Sharding JDBC 分片策略四:Hint强制路由HintShardingStrategy
一、Hint强制路由HintShardingStrategy
在分库分区中,有些特定的SQL,Sharding-jdbc、Mycat、Vitess都不支持(可以查看相关文档各自对哪些SQL不支持),例如:insert into table1 select * from table2 where ….这种SQL 路由很麻烦,需要解析table2的路由(是在ds0 /ds1 table2_0/table_1),结果集归并,insert 语句也需要同样的路由解析。这种情况Sharding-jdbc可以使用Hint分片策略来实现各种Sharding-jdbc不支持语法的限制
- 通过Hint而非SQL解析的方式分片的策略。对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段
- Hint分片策略是绕过SQL解析的,所以对于这些比较复杂的需要分片的查询,采用Hint分片策略性能可能会更好
- 在读写分离数据库中,Hint 可以通过HintManager.setMasterRouteOnly()方法,强制读主库(主从复制存在一定延时,但在某些特定的业务场景中,可能更需要保证数据的实时性)
- 在读写分离中,Hint 可以强制读主库(主从复制是存在一定延时,但在业务场景中,可能更需要保证数据的实时性)
二、Hint强制路由HintShardingStrategy配置实现
Sharding -jdbc 在使用分片策略的时候,与分片算法是成对出现的,每种策略都对应一到两种分片算法(不分片策略NoneShardingStrategy除外)
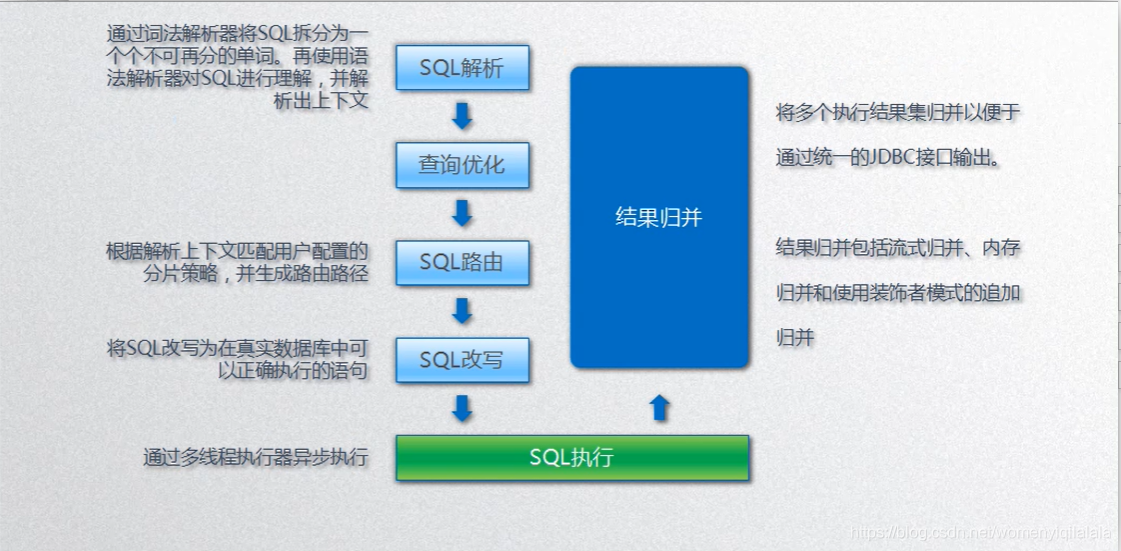
分库分表最核心的两点SQL 路由 、 SQL 改写
SQL 路由:解析原生SQL,确定需要使用哪些数据库,哪些数据表
Route (路由)引擎:为什么要用Route 引擎呢?
在实际查询当中,数据可能不只是存在一台MYSQL服务器上,
SELECT * FROM t_order WHERE order _id IN(1,3,6)
数据分布:
ds0.t_order0 (1,3,5,7)
ds1.t_order0(2,4,6)
这个SELECT 查询就需要走2个database,如果这个SQL原封不动的执行,肯定会报错(表不存在),Sharding-jdbc 必须要对这个sql进行改写,将库名和表名 2个路由加上
SELECT * FROM ds0.t_order0 WHERE order _id IN(1,3)
SELECT * FROM ds0.t_order1 WHERE order _id IN(6)
SQL 改写:将SQL 按照一定规则,重写FROM 的数据库和表名(Route 返回路由决定需要去哪些库表中执行SQL)
application.properties 配置
配置主要分为三个部分
- 配置数据源
- 分库配置
- 分表配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27# Hint 强制路由分片策略 sharding.jdbc.datasource.names=ds0,ds1 sharding.jdbc.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver sharding.jdbc.datasource.ds0.url=jdbc:mysql://127.0.0.1:5306/ds0?useUnicode=yes&characterEncoding=utf8 sharding.jdbc.datasource.ds0.username=root sharding.jdbc.datasource.ds0.password=root sharding.jdbc.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver sharding.jdbc.datasource.ds1.url=jdbc:mysql://127.0.0.1:5306/ds1?useUnicode=yes&characterEncoding=utf8 sharding.jdbc.datasource.ds1.username=root sharding.jdbc.datasource.ds1.password=root # 分库配置 sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2} # t_order强制分片配置 sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1} # 和其他3种不同的是,Hint 需要指定分片表 的数据库分片算法 + 表分片算法 sharding.jdbc.config.sharding.tables.t_order.database-strategy.hint.algorithm-class-name=ai.yunxi.sharding.config.HintShardingKeyAlgorithm sharding.jdbc.config.sharding.tables.t_order.table-strategy.hint.algorithm-class-name=ai.yunxi.sharding.config.HintShardingKeyAlgorithm sharding.jdbc.config.props.sql.show=true
自定义HintShardingKeyAlgorithm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41import com.alibaba.druid.util.StringUtils; import io.shardingsphere.api.algorithm.sharding.ListShardingValue; import io.shardingsphere.api.algorithm.sharding.ShardingValue; import io.shardingsphere.api.algorithm.sharding.hint.HintShardingAlgorithm; import java.util.ArrayList; import java.util.Collection; import java.util.List; public class HintShardingKeyAlgorithm implements HintShardingAlgorithm { /** * 自定义Hint 实现算法 * 能够保证绕过Sharding-JDBC SQL解析过程 * @param availableTargetNames * @param shardingValue 不再从SQL 解析中获取值,而是直接通过hintManager.addTableShardingValue("t_order", 1)参数指定 * @return */ @Override public Collection<String> doSharding(Collection<String> availableTargetNames, ShardingValue shardingValue) { System.out.println("shardingValue=" + shardingValue); System.out.println("availableTargetNames=" + availableTargetNames); List<String> shardingResult = new ArrayList<>(); for (String targetName : availableTargetNames) { String suffix = targetName.substring(targetName.length() - 1); if (StringUtils.isNumber(suffix)) { // hint分片算法的ShardingValue有两种具体类型: // ListShardingValue和RangeShardingValue // 使用哪种取决于HintManager.addDatabaseShardingValue(String, String, ShardingOperator,...),ShardingOperator的类型 ListShardingValue<Integer> tmpSharding = (ListShardingValue<Integer>) shardingValue; for (Integer value : tmpSharding.getValues()) { if (value % 2 == Integer.parseInt(suffix)) { shardingResult.add(targetName); } } } } return shardingResult; } }
编写测试类HintApplicationTests
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29import ai.yunxi.sharding.service.OrderService; import io.shardingsphere.api.HintManager; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; @RunWith(SpringRunner.class) @SpringBootTest(classes = VipShardingApplication.class) public class HintApplicationTests { @Autowired private OrderService orderService; @Test public void test() { // Hint分片策略必须要使用 HintManager工具类 HintManager hintManager = HintManager.getInstance(); // hintManager.addDatabaseShardingValue("t_order", 0); hintManager.addTableShardingValue("t_order", 1); // 直接指定对应具体的数据库 //hintManager.setDatabaseShardingValue(1); //在读写分离数据库中,Hint 可以强制读主库(主从复制是存在一定延时,但在业务场景中,可能更需要保证数据的实时性) //hintManager.setMasterRouteOnly(); System.out.println(orderService.findHint()); } }

- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/mybatis/Sharding-JDBC-%E5%88%86%E7%89%87%E7%AD%96%E7%95%A5%E5%9B%9BHint%E5%BC%BA%E5%88%B6%E8%B7%AF%E7%94%B1HintShardingStrategy/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


