让你更懂 JavaScript:V8 引擎的内部结构
V8 是一个非常复杂的项目,有超过 100 万行 C++ 代码。它由许多子模块构成,其中这 4 个模块是最重要的:
Parse
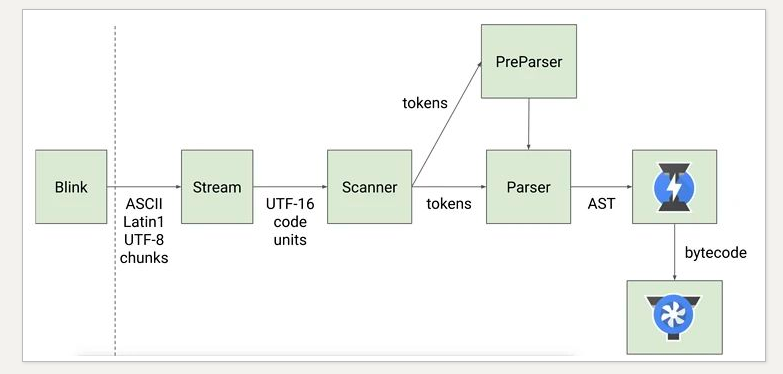
负责将 JavaScript 源码转换为 Abstract Syntax Tree (AST)。确切的说,在 Parser 将 JavaScript 源码转换为 AST 前,还有一个叫 Scanner 的过程,具体流程如下:
Ignition
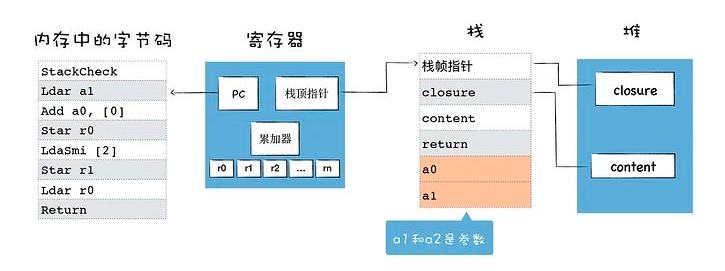
即解释器,负责将 AST 转换为 Bytecode,解释执行 Bytecode;同时收集 TurboFan 优化编译所需的信息,比如函数参数的类型;解释器执行时主要有四个模块,内存中的字节码、寄存器、栈、堆。通常有两种类型的解释器,基于栈 (Stack-based) 和 基于寄存器 (Register-based)。
- 基于栈的解释器:使用栈来保存函数参数、中间运算结果、变量等;
- 基于寄存器的虚拟机则支持寄存器的指令操作,使用寄存器来保存参数、中间计算结果。 通常,基于栈的虚拟机也定义了少量的寄存器,基于寄存器的虚拟机也有堆栈,其区别体现在它们提供的指令集体系。大多数解释器都是基于栈的,比如 Java 虚拟机,.Net 虚拟机,还有早期的 V8 虚拟机。基于堆栈的虚拟机在处理函数调用、解决递归问题和切换上下文时简单明快。而现在的 V8 虚拟机则采用了基于寄存器的设计,它将一些中间数据保存到寄存器中。
TurboFan
compiler,即编译器,利用 Ignition 所收集的类型信息,将 Bytecode 转换为优化的汇编代码;
Orinoco
garbage collector,垃圾回收模块,负责将程序不再需要的内存空间回收。
其中,Parser,Ignition 以及 TurboFan 可以将 JS 源码编译为汇编代码,其流程图如下:
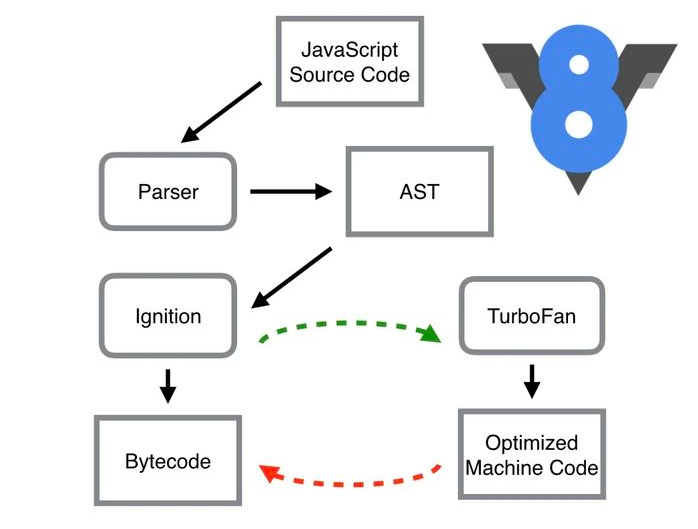
简单地说,Parser 将 JS 源码转换为 AST,然后 Ignition 将 AST 转换为 Bytecode,最后 TurboFan 将 Bytecode 转换为经过优化的 Machine Code(实际上是汇编代码)。
- 如果函数没有被调用,则 V8 不会去编译它。
- 如果函数只被调用 1 次,则 Ignition 将其编译 Bytecode 就直接解释执行了。TurboFan 不会进行优化编译,因为它需要 Ignition 收集函数执行时的类型信息。这就要求函数至少需要执行 1 次,TurboFan 才有可能进行优化编译。
- 如果函数被调用多次,则它有可能会被识别为热点函数,且 Ignition 收集的类型信息证明可以进行优化编译的话,这时 TurboFan 则会将 Bytecode 编译为 Optimized Machine Code(已优化的机器码),以提高代码的执行性能。 图片中的红色虚线是逆向的,也就是说 Optimized Machine Code 会被还原为 Bytecode,这个过程叫做 Deoptimization。这是因为 Ignition 收集的信息可能是错误的,比如 add 函数的参数之前是整数,后来又变成了字符串。生成的 Optimized Machine Code 已经假定 add 函数的参数是整数,那当然是错误的,于是需要进行 Deoptimization
function add(x, y) {
return x + y;
}
add(3, 5);
add('3', '5');
在运行 C、C++ 以及 Java 等程序之前,需要进行编译,不能直接执行源码;但对于 JavaScript 来说,我们可以直接执行源码 (比如:node test.js),它是在运行的时候先编译再执行,这种方式被称为「即时编译 (Just-in-time compilation)」,简称为 JIT。因此,V8 也属于 JIT 编译器。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/javascript/%E8%AE%A9%E4%BD%A0%E6%9B%B4%E6%87%82-JavaScript06-V8-%E5%BC%95%E6%93%8E%E7%9A%84%E5%86%85%E9%83%A8%E7%BB%93%E6%9E%84/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


