上的用命名实体识别任务来解释推理
作者:CreateMoMo
编译:ronghuaiyang
导读
今天是第三部分,介绍如何推理新的句子。
前两篇链接:
BiLSTM 上的 CRF,用命名实体识别任务来解释 CRF(1)
BiLSTM 上的 CRF,用命名实体识别任务来解释 CRF(2)损失函数
2.6 为新的句子推理标签
在前面的章节中,我们学习了 BiLSTM-CRF 模型的结构和 CRF 损失函数的细节。你可以通过各种开源框架(Keras、Chainer、TensorFlow 等)实现自己的 BiLSTM-CRF 模型。最重要的事情之一是模型的反向传播是在这些框架上自动计算的,因此你不需要自己实现反向传播来训练你的模型(即计算梯度和更新参数)。此外,一些框架已经实现了 CRF 层,因此将 CRF 层与你自己的模型结合起来非常容易,只需添加一行代码即可。
在本节中,我们将探索如何在模型准备好时在测试期间推断句子的标签。
步骤 1:BiLSTM-CRF 模型的 Emission 和 transition 得分
假设,我们有一个包含三个单词的句子:x = [w_0,w_1,w_2]
此外,我们已经从 BiLSTM 模型得到了 Emission 分数,从下面的 CRF 层得到了 transition 分数:
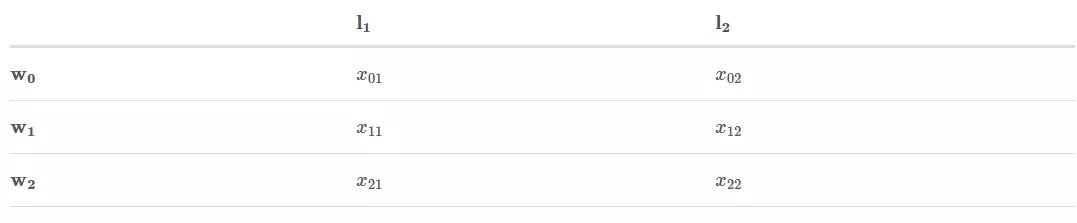
x_{ij}表示w_i被标记为l_j的得分。

t_{ij}是从标签 i 转换成标签 j 的得分。
步骤 2:开始推理
如果你熟悉 Viterbi 算法,那么这一部分对你来说很容易。但如果你不熟悉,请不要担心。与前一节类似,我将逐步解释该算法。我们将从句子的左到右进行推理算法,如下图所示:
- w_0
- w_0 -> w_1
- w_0 -> w_1 -> w_2
你会看到两个变量:obs 和 previous。previous 存储前面步骤的最终结果。obs 表示当前单词的信息。
alpha_0是历史最好得分,alpha_1是历史对应的索引。这两个变量的细节将在它们出现时进行解释。请看下面的图片:你可以把这两个变量当作狗在探索森林时沿路留下的“记号”,这些“记号”可以帮助狗找到回家的路。
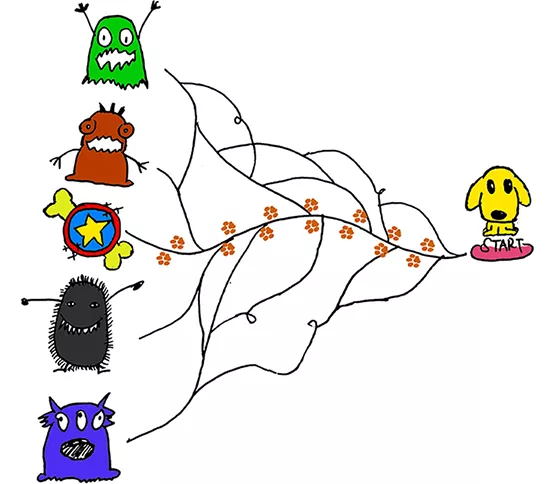
狗需要找到最好的路径来得到他最喜欢的骨头玩具,然后沿着他来的路回家
w_0:
obs=[x_{01}, x_{02}] previous=None
现在,我们观察到第一个单词,现在,对于是很明显的。
比如,如果obs=[x_{01}=0.2, x_{02}=0.8],很显然,w_0的最佳标签是l_2.
因为只有一个单词,而且没有标签直接的转换,transition 的得分没有用到。
w_0 -> w_1:
obs=[x_{11}, x_{12}] previous=[x_{01}, x_{02}]
- 把 previous 扩展成:
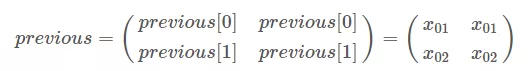
- 把 obs 扩展成:
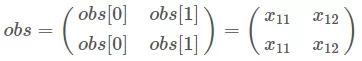
- 把 previous, obs 和 transition 分数都加起来:
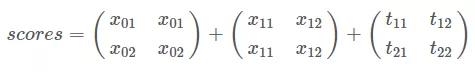
然后:
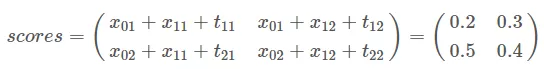
你可能想知道,当我们计算所有路径的总分时,与上一节没有什么不同。请耐心和细心,你很快就会看到区别。
为下一次迭代更改 previous 的值:
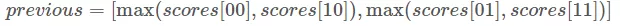
比如,如果我们的得分是:
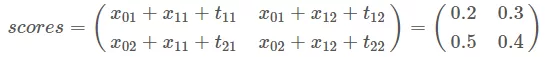
我们的下个迭代的 previous 是:
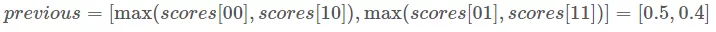
previous 有什么含义吗? previous 列表存储了每个当前的单词的标签的最大的得分。
[Example Start]
举个例子:
我们知道在我
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%8A%E7%9A%84%E7%94%A8%E5%91%BD%E5%90%8D%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB%E4%BB%BB%E5%8A%A1%E6%9D%A5%E8%A7%A3%E9%87%8A%E6%8E%A8%E7%90%86/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


