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。
- 从编码的角度,GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。
- 从参数的角度,GET 一般放在 URL 中,因此不安全,POST 放在请求体中,更适合传输敏感信息。
- 从幂等性的角度,GET 是幂等的,而 POST 不是。(幂等表示执行相同的操作,结果也是相同的)
- 从 TCP 的角度,GET 请求会把请求报文一次性发出去,而 POST 会分为两个 TCP 数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。(火狐浏览器除外,它的 POST 请求只发一个 TCP 包)
HTTP/2 有哪些改进?(很大可能问原理)
- 头部压缩。
- 多路复用。
- 服务器推送。
关于 HTTPS 的一些原理,可以阅读这篇文章:这一次,彻底理解 https 原理。接着你可以观看这个视频进行更进一步的学习:HTTPS 底层原理,面试官直接下跪,唱征服!
关于跨域问题,大部分文章都是理论性比较强,还不如读这篇文章,聊聊跨域的原理与解决方法,讲的非常清晰,我个人觉得对付面试就是先知道使用流程,把这个流程能自己说出来,然后再讲下原理即可。
六、React
1、 React 事件机制,React 16 和 React 17 事件机制的不同
阅读这篇文章即可:一文吃透 react 事件系统原理。
为什么要自定义事件机制?
- 抹平浏览器差异,实现更好的跨平台。
- 避免垃圾回收,React 引入事件池,在事件池中获取或释放事件对象,避免频繁地去创建和销毁。
- 方便事件统一管理和事务机制。
2、class component
不排除现在还会有面试官问关于 class component 的问题。
2.1 生命周期
- 初始化阶段。
发生在 constructor 中的内容,在 constructor 中进行 state 、props 的初始化,在这个阶段修改 state,不会执行更新阶段的生命周期,可以直接对 state 赋值。
- 挂载阶段。
|
|
- 更新阶段。
更新阶段分为由 state 更新引起和 props 更新引起。
|
|
- 卸载阶段。
|
|
在 React 16 中官方已经建议删除以下三个方法,非要使用必须加前缀:UNSAVE_ 。
|
|
取代这两三个生命周期的以下两个新的。
|
|
需要注意的是,一般都会问为什么要废弃三个生命周期,原因是什么。
2.2 setState 同步还是异步
setState 本身代码的执行肯定是同步的,这里的异步是指是多个 state 会合成到一起进行批量更新。 同步还是异步取决于它被调用的环境。
- 如果
setState在 React 能够控制的范围被调用,它就是异步的。比如合成事件处理函数,生命周期函数, 此时会进行批量更新,也就是将状态合并后再进行 DOM 更新。 - 如果
setState在原生 JavaScript 控制的范围被调用,它就是同步的。比如原生事件处理函数,定时器回调函数,Ajax 回调函数中,此时setState被调用后会立即更新 DOM 。
3、对函数式编程的理解
这篇文章写的真的太好了,一定要读:简明 JavaScript 函数式编程——入门篇。
总结一下: 函数式编程有两个核心概念。
- 数据不可变(无副作用): 它要求你所有的数据都是不可变的,这意味着如果你想修改一个对象,那你应该创建一个新的对象用来修改,而不是修改已有的对象。
- 无状态: 主要是强调对于一个函数,不管你何时运行,它都应该像第一次运行一样,给定相同的输入,给出相同的输出,完全不依赖外部状态的变化。
纯函数带来的意义。
- 便于测试和优化:这个意义在实际项目开发中意义非常大,由于纯函数对于相同的输入永远会返回相同的结果,因此我们可以轻松断言函数的执行结果,同时也可以保证函数的优化不会影响其他代码的执行。
- 可缓存性:因为相同的输入总是可以返回相同的输出,因此,我们可以提前缓存函数的执行结果。
- 更少的 Bug:使用纯函数意味着你的函数中不存在指向不明的 this,不存在对全局变量的引用,不存在对参数的修改,这些共享状态往往是绝大多数 bug 的源头。
4、react hooks
现在应该大多数面试官会问 hooks 相关的啦。这里我强烈推荐三篇文章,即使没看过源码,也能比较好地理解一些原理: 用动画和实战打开 React Hooks(一):useState 和 useEffect 用动画和实战打开 React Hooks(二):自定义 Hook 和 useCallback 用动画和实战打开 React Hooks(三):useReducer 和 useContext
4.1 为什么不能在条件语句中写 hook
推荐这篇文章:我打破了 React Hook 必须按顺序、不能在条件语句中调用的枷锁。
hook 在每次渲染时的查找是根据一个“全局”的下标对链表进行查找的,如果放在条件语句中使用,有一定几率会造成拿到的状态出现错乱。
4.2 HOC 和 hook 的区别
hoc 能复用逻辑和视图,hook 只能复用逻辑。
4.3 useEffect 和 useLayoutEffect 区别
对于 React 的函数组件来说,其更新过程大致分为以下步骤:
- 因为某个事件
state发生变化。 - React 内部更新
state变量。 - React 处理更新组件中 return 出来的 DOM 节点(进行一系列 dom diff 、调度等流程)。
- 将更新过后的 DOM 数据绘制到浏览器中。
- 用户看到新的页面。
useEffect 在第 4 步之后执行,且是异步的,保证了不会阻塞浏览器进程。 useLayoutEffect 在第 3 步至第 4 步之间执行,且是同步代码,所以会阻塞后面代码的执行。
4.4 useEffect 依赖为空数组与 componentDidMount 区别
在 render 执行之后,componentDidMount 会执行,如果在这个生命周期中再一次 setState ,会导致再次 render ,返回了新的值,浏览器只会渲染第二次 render 返回的值,这样可以避免闪屏。
但是 useEffect 是在真实的 DOM 渲染之后才会去执行,这会造成两次 render ,有可能会闪屏。
实际上 useLayoutEffect 会更接近 componentDidMount 的表现,它们都同步执行且会阻碍真实的 DOM 渲染的。
4.5 React.memo() 和 React.useMemo() 的区别
memo是一个高阶组件,默认情况下会对props进行浅比较,如果相等不会重新渲染。多数情况下我们比较的都是引用类型,浅比较就会失效,所以我们可以传入第二个参数手动控制。useMemo返回的是一个缓存值,只有依赖发生变化时才会去重新执行作为第一个参数的函数,需要记住的是,useMemo是在render阶段执行的,所以不要在这个函数内部执行与渲染无关的操作,诸如副作用这类的操作属于useEffect的适用范畴。
4.6 React.useCallback() 和 React.useMemo() 的区别
useCallback可缓存函数,其实就是避免每次重新渲染后都去重新执行一个新的函数。useMemo可缓存值。
有很多时候,我们在 useEffect 中使用某个定义的外部函数,是要添加到 deps 数组中的,如果不用 useCallback 缓存,这个函数在每次重新渲染时都是一个完全新的函数,也就是引用地址发生了变化,这就会导致 useEffect 总会无意义的执行。
4.7 React.forwardRef 是什么及其作用
这里还是阅读官方文档来的清晰:React.forwardRef。 一般在父组件要拿到子组件的某个实际的 DOM 元素时会用到。
6、react hooks 与 class 组件对比
react hooks 与 class 组件对比 函数式组件与类组件有何不同
7、介绍 React dom diff 算法
8、对 React Fiber 的理解
关于这块儿我觉得可以好好阅读下这篇无敌的博客了:Build your own React。 它可以教你一步步实现一个简单的基于 React Fiber 的 React,可以学到很多 React 的设计思想,毕竟为了面试我们可能大多数人是没有时间或能力去阅读源码的了。
然后我们再阅读下其它作者对于 React Fiber 的理解,再转化为我们自己的思考总结,以下是推荐文章: 这可能是最通俗的 React Fiber(时间分片) 打开方式
9、React 性能优化手段
- 使用
React.memo来缓存组件。 - 使用
React.useMemo缓存大量的计算。 - 避免使用匿名函数。
- 利用
React.lazy和React.Suspense延迟加载不是立即需要的组件。 - 尽量使用 CSS 而不是强制加载和卸载组件。
- 使用
React.Fragment避免添加额外的 DOM。
10、React Redux
七、webpack
原理初探:当面试官问 Webpack 的时候他想知道什么 简易实现:面试官:webpack 原理都不会,手写一个 webpack,看看 AST 怎么用 加料:简单易懂的 webpack 打包后 JS 的运行过程,Webpack 手写 loader 和 plugin 热更新原理:Webpack HMR 原理解析 面试题:「吐血整理」再来一打 Webpack 面试题
这里要注意,应该还会考 webpack5 和 4 有哪些区别。
八、模块化
前端模块化详解(完整版) (这里面没有讲 umd) 可能是最详细的 UMD 模块入门指南
九、性能优化
代码层面:
- 防抖和节流(resize,scroll,input)。
- 减少回流(重排)和重绘。
- 事件委托。
- css 放 ,js 脚本放 最底部。
- 减少 DOM 操作。
- 按需加载,比如 React 中使用
React.lazy和React.Suspense,通常需要与 webpack 中的splitChunks配合。
构建方面:
- 压缩代码文件,在 webpack 中使用
terser-webpack-plugin压缩 Javascript 代码;使用css-minimizer-webpack-plugin压缩 CSS 代码;使用html-webpack-plugin压缩 html 代码。 - 开启 gzip 压缩,webpack 中使用
compression-webpack-plugin,node 作为服务器也要开启,使用compression。 - 常用的第三方库使用 CDN 服务,在 webpack 中我们要配置 externals,将比如 React, Vue 这种包不打倒最终生成的文件中。而是采用 CDN 服务。
其它:
- 使用 http2。因为解析速度快,头部压缩,多路复用,服务器推送静态资源。
- 使用服务端渲染。
- 图片压缩。
- 使用 http 缓存,比如服务端的响应中添加
Cache-Control / Expires。
十、常见手写
以下的内容是上面没有提到的手写,比如 new 、Promise.all 这种上面内容中已经提到了如何写。
1、防抖
JavaScript 专题之跟着 underscore 学防抖
|
|
2、节流
JavaScript 专题之跟着 underscore 学节流
|
|
3、快速排序
这里对快排思想不太明白的同学可以看下这个讲解的很清晰的视频:快速排序算法。
|
|
4、instanceof
这个手写一定要懂原型及原型链。
|
|
5、数组扁平化
重点,不要觉得用不到就不管,这道题就是考察你对 js 语法的熟练程度以及手写代码的基本能力。
|
|
6、手写 reduce
先不考虑第二个参数初始值:
|
|
考虑上初始值:
|
|
7、带并发的异步调度器 Scheduler
JS 实现一个带并发限制的异度调度器 Scheduler,保证同时运行的任务最多有两个。完善下面代码中的 Scheduler 类,使得以下程序能正确输出。
|
|
根据题目,我们只需要操作 Scheduler 类就行:
|
|
8、去重
- 利用 ES6
set关键字:
|
|
- 利用 ES5
filter方法:
|
|
十一、其它
- requestAnimationFrame(一个神奇的前端动画 API requestAnimationFrame)
- 如何排查内存泄漏问题,面试官可能会问为什么页面越来越卡顿,直至卡死,怎么定位到产生这种现象的源代码(开发环境)?(一文带你了解如何排查内存泄漏导致的页面卡顿现象)
- vite 大火,我复习的时候是去年 9 月份,还没那么火,可能现在的你需要学一学了~
- vue3 也一样,如果你是 React 技术栈(就像我之前一样)当我没说。
十二、算法
这部分大家可以点击以下这个仓库,按照仓库中的题目顺序进行刷题,都是我亲自刷过的,排了最适合的顺序:vortesnail/leetcode。 然后如果大家想看下大厂的算法高频题可以看这个仓库:afatcoder/LeetcodeTop。
作者:vortesnail 链接:https://juejin.cn/post/7061588533214969892 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/css/%E5%89%8D%E7%AB%AF%E7%9F%A5%E8%AF%86%E7%82%B9%E5%A4%A7%E5%85%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


