万字长文带你解读深度学习的各类模型
文章作者:陈桂敏(Derek) 腾讯
导读:NLP,让人与机器的交互不再遥远;深度学习,让语言解析不再是智能系统的瓶颈。本文尝试回顾NLP发展的历史,解读NLP升级迭代过程中一些重要而有意思的模型,总结不同任务场景应用模型的思路,对NLP未来发展趋势发表自己的看法。笔者经验有限,如有不全或不当地方,请予指正。
背景
\\\__
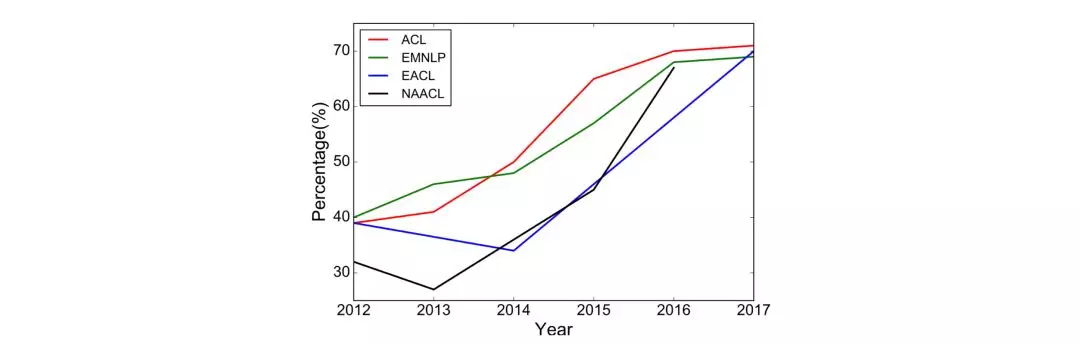
自然语言处理(英语:Natural Language Process,简称NLP)是计算机科学、信息工程以及人工智能的子领域,专注于人机语言交互,探讨如何处理和运用自然语言。自然语言处理的研究,最早可以说开始于图灵测试,经历了以规则为基础的研究方法,流行于现在基于统计学的模型和方法,从早期的传统机器学习方法,基于高维稀疏特征的训练方式,到现在主流的深度学习方法,使用基于神经网络的低维稠密向量特征训练模型。最近几年,随着深度学习以及相关技术的发展,NLP领域的研究取得一个又一个突破,研究者设计各种模型和方法,来解决NLP的各类问题。下图是Young等[1]统计了过去6年ACL、EMNLP、EACL和NAACL上发表深度学习长篇论文的比例逐年增加,而2018年下半场基本是ELMo、GPT、BERT等深度学习模型光芒四射的showtime,所以本文会将更多的笔墨用于陈述分析深度学习模型。
机器学习是计算机通过模式和推理、而不是明确指令的方式,高效执行指定任务的学习算法。贝叶斯概率模型、逻辑回归、决策树、SVM、主题模型、HMM模型等,都是常见的用于NLP研究的传统机器学习算法。而深度学习是一种基于特征学习的机器学习方法,把原始数据通过简单但非线性的模块转变成更高层次、更加抽象的特征表示,通过足够多的转换组合,非常复杂的函数也能被学习。在多年的实验中,人们发现了认知的两个重要机制:抽象和迭代,从原始信号,做底层抽象,逐渐向高层抽象迭代,在迭代中抽象出更高层的模式。如何形象地理解?在机器视觉领域会比较容易理解,深度学习通过多层神经网络依次提取出图像信息的边缘特征、简单形状特征譬如嘴巴的轮廓、更高层的形状特征譬如脸型;而在自然语言处理领域则没有那么直观的理解,我们可以通过深度学习模型学习到文本信息的语法特征和语义特征。可以说,深度学习,代表自然语言处理研究从机器学习到认知计算的进步。
要讲深度学习,得从语言模型开始讲起。自然语言处理的基础研究便是人机语言交互,以机器能够理解的算法来反映人类的语言,核心是基于统计学的语言模型。语言模型(英语:Language Model,简称LM),是一串词序列的概率分布。通过语言模型,可以量化地评估一串文字存在的可能性。对于一段长度为n的文本,文本中的每个单词都有通过上文预测该单词的过程,所有单词的概率乘积便可以用来评估文本存在的可能性。在实践中,如果文本很长,P(w_i|context(w_i))的估算会很困难,因此有了简化版:N元模型。在N元模型中,通过对当前词的前N个词进行计算来估算该词的条件概率。对于N元模型。常用的有unigram、bigram和trigram,N越大,越容易出现数据稀疏问题,估算结果越不准。为了解决N元模型估算概率时的数据稀疏问题,研究者尝试用神经网络来研究语言模型。
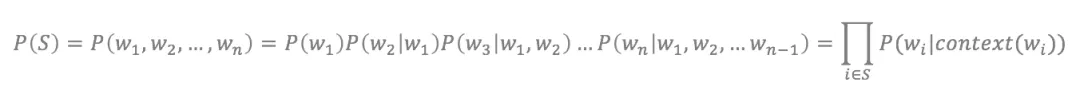
早在2000年,就有研究者提出用神经网络研究语言模型的想法,经典代表有2003年Bengio等[2]提出的NNLM,但效果并不显著,深度学习用于NLP的研究一直处在探索的阶段。直到2011年,Collobert等[3]用一个简单的深度学习模型在命名实体识别NER、语义角色标注SRL、词性标注POS-tagging等NLP任务取得SOTA成绩,基于深度学习的研究方法得到越来越多关注。2013年,以Word2vec、Glove为代表的词向量大火,更多的研究从词向量的角度探索如何提高语言模型的能力,研究关注词内语义和上下文语义。此外,基于深度学习的研究经历了CNN、RNN、Transormer等特征提取器,研究者尝试用各种机制优化语言模型的能力,包括预训练结合下游任务微调的方法。最近最吸睛的EMLo、GPT和BERT模型,便是这种预训练方法的优秀代表,频频刷新SOTA。
模型
\\\__
接下来文章会以循序渐进的方式分成五个部分来介绍深度学习模型:第一部分介绍一些基础模型;第二部分介绍基于CNN的模型;第三部分介绍基于RNN的模型;第四部分介绍基于Attention机制的模型;第五部分介绍基于Transformer的模型,讲述一段语言模型升级迭代的故事。NLP有很多模型和方法,不同的任务场景有不同的模型和策略来解决某些问题。笔者认为,理解了这些模型,再去理解别的模型便不是很难的事情,甚至可以自己尝试设计模型来满足具体任务场景的需求。
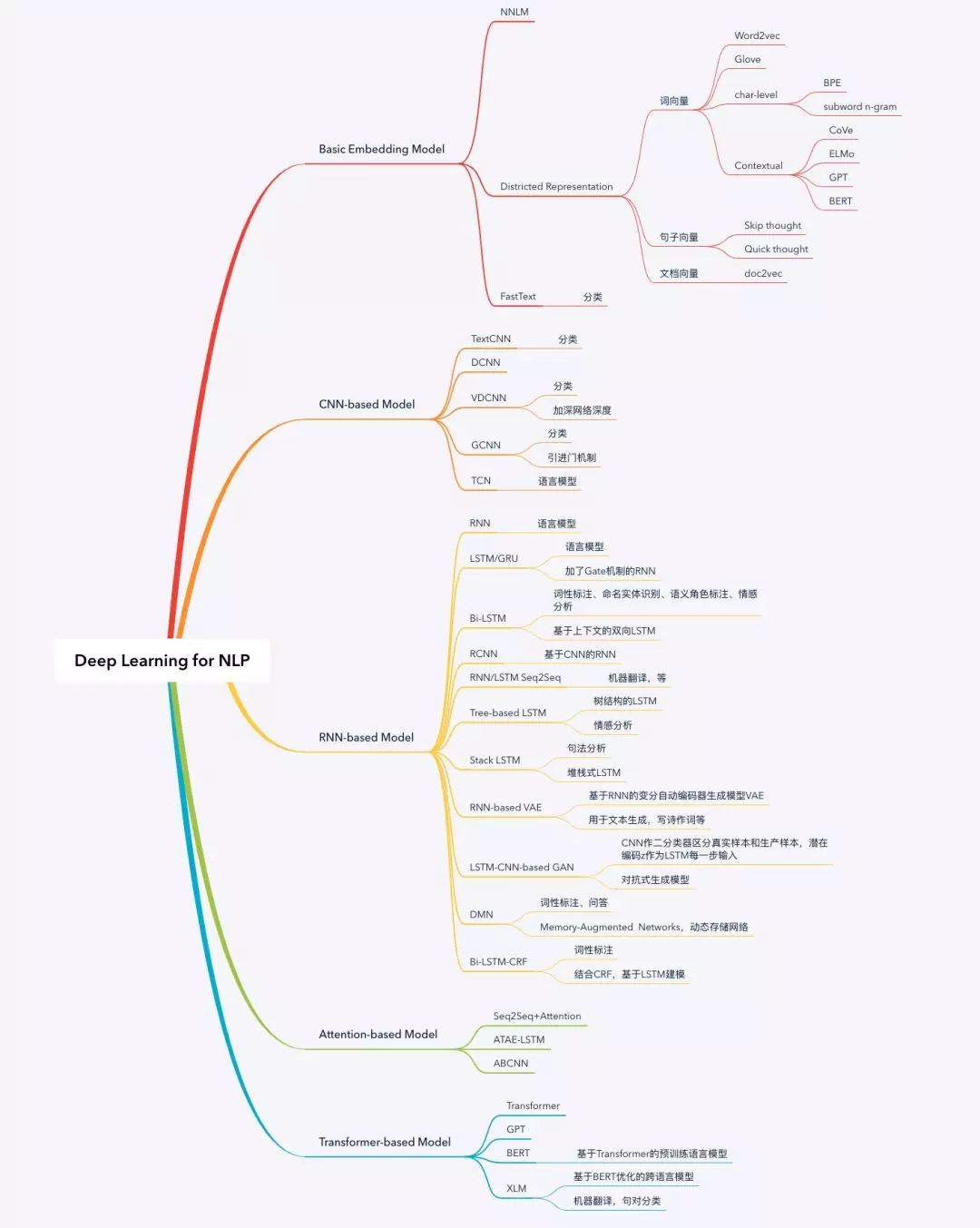
Basic Embedding Model
NNLM是非常经典的神经网络语言模型,虽然相比传统机器学习并没有很显著的成效,但大家说起NLP在深度学习方向的探索,总不忘提及这位元老。分布式表示的概念很早就有研究者提出并应用于深度学习模型,Word2vec使用CBOW和Skip-gram训练模型,意外的语意组合效果才使得词向量广泛普及。FastText在语言模型上没有什么特别的突破,但模型的优化使得深度学习模型在大规模数据的训练非常快甚至秒级,而且文本分类的效果匹敌CNN/RNN之类模型,在工业化应用占有一席之地。
NNLM
2003年Bengio等[2]提出一种基于神经网络的语言模型NNLM,模型同时学习词的分布式表示,并基于词的分布式表示,学习词序列的概率函数,这样就可以用词序列的联合概率来表示句子,而且,模型还能够产生指数量级的语义相似的句子。作者认为,通过这种方式训练出来的语言模型具有很强的泛化能力,对于训练语料里没有出现过的句子,模型能够通过见过的相似词组成的相似句子来学习。
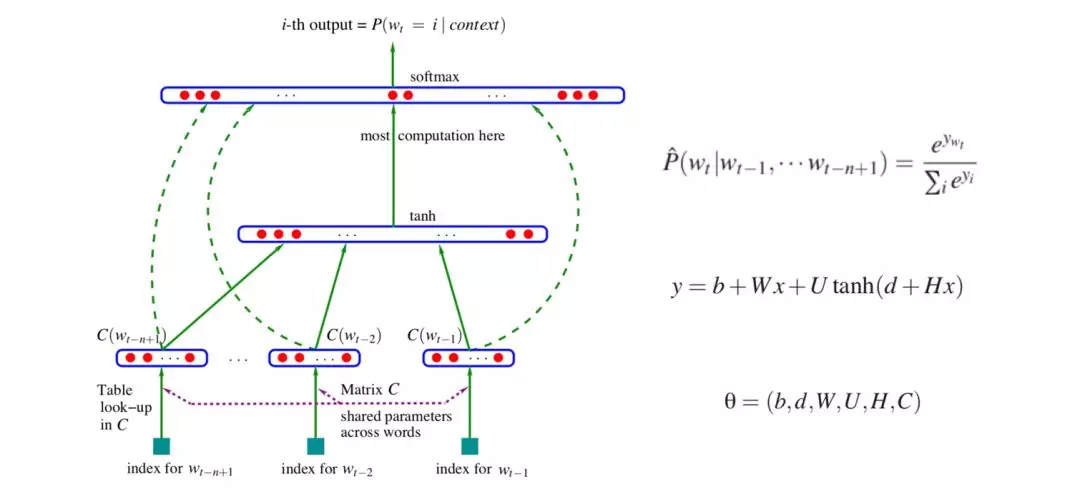
模型训练的目标函数是长度为n的词序列的联合概率,分解成两部分:一是特征映射,通过映射矩阵C,将词典V中的每个单词都能映射成一个特征向量C(i) ∈ Rm;二是计算条件概率分布,通过函数g,将输入的词向量序列(C(wt−n+1),··· ,C(wt−1))转化成一个概率分布y ∈ R|V|,g的输出是个向量,第i个元素表示词序列第n个词是Vi的概率。网络输出层采用softmax函数。
Word2vec
对于复杂的自然语言任务进行建模,概率模型应运而生成为首选的方法,但在最开始的时候,学习语言模型的联合概率函数存在致命的维数灾难问题。假如语言模型的词典大小为100000,要表示10个连续词的联合分布,模型参数可能就要有1050个。相应的,模型要具备足够的置信度,需要的样本量指数级增加。为了解决这个问题,最早是1986年Hinton等[5]提出分布式表示(Distributed Representation),基本思想是将词表示成n维连续的实数向量。分布式表示具备强大的特征表示能力,n维向量,每维有k个值,便能表示 kn个特征。
词向量是NLP深度学习研究的基石,本质上遵循这样的假设:语义相似的词趋向于出现在相似的上下文。因此在学习过程中,这些向量会努力捕捉词的邻近特征,从而学习到词汇之间的相似性。有了词向量,便能够通过计算余弦距离等方式来度量词与词之间的相似度。

Mikolov等[4]对词向量的广泛普及功不可没,他们用CBOW和Skip-gram模型训练出来的词向量具有神奇的语意组合特效,词向量的加减计算结果刚好是对应词的语意组合,譬如v(King) - v(Man) + v(Woman) = v(Queen)。这种意外的特效使得Word2vec快速流行起来。至于为什么会有这种行为呢?有意思的是Gittens等[10]做了研究,尝试给出了理论假设:词映射到低维分布式空间必须是均匀分布的,词向量才能有这个语意组合效果。
CBOW和Skip-gram是Word2vec的两种不同训练方式。CBOW指抠掉一个词,通过上下文预测该词;Skip-gram则与CBOW相反,通过一个词预测其上下文。
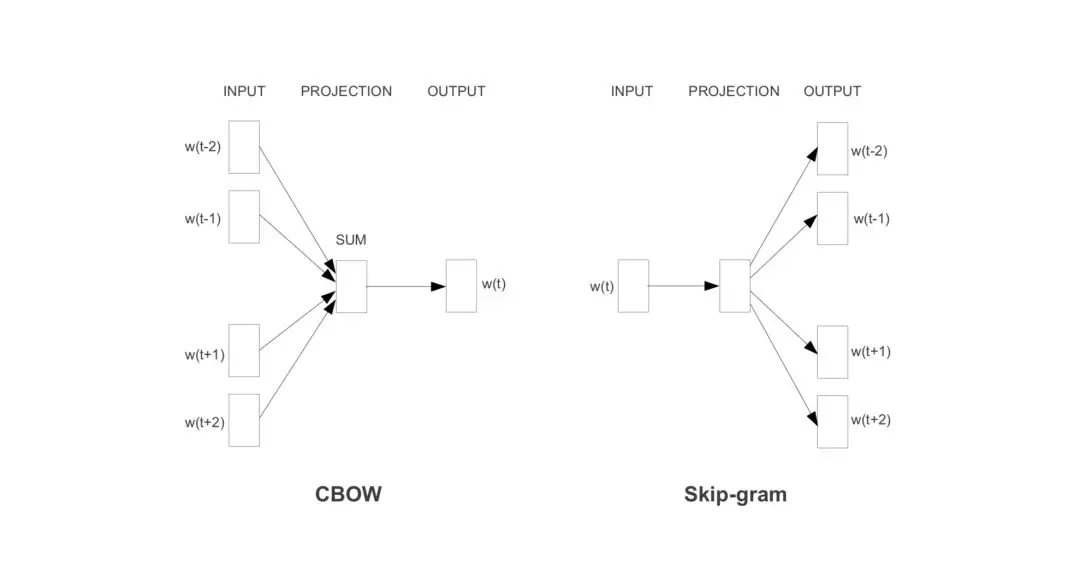
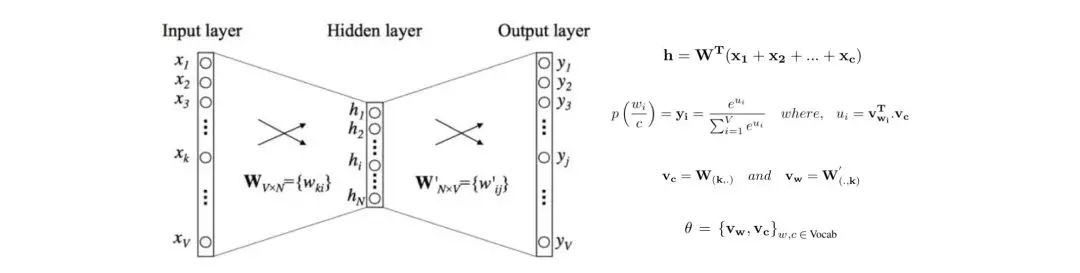
以CBOW为例。CBOW模型是一个简单的只包含一个隐含层的全连接神经网络,输入层采用one-hot编码方式,词典大小为V;隐含层大小是N;输出层通过softmax函数得到词典里每个词的概率分布。层与层之间分别有两个权重矩阵W ∈ RV ×N和W′ ∈ RH×V。词典里的每个单词都会学习到两个向量vc和vw,分别代表上下文向量和目标词向量。因此,给予上下文c,出现目标词w的概率是:p(w|c),该模型需要学习的网络参数θ 。
词向量是用概率模型训练出来的产物,对训练语料库出现频次很低甚至不曾出现的词,词向量很难准确地表示。词向量是词级别的特征表示方式,单词内的形态和形状信息同样有用,研究者提出了基于字级别的表征方式,甚至更细粒度的基于Byte级别的表征方式。2017年,Mikolov等[9]提出用字级别的信息丰富词向量信息。此外,在机器翻译相关任务里,基于Byte级别的特征表示方式BPE还被用来学习不同语言之间的共享信息,主要以拉丁语系为主。2019年,Lample等[11]提出基于BERT优化的跨语言模型XLM,用BPE编码方式来提升不同语言之间共享的词汇量。
虽然通过词向量,一个单词能够很容易找到语义相似的单词,但单一词向量,不可避免一词多义问题。对于一词多义问题,最常用有效的方式便是基于预训练模型,结合上下文表示单词,代表模型有EMLo、GPT和BERT,都能有效地解决这个问题。
词,可以通过词向量进行表征,自然会有人思考分布式表示这个概念是否可以延伸到句子、文章、主题等。词袋模型Bag-of-Words忽略词序以及词语义,2014年Mikolov等[8]将分布式向量的表示扩展到句子和文章,模型训练类似word2vec。关于句子的向量表示,2015年Kiros等提出skip-thought,2018年Logeswaran等提出改进版quick-thought。
FastText
2016年,Mikolov等[7]提出一种简单轻量、用于文本分类的深度学习模型,架构跟Mikolov等[4]提出的word2vec的CBOW模型相似,但有所不同:各个词的embedding向量,补充字级别的n-gram特征向量,然后将这些向量求和平均,用基于霍夫曼树的分层softmax函数,输出对应的类别标签。FastText能够做到效果好、速度快,优化的点有两个:一是引入subword n-gram的概念解决词态变化的问题,利用字级别的n-gram信息捕获字符间的顺序关系,依次丰富单词内部更细微的语义;二是用基于霍夫曼树的分层softmax函数,将计算复杂度从O(kh)降低到O(h log2(k)),其中,k是类别个数,h是文本表示的维数。相比char-CNN之类的深度学习模型需要小时或天的训练时间,FastText只需要秒级的训练时间。
CNN-based Model
词向量通过低维分布式空间能够有效地表示词,使其成为NLP深度学习研究的基石。在词向量的基础上,需要有一种有效的特征提取器从词向量序列里提取出更高层次的特征,应用到NLP任务中去,譬如机器翻译、情感分析、问答、摘要,等。鉴于卷积神经网络CNN在机器视觉领域非常出色的特征提取能力,自然而然被研究者尝试用于自然语言处理领域。
回顾CNN应用于NLP领域的过去,好像一段民间皇子误入宫廷的斗争史。CNN用于句子建模最早可以追溯到2008年Collobert等[12]的研究,使用的是查找表映射词的表征方式,这可以看作是一种原始的词向量方法。2011年Collobert等[3]扩展了他的研究工作,提出一种基于CNN的通用框架用于各种NLP任务。Collobert[3]、Kalchbrenner[14]、Kim[13]等基于CNN的研究工作,推进了CNN应用在NLP研究的普及。
CNN擅长捕获局部特征,能够将信息量丰富的潜在语义特征用于下游任务,譬如TextCNN用于文本分类。但CNN却有长距离依赖问题,研究者尝试用动态卷积网络DCNN来改善这个不足。跟RNN的竞争过程中,CNN不停地优化自身能力,现在CNN的研究趋势是:加入GLU/GTU门机制来简化梯度传播,使用Dilated CNN增加覆盖长度,基于一维卷积层叠加深度并用Residual Connections辅助优化,优秀代表:增加网络深度的VDCNN和引进Gate机制的GCNN。
TextCNN
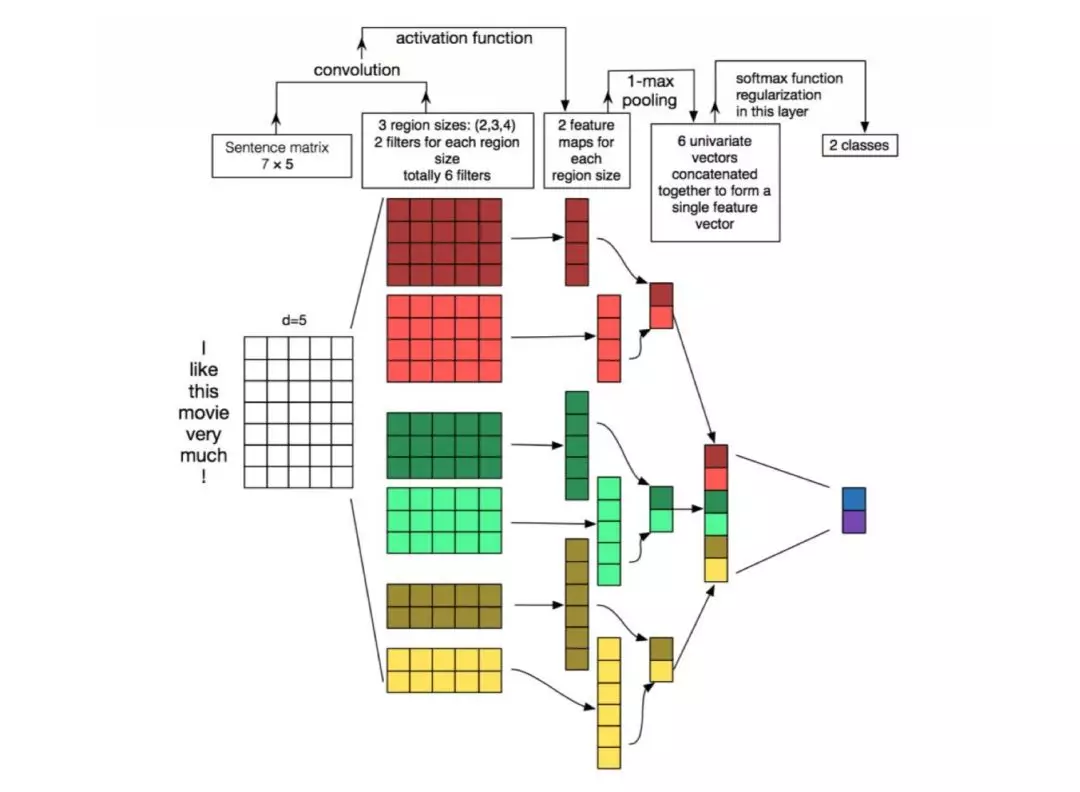
2014年,Kim[13]提出基于预训练Word2vec的TextCNN模型用于句子分类任务。CNN,通过卷积操作做特征检测,得到多个特征映射,然后通过池化操作对特征进行筛选,过滤噪音,提取关键信息,用来分类。
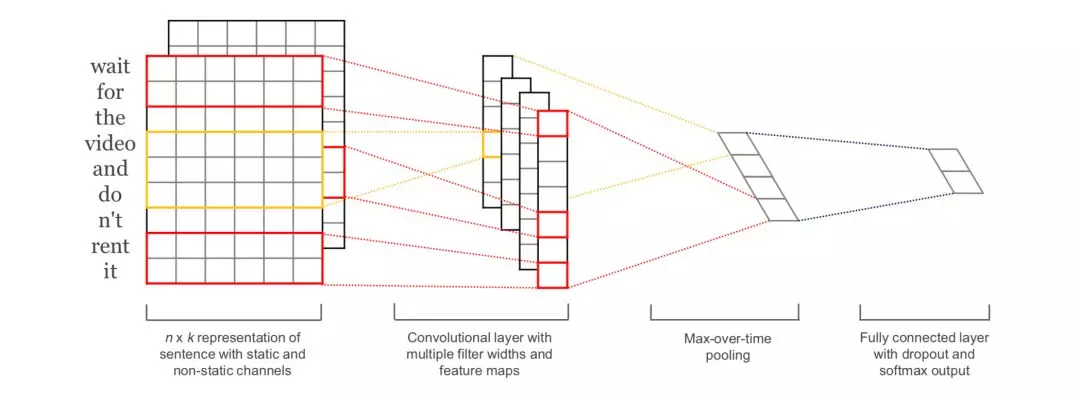
TextCNN的详细过程叙述如下:对输入长度为n、词向量维度为d的句子,有filter_size=(2, 3, 4)的一维卷积层,每个filter有2个channel,相当于分别提取两个2-gram、3-gram和4-gram特征。卷积操作ci = f(w · xi:i+h−1 + b),f是激活函数,ci表示卷积得到的特征,通过滑动窗口w,跟句子所有词进行卷积运算,得到特征映射c = [c1,c2,…,cn−h+1]。然后通过1-max pooling最大池化操作提取特征映射c中最大的值,不同的filter获得不同的n-gram特征。最后,通过softmax函数得到分类结果。这里的channel,可以是两个不同词向量,譬如Word2vec和Glove,也可以是Frozen和Fine-tuning两种不同处理预训练词向量的方式。CNN天生不是用于提取语言语法语义信息,channel采用不同特征表示方式,就像鸡蛋放多个篮子一样,期待收益最大化。
DCNN
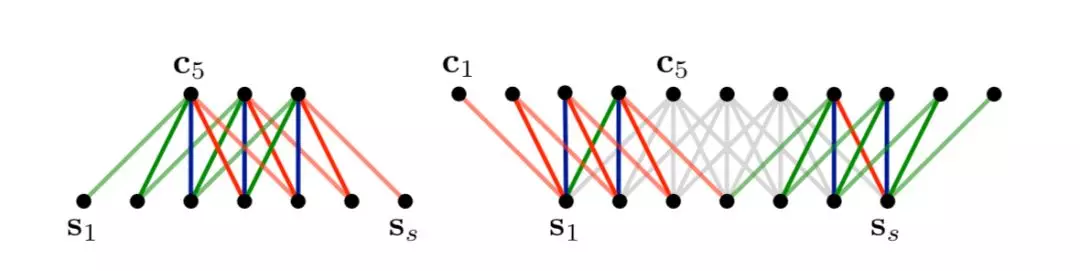
2014年,Kalchbrenner等[14]提出一种用于句子语义建模的动态卷积网络DCNN,采用动态挑选K个最大特征的池化策略。这种策略保留了特征的顺序但不包括具体位置,支持模型以较小的卷积层覆盖较广的范围,有利于累计句子中的关键信息。
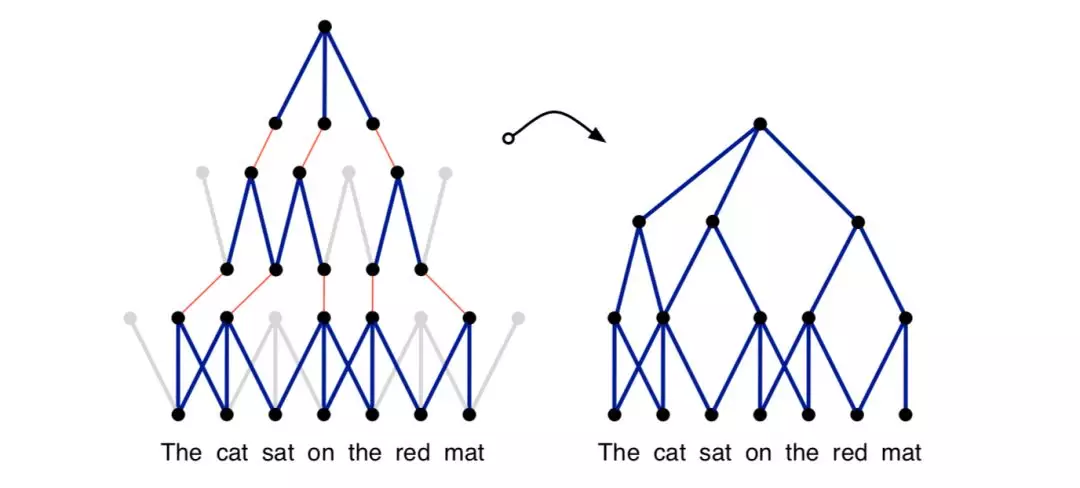
这个模型除了K最大池化,还有两个关键的知识点:宽卷积Wide Convolution和折叠Folding。宽卷积,指对句子左右进行补零再卷积操作,得到比原来更长的特征映射表,句子中的词与词更多可能地组合。折叠,在最后的K-Max Pooling之前,对特征每两行综合叠加,降低特征维数。这个结构不需要语法分析树,便能基于句子生成特征图,捕捉短的和长的语义关系。
GCNN
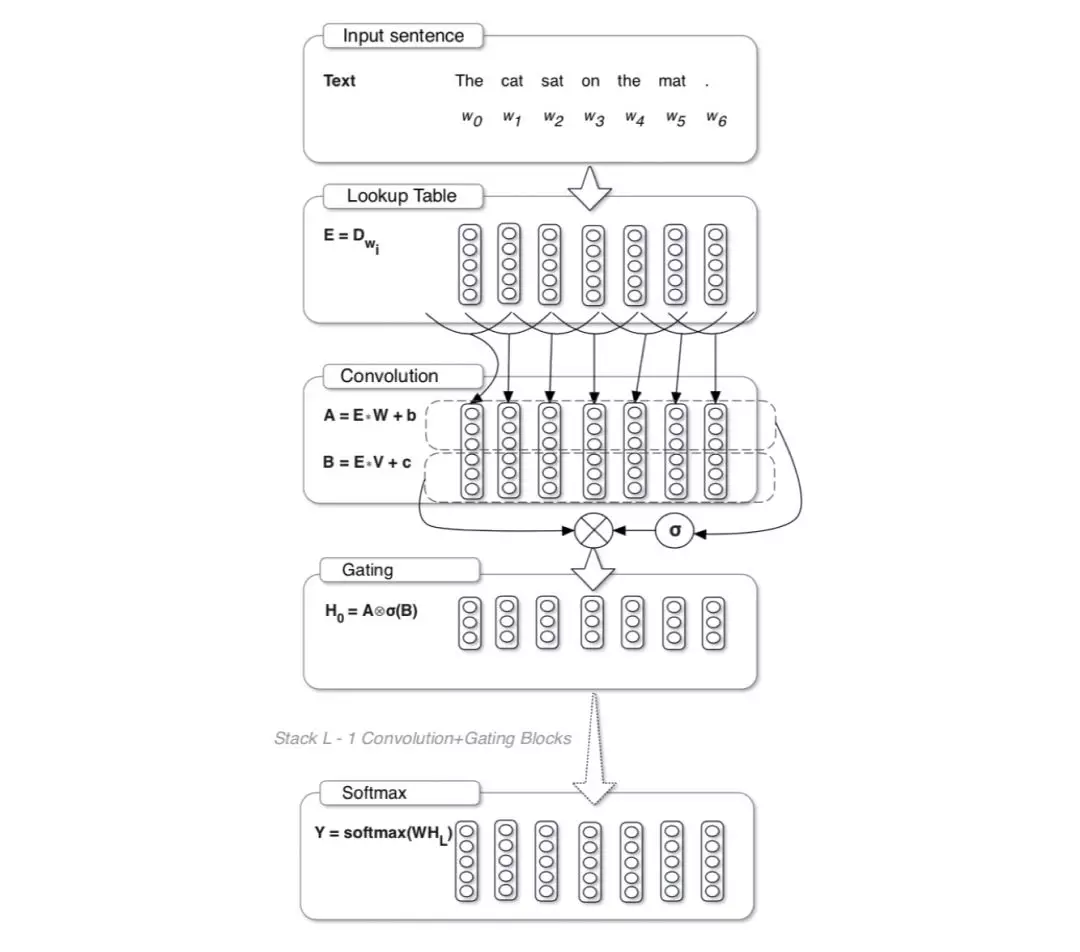
2017年,Dauphin等[15]将Gate机制引进CNN。在此之前,语言模型主要方式还是基于RNN,特别是LSTM在NLP领域广泛应用。GCNN引进一种Gate机制简化梯度传播,执行效果和效率比当时的LSTM好。GCNN的流程:输入句子经过查找表获取相应的词向量,基于输入的词向量或上一层卷积输出结果,进行卷积运算和门运算hl(X)=(X∗W+b)⊗σ(X∗V+c),输出结果采用Adaptive Softmax加速预测。
VDCNN
2017年,Conneau等[16]提出了加大网络深度的VDCNN用于文本分类任务。VDCNN架构由29个卷积层组成,包括8个卷积层Block、3个最大池化层、1个K-Max Pooling、3个全连接层。其中,卷积层的通道数分别是64、64、128、128、256、256、512、512;前3个池化层的步长设置为2,最后1个K-Max池化层的k设置为8;卷积核大小为conv3。
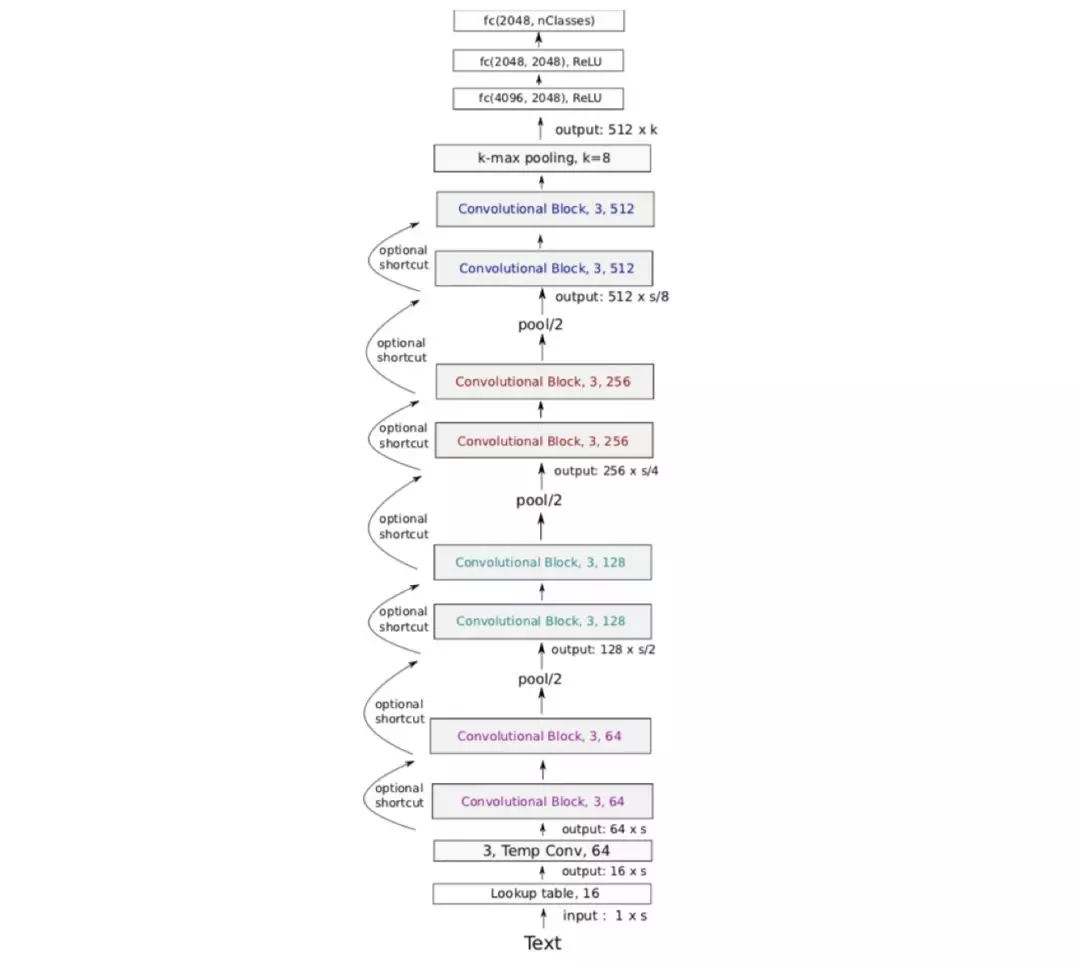
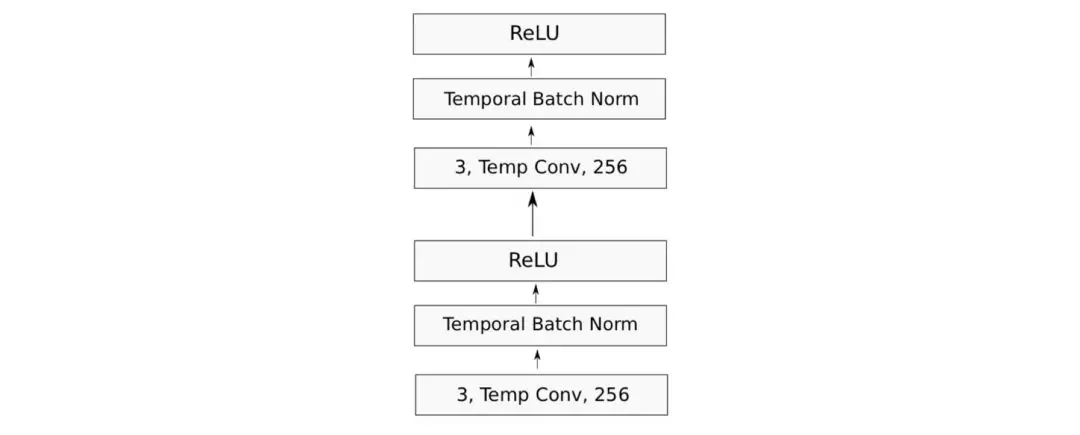
每个卷积层Block包括两个卷积层序列,每个卷积层都会连接1个Temporal BatchNorn层和1个ReLU激活函数。
RNN-based Model
CNN本质上通过卷积运算和池化操作提取关键信息,擅长捕获局部特征,而RNN则擅长处理时序信息和长距离依赖,两者各有专长,没有完胜的强者,只有什么场景更适合谁。RNN更符合人类语言的特性,人的思考基于先知,理解文章中的每一个词都是基于前面已经读过的词。所以,RNN被用到更多NLP任务场景,研究者基于RNN结合各种机制来满足不同NLP任务场景的需求。
RNN模型可以用来做什么呢?语言模型和文本生成,对一个文本序列,基于前面的单词预测下一个词的概率,同样,基于输出概率分布进行采样,用于生成文本;机器翻译,跟语言模型相似,基于源语言的词序列,输出目标语言的词序列,不同的是输出前需要提前看到完整的输入信息;语音识别,输入声音信号,基于概率预测语音片段序列;图像描述生成,结合CNN提取特征,作为模型的一部分用来生成未标注图像的描述信息。
RNN成长的过程中,有哪些有意思的模型呢?RNN有梯度消失的问题,LSTM/GRU采用Gate机制有效解决了这个问题。RNN是单向的基于上文或下文进行分析的模型,在很多NLP任务场景,基于上下文的双层双向语言模型相比更有优势,能够更好地捕获变长且双向的n-gram信息,优秀代表Bi-LSTM,前沿的上下文预训练模型CoVe、ELMo、CVT等便是基于Bi-LSTM。RNN的模型特性使其很适合Seq2Seq场景,基于RNN/LSTM的Encoder-Decoder框架常用于机器翻译等任务。此外,还有尝试结合CNN和RNN的RCNN、基于RNN的文本生成模型VAE、结合LSTM和树形结构的解析框架Tree-base LSTM,这里就不作详细介绍。
RNN
早在1990年,Elman[17]就提出使用时序信息的思想。RNN之所以被命名Recurrent这个词,是因为模型对句子每个元素都执行相同操作:当前时刻的计算依赖上一时刻计算的结果。换句话说,RNN模型是具有“记忆”能力的,它能捕获之前已经被计算过的信息,用于当前的计算。
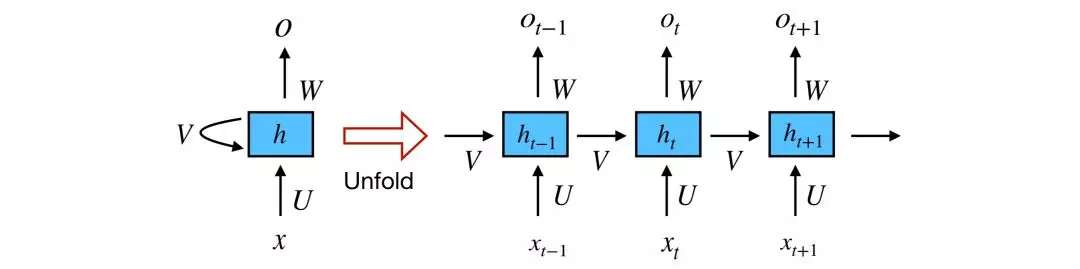
下图展示的是沿时间轴展开整个序列的通用RNN网络架构,详细计算流程:xt是t时刻的输入;st是t时刻的隐含层状态,计算公式是st =f(Uxt +Wst−1),st的计算依赖上一时刻的隐含层状态和当前时刻的输入,函数f是非线性的tanh或ReLU;ot是t时刻的输出。
LSTM
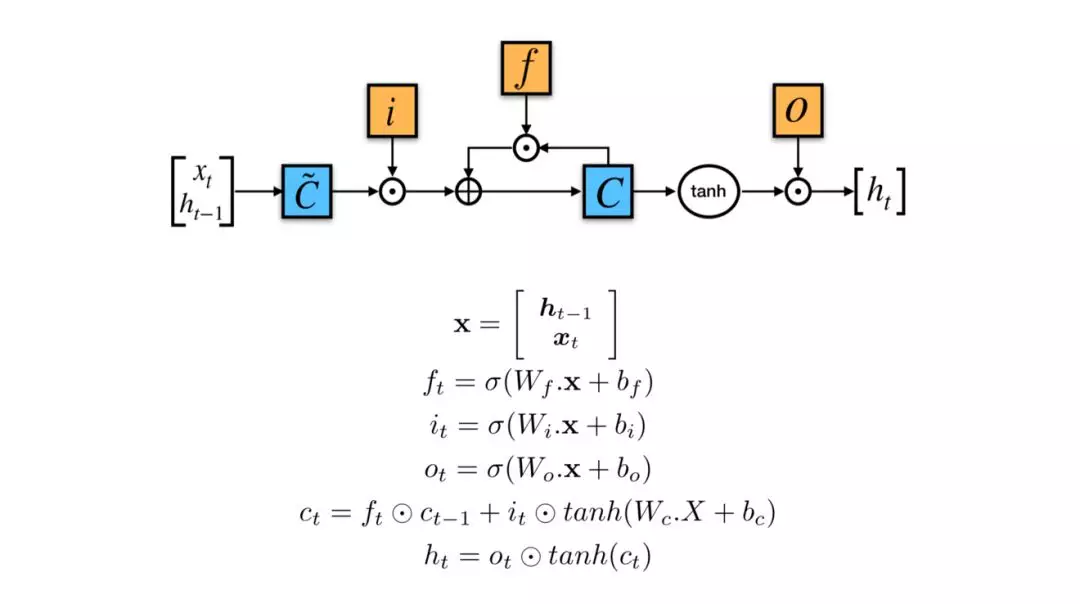
理论上,这种架构支持RNN捕获无限长的上下文信息用于当前计算,但是,这些信息都是需要的吗?不一定,看情况而定。譬如,预测句子“the clouds are in the sky”的最后一个词sky,我们不需要额外的上下文信息就能预测,而预测句子“I grew up in France … I speak fluent French”的最后一个词French,则需要前面France信息的参考。这便是原生RNN的长距离依赖问题。此外,在实际模型训练过程中发现,RNN还有严重的梯度消失和梯度膨胀问题。LSTM和GRU加入门机制解决该问题。LSTM主要包括3个门:输入门、遗忘门和输出门,GRU主要包括2个门:重置门和更新门。
以LSTM为例。x包括t时刻的输入和上一时刻的隐含层状态;ft通过sigmoid层决定上一个单元状态ct−1是否被遗忘;it决定t时刻哪些数据被更新,tanh(Wc.X +bc)是待更新的候选数据;ot决定t时刻的输出。换句话说,门机制就是让LSTM学会上下文语境下哪些信息该丢弃,哪些需要继续传递下去。LSTM和GRU相互之间没有明显优势,但在很多NLP任务表现都比原生RNN好,具体选择LSTM还是GRU,取决于其他因素,譬如计算资源等。
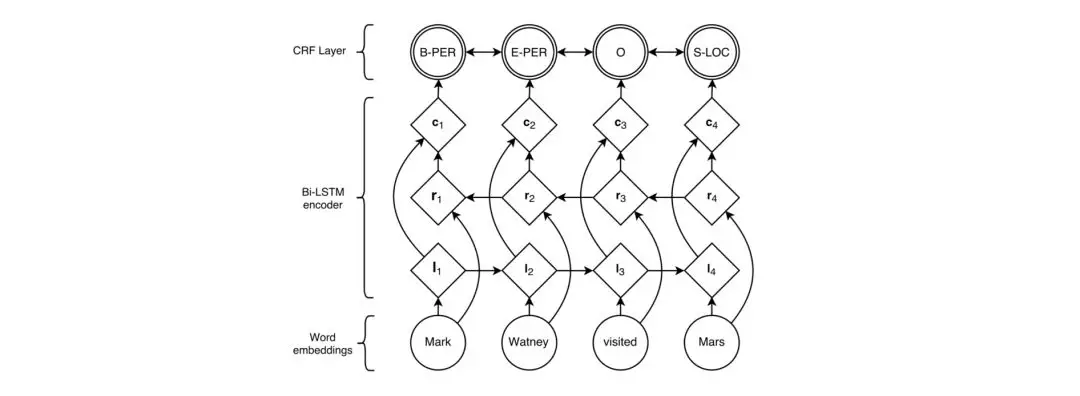
Bi-LSTM
Bi-LSTM是RNN的一种扩展。2016年,Lample等[19]采用Bi-LSTM做命名实体识别NER。模型采用双层双向LSTM做编码器,能够捕获任意目标词的无限长上下文信息。li代表目标词i的上文,ri代表目标词i的下文,ci负责把两层信息向量综合起来作为目标词i的上下文,最后送入CRF层。其中,CRF是常用于NER等序列标注任务的概率图模型。
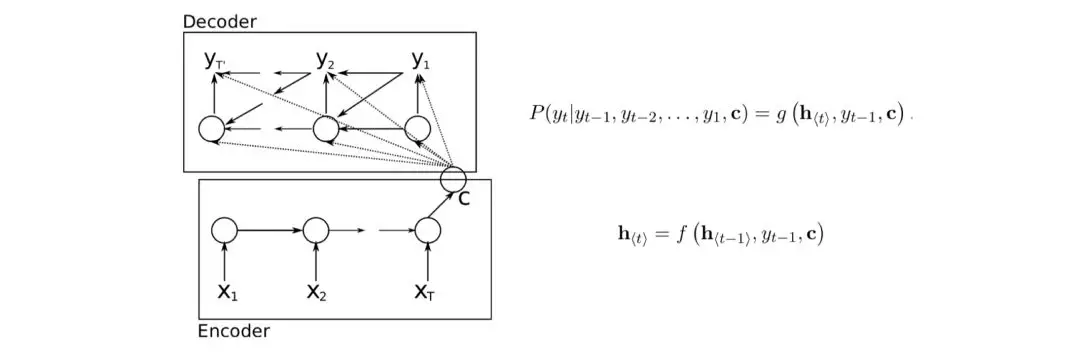
Seq2Seq
Seq2Seq,即Sequence to Sequence,通用的Encoder-Decoder框架,常用于机器翻译、文本摘要、聊天机器人、阅读理解、语音识别、图像描述生成、图像问答等场景。最早是2014年Bengio等[22]和Bowman等[21]分别提出基于RNN/LSTM的Seq2Seq模型用于机器翻译。
Bengio等[22]提出一个新的神经网络模型:RNN Encoder-Decoder,包括2个RNN分别负责Encoder和Decoder。具体流程:对输入序列x,RNN编码器依次读取每个xt并更新隐含层状态,当读完序列的结束符号EOS,得到最后的隐含层状态c,代表整个输入序列;另一个RNN解码器负责生成输出序列,基于隐含层状态h⟨t⟩预测下一个输出yt,其中,t时刻的隐含层状态h⟨t⟩和输出yt都依赖上一时刻的输出yt−1和以及输入序列的c,t时刻解码器隐含层状态计算公式h⟨t⟩ ,输出的概率分布P(yt|yt−1,yt−2,…,y1,c) 。
Bowman等[21]提出的也是这种框架,只不过用是的多层LSTM。模型用多层LSTM将输入序列映射成一个固定维数的向量,另外一个深层LSTM负责从这个向量解码出目标序列。

Attention-based Model
不同于CNN、RNN,注意力机制是一种让模型重点关注重要关键信息并将其特征提取用于学习分析的策略。最早将注意力机制引进NLP领域的是机器翻译等基于Encoder-Decoder框架的场景。传统的Encoder-Decoder框架有个问题:一些跟当前任务无关的信息都会被编码器强制编码进去,尤其输入很长或信息量很大时这个问题特别明显,进行选择性编码不是框架所能做到的。所以,注意力机制刚好能解决这个痛点。
如何理解注意力机制?类比人类世界,当我们看到一个人走过来,为了识别这个人的身份,眼睛注意力会关注在脸上,除了脸之后的其他区域信息会被暂时无视或不怎么重视。对于语言模型,为了模型能够更加准确地判断,需要对输入的文本提取出关键且重要的信息。怎么做?对输入文本的每个单词赋予不同的权重,携带关键重要信息的单词偏向性地赋予更高的权重。抽象来说,即是:对于输入Input,有相应的query向量和key-value向量集合,通过计算query和key关系的function,赋予每个value不同的权重,最终得到一个正确的向量输出Output。
注意力机制最早是为了解决Seq2Seq问题的,后来研究者尝试将其应用到情感分析、句对关系判别等其他任务场景,譬如关注aspect的情感分析模型ATAE LSTM、分析句对关系的ABCNN。
AT Seq2Seq
最早将注意力机制用于机器翻译模型NMT的是Bengio等[24],NMT是一个典型的Seq2Seq模型。跟原来的模型相似,i时刻的输出yi和隐含层状态si依赖上一时刻的输出yi−1和输入序列的上下文信息向量c。不同的是,上下文信息向量c的计算是基于输入序列相应隐含层状态的加权计算结果,而这个权值是由目标输入跟输入序列的相关性计算得来。模型使用一个双向双层RNN编码器计算输入序列x的隐含层状态h,解码器在解码翻译过程会对输入序列进行仿真搜索,第i时刻会依次计算目标输出si−1跟输入序列隐含层状态h的相关性,eij代表目标输出si−1跟第j个值hj的相关性,权重αij用来更新第i时刻的上下文信息向量ci。
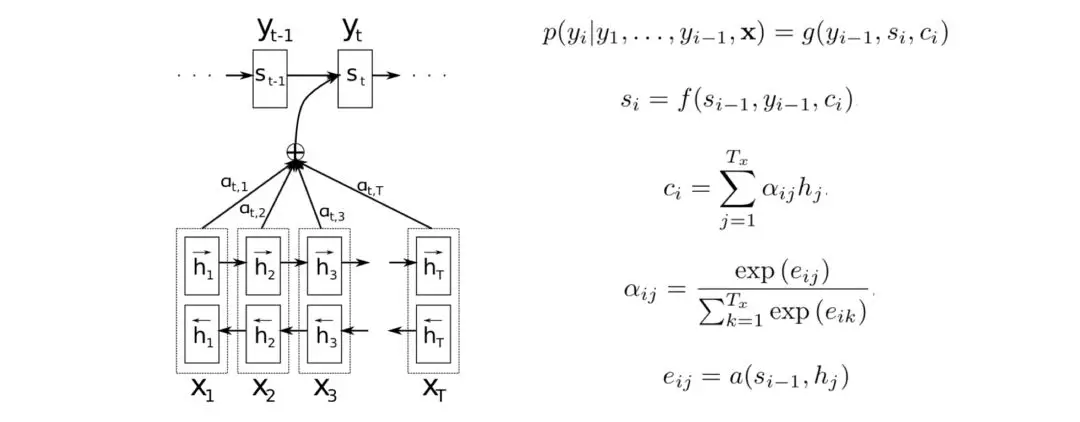
2015年,Luong等[25]针对Seq2Seq模型提出应用注意力机制的优化方案,主要包括Global Attention和Local Attention两种机制。这两种注意力机制跟Bengio等[24]的思路是相似的,不同的是Global机制对输入序列的所有词进行分析并提出几种不同扩展方式,Local机制考虑的是节省应用注意力机制的计算资源消耗。对于Global机制的几种扩展方式,作者的实验结果是general方式最好。
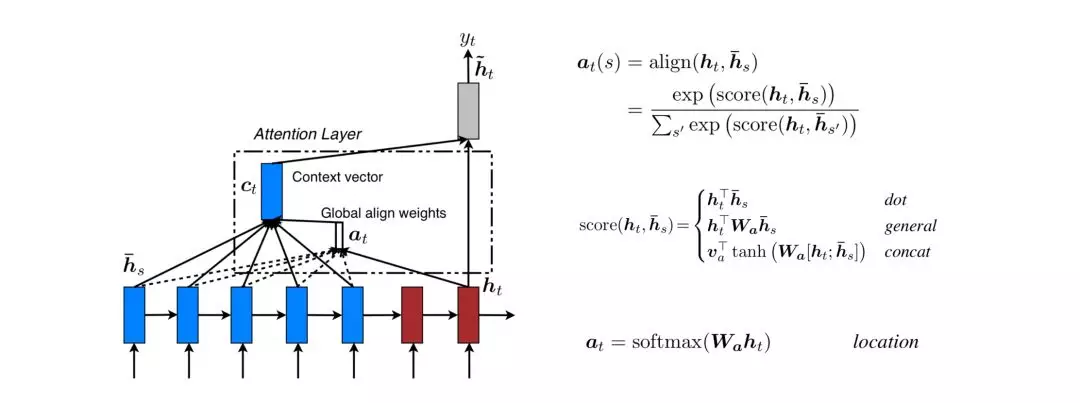
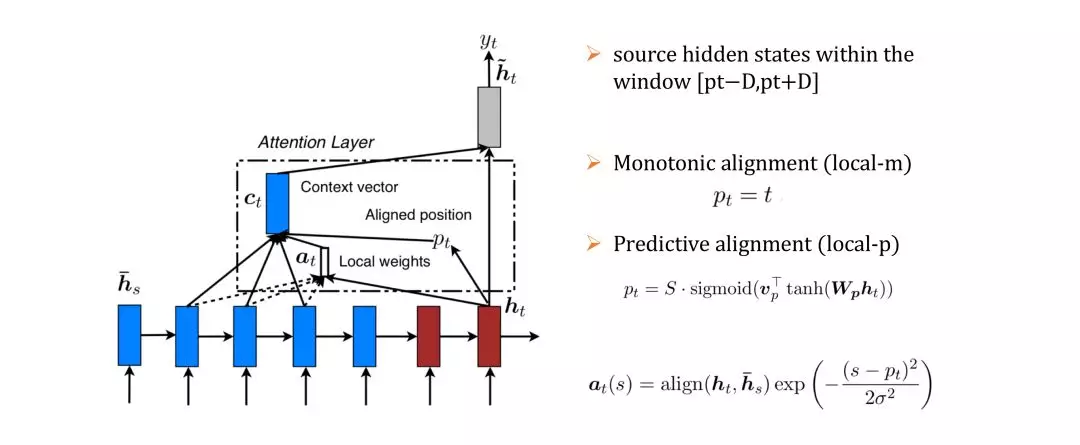
Global机制的弊端就是目标输出需要跟输入的所有词都计算,这种成本是很昂贵的,特别是段落、文章等长序列,要将其翻译是不太实际的。Local机制采用的优化方案是增加一个2D+1长度的窗口,确定窗口命中位置pt,目标输出只需要跟窗口内的输入序列计算即可。位置pt的确定方式有两种:local-m和local-p,local-m是直接根据时刻t简单指定,local-p是根据t时刻的隐含层状态ht预测输入序列S的位置。最后,权值at(s)的计算在原来的align函数上增加一个高斯分布。
ATAE-LSTM
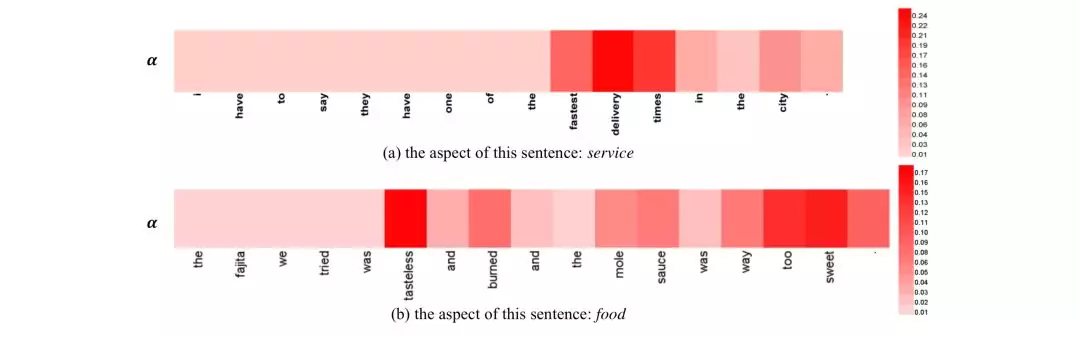
Aspect级别的情感分类分析的是句子关于某个aspect的情感倾向,相比文档级别分析粒度更细。2016年,Wang等[26]提出基于注意力机制的LSTM模型,用于aspect级别的情感分类。当分析不同aspect的情感倾向时,模型能够关注到句子的不同部分。下图是注意力机制的效果可视化。模型不仅能够抓到跟aspect相关的重要词,哪怕是多义词,还有能注意到句子不同位置的重要信息。
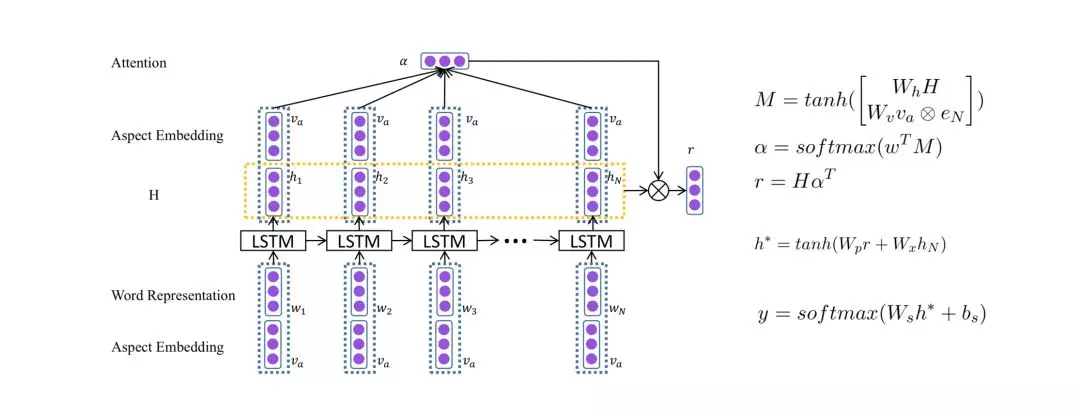
模型不同于Seq2Seq,只有一个编码器LSTM。输入层和隐含层都加了aspect的向量??,?是注意力权重,r是基于aspect的句子表示,h?是隐含层状态的最后输出,h*是最后句子的表示,模型最后经过softmax得到情感类别的概率分布。
ABCNN
Yin等[28]探索了注意力机制在CNN模型的应用,提出了ABCNN模型,用于句对关系判别,包括答案选择AS、释义识别PI、文本蕴含TE。作者在论文中分析了三种不同的应用注意力机制的方法。
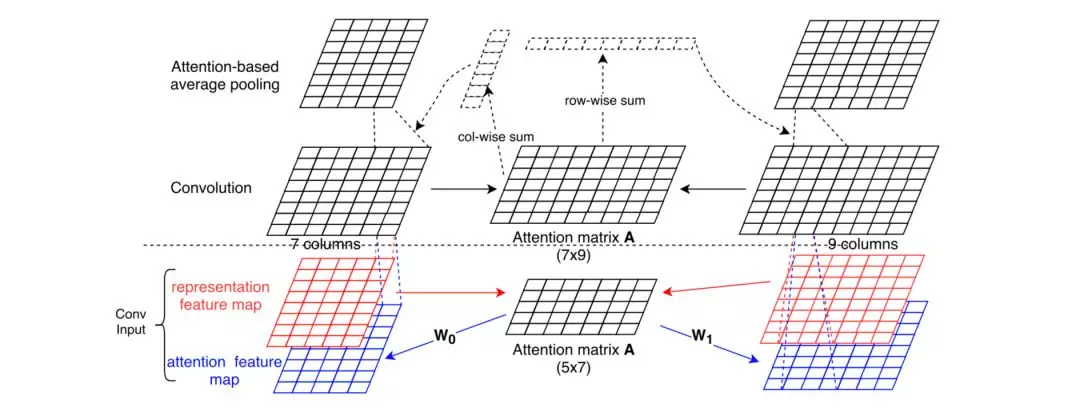
第一种ABCNN-1,在卷积前计算出s0和s1的注意力矩阵A,s0和s1的特征映射表跟矩阵A进行计算得到注意力特征映射表,特征映射表和注意力特征映射表一起输入卷基层。
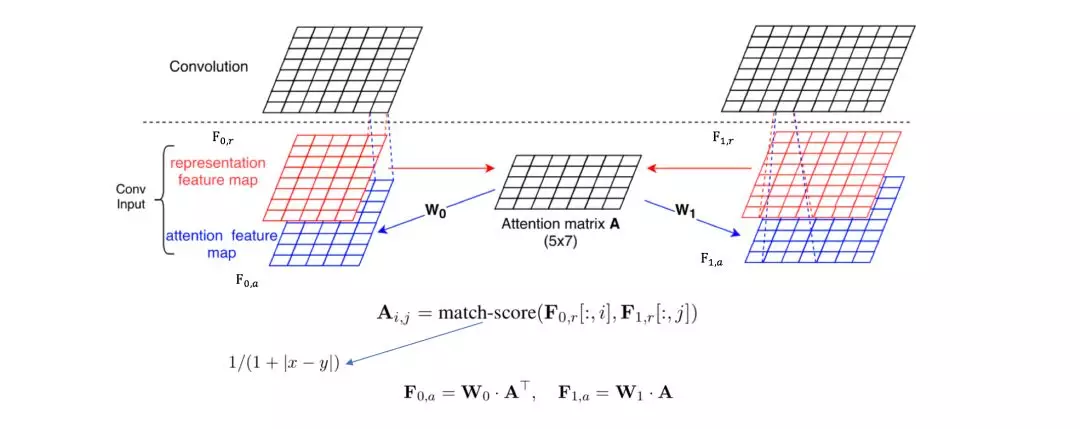
第二种ABCNN-2,在s0和s1卷积后计算两者的注意力矩阵A,通过A进行计算再池化。
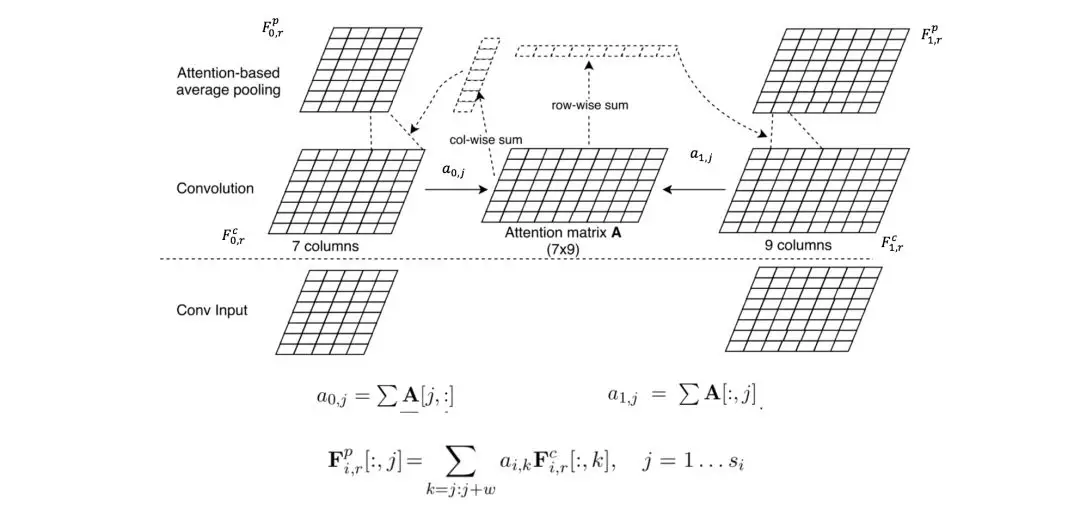
第三种ABCNN-3,将前面两种结合起来,卷积前和池化前都进行注意力计算。
Transformer-based Model
在Seq2Seq场景,注意力机制的引入,显著提升了模型的能力。但基于RNN的Seq2Seq框架有个很大的不足就是编码阶段必须按序列依次处理。为了提升并行计算,研究者提出了基于CNN的ConvS2S[28]和ByteNet[29]。在这些模型里,输入或输出任意两个位置之间的关联运算量跟位置有关,ConvS2S是线性,ByteNet是对数性,这对长距离学习很困难。因此,Google提出了Transformer[30],完全抛弃了CNN和RNN,只基于注意力机制捕捉输入和输出的全局关系,框架更容易并行计算,在诸如机器翻译和解析等任务训练时间减少,效果提升。Transformer的能力有目共睹,被应用到GPT、BERT、XLM等预训练模型,刷新各种NLP任务的SOTA。
Transformer
Transformer由Encoder和Decoder组成。Encoder是由N个完全一样的网络层组成,每个网络层都包含一个多头自注意力子层和全连接前向神经网络子层。Decoder相比Encoder多了一个多头自注意力子层。为了更好地优化深度网络,每个子层都加了残差连接并归一化处理。
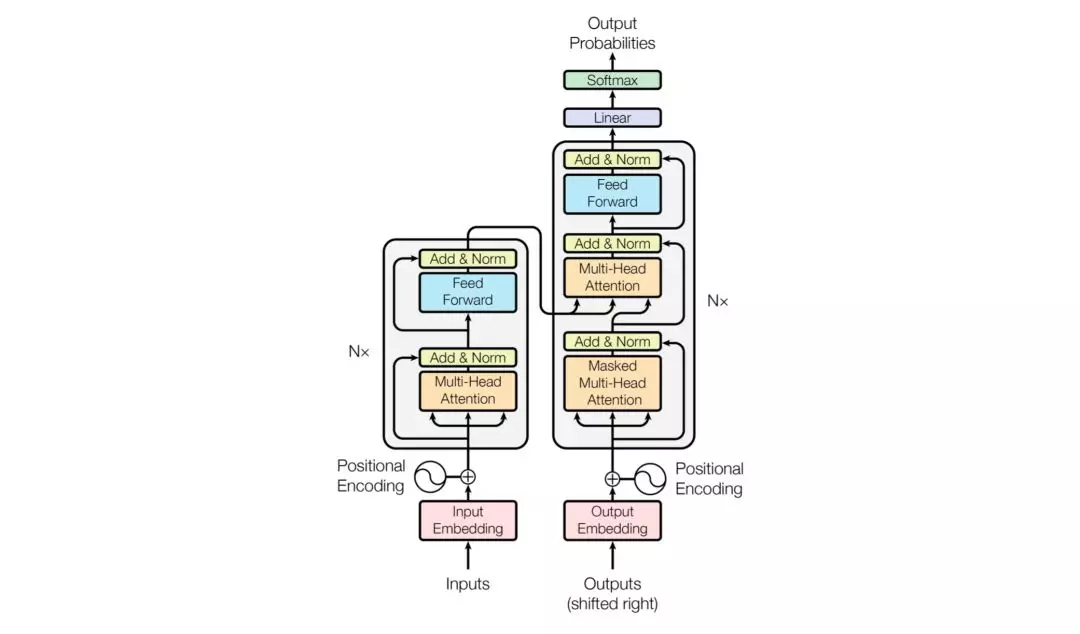
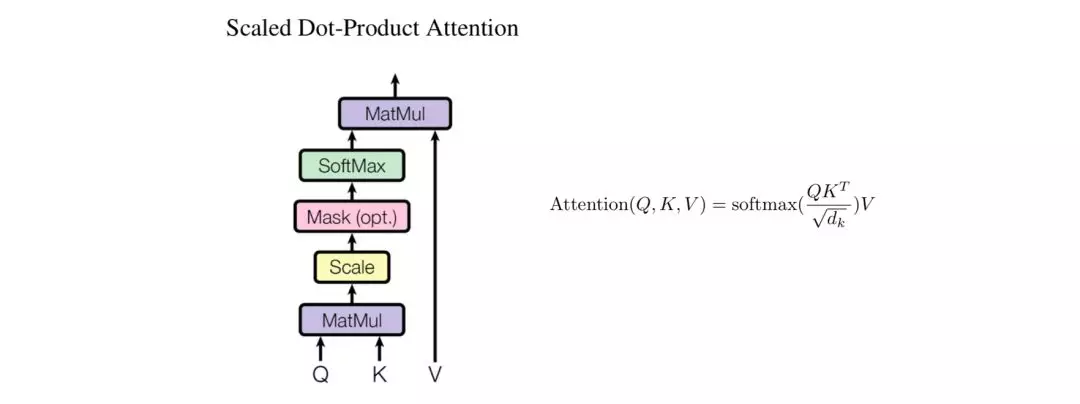
论文提到了两个注意力机制:Scaled Dot-Product Attention和Multi-Head Attention。
Scaled Dot-Product Attention。Self-Attention机制是在该单元实现的。对于输入Input,通过线性变换得到Q、K、V,然后将Q和K通过Dot-Product相乘计算,得到输入Input中词与词之间的依赖关系,再通过尺度变换Scale、掩码Mask和Softmax操作,得到Self-Attention矩阵,最后跟V进行点乘计算。
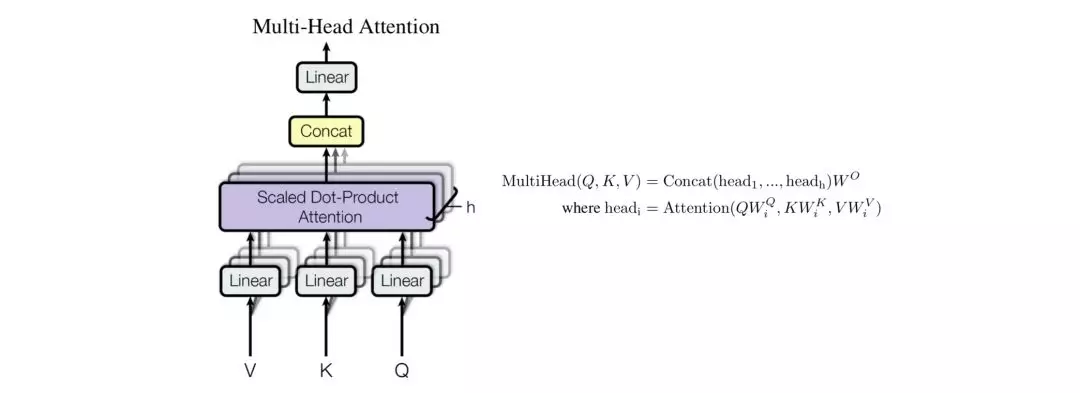
Multi-Head Attention。通过h个不同线性变换,将d_model维的Q、K、V分别映射成d_k、d_k、d_v维,并行应用Self-Attention机制,得到h个d_v维的输出,进行拼接计算Concat、线性变换Linear操作。
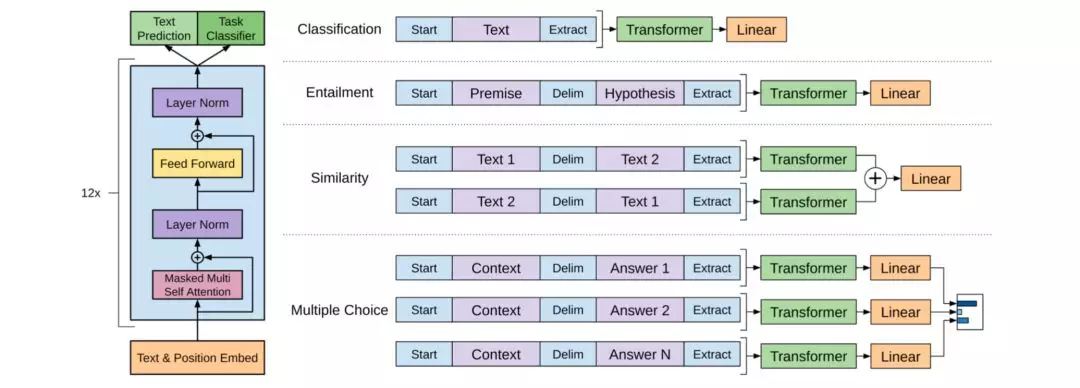
GPT
2018年,Radford等[31]在OpenAI发表基于生成式预训练的单向神经网络语言模型GPT,成为当年最火的预训练模型之一。采用的是Fine-tuning方式,分成两个阶段:第一阶段采用Transformer解码器部分,基于无标注语料进行生成式预训练;第二阶段基于特定任务进行有区别地Fine-tuning训练,譬如文本分类、句对关系判别、文本相似性、多选任务。
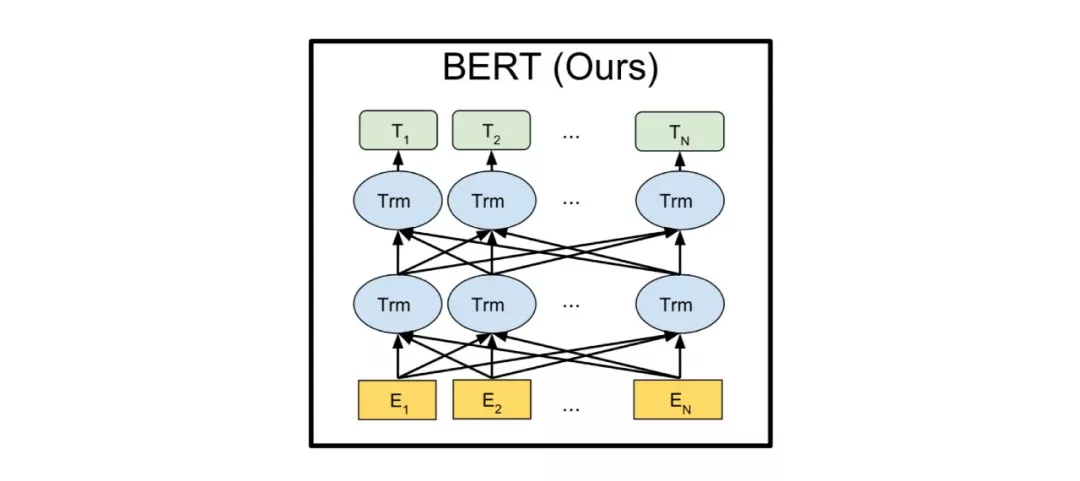
BERT
2018年,Devlin等[32]提出基于深度双向Transformer的预训练模型BERT,与GPT不同的是,BERT采用的特征提取器是Transformer编码器部分。同样,BERT也分成预训练和下游任务微调两个阶段。
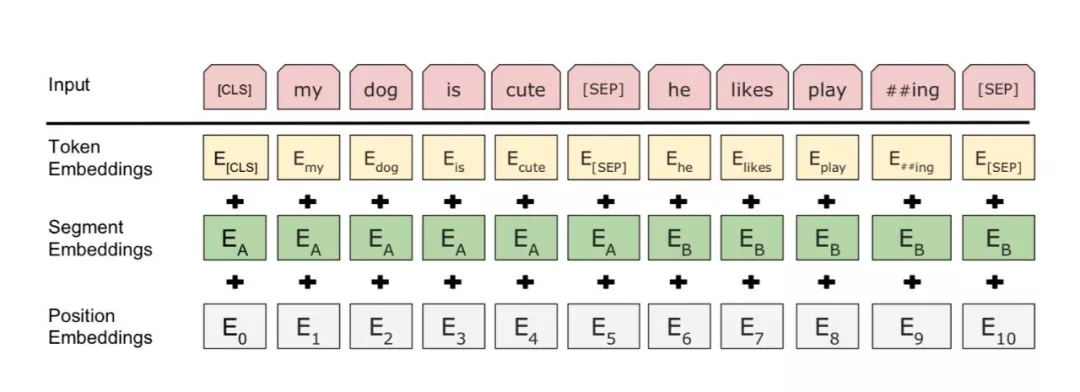
BERT的输入是一个线性序列,支持单句文本和句对文本,句首用符号[CLS]表示,句尾用符号[SEP]表示,如果是句对,句子之间添加符号[SEP]。输入特征,由Token向量、Segment向量和Position向量三个共同组成,分别代表单词信息、句子信息、位置信息。
BERT采用了MLM和NSP两种策略用于模型预训练。
MLM,Masked LM。对输入的单词序列,随机地掩盖15%的单词,然后对掩盖的单词做预测任务。相比传统标准条件语言模型只能left-to-right或right-to-left单向预测目标函数,MLM可以从任意方向预测被掩盖的单词。不过这种做法会带来两个缺点:1.预训练阶段随机用符号[MASK]替换掩盖的单词,而下游任务微调阶段并没有Mask操作,会造成预训练跟微调阶段的不匹配;2.预训练阶段只对15%被掩盖的单词进行预测,而不是整个句子,模型收敛需要花更多时间。对于第二点,作者们觉得效果提升明显还是值得;而对于第一点,为了缓和,15%随机掩盖的单词并不是都用符号[MASK]替换,掩盖单词操作进行了以下改进,同时举例:“my dog is hairy”挑中单词“hairy”。

NSP,Next Sentence Prediction。许多重要的下游任务譬如QA、NLI需要语言模型理解两个句子之间的关系,而传统的语言模型在训练的过程没有考虑句对关系的学习。NSP,预测下一句模型,增加对句子A和B关系的预测任务,50%的时间里B是A的下一句,分类标签为IsNext,另外50%的时间里B是随机挑选的句子,并不是A的下一句,分类标签为NotNext。

XLM
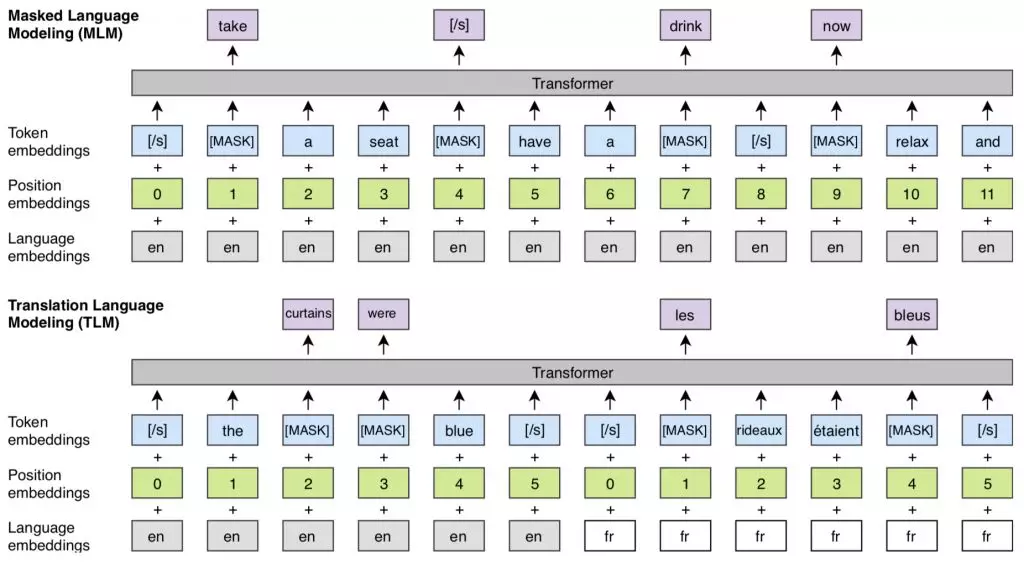
2019年,Lample等[33]在Facebook AI提出基于BERT优化的跨语言模型XLM。XLM的优秀,不仅在于它基于BERT优化后在句对关系判别和机器翻译任务上的表现,作者处理低资源语言问题的做法给了我们很多思路,而低资源语言问题是目前NLP四大开放性问题之一。相比BERT,XLM做了几点优化。首先,替换原来用单词或字符作为模型输入的方式,XLM模型采用一种Byte-Pair Encoding(BPE)编码方式,将文本输入切分成所有语言最通用的子单词,从而提升不同语言之间共享的词汇量。其次,基于BERT架构,并做了两点升级:XLM模型的每个训练样本由两段内容一样但语言不通的文本组成,而BERT模型的训练样本都是单一语言,BERT的目标是预测被掩盖单词,而XLM模型不仅仅如此,基于新架构,能够利用一个语言的上下文去预测另一种语言的Token,此外,每一种语言都会被随机掩盖单词;XLM模型还会分别输入语言ID以及每一种语言的Token位置信息,这些新的元数据能够帮助模型更好地学习不同语言相关联Token之间的关系信息。
完整的XLM模型是通过MLM和TLM两种策略进行训练和交互。
应用
\\\__
想起一句格言“All models are wrong, but some are useful.”发展到现在,NLP更迭了很多模型,有的甚至淡出了人们视野,但是,没有无用的模型,只有适合它的地方,即便是规则方法,在现在很多NLP应用中依然发挥着作用。在这里,笔者尝试总结NLP不同任务场景一些有意思的模型,经验有限,如有不全或不当地方,请予指正。
除了OCR、语音识别,自然语言处理有四大类常见的任务。第一类任务:序列标注,譬如命名实体识别、语义标注、词性标注、分词等;第二类任务:分类任务,譬如文本分类、情感分析等;第三类任务:句对关系判断,譬如自然语言推理、问答QA、文本语义相似性等;第四类任务:生成式任务,譬如机器翻译、文本摘要、写诗造句、图像描述生成等。
向量表示
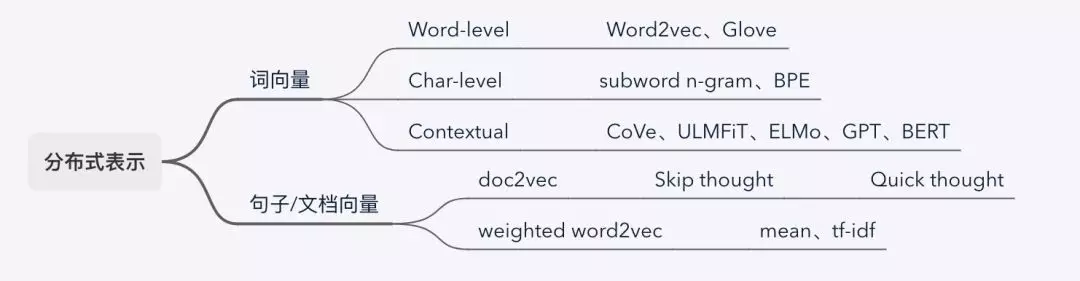
词、句子、文章的向量表示,包括基于上下文的方法。词的向量表示,看任务对词粒度的要求,一般场景用预训练好的词向量Word2vec和Glove,或者通过one-shot编码再加一个Embedding层的方式。在序列标注、机器翻译等场景,对词内特征要求比较高,可以采用字级别的,常用的有subword n-gram和BPE,也有结合词级别向量的做法。迁移学习带来的模型效果提升有目共睹,EMLo、GPT、BERT等预训练模型,将上下文考虑进来,在具体下游任务微调适配,更恰当的表示词的语义信息,特别是一词多义场景。句子和文档等序列的向量表示,大概分两类:一种是用TextRank的方式提取序列的主要关键词,基于关键词的词向量并赋予权重的方式表示序列,权重分配可以是平均也可以用tf-idf之类的算法;一种是将序列进行embedding,方法有很多种,譬如doc2vec、skip-thought、quick-thought、BERT等。
文本相似性
大家应该很熟悉谷歌提出的simhash算法,用来文本去重。深度学习用来处理文本语义相似性任务,简单可以分成两类:一种是用预训练好的词向量Word2vec或Glove来表示句子,计算向量之间的距离来区分相似性;一种是用预训练模型来表示句子,譬如2018年谷歌[37]提出通用句子编码器来获取句子向量,然后用arccos来计算相似距离,作者在论文中介绍了两种编码器:DAN和Tansformer。

文本分类
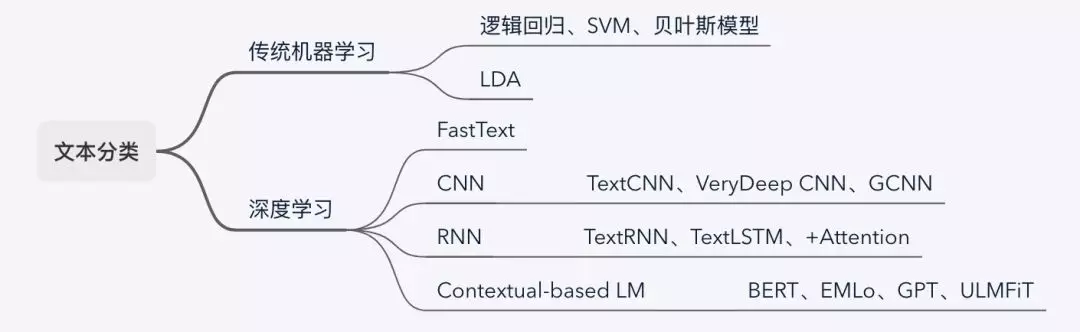
文本分类,NLP工业化应用最广泛的任务之一,譬如辨别垃圾信息或恶意评论、对文章进行政治倾向分类、对商品积极和消极的评论进行分类,等等。文本分类的方法有很多种,传统机器学习的逻辑回归、SVM、贝叶斯分类模型、主题模型,深度学习的FastText、基于CNN/RNN的分类模型,以及最近很火的基于预训练模型的BERT、ELMo、GPT、ULMFiT。如果是语料语义简单的分类任务,用传统机器学习方法即可,抑或FastText也是个不错的选择,成本低,如果是像社交数据之类语义丰富的场景,可以考虑深度学习模型,CNN擅长捕获局部特征,RNN擅长处理时序信息,预训练模型的优点就不用多说,注意力机制在模型效果不满足时可以考虑一试。
情感分析
情感分析,又叫观点挖掘,该任务目的是从文本中研究人们对实体以及其属性所表达的观点、情绪、情感、评价和态度。这些实体可以是各种产品、机构、服务、个人、事件、问题或主题等。这一领域涉及的问题十分多样,包括很多研究任务,譬如情感分析、观点挖掘、观点信息提取、情感挖掘、主观性分析、倾向性分析、情绪分析以及评论挖掘等。基于所处理文本的颗粒度,情感分析研究可以分成三个级别:篇章级、句子级和属性级。研究情感分析的方法有很多种,情感词典匹配规则、传统机器学习、深度学习,等。

机器翻译
机器翻译,非常具有挑战性的NLP任务之一。从基于短语匹配概率的SMT框架,到基于CNN/RNN/Transformer的NMT框架,注意力机制在提升模型效果发挥重要的作用。机器翻译任务里,低资源语言的翻译问题是个大难点,跨语言模型XLM在这块进行了探索,利用富资源语言来学习低资源语言。

命名实体识别
命名实体识别(英语:Named Entity Recognition,简称NER)是NLP序列标注任务的一种,指从输入文本中识别出有特定意义或指代性强的实体,是机器翻译、知识图谱、关系抽取、问答系统等的基础。学术上NER的命名实体分3大类和7小类,3大类指实体类、时间类、数字类,7小类指人名、地名、组织机构名、时间、日期、货币、百分比。语言具有语法,语料遵循一定的语法结构,所以CRF、HMM和MEMM等概率图模型被用来分析标签转移概率,包括深度学习模型一般会加上CRF层来负责句子级别的标签预测。深度学习模型一般用ID-CNN和Bi-LSTM再加一个CRF层,迁移学习火起来后,CVT、ELMo和BERT在NER任务上的表现也是非常不错。

未来
\\\__
在由Deepmind主办的Deep Learning Indaba 2018深度学习峰会上,20多位NLP研究者探讨了NLP领域的四个主要开放性问题:自然语言理解,很难,现在很多模型和机制只是在提升系统模式匹配的能力;低资源场景的NLP,除了语言,在生活中还有很多场景碰到这种问题,譬如如何在缺乏用户评论的前提下评价一家新开的餐厅;大型文本或多个文本的推理;数据集、问题和评估。

在接下来一两年,NLP领域的研究和应用,可能会有这样的趋势或借鉴的地方:
1. 预训练+微调两阶段模型;
2. 基于Transformer的特征提取
3. 基于BERT优化、在不同任务场景的应用探索
4. 新语言模型的探索,Transformer给了我们很多思路
新模型在应用落地会经历成本和收益的权衡过程,期待硬件技术的发展。
参考资料
[1]Tom Young, Devamanyu Hazarika, Soujanya Poria, Erik Cambria.Recent Trends 2018. in Deep Learning Based Natural Language Processing.
[2]Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin. 2003. A neural probabilistic language model.
[3]R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa. 2011. Natural language processing (almost) from scratch
[4]T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. 2013. Distributed representations of words and phrases and their compositionality
[5]A.Paccanaro,G.Hinton. 1986. Learning Distributed Representations of Concepts using Linear Relational Embedding.
[6]H. Schutze. Word space. In S. J. Hanson, J. D. Cowan, and C. L. Giles. 1993. Advances in Neural Information Processing Systems.
[7]A. Joulin, E. Grave, P. Bojanowski, T. Mikolov. 2016. Bag of Tricks for Efficient Text Classification
[8]Q. Le, T. Mikolov. 2014. Distributed Representations of Sentences and Documents
[9]A. Joulin, E. Grave, P. Bojanowski, T. Mikolov. 2017. Enriching Word Vectors with Subword Information
[10]A. Gittens, D. Achlioptas, and M. W. Mahoney. 2017. Skip-gram-zipf+ uniform= vector additivity.
[11]G. Lample, A. Conneau. 2019. Cross-Lingual Language Model Pretraining.
[12]R. Collobert and J. Weston. 2008. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning.
[13]Y. Kim. 2014. Convolutional Neural Networks for Sentence Classification
[14]N. Kalchbrenner, E. Grefenstette, P. Blunsom. 2014. A Convolutional Neural Network for Modelling Sentences.
[15]Y. Dauphin, A. Fan, M. Auli, D. Grangier. 2017. Language Modeling with Gated Convolutional Networks.
[16]A. Conneau, H. Schwenk, Y. Le Cun, L. Barrault. 2017. Very Deep Convolutional Networks for Text Classification.
[17]J. L. Elman. 1990. Finding structure in time.
[18]T. Mikolov, M. Karafia ́t, L. Burget, J. Cernocky`, and S. Khudanpur. 2010. Recurrent neural network based language model.
[19]G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer. 2016. Neural architectures for named entity recognition.
[20]M. Malinowski, M. Rohrbach, and M. Fritz. 2015. Ask your neurons: A neural-based approach to answering questions about images.
[21]S. R. Bowman, L. Vilnis, O. Vinyals, A. M. Dai, R. Jozefowicz, and S. Bengio. 2015. Generating sentences from a continuous space.
[22]K.Cho,B.Merrienboer,C.Gulcehre,F.Bougares,H.Schwenk,andY.Bengio. 2014. Learningphraserepresen- tations using RNN encoder-decoder for statistical machine translation.
[23]I. Sutskever, O. Vinyals, and Q. V. Le. 2014. Sequence to sequence learning with neural networks
[24]D.Bahdanau,K.Cho,andY.Bengio. 2014. Neural machine translation by jointly learning to align and translate.
[25]M. Luong, H. Pham, C. Manning. 2015. Effective Approaches to Attention-based Neural Machine Translation.
[26]Y. Wang, M. Huang, X. Zhu, and L. Zhao. 2016. Attention-based lstm for aspect-level sentiment classification.
[27]W. Yin, H. Schuzte, B. Xiang, B. Zhou. 2018. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs.
[28]Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. 2017. Convolu- tional sequence to sequence learning.
[29]Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Ko- ray Kavukcuoglu. 2017. Neural machine translation in linear time.
[30]A. Vaswani, N. Shazeer, N. Parmar, and J. Uszkoreit. 2017. Attention is all you need.
[31]Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language under- standing by Generative Pre-Training.
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%87%E5%AD%97%E9%95%BF%E6%96%87%E5%B8%A6%E4%BD%A0%E8%A7%A3%E8%AF%BB%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%9A%84%E5%90%84%E7%B1%BB%E6%A8%A1%E5%9E%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


